J'ai lu un livre faisant autorité sur les stratégies de trading et j'ai écrit mon robot de trading. À ma grande surprise, le robot n'apporte pas des millions, même des échanges virtuels. La raison en est évidente: un robot, comme une voiture de course, doit être «réglé», pour sélectionner des paramètres adaptés à un marché spécifique, une période de temps spécifique.
Étant donné que le robot a suffisamment de paramètres, itère sur toutes leurs combinaisons possibles à la recherche de la meilleure tâche, trop longue. À un moment donné, résolvant le problème d'optimisation, je n'ai pas trouvé un choix raisonnable de l'algorithme de recherche pour le vecteur quasi-optimal des paramètres du robot de trading. J'ai donc décidé de comparer indépendamment plusieurs algorithmes ...
Bref énoncé du problème d'optimisation
Nous avons un algorithme de trading. Données d'entrée - historique des prix de l'intervalle horaire pour 1 an d'observation. Données de sortie - P - profit ou perte, valeur scalaire.
L'algorithme de trading a 4 paramètres configurables:
- Mf est la période de la moyenne mobile "rapide",
- Période de la moyenne mobile «lente»
- T - TakeProfit, le niveau de profit cible pour chaque transaction individuelle,
- S - StopLoss, le niveau de perte cible pour chaque transaction individuelle.
Nous attribuons une plage et une étape de changement fixe à chacun des paramètres, un total de
20 valeurs pour chacun des paramètres.
Ainsi, nous pouvons rechercher le profit maximum (P) pour un paramètre sur un tableau de données d'entrée:
- faire varier un paramètre, par exemple P = f (Ms), produisant jusqu'à 20 backtests ,
- faire varier deux paramètres, par exemple P = f (Ms, T), produisant jusqu'à 20 * 20 = 400 backtests,
- faire varier trois paramètres, par exemple P = f (Mf, Ms, T), produisant jusqu'à 20 * 20 * 20 = 8 000 backtests,
- faisant varier chacun des paramètres, P = f (Mf, Ms, T, S) et produisant jusqu'à 20 ^ 4 = 160 000 backtests.
Pour la plupart des algorithmes de trading, cependant, il faut plusieurs ordres de grandeur de plus pour effectuer un seul test. Ce qui nous amène à la tâche de trouver un vecteur de paramètres quasi-optimal sans avoir à itérer sur l'ensemble des combinaisons possibles.
détails sur le commerce et les robots commerciauxNégociation en bourse, paris au Forex trading center, paris fous sur les «options binaires», spéculation sur les crypto-monnaies - une sorte de «diagnostic», avec plusieurs options possibles pour le développement de la «maladie». Un scénario très courant est lorsqu'un joueur, après avoir joué à «l'intuition», arrive au trading automatique. Ne vous méprenez pas, je ne veux pas mettre l’accent de telle manière que les robots de trading rigoureux «technologiquement et mathématiquement» sont opposés au trading «manuel» naïf et impuissant. Par exemple, je suis moi-même convaincu que toutes mes tentatives pour tirer profit d'un marché efficace (lu sur n'importe quel marché transparent et liquide) par la spéculation, qu'elle soit discrétionnaire ou entièrement automatisée, sont a priori vouées à l'échec. Si, peut-être, pour ne pas permettre le facteur de chance aléatoire.
Cependant, le commerce, et en particulier le commerce algo (rythmique), est un passe-temps populaire pour beaucoup. Certains programment indépendamment des robots de trading, d'autres vont encore plus loin et créent leurs propres plateformes d'écriture, de débogage et de backtesting des stratégies de trading, tandis que d'autres téléchargent / achètent un «expert» électronique prêt à l'emploi. Mais même ceux qui n’écrivent pas eux-mêmes des algorithmes de trading devraient avoir une idée de la manière de gérer cette «boîte noire» afin d’en tirer profit conformément à l’idée de l’auteur. Afin de ne pas être infondé, je donne mes observations supplémentaires en utilisant un exemple d'une stratégie de trading simple:
Robot de trading simple
Un robot de trading analyse la dynamique de la valeur de l'or, en dollars par once troy, et décide «d'acheter» ou de «vendre» une certaine quantité d'or. Pour simplifier, nous supposons que le robot échange toujours une once troy.
Par exemple, au moment de l'achat, le coût d'une once d'or troy était de 1075,00
USD . Au moment de la vente ultérieure (clôture de la transaction), le prix a augmenté à 1079,00 USD. Le bénéfice de cette transaction s'est élevé à 4 USD.
Si le robot «vend» de l'or à 1075,00 USD, puis termine (clôture) la transaction en «rachetant» de l'or au prix de 1079 USD, le bénéfice de la transaction sera négatif - moins 4 USD. En fait, peu importe pour nous comment le robot vend de l'or, ce qu'il n'a pas, afin de le «racheter» plus tard. Un courtier / centre de négociation permet à un trader «d'acheter» et de «vendre» un actif d'une manière ou d'une autre, gagnant (ou, plus souvent, perdant), sur la différence de taux.
