
Il y a généralement un problème avec la base de connaissances de l'entreprise pour les développeurs - cela se transforme en vide, car il n'y a pas de motivation pour le remplir soit avec une personne responsable, soit dans un balcon rempli de choses provenant d'un appartement soviétique, tout le monde contribue, mais ils écrivent au hasard, les informations deviennent rapidement obsolètes, et il n'a pas toujours le temps de se mettre à jour.
Comment éviter cela, ou au moins réduire les coûts possibles? Comment rendre votre base d'entreprise chaude et lumineuse? Je vais essayer de répondre.
Documentation sur le style de collaboration
Il existe une telle approche, la documentation collaborative, elle est apparue à l'origine dans le domaine de la médecine, lorsque la décision de poser un diagnostic est prise collectivement par le patient et plusieurs médecins.
Un exemple frappant dans le domaine de l'informatique est Google Docs, Wiki, Github, tout système qui a des conventions internes et la capacité de travailler ensemble sur un projet.
L'idée est d'inclure les développeurs, les experts, les critiques dans les travaux sur la documentation le plus tôt possible, afin d'identifier ensemble les lacunes.
Pourquoi est-ce même nécessaire?

Premièrement, la réduction du facteur bus est un goulot d'étranglement dans la connaissance des entreprises, où le nombre de détenteurs de connaissances tend à l'unité. Vous devez transférer ces connaissances de la tête du développeur, des tableaux blancs, des billets, des conversations dans la cuisine dans un seul espace afin que tout le monde puisse travailler avec eux et contribuer.
Deuxièmement, pour simplifier l'entrée des nouveaux venus dans les projets, ce qui est particulièrement important pour les équipes distribuées et les équipes avec un certain nombre de développeurs d'externalisation, ainsi que pour les entreprises qui ont un domaine d'activité très spécifique, la chance de trouver un spécialiste tout fait est nulle.
Troisièmement, pour la formation d'une solide culture d'entreprise, la transparence "pas dans les mots". Un développeur dans un tel environnement comprend clairement les points de croissance professionnelle, quelles autres technologies il peut essayer dans l'entreprise, ce qu'il faut apprendre.
Que faire?
La documentation au sein de la base de connaissances d'entreprise peut être écrite par n'importe quel membre de l'équipe, cette opportunité doit être simplifiée pour eux, puis ils se sentiront les propriétaires du résultat - impliqués.
Cependant, vous avez certainement besoin d'une personne qui assumera les fonctions d'un architecte de l'information - définissez des règles uniformes, une structure, une logique, un style, placez correctement les documents dans les espaces.
Ouvrez la possibilité de modifier et de créer des documents aux membres de l'équipe, après avoir préalablement convenu des règles du jeu. Automatisez ces règles au maximum - ne comptez pas sur l'équipe, créez des modèles, étiquetez le contenu automatiquement, configurez le téléchargement depuis le référentiel vers la base de connaissances (je veux d'ailleurs faire un article séparé à ce sujet).

Il est important que les développeurs voient que les documents ne meurent pas dans le wiki d'entreprise.
Un principe important: la définition du fait d'un document interne, c'est le moment où des modifications ou des commentaires y ont été apportés , c'est en fait le moment de la collaboration. C'est sa valeur, ils veulent y passer du temps. Ne pas compléter - cela signifie que le processus de livraison, la mise en œuvre de la recherche est mal organisé ou que l'outil n'est pas pratique.

