Traduction d' architectures de réseaux neuronauxLes algorithmes des réseaux de neurones profonds ont gagné en popularité aujourd'hui, ce qui est largement assuré par une architecture bien pensée. Regardons l'histoire de leur développement au cours des dernières années. Si vous êtes intéressé par une analyse plus approfondie, reportez-vous à
ce travail .
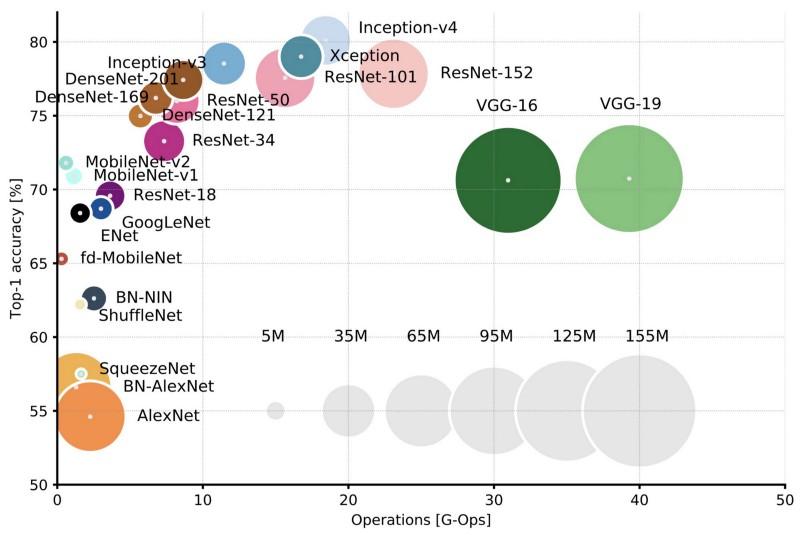 Comparaison des architectures populaires pour la précision d'une seule récolte Top-1 et le nombre d'opérations nécessaires pour un passage direct. Plus de détails ici .
Comparaison des architectures populaires pour la précision d'une seule récolte Top-1 et le nombre d'opérations nécessaires pour un passage direct. Plus de détails ici .Lenet5
En 1994, l'un des premiers réseaux de neurones convolutifs a été développé, qui a jeté les bases de l'apprentissage en profondeur. Cette œuvre pionnière de Yann LeCun, après de nombreuses itérations réussies depuis 1988, s'appelait
LeNet5 !

L'architecture LeNet5 est devenue fondamentale pour l'apprentissage en profondeur, en particulier en termes de distribution des propriétés de l'image à travers l'image. Des convolutions avec des paramètres d'apprentissage ont permis d'utiliser plusieurs paramètres pour extraire efficacement les mêmes propriétés de différents endroits. À cette époque, aucune carte vidéo ne pouvait accélérer le processus d'apprentissage et même les processeurs centraux étaient lents. Par conséquent, l'avantage clé de l'architecture était la possibilité d'enregistrer les paramètres et les résultats des calculs, contrairement à l'utilisation de chaque pixel comme données d'entrée distinctes pour un grand réseau neuronal multicouche. Dans LeNet5, les pixels ne sont pas utilisés dans la première couche, car les images sont fortement corrélées spatialement, donc l'utilisation de pixels individuels comme propriétés d'entrée ne vous permettra pas de tirer parti de ces corrélations.
Caractéristiques de LeNet5:
- Un réseau de neurones convolutifs qui utilise une séquence de trois couches: couches de convolution, couches de mise en commun et couches de non-linéarité -> depuis la publication des travaux de Lekun, c'est peut-être l'une des principales caractéristiques de l'apprentissage profond par rapport aux images.
- Utilise la convolution pour récupérer les propriétés spatiales.
- Sous-échantillonnage en utilisant la moyenne de la carte spatiale.
- Non linéarité sous forme de tangente hyperbolique ou sigmoïde.
- Le classificateur final sous la forme d'un réseau neuronal multicouche (MLP).
- La matrice clairsemée de connectivité entre les couches réduit la quantité de calcul.
Ce réseau neuronal a constitué la base de nombreuses architectures ultérieures et a inspiré de nombreux chercheurs.
