Dans la première partie, nous nous sommes familiarisés avec les méthodes d'adaptation de domaine par apprentissage profond. Nous avons parlé des principaux ensembles de données, ainsi que des approches non génératives fondées sur les écarts et basées sur les accusations. Ces méthodes fonctionnent bien pour certaines tâches. Et cette fois, nous analyserons les méthodes contradictoires les plus complexes et les plus prometteuses: les modèles génératifs, ainsi que les algorithmes qui montrent les meilleurs résultats sur l'ensemble de données VisDA (adaptations des données synthétiques aux photos réelles).

Modèles génératifs
La base de cette approche est la capacité du GAN à générer des données à partir de la distribution nécessaire. Grâce à cette propriété, vous pouvez obtenir la bonne quantité de données synthétiques et l'utiliser pour la formation. L'idée principale des méthodes de la famille des modèles génératifs est de générer des données en utilisant le domaine source qui soit aussi similaire que possible aux représentants du domaine cible. Ainsi, les nouvelles données synthétiques auront les mêmes labels que les représentants du domaine d'origine sur la base desquels elles ont été obtenues. Ensuite, le modèle du domaine cible est simplement formé sur ces données générées.
Présentée à ICML-2018, la méthode CyCADA: Adaptation de domaine contradictoire ( code ) à cycle cohérent est un membre représentatif de la famille des modèles génératifs. Il combine plusieurs approches réussies des GAN et l'adaptation de domaine. Une partie importante de cela est l'utilisation de la perte de cohérence du cycle, introduite pour la première fois dans un article sur CycleGAN . L'idée de perte de cohérence de cycle est que l'image obtenue en générant de la source vers le domaine cible, suivie de la transformation inverse, doit être proche de l'image initiale. De plus, CyCADA inclut une adaptation au niveau des pixels et au niveau des représentations vectorielles, ainsi qu'une perte sémantique pour sauvegarder la structure dans l'image générée.
Soit fT et fS - réseaux pour les domaines cible et source, respectivement, XT et XS - domaines cible et source, YS - balisage sur le domaine source, GS−>T et GT−>S - des générateurs de la source au domaine cible et inversement, DT et DS - discriminateurs d'appartenance aux domaines cible et source, respectivement. Ensuite, la fonction de perte, qui est minimisée dans CyCADA, est la somme de six fonctions de perte (le programme de formation avec les nombres de pertes est présenté ci-dessous):
- Ltâche(fT,GS−>T(XS),YS) - classification des modèles fT sur les données générées et les pseudo-étiquettes du domaine source.
- LGAN(GS−>T,DT,XT,XS) - perte accusatoire pour la formation des générateurs GS−>T .
- LGAN(GT−>S,DS,XS,XT) - perte accusatoire pour la formation des générateurs GT−>S .
- Lcyc(GS−>T,GT−>S,XS,XT) (perte de cohérence du cycle) - L1 -perte, en veillant à ce que les images obtenues GS−>T et GT−>S sera proche.
- LGAN(fT,Dfeat,fS(GS−>T(XS)),XT) - perte accusatoire pour les représentations vectorielles fT et fS sur les données générées (similaire à ce qui est utilisé dans ADDA).
- Lsem(GS−>T,GT−>S,XS,XT,fS) (perte de cohérence sémantique) - L1 perte, responsable du fait que fS fonctionnera de la même manière que sur les images GS−>T à la fois de GT−>S .
