Velocity est une conférence dédiée aux systèmes distribués. Il est organisé par la maison d'édition O'Reilly et a lieu trois fois par an: une fois en Californie, une fois à New York et une fois en Europe (et la ville change chaque année).
En 2018, la conférence s'est tenue à Londres du 30 octobre au 2 novembre. Le bureau principal de Badoo est situé là-bas, donc mes collègues et moi avions deux raisons d'aller à Velocity.
Son appareil s'est avéré être un peu plus compliqué que celui que j'ai rencontré lors de conférences russes. En plus des deux jours habituels de présentations, il y avait deux autres jours de formation, qui peuvent être suivis complètement, partiellement ou pas du tout. Ensemble, cela se transforme en une quête sérieuse pour choisir le type de billet dont vous avez besoin.
Dans cette revue, je vais parler de ces rapports et master classes dont je me souviens. J'attache des liens vers des documents supplémentaires à certains rapports. En partie, ce sont des documents auxquels les auteurs ont fait référence et en partie des documents pour une étude plus approfondie, que j'ai moi-même trouvés.
L'impression générale de la conférence: les auteurs se comportent très bien (et les séances d'ouverture sont un spectacle complet avec des conférenciers qui présentent et montent sur scène pour la musique), mais en même temps, je suis tombé sur quelques rapports qui étaient profonds d'un point de vue technique.
Le sujet le plus chaud de cette conférence est Kubernetes , qui est mentionné dans presque chaque deuxième rapport.
Le travail avec les réseaux sociaux est très bien construit: sur le compte twitter officiel de la conférence, il y avait beaucoup de retweets opérationnels avec des rapports. Cela a permis de voir rapidement ce qui se passait dans d'autres pièces.
Master classes
Le 31 octobre était le jour où il n'y avait aucun rapport, mais il y avait six ou huit master classes de trois heures de temps pur chacune, dont deux devaient être choisies.
PS Dans l'original, ils s'appellent tutoriel, mais il me semble correct de les traduire en "master class".
Bootcamp d'ingénierie du chaos
Présentatrice: Ana Medina , ingénieur à Gremlin | La description
L'atelier était consacré à l'introduction de l'ingénierie du chaos. Ana a parlé couramment de ce que c'est, de ses avantages, a démontré comment il peut être utilisé, quel logiciel peut aider et comment commencer à l'utiliser dans une entreprise.
En général, c'était une bonne introduction pour les débutants, mais je n'aimais pas vraiment la partie pratique, qui était le déploiement d'une application Web de démonstration dans un cluster de plusieurs machines utilisant Kubernetes et le contrôle de vissage de DataDog . Le problème principal était que nous avons passé près de la moitié du temps de la classe de maître à ce sujet et il était seulement nécessaire de jouer avec des scripts émulant divers problèmes dans le cluster pendant 5-10 minutes et d'examiner les changements dans les graphiques.
Il me semble que pour le même effet, il suffisait de donner accès à un DataDog préconfiguré et / ou de tout montrer de la scène, et ce temps devrait être consacré, par exemple, à une revue plus détaillée et à des exemples d'utilisation du même Chaos Monkey, dont on vient de parler littéralement quelques phrases.


Intéressant: lors de cette conférence, les intervenants ont souvent mentionné le terme "rayon de souffle", que je n'avais pas vu auparavant. Ils ont désigné la partie du système qui est affectée lorsqu'un problème spécifique se produit.
Matériaux supplémentaires:
Construire une infrastructure évolutive
Présentateur: Kief Morris , consultant en infrastructure et auteur d' Infrastructure as a code | La description
Les principaux points de la master class peuvent être réduits à deux choses:
- Les systèmes changent tout le temps, il est donc normal que l'infrastructure doive également changer;
- Une fois que l'infrastructure change, vous devez vous assurer qu'elle est simple et sûre, et cela ne peut être réalisé que par l'automatisation.
La partie principale de son histoire était consacrée spécifiquement à l'automatisation des changements d'infrastructure, aux solutions possibles à ce problème et aux tests de changements. Je ne suis pas un expert dans ce domaine, mais il me semblait qu'il parlait avec beaucoup de confiance et de détail (et très rapidement).
Le principal point dont je me souviens de cette master class est la recommandation de maximiser la distinction entre les environnements (production, staging, etc.) du code en variables d'environnement. Cela réduira la probabilité d'erreurs dans l'infrastructure lors de la modification de l'environnement et la rendra plus testable.