Nous avons décidé
des données d'entrée pour le robot - il s'agit en fait de la série chronologique des prix (cotations) de l'or. Si vous dites que mon exemple est trop simple, pas vital - je peux vous l'assurer: la plupart des robots qui circulent sur le marché (et aussi les commerçants) dans leurs échanges ne sont guidés que par les statistiques de prix des biens qu'ils échangent. Dans tous les cas, dans le problème de l'optimisation paramétrique d'une stratégie de trading, il n'y a pas de différence fondamentale entre un robot qui négocie sur la base du vecteur de prix et un robot accédant à un tableau de téraoctets d'analyses de marché multi-triées. L'essentiel est que ces deux robots puissent (devraient pouvoir) être testés sur des données historiques. Les algorithmes doivent être déterminés: c'est-à-dire, sur les mêmes données d'entrée (heure du modèle, si nécessaire, nous pouvons également les prendre comme paramètre), le robot de trading devrait afficher le même résultat.
Plus de détails sur le robot de trading peuvent être trouvés dans le spoiler suivant:
algorithme de trading de robots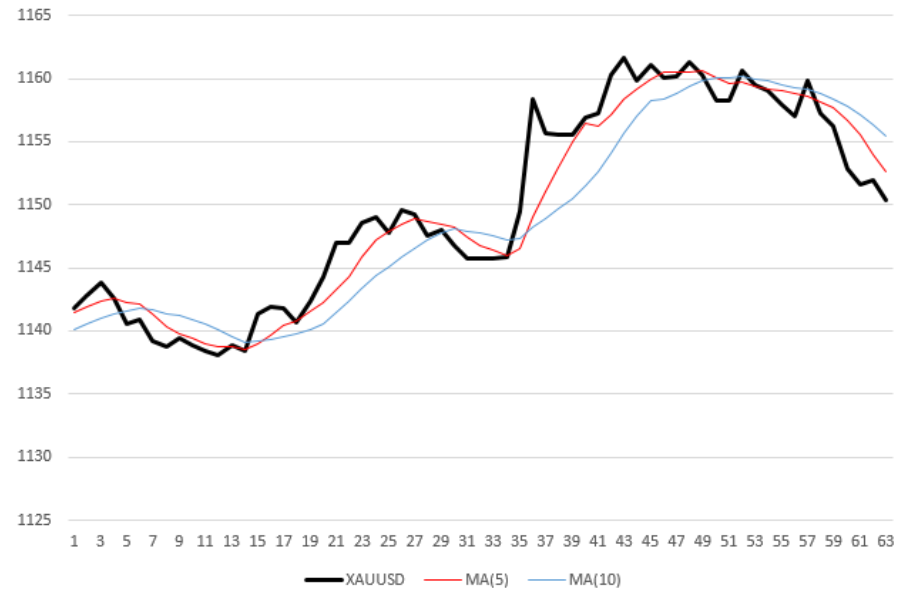
La courbe noire (épaisse) sur le graphique est la mesure horaire
du prix
XAUUSD . Deux fines lignes brisées, rouge et bleu - valeurs moyennes des prix avec des périodes moyennes de 5 et 10, respectivement. En d'autres termes, moyenne mobile (MA) avec des périodes de 5, 10. Par exemple, afin de calculer l'ordonnée du dernier point (à droite) de la courbe rouge, j'ai pris la moyenne des 5 dernières valeurs de prix. Ainsi, chaque moyenne mobile est non seulement «lissée» par rapport à la courbe des prix, mais aussi en retard de moitié par rapport à elle.
Règle d'ouverture de transaction
Le robot a une règle simple pour prendre une décision d'achat / vente:
- dès qu'une moyenne mobile à courte période (
MA «rapide») croise une moyenne mobile à longue période (MA «lente») de bas en haut, le robot achète un actif (or).
Dès que le MA «rapide» traverse le MA «lent» de haut en bas, le robot vend l'actif. Dans la figure ci-dessus, le robot effectuera 5 transactions: 3 ventes aux horodatages 7, 31 et 50 et deux achats (marques 16 et 36).
Le robot est autorisé à ouvrir un nombre illimité de transactions. Par exemple, à un moment donné, le robot peut avoir plusieurs achats et ventes en attente en même temps.
Règle de clôture des transactions
Le robot conclut l'accord dès que:
- le bénéfice de la transaction dépasse le seuil spécifié en pourcentage - TakeProfit,
- ou la perte sur la transaction, en pourcentage, dépasse la valeur correspondante - StopLoss.
Supposons que StopLoss est de 0,2%.
L'accord est une «vente» d'or au prix de 1061,50.
