En tant qu'ingénieur d'infrastructure dans l'équipe de développement de la plateforme cloud , j'ai eu l'opportunité de travailler avec de nombreux systèmes de stockage distribués, y compris ceux qui sont indiqués dans l'en-tête. Il semble qu'il y ait une compréhension de leurs forces et de leurs faiblesses, et je vais essayer de partager mes réflexions avec vous à ce sujet. Pour ainsi dire, voyons qui a la fonction de hachage plus longtemps.

Avertissement: Plus tôt dans ce blog, vous pouvez voir des articles sur GlusterFS. Je n'ai rien à voir avec ces articles. Il s'agit du blog de l'auteur de l'équipe de projet de notre cloud et chacun de ses membres peut raconter son histoire. L'auteur de ces articles est ingénieur de notre groupe opérationnel et il a ses propres tâches et son expérience, qu'il a partagées. Veuillez en tenir compte si vous constatez soudainement une différence d'opinion. J'en profite pour transmettre mes salutations à l'auteur de ces articles!
Ce qui sera discuté
Parlons des systèmes de fichiers qui peuvent être construits sur la base de GlusterFS et CephFS. Nous allons discuter de l'architecture de ces deux systèmes, les regarder sous des angles différents, et à la fin je risquerai même de tirer des conclusions. Les autres fonctionnalités de Ceph, telles que RBD et RGW, ne seront pas affectées.
Terminologie
Pour rendre l'article complet et compréhensible pour tout le monde, regardons la terminologie de base des deux systèmes:
Terminologie Ceph:
RADOS (Reliable Autonomic Distributed Object Store) est un stockage d'objets autonome, qui est la base du projet Ceph.
CephFS , RBD (RADOS Block Device), RGW (RADOS Gateway) sont des gadgets de haut niveau pour RADOS qui fournissent aux utilisateurs finaux diverses interfaces avec RADOS.
Plus précisément, CephFS fournit une interface de système de fichiers compatible POSIX. En fait, les données CephFS sont stockées dans RADOS.
OSD (Object Storage Daemon) est un processus desservant un stockage disque / objet séparé dans un cluster RADOS.
RADOS Pool (pool) - plusieurs OSD unis par un ensemble commun de règles, comme, par exemple, une politique de réplication. Du point de vue de la hiérarchie des données, un pool est un répertoire ou un espace de noms séparé (plat, sans sous-répertoires) pour les objets.
PG (Placement Group) - Je présenterai le concept de PG un peu plus tard, dans le contexte, pour une meilleure compréhension.
RADOS étant la base sur laquelle CephFS est construit, j'en parlerai souvent et cela s'appliquera automatiquement à CephFS.
Terminologie de GlusterFS (ci-après gl):
La brique est un processus desservant un seul disque, un analogue de l'OSD dans la terminologie RADOS.
Volume - volume dans lequel les briques sont unies. Tom est un analogue de pool dans RADOS, il a également une topologie de réplication spécifique entre les briques.
Distribution des données
Pour le rendre plus clair, considérons un exemple simple qui peut être implémenté par les deux systèmes.
La configuration à utiliser comme exemple:
- 2 serveurs (S1, S2) avec 3 disques de volume égal (sda, sdb, sdc) dans chacun;
- volume / pool avec réplication 2.
Les deux systèmes nécessitent au moins 3 serveurs pour un fonctionnement normal. Mais nous fermons les yeux sur ce point, car ce n'est qu'un exemple pour un article.
Dans le cas de gl, ce sera un volume distribué-répliqué composé de 3 groupes de réplication:

Chaque groupe de réplication est composé de deux briques sur des serveurs différents.
En fait, il s'avère que le volume combine les trois RAID-1.
Lorsque vous le montez, obtenez le système de fichiers souhaité et commencez à y écrire des fichiers, vous constaterez que chaque fichier que vous écrivez appartient à l'un de ces groupes de réplication dans son ensemble.
La distribution des fichiers entre ces groupes distribués se fait par DHT (Distributed Hash Tables), qui est essentiellement une fonction de hachage (nous y reviendrons plus tard).
Sur le "diagramme", cela ressemblera à ceci:
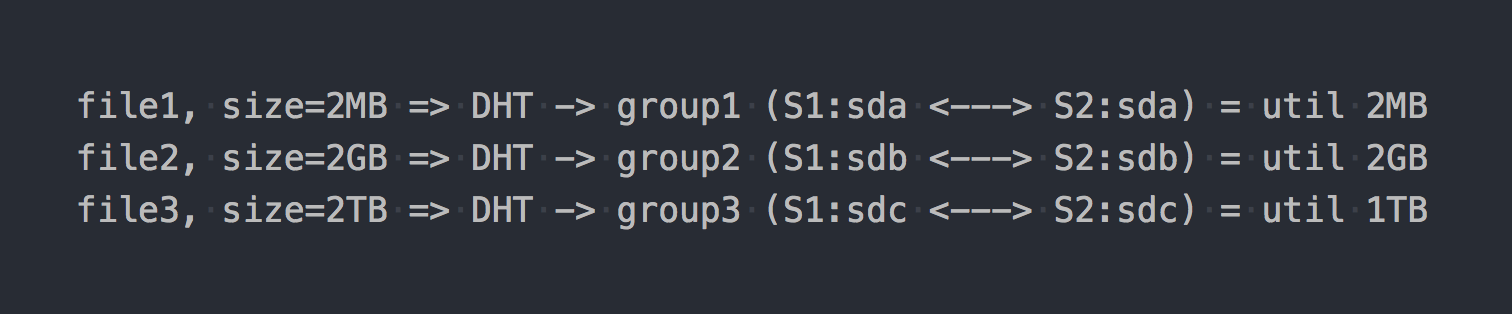
Comme si les premières caractéristiques architecturales étaient déjà manifestées:
- placer en groupes est inégalement éliminé, cela dépend de la taille des fichiers;
- lors de l'écriture d'un fichier, IO va à un seul groupe, les autres sont inactifs;
- Vous ne pouvez pas obtenir l'IO de l'intégralité du volume lors de l'écriture d'un seul fichier;
- s'il n'y a pas assez d'espace dans le groupe pour écrire le fichier, vous obtiendrez une erreur, le fichier ne sera pas écrit et ne sera pas redistribué à un autre groupe.