Rapports
Les 1er et 2 novembre étaient des jours de rapports. Ils étaient divisés en deux blocs principaux: une série de trois ou quatre courts rapports d'orientation qui se sont déroulés en un seul flux le matin (et pour eux, une grande salle réunie à partir de deux plus petits) et des rapports thématiques plus longs en cinq flux qui se sont déroulés le reste de la journée. . Pendant la journée, il y a eu plusieurs grandes pauses entre les reportages, quand il a été possible de se promener dans l'exposition avec les stands des partenaires de la conférence.
Evolution du backend Runtastic
Simon Lasselsberger (Runtastic GmbH) | Description et diapositives
L'un des rares rapports dans lesquels l'auteur n'a pas seulement dit comment faire quelque chose, mais a montré les détails d'un projet spécifique et ce qui lui est arrivé.
Au début, Runtastic avait une base de données Percona Server commune et un monolithe avec du code servant des applications mobiles et un site. Ensuite, ils ont commencé à écrire dans Cassandra (je ne me souviens pas pourquoi c'était dedans) la partie des données pour laquelle la valeur-clé du stockage était suffisante. Peu à peu, la base de données s'est gonflée et ils ont ajouté MongoDB, dans lequel ils ont commencé à écrire des données de la plupart des services. Au fil du temps, ils ont créé un niveau général qui répond aux demandes des applications Web et mobiles (quelque chose comme notre application , si je comprends bien).
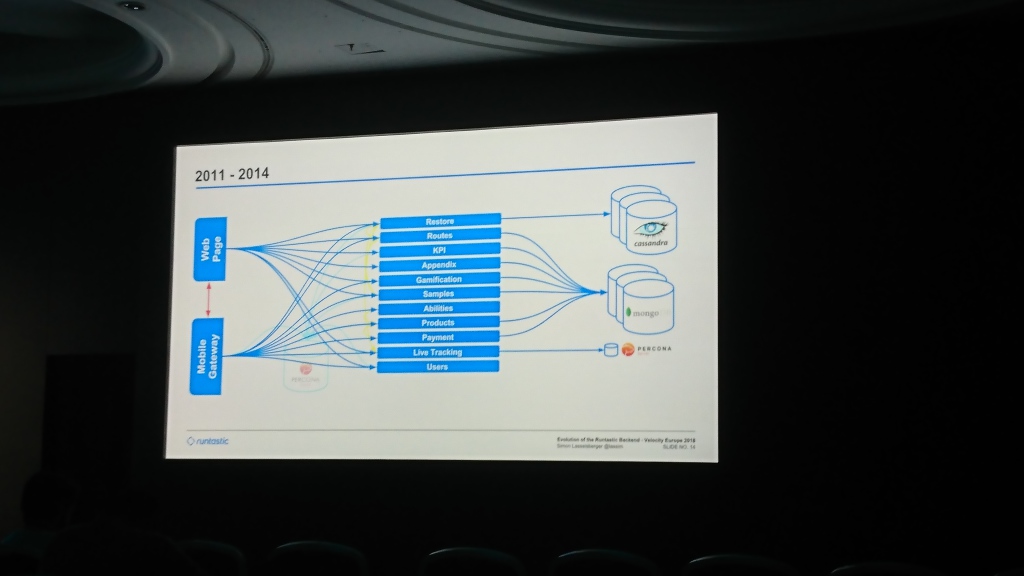
La majeure partie du rapport était consacrée au passage d'un centre de données à l'autre. Au début, ils ont gardé le serveur à Hetzner, qui après un certain temps a été considéré comme insuffisamment stable et les données ont migré vers T-Systems. Quelques années plus tard, ils ont fait face à un manque d'espace déjà là et ont déménagé à nouveau à Linz AG. La partie la plus intéressante ici est la migration des données. Ils ont commencé à copier des données qui ont duré plusieurs mois. Ils ne pouvaient pas attendre autant car ils manquaient d'espace, et ils ne pouvaient pas l'ajouter, ils ont donc fait un repli dans le code, qui a essayé de lire les données de l'ancien centre de données si ce n'était pas dans le nouveau.
À l'avenir, ils prévoient de diviser les données en plusieurs centres de données distincts (Simon a dit à plusieurs reprises que cela est nécessaire pour la Russie et la Chine) et de diviser de manière rigide les bases de données par des services séparés (maintenant un pool commun est utilisé pour tous les services).
Une approche intéressante de la conception de modules dans un système, dont Simon a parlé avec désinvolture: l' architecture hexagonale .
Permettre à une application d'être également pilotée par des utilisateurs, des programmes, des scripts de test ou de lot automatisés, et d'être développée et testée indépendamment de ses éventuels périphériques d'exécution et bases de données.
Alistair cockburn
Matériaux supplémentaires:
Surveillance des métriques personnalisées; ou, comment j'ai appris à instrumenter d'abord et à poser des questions plus tard
Maxime Petazzoni (SignalFx) | Description et présentation
L'histoire était consacrée à la collecte des mesures nécessaires pour comprendre l'application. Le message principal était que les mesures RED habituelles (taux, erreurs et durée) ne suffisent pas, et en plus d'elles, vous devez en collecter immédiatement d'autres qui aideront à comprendre ce qui se passe à l'intérieur de l'application.
Résumé, l'auteur a suggéré de collecter des compteurs et des temporisateurs pour certaines actions importantes dans le système (et nécessairement des compteurs d'échecs), de construire des graphiques et des histogrammes de distribution à partir d'eux, de déterminer un méta-modèle pour les métriques utilisateur (afin que différentes métriques aient le même ensemble de paramètres requis et les mêmes significations étaient appelées les mêmes partout).