Les problèmes potentiels de cette approche sont l'accumulation de modifications et de commentaires sous forme de boule de neige, il est difficile de les suivre, des documents en double sont souvent créés.
Pour éviter cela, vous pouvez et devez: A. Définir l'équipe sur un vecteur, un ensemble de règles et compliquer le processus de non-respect (par exemple, nous avons caché le bouton Créer dans Confluence et rendu la sélection du modèle obligatoire). B. Délimiter judicieusement les droits et configurer les processus d'édition de manière pratique pour ceux qui sont responsables de l'architecture de l'information.
Et puis le monde parfait viendra
 Les développeurs n'arrêteront pas de se poser des questions, y compris stupides et répétitives
Les développeurs n'arrêteront pas de se poser des questions, y compris stupides et répétitives . Ils n'apprendront pas à trouver par eux-mêmes toutes les réponses dans la base de connaissances. Nous avons de l'humour interne lorsque, en raison des limites de l'index de recherche Confluence, les développeurs ne peuvent pas trouver quelque chose, ils me demandent en tant qu'architecte de l'information. Nous l'appelons la recherche basée sur Sveta.
Malgré ces limites, la structure même de la base de connaissances, la dénomination unifiée des pages, l'utilisation d'étiquettes les inciteront à rechercher et à créer des connaissances pour qu'elles ne répondent pas, par exemple, à des questions répétitives.
Un autre hack de vie que nous avons appliqué est de toujours inclure un contexte commercial dans les documents, même s'il s'agit d'une description d'une bibliothèque ou d'une classe ou d'une liste de contrôle pour une tâche, il est important de comprendre ce que cela signifie pour le client.
Maintenant pour pratiquer
La prochaine partie portera sur «Comment», quelles fonctionnalités internes de Confluence (oui, nous utilisons la pile Atlassian) peuvent être utilisées pour implémenter ces principes.
Patterns
Nous avons créé des modèles prêts à l'emploi pour différents types de documents que nous écrivons le plus souvent - spécifications techniques, procédures, liste de contrôle. Ils peuvent être configurés dans le panneau de l'espace administrateur. Des modèles sont nécessaires pour que lors de la création d'un document, le développeur ne voit pas de page vierge devant lui, il ait déjà des instructions sur ce qu'il faut écrire dans telle ou telle section. Si vous souhaitez que les documents d'un certain type tombent dans une seule section et que les méta-informations s'affichent (cela est pratique, par exemple, pour décrire les composants d'un produit complexe ou d'un ensemble de microservices selon un schéma), puis créez un plan, c'est comme un modèle à vitesse maximale.
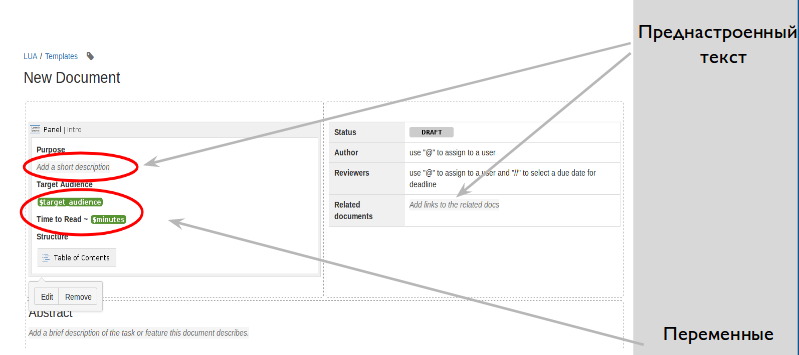
Nous y mettons en place la mise en page, les en-têtes, où il ne reste plus qu'à remplacer quelques mots, un en-tête avec un état, des images, des tableaux, des blocs de code et même des variables.
Les variables sont des éléments de contenu préconfigurés auxquels un autre éditeur de documents doit attacher de l'importance, par exemple, saisir du texte ou effectuer une sélection dans une liste.
Vous pouvez également ajouter des balises au modèle à l'avance, s'il s'agit d'un type étroit du document, vous pouvez mentionner les utilisateurs en tant que réviseurs, par exemple, s'il existe un flux de travail clair par nom, macro Jira et joindre un ticket de Jira. Notre expérience montre que jusqu'à 80% des tâches peuvent être couvertes par des modèles.
Mise en page
Un autre élément important est la création d'une page de destination compréhensible et belle dans l'espace de l'équipe. Pour ce faire, nous utilisons la mise en page et les macros Panel, Column et Section.
Vous trouverez ci-dessous un exemple de l'un de nos espaces d'équipe de développement.

Utilisez des noms de page conviviaux. Comme vous le savez peut-être, Confluence ne prend pas en charge les noms de page identiques dans le même espace. Conservez des noms de page clairs, tels que
Mauvais nom Python
Bon nom Python Styleguide pour l'équipe des services internes
Les étiquettes
Confluence a certaines limites à l'algorithme de recherche lié à l'indexation de contenu. Et pour la base de connaissances de l'entreprise, c'est précisément la recherche et la connectivité qui sont les enjeux les plus urgents. Nous avons un article entier dans la base de connaissances intitulé Comment battre la recherche de Confluence, si vous voulez, je le partagerai dans les commentaires.

Pour surmonter ces limitations, nous utilisons un système d'étiquettes. En fait, ce sont des balises qui marquent le sujet du contenu, et pourquoi elles vous permettent d'agréger le contenu d'un sujet particulier en un seul endroit sous la forme d'une sorte de flux RSS (macro Content by Label). Nous avons donc configuré des index de sujets.
Si vous avez déjà des centaines de pages dans la base de données, alors je vous conseille de commencer par les exercices suivants:
- Consultez la liste de toutes les étiquettes à l'URL suivante https: // <my-host-name> /labels/listlabels-alphaview.action.
- Rechercher tout le contenu non étiqueté avec des étiquettes dans la chaîne de recherche avancée: type: page PAS étiquetteTexte: [a TO z] PAS étiquetteTexte: [0 À 9].
Que pouvez-vous faire maintenant?
- Donnez aux développeurs le droit de modifier, mais à bon escient.
- Pensez à la structure de l'espace de commande, créez une page de destination pratique.
- Personnalisez les modèles.
- Utilisez des étiquettes.
- Allez éditer le document de quelqu'un d'autre ou écrivez un commentaire, faites fonctionner ce document.