Dès que le prix de l'or monte à 1061,50 + 1061,50 * 0,2% / 100% = 1063,12%, la perte sur la transaction sera évidemment de 0,2% et le robot clôturera la transaction automatiquement.
Le robot prend toutes les décisions concernant l'ouverture / la clôture d'une transaction à des moments discrets - à la fin de chaque heure, après la publication du prochain devis XAUUSD.
Oui, le robot est extrêmement simple. En même temps, il répond à 100% aux exigences:
- l'algorithme est déterministe: à chaque fois, en simulant le travail du robot sur les mêmes données de prix, on obtiendra le même résultat,
- a un nombre suffisant de paramètres ajustables, à savoir: la période de «rapide» et la période de moyenne mobile «lente» (nombres naturels), TakeProfit et StopLoss - nombres réels positifs,
- une modification de chacun des 4 paramètres, dans le cas général, a un effet non linéaire sur les caractéristiques de trading du robot, notamment sur sa rentabilité,
- la rentabilité d'un robot sur l'historique des prix est considérée comme un code de programme élémentaire, et le calcul lui-même prend une fraction de seconde pour un vecteur de milliers de devis,
- enfin, ce qui n'est pourtant pas pertinent, le robot, avec toute sa simplicité, ne s'avérera en réalité pas pire (quoique probablement pas meilleur) que le Graal vendu par l'auteur sur Internet pour un montant impudique.
Recherche rapide d'un ensemble quasi optimal de paramètres d'entrée
En utilisant l'exemple de notre robot simple, on peut voir qu'une énumération complète de tous les vecteurs possibles des paramètres du robot est trop coûteuse même pour 4 paramètres variables. Une alternative évidente à la recherche exhaustive est le choix de vecteurs de paramètres pour une stratégie spécifique. Nous ne considérons qu'une partie de toutes les combinaisons possibles à la recherche de la meilleure, dans laquelle le
CF approche le plus haut (ou le plus petit, selon le CF que nous choisissons et le résultat que nous obtenons).
Nous considérerons trois algorithmes de recherche pour la valeur quasi
optimale du
filtre numérique . Pour chaque algorithme, nous avons fixé une limite de 40 tests (sur 400 combinaisons possibles).
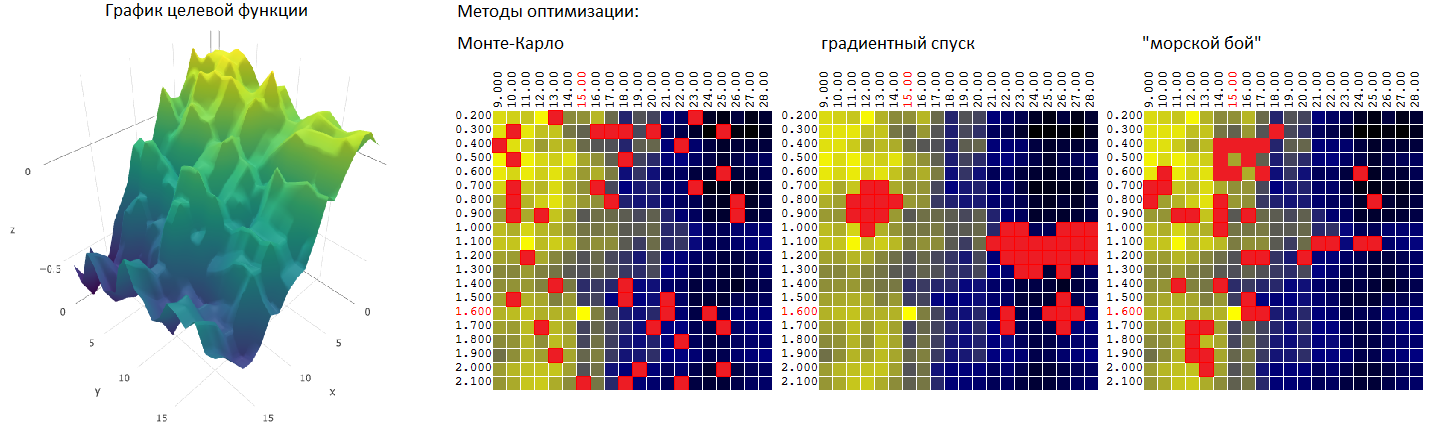
Méthode Monte Carlo
ou une sélection aléatoire de M vecteurs non corrélés parmi le nombre possible d'ensembles égal à N. La méthode est probablement la plus simple possible. Nous l'utiliserons comme point de départ pour une comparaison ultérieure avec d'autres méthodes d'optimisation.
Exemple 1
le graphique montre la dépendance du bénéfice (P) de notre robot de trading trading
EURUSD , obtenu sur le segment annuel de l'historique des mesures de prix horaires, sur la valeur du paramètre - la période de la
moyenne mobile «lente» (M). Tous les autres paramètres sont fixes et ne sont pas optimisés.