Il est assez difficile de raconter les détails avec des mots, il sera plus facile de voir les détails et les exemples dans la présentation, dont un lien se trouve sur la page du rapport sur le site Web de la conférence.
Matériaux supplémentaires:
Comment le serverless change le département informatique
Paul Johnston (laboratoires ronds-points) | Description et présentation
L'auteur s'est présenté comme CTO et environnementaliste, a déclaré que le sans serveur n'est pas une solution technologique, mais une solution commerciale ("Vous ne payez rien s'il n'est pas utilisé"). Il a ensuite décrit les meilleures pratiques pour travailler avec un serveur sans serveur, quelles compétences sont nécessaires pour travailler avec lui et comment cela affecte la sélection de nouveaux employés et le travail avec les employés existants.

Le moment clé de «l'influence sur le service informatique» dont je me suis souvenu a été le passage des compétences nécessaires de la simple écriture de code à l'utilisation de l'infrastructure et de son automatisation («Plus» d'ingénierie »que de« développement »). Tout le reste était assez banal (il faut constamment effectuer révision de code, pour documenter les flux de données et les événements disponibles pour une utilisation dans le système, pour communiquer plus et apprendre rapidement), mais pour une raison quelconque, l'auteur les a attribués aux fonctionnalités sans serveur.

Dans l'ensemble, le rapport semblait un peu mitigé. Beaucoup des choses dont l'orateur a parlé peuvent être attribuées à tout système complexe qui ne rentre pas entièrement dans la tête.
Matériaux supplémentaires:
Pas de panique! Comment faire face maintenant que vous êtes responsable de la production
Euan Finlay (Financial Times) | Description et présentation
Un rapport sur la façon de gérer les incidents de production en cas de problème en ce moment. Les principaux points ont été divisés en parties par le temps.
Avant l'incident:
- différencier les alertes par criticité - certaines peuvent peut-être attendre, et vous n'avez pas besoin de les traiter d'urgence;
- Préparer un plan pour analyser les incidents à l'avance et maintenir la documentation à jour;
- effectuer des exercices - casser quelque chose et voir ce qui se passe (alias ingénierie du chaos);
- Établissez un endroit unique où toutes les informations sur les changements et les problèmes se rassemblent.
Pendant l'incident:
- il est normal que vous ne sachiez pas tout - attirez d'autres personnes si nécessaire;
- établir un lieu unique de communication entre les personnes travaillant sur la solution de l'incident;
- Recherchez la solution la plus simple qui remettra la production en état de fonctionnement et n'essayez pas de résoudre complètement le problème.
Après l'incident:
- comprendre pourquoi le problème est survenu et ce qu'il vous a appris;
- il est important de rédiger un rapport à ce sujet ("rapport d'incident");
- identifier ce qui peut être amélioré et planifier des actions spécifiques.
À la fin, Ewan a raconté une histoire amusante sur l'incident dans le Financial Times, qui est survenue parce que la base de production (appelée prod ) a été modifiée par erreur au lieu de la pré-production ( pprod ), et a conseillé d'éviter de tels noms similaires.
Apprendre de la toile de la vie (Keynote)
Claire Janisch (BiomimicrySA) | La description
J'étais en retard pour ce rapport, mais sur Twitter, ils en ont très bien parlé. Vous devez voir s'il apparaît.
Une vidéo avec un fragment du discours peut être visionnée sur le site Web de la conférence .
Jane Adams (deux investissements Sigma) | La description
Rapport philosophique sur le thème "pouvons-nous faire confiance aux algorithmes de prise de décision". La conclusion générale était que non: l'algorithme peut optimiser des métriques spécifiques, mais en même temps affecter sérieusement ce qui est difficile à mesurer ou se situe en dehors de ces métriques (par exemple, il y avait une discrimination dans l'algorithme pour l'embauche d'employés chez Amazon, qui a affecté négativement la culture dans l'entreprise et forcé d'abandonner cet algorithme).
La liberté de Kubernetes (Keynote)
Kris Nova | La description
De là, je me suis souvenu de deux pensées:
- la flexibilité n'est pas la liberté, mais le chaos;
- la complexité en soi n'est pas un problème si elle a une valeur quelconque (dans l'original, elle était appelée "complexité nécessaire"), ce qui dépasse le coût de cette complexité.
Le rapport était assez philosophique, donc, d’une part, je ne pouvais pas en tirer grand-chose, mais d’autre part, ce que j’ai retiré ne s’appliquait pas seulement à Kubernetes.

