La vente au détail a un cercle très diversifié de clients. Ils sont nombreux - professions et niveaux de revenus divers, des jeunes aux seniors. Une telle variété ne peut pas être correctement décrite par deux ou trois règles commerciales, car vous ne pouvez tout simplement pas couvrir toutes les combinaisons de critères et perdre inévitablement certains clients. Par conséquent, pour le commerce de détail, il est très important de segmenter votre public aussi précisément que possible, mais cela complique inévitablement les modèles. Les technologies de Machine Learning viennent à la rescousse ici, offrant aux entreprises des prévisions et des réponses plus précises aux questions importantes.
Quelles questions voulez-vous dire? Par exemple: le client partira-t-il? Souvent, les clients partent si le magasin n'a pas le bon produit. Par exemple, une femme achète une crème spéciale chaque mois pour 10 000 roubles et peut choisir parmi deux magasins de cosmétiques. Dans l'un d'eux, le produit requis fait souvent défaut et dans le second, il n'y a pas de problème de disponibilité. Très probablement, elle achètera constamment dans le second, bien qu'un peu plus cher.
Autre question urgente: comment optimiser le travail du personnel? Par exemple, vous devez planifier des quarts de travail pour les caissiers et les conseillers commerciaux. Une façon consiste à utiliser l'analyse statistique. L'analyste évalue l'activité des clients en fonction du jour de la semaine et constate que le samedi ils achètent le plus, le vendredi et le dimanche un peu moins. Cette hypothèse est vérifiée par des tests statistiques et les conclusions sont transmises à la direction.
Mais une telle analyse peut ne pas prendre en compte de nombreuses combinaisons de facteurs. Par exemple, si le 7 mars est le mercredi - achèteront-ils plus ce jour-là que le vendredi (après tout, en temps normal, le vendredi est un jour plus populaire que les autres jours de la semaine)? Et la remise des diplômes? Ou des vacances locales? Plus il y a de facteurs, plus il est difficile de tous les prendre en compte à l'aide de règles simples. Et au lieu de compliquer infiniment les règles, vous pouvez créer un modèle qui prédit la demande pour un jour particulier.
Notre projet dans la distribution non alimentaire
Dans ce cas, il a fallu analyser la base de clients (environ 2,5 millions de personnes) et prédire lequel d'entre eux reviendrait au magasin dans les deux prochaines semaines. Nous avons utilisé deux méthodes de la bibliothèque CatBoost - CatBoostClassifier et CatBoostRegressor, la première - pour prédire la composition de l'audience, la seconde - pour sélectionner les produits les plus populaires au cours des 2 prochaines semaines. CatBoost
est sorti au tout début de notre projet, c'était une nouvelle approche pour travailler avec des attributs catégoriels. Et comme la gamme de produits de notre client contient de nombreuses fonctionnalités catégoriques, nous avons volontiers essayé le nouveau produit. Après avoir sélectionné les paramètres, le modèle a immédiatement répondu à nos attentes avec des prévisions précises. Pas étonnant que CatBoost soit l'un des modèles d'augmentation de gradient les plus populaires aujourd'hui.
Pour le modèle, nous avons pris des statistiques pour 2017:
- chèques: à qui appartient la carte bonus du chèque, lors de l'achat, ce qu'ils ont acheté, la remise, l'acheter ou le rembourser.
- démographie: région et ville de résidence du client, date de naissance et sexe, consentement à l'envoi par téléphone ou par courrier.
- produits: quelle catégorie ou segment comprend les achats, la portée, etc.
Nous avons nettoyé les données de bruit (cartes du vendeur, retours, achats de services, pas de marchandises) et calculé les critères nécessaires (pourcentage de remise, âge). Après cela, nous avons calculé le plus grand et le plus petit reçu pour chaque client, les remises moyennes, médianes et maximales, combien de fois une personne est entrée et combien de produits de quelles catégories elle a acheté. Ces paramètres ont été comptés en intervalles: la semaine dernière, deux semaines, un mois, trois mois. Ce travail minutieux a permis de construire des modèles avec une grande précision de prévision.