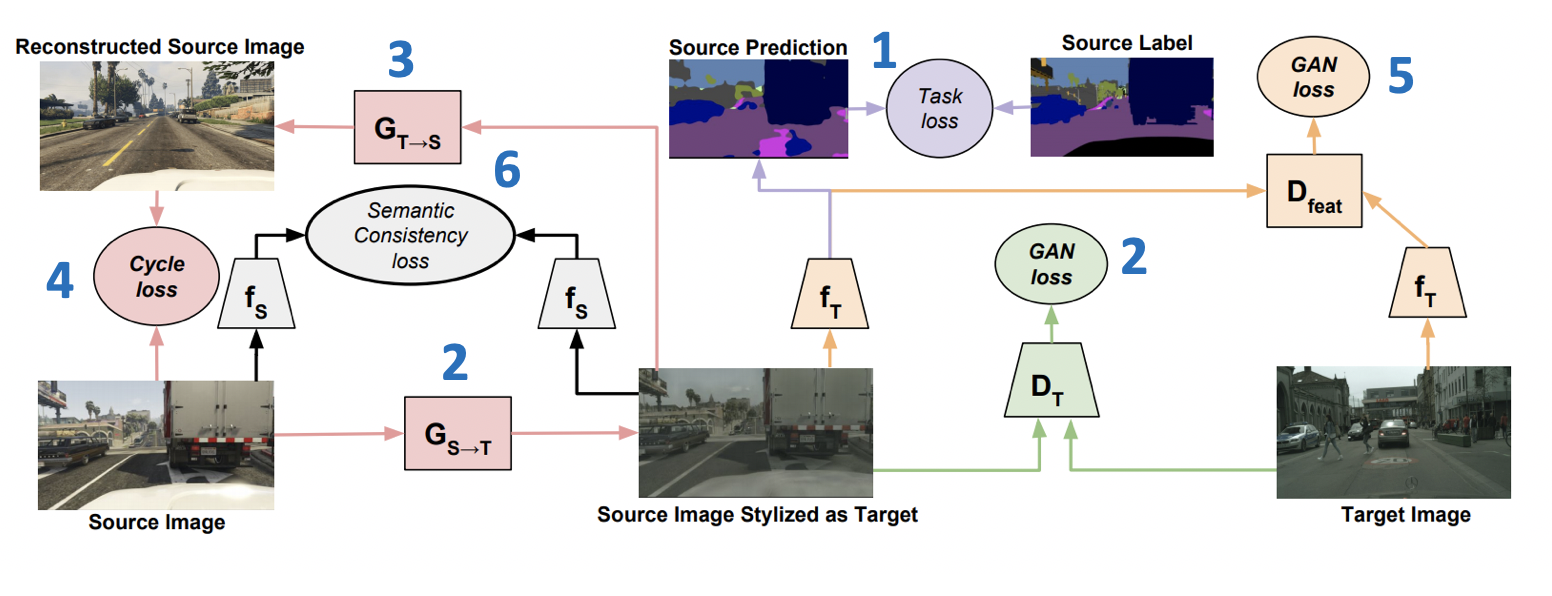
Résultats de CyCADA:
- Sur une paire de domaines numériques USPS -> MNIST: 95,7%.
- Sur la tâche de segmentation GTA 5 -> Paysages urbains: IoU moyen = 39,5%.
Dans le cadre de l'approche, Generate To Adapt: Aligning Domains using Generative Adversarial Networks ( code ) forme un tel générateur G de sorte qu'en sortie il produit des images proches du domaine d'origine. Ces G vous permet de convertir les données du domaine cible et de leur appliquer le classificateur formé sur les données balisées du domaine source.
Pour former un tel générateur, les auteurs utilisent un discriminateur modifié D extrait de l'article AC-GAN . Caractéristique de cette D réside dans le fait qu'il répond non seulement 1 si l'entrée provient du domaine source, et 0 sinon, mais également dans le cas d'une réponse positive il classe les données d'entrée selon les classes du domaine source.
