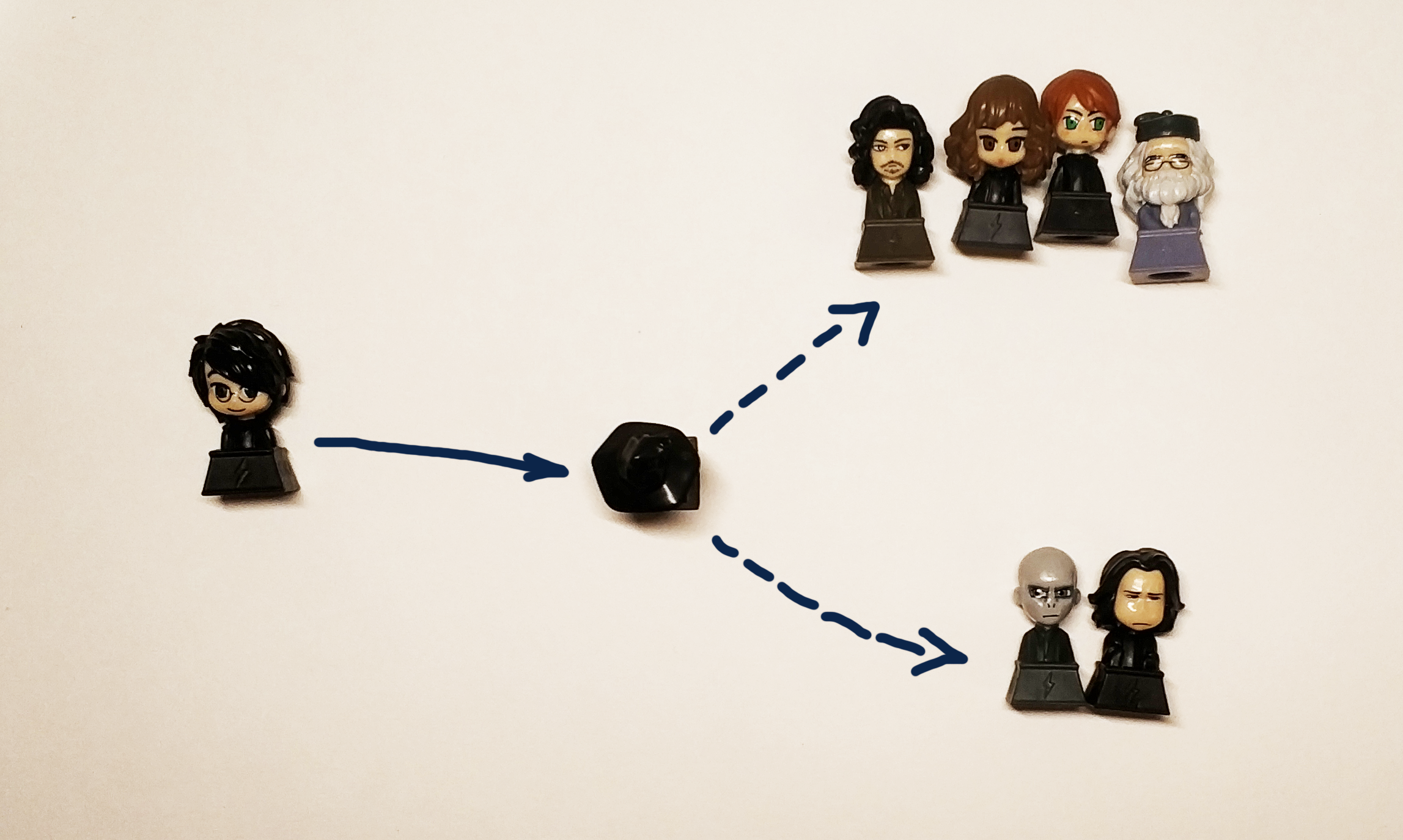
Il y a un mois, Lenta a lancé un concours dans lequel le même chapeau parlant d'Harry Potter identifie les participants qui ont accès au réseau social à l'une des quatre facultés. La concurrence n'est pas mauvaise, les noms qui sonnent différemment sont déterminés par différents départements, et les noms et prénoms anglais et russes similaires sont distribués de manière similaire. Je ne sais pas si la distribution dépend uniquement des noms et prénoms, et si le nombre d'amis ou d'autres facteurs est pris en compte d'une manière ou d'une autre, mais ce concours a suggéré l'idée de cet article: essayez de former un classificateur à partir de zéro, ce qui permettra aux utilisateurs d'être distribués dans différentes facultés.
Dans cet article, nous allons créer un modèle ML simple qui répartit les personnes dans les départements de Harry Potter en fonction de leur nom et prénom, après avoir traversé un petit processus de recherche suivant la méthodologie CRISP . À savoir, nous:
- Nous formulons le problème;
- Nous étudions les approches possibles de sa solution et formulons les besoins en données (méthodes et données de la solution);
- Nous collecterons les données nécessaires (méthodes de solution et données);
- Nous étudierons l'ensemble de données collectées (Recherche exploratoire);
- Extraire des fonctionnalités de données brutes (Feature Engineering);
- Enseignons un modèle d'apprentissage automatique (évaluation de modèle);
- Comparez les résultats obtenus, évaluez la qualité des solutions et, si nécessaire, répétez les paragraphes 2 à 6;
- Nous intégrons la solution dans un service utilisable (Production).