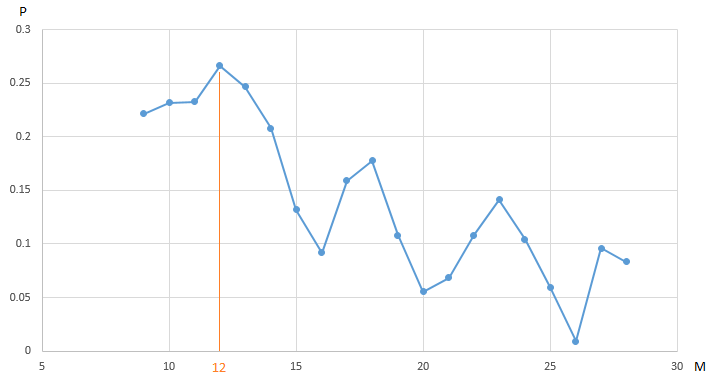
CF (profit) atteint un maximum de 0,27 au point M = 12. Afin de garantir la valeur maximale du profit, nous devons effectuer 20 itérations de tests. Une alternative consiste à effectuer un plus petit nombre de tests d'un robot de trading avec une valeur choisie au hasard du paramètre M sur l'intervalle [9, 20]. Par exemple, après 5 itérations (20% du nombre total de tests, nous avons trouvé un vecteur quasi optimal (vecteur, évidemment, unidimensionnel) de paramètres: M = 18 avec une valeur de CF (M) égale à 0,18:

Les valeurs restantes sur le graphique de notre algorithme d'optimisation ont été cachées par le «brouillard de guerre».
L'optimisation de l'un des quatre paramètres de notre robot de trading, avec des valeurs fixes des paramètres restants, ne nous permet pas de voir l'ensemble du tableau. Peut-être qu'un maximum de 0,27 CF n'est pas la meilleure valeur de l'indicateur, si vous faites varier la valeur d'autres paramètres?

C'est ainsi que la dépendance du profit sur la période moyenne mobile change pour différentes valeurs du paramètre TakeProfit sur l'intervalle [0,2 ... 0,8].
Méthode Monte Carlo: optimisation de deux paramètres
La dépendance du profit d'un robot de trading sur deux paramètres peut être représentée graphiquement comme une surface:

Les deux axes sont les valeurs des paramètres T (TakeProfit) et M (période de la moyenne mobile), le troisième axe est la valeur de profit.
Pour notre robot de trading, après avoir effectué 400 tests sur un intervalle de données d'un an (~ 6000 cotations horaires de l'euro contre le dollar américain), nous obtenons une surface du formulaire:

ou, dans le plan où les valeurs des actifs financiers (profit, P) sont représentées par la couleur:

En choisissant des points arbitraires sur le plan, dans cet exemple, l'algorithme n'a pas trouvé la valeur optimale, mais s'en est approché assez près:

Quelle est l'efficacité de la méthode de Monte Carlo pour trouver le
CF maximum? Après avoir effectué 1000 itérations de recherche du maximum de CF sur les données source de l'exemple ci-dessus, j'ai obtenu les statistiques suivantes:
- la valeur moyenne du maximum du DF trouvé lors de 1000 itérations d'optimisation (40 vecteurs aléatoires de paramètres [M, T] sur 400 combinaisons possibles) était de 0,231 ou 95,7% du maximum global du DF (0,279).
Évidemment, en comparant les méthodes d'optimisation paramétrique des robots de trading, un échantillon n'est pas un indicateur. Mais pour l'instant, cette évaluation est suffisante. Nous passons à la méthode suivante - la méthode de
descente en gradient .
Méthode de descente en gradient
Formellement, comme son nom l'indique, la méthode est utilisée pour rechercher le minimum de DF.