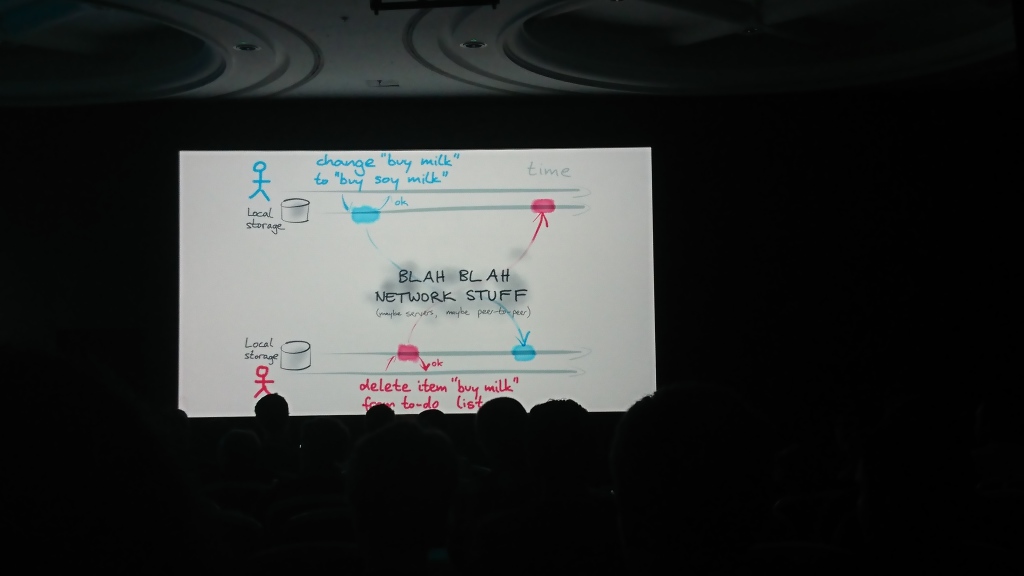
Qu'est-ce qui change lorsque nous nous déconnectons d'abord? (Keynote)
Martin Kleppmann (Université de Cambridge), auteur de Designing Data-Intensive Applications | La description
Le rapport se composait de deux parties logiques: dans la première, Martin a parlé du problème de la synchronisation des données entre elles, qui peuvent être modifiées indépendamment dans plusieurs sources, et dans la seconde, il a parlé des solutions et algorithmes possibles qui peuvent être utilisés pour cela ( transformation opérationnelle , OT et le type de données répliquées sans conflit , CRDT)) et a proposé sa solution - la bibliothèque de fusion automatique pour résoudre ces problèmes.