Si vous utilisez d'autres types de volumes, par exemple, Distributed-Striped-Replicated ou même Dispersed (Erasure Coding), alors seule la mécanique de distribution des données au sein d'un groupe changera fondamentalement. DHT décomposera également les fichiers entièrement dans ces groupes, et à la fin nous aurons tous les mêmes problèmes. Oui, si le volume se compose d'un seul groupe ou si vous avez tous les fichiers de la même taille, il n'y aura pas de problème. Mais nous parlons de systèmes normaux, sous des centaines de téraoctets de données, y compris des fichiers de différentes tailles, nous pensons donc qu'il y a un problème.
Voyons maintenant CephFS. La RADOS mentionnée ci-dessus entre en scène. Dans RADOS, chaque disque est servi par un processus distinct - OSD. Sur la base de notre configuration, nous n'en obtenons que 6, 3 sur chaque serveur. Ensuite, nous devons créer un pool pour les données et définir le nombre de PG et le facteur de réplication des données dans ce pool - dans notre cas 2.
Disons que nous avons créé un pool avec 8 PG. Ces PG seront distribués à peu près également sur l'OSD:
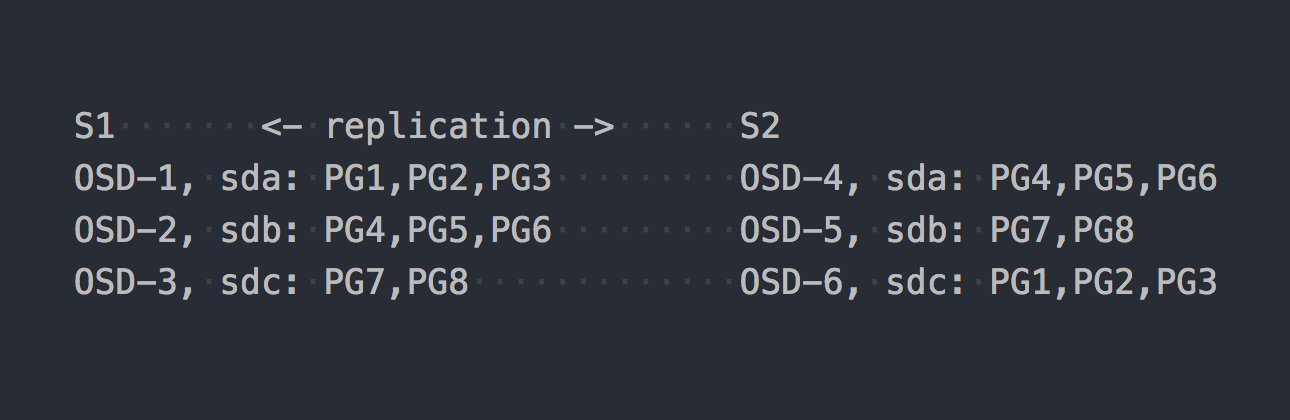
Il est temps de préciser que PG est un groupe logique qui combine un certain nombre d'objets. Depuis que nous avons défini le fait de réplication 2, chaque PG a une réplique sur un autre OSD sur un autre serveur (par défaut). Par exemple, PG1, qui est sur OSD-1 sur le serveur S1, a un jumeau sur S2 sur OSD-6. Dans chaque paire de PG (ou triple, si la réplication 3) est PRIMARY PG, qui est en cours d'enregistrement. Par exemple, PRIMARY for PG4 est sur S1, mais PRIMARY for PG3 est sur S2.
Maintenant que vous savez comment fonctionne RADOS, nous pouvons passer à l'écriture de fichiers dans notre tout nouveau pool. Bien que RADOS soit un stockage à part entière, il n'est pas possible de le monter en tant que système de fichiers ou de l'utiliser comme périphérique de bloc. Pour y écrire directement des données, vous devez utiliser un utilitaire ou une bibliothèque spéciale.