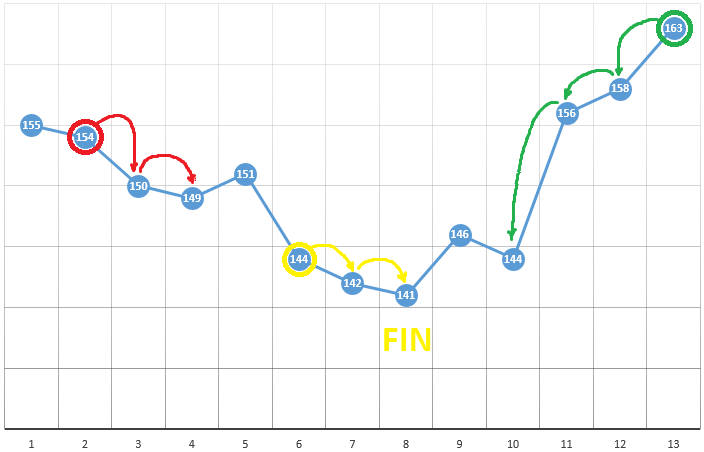
Selon la méthode, nous sélectionnons le point de départ avec les coordonnées [x0, y0, z0, ...]. Sur l'exemple d'optimisation d'un paramètre, il peut s'agir d'un point choisi au hasard:
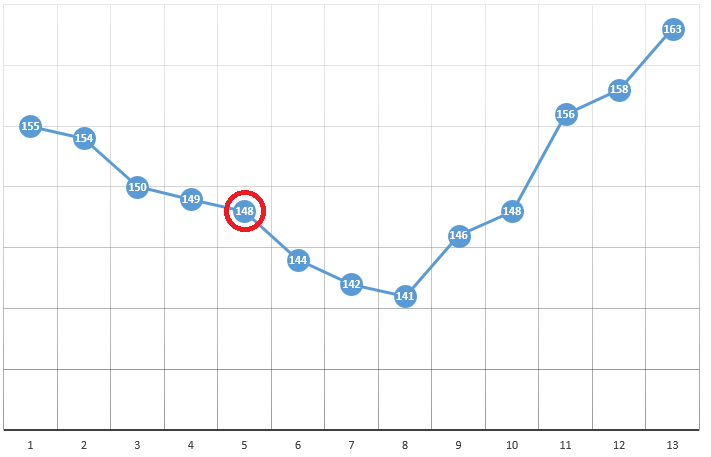
avec les coordonnées [5] et une valeur DF de 148. Voici trois étapes simples:
- vérifier les valeurs CF au voisinage de la position actuelle (149 et 144)
- passer au point avec la plus petite valeur CF
- s'il est absent, un extremum local est trouvé, l'algorithme est terminé

Pour optimiser le DF en fonction de deux paramètres, nous utilisons le même algorithme. Si plus tôt nous avons calculé le CF à deux points voisins
[xi−1],[xi+1] , maintenant nous vérifions 4 points:
[xi−1,yi],[xi+1,yi],[xi,yi−1],[xi,yi+1].
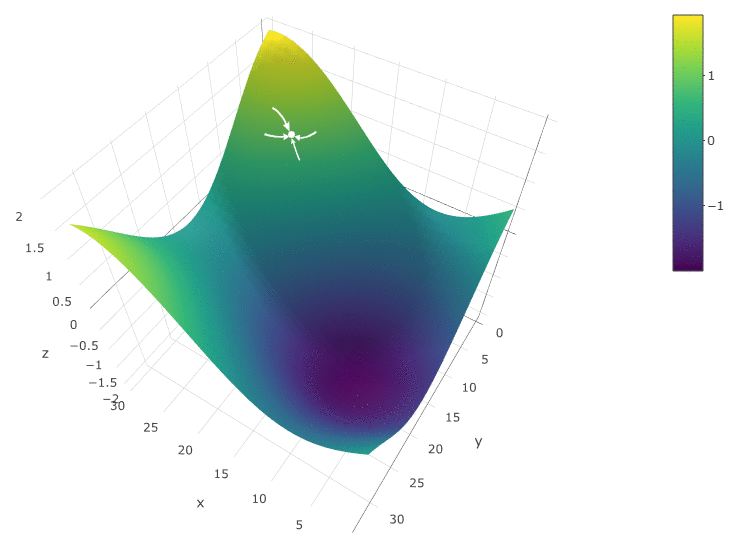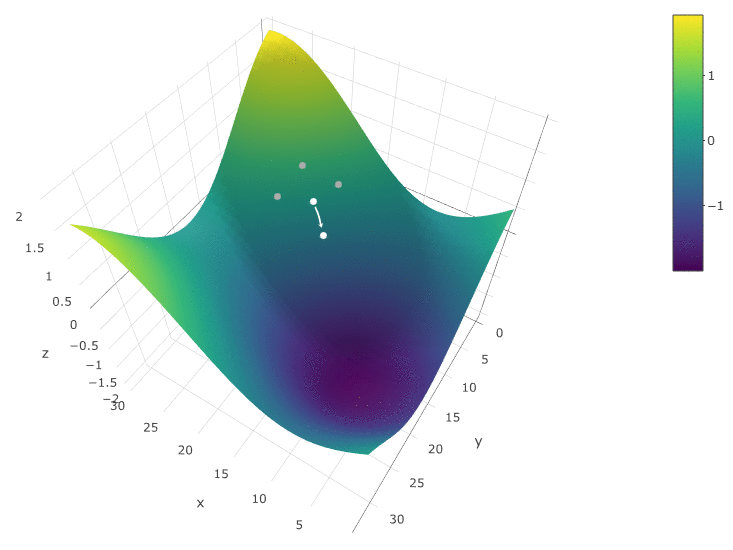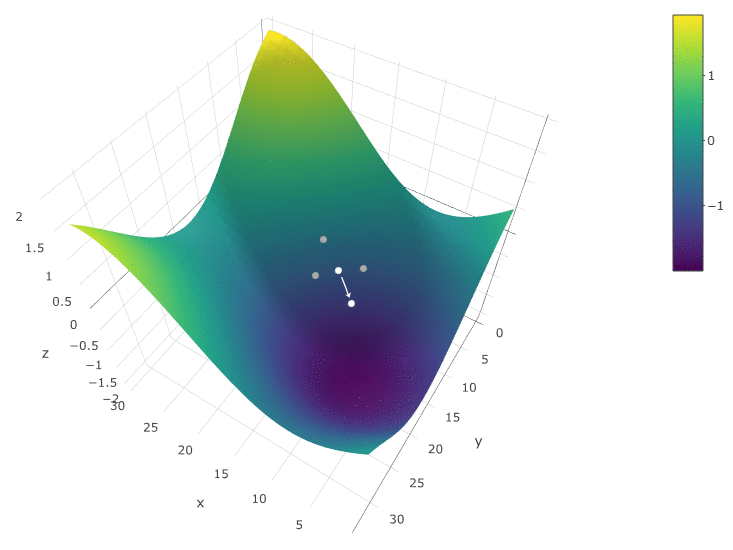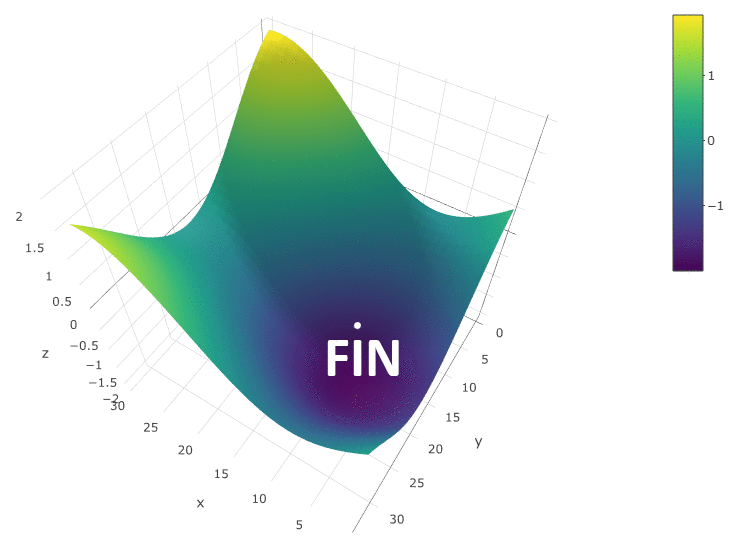
La méthode est définitivement bonne quand il n'y a qu'un seul extremum dans un DF dans un espace de test. S'il y a plusieurs extrema, la recherche devra être répétée plusieurs fois pour augmenter la probabilité de trouver un extremum global:
Dans notre exemple, nous recherchons le DF