Nous dénotons F comme un réseau convolutionnel qui produit une représentation vectorielle d'une image, C - un classificateur qui fonctionne sur un vecteur dérivé de F . Algorithmes d'apprentissage et d'inférence:
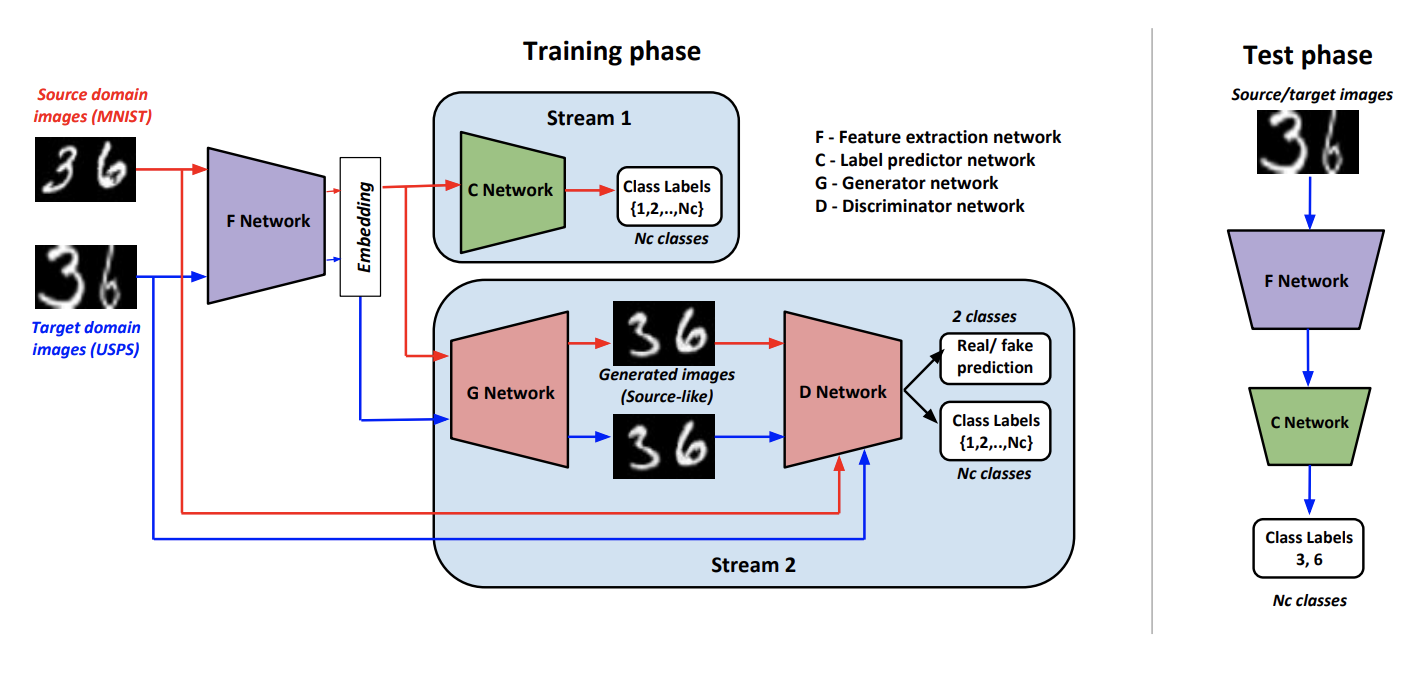
La procédure de formation comprend plusieurs éléments:
- Discriminateur D apprend à déterminer le domaine pour tout reçu de G et pour le domaine source, une perte de classification est toujours ajoutée, comme décrit ci-dessus.
- Sur les données du domaine source G en utilisant une combinaison de perte accusatoire et de classification, il est formé pour générer un résultat similaire au domaine source et correctement classé D .
- F et C Apprenez à classer les données du domaine source. Aussi F à l'aide d'une autre perte de classification, elle est modifiée de manière à augmenter la qualité de la classification D .
- Utiliser la perte accusatoire F apprend à "tricher" D sur les données du domaine cible.
- Les auteurs ont empiriquement conclu qu'avant de soumettre à G il est logique de concaténer un vecteur de F avec un bruit normal et un vecteur de classe à chaud ( K+1 pour les données cibles).
Les résultats de la méthode sur les benchmarks:
- Sur les domaines numériques USPS -> MNIST: 90,8%.
- Sur l'ensemble de données Office, la qualité moyenne d'adaptation pour les paires de domaines Amazon et Webcam est de 86,5%.
- Dans l'ensemble de données VisDA, la valeur de qualité moyenne pour 12 catégories sans classe inconnue est de 76,7%.
Dans l'article De la source à la cible et inversement: GAN adaptatif bidirectionnel symétrique ( code ), le modèle SBADA-GAN a été introduit, qui est assez similaire à CyCADA et dont la fonction cible, comme CyCADA, se compose de 6 composants. Dans la notation des auteurs Gst et Gts - des générateurs du domaine source à la cible et inversement, Ds et Dt - des discriminateurs qui distinguent les données réelles des données générées dans les domaines source et cible, respectivement, Cs et Ct - des classificateurs formés sur les données du domaine source et sur leurs versions transformées dans le domaine cible.