Données agrégées pour les modèles et calculs lancés. Le premier modèle a prédit lequel des acheteurs viendra dans les deux prochaines semaines et le second a émis des recommandations: quels produits (jusqu'au niveau de l'article) une personne particulière achètera. Soit dit en passant, l'exigence de prédire la popularité d'articles spécifiques a considérablement compliqué la tâche (généralement, les besoins des entreprises sont basés sur des catégories et des noms de marchandises plutôt que sur des positions).
Les clients recommandés par le modèle pour le publipostage ciblé avaient un chèque médian plus important pour une visite, et pour la période analysée, ils ont acheté un montant total plus élevé que les autres clients.
En conséquence, après l'envoi, environ 30% des clients ont acheté au moins l'un des trois produits prévus par le modèle.
Désormais, l'entreprise peut prédire avec plus de précision les ventes: le détaillant sait qui viendra le voir dans un avenir proche et ce qu'il achètera. Cela permet non seulement d'optimiser la logistique, mais également de réduire les coûts associés. Par exemple, si un client particulier n'achète généralement rien en hiver, vous n'avez pas besoin de lui envoyer un SMS en janvier. Les modèles optimisent également les envois: un spécialiste basé sur une prévision comprend immédiatement qui doit envoyer un e-mail et à qui - un SMS urgent.
Pièges
Ils sont dans n'importe quelle tâche ML - ils étaient dans les nôtres. Par exemple, nous avons testé si les envois de recommandations de produits contribuent à augmenter les ventes. Pour cela, le segment de clientèle prévu a été divisé en trois groupes:
- Contrôle - n'a pas reçu la newsletter.
- Groupe avec rappels - a reçu un texte commun du magasin.
- Groupe avec recommandations - SMS reçu avec trois produits spécifiques prévus par le modèle.
Il s'est avéré que les personnes ayant reçu des recommandations achetaient moins que les clients qui ne recevaient pas de newsletters. La facture moyenne et le montant des marchandises achetées étaient moindres. Le test T a montré que les différences étaient statistiquement significatives (valeur p = 0,017).
Pour dire les choses modestement, ces résultats ont découragé tout le monde. Ils ont commencé à chercher la raison et ont découvert que les magasins envoyaient des messages aux clients dans un messager spécifique, et ses utilisateurs de notre segment achetaient initialement moins que les autres clients. Même les spécialistes du marketing du client ne le savaient pas. L'expérience s'est donc avérée incorrecte, mais selon ses résultats, nous avons ajouté le paramètre «utilisateur messager» au modèle. Ce cas montre comment sélectionner soigneusement les canaux de communication avec les clients.
Quelles autres conclusions peut-on tirer?
- Il n'y a pas beaucoup de données.
- Parfois, le point de vue de l’analyste conduit à une nouvelle idée.
