
La plupart des développeurs connaissent et aiment les pages github. Au cas où vous ne les auriez pas rencontrés, ce service permet de créer un site statique à partir de votre référentiel, qui sera disponible sur le domaine smth.imtqy.com. C'est incroyablement pratique pour toute statique temporaire, documentation, petits sites simples, etc. Pas besoin de penser à une sorte de serveur Web supplémentaire.
Il y a aussi la possibilité de lier votre domaine au référentiel - alors tout sera très beau. Il existe même un support SSL.
Après cette courte introduction, nous passons au sujet réel de l'article. Plus récemment (9 novembre), j'ai eu une histoire intéressante. Je recommande de ne pas le lire en une seule gorgée, mais d'arrêter périodiquement et de me demander ce que signifient toutes les notes d'introduction reçues à l'heure actuelle. Je pense qu'un entraînement intéressant en sortira, bien que l'intrigue de mon détective n'ait pas été très longue et tordue.
J'ai décidé d'ajouter l'adresse de mon CV au profil suivant. Le résumé se trouve simplement sur les pages github, car pourquoi pas. Par habitude, il a cliqué pour vérifier si tout fonctionnait bien ... Et soudain j'ai découvert quelque chose d'étrange là-bas:
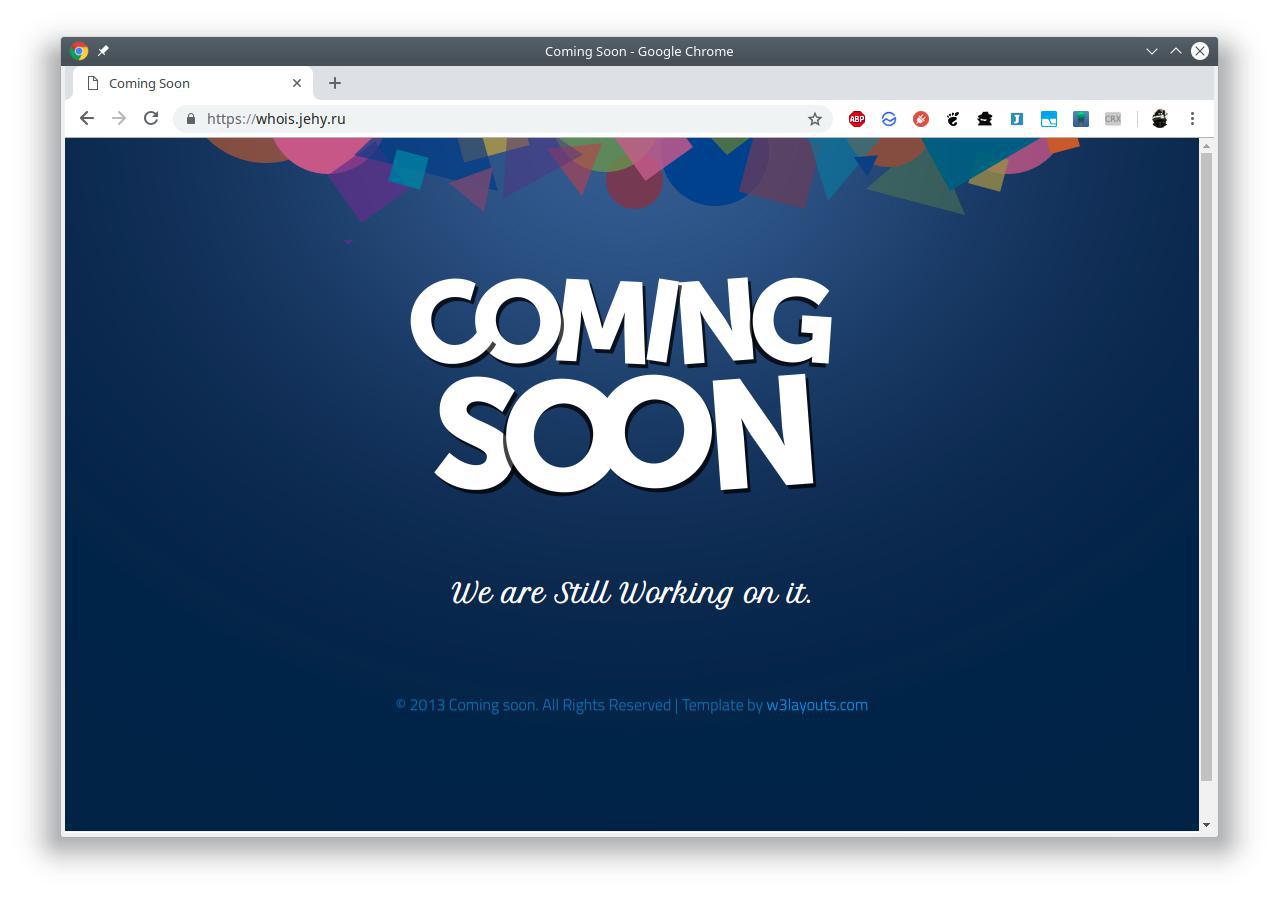
J'étais très surpris. Je suis allé aux paramètres du référentiel. J'ai vu qu'en ce moment il n'est pas lié au domaine auquel il devrait être lié. J'ai essayé de casser. J'ai soudain une erreur:
Le CNAME whois.jehy.ru est déjà pris. Consultez https://help.github.com/articles/troubleshooting-custom-domains/#cname-already-taken pour plus d'informations
Il se tendit un peu et fut surpris. Après cela, je suis allé regarder de près cette page soudaine. Comme auparavant, je n'y ai vu qu'un certain modèle standard, le copyright de 2013 et tout à coup un lien vers le plan du site. Le plan du site contient la date de sa génération à partir de la date actuelle, ainsi qu'un document HTML statique avec un nom et un contenu qui rappellent très la méthode de validation Google (nom googlef3e716e930ae1730 , googlef3e716e930ae1730 google-site-verification: googlef3e716e930ae1730.html ). Ici, j'étais déjà fortement tendu, j'ai couru, changé l'enregistrement NS sur mon serveur et commencé à penser à ce qui avait mal tourné.
La recherche sur la surface a révélé ce qui suit:
- Il semble que le détournement de domaine soit un problème potentiellement connu, et il a déjà été résolu - il suffit d' enregistrer l' adresse de votre référentiel dans CNAME .
- Malgré cela, dans de nombreuses instructions sur la liaison d'un github à un domaine (y compris à partir des 10 premières recherches), les adresses IP sont écrites directement, ou simplement imtqy.com.
Ensuite, j'ai pensé que j'avais probablement un enregistrement CNAME. Je l'ai donc changé pour le bon, lié à mon référentiel. Maintenant, l'entrée ressemblait à ceci:
dig whois.jehy.ru +nostats +nocomments +nocmd ; <<>> DiG 9.11.3-1ubuntu1.2-Ubuntu <<>> whois.jehy.ru +nostats +nocomments +nocmd ;; global options: +cmd ;whois.jehy.ru. IN A whois.jehy.ru. 6984 IN CNAME jehy.github.io. jehy.github.io. 3384 IN A 185.199.108.153 jehy.github.io. 3384 IN A 185.199.110.153 jehy.github.io. 3384 IN A 185.199.109.153 jehy.github.io. 3384 IN A 185.199.111.153
Et quelle a été ma stupéfaction lorsque j'ai revu ce merveilleux atterrissage «Coming Soon»!
Pour vérifier, j'ai même fait un autre test:
1) A commencé un nouveau record CNAME test.jehy.ru et lui a indiqué un profil de Ryan Dahl
2) Démarré un référentiel de test , en spécifiant pour lui un domaine personnalisé test.jehy.ru. Tout semble être correct, selon les instructions, et la reliure ne devrait pas fonctionner. Mais hélas, le résultat est évident .
Ensuite, j'ai contacté le support technique du github via un formulaire étrange sur le site . Là, ils m'ont dit qu'ils pouvaient délier le référentiel de quelqu'un d'autre de mon domaine si j'ajoutais un autre enregistrement NS à moi-même. Je l'ai fait, je l'ai réécrit, et du vendredi au lundi, je n'ai pas reçu de réponse. Peut-être était-il nécessaire de réécrire sous cette forme - mais c'était déjà plus élevé que ma force. Je viens donc de laisser mon site statique sur mon serveur.
À cette époque, j'avais trois options pour ce qui s'était passé:
1) Quelqu'un a accidentellement écrit l'adresse «whois.jehy.ru» dans son référentiel en 2018, tout en disposant une page de destination avec «à venir bientôt» de 2013, où pour une raison quelconque se trouve un html Google pour vérifier les droits. Enfin, à peine.
2) Un bug fou s'est produit. C'est également peu probable. Il a répété sur le deuxième site d'essai.
3) Le focus basé sur CNAME n'a jamais fonctionné, ou il s'est brisé, et les attaquants l'utilisent pour attaquer. Jusqu'à présent, cela m'a semblé l'option la plus probable.