Nous écrivons les trois mêmes fichiers que dans l'exemple ci-dessus:
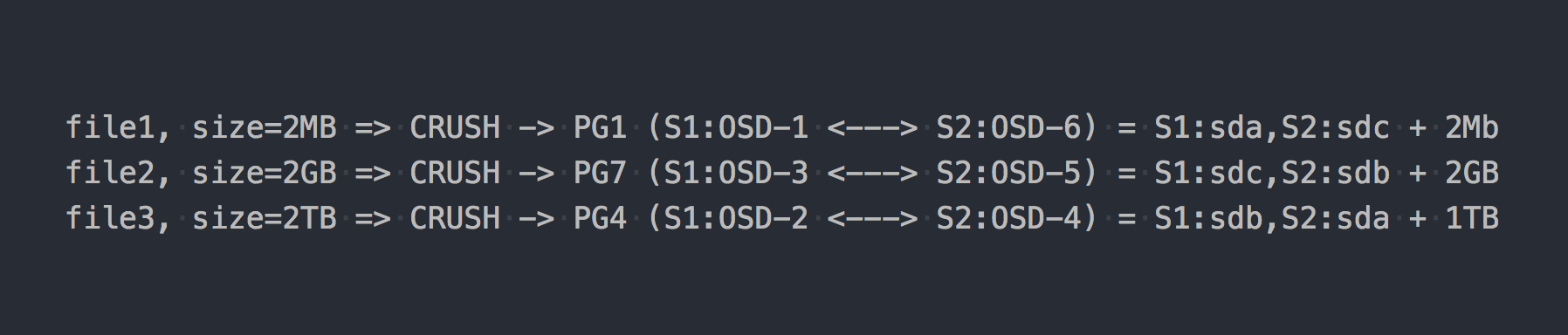
Dans le cas de RADOS, tout est devenu en quelque sorte plus compliqué, d'accord.
Puis CRUSH (réplication contrôlée sous hachage évolutif) est apparu dans la chaîne. CRUSH est l'algorithme sur lequel repose RADOS (nous y reviendrons plus tard). Dans ce cas particulier, en utilisant cet algorithme, il est déterminé où le fichier doit être écrit dans quelle PG. Ici CRUSH remplit la même fonction que DHT dans gl. À la suite de cette distribution pseudo-aléatoire de fichiers sur PG, nous avons eu les mêmes problèmes que gl, uniquement sur un schéma plus complexe.
Mais j'ai délibérément gardé le silence sur un point important. Presque personne n'utilise RADOS sous sa forme pure. Pour un travail pratique avec RADOS, les couches suivantes ont été développées: RBD, CephFS, RGW, que j'ai déjà mentionné.
Tous ces traducteurs (clients RADOS) fournissent une interface client différente, mais ils sont similaires dans leur travail avec RADOS. La similitude la plus importante est que toutes les données qui les traversent sont coupées en morceaux et placées dans RADOS en tant qu'objets RADOS séparés. Par défaut, les clients officiels coupent le flux d'entrée en morceaux de 4 Mo. Pour RBD, la taille de bande peut être définie lors de la création du volume. Dans le cas de CephFS, il s'agit de l'attribut (xattr) du fichier et peut être géré au niveau des fichiers individuels ou pour tous les fichiers de catalogue. Eh bien, RGW a également un paramètre correspondant.
Supposons maintenant que nous empilions CephFS au-dessus du pool RADOS présenté dans l'exemple précédent. Désormais, les systèmes en question sont sur un pied d'égalité et offrent une interface d'accès aux fichiers identique.
Si nous réécrivons nos fichiers de test sur le tout nouveau CephFS, nous trouverons une distribution des données complètement différente et presque uniforme sur l'OSD. Par exemple, le fichier 2 de 2 Go sera divisé en 512 morceaux, qui seront répartis sur différentes PG et, par conséquent, sur différents OSD presque uniformément, et cela résout pratiquement les problèmes de distribution de données décrits ci-dessus.
Dans notre exemple, seulement 8 PG sont utilisés, bien qu'il soit recommandé d'avoir ~ 100 PG sur un OSD. Et vous avez besoin de 2 pools pour que CephFS fonctionne. Vous avez également besoin de quelques démons de service pour que RADOS fonctionne en principe. Ne pensez pas que tout est si simple, j'en omet spécifiquement beaucoup, pour ne pas sortir de l'essence.
Alors maintenant, CephFS semble plus intéressant, non? Mais je n'ai pas mentionné un autre point important, cette fois à propos de gl. Gl a également un mécanisme pour couper des fichiers en morceaux et exécuter ces morceaux via DHT. Le soi-disant sharding (Sharding).
Cinq minutes d'histoire
Le 21 avril 2016, l'équipe de développement de Ceph a publié "Jewel", la première version de Ceph dans laquelle CephFS est considéré comme stable.
Ce sont maintenant tous des cris de gauche et de droite à propos de CephFS! Et il y a 3-4 ans, l'utiliser serait au moins une décision douteuse. Nous avons cherché d'autres solutions, et gl avec l'architecture décrite ci-dessus n'était pas bonne. Mais nous y croyions plus qu'en CephFS, et attendions le partage, qui se préparait pour la sortie.
Et ici, c'est le jour X:
4 juin 2015 - La communauté Gluster a annoncé aujourd'hui la disponibilité générale du logiciel de stockage défini par logiciel ouvert GlusterFS 3.7.
3.7 - la première version de gl, dans laquelle le sharding a été annoncé comme une opportunité expérimentale. Ils avaient presque un an avant la sortie stable de CephFS afin de prendre pied sur le podium ...