maximum . Pour rester dans la définition de l'algorithme, nous pouvons supposer que nous recherchons un minimum de «moins DF». Toujours le même exemple, le profit d'un robot de trading en fonction de la période de la moyenne mobile et de la valeur TakeProfit, une itération:
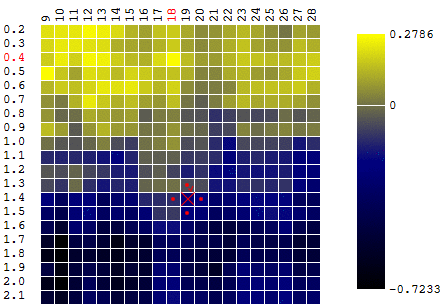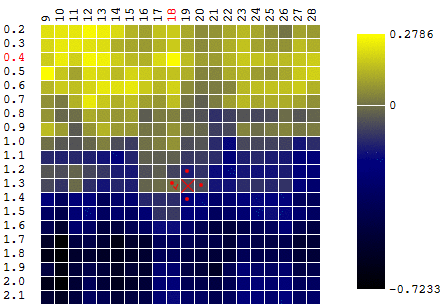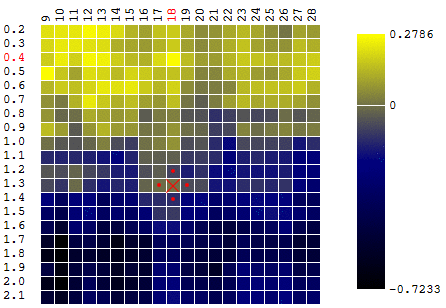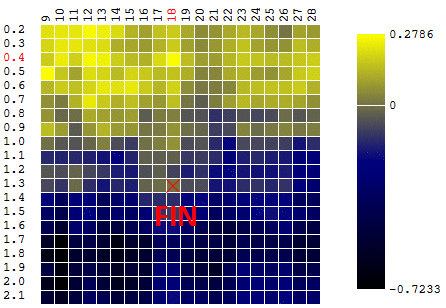
Dans ce cas, un extremum local a été trouvé qui est loin du maximum global des FC. Exemple de plusieurs itérations de la recherche de l'extrémum du FS par la méthode de descente en gradient, la valeur du FS est calculée 40 fois (40 points sur 400 possibles):

Maintenant, nous comparons l'efficacité de la recherche du maximum global du CF (profit) sur nos données initiales en utilisant des algorithmes de Monte Carlo et de descente de gradient. Dans chaque cas, 40 tests sont effectués (calculs CF). 1000 itérations d'optimisation ont été réalisées par chacune des méthodes:
| Monte Carlo | descente de gradient |
|---|
| la moyenne de la valeur quasi-optimale obtenue de CF | 0,231 | 0,200 |
| la valeur obtenue du maximum du CF | 95,7% | 92,1% |
Comme vous pouvez le voir dans le tableau, dans cet exemple, la méthode de descente en gradient est moins performante pour sa tâche - rechercher l'extremum global de l'actif numérique - le profit maximum. Mais nous ne sommes pas pressés de le rejeter.