Ensuite, je me suis souvenu que dans le cas de la liaison de domaine, github crée lui-même un fichier nommé CNAME dans votre référentiel. Et il est allé chercher qui a ajouté mon domaine. Et - bingo!
Un attaquant a été trouvé lors d'une recherche:
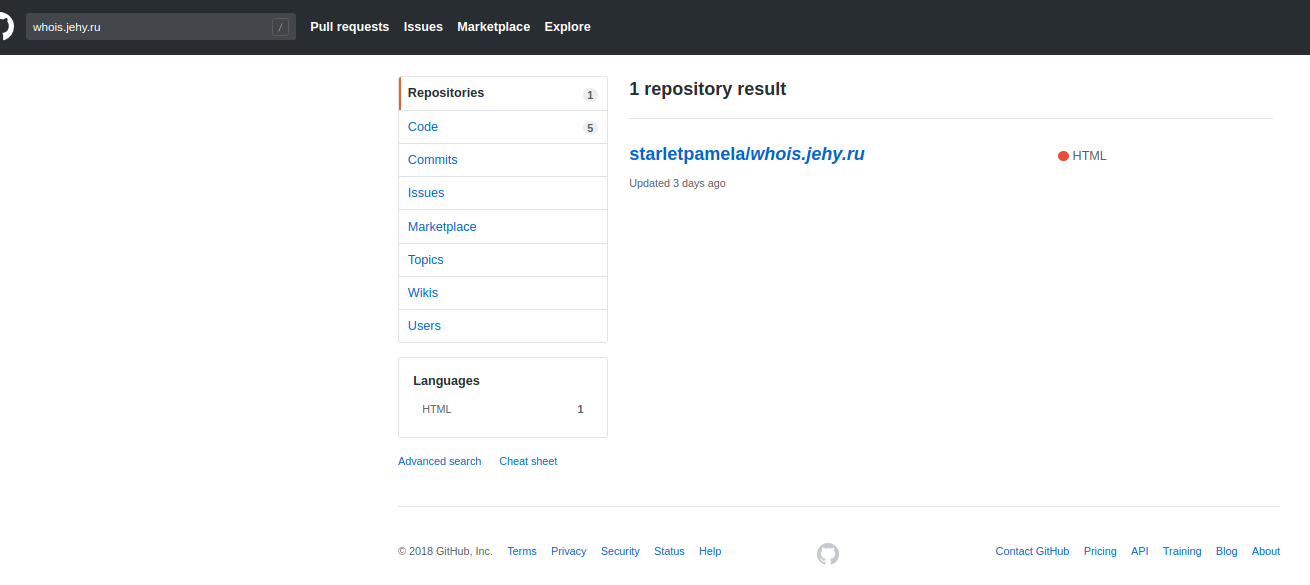
Voici mon domaine:

Et voici un tas d'autres:

Comme vous pouvez le voir, ce n'était pas du tout un accident. Quelqu'un a volé une quantité décente de domaines - y compris le deuxième niveau! Et il a eu le plein contrôle sur leur contenu, y compris en confirmant dans Google les droits de propriété de ces domaines!
À propos, vous pouvez également ajouter que parfois un pirate ne se contente pas de remplacer le contenu du site, mais de bifurquer le référentiel d'origine, après quoi il y ajoute des fichiers de vérification. Et donc ça fait plaisir depuis au moins un mois (j'ai trouvé des commits désinvoltes à partir du 6 octobre). Eh bien, les adeptes y sont similaires.
De plus, mes hypothèses sur la façon dont une telle attaque se produit et pourquoi elle est nécessaire.
1) Premièrement, le pirate trouve des sites qui se résolvent sur imtqy.com. C'est assez facile à faire.
2) Ensuite, il les filtre, ne laissant que ceux qui retournent une erreur (il semble qu'il n'y en ait que 404). Il peut y avoir de nombreux cas où les référentiels n'étaient pas liés - quelqu'un n'a pas configuré le référentiel, quelqu'un l'a supprimé, quelqu'un a obtenu les paramètres de liaison (il me semble que cela s'est produit lorsque j'ai changé la branche des pages github).
3) Ensuite, le pirate crée simplement un nouveau référentiel avec le contenu dont il a besoin et le lie au domaine "gratuit". Voila!
4) Alors tout ne dépend que de l'imagination du pirate. Portes, placer des liens, intercepter des données, accéder à la gestion de Google Apps via Google ... Il y a beaucoup d'options.
