Il existe une classe de tâches si populaire dans laquelle il est nécessaire d'effectuer une analyse suffisamment approfondie de l'ensemble du volume des chaînes de travail enregistrées par tout système d'information (SI). En tant qu'IP, il peut y avoir un flux de documents, un centre de services, un suivi des bogues, un journal électronique, la comptabilité d'entrepôt, etc. Les nuances se manifestent dans les modèles de données, les API, les volumes de données et d'autres aspects, mais les principes de résolution de ces problèmes sont à peu près les mêmes. Et le râteau sur lequel vous pouvez marcher est également très similaire.
Pour résoudre cette classe de problèmes, R s'adapte parfaitement. Mais, pour ne pas hausser les épaules de manière décevante, que R peut être bon, mais oh, très lent, il est important de faire attention aux performances des méthodes de traitement de données sélectionnées.
Il s'agit d'une continuation des publications précédentes .
Habituellement, une approche «frontale» superficielle n'est pas la plus efficace. 99% des tâches associées à l'analyse et au traitement des données commencent par leur importation. Dans ce bref essai, nous examinerons les problèmes qui se posent au stade de base de l'importation de données avec des données au format json , en utilisant l'exemple d'une tâche typique d'analyse "approfondie" des données d'installation de Jira. json prend en charge un modèle d'objet complexe, contrairement à csv , donc l'analyse dans le cas de structures complexes peut devenir très difficile et longue.
Énoncé du problème
Étant donné:
- jira est implémenté et utilisé dans le processus de développement logiciel comme système de gestion des tâches et traqueur de bogues.
- Il n'y a pas d'accès direct à la base de données jira, l'interaction se fait via l'API REST (isolation galvanique).
- Les fichiers json à prendre ont une structure arborescente très complexe avec des tuples imbriqués nécessaires pour télécharger tout l'historique des actions. Le calcul des métriques nécessite un nombre relativement petit de paramètres dispersés à différents niveaux de la hiérarchie.
Un exemple d'un jira json régulier sur la figure.
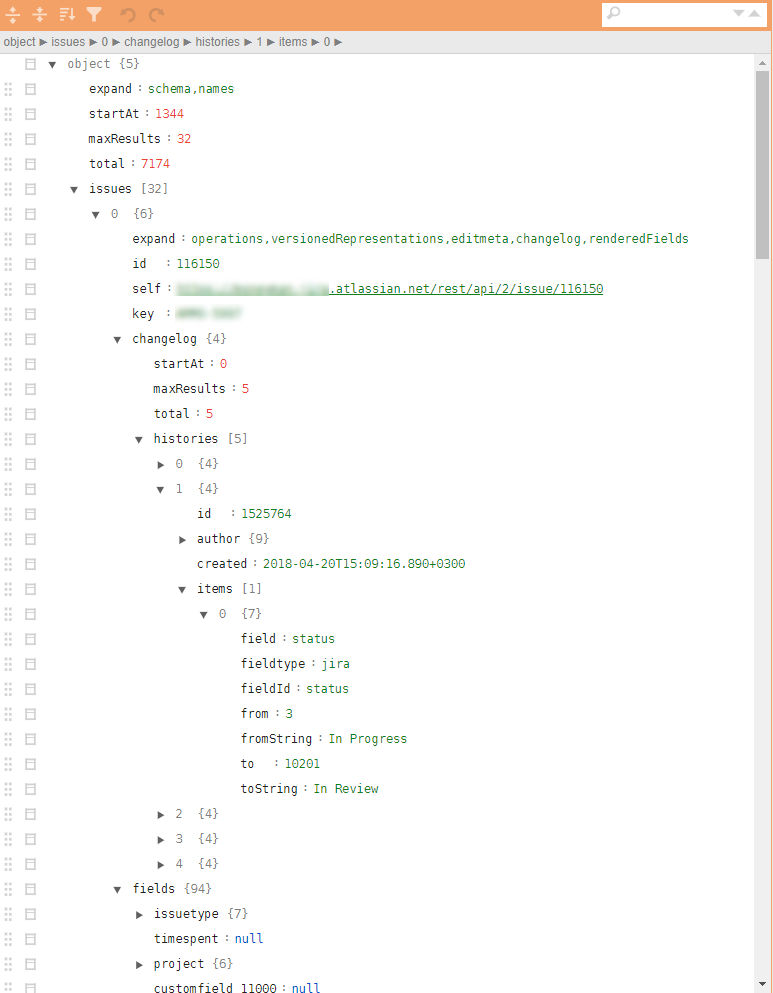
Il faut:
- Sur la base des données jira, il est nécessaire de trouver les goulots d'étranglement et les points d'une éventuelle augmentation de l'efficacité des processus de développement et d'améliorer la qualité du produit résultant sur la base d'une analyse de toutes les actions enregistrées.
Solution
Théoriquement, il existe plusieurs packages différents dans R pour charger json et les convertir en data.frame . Le package le plus pratique est jsonlite . Cependant, la conversion directe de la hiérarchie json en data.frame difficile en raison de l'imbrication à plusieurs niveaux et du paramétrage fort de la structure d'enregistrement. L'embrayage de paramètres spécifiques liés, par exemple, à l'historique des actions, peut nécessiter diverses ext. vérifie et boucle. C'est-à-dire le problème peut être résolu, mais pour un fichier json de 32 tâches (comprend tous les artefacts et l'historique complet des tâches), une telle analyse non linéaire utilisant jsonlite et tidyverse prend environ 10 secondes sur un ordinateur portable à performances moyennes.