Cette tâche peut sembler triviale, nous imposerons donc une restriction supplémentaire sur l'ensemble du processus (pour qu'il prenne moins de 2 heures) et sur cet article (pour que son temps de lecture soit inférieur à 15 minutes).
Si vous êtes déjà plongé dans le monde magnifique et merveilleux de la science des données et que vous ne voyez pas Kagglite en permanence, ou (Dieu nous en préserve) comme pour mesurer la longueur de votre Hadup lors de réunions avec des collègues, alors l'article vous semblera probablement simple et sans intérêt. De plus: la qualité des modèles finaux n'est pas la valeur principale de cet article. Nous vous avons prévenu. Allons-y.
Un référentiel github avec le code utilisé dans l'article est également disponible pour les lecteurs curieux. En cas d'erreur, veuillez ouvrir PR.
Il est possible de résoudre un problème qui n'a pas de critères de décision clairs pendant une durée infiniment longue. Nous déciderons donc immédiatement que nous voulons obtenir une solution qui nous permettrait d'obtenir la réponse "Gryffondor", "Serdaigle", "Poufsouffle" ou "Serpentard" en réponse à la ligne saisie.
En fait, nous voulons obtenir une boîte noire:
" " => [?] => Griffindor
Le chapeau noir d'origine distribuait les jeunes sorciers aux départements en fonction de leur nature et de leurs qualités personnelles. Étant donné que les données sur le caractère et la personnalité selon les conditions de la tâche ne sont pas disponibles pour nous, nous utiliserons le nom et le prénom du participant, en se rappelant que dans ce cas, nous devons répartir les caractères du livre entre les départements qui correspondent à leurs départements natifs du livre. Et les potteromanes seraient certainement contrariés si notre décision distribuait Harry à Poufsouffle ou Serdaigle (mais cela devrait envoyer Harry à Gryffondor et Serpentard avec une probabilité égale de transmettre l'esprit du livre).
Puisque nous parlons de probabilités, nous formalisons le problème en termes mathématiques plus rigoureux. Du point de vue de la Data Science, nous résolvons le problème de classification, à savoir assigner à un objet (ligne, sous forme de nom et prénom) une certaine classe (en fait c'est juste une étiquette, ou étiquette, qui peut être un nombre ou 4 variables qui ont une valeur oui / non ) Nous comprenons qu'au moins dans le cas de Harry, il sera correct de donner 2 réponses: Gryffondor et Serpentard, il serait donc préférable de ne pas prédire la faculté spécifique que le chapeau définit, mais la probabilité qu'une personne soit affectée à cette faculté, donc notre décision sera prise en une sorte de fonction
Mesures et évaluation de la qualité
La tâche et le but sont formulés, Maintenant, nous allons penser comment le résoudre mais ce n’est pas tout. Pour démarrer l'étude, vous devez saisir des mesures de qualité. En d'autres termes, pour déterminer comment nous comparerons 2 solutions différentes l'une à l'autre.
Tout dans la vie est bon et simple - nous comprenons intuitivement qu'un détecteur de spam doit transmettre un minimum de spam aux messages entrants, ainsi que passer un maximum des lettres nécessaires et il ne doit certainement pas envoyer les lettres nécessaires au spam.
En réalité, tout est plus compliqué et la confirmation de cela est un grand nombre d' articles qui expliquent comment et quelles mesures sont utilisées. La pratique aide à mieux comprendre cela, mais c'est un sujet tellement volumineux que nous promettons d'écrire un article séparé à ce sujet et de créer une table ouverte afin que tout le monde puisse jouer et comprendre dans la pratique en quoi cela diffère.
Le ménage «mais choisissons le meilleur» pour nous sera ROC AUC . C'est exactement ce que nous voulons de la métrique dans ce cas: moins il y a de faux positifs et plus la prédiction réelle est précise, plus l'ASC ROC est élevée.
Pour un modèle ROC idéal, AUC est 1, pour un modèle aléatoire idéal qui définit les classes de manière absolument aléatoire - 0,5.
Des algorithmes
Notre boîte noire devrait prendre en compte la distribution des héros des livres, prendre un nom et un prénom différents en entrée et donner le résultat. Pour résoudre le problème de classification, vous pouvez utiliser différents algorithmes d'apprentissage automatique:
réseaux de neurones, machines de factorisation, régression linéaire ou, par exemple, SVM.
Contrairement à la croyance populaire, la Data Science ne se limite pas aux seuls réseaux de neurones, et pour vulgariser cette idée, dans cet article les réseaux de neurones sont laissés à l'exercice pour un lecteur curieux . Ceux qui n'ont pas suivi un seul cours d'analyse de données (en particulier le meilleur subjectivement de l'ODS), ou simplement lu n nouvelles sur l'apprentissage automatique ou l'IA, qui sont maintenant publiées même dans les magazines de pêcheurs amateurs, doivent avoir rencontré les noms de groupes généraux d'algorithmes : ensachage, boosting, méthode des vecteurs supports (SVM), régression linéaire. Ce sont eux que nous utiliserons pour résoudre notre problème.