SBADA-GAN, comme CyCADA, utilise l'idée de CycleGAN, la perte de cohérence et les pseudo-étiquettes pour les données générées dans le domaine cible, en composant la fonction cible à partir des termes correspondants. Les fonctionnalités de SBADA-GAN comprennent:
- L'image + le bruit est envoyé à l'entrée des générateurs.
- Le test utilise une combinaison linéaire de prédictions du modèle cible et du modèle source en fonction de la transformation Gst .
Programme de formation SBADA-GAN:
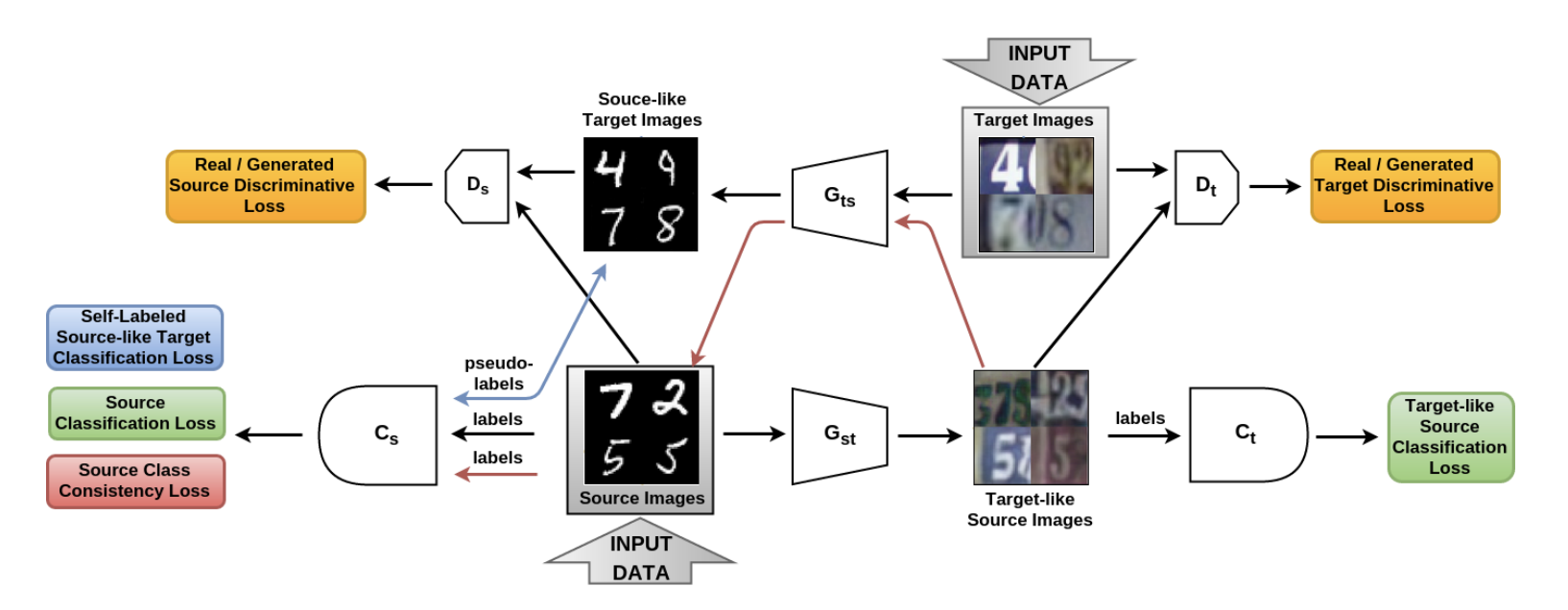
Les auteurs de SBADA-GAN ont mené plus d'expériences que les auteurs de CyCADA et ont obtenu les résultats suivants:
- Sur les domaines USPS -> MNIST: 95,0%.
- Sur les domaines MNIST -> SVHN: 61,1%.
- Signalisation routière Synth Signs -> GTSRB: 97,7%.
De la famille des modèles génératifs, il est logique de considérer les articles significatifs suivants:
Défi d'adaptation du domaine visuel
Dans le cadre de l'atelier, les conférences ECCV et ICCV organisent un concours d'adaptation de domaine du Visual Domain Adaptation Challenge . Dans ce document, les participants sont invités à former le classificateur sur les données synthétiques et à l'adapter aux données non attribuées d'ImageNet.