Développement
De 1998 à 2010, les réseaux neuronaux étaient en état d'incubation. La plupart des gens n'ont pas remarqué leurs capacités croissantes, bien que de nombreux développeurs aient progressivement perfectionné leurs algorithmes. Grâce à l'apogée des appareils photo pour téléphones portables et à la baisse du prix des appareils photo numériques, de plus en plus de données d'entraînement sont devenues disponibles pour nous. Dans le même temps, les capacités informatiques ont augmenté, les processeurs sont devenus plus puissants et les cartes vidéo sont devenues le principal outil informatique. Tous ces processus ont permis le développement de réseaux de neurones, quoique assez lentement. L'intérêt pour les tâches qui pourraient être résolues à l'aide de réseaux de neurones grandissait, et finalement la situation est devenue évidente ...
Dan ciresan net
En 2010, Dan Claudiu Ciresan et Jurgen Schmidhuber ont publié l'une des premières descriptions de la mise en œuvre de
réseaux neuronaux GPU . Leur travail contenait l'implémentation directe et inverse d'un réseau neuronal à 9 couches sur la
NVIDIA GTX 280 .
Alexnet
En 2012, Alexei Krizhevsky a publié
AlexNet , une version approfondie et étendue de LeNet, qui a remporté une large marge au concours ImageNet.
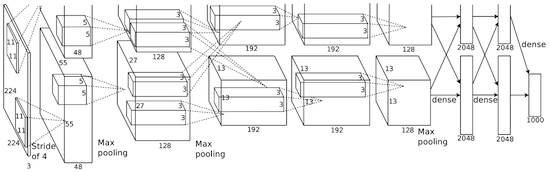
Chez AlexNet, les résultats des calculs LeNet sont mis à l'échelle dans un réseau neuronal beaucoup plus grand, qui est capable d'étudier des objets beaucoup plus complexes et leurs hiérarchies. Caractéristiques de cette solution:
- Utilisation d'unités de rectification linéaire (ReLU) comme non-linéarités.
- L'utilisation de techniques de rejet pour ignorer sélectivement les neurones individuels pendant la formation, ce qui évite la sur-formation du modèle.
- Overlap max pooling, ce qui évite les effets de la moyenne du pooling moyen.
- Utilisation de NVIDIA GTX 580 pour accélérer l'apprentissage.
À ce moment-là, le nombre de cœurs dans les cartes vidéo avait considérablement augmenté, ce qui leur a permis de réduire le temps de formation d'environ 10 fois, et en conséquence, il est devenu possible d'utiliser des jeux de données et des images beaucoup plus grands.
Le succès d'AlexNet a lancé une petite révolution, les réseaux de neurones convolutifs se sont transformés en cheval de bataille de l'apprentissage en profondeur - ce terme signifie désormais «de grands réseaux de neurones qui peuvent résoudre des problèmes utiles».
Surpasser
En décembre 2013, le laboratoire de NYU de Jan Lekun a publié une description d'
Overfeat , une variante d'AlexNet. En outre, l'article décrivait les cadres de délimitation formés, et par la suite de nombreux autres travaux sur ce sujet ont été publiés. Nous pensons qu'il est préférable d'apprendre à segmenter des objets plutôt que d'utiliser des boîtes de délimitation artificielles.
Vgg
Les réseaux
VGG se sont développés à Oxford dans chaque couche convolutionnelle utilisée pour la première fois des filtres 3x3, et ont même combiné ces couches dans une séquence de convolutions.
Cela contredit les principes énoncés dans LeNet, selon lesquels de grandes convolutions ont été utilisées pour extraire les mêmes propriétés d'image. Au lieu des filtres 9x9 et 11x11 utilisés dans AlexNet, des filtres beaucoup plus petits ont commencé à être utilisés, dangereusement proches des convolutions 1x1, que les auteurs de LeNet ont essayé d'éviter, au moins dans les premières couches du réseau. Mais le grand avantage de VGG était la découverte que plusieurs convolutions 3x3 combinées dans une séquence peuvent émuler des champs récepteurs plus grands, par exemple 5x5 ou 7x7. Ces idées seront ensuite utilisées dans les architectures Inception et ResNet.