Et pour être plus précis, on compare:
- Régression linéaire
- Boosting (XGboost, LightGBM)
- Décider des arbres (à proprement parler, c'est le même coup de pouce, mais nous le retirerons séparément: Extra Trees)
- Ensachage (forêt aléatoire)
- SVM
Nous pouvons résoudre le problème de la distribution de chaque étudiant de Poudlard à l'une des facultés en définissant la faculté qui lui correspond, mais à proprement parler, cette tâche revient à résoudre le problème de déterminer si chaque classe appartient individuellement. Par conséquent, dans le cadre de cet article, nous nous sommes fixé pour objectif d'obtenir 4 modèles, un pour chaque faculté.
Les données
Trouver le bon ensemble de données pour la formation, et plus important encore, légal pour l'utiliser à la bonne fin, est l'une des tâches les plus complexes et chronophages de la science des données. Pour notre tâche, nous prendrons les données de Wikia dans le monde de Harry Potter. Par exemple, sur ce lien vous pouvez trouver tous les personnages qui ont étudié à la faculté de Gryffondor. Il est important que dans ce cas, nous utilisons les données à des fins non commerciales, par conséquent, nous ne violons pas la licence de ce site.

Pour ceux qui pensent que les Data Scientists sont des gars si cool, je vais aller voir les Data Scientists et laissez-moi enseigner, nous vous rappelons qu'il y a une telle étape que le nettoyage et la préparation des données. Les données téléchargées doivent être modérées manuellement afin de supprimer, par exemple, "Le septième préfet de Gryffondor" et de supprimer "Fille inconnue de Gryffondor" semi-automatiquement. Dans le travail réel, une partie proportionnellement grande de la tâche est toujours associée à la préparation, au nettoyage et à la restauration des valeurs manquantes dans l'ensemble de données.
Un peu ctrl + c & ctrl + v et à la sortie, nous obtenons 4 fichiers texte, qui contiennent les noms des caractères en 2 langues: anglais et russe.
Nous étudions les données collectées (EDA, Exploratory Data Analysis)
Pour cette étape, nous avons 4 fichiers contenant les noms des étudiants des facultés, nous allons regarder plus en détail:
$ ls ../input griffindor.txt hufflpuff.txt ravenclaw.txt slitherin.txt
Chaque dossier contient 1 nom et prénom (le cas échéant) de l'élève par ligne:
$ wc -l ../input/*.txt 250 ../input/griffindor.txt 167 ../input/hufflpuff.txt 180 ../input/ravenclaw.txt 254 ../input/slitherin.txt 851 total
Les données collectées se présentent sous la forme:
$ cat ../input/griffindor.txt | head -3 && cat ../input/griffindor.txt | tail -3 Charlie Stainforth Melanie Stanmore Stewart
Notre idée est basée sur l'hypothèse qu'il y a quelque chose de similaire dans les noms et prénoms que notre boîte noire (ou chapeau noir) peut apprendre à distinguer.
L'algorithme peut alimenter les lignes telles quelles, mais le résultat ne sera pas bon, car les modèles de base ne pourront pas comprendre indépendamment en quoi «Draco» diffère de «Harry», nous devrons donc extraire des signes de nos noms et prénoms.
Préparation des données (ingénierie des fonctionnalités)
Les signes (ou caractéristiques, à partir de la propriété caractéristique anglaise ) sont les propriétés distinctives d'un objet. Le nombre de fois où une personne a changé d'emploi au cours de l'année écoulée, le nombre de doigts sur sa main gauche, la cylindrée du moteur, que le kilométrage de la voiture dépasse 100 000 km ou non. Toutes sortes de classifications de signes ont été inventées par un très grand nombre, il n'y a pas et ne peut pas y avoir de système unique à cet égard, nous allons donc donner des exemples de ce que peuvent être les signes:
- Numéro rationnel
- Catégorie (jusqu'à 12, 12-18 ou 18+)
- Valeur binaire (retourné le premier prêt ou non)
- Date, couleur, partages, etc.
La recherche (ou la formation) de fonctionnalités (en anglais Feature Engineering ) se démarque très souvent comme une étape distincte de la recherche ou le travail d'un spécialiste de l'analyse de données. En fait, le bon sens, l'expérience et les tests d'hypothèses contribuent au processus lui-même. Deviner les bons signes tout de suite est une question de combinaison d'une main pleine, de connaissances fondamentales et de chance. Parfois, il y a du chamanisme, mais l'approche générale est très simple: vous devez faire ce qui vous vient à l'esprit, puis vérifier s'il était possible d'améliorer la solution en ajoutant un nouvel attribut. Par exemple, comme signe de notre tâche, nous pouvons prendre le nombre de grésillement dans le nom.
Dans la première version (car la véritable étude Data Science - en tant que chef-d'œuvre, ne peut jamais être terminée) de notre modèle, nous utiliserons les fonctionnalités suivantes pour le nom et le prénom:
- 1 et la dernière lettre du mot - voyelle ou consonne
- Voyelles doubles et consonnes
- Nombre de voyelles, consonnes, sourdes, voisées
- Longueur du nom, longueur du nom de famille
- ...
Pour ce faire, nous prendrons ce référentiel comme base et ajouterons une classe afin qu'il puisse être utilisé pour les lettres latines. Cela nous donnera l'occasion de déterminer le son de chaque lettre.