Donc sharding signifie. Comme tout dans gl, cela est implémenté dans un traducteur séparé, qui se tenait au-dessus du DHT (également traducteur) sur la pile. Puisqu'il est supérieur à DHT, DHT reçoit des fragments prêts à l'emploi à l'entrée et les distribue parmi les groupes de réplication sous forme de fichiers normaux. Le partage est activé au niveau du volume individuel. La taille du fragment peut être définie, par défaut - 4 Mo, comme les lotions Ceph.
Lorsque j'ai effectué les premiers tests, j'étais ravi! J'ai dit à tout le monde que gl est maintenant la chose la plus importante et maintenant nous allons vivre! Lorsque le partage est activé, l'enregistrement d'un fichier se fait en parallèle avec différents groupes de réplication. La décompression après la compression «en écriture» peut être incrémentielle au niveau du fragment. En présence de prises de vue en cache ici aussi, tout devient bon et des fragments séparés sont déplacés vers le cache, et non les fichiers entiers. En général, je me réjouissais, car il semblait qu'il avait entre les mains un instrument très cool.
Il restait à attendre les premières corrections de bugs et le statut de "prêt pour la production". Mais tout s'est avéré moins rose ... Afin de ne pas étirer l'article avec une liste de bugs critiques liés au sharding, apparaissant de temps en temps dans les prochaines versions, je ne peux que dire que le dernier "problème majeur" avec la description suivante:
L'extension d'un volume gluster qui est fragmenté peut endommager les fichiers. Les volumes éclatés sont généralement utilisés pour les images de machine virtuelle, si ces volumes sont étendus ou éventuellement contractés (c'est-à-dire ajouter / supprimer des briques et rééquilibrer), il y a des rapports d'images corrompues.
a été fermé dans la version 3.13.2 du 20 janvier 2018 ... ce n'est peut-être pas le dernier?
Commentaire sur l'un de nos articles à ce sujet, pour ainsi dire, de première main.
RedHat dans sa documentation pour l'actuel RedHat Gluster Storage 3.4 note que le seul cas de partage qu'ils prennent en charge est le stockage pour les disques VM.
Sharding a un cas d'utilisation pris en charge: dans le contexte de la fourniture de Red Hat Gluster Storage en tant que domaine de stockage pour Red Hat Enterprise Virtualization, afin de fournir un stockage pour les images de machine virtuelle en direct. Notez que le partitionnement est également une exigence pour ce cas d'utilisation, car il fournit des améliorations de performances significatives par rapport aux implémentations précédentes.
Je ne sais pas pourquoi une telle restriction, mais vous devez admettre que c'est alarmant.
Maintenant j'ai tout ici pour toi
Les deux systèmes utilisent une fonction de hachage pour distribuer de manière pseudo-aléatoire les données sur les disques.
Pour RADOS, cela ressemble à ceci:
PG = pool_id + "." + jenkins_hash(object_name) % pg_coun # eg pool id=5 => pg = 5.1f OSD = crush_hash_based_on_jenkins(PG) # eg pg=5.1f => OSD = 12
Gl utilise le hachage dit cohérent . Chaque brique obtient une "plage dans un espace de hachage 32 bits". Autrement dit, toutes les briques partagent tout l'espace de hachage d'adresse linéaire sans intersection de plages ou de trous. Le client exécute le nom de fichier via la fonction de hachage, puis détermine dans quelle plage de hachage le hachage reçu tombe. Ainsi, la brique est sélectionnée. S'il y a plusieurs briques dans le groupe de réplication, elles ont toutes la même plage de hachage. Quelque chose comme ça:
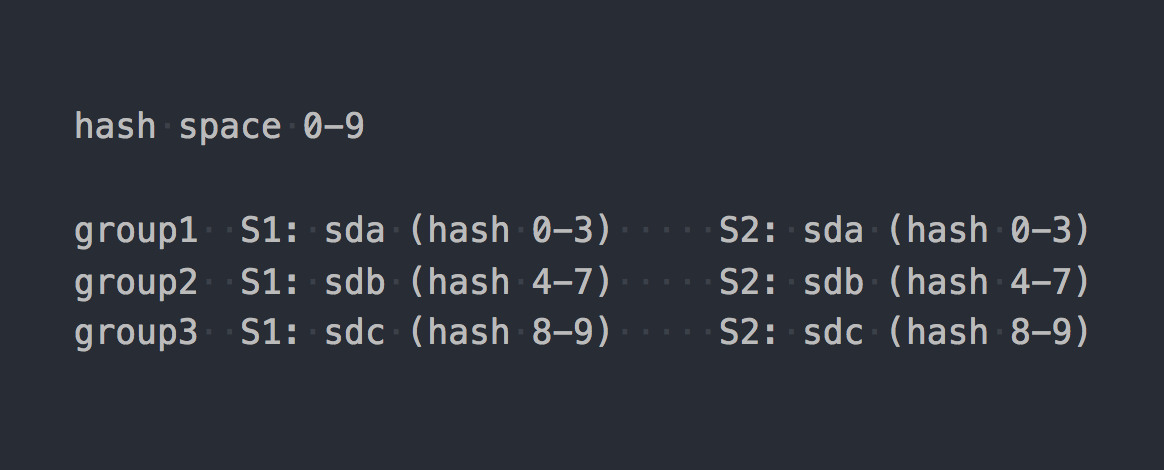
Si nous apportons le travail de deux systèmes à une certaine forme logique, il en résultera quelque chose comme ceci:
file -> HASH -> placement_unit
où placement_unit dans le cas de RADOS est PG, et dans le cas de gl c'est un groupe de réplication de plusieurs briques.