Ce que j'ai fait ensuite, avec toutes les preuves d'une utilisation malveillante des liaisons à portée de main:
- Décrit en correspondance avec support@github.com tous les détails;
- Encore une fois, réécrivez-les dans le formulaire de contact;
- Ajout d'un ticket à hackerone.com . Je dois dire qu'il indique que githubpages.io n'est pas inclus dans le programme de récompense, mais il n'y avait pas d'autres options. J'ai donc dû ignorer cet avertissement, et même le robot, qui m'a gentiment conseillé de ne pas envoyer ce rapport pour les mêmes raisons.
À ce jour, ils n'ont pas répondu au formulaire de contact à ce jour, mais deux jours plus tard, ils m'ont répondu sur hackerone. En bref, la réponse a été que c'est une caractéristique connue du service, ce n'est pas une vulnérabilité, et l'équipe de spam est engagée dans de telles choses. Le rapport a été clôturé comme "informatif", donc j'écris sur tout ce qui s'est passé en toute conscience. Ils m'ont également informé que le compte que j'ai indiqué était interdit. J'ai vérifié - oui, il n'est plus. Ses partisans ont disparu quelques jours plus tard (on ne sait pas pourquoi pas tout de suite).
On pourrait terminer là-dessus et dire que tout est en ordre ... Mais en fait, je suis extrêmement gêné par cette situation:
- Pourquoi ces comptes ne sont-ils pas en mois? Il y a un contenu identique, il y a des fichiers de validation Google partout, sur un seul compte il y a beaucoup de tels sites ... Signes communs - un chariot et un petit chariot.
- Pourquoi l'équipe de spam n'a-t-elle pas vérifié les référentiels associés?
- Pourquoi voyez-vous l'illusion de sécurité dans les instructions de liaison d'un domaine, suggérant que vous définissez le nom de votre référentiel dans CNAME si cela n'affecte rien?
- Pourquoi n'y a-t-il pas de mécanisme d'avertissement qui dirait qu'un domaine qui était auparavant lié à votre compte est maintenant lié à un autre?
- Pourquoi dans le github est-il impossible de répondre aux e-mails du support? Ou peut-être que je suis tombé sous une sorte de filtre?
Mais la principale question qui me dérange est pourquoi le github ne vérifie pas les enregistrements NS des domaines répertoriés sur les pages du github pour la présence d'un référentiel spécifique CNAME en eux? Il s'agit de l'opération la plus simple qui puisse être effectuée lors de la liaison d'un domaine, et ne prend pas de temps ... De plus, les instructions donnent l'impression qu'il était censé l'être ... Alors pourquoi ce chèque est-il cassé?
En général, j'écris ce post avec l'espoir que, sous une forme ou une autre, il atteindra le github et que les gars agiront. Avant la question "pourquoi en parler, tout le monde va grimper pour le faire maintenant" - je répondrai que le trou est déjà bien connu et est activement exploité. Et maintenant, clairement, les domaines «abandonnés» sont constamment analysés, donc plusieurs nouveaux participants ne changeront pas l'image.
Habituellement, je ne le fais pas, mais ce sera génial si vous tapotez la traduction de cet article, que j'ai mis sur le support. Oui, je sais que habr est maintenant multilingue, mais j'ai toujours vu un poste et demi en anglais, et je ne pense pas que quiconque puisse y prêter attention. Et sur le médium, il y a souvent de bons postes techniques. Ce sera donc génial si vous aidez à faire attention à ce trou. Si quoi que ce soit - je n’obtiendrai pas d’argent pour cela, il n’y a pas de carte US, l’intérêt est purement altruiste.
À quoi d'autre pouvez-vous penser à la fin? Probablement qu'il vaut toujours la peine de se rappeler lorsque vous placez quelque chose sur des capacités tierces. Bien sûr, sur Internet, il n'y a rien de personnel du tout, et tout est tiers - «vos» domaines appartiennent au registraire, «vos» serveurs appartiennent à Google, Amazon ou quelqu'un d'autre ... On ne peut pas dire que le github est moins fiable que n'importe quel serveur «propre» ... Mais "votre" serveur est en quelque sorte plus proche du corps et plus prévisible. En général, vous devez toujours vous souvenir de vos ressources, de leur importance, des pertes potentielles lors de leur interception et du fait que dans les services tiers, il peut y avoir une spécificité très soudaine du travail.
PS Merci cavin pour la photo et pndpnd pour la traduction de l'article en anglais.