Au début de l'année, nous avons décidé d'apprendre à stocker et à lire les journaux de débogage VK plus efficacement qu'auparavant. Les journaux de débogage sont, par exemple, des journaux de conversion vidéo (essentiellement la sortie de la commande ffmpeg et une liste d'étapes de prétraitement des fichiers), dont nous n'avons parfois besoin que de 2 à 3 mois après le traitement du fichier problème.
À cette époque, nous avions 2 façons de stocker et de traiter les journaux - notre propre moteur de journaux et rsyslog, que nous utilisions en parallèle. Nous avons commencé à envisager d'autres options et avons réalisé que ClickHouse de Yandex nous convenait parfaitement - nous avons décidé de la mettre en œuvre.
Dans cet article, je vais vous parler de la façon dont nous avons commencé à utiliser ClickHouse sur VKontakte, du type de râteau sur lequel ils ont marché et de ce que sont KittenHouse et LightHouse. Les deux produits sont présentés en open-source, des liens à la fin de l'article.
Tâche de collecte des journaux
Configuration requise:
- Stockage de centaines de téraoctets de journaux.
- Stockage pendant des mois ou (rarement) des années.
- Vitesse d'écriture élevée.
- Vitesse de lecture élevée (la lecture est rare).
- Prise en charge de l'index
- Prise en charge des cordes longues (> 4 Ko).
- Simplicité de fonctionnement.
- Stockage compact.
- La possibilité d'insérer à partir de dizaines de milliers de serveurs (UDP sera un plus).
Solutions possibles
Énumérons brièvement les options que nous avons envisagées et leurs inconvénients:
Moteur de journaux
Notre microservice auto-écrit pour les journaux.
- Capable de ne donner que les N dernières lignes qui tiennent dans la RAM.
- Stockage peu compact (pas de compression transparente).
Hadoop
- Tous les formats n'ont pas d'index.
- La vitesse de lecture peut être plus élevée (selon le format).
- La complexité des paramètres.
- Il n'y a aucune possibilité d'insertion à partir de dizaines de milliers de serveurs (Kafka ou analogues sont nécessaires).
Fichiers Rsyslog +
- Pas d'index.
- Faible vitesse de lecture (grep / zgrep régulier).
- Chaînes non prises en charge sur le plan architectural> 4 Ko, UDP encore moins (1,5 Ko).
± Le stockage compact est réalisé par logrotate sur la couronne
Nous avons utilisé rsyslog comme solution de rechange pour le stockage à long terme, mais les longues lignes ont été tronquées, il peut donc difficilement être qualifié d'idéal.
Fichiers LSD +
- Pas d'index.
- Faible vitesse de lecture (grep / zgrep régulier).
- Pas spécialement conçu pour être inséré à partir de dizaines de milliers de serveurs.
± Le stockage compact est réalisé par logrotate sur la couronne.
Les différences par rapport à rsyslog dans notre cas sont que LSD prend en charge les chaînes longues, mais des modifications importantes du protocole interne sont nécessaires pour insérer à partir de dizaines de milliers de serveurs, bien que cela puisse être fait.
Elasticsearch
- Problèmes de fonctionnement.
- Enregistrement instable.
- Pas d'UDP.
- Mauvaise compression.
La pile ELK est déjà presque la norme de l'industrie pour le stockage des journaux. D'après notre expérience, tout va bien avec la vitesse de lecture, mais il y a des problèmes d'écriture, par exemple, lors de la fusion d'indices.
ElasticSearch est principalement conçu pour la recherche en texte intégral et les demandes de lecture relativement fréquentes. Pour nous, un enregistrement stable et la possibilité de lire nos données plus ou moins rapidement sont plus importants, et par coïncidence exacte. L'index pour ElasticSearch est affiné pour la recherche en texte intégral, et l'espace disque est assez important par rapport au gzip du contenu original.
Clickhouse
- Pas d'UDP.
Dans l'ensemble, la seule chose qui ne nous convenait pas chez ClickHouse était le manque de communication UDP. En fait, parmi les options ci-dessus, seul rsyslog l'avait, mais rsyslog ne supportait pas les longues lignes.