Donc, une fonction de hachage, puis celle-ci distribue, distribue des fichiers, et tout à coup, il s'avère que l'un placement_unit est utilisé plus que l'autre. Telle est la caractéristique fondamentale des systèmes de distribution de hachage. Et nous sommes confrontés à une tâche très courante: déséquilibrer les données.
Gl est capable de reconstruire, mais en raison de l'architecture avec les plages de hachage décrites ci-dessus, vous pouvez exécuter la reconstruction autant que vous le souhaitez, mais aucune plage de hachage (et, par conséquent, les données) ne bougera. Le seul critère de redistribution des plages de hachage est un changement de capacité volumique. Et il vous reste une option: ajouter des briques. Et si nous parlons d'un volume avec réplication, alors nous devons ajouter un groupe de réplication entier, c'est-à-dire deux nouvelles briques dans notre configuration. Après avoir augmenté le volume, vous pouvez commencer la reconstruction - les plages de hachage seront redistribuées en tenant compte du nouveau groupe et les données seront distribuées. Lorsqu'un groupe de réplication est supprimé, les plages de hachage sont allouées automatiquement.
RADOS a toute une voiture de possibilités. Dans un article de Ceph, je me plaignais beaucoup du concept de PG, mais ici, comparant avec gl, bien sûr, RADOS à cheval. Chaque OSD a son propre poids, il est généralement défini en fonction de la taille du disque. À leur tour, les PG sont distribués par OSD en fonction du poids de ce dernier. Tout, alors nous modifions simplement le poids de l'OSD vers le haut ou vers le bas et la PG (avec les données) commence à se déplacer vers d'autres OSD. De plus, chaque OSD a un poids d'ajustement supplémentaire, qui vous permet d'équilibrer les données entre les disques d'un serveur. Tout cela est inhérent à CRUSH. Le principal bénéfice est qu'il n'est pas nécessaire d'augmenter la capacité du pool pour mieux déséquilibrer les données. Et il n'est pas nécessaire d'ajouter des disques en groupes, vous ne pouvez ajouter qu'un seul OSD et une partie de PG y sera transférée.
Oui, il est possible que lors de la création d'un pool, ils n'aient pas créé suffisamment de PG et il s'est avéré que chacune des PG est assez volumineuse, et où qu'elles se déplacent, le déséquilibre restera. Dans ce cas, vous pouvez augmenter le nombre de PG, et ils sont divisés en plus petits. Oui, si le cluster est plein de données, cela fait mal, mais l'essentiel de notre comparaison est qu'il existe une telle opportunité. Maintenant, seule une augmentation du nombre de PG est autorisée et avec cela, vous devez être plus prudent, mais dans la prochaine version de Ceph - Nautilus, il y aura un soutien pour réduire le nombre de PG (fusion de pg).
Réplication de données
Nos pools et volumes de test ont un facteur de réplication de 2. Fait intéressant, les systèmes en question utilisent différentes approches pour atteindre ce nombre de répliques.
Dans le cas de RADOS, le schéma d'enregistrement ressemble à ceci:
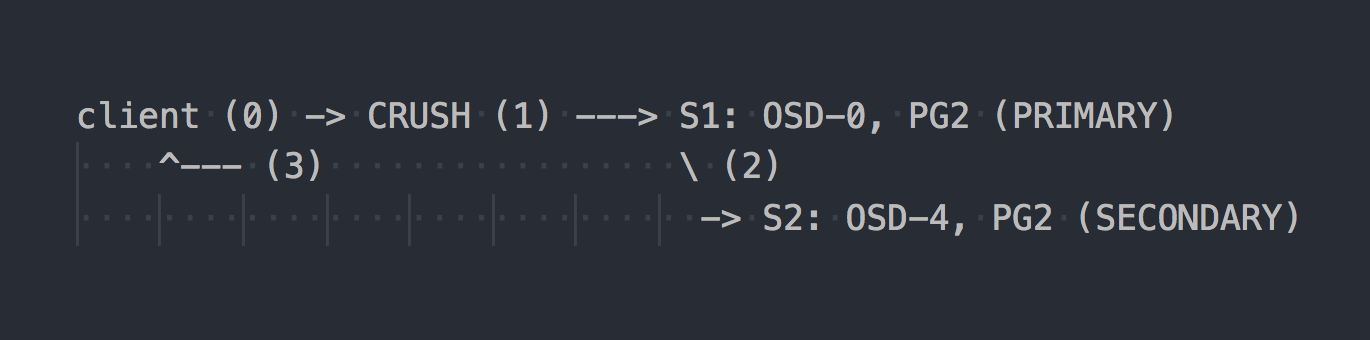
Le client connaît la topologie de l'ensemble du cluster, utilise CRUSH (étape 0) pour sélectionner une PG spécifique pour l'écriture, écrit sur PRIMARY PG sur OSD-0 (étape 1), puis OSD-0 réplique de manière synchrone les données sur SECONDARY PG (étape 2), et seulement après étape 2 réussie / échouée, l'OSD confirme / ne confirme pas l'opération au client (étape 3). La réplication des données entre deux OSD est transparente pour le client. Les OSD peuvent généralement utiliser un «cluster» distinct, un réseau plus rapide pour la réplication des données.