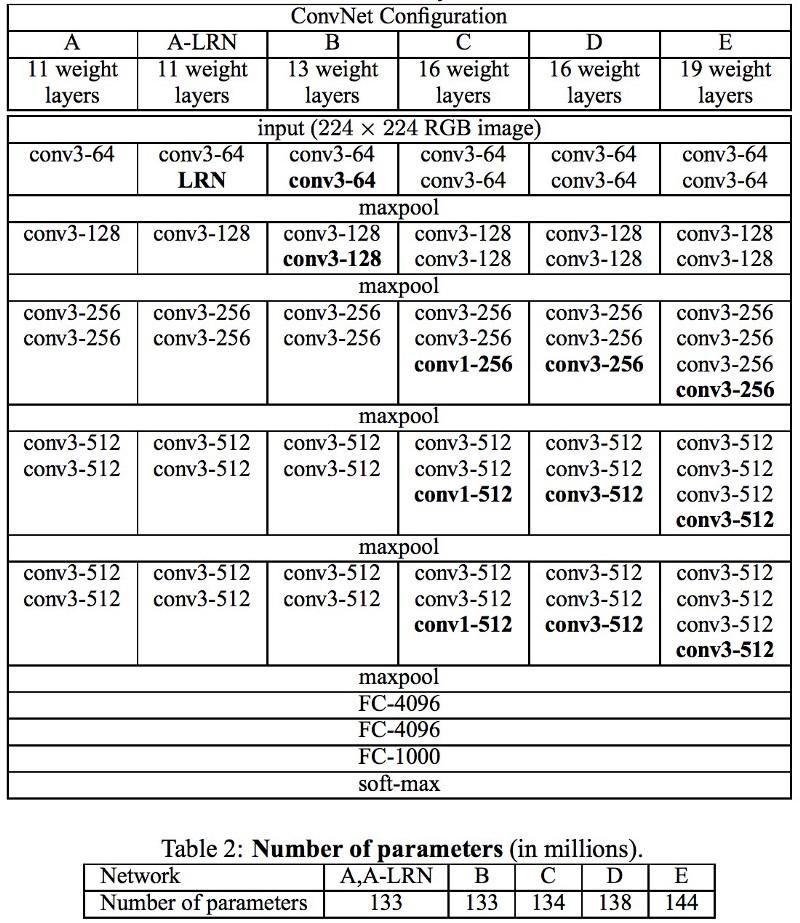
Les réseaux VGG utilisent plusieurs couches convolutionnelles 3x3 pour représenter des propriétés complexes. Faites attention aux blocs 3, 4 et 5 dans VGG-E: pour extraire des propriétés plus complexes et les combiner, 256 × 256 et 512 × 512 séquences de filtre 3 × 3 sont utilisées. Cela équivaut à un grand classificateur convolutionnel 512x512 avec trois couches! Cela nous donne un grand nombre de paramètres et d'excellentes capacités d'apprentissage. Mais il était difficile d'apprendre de tels réseaux; j'ai dû les diviser en plus petits, en ajoutant des couches une par une. La raison en était le manque de moyens efficaces pour régulariser les modèles ou certaines méthodes pour limiter un grand espace de recherche, ce qui est favorisé par de nombreux paramètres.
VGG dans de nombreuses couches utilise un grand nombre de propriétés, donc la formation était
coûteuse en calcul . La charge peut être réduite en réduisant le nombre de propriétés, comme cela se fait dans les couches de goulot d'étranglement de l'architecture Inception.
Réseau en réseau
L'architecture de
réseau en réseau (NiN) est basée sur une idée simple: utiliser des convolutions 1x1 pour augmenter la combinatoire des propriétés dans les couches convolutives.
Dans NiN, après chaque convolution, des couches MLP spatiales sont utilisées pour mieux combiner les propriétés avant de passer à la couche suivante. Il peut sembler que l'utilisation de convolutions 1x1 contredit les principes originaux de LeNet, mais en réalité cela permet de combiner des propriétés mieux que de simplement bourrer plus de couches convolutives. Cette approche est différente de l'utilisation de pixels nus comme entrée pour la couche suivante. Dans ce cas, les convolutions 1x1 sont utilisées pour la combinaison spatiale des propriétés après convolution dans le cadre des cartes de propriétés, vous pouvez donc utiliser beaucoup moins de paramètres communs à tous les pixels de ces propriétés!