Stabilité paramétrique de l'algorithme de trading
Trouver les coordonnées du maximum / minimum global d'un filtre numérique n'est souvent pas un objectif d'optimisation. Supposons, sur le graphique, qu'il y ait un pic «net» - un maximum global, dont la valeur de CF au voisinage est bien inférieure à la valeur de pic:
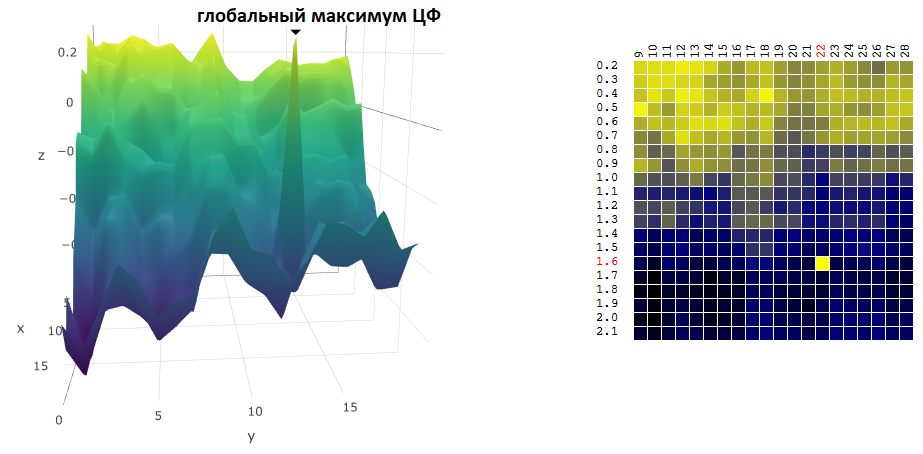
Supposons que nous ayons sélectionné les paramètres du robot de trading qui correspondent au maximum trouvé de l'actif numérique. Si nous modifions légèrement la valeur d'au moins un des paramètres - la période de la moyenne mobile et / ou TakeProfit - la rentabilité du robot baissera fortement (deviendra négative). En ce qui concerne le trading réel, on peut au moins s'attendre à ce que le marché sur lequel notre robot doit trader soit sensiblement différent de la période de l'histoire dans laquelle nous avons optimisé l'algorithme de trading.
Par conséquent, lors du choix des paramètres «optimaux» d'un robot de trading, il est utile de se faire une idée de la sensibilité du robot aux changements de paramètres au voisinage du point d'extrémité trouvé du DF.
De toute évidence, la méthode de descente en gradient, en règle générale, nous donne les valeurs de TF au voisinage de l'extremum. La méthode de Monte-Carlo est plus susceptible de toucher des carrés.
Dans plusieurs instructions pour tester des stratégies de trading automatisées, une fois l'optimisation terminée, il est recommandé de vérifier les indicateurs cibles du robot à proximité du vecteur de paramètres trouvé. Mais ce sont des tests supplémentaires. De plus, que se passe-t-il si la rentabilité de la stratégie baisse avec un léger changement de paramètres? De toute évidence, vous devez répéter le processus de test.