>> from Phonetic import RussianLetter, EnglishLetter >> RussianLetter('').classify() {'consonant': True, 'deaf': False, 'hard': False, 'mark': False, 'paired': False, 'shock': False, 'soft': False, 'sonorus': True, 'vowel': False} >> EnglishLetter('d').classify() {'consonant': True, 'deaf': False, 'hard': True, 'mark': False, 'paired': False, 'shock': False, 'soft': False, 'sonorus': True, 'vowel': False}
Nous pouvons maintenant définir des fonctions simples pour calculer des statistiques, par exemple:
def starts_with_letter(word, letter_type='vowel'): """ , . :param word: :param letter_type: 'vowel' 'consonant'. . :return: Boolean """ if len(word) == 0: return False return Letter(word[0]).classify()[letter_type] def count_letter_type(word): """ . :param word: :param debug: :return: :obj:`dict` of :obj:`str` => :int:count """ count = { 'consonant': 0, 'deaf': 0, 'hard': 0, 'mark': 0, 'paired': 0, 'shock': 0, 'soft': 0, 'sonorus': 0, 'vowel': 0 } for letter in word: classes = Letter(letter).classify() for key in count.keys(): if classes[key]: count[key] += 1 return count
En utilisant ces fonctions, nous pouvons déjà obtenir les premiers signes:
from feature_engineering import * >> print(" («»): ", len("")) («»): 5 >> print(" («») : ", starts_with_letter('', 'vowel')) («») : False >> print(" («») : ", starts_with_letter('', 'consonant')) («») : True >> count_Harry = count_letter_type("") >> print (" («»): ", count_Harry['paired']) («»): 1
À strictement parler, à l'aide de ces fonctions, nous pouvons obtenir une représentation vectorielle de la chaîne, c'est-à-dire que nous obtenons le mappage:
Nous pouvons maintenant présenter nos données sous la forme d'un ensemble de données qui peut être entré dans l'algorithme d'apprentissage automatique:
>> from data_loaders import load_processed_data >> hogwarts_df = load_processed_data() >> hogwarts_df.head()

De plus, en conséquence, nous obtenons les symptômes suivants pour chaque élève:
>> hogwarts_df[hogwarts_df.columns].dtypes
Signes reçus name object surname object is_english bool name_starts_with_vowel bool name_starts_with_consonant bool name_ends_with_vowel bool name_ends_with_consonant bool name_length int64 name_vowels_count int64 name_double_vowels_count int64 name_consonant_count int64 name_double_consonant_count int64 name_paired_count int64 name_deaf_count int64 name_sonorus_count int64 surname_starts_with_vowel bool surname_starts_with_consonant bool surname_ends_with_vowel bool surname_ends_with_consonant bool surname_length int64 surname_vowels_count int64 surname_double_vowels_count int64 surname_consonant_count int64 surname_double_consonant_count int64 surname_paired_count int64 surname_deaf_count int64 surname_sonorus_count int64 is_griffindor int64 is_hufflpuff int64 is_ravenclaw int64 is_slitherin int64 dtype: object
Les 4 dernières colonnes sont ciblées - elles contiennent des informations sur la faculté dans laquelle un étudiant est inscrit.
Formation à l'algorithme
En un mot, les algorithmes sont formés comme les gens: ils font des erreurs et apprennent d'eux. Afin de comprendre combien ils ont commis une erreur, les algorithmes utilisent des fonctions d' erreur (fonctions de perte, fonction de perte en anglais ).
En règle générale, le processus d'apprentissage est très simple et comprend plusieurs étapes:
- Faites une prédiction.
- Évaluez l'erreur.
- Corrigez les paramètres du modèle.
- Répétez 1-3 jusqu'à ce que l'objectif soit atteint, que le processus s'arrête ou que les données se terminent.
Évaluez la qualité du modèle résultant.
Dans la pratique, bien sûr, tout est un peu plus compliqué. Par exemple, il y a le phénomène de sur- ajustement - l'algorithme peut littéralement se souvenir quelles caractéristiques correspondent à la réponse et ainsi aggraver le résultat pour des objets qui ne sont pas similaires à ceux sur lesquels il a été formé. Pour éviter cela, il existe différentes techniques et hacks.
Comme mentionné ci-dessus, nous allons résoudre 4 problèmes: un pour chaque faculté. Par conséquent, nous préparerons des données pour Serpentard:
Tout en apprenant, l'algorithme compare constamment ses résultats avec des données réelles, car cette partie de l'ensemble de données est allouée pour validation. La règle du bon ton est également considérée pour évaluer le résultat de l'algorithme sur des données individuelles que l'algorithme n'a pas du tout vu. Par conséquent, maintenant nous divisons l'échantillon dans la proportion de 70/30 et formons le premier algorithme:
from sklearn.cross_validation import train_test_split from sklearn.ensemble import RandomForestClassifier
C'est fait. Maintenant, si vous soumettez des données à l'entrée de ce modèle, cela produira un résultat. C'est amusant, donc nous allons d'abord vérifier si le modèle dans Harry reconnaît le Serpentard. Pour ce faire, préparez d'abord les fonctions afin d'obtenir la prédiction de l'algorithme:
Afficher le code from data_loaders import parse_line_to_hogwarts_df import pandas as pd def get_single_student_features (name): """ :param name: string :return: pd.DataFrame """ featurized_person_df = parse_line_to_hogwarts_df(name) person_df = pd.DataFrame(featurized_person_df, columns=[ 'name', 'surname', 'is_english', 'name_starts_with_vowel', 'name_starts_with_consonant', 'name_ends_with_vowel', 'name_ends_with_consonant', 'name_length', 'name_vowels_count', 'name_double_vowels_count', 'name_consonant_count', 'name_double_consonant_count', 'name_paired_count', 'name_deaf_count', 'name_sonorus_count', 'surname_starts_with_vowel', 'surname_starts_with_consonant', 'surname_ends_with_vowel', 'surname_ends_with_consonant', 'surname_length', 'surname_vowels_count', 'surname_double_vowels_count', 'surname_consonant_count', 'surname_double_consonant_count', 'surname_paired_count', 'surname_deaf_count', 'surname_sonorus_count', ], index=[0] ) featurized_person = person_df.drop( ['name', 'surname'], axis = 1 ) return featurized_person def get_predictions_vector (model, person): """ :param model: :param person: string :return: list """ encoded_person = get_single_student_features(person) return model.predict_proba(encoded_person)[0]
Définissons maintenant un petit ensemble de données de test pour prendre en compte les résultats de l'algorithme.