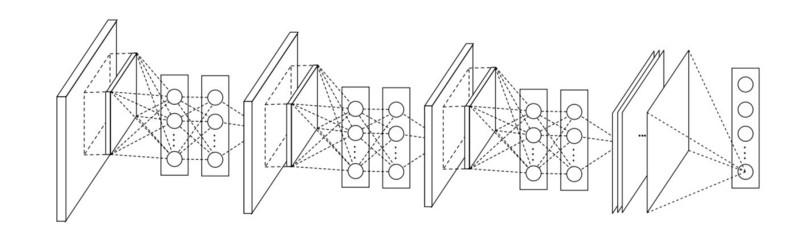
MLP peut augmenter considérablement l'efficacité des couches convolutives individuelles en les combinant en groupes plus complexes. Cette idée a ensuite été utilisée dans d'autres architectures, telles que ResNet, Inception et leurs variantes.
GoogLeNet et création
Google Christian Szegedy est préoccupé par la réduction des calculs dans les réseaux de neurones profonds et a donc créé
GoogLeNet, la première architecture Inception .
À l'automne 2014, les modèles d'apprentissage profond étaient devenus très utiles pour catégoriser le contenu des images et les cadres des vidéos. De nombreux sceptiques ont reconnu les avantages de l'apprentissage en profondeur et des réseaux de neurones, et les géants de l'Internet, dont Google, sont devenus très intéressés par le déploiement de réseaux efficaces et de grande taille sur leurs capacités de serveur.
Christian cherchait des moyens de réduire la charge de calcul dans les réseaux de neurones, atteignant les performances les plus élevées (par exemple, dans ImageNet). Ou en préservant la quantité de calcul, tout en augmentant la productivité.
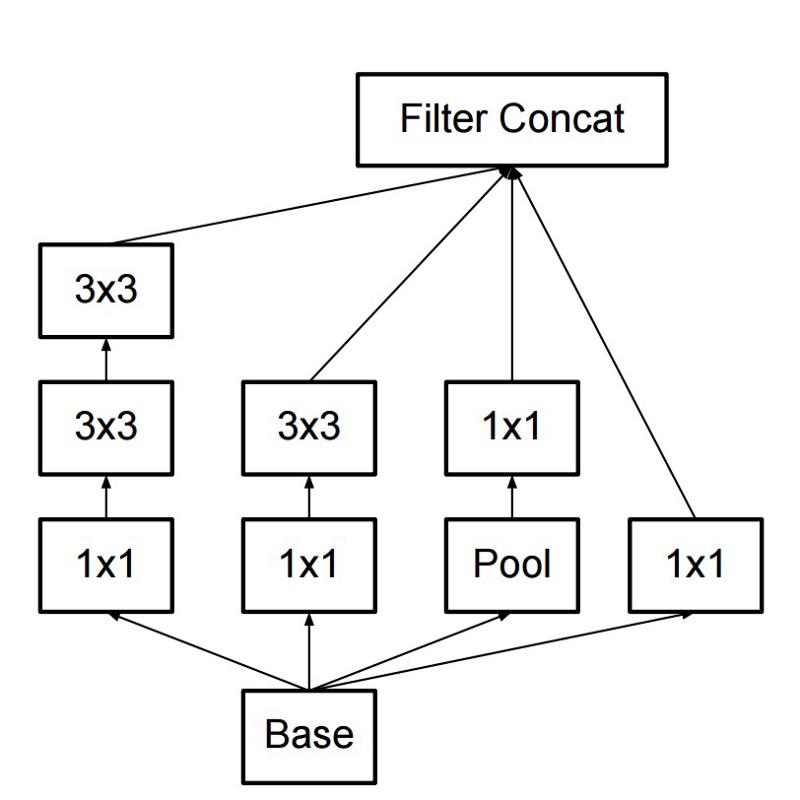
En conséquence, la commande a créé un module Inception:

À première vue, il s'agit d'une combinaison parallèle de filtres convolutionnels 1x1, 3x3 et 5x5. Mais le point culminant a été l'utilisation de blocs de convolution 1x1 (NiN) pour réduire le nombre de propriétés avant de servir dans les blocs parallèles "chers". Habituellement, cette partie est appelée goulot d'étranglement, elle est décrite plus en détail dans le chapitre suivant.
GoogLeNet utilise une tige sans modules Inception comme couche initiale, et utilise également le regroupement moyen et un classificateur softmax similaire à NiN. Ce classificateur effectue extrêmement peu d'opérations par rapport à AlexNet et VGG. Il a également aidé à créer une
architecture de réseau neuronal très efficace .