Segmentation de la clientèle
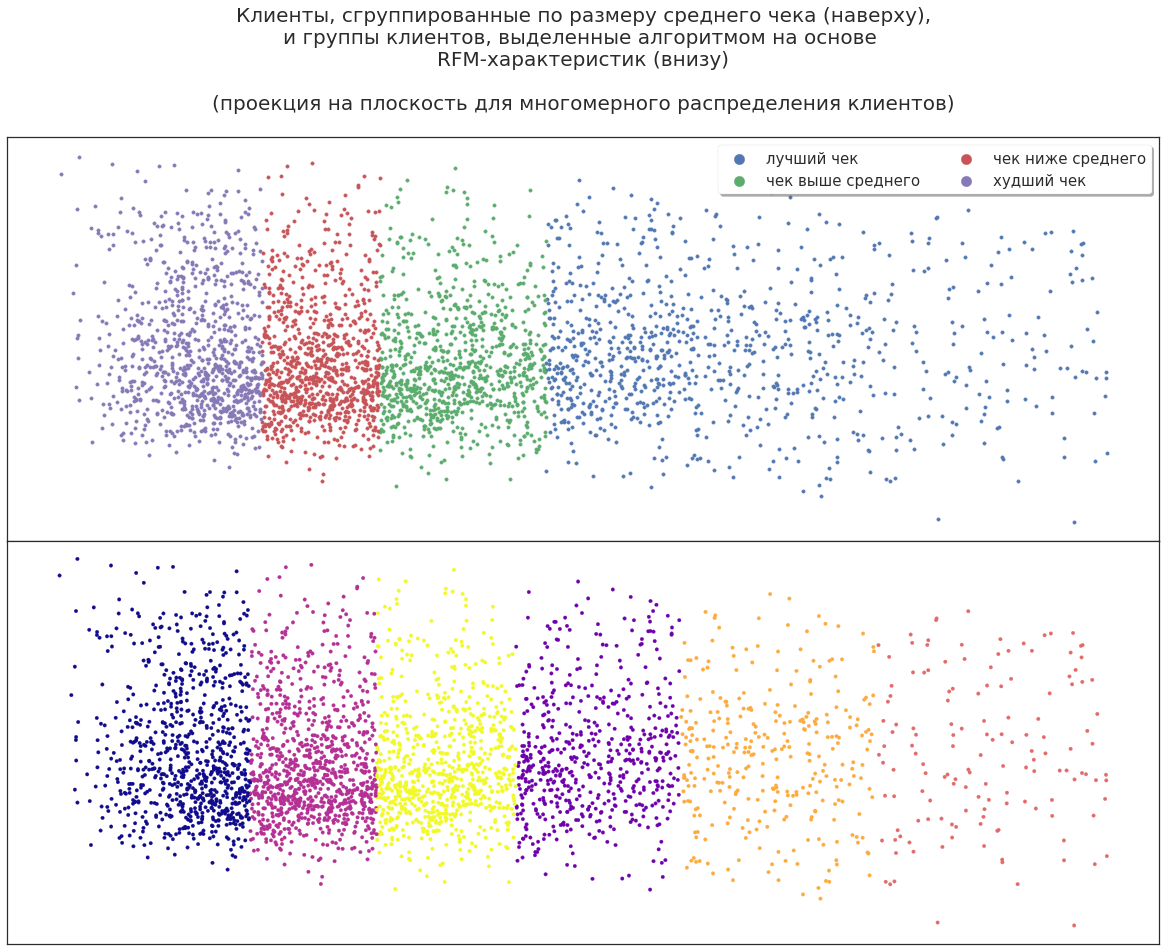
L'analyse des données vous permet de détecter des modèles qui étaient cachés dans les informations précédemment disponibles. Un bon exemple est de comparer les groupes de clients en utilisant la segmentation RFM (fréquence de récence monétaire) et la segmentation en utilisant des algorithmes ML.
La segmentation RFM utilise trois mesures clés:
- Prescription du dernier achat
- fréquence des achats pour la période
- montant dépensé par le client.
Sur la base de ces données, les principaux groupes sont distingués: «gaspilleurs», «clients fidèles», «clients presque perdus», etc. Et les spécialistes du marketing incluent déjà le groupe cible souhaité dans une newsletter spécifique ou font une offre spécifiquement pour ce groupe.