def score_testing_dataset (model): """ . :param model: """ testing_dataset = [ " ", "Kirill Malev", " ", "Harry Potter", " ", " ","Severus Snape", " ", "Tom Riddle", " ", "Salazar Slytherin"] for name in testing_dataset: print ("{} — {}".format(name, get_predictions_vector(model, name)[1])) score_testing_dataset(rfc_model)
— 0.5 Kirill Malev — 0.5 — 0.0 Harry Potter — 0.0 — 0.75 — 0.9 Severus Snape — 0.5 — 0.2 Tom Riddle — 0.5 — 0.2 Salazar Slytherin — 0.3
Les résultats étaient douteux. Même le fondateur de la faculté ne serait pas dans sa faculté, selon ce modèle. Par conséquent, vous devez évaluer une qualité stricte: regardez les métriques que nous avons demandées au début:
from sklearn.metrics import accuracy_score, roc_auc_score, classification_report predictions = rfc_model.predict(X_test) print("Classification report: ") print(classification_report(y_test, predictions)) print("Accuracy for Random Forest Model: %.2f" % (accuracy_score(y_test, predictions) * 100)) print("ROC AUC from first Random Forest Model: %.2f" % (roc_auc_score(y_test, predictions)))
Classification report: precision recall f1-score support 0 0.66 0.88 0.75 168 1 0.38 0.15 0.21 89 avg / total 0.56 0.62 0.56 257 Accuracy for Random Forest Model: 62.26 ROC AUC from first Random Forest Model: 0.51
Il n'est pas surprenant que les résultats soient si douteux - l'ASC ROC d'environ 0,51 suggère que le modèle prédit légèrement mieux qu'un tirage au sort.
Test des résultats. Mesures de qualité
En utilisant un exemple ci-dessus, nous avons examiné comment 1 algorithme est formé qui prend en charge les interfaces sklearn. Les autres sont formés exactement de la même manière, nous ne pouvons donc former que tous les algorithmes et choisir le meilleur dans chaque cas.

Ce n'est pas compliqué, pour chaque algorithme, nous formons 1 avec des paramètres standard, et nous formons également un ensemble complet, triant diverses options qui affectent la qualité de l'algorithme. Cette étape est appelée Model Tuning ou Hyperparameter Optimization et son essence est très simple: l'ensemble de paramètres qui donne le meilleur résultat est sélectionné.
from model_training import train_classifiers from data_loaders import load_processed_data import warnings warnings.filterwarnings('ignore')
— 0.09437856871661066 Kirill Malev — 0.20820536334902712 — 0.07550095601699099 Harry Potter — 0.07683794773639624 — 0.9414529336862744 — 0.9293671807790949 Severus Snape — 0.6576783576162999 — 0.18577792617672767 Tom Riddle — 0.8351835484058869 — 0.25930925139546795 Salazar Slytherin — 0.24008788903854789
Les chiffres de cette version sont subjectivement meilleurs que par le passé, mais toujours pas assez bons pour un perfectionniste interne. Par conséquent, nous descendrons un niveau plus profond et reviendrons au sens du produit de notre tâche: nous devons prédire la faculté la plus probable, à laquelle le héros sera déterminé par le chapeau de distribution. Cela signifie que vous devez former des modèles pour chacune des facultés.