Couche de goulot d'étranglement
Cette couche réduit le nombre de propriétés (et donc d'opérations) dans chaque couche, de sorte que la vitesse d'obtention du résultat peut être maintenue à un niveau élevé. Avant de transférer des données vers des modules convolutifs «coûteux», le nombre de propriétés est réduit, disons, 4 fois. Cela réduit considérablement la quantité de calcul, ce qui a rendu l'architecture populaire.
Voyons cela. Supposons que nous ayons 256 propriétés en entrée et 256 en sortie, et que la couche Inception n'effectue que 3x3 convolutions. On obtient 256x256x3x3 convolutions (589 000 opérations de multiplication d'accumulation, c'est-à-dire des opérations MAC). Cela peut aller au-delà de nos exigences de vitesse de calcul; disons qu'une couche est traitée en 0,5 milliseconde sur Google Server. Réduisez ensuite le nombre de propriétés de pliage à 64 (256/4). Dans ce cas, nous effectuons d'abord une convolution 1x1 de 256 -> 64, puis une autre 64 convolution dans toutes les branches Inception, puis appliquons à nouveau une convolution 1x1 de 64 -> 256 propriétés. Nombre d'opérations:
- 256 × 64 × 1 × 1 = 16 000
- 64 × 64 × 3 × 3 = 36 000
- 64 × 256 × 1 × 1 = 16 000
Seulement environ 70 000, ont réduit le nombre d'opérations de près de 10 fois! Mais en même temps, nous n'avons pas perdu la généralisation dans cette couche. Les couches de goulot d'étranglement ont montré d'excellentes performances sur l'ensemble de données ImageNet et ont été utilisées dans des architectures ultérieures telles que ResNet. La raison de leur succès est que les propriétés d'entrée sont corrélées, ce qui signifie que vous pouvez vous débarrasser de la redondance en combinant correctement les propriétés avec des convolutions 1x1. Et après avoir plié avec moins de propriétés, vous pouvez à nouveau les déployer dans une combinaison significative sur la couche suivante.
Inception V3 (et V2)
Christian et son équipe se sont révélés être des chercheurs très efficaces. En février 2015, l'architecture
Inception normalisée par lots a été introduite en tant que deuxième version d'
Inception . La normalisation par lots calcule la moyenne et l'écart-type de toutes les cartes de distribution des propriétés dans la couche de sortie et normalise leurs réponses avec ces valeurs. Cela correspond au "blanchiment" des données, c'est-à-dire que les réponses de toutes les cartes neuronales se situent dans la même plage et avec une moyenne nulle. Cette approche facilite l'apprentissage, car la couche suivante n'est pas tenue de mémoriser les décalages des données d'entrée et ne peut rechercher que les meilleures combinaisons de propriétés.
En décembre 2015, une
nouvelle version des modules Inception et l'architecture correspondante a été lancée . L'article de l'auteur explique mieux l'architecture originale de GoogLeNet, qui en dit beaucoup plus sur les décisions prises. Idées clés:
- Maximiser le flux d'informations dans le réseau grâce à l'équilibre soigné entre sa profondeur et sa largeur. Avant chaque regroupement, les cartes de propriétés augmentent.
- Avec une profondeur croissante, le nombre de propriétés ou la largeur de couche augmente également systématiquement.
- La largeur de chaque couche augmente pour augmenter la combinaison de propriétés avant la couche suivante.
- Dans la mesure du possible, seules des convolutions 3x3 sont utilisées. Étant donné que les filtres 5x5 et 7x7 peuvent être décomposés en utilisant plusieurs 3x3
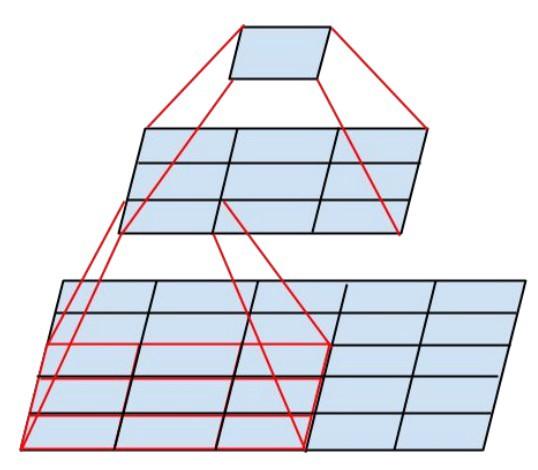
Le nouveau module Inception ressemble à ceci:
- Les filtres peuvent également être décomposés à l'aide de convolutions lissées en modules plus complexes:

- Les modules de création peuvent réduire la taille des données en utilisant le regroupement lors des calculs de création. Cela revient à effectuer une convolution avec des enjambées en parallèle avec une simple couche de regroupement:

Inception utilise la couche de regroupement avec softmax comme classificateur final.