Par exemple, à l'aide de la segmentation RFM, vous pouvez sélectionner des segments clients et les représenter comme des points dans un espace tridimensionnel:
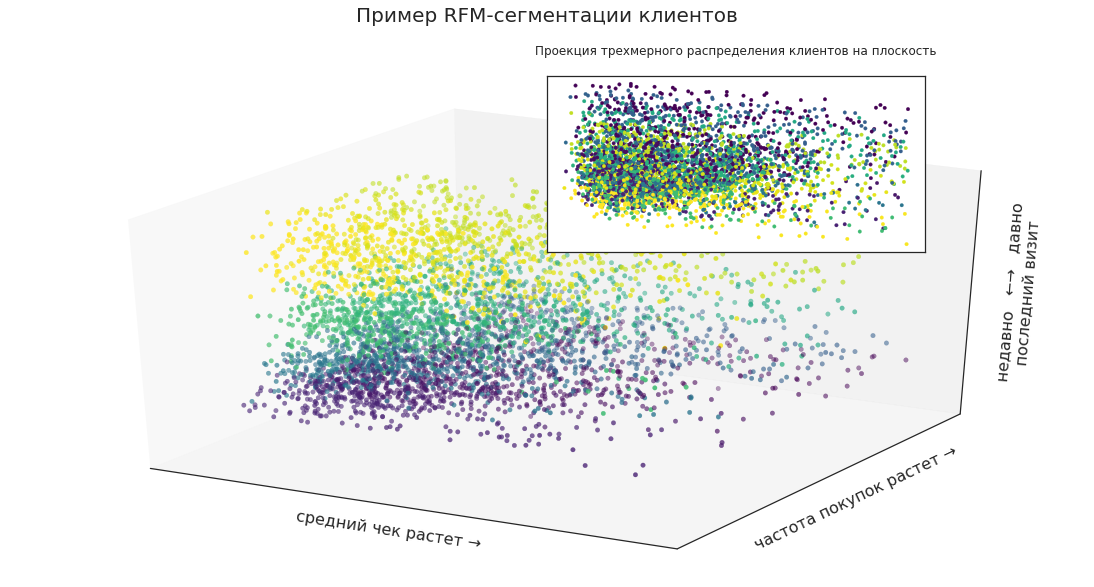
Cela vous permet de voir visuellement l'emplacement de certains groupes dans la masse totale des clients, leurs proportions et la dynamique des changements.
Projetez maintenant la distribution tridimensionnelle des segments sur le plan. Les clients peuvent être divisés par les revenus apportés par l'entreprise pour inclure les plus rentables dans les campagnes marketing, mais cela suffira-t-il pour une planification efficace?
Même dans de telles données, l'algorithme d'apprentissage automatique trouve des possibilités supplémentaires: il divise les clients en nouveaux grands groupes. Vous pouvez analyser cette partition pour savoir pourquoi l'algorithme a divisé les clients de cette façon. Par exemple, certains clients très rentables sont des experts qui accompagnent leurs clients dans leurs achats et utilisent leurs cartes de réduction; certains partagent activement leurs cartes avec des amis et des connaissances. Autrement dit, après la première utilisation de ML, vous pouvez obtenir des informations supplémentaires sur vos clients sur la base des mêmes données.
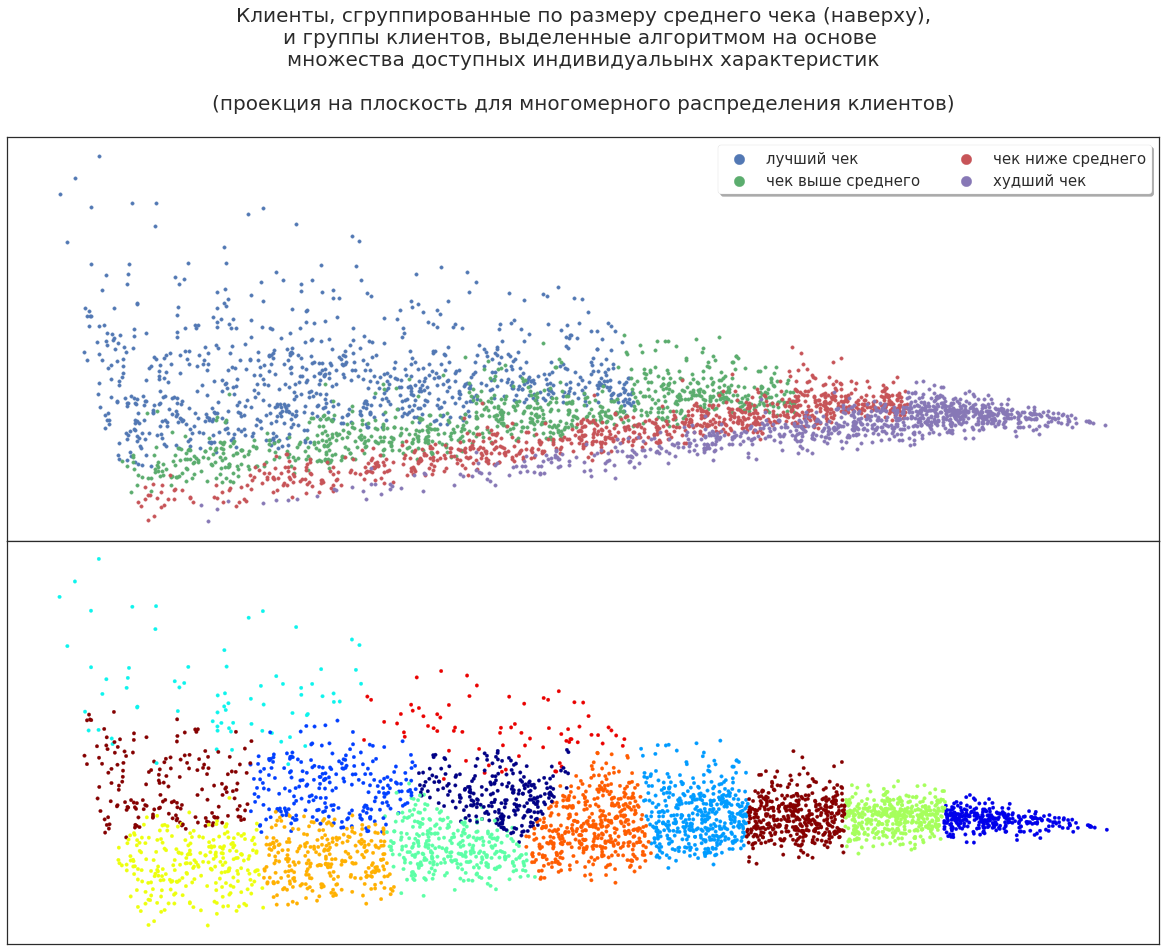
Développons l'ensemble des caractéristiques des clients: ajoutons le sexe, l'âge, les comportements, etc. Comment maintenant l'algorithme répartira-t-il les acheteurs?