>> from model_training import train_all_models
Longue conclusion des résultats et résultats de la régression multinomiale SVM Default Report Accuracy for SVM Default: 73.93 ROC AUC for SVM Default: 0.53 Tuned SVM Report Accuracy for Tuned SVM: 72.37 ROC AUC for Tuned SVM: 0.50 KNN Default Report Accuracy for KNN Default: 70.04 ROC AUC for KNN Default: 0.58 Tuned KNN Report Accuracy for Tuned KNN: 69.65 ROC AUC for Tuned KNN: 0.58 XGBoost Default Report Accuracy for XGBoost Default: 70.43 ROC AUC for XGBoost Default: 0.54 Tuned XGBoost Report Accuracy for Tuned XGBoost: 68.09 ROC AUC for Tuned XGBoost: 0.56 Random Forest Default Report Accuracy for Random Forest Default: 73.93 ROC AUC for Random Forest Default: 0.62 Tuned Random Forest Report Accuracy for Tuned Random Forest: 74.32 ROC AUC for Tuned Random Forest: 0.54 Extra Trees Default Report Accuracy for Extra Trees Default: 69.26 ROC AUC for Extra Trees Default: 0.57 Tuned Extra Trees Report Accuracy for Tuned Extra Trees: 73.54 ROC AUC for Tuned Extra Trees: 0.55 LGBM Default Report Accuracy for LGBM Default: 70.82 ROC AUC for LGBM Default: 0.62 Tuned LGBM Report Accuracy for Tuned LGBM: 74.71 ROC AUC for Tuned LGBM: 0.53 RGF Default Report Accuracy for RGF Default: 70.43 ROC AUC for RGF Default: 0.58 Tuned RGF Report Accuracy for Tuned RGF: 71.60 ROC AUC for Tuned RGF: 0.60 FRGF Default Report Accuracy for FRGF Default: 68.87 ROC AUC for FRGF Default: 0.59 Tuned FRGF Report Accuracy for Tuned FRGF: 69.26 ROC AUC for Tuned FRGF: 0.59 SVM Default Report Accuracy for SVM Default: 70.43 ROC AUC for SVM Default: 0.50 Tuned SVM Report Accuracy for Tuned SVM: 71.60 ROC AUC for Tuned SVM: 0.50 KNN Default Report Accuracy for KNN Default: 63.04 ROC AUC for KNN Default: 0.49 Tuned KNN Report Accuracy for Tuned KNN: 65.76 ROC AUC for Tuned KNN: 0.50 XGBoost Default Report Accuracy for XGBoost Default: 69.65 ROC AUC for XGBoost Default: 0.54 Tuned XGBoost Report Accuracy for Tuned XGBoost: 68.09 ROC AUC for Tuned XGBoost: 0.50 Random Forest Default Report Accuracy for Random Forest Default: 66.15 ROC AUC for Random Forest Default: 0.51 Tuned Random Forest Report Accuracy for Tuned Random Forest: 70.43 ROC AUC for Tuned Random Forest: 0.50 Extra Trees Default Report Accuracy for Extra Trees Default: 64.20 ROC AUC for Extra Trees Default: 0.49 Tuned Extra Trees Report Accuracy for Tuned Extra Trees: 70.82 ROC AUC for Tuned Extra Trees: 0.51 LGBM Default Report Accuracy for LGBM Default: 67.70 ROC AUC for LGBM Default: 0.56 Tuned LGBM Report Accuracy for Tuned LGBM: 70.82 ROC AUC for Tuned LGBM: 0.50 RGF Default Report Accuracy for RGF Default: 66.54 ROC AUC for RGF Default: 0.52 Tuned RGF Report Accuracy for Tuned RGF: 65.76 ROC AUC for Tuned RGF: 0.53 FRGF Default Report Accuracy for FRGF Default: 65.76 ROC AUC for FRGF Default: 0.53 Tuned FRGF Report Accuracy for Tuned FRGF: 69.65 ROC AUC for Tuned FRGF: 0.52 SVM Default Report Accuracy for SVM Default: 74.32 ROC AUC for SVM Default: 0.50 Tuned SVM Report Accuracy for Tuned SVM: 74.71 ROC AUC for Tuned SVM: 0.51 KNN Default Report Accuracy for KNN Default: 69.26 ROC AUC for KNN Default: 0.48 Tuned KNN Report Accuracy for Tuned KNN: 73.15 ROC AUC for Tuned KNN: 0.49 XGBoost Default Report Accuracy for XGBoost Default: 72.76 ROC AUC for XGBoost Default: 0.49 Tuned XGBoost Report Accuracy for Tuned XGBoost: 74.32 ROC AUC for Tuned XGBoost: 0.50 Random Forest Default Report Accuracy for Random Forest Default: 73.93 ROC AUC for Random Forest Default: 0.52 Tuned Random Forest Report Accuracy for Tuned Random Forest: 74.32 ROC AUC for Tuned Random Forest: 0.50 Extra Trees Default Report Accuracy for Extra Trees Default: 73.93 ROC AUC for Extra Trees Default: 0.52 Tuned Extra Trees Report Accuracy for Tuned Extra Trees: 73.93 ROC AUC for Tuned Extra Trees: 0.50 LGBM Default Report Accuracy for LGBM Default: 73.54 ROC AUC for LGBM Default: 0.52 Tuned LGBM Report Accuracy for Tuned LGBM: 74.32 ROC AUC for Tuned LGBM: 0.50 RGF Default Report Accuracy for RGF Default: 73.54 ROC AUC for RGF Default: 0.51 Tuned RGF Report Accuracy for Tuned RGF: 73.93 ROC AUC for Tuned RGF: 0.50 FRGF Default Report Accuracy for FRGF Default: 73.93 ROC AUC for FRGF Default: 0.53 Tuned FRGF Report Accuracy for Tuned FRGF: 73.93 ROC AUC for Tuned FRGF: 0.50 SVM Default Report Accuracy for SVM Default: 80.54 ROC AUC for SVM Default: 0.50 Tuned SVM Report Accuracy for Tuned SVM: 80.93 ROC AUC for Tuned SVM: 0.52 KNN Default Report Accuracy for KNN Default: 78.60 ROC AUC for KNN