Resnet
En décembre 2015, à peu près au moment où l'architecture Inception v3 a été introduite, une révolution s'est produite - ils ont publié
ResNet . Il contient des idées simples: soumettre la sortie de deux couches convolutionnelles réussies Et contourner l'entrée pour la couche suivante!

De telles idées ont déjà été proposées, par exemple,
ici . Mais dans ce cas, les auteurs contournent DEUX couches et appliquent l'approche à grande échelle. Le contournement d'une couche ne donne pas beaucoup d'avantages, et le contournement de deux est une découverte clé. Cela peut être vu comme un petit classifieur, comme réseau en réseau!
Il s'agissait également du premier exemple de formation d'un réseau de plusieurs centaines, voire milliers de couches.
ResNet multicouche a utilisé une couche de goulot d'étranglement similaire à celle utilisée dans Inception:

Cette couche réduit le nombre de propriétés dans chaque couche, en utilisant d'abord une convolution 1x1 avec une sortie inférieure (généralement un quart de l'entrée), puis une couche 3x3, puis convoluant à nouveau 1x1 en un plus grand nombre de propriétés. Comme dans le cas des modules Inception, cela permet d'économiser des ressources de calcul tout en conservant une multitude de combinaisons de propriétés. Comparez avec les tiges plus complexes et moins évidentes dans Inception V3 et V4.
ResNet utilise une couche de mise en commun avec softmax comme classificateur final.
Chaque jour, des informations supplémentaires sur l'architecture ResNet apparaissent:
- Il peut être considéré comme un système de modules simultanément parallèles et série: dans de nombreux modules, le signal d'entrée est parallèle, et les signaux de sortie de chaque module sont connectés en série.
- ResNet peut être considéré comme plusieurs ensembles de modules parallèles ou série .
- Il s'est avéré que ResNet fonctionne généralement avec des blocs de profondeur relativement petits de 20 à 30 couches travaillant en parallèle, plutôt que de fonctionner séquentiellement sur toute la longueur du réseau.
- Puisque le signal de sortie revient et est alimenté en entrée, comme cela est fait dans RNN, ResNet peut être considéré comme un modèle plausible amélioré du cortex cérébral .
Inception V4
Christian et son équipe ont de nouveau excellé avec une
nouvelle version d'Inception .
La tige suivante du module de création est la même que dans la création V3:

Dans ce cas, le module Inception est combiné avec le module ResNet:

Cette architecture s'est avérée, à mon goût, plus compliquée, moins élégante et également remplie de solutions heuristiques opaques. Il est difficile de comprendre pourquoi les auteurs ont pris telle ou telle décision, et il est tout aussi difficile de leur donner une sorte d’évaluation.
Par conséquent, le prix pour un réseau neuronal propre et simple, facile à comprendre et à modifier, revient à ResNet.
Squeezenet
SqueezeNet a publié récemment. Il s'agit d'un remake d'une nouvelle façon de nombreux concepts de ResNet et Inception. Les auteurs ont démontré que l'amélioration de l'architecture réduit la taille du réseau et le nombre de paramètres sans algorithmes de compression complexes.
ENet
Toutes les fonctionnalités des architectures récentes sont combinées en un réseau très efficace et compact, utilisant très peu de paramètres et de puissance de calcul, mais donnant en même temps d'excellents résultats. L'architecture s'appelait
ENet , elle a été développée par Adam Paszke (
Adam Paszke ). Par exemple, nous l'avons utilisé pour le marquage très précis d'objets à l'écran et l'analyse de scènes.
Quelques exemples d'Enet . Ces vidéos ne sont pas liées à l'
ensemble de données de formation .