Si la réplication triple est configurée, elle s'exécute également de manière synchrone entre OSD PRIMAIRE et deux SECONDAIRES, transparente pour le client ... eh bien, seule cette latence est plus élevée.
Gl fonctionne différemment:
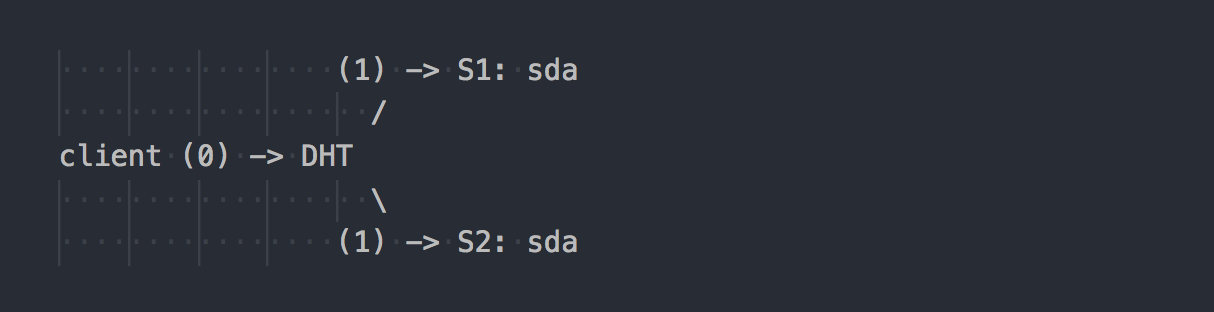
Le client connaît la topologie du volume, utilise DHT (étape 0) pour déterminer la brique souhaitée, puis y écrit (étape 1). Tout est simple et clair. Mais ici, nous rappelons que toutes les briques du groupe de réplication ont la même plage de hachage. Et cette caractéristique mineure fait toute la fête. Le client écrit en parallèle sur toutes les briques qui ont une plage de hachage appropriée.
Dans notre cas, avec double réplication, le client effectue un double enregistrement en parallèle sur deux briques différentes. Au cours de la triple réplication, un triple enregistrement sera effectué, respectivement, et 1 Mo de données se transformeront approximativement en 3 Mo de trafic réseau du client vers le côté des serveurs gl. D'accord, les concepts de systèmes sont perpendiculaires.
Dans un tel schéma, plus de travail est assigné au client gl, et, par conséquent, il a besoin de plus de CPU, eh bien, j'ai déjà dit à propos du réseau.
La réplication est effectuée par le traducteur AFP (réplication automatique de fichiers) - Un xlator côté client qui effectue une réplication synchrone. Réplique les écritures sur toutes les briques de la réplique → Utilise un modèle de transaction.
Si nécessaire, synchronisez les répliques dans le groupe (guérison), par exemple, après une indisponibilité temporaire d'une brique, les démons gl le font par eux-mêmes en utilisant l'AFP intégré, transparent pour les clients et sans leur participation.
Il est intéressant de noter que si vous ne travaillez pas via le client gl natif, mais écrivez via le serveur NFS intégré dans gl, nous obtiendrons le même comportement que RADOS. Dans ce cas, AFP sera utilisé dans les démons gl pour répliquer les données sans intervention du client. Mais le NFS intégré est sécurisé dans gl v4, et si vous voulez ce comportement, il est recommandé d'utiliser NFS-Ganesha.
Soit dit en passant, en raison de comportements si différents lors de l'utilisation de NFS et du client natif, vous pouvez voir des indicateurs de performances complètement différents.
Avez-vous le même cluster, uniquement "sur le genou"?
Je vois souvent sur Internet des discussions sur toutes sortes de configurations de rotule, où un cluster de données est construit à partir de ce qui est à portée de main. Dans ce cas, une solution basée sur RADOS peut vous donner plus de liberté lors du choix de vos disques. Dans RADOS, vous pouvez ajouter des lecteurs de presque toutes les tailles. Chaque disque aura un poids correspondant à sa taille (généralement) et les données seront réparties sur les disques presque proportionnellement à leur poids. Dans le cas de gl, il n'y a pas de concept de «disques séparés» dans les volumes avec réplication. Les disques sont ajoutés par paires à double réplication ou triples à triple. S'il existe des disques de tailles différentes dans un groupe de réplication, vous exécuterez alors un emplacement sur le plus petit disque du groupe et déploierez la capacité des grands disques. Dans un tel schéma, gl supposera que la capacité d'un groupe de réplication est égale à la capacité du plus petit disque du groupe, ce qui est logique. En même temps, il est permis d'avoir des groupes de réplication composés de disques de tailles différentes - des groupes de tailles différentes. Les groupes plus importants peuvent recevoir une plus grande plage de hachage par rapport aux autres groupes et, par conséquent, recevoir plus de données.
Nous vivons avec Ceph depuis la cinquième année. Nous avons commencé avec des disques du même volume, maintenant nous introduisons des disques plus volumineux. Avec Ceph, vous pouvez retirer le disque et le remplacer par un autre plus grand ou légèrement plus petit sans aucune difficulté architecturale. Avec gl, tout est plus compliqué - a sorti un disque de 2 To - mettez le même, s'il vous plaît. Eh bien, ou retirer l'ensemble du groupe dans son ensemble, ce qui n'est pas très bon, d'accord.