Default: 0.50 Tuned KNN Report Accuracy for Tuned KNN: 80.16 ROC AUC for Tuned KNN: 0.51 XGBoost Default Report Accuracy for XGBoost Default: 80.54 ROC AUC for XGBoost Default: 0.50 Tuned XGBoost Report Accuracy for Tuned XGBoost: 77.04 ROC AUC for Tuned XGBoost: 0.52 Random Forest Default Report Accuracy for Random Forest Default: 77.43 ROC AUC for Random Forest Default: 0.49 Tuned Random Forest Report Accuracy for Tuned Random Forest: 80.54 ROC AUC for Tuned Random Forest: 0.50 Extra Trees Default Report Accuracy for Extra Trees Default: 76.26 ROC AUC for Extra Trees Default: 0.48 Tuned Extra Trees Report Accuracy for Tuned Extra Trees: 78.60 ROC AUC for Tuned Extra Trees: 0.50 LGBM Default Report Accuracy for LGBM Default: 75.49 ROC AUC for LGBM Default: 0.51 Tuned LGBM Report Accuracy for Tuned LGBM: 80.54 ROC AUC for Tuned LGBM: 0.50 RGF Default Report Accuracy for RGF Default: 78.99 ROC AUC for RGF Default: 0.52 Tuned RGF Report Accuracy for Tuned RGF: 75.88 ROC AUC for Tuned RGF: 0.55 FRGF Default Report Accuracy for FRGF Default: 76.65 ROC AUC for FRGF Default: 0.50 # ,
from sklearn.linear_model import LogisticRegression clf = LogisticRegression(random_state=0, solver='lbfgs', multi_class='multinomial') hogwarts_df = load_processed_data_multi()
— [0.3602361 0.16166944 0.16771712 0.31037733] Kirill Malev — [0.47473072 0.16051924 0.13511385 0.22963619] — [0.38697926 0.19330242 0.17451052 0.2452078 ] Harry Potter — [0.40245098 0.16410043 0.16023278 0.27321581] — [0.13197025 0.16438855 0.17739254 0.52624866] — [0.17170203 0.1205678 0.14341742 0.56431275] Severus Snape — [0.15558044 0.21589378 0.17370406 0.45482172] — [0.39301231 0.07397324 0.1212741 0.41174035] Tom Riddle — [0.26623969 0.14194379 0.1728505 0.41896601] — [0.24843037 0.21632736 0.21532696 0.3199153 ] Salazar Slytherin — [0.09359144 0.26735897 0.2742305 0.36481909]
Et confusion_matrix:
confusion_matrix(clf.predict(X_data), y)
array([[144, 68, 64, 78], [ 8, 9, 8, 6], [ 22, 18, 31, 20], [ 77, 73, 78, 151]])
def get_predctions_vector (models, person): predictions = [get_predictions_vector (model, person)[1] for model in models] return { 'slitherin': predictions[0], 'griffindor': predictions[1], 'ravenclaw': predictions[2], 'hufflpuff': predictions[3] } def score_testing_dataset (models): testing_dataset = [ " ", "Kirill Malev", " ", "Harry Potter", " ", " ","Severus Snape", " ", "Tom Riddle", " ", "Salazar Slytherin"] data = [] for name in testing_dataset: predictions = get_predctions_vector(models, name) predictions['name'] = name data.append(predictions) scoring_df = pd.DataFrame(data, columns=['name', 'slitherin', 'griffindor', 'hufflpuff', 'ravenclaw']) return scoring_df
name slitherin griffindor hufflpuff ravenclaw 0 0.349084 0.266909 0.110311 0.091045 1 Kirill Malev 0.289914 0.376122 0.384986 0.103056 2 0.338258 0.400841 0.016668 0.124825 3 Harry Potter 0.245377 0.357934 0.026287 0.154592 4 0.917423 0.126997 0.176640 0.096570 5 0.969693 0.106384 0.150146 0.082195 6 Severus Snape 0.663732 0.259189 0.290252 0.074148 7 0.268466 0.579401 0.007900 0.083195 8 Tom Riddle 0.639731 0.541184 0.084395 0.156245 9 0.653595 0.147506 0.172940 0.137134 10 Salazar Slytherin 0.647399 0.169964 0.095450 0.26126

,
, , , , XGBoost CV , .
Important! , 70% . , 4 .
from model_training import train_production_models from xgboost import XGBClassifier best_models = [] for i in range (0,4): best_models.append(XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1, colsample_bytree=0.7, gamma=0, learning_rate=0.05, max_delta_step=0, max_depth=6, min_child_weight=11, missing=-999, n_estimators=1000, n_jobs=1, nthread=4, objective='binary:logistic', random_state=0, reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=1337, silent=1, subsample=0.8)) slitherin_model, griffindor_model, ravenclaw_model, hufflpuff_model = \ train_production_models(best_models) top_models = slitherin_model, griffindor_model, ravenclaw_model, hufflpuff_model score_testing_dataset(top_models)
name slitherin griffindor hufflpuff ravenclaw 0 0.273713 0.372337 0.065923 0.279577 1 Kirill Malev 0.401603 0.761467 0.111068 0.023902 2 0.031540 0.616535 0.196342 0.217829 3 Harry Potter 0.183760 0.422733 0.119393 0.173184 4 0.945895 0.021788 0.209820 0.019449 5 0.950932 0.088979 0.084131 0.012575 6 Severus Snape 0.634035 0.088230 0.249871 0.036682 7 0.426440 0.431351 0.028444 0.083636 8 Tom Riddle 0.816804 0.136530 0.069564 0.035500 9 0.409634 0.213925 0.028631 0.252723 10 Salazar Slytherin 0.824590 0.067910 0.111147 0.085710
, , .