Selon d'autres critères, ClickHouse est venu vers nous, et nous avons décidé de l'utiliser, et des problèmes de transport ont été résolus au cours du processus.
Pourquoi KittenHouse est nécessaire
Comme vous le savez probablement, VKontakte fonctionne sur PHP / KPHP, avec des "moteurs" (microservices) en C / C ++ et un peu sur Go. PHP n'a pas de concept «d'état» entre les requêtes, sauf peut-être pour la mémoire partagée et les connexions ouvertes.
Puisque nous avons des dizaines de milliers de serveurs à partir desquels nous voulons pouvoir envoyer des journaux à ClickHouse, il ne serait pas rentable de garder des connexions ouvertes de chaque travailleur PHP (il peut y avoir plus de 100 travailleurs pour chaque serveur). Par conséquent, nous avons besoin d'une sorte de proxy entre ClickHouse et PHP. Nous avons appelé ce proxy KittenHouse.
KittenHouse, v1
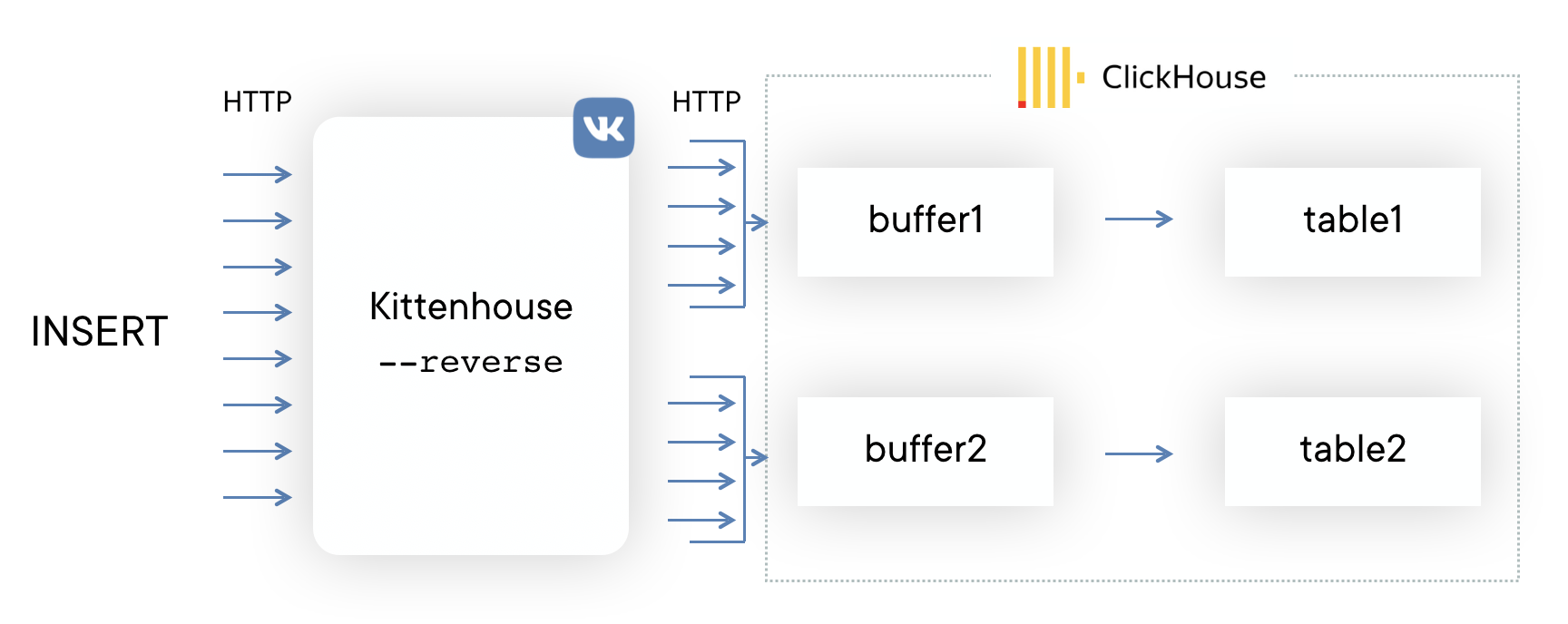
Tout d'abord, nous avons décidé d'essayer le schéma le plus simple possible pour comprendre si notre approche fonctionnerait ou non. Si Kafka vous vient à l'esprit lorsque vous résolvez ce problème, alors vous n'êtes pas seul. Cependant, nous ne voulions pas utiliser de serveurs intermédiaires supplémentaires - dans ce cas, nous pourrions facilement nous reposer sur les performances de ces serveurs, et non sur ClickHouse lui-même. De plus, nous avons collecté des journaux et nous avions besoin d'un léger retard prévisible dans l'insertion des données. Le schéma est le suivant:

Sur chacun des serveurs, notre proxy local (kittenhouse) est installé et chaque instance conserve strictement une connexion HTTP avec le serveur ClickHouse nécessaire. Le collage se fait dans des tables spoulées, car il n'est souvent pas recommandé d'insérer MergeTree.