Basculement
Nous connaissions déjà un peu l'architecture des deux solutions et nous pouvons maintenant parler de la façon de vivre avec et des fonctionnalités lors de la maintenance.
Supposons que sda sur s1 soit refusé - une chose courante.
Dans le cas de gl:
- une copie des données sur le disque actif restant dans le groupe n'est pas automatiquement redistribuée aux autres groupes;
- jusqu'à ce que le disque soit remplacé, il ne reste qu'une copie des données;
- lors du remplacement d'un disque défectueux par un nouveau, la réplication est effectuée à partir d'un disque de travail vers un nouveau (1 sur 1).
C'est comme servir une étagère avec plusieurs RAID-1. Oui, avec une triple réplication, si un disque tombe en panne, il ne reste plus une copie, mais deux, mais cette approche présente néanmoins de sérieux inconvénients, et je vais les montrer avec un bon exemple avec RADOS.
Supposons que nous ayons échoué sda sur S1 (OSD-0) - une chose courante:
- Les PG qui étaient sur OSD-0 seront automatiquement remappées vers d'autres OSD après 10 minutes (par défaut). Dans notre exemple, sur OSD 1 et 2. S'il y avait plus de serveurs, alors sur un plus grand nombre d'OSD.
- Les PG qui stockent la deuxième copie survivante des données les répliqueront automatiquement sur les OSD où les PG restaurées sont transférées. Il s'avère que la réplication plusieurs à plusieurs, pas la réplication un à un comme gl.
- Lorsqu'un nouveau disque est introduit, au lieu d'un disque cassé, certaines PG seront accumulées en fonction de son poids dans le nouvel OSD et les données d'autres OSD seront redistribuées.
Je pense que cela n'a aucun sens d'expliquer les avantages architecturaux de RADOS. Vous ne pouvez pas trembler lorsque vous recevez une lettre disant que le disque est tombé en panne. Et lorsque vous venez travailler le matin, constatez que toutes les copies manquantes ont déjà été restaurées sur des dizaines d'autres OSD ou en cours de traitement. Sur les grands clusters, où des centaines de PG sont réparties sur un tas de disques, la récupération de données d'un OSD peut avoir lieu à des vitesses beaucoup plus élevées que la vitesse d'un disque en raison du fait que des dizaines d'OSD sont impliqués (lecture et écriture). Eh bien, vous ne devez pas non plus oublier l'équilibrage de charge.
Mise à l'échelle
Dans ce contexte, je donnerai probablement le piédestal gl. Dans un article sur Ceph, j'ai déjà écrit sur certaines des complexités de la mise à l'échelle RADOS associées au concept PG. Si l'augmentation de PG avec la croissance du cluster peut encore être ressentie, alors qu'en est-il de Ceph MDS n'est pas clair. CephFS fonctionne au-dessus de RADOS et utilise un pool séparé pour les métadonnées et un processus spécial, le serveur de métadonnées ceph (MDS), pour la maintenance des métadonnées du système de fichiers et la coordination de toutes les opérations avec le FS. Je ne dis pas qu'avoir MDS met fin à l'évolutivité de CephFS, non, d'autant plus que vous pouvez exécuter plusieurs MDS en mode actif-actif. Je veux juste noter que gl est architecturalement dépourvu de tout cela. Il n'a pas d'équivalent PG, rien de tel que MDS. Gl évolue vraiment parfaitement en ajoutant simplement des groupes de réplication, presque linéairement.
Dans les jours qui ont précédé CephFS, nous avons conçu la solution pour les pétaoctets de données et examiné GL. Ensuite, nous avions des doutes sur l'évolutivité de gl et nous l'avons découvert par le biais de la liste de diffusion. Voici une des réponses (Q: ma question):
J'utilise 60 serveurs chacun a des disques 26x8TB total 1560 disque 16 + 4 volume EC avec 9PB d'espace utilisable.
Q: Utilisez-vous libgfapi ou FUSE ou NFS côté client?
J'utilise FUSE et j'ai près de 1000 clients.
Q: Combien de fichiers avez-vous dans votre volume?
Q: Les fichiers sont plus gros ou plus petits?
J'ai plus de 1 million de fichiers et% 13 du cluster est utilisé, ce qui fait une taille de fichier moyenne de 1 Go.
La taille de fichier minimale / maximale est de 100 Mo / 2 Go. Chaque jour, 10 à 20 To de nouvelles données entrent dans le volume.
Q: À quelle vitesse "ls" fonctionne-t-il)?
Les opérations de métadonnées sont lentes comme vous vous y attendez. J'essaye de ne pas mettre plus de 2-3K fichiers dans un répertoire. Mon cas d'utilisation est pour la sauvegarde / l'archivage, donc je fais rarement des opérations de métadonnées.
Renommer des fichiers
Retour aux fonctions de hachage à nouveau. Nous avons compris comment des fichiers spécifiques sont acheminés vers des disques spécifiques, et maintenant la question devient pertinente, mais que se passera-t-il lors du changement de nom des fichiers?
Après tout, si nous changeons le nom du fichier, le hachage en son nom changera également, ce qui signifie la place de ce fichier sur un autre disque (dans une plage de hachage différente) ou sur une autre PG / OSD en cas de RADOS. Oui, nous pensons correctement, et ici, sur deux systèmes, tout est à nouveau perpendiculaire.