Un algorithme nous serait utile qui, en même temps que la recherche de l'extremum des CF, nous permettrait d'évaluer la stabilité de la stratégie de trading pour changer les paramètres dans une fourchette étroite par rapport aux pics trouvés. Par exemple, ne recherchez pas directement le CF maximum
P=f(mi,ti),
et la valeur moyenne pondérée qui prend en compte les valeurs voisines de la fonction objectif, où le poids est inversement proportionnel à la distance à la valeur voisine (pour optimiser deux paramètres x, y et la fonction objectif P):
P′(xi,yi)= fracwi foisP(xi,yi)+wj foisP(xj,yj)+wk foisP(xk,yk)+...wi+wj+wk+...
wj= sqrt(xj−xi)2+(yj−yi)2
wi+wj+wk+...=1
En d'autres termes, lors du choix d'un vecteur de paramètres quasi optimal, l'algorithme évaluera la fonction objectif «lissée»:
étaitest devenu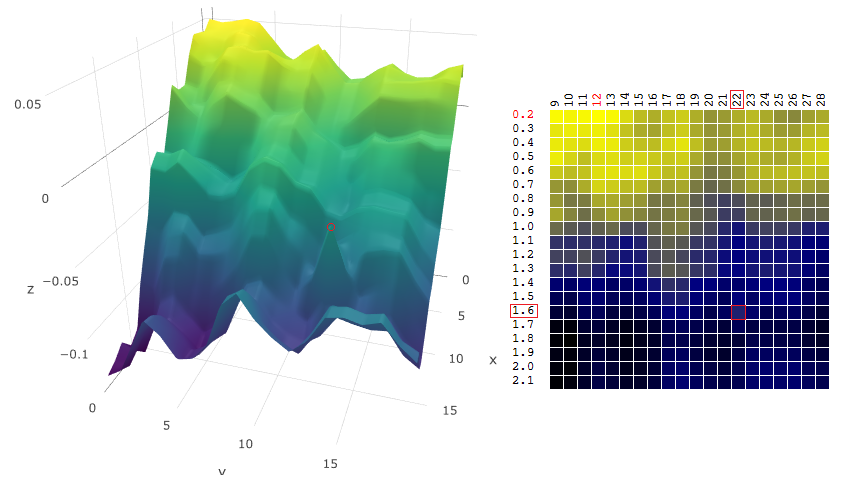
La méthode de la «bataille navale»
En essayant de combiner les avantages des deux méthodes (Monte Carlo et la méthode de descente en gradient), j'ai essayé un algorithme similaire à l'algorithme du jeu dans la «bataille navale»:
- d'abord, je frappe quelques "coups" sur toute la zone
- puis, dans les lieux de «coups», j'ouvre un feu massif.
En d'autres termes, les N premiers tests sont effectués sur des vecteurs aléatoires non corrélés de paramètres d'entrée. Parmi ceux-ci, les M meilleurs résultats sont sélectionnés. Au voisinage de ces tests (plus - minutes 0..L pour chacune des coordonnées) un autre K tests est effectué.
Pour notre exemple (400 points, 40 essais au total) nous avons:
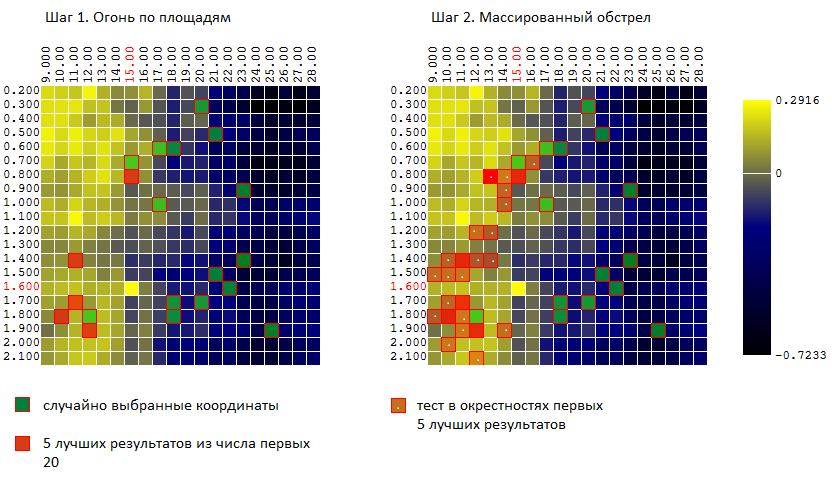
Et encore une fois, nous comparons l'efficacité de maintenant 3 algorithmes d'optimisation:
| Monte Carlo | descente de gradient | «Bataille maritime» |
|---|
La valeur moyenne de l'extremum trouvé des FC en pourcentage de la valeur globale.
40 tests, 1 000 itérations d'optimisation
| 95,7% | 92,1% | 97,0% |
Le résultat est encourageant. Bien entendu, la comparaison a été effectuée sur un échantillon de données spécifique: un algorithme de négociation sur une série chronologique de la valeur de l'euro par rapport au dollar américain.
Mais, avant de comparer les algorithmes sur un plus grand nombre d'échantillons de données source, je vais parler d'un autre algorithme populaire pour optimiser les stratégies de trading, de manière inattendue (injustifiable?) - l'optimisation de l' algorithme génétique (GA). Cependant, l'article est sorti trop volumineux et l'AG devra être reportée à la prochaine publication .