Caractéristiques KittenHouse, v1
La première version de KittenHouse en savait un peu, mais cela suffisait pour les tests:
- Communication via notre RPC (TL Scheme).
- Maintenez 1 connexion TCP / IP par serveur.
- Mise en mémoire tampon par défaut, avec une taille de mémoire tampon limitée (le reste est rejeté).
- La possibilité d'écrire sur le disque, dans ce cas il y a une garantie de livraison (au moins une fois).
- L'intervalle d'insertion est une fois toutes les 2 secondes.
Premiers problèmes
Nous avons rencontré le premier problème lorsque nous avons «remboursé» le serveur ClickHouse pendant plusieurs heures, puis l'avons rallumé. Ci-dessous, vous pouvez voir la moyenne de charge sur le serveur après qu'il a "augmenté":
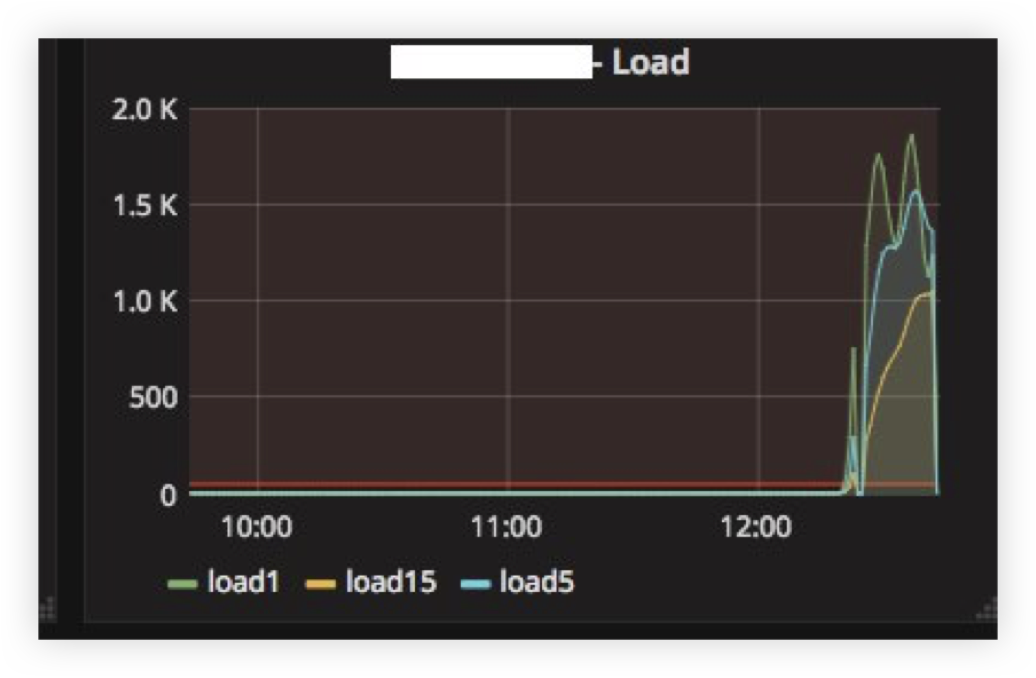
L'explication est assez simple: ClickHouse a un modèle de réseau par thread, donc quand j'essaye de faire INSERT à partir de milliers de nœuds en même temps, il y avait une très forte concurrence pour les ressources CPU et le serveur a à peine répondu. Cependant, toutes les données ont finalement été insérées et rien n'est tombé.