Par exemple, il existe un groupe qui couvre à la fois les meilleurs clients (les plus rentables) et leurs «voisins», ce qui rapporte moins de profit. La raison pour laquelle l'algorithme a attribué ce groupe est une question pour l'analyste. Peut-être que ces clients avec une stimulation supplémentaire afficheront une plus grande rentabilité. Ou, au contraire, ces clients ne sont pas particulièrement prometteurs, et l'augmentation de la rentabilité a été une déviation aléatoire - les stimuler est en outre inutile. Différentes théories peuvent être avancées, mais elles doivent être vérifiées expérimentalement.
Planification de l'entrepôt - prévision des ventes
De plus, le projet a plusieurs options de développement. Par exemple, vous pouvez prévoir les achats dans un magasin particulier pour la période à venir. L'administrateur du magasin pourra alors commander à temps les marchandises nécessaires auprès de l'entrepôt central.
L'analyse des achats dans un point de vente particulier aidera à formuler l'affichage des marchandises sur les vitrines. Par exemple, si de nombreux acheteurs masculins viennent au magasin, le rayon des produits masculins ne doit pas être placé dans le coin le plus éloigné.
N'oubliez pas la soi-disant cannibalisation des magasins. Autrement dit, si deux points de vente du même réseau sont à proximité (par exemple, à des extrémités différentes de la même rue), l'un d'eux peut éloigner les clients et le second restera inactif. Vous pouvez construire un modèle qui suivra de tels phénomènes et en signalera le fonctionnement.
***
En bref, l'apprentissage automatique est un outil puissant qui peut faire beaucoup. Souvent, lors de la création de modèles, des modèles non évidents sont révélés que même les utilisateurs professionnels ne connaissaient pas. Cependant, la qualité du modèle dépend beaucoup de la qualité et de la quantité des données.
Analystes de la Direction du développement et de la mise en œuvre des logiciels, Jet Infosystems