Vous trouverez ici les détails techniques d'ENet. Il s'agit d'un réseau basé sur un encodeur et un décodeur. L'encodeur est construit sur le schéma de catégorisation CNN habituel, et le décodeur est un réseau de suréchantillonnage conçu pour la segmentation en redistribuant les catégories à l'image de taille d'origine. Pour la segmentation de l'image, seuls les réseaux de neurones ont été utilisés, aucun autre algorithme.
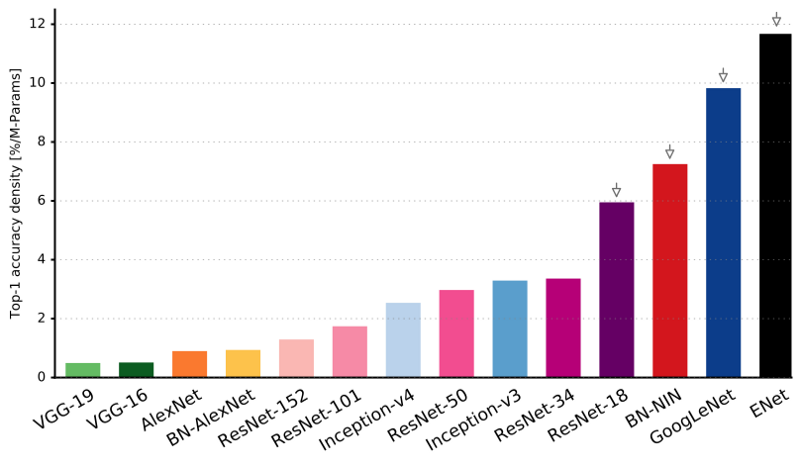
Comme vous pouvez le voir, ENet a la précision spécifique la plus élevée par rapport à tous les autres réseaux de neurones.
ENet a été conçu pour utiliser le moins de ressources possible dès le début. En conséquence, l'encodeur et le décodeur n'occupent ensemble que 0,7 Mo avec une précision fp16. Et avec une si petite taille, ENet n'est pas inférieur à la précision de segmentation ou supérieur à d'autres solutions de réseau purement neuronales.
Analyse de module
Publication d'une évaluation systématique des modules CNN. Cela s'est avéré bénéfique:
- Utilisez la non-linéarité ELU sans normalisation par lots (batchnorm) ou ReLU avec normalisation.
- Appliquez la transformation apprise de l'espace colorimétrique RVB.
- Utilisez une politique de décroissance du taux d'apprentissage linéaire.
- Utilisez la somme de la couche de mise en commun moyenne et maximale.
- Utilisez un mini-paquet 128 ou 256. Si cela est trop pour votre carte vidéo, réduisez la vitesse d'apprentissage proportionnellement à la taille du paquet.
- Utilisez des couches entièrement connectées comme couches convolutives et prévisions moyennes pour donner la solution finale.
- Si vous augmentez la taille de l'ensemble de données d'entraînement, assurez-vous que vous n'avez pas atteint un plateau d'entraînement. La propreté des données est plus importante que la taille.
- Si vous ne pouvez pas augmenter la taille de l'image d'entrée, réduire la foulée dans les calques suivants, l'effet sera à peu près le même.
- Si votre réseau a une architecture complexe et hautement optimisée, comme dans GoogLeNet, modifiez-la avec prudence.
Xception
Xception a introduit une architecture plus simple et plus élégante dans le module Inception, qui n'est pas moins efficace que ResNet et Inception V4.
Voici à quoi ressemble le module Xception:
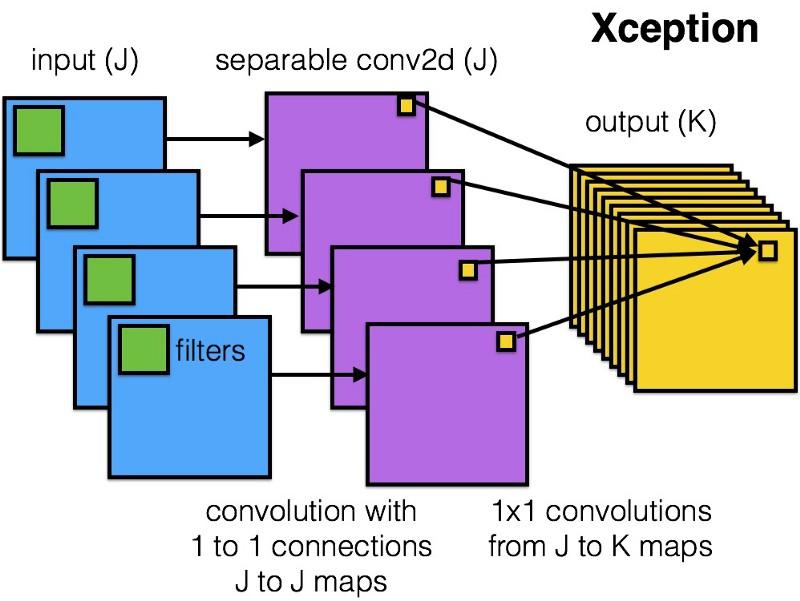
Tout le monde aimera ce réseau en raison de la simplicité et de l'élégance de son architecture:

Il contient 36 étapes de convolution, ce qui est similaire à ResNet-34. En même temps, le modèle et le code sont simples, comme dans ResNet, et beaucoup plus agréables que dans Inception V4.