10 secondes seules, ce n'est pas beaucoup. Mais exactement jusqu'au moment où il n'y a pas trop de ces fichiers. L'évaluation d'un échantillon analysant et chargeant en utilisant une méthode similaire "directe" ~ 4000 fichiers (~ 4 Go) a donné 8-9 heures de travail.
Un si grand nombre de fichiers est apparu pour une raison. Tout d'abord, jira a des limites de temps pour une session REST, il est impossible de tout retirer avec une poutre. Deuxièmement, étant intégré au circuit de production, le téléchargement quotidien de données sur les tâches mises à jour est attendu. Troisièmement, et cela sera mentionné ci-dessous, la tâche est très bonne pour la mise à l'échelle linéaire et vous devez penser à la parallélisation dès la toute première étape.
Même 10 à 15 itérations au stade de l'analyse des données, l'identification de l'ensemble minimal requis de paramètres, la détection de situations exceptionnelles ou erronées et le développement d'algorithmes de post-traitement entraînent des coûts de 2 à 3 semaines (seulement le temps de comptage).
Naturellement, une telle «performance» ne convient pas à l'analyse opérationnelle, qui est intégrée au circuit de production, et est très inefficace au stade de l'analyse initiale des données et du développement du prototype.
Ignorant tous les détails intermédiaires, je passe immédiatement à la réponse. Nous rappelons Donald Knuth, retroussons nos manches et commençons à mettre en place toutes les opérations clés, coupant impitoyablement tout ce qui est possible.
La solution résultante est réduite aux 10 lignes suivantes (il s'agit d'un faux squelette, sans kit de corps non fonctionnel ultérieur):
library(tidyverse) library(jsonlite) library(readtext) fnames <- fs::dir_ls(here::here("input_data"), glob = "*.txt") ff <- function(fname){ json_vec <- readtext(fname, text_field = "texts", encoding = "UTF-8") %>% .$text %>% jqr::jq('[. | {issues: .issues}[] | .[]', '{id: .id, key: .key, created: .fields.created, type: .fields.issuetype.name, summary: .fields.summary, descr: .fields.description}]') jsonlite::fromJSON(json_vec, flatten = TRUE) } tictoc::tic("Loading with jqr-jsonlite single-threaded technique") issues_df <- fnames %>% purrr::map(ff) %>% data.table::rbindlist(use.names = FALSE) tictoc::toc() system.time({fst::write_fst(issues_df, here::here("data", "issues.fst"))})
Qu'est-ce qui est intéressant ici?
- Pour accélérer le processus de chargement, il est bon d’utiliser des packages spécialisés et profilés, tels que du
readtext . - L'utilisation de l'
jq streaming jq permet de traduire tous les accrochages des attributs nécessaires dans un langage fonctionnel, de le réduire au niveau CPP et de minimiser la manipulation manuelle des listes imbriquées ou des listes dans data.frame . - Un ensemble de
bench très prometteur pour les microbenchmarks est apparu. Il vous permet d'étudier non seulement le temps d'exécution des opérations, mais aussi la manipulation de la mémoire. Ce n'est pas un secret que vous pouvez perdre beaucoup en copiant des données en mémoire. - Pour de grandes quantités de données et un traitement simple, il est souvent nécessaire dans la décision finale d'abandonner
tidyverse et de transférer les parties chronophages vers data.table , en particulier, les tables sont fusionnées ici à l'aide de data.table . Et toutes les transformations au stade du post-traitement (qui sont incluses dans le cycle de la fonction ff sont également effectuées à l'aide des outils data.table avec l'approche de changer les données par référence, ou des packages construits à l'aide de Rcpp , par exemple, un package à anytime pour travailler avec des dates et des heures. - Le package
fst est très bon pour vider des données dans un fichier et ensuite les lire. En particulier, il ne faut qu'une fraction de seconde pour enregistrer toutes les analyses de l'historique jira pendant 4 ans, et les données sont enregistrées exactement comme les types de données R, ce qui est bon pour leur réutilisation ultérieure.
Au cours de la solution, une approche utilisant le package rjson été rjson . L' jsonlite::fromJSON environ 2 fois plus lente que rjson = rjson::fromJSON(json_vec) , mais il était nécessaire de la laisser, car il y a des valeurs NULL dans les données, et au stade de la conversion NULL en NA dans les listes rjson par rjson nous perdons avantage, et le code devient plus lourd.
Conclusion
- Un tel refactoring a conduit à une modification du temps de traitement de tous les fichiers json en mode single-threaded sur le même ordinateur portable de 8-9 heures à 10 minutes.
- L'ajout de la parallélisation de la tâche à l'aide de
foreach n'a pratiquement pas alourdi le code (+ 5 lignes) mais a réduit le temps d'exécution à 5 minutes. - Le transfert de la solution vers un serveur Linux faible (seulement 4 cœurs), mais l'exécution sur un SSD en mode multi-thread a réduit le temps d'exécution à 40 secondes.
- La publication sur un circuit productif (20 cœurs, 3 GHz, SSD) a réduit le temps d'exécution à 6-8 secondes, ce qui est plus qu'acceptable pour les tâches d'analyse opérationnelle.
Au total, restant dans le cadre de la plateforme R, une simple refactorisation de code a réussi à réduire le temps d'exécution de ~ 9 heures à ~ 9 secondes.
Les décisions sur R peuvent être assez rapides. Si quelque chose ne fonctionne pas pour vous, essayez de le regarder sous un angle différent et d'utiliser de nouvelles techniques.
Publication précédente - «Parachute Analytique pour Manager» .