Pour résoudre ce problème, nous avons mis nginx devant ClickHouse et, en général, cela a aidé.
Développement ultérieur
Au cours de l'opération, nous avons rencontré un certain nombre de problèmes, principalement liés non pas à ClickHouse, mais à notre mode de fonctionnement. Voici un autre râteau sur lequel nous avons marché:
Un grand nombre de «morceaux» de tables Buffer entraîne des vidages fréquents de tampon dans MergeTree
Dans notre cas, il y avait 16 morceaux de tampon et un intervalle de réinitialisation toutes les 2 secondes, et il y avait 20 morceaux de tables, ce qui donnait jusqu'à 160 insertions par seconde. Cela affectait périodiquement très fortement les performances d'insertion - il y avait beaucoup de fusions en arrière-plan et l'utilisation du disque atteignait 80% et plus.
Solution: augmentez l'intervalle de réinitialisation du tampon par défaut, réduisez le nombre de pièces à 2.
Nginx renvoie 502 lorsque les connexions à l'extrémité amont
Cela en soi n'est pas un problème, mais en combinaison avec un vidage fréquent du tampon, cela a donné un arrière-plan assez élevé de 502 erreurs lors de la tentative d'insertion dans l'une des tables, ainsi que lors de la tentative de SELECT.
Solution: ils ont écrit leur proxy inverse à l'aide de la bibliothèque
fasthttp , qui regroupe l'insert en tables et consomme très économiquement les connexions. Il fait également la distinction entre SELECT et INSERT et dispose de pools de connexion distincts pour l'insertion et la lecture.
Manque de mémoire avec insertion intensive
La bibliothèque fasthttp a ses avantages et ses inconvénients. L'un des inconvénients est que la requête et la réponse sont entièrement mises en mémoire tampon avant de donner le contrôle au gestionnaire de requêtes. Pour nous, cela a abouti au fait que si l'insertion dans ClickHouse "n'avait pas le temps", alors les tampons ont commencé à augmenter et finalement toute la mémoire sur le serveur s'est épuisée, ce qui a conduit à la destruction du proxy inverse par OOM. Des collègues ont dessiné un démotivateur:
 Solution:
Solution: patcher fasthttp pour prendre en charge le streaming du corps de la demande POST s'est avéré être une tâche intimidante, nous avons donc décidé d'utiliser les connexions Hijack () et de mettre à niveau la connexion à notre protocole si la demande venait avec la méthode HTTP KITTEN. Puisque le serveur doit répondre MEOW en réponse, s'il comprend ce protocole, l'ensemble du schéma est appelé protocole KITTEN / MEOW.
Nous lisons uniquement à partir de 50 connexions aléatoires à la fois, donc, grâce à TCP / IP, le reste des clients «attend» et nous ne dépensons pas de mémoire sur les tampons jusqu'à ce que la file d'attente atteigne les clients correspondants. Cela a réduit la consommation de mémoire d'au moins 20 fois, et nous n'avons plus eu de tels problèmes.
Les tables ALTER peuvent durer longtemps s'il y a de longues requêtes
ClickHouse a un ALTER non bloquant dans le sens où il n'interfère pas avec les requêtes SELECT et INSERT. Mais ALTER ne peut pas démarrer tant qu'il n'a pas terminé d'exécuter des requêtes sur cette table envoyée avant ALTER.
Si votre serveur a des antécédents de «longues» requêtes sur certaines tables, vous pouvez rencontrer une situation où ALTER sur cette table n'aura pas le temps de s'exécuter dans un délai par défaut de 60 secondes. Mais cela ne signifie pas qu'ALTER échouera: il sera exécuté dès que ces requêtes SELECT seront terminées.
Cela signifie que vous ne savez pas à quel moment ALTER s'est réellement produit et que vous n'avez pas la possibilité de recréer automatiquement les tables Buffer afin que leur disposition soit toujours la même. Cela peut entraîner des problèmes d'insertion.