, , . .
import pickle pickle.dump(slitherin_model, open("../output/slitherin.xgbm", "wb")) pickle.dump(griffindor_model, open("../output/griffindor.xgbm", "wb")) pickle.dump(ravenclaw_model, open("../output/ravenclaw.xgbm", "wb")) pickle.dump(hufflpuff_model, open("../output/hufflpuff.xgbm", "wb"))
, . , , , .
, , . , . , Data Scientist — -.
:
, docker-, python-. , flask.
from __future__ import print_function
Dockerfile:
FROM datmo/python-base:cpu-py35
:
docker build -t talking_hat . && docker rm talking_hat && docker run --name talking_hat -p 5000:5000 talking_hat
— . , Apache Benchmark . , . — .
$ ab -p data.json -T application/json -c 50 -n 10000 http://0.0.0.0:5000/predict
ab This is ApacheBench, Version 2.3 <$Revision: 1807734 $> Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Licensed to The Apache Software Foundation, http://www.apache.org/ Benchmarking 0.0.0.0 (be patient) Completed 1000 requests Completed 2000 requests Completed 3000 requests Completed 4000 requests Completed 5000 requests Completed 6000 requests Completed 7000 requests Completed 8000 requests Completed 9000 requests Completed 10000 requests Finished 10000 requests Server Software: Werkzeug/0.14.1 Server Hostname: 0.0.0.0 Server Port: 5000 Document Path: /predict Document Length: 141 bytes Concurrency Level: 50 Time taken for tests: 238.552 seconds Complete requests: 10000 Failed requests: 0 Total transferred: 2880000 bytes Total body sent: 1800000 HTML transferred: 1410000 bytes Requests per second: 41.92 [#/sec] (mean) Time per request: 1192.758 [ms] (mean) Time per request: 23.855 [ms] (mean, across all concurrent requests) Transfer rate: 11.79 [Kbytes/sec] received 7.37 kb/s sent 19.16 kb/s total Connection Times (ms) min mean[+/-sd] median max Connect: 0 0 0.1 0 3 Processing: 199 1191 352.5 1128 3352 Waiting: 198 1190 352.5 1127 3351 Total: 202 1191 352.5 1128 3352 Percentage of the requests served within a certain time (ms) 50% 1128 66% 1277 75% 1378 80% 1451 90% 1668 95% 1860 98% 2096 99% 2260 100% 3352 (longest request)
, :
def prod_predict_classes_for_name (full_name): <...> predictions = get_predctions_vector([ app.slitherin_model, app.griffindor_model, app.ravenclaw_model, app.hufflpuff_model ], person_df.drop(['name', 'surname'], axis=1)) return { 'slitherin': float(predictions[0][1]), 'griffindor': float(predictions[1][1]), 'ravenclaw': float(predictions[2][1]), 'hufflpuff': float(predictions[3][1]) } def create_app(): <...> with app.app_context(): app.slitherin_model = pickle.load(open("models/slitherin.xgbm", "rb")) app.griffindor_model = pickle.load(open("models/griffindor.xgbm", "rb")) app.ravenclaw_model = pickle.load(open("models/ravenclaw.xgbm", "rb")) app.hufflpuff_model = pickle.load(open("models/hufflpuff.xgbm", "rb")) return app
:
$ docker build -t talking_hat . && docker rm talking_hat && docker run --name talking_hat -p 5000:5000 talking_hat $ ab -p data.json -T application/json -c 50 -n 10000 http://0.0.0.0:5000/predict
ab This is ApacheBench, Version 2.3 <$Revision: 1807734 $> Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Licensed to The Apache Software Foundation, http://www.apache.org/ Benchmarking 0.0.0.0 (be patient) Completed 1000 requests Completed 2000 requests Completed 3000 requests Completed 4000 requests Completed 5000 requests Completed 6000 requests Completed 7000 requests Completed 8000 requests Completed 9000 requests Completed 10000 requests Finished 10000 requests Server Software: Werkzeug/0.14.1 Server Hostname: 0.0.0.0 Server Port: 5000 Document Path: /predict Document Length: 141 bytes Concurrency Level: 50 Time taken for tests: 219.812 seconds Complete requests: 10000 Failed requests: 3 (Connect: 0, Receive: 0, Length: 3, Exceptions: 0) Total transferred: 2879997 bytes Total body sent: 1800000 HTML transferred: 1409997 bytes Requests per second: 45.49 [#/sec] (mean) Time per request: 1099.062 [ms] (mean) Time per request: 21.981 [ms] (mean, across all concurrent requests) Transfer rate: 12.79 [Kbytes/sec] received 8.00 kb/s sent 20.79 kb/s total Connection Times (ms) min mean[+/-sd] median max Connect: 0 0 0.1 0 2 Processing: 235 1098 335.2 1035 3464 Waiting: 235 1097 335.2 1034 3462 Total: 238 1098 335.2 1035 3464 Percentage of the requests served within a certain time (ms) 50% 1035 66% 1176 75% 1278 80% 1349 90% 1541 95% 1736 98% 1967 99% 2141 100% 3464 (longest request)
. . , .
Conclusion
, . - .
, :
- feature engineering- ( ), , Soundex .
- PyTorch . , , .
- flask Quart , , .
- - -, .
, , . , !
Cet article n'aurait pas été publié sans la communauté Open Data Science, qui rassemble un grand nombre d'experts russophones dans le domaine de l'analyse des données.