Une startup cool au début de son voyage est similaire à Sapsan. Une petite équipe prend rapidement de l'ampleur et se précipite vers l'avenir, portant un tas de tâches à la production. Si le projet s'avérait prometteur, comme Skyeng, alors dans quelques années, il y aura beaucoup plus d'équipes, et il est possible qu'il y ait des locomotives à vapeur dans lesquelles vous devrez constamment jeter du bois de chauffage dans le four pour qu'au moins quelque chose atteigne les utilisateurs.
Consultez ou lisez le
discours d’ Alexei Kataev à Saint
TeamLead Conf si vous ne savez pas quels critères officiels déterminer si votre équipe est cool. Si vous voulez pouvoir mesurer la dette technique en heures, plutôt que de travailler avec les catégories «pas mal», «combien», «terriblement». Si votre chef de produit estime qu'une équipe de trois personnes par mois fera 60 tâches - montrez-lui cet article. Si votre responsable a suspendu le développement avec des métriques et vous suggère de prendre des mesures basées sur des résultats tels que: «34% pensent que l'équipe a un problème avec la planification», ce rapport est pour vous.
À propos de l'orateur: Alexei Kataev (
deusdeorum ) est engagé dans le développement web depuis 15 ans. A réussi à travailler en tant que backend, frontend, développeur fullstack et chef d'équipe. Actuellement engagé dans la rationalisation des processus de développement chez
Skyeng . Peut être familier aux chefs d'équipe lorsqu'ils
parlent du travail d'une équipe répartie.
Nous passons enfin la parole à l'orateur. Commençons par le contexte et passons progressivement au problème principal.

J'ai rejoint Skyeng en 2015 et j'étais l'un des cinq développeurs - ils étaient tous des développeurs de l'entreprise.
Un peu plus de trois ans se sont écoulés, et nous avons maintenant
15 équipes - ce sont 68 développeurs .
 Tous les développeurs travaillent à distance
Tous les développeurs travaillent à distance , ils sont dispersés dans le monde.
Examinons les problèmes qui surviennent inévitablement lors de la mise à l'échelle d'une entreprise de 5 à 68 employés.
Dans l'image, Sergey est le responsable du développement.

Une fois, nous avions une équipe, et c'était Sapsan, qui s'est précipité vers l'avenir et a effectué un tas de tâches en production. Mais pas seulement des tâches, mais un peu de dette technique. Puis à un moment donné, de façon inattendue pour nous, il y avait beaucoup plus d'équipes.
La première question à laquelle Sergey est confronté est de
savoir si toutes nos équipes sont des Sapsans , ou y a-t-il parmi nous des
machines à
vapeur où vous devez jeter du bois de chauffage dans la chambre de combustion.

Cette question est importante car une telle situation peut survenir: un chef de produit ou un représentant commercial viendra chez Sergey et dira que nous n'avons pas le temps, l'équipe fonctionne mal. Mais en fait, le problème peut être non seulement dans l'équipe. Le problème peut être dans la relation entre l'équipe et l'entreprise ou dans l'entreprise elle-même - elle peut ne pas bien fixer les objectifs ou avoir des plans trop optimistes.
Vous devez comprendre si l'équipe est cool .
 La deuxième question concerne les ressources de l'équipe
La deuxième question concerne les ressources de l'équipe : combien de tâches pouvons-nous effectuer sur les produits. Ce problème est important car le produit a toujours beaucoup de plans pour le futur proche. Il est important de comprendre si l'équipe fera face à ces plans ou si vous devez abandonner la moitié des tâches. Ou peut-être que cela vaut la peine d'embaucher quelques personnes supplémentaires pour réaliser toutes les tâches.
 La troisième question est de savoir combien de dettes techniques avons-nous sur nous?
La troisième question est de savoir combien de dettes techniques avons-nous sur nous? Il s'agit d'une question critique, car si sa quantité dépasse la valeur limite, notre train ne pourra finalement pas aller du tout. Nous devrons licencier l'équipe, démarrer le projet depuis le début, et nous ne voulons pas le permettre.

Enfin - comment s'assurer que
toutes les équipes sont des Sapsans et non des trains?
1. Nous déterminons à quel point nos équipes sont cool.
Bien sûr, la première chose qui me vient à l'esprit est de mesurer certaines métriques! Maintenant, je vais vous parler de notre expérience et comment nous nous sommes trompés encore et encore.

Tout d'abord, nous avons essayé de surveiller la
vitesse - combien de tâches nous déployons pour le sprint. Mais il s'est avéré que la moitié de nos équipes n'ont pas du tout de sprints, elles ont Kanban. Et là où il y a des sprints, les tâches sont notées en heures ou en points d'histoire. Il y a encore quelques équipes qui font juste les tâches - elles n'ont pas Kanban, elles ne savent pas ce qu'est Scrum.
Il s'agit d'une incohérence des données. Nous essayons de calculer un nombre sur des données complètement différentes. Dans le même temps, faire des sprints partout pour que toutes les équipes soient identiques coûtera très cher. Pour calculer une métrique, il faudrait changer de processus.
Nous avons pensé, essayé quelques options supplémentaires et sommes arrivés à une mesure simple - la
mise en œuvre des plans . Il est également coûteux, mais seuls les plans de produits doivent être rendus identiques et cohérents. Quelqu'un les conduit à Jira, quelqu'un à Google Spreadsheets, quelqu'un construit des graphiques - la conversion en un format est beaucoup moins chère que de changer les processus en équipe.
Chaque trimestre, nous voyons si l'équipe répond aux exigences de l'entreprise, combien de tâches planifiées ont été réalisées.