L'algorithme présenté dans Auto-assemblage pour l'adaptation du domaine visuel ( code ) a gagné dans VisDA-2017. Cette méthode est basée sur l'idée de l'auto-assemblage: il existe un réseau d'enseignants (modèle d'enseignant) et un réseau d'élèves. À chaque itération, l'image d'entrée est exécutée sur ces deux réseaux. L'élève est formé en utilisant la somme de la perte de classification et de la perte de cohérence, où la perte de classification est l'entropie croisée habituelle avec une étiquette de classe bien connue, et la perte de cohérence est la différence quadratique moyenne entre les prédictions de l'enseignant et de l'élève (différence quadratique). Les poids du réseau d'enseignants sont calculés comme la moyenne mobile exponentielle des poids du réseau d'élèves. Cette procédure de formation est illustrée ci-dessous.
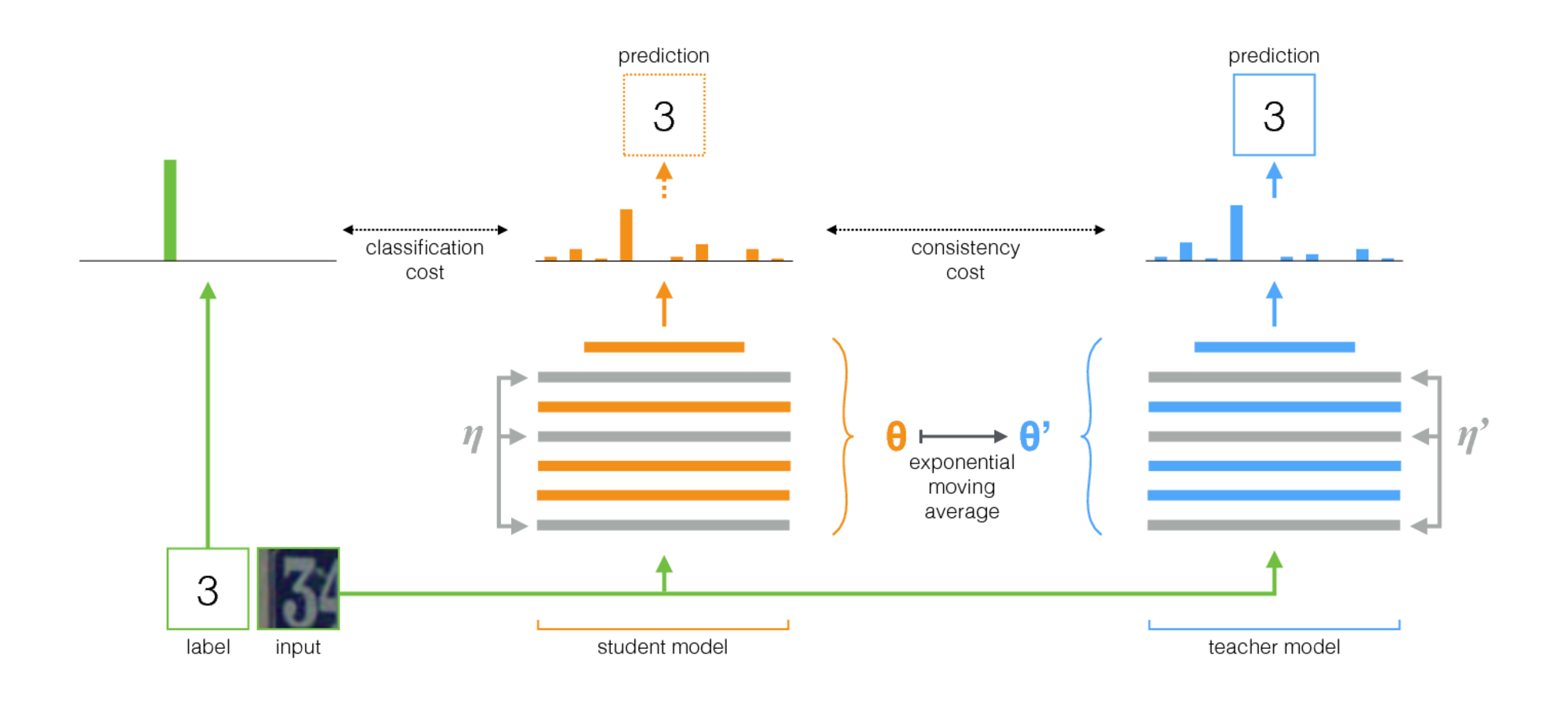
Les caractéristiques importantes de l'application de cette méthode d'adaptation de domaine sont:
- Dans le lot de formation, les données du domaine source sont mélangées xSi avec des étiquettes de classe ySi et les données du domaine cible xTi sans étiquettes.