Matériaux supplémentaires:
Un guide du programmeur pour sécuriser les connexions
Conférencière: Liz Rice | Description et diapositives
Le rapport s'est déroulé sous la forme d'une session de codage en direct, et Liz y a montré comment fonctionne HTTPS, quelles erreurs peuvent se produire lorsque vous travaillez avec des connexions sécurisées et comment les résoudre. Il n'y avait pas de grandes profondeurs, mais la démonstration elle-même était très bonne.
Le plus utile: une diapositive avec les principales erreurs ( alias du rapport de Liz lors d'une autre conférence ):

Matériaux supplémentaires:
Tout ce que vous vouliez savoir sur les monorepos mais que vous aviez peur de demander
Simon Stewart (projet Selenium) | La description
La thèse principale du rapport est qu'en monorepo, il est beaucoup plus facile de gérer les dépendances dans le code, et cela couvre tous les avantages des référentiels individuels. Il a fait appel au fait que Google et Microsoft stockent les données dans un seul référentiel (respectivement 86 To et 300 Go) et que le référentiel Facebook (fichiers de 54 Go) utilise "off the shell mercurial".
La salle a "explosé" après la question "Qui a plus de référentiels dans l'entreprise que d'employés?"
L'argument "avec un grand référentiel pour travailler lentement" s'est cassé comme suit:
- vous n'avez pas besoin de transférer l'intégralité de l'historique des modifications sur la machine locale: utilisez le clonage instantané et la récupération clairsemée
- vous n'avez pas besoin d'utiliser tous les fichiers du référentiel: organisez la hiérarchie des fichiers et travaillez uniquement avec le répertoire nécessaire, et excluez tout le reste.
Matériaux supplémentaires:
Construire un système de traitement de flux distribué en temps réel
Amy Boyle (nouvelle relique) | Description et présentation
Une bonne histoire sur le travail avec les données en streaming d'un ingénieur de NewRelic (où ils ont clairement beaucoup d'expérience avec ces données). Amy a déclaré qu'elle travaillait avec des données en streaming, comment les agréger, ce qui pouvait être fait avec des données retardées, comment partager des flux d'événements et comment les rééquilibrer en cas de défaillance du processeur, ce qu'il fallait surveiller, etc.
Le rapport était beaucoup de matériel, je n'essaierai pas de le redire, mais je recommande simplement de voir la présentation elle-même (elle est déjà sur le site Web de la conférence).


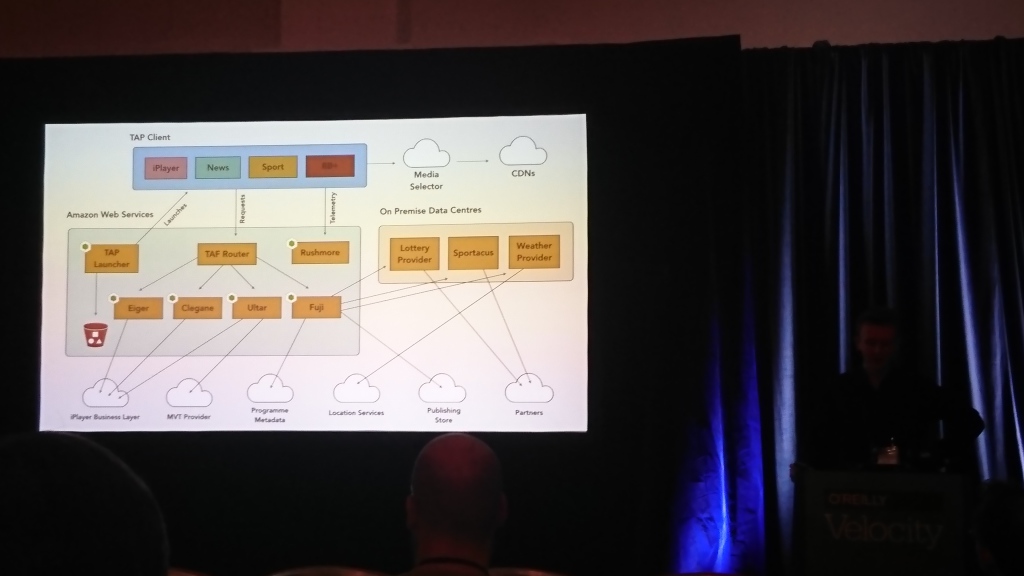
Architecte pour la télévision
David Buckhurst (BBC), Ross Wilson (BBC) | La description
La plupart des discussions portaient sur le frontend de la BBC. Les gars ont la télévision interactive et de nombreux téléviseurs et autres appareils (ordinateurs, téléphones, tablettes) sur lesquels cela devrait fonctionner. Vous devez travailler avec différents appareils de manière complètement différente, ils ont donc créé leur propre langage basé sur JSON pour décrire les interfaces et le traduire en ce qu'un appareil spécifique peut comprendre.
La principale conclusion pour moi est que par rapport aux téléspectateurs, les applications mobiles n'ont aucun problème avec les anciens clients.