Le comptage du
nombre d'incidents a également échoué.
Nous enregistrons chaque déploiement échoué ou bug qui a causé des dommages à l'entreprise et à l'autopsie. Sergei est venu me voir en tant que chef d'équipe et a déclaré: «Votre équipe admet le plus de chutes. Pourquoi? " Nous avons pensé, regardé et il s'est avéré que notre équipe est la plus responsable et la seule qui enregistre toutes les chutes. Les autres agissent selon le principe de l'élévation rapide, non considérée comme tombée.
Le problème est encore une fois l'incohérence des données et un échantillonnage insuffisant. Nous avons des équipes qui ont juste un atterrissage - ça ne plante jamais du tout. On ne peut pas dire que cette équipe est meilleure, car elle a un projet plus stable.
Le deuxième - mon sujet préféré - est
la distorsion cognitive . La facilité cognitive, c'est quand nous faisons une conclusion qui nous semble simple et que nous commençons immédiatement à y croire. Nous n'incluons pas la pensée critique: s'il y a beaucoup de chutes, cela signifie une mauvaise équipe.
Nous sommes arrivés exactement à la même mesure du nombre d'incidents, mais nous avons seulement révisé sa mise en œuvre. Nous avons fait un processus dans lequel
toutes les chutes sont enregistrées . À la fin de chaque mois, nous demandons aux personnes qui ne souhaitent pas cacher des incidents - ce sont l'AQ et les produits, est-ce une liste complète des problèmes survenus en raison de la faute de l'équipe. Ils se souviennent quand nous avons laissé tomber quelque chose et complètent cette liste.

Il y a aussi des problèmes avec les sondages. Il semblerait qu'un outil super universel - nous interrogerons tout le monde (produits, chefs d'équipe, clients) sur les problèmes que nous avons dans les équipes. Selon leurs réponses, nous construirons des graphiques, et nous découvrirons tout. Mais il y a beaucoup de problèmes.
Premièrement, si vous posez des questions fermées, aucune conclusion ne peut être tirée de ces données. Par exemple, nous demandons: "L'équipe a-t-elle un problème avec la planification?" et 34% disent qu'il y a - et que faire à ce sujet? Si vous posez des questions ouvertes: «Quels sont les problèmes de l'équipe avec l'infrastructure?» - vous obtiendrez des réponses vides, car tout le monde est trop paresseux pour écrire quoi que ce soit.
Aucune conclusion ne peut être tirée de ces données .
Nous avons développé cette idée - nous menons d'abord des enquêtes en tant que dépistage, puis des entretiens pour comprendre quel est exactement le problème. Nous parlerons de l'interview un peu plus tard.
J'ai donné trois exemples, en fait,
nous avons essayé des dizaines de mesures .
Maintenant, nous utilisons uniquement:
- Réalisation des plans.
- Le nombre d'incidents.
- Sondages + interviews.
Je suis trompeur si je dis que nous mesurons même ces choses simples dans toutes les équipes, car la
chose la
plus coûteuse est la mise en œuvre . Surtout quand il y a 15 équipes différentes, quand le produit dit: "Oui, nous n'en avons pas besoin du tout! Il faudrait déployer notre tâche, ce n'est pas à la hauteur! » Il est très difficile de faire en sorte de mesurer un nombre dans toutes les équipes.
L'entretien
Faisons une brève digression sur l'
entretien avec les développeurs . J'ai lu plusieurs articles, j'ai suivi le cours d'épicerie. Il y a beaucoup de recherches sur les utilisateurs et de développement client. J'en ai pris plusieurs pratiques, et elles sont très bien tombées en communication avec les développeurs.
Si votre objectif est de découvrir les problèmes rencontrés par l'équipe, vous devez tout d'abord rédiger des questions ciblées dont vous chercherez la réponse. Autrement dit, vous ne posez pas seulement 30 questions,
vous choisissez 2-3 questions auxquelles vous cherchez une réponse. Par exemple: l'équipe a-t-elle des problèmes d'infrastructure; comment la communication entre l'entreprise et l'équipe est établie.
Dans ce cas, les questions doivent être:
- Ouvrez . La réponse à la question: "Y a-t-il un problème?" "Oui!" "Il ne vous dira rien."
- Neutre Une question sur un problème est une mauvaise question. Mieux vaut demander: "Parlez-moi du processus de planification dans votre équipe." Une personne parle du processus et vous commencez déjà à lui poser des questions plus profondes.
Une autre très bonne approche est la
priorisation . Vous avez différents aspects de la vie d'équipe. Vous demandez à l'employé qui, à son avis, est le plus cool et devrait rester le même, et qui, peut-être, devrait être amélioré.
Il y a une autre approche que j'ai empruntée au chapitre sur les interviews dans le livre «Who. Résolvez votre problème numéro un "- posez des questions comme celle-ci:"
Si je demandais un produit, qu'en pensez-vous, quels problèmes nommerait-il? " Cela oblige le développeur à regarder la situation dans son ensemble, et non à partir de leur position, pour voir tous les problèmes.
2. Évaluer les ressources
Parlons maintenant de l'
évaluation des ressources .
Commençons par l'approche du produit - car il évalue généralement les ressources de son équipe. Il y a 3 personnes, 20 jours ouvrables par mois - nous multiplions les personnes par jours, nous obtenons 60 tâches.

Bien sûr, j'exagère, un produit normal multipliera cela par 60 jours de développement. Mais c'est également faux, personne ne déploiera jamais des tâches évaluées pendant 60 jours en 60 jours. Même Scrum vous conseille de considérer le facteur de mise au point et de le multiplier par un certain nombre magique, par exemple 0,2. En fait, d'itération en itération, nous déploierons 12, puis 17, puis 10 tâches. Je pense que c'est une évaluation très approximative.
J'ai