Dans le cas de gl, lorsque vous renommez un fichier, le nouveau nom est exécuté via une fonction de hachage, une nouvelle brique est définie et un lien spécial est créé sur celle-ci vers l'ancienne brique, où le fichier reste comme avant. Topovka, c'est ça? Pour que les données se déplacent vraiment vers un nouvel endroit, et que le client n'a pas cliqué sur le lien inutilement, vous devez faire une rébellion.
Mais RADOS n'a généralement pas de méthode pour renommer les objets simplement en raison de la nécessité de leur déplacement ultérieur. Il est proposé d'utiliser une copie équitable pour renommer, ce qui entraîne un mouvement synchrone de l'objet. Et CephFS, qui fonctionne au-dessus de RADOS, a un atout dans sa manche sous la forme d'un pool de métadonnées et de MDS. La modification du nom de fichier n'affecte pas le contenu du fichier dans le pool de données.
Réplication 2.5
Gl a une fonctionnalité très intéressante que je voudrais mentionner séparément. Tout le monde comprend que la réplication 2 n'est pas une configuration fiable, mais néanmoins elle a lieu périodiquement pour être tout à fait justifiée. Pour vous protéger contre le split-brain dans de tels schémas et pour garantir la cohérence des données, gl vous permet de créer des volumes avec la réplique 2 et un arbitre supplémentaire. L'arbitre est applicable pour la réplication de 3 ou plus. Il s'agit de la même brique du groupe que les deux autres, mais elle ne crée en fait qu'une structure de fichiers à partir de fichiers et de répertoires. Les fichiers sur une telle brique sont de taille nulle, mais leurs attributs étendus du système de fichiers (attributs étendus) sont conservés en état synchronisé avec les fichiers de taille normale dans la même réplique. Je pense que l'idée est claire. Je pense que c'est une bonne opportunité.
Le seul moment ... la taille de l'emplacement dans le groupe de réplication est déterminée par la taille de la plus petite brique, ce qui signifie que l'arbitre doit glisser un disque au moins de la même taille que le reste du groupe. Pour ce faire, il est recommandé de créer des LV minces (fines) fictives, de grandes tailles, afin de ne pas utiliser un vrai disque.
Et les clients?
L'API native des deux systèmes est implémentée sous la forme des bibliothèques libgfapi (gl) et libcephfs (CephFS). Des liaisons pour les langues populaires sont également disponibles. En général, avec les bibliothèques, tout est à peu près aussi bon. Le NFS-Ganesha omniprésent prend en charge les deux bibliothèques en tant que FSAL, ce qui est également la norme. Qemu prend également en charge l'API native gl via libgfapi.
Mais fio (Flexible I / O Tester) prend en charge libgfapi depuis longtemps et avec succès, mais il ne prend pas en charge libcephfs. C'est un plus, car utiliser fio est vraiment sympa pour tester gl directement. En travaillant uniquement depuis l'espace utilisateur via libgfapi, vous obtiendrez tout ce que gl peut faire de gl.
Mais si nous parlons du système de fichiers POSIX et de la façon de le monter, alors gl ne peut proposer que le client FUSE et l'implémentation CephFS dans le noyau en amont. Il est clair que dans le module du noyau, vous pouvez faire une telle astuce que FUSE affichera de meilleures performances. Mais dans la pratique, FUSE est toujours une surcharge pour le changement de contexte. J'ai personnellement vu plus d'une fois comment FUSE a plié un serveur à double socket avec des CS uniquement.
D'une manière ou d'une autre, Linus a déclaré:
Système de fichiers de l'espace utilisateur? Le problème est là. Depuis toujours. Les gens qui pensent que les systèmes de fichiers de l'espace utilisateur sont réalistes pour tout, mais les jouets sont tout simplement malavisés.
Les développeurs de Gl, au contraire, pensent que FUSE est cool. On dit que cela donne plus de flexibilité et se détache des versions du noyau. Quant à moi, ils utilisent FUSE car gl n'est pas une question de vitesse. D'une certaine manière, c'est écrit - eh bien, c'est normal, et s'embêter avec l'implémentation dans le noyau est vraiment étrange.
Performances
Il n'y aura pas de comparaisons).
C'est trop compliqué. Même sur une configuration identique, il est trop difficile de réaliser des tests objectifs. Quoi qu'il en soit, il y aura quelqu'un dans les commentaires qui donnera 100500 paramètres qui «accélèrent» l'un des systèmes et disent que les tests sont des conneries. Par conséquent, si vous êtes intéressé, testez-vous, s'il vous plaît.
Conclusion
RADOS et CephFS, en particulier, sont une solution plus complexe à la fois dans la compréhension, la configuration et la maintenance.
Mais personnellement, j'aime l'architecture de RADOS et son fonctionnement sur CephFS plus que sur GlusterFS. Plus de poignées (PG, poids OSD, hiérarchie CRUSH, etc.), les métadonnées CephFS augmentent la complexité, mais donnent plus de flexibilité et rendent cette solution plus efficace, à mon avis.
Ceph est beaucoup mieux adapté aux critères SDS actuels et me semble plus prometteur. Mais c'est mon avis, qu'en pensez-vous?