 Solution:
Solution: En conséquence, nous prévoyons d'abandonner complètement l'utilisation des tables tampons. En général, les tables tampons ont une portée, jusqu'à présent, nous les utilisons et ne rencontrons pas d'énormes problèmes. Mais maintenant, nous avons finalement atteint le point où il est plus facile d'implémenter la fonctionnalité des tables de tampons du côté du proxy inverse que de continuer à accepter leurs défauts. Un exemple de circuit ressemblera à ceci (la ligne pointillée montre l'asynchronie ACK sur INSERT).

Lecture des données
Disons que nous avons compris l'encart. Comment lire ces journaux de ClickHouse? Malheureusement, nous n'avons trouvé aucun outil pratique et facile à utiliser pour lire les données brutes (sans graphiques et autres) de ClickHouse, nous avons donc écrit notre propre solution - LightHouse. Ses capacités sont plutôt modestes:
- Vue rapide du contenu du tableau.
- Filtrage, tri.
- Modification d'une requête SQL.
- Voir la structure de la table.
- Affiche le nombre approximatif de lignes et l'espace disque utilisé.
Cependant, LightHouse est rapide et capable de faire ce dont nous avons besoin. Voici quelques captures d'écran:
Voir la structure de la table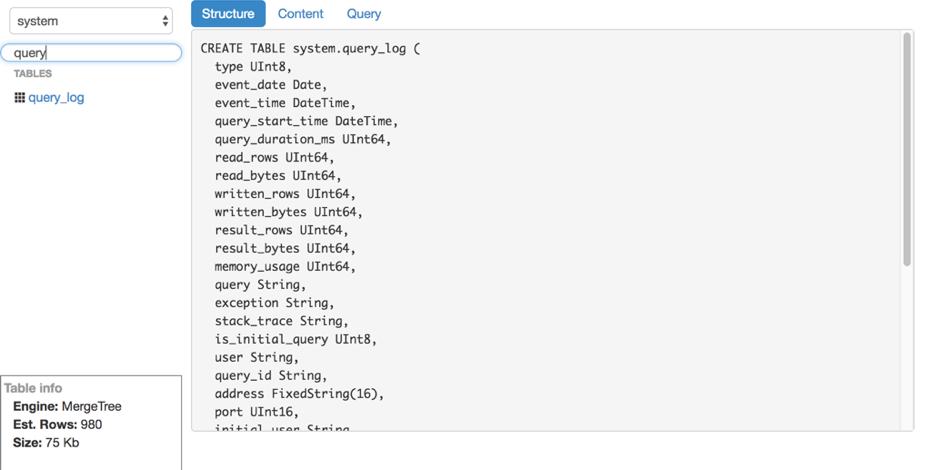 Filtrage de contenu
Filtrage de contenu
Résultats
ClickHouse est pratiquement la seule base de données open source qui a pris racine sur VKontakte. Nous sommes satisfaits de la rapidité de ses travaux et sommes prêts à accepter les lacunes qui sont examinées ci-dessous.
Difficulté au travail
Dans l'ensemble, ClickHouse est une base de données très stable et très rapide. Cependant, comme pour tout produit, surtout si jeune, il y a des caractéristiques dans le travail qui doivent être prises en compte:
- Toutes les versions ne sont pas également stables: ne passez pas directement à la nouvelle version en production, il vaut mieux attendre plusieurs versions de correction de bugs.
- Pour des performances optimales, il est fortement conseillé de configurer le RAID et d'autres choses selon les instructions. Cela a été récemment signalé sur une charge élevée .
- La réplication n'a pas de limites de vitesse intégrées et peut entraîner une dégradation significative des performances du serveur si vous ne la limitez pas vous-même (mais ils promettent de la corriger).
- Linux a une caractéristique désagréable du mécanisme de mémoire virtuelle: si vous écrivez activement sur le disque et que les données n'ont pas le temps d'être vidées, à un moment donné, le serveur «se met complètement en lui-même», commence à vider activement le cache des pages sur le disque et bloque presque complètement le processus ClickHouse. Cela se produit parfois avec des fusions importantes et vous devez surveiller cela, par exemple, vider régulièrement les tampons vous-même ou effectuer une synchronisation.
Open source
KittenHouse et LightHouse sont maintenant disponibles en open source dans notre dépôt github:
Je vous remercie!
Yuri Nasretdinov, développeur au département d'infrastructure backend de VKontakte