Une implémentation torch7 de ce réseau est disponible
ici , tandis qu'une implémentation Keras / TF est disponible ici.
Curieusement, les auteurs de la récente architecture Xception se sont également inspirés de
nos travaux sur les filtres convolutionnels séparables .
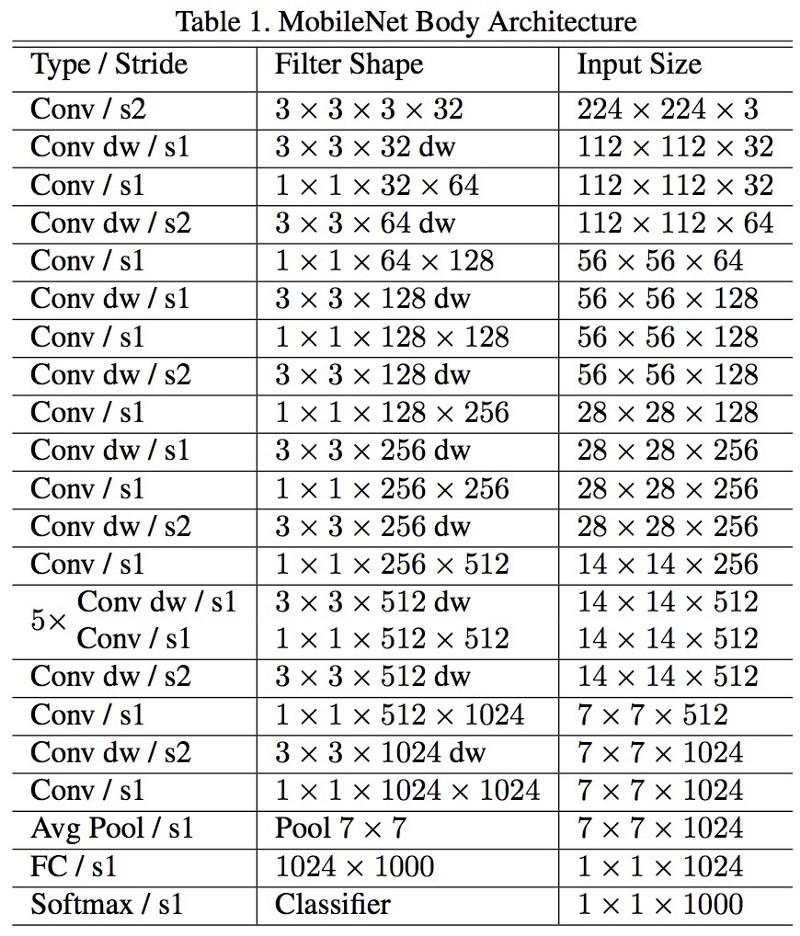
MobileNets
La nouvelle architecture de M
obileNets a été lancée en avril 2017. Pour réduire le nombre de paramètres, il utilise des convolutions détachables, les mêmes que dans Xception. Il est également indiqué dans l'ouvrage que les auteurs ont pu réduire considérablement le nombre de paramètres: environ la moitié dans le cas de FaceNet. :
, 1 (batch of 1) Titan Xp. :
- resnet18: 0,002871
- alexnet: 0,001003
- vgg16: 0,001698
- squeezenet: 0,002725
- mobilenet: 0,033251
! , .
FractalNet , ImageNet ResNet.
, . , .
, , , , ? , .
.
, . , .
, .
.