- Avant l'entrée d'images dans les réseaux de neurones, diverses augmentations fortes sont appliquées: bruits gaussiens, transformations affines, etc.
- Les deux réseaux ont utilisé de solides méthodes de régularisation (telles que le décrochage).
- zTi - sortie réseau étudiant, widetildezTi - enseignants du réseau. Si l'entrée provient du domaine cible, seule la perte de cohérence entre zTi et widetildezTi , perte d'entropie croisée = 0.
- Pour la durabilité de l'apprentissage, un seuil de confiance est utilisé: si la prédiction de l'enseignant est inférieure au seuil (0,9), alors la perte de perte de cohérence = 0.
Schéma de la procédure décrite:

Sur les principaux jeux de données, l'algorithme a atteint des performances élevées. Certes, les auteurs ont sélectionné séparément un ensemble d'augmentations pour chaque tâche.
- USPS -> MNIST: 99,54%.
- MNIST -> SVHN: 97,0%.
- Numéros de synthé -> SVHN: 97,11%.
- Signalisation routière Synth Signs -> GTSRB: 99,37%.
- Dans l'ensemble de données VisDA, la valeur de qualité moyenne pour 12 catégories sans la classe Inconnu est de 92,8%. Il est important de noter que ce résultat a été obtenu en utilisant un ensemble de 5 modèles et en utilisant l'augmentation du temps de test.
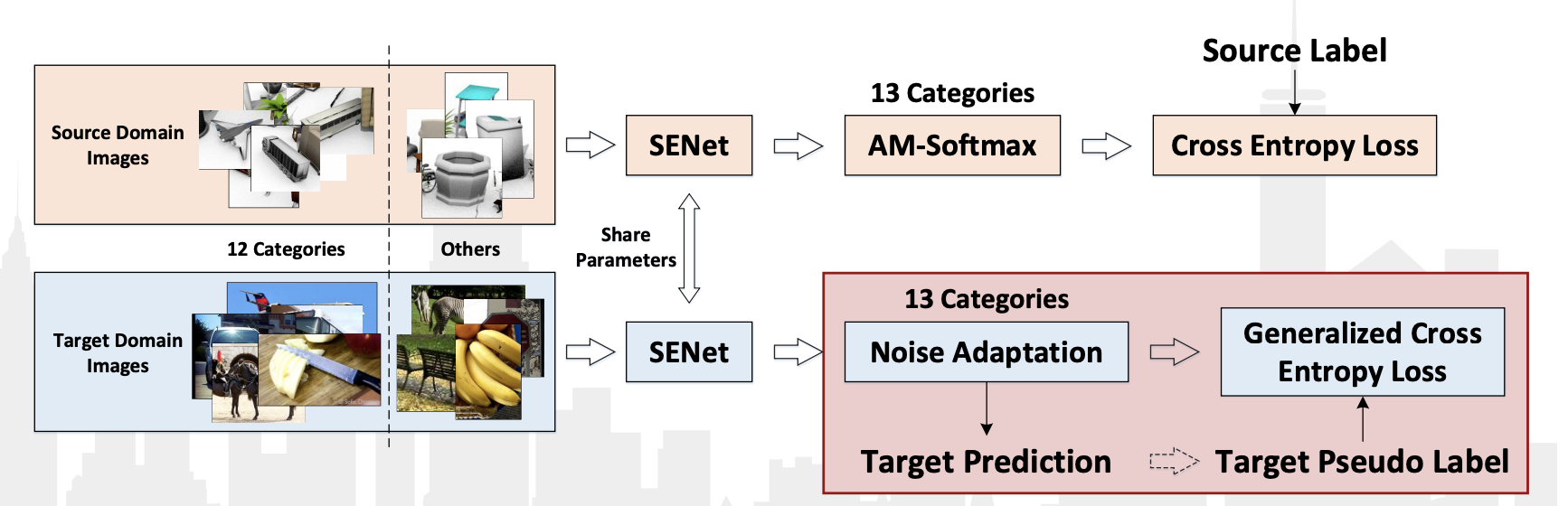
Le concours VisDA-2018 a eu lieu cette année dans le cadre de la conférence ECCV-2018. Cette fois, ils ont ajouté la 13e classe: Unknown, qui a obtenu tout ce qui ne tombait pas en 12 classes. De plus, un concours distinct a été organisé pour détecter les objets appartenant à ces 12 classes. Dans les deux catégories, l'équipe chinoise JD AI Research a gagné. Au concours de classement, ils ont obtenu un résultat de 92,3% (la valeur moyenne de la qualité dans 13 catégories). Il n'y a pas de publications avec une description détaillée de leur méthode, il n'y a qu'une présentation de l'atelier .
Des caractéristiques de leur algorithme peuvent être notées:
- Utilisation de pseudo-étiquettes pour les données du domaine cible et recyclage du classificateur sur celles-ci avec les données du domaine source.
- Utilisation du réseau de convolution SE-ResNeXt-101, couche d'adaptation AM-Softmax et bruit, perte d'entropie croisée généralisée pour les données du domaine cible.
Diagramme d'algorithme de la présentation:
Conclusion
Pour la plupart, nous avons discuté des méthodes d'adaptation basées sur l'approche basée sur le contradictoire. Cependant, dans les deux derniers concours VisDA, des algorithmes qui ne lui étaient pas liés et utilisant une formation sur des pseudo-étiquettes et des modifications de méthodes d'apprentissage en profondeur plus classiques ont gagné. À mon avis, cela est dû au fait que les méthodes basées sur les GAN ne sont encore qu'au début de leur développement et sont extrêmement instables. Mais chaque année, nous obtenons de plus en plus de nouveaux résultats qui améliorent le travail des GAN. En outre, l'intérêt de la communauté scientifique dans le domaine de l'adaptation de domaine est principalement axé sur les méthodes basées sur le contradictoire, et de nouveaux articles étudient principalement cette approche. Par conséquent, il est probable que les algorithmes associés aux GAN viendront progressivement au premier plan des problèmes d'adaptation.
Mais la recherche d'approches non accusatoires est également en cours. Voici quelques articles intéressants de ce domaine:
Les méthodes basées sur les écarts peuvent être classées comme «historiques», mais bon nombre des idées utilisées dans les dernières méthodes: MMD, pseudo-étiquettes, apprentissage métrique, etc. De plus, parfois dans des problèmes d'adaptation simples, il est logique d'appliquer ces méthodes en raison de leur relative facilité d'apprentissage et d'une meilleure interprétabilité des résultats.
En conclusion, je tiens à noter que les méthodes d'adaptation de domaine sont toujours à la recherche de leur application dans des domaines appliqués, mais les tâches prospectives nécessitant l'utilisation de l'adaptation deviennent progressivement de plus en plus. Par exemple, l'adaptation de domaine est activement utilisée dans la formation de modules de voitures autonomes : comme il est coûteux et long de collecter des données réelles dans les rues de la ville pour la formation de pilotes automatiques, les voitures autonomes utilisent des données synthétiques (les bases de données SYNTHIA et GTA 5 servent d'exemples), en particulier. pour résoudre le problème de la segmentation de ce que la caméra «voit» de la voiture.
L'obtention de modèles de haute qualité basés sur une formation approfondie à Computer Vision dépend largement de la disponibilité de grands ensembles de données étiquetés pour la formation. Le balisage nécessite presque toujours beaucoup de temps et d'argent, ce qui augmente considérablement le cycle de développement des modèles et, par conséquent, des produits basés sur eux.
Les méthodes d'adaptation de domaine visent à résoudre ce problème et peuvent potentiellement contribuer à une percée dans de nombreux problèmes appliqués et dans l'intelligence artificielle en général. Le transfert de connaissances d'un domaine à un autre est une tâche vraiment difficile et intéressante, qui est actuellement activement étudiée. Si vous souffrez d'un manque de données dans vos tâches et que vous pouvez émuler des données ou trouver des domaines similaires, je vous recommande d'essayer des méthodes d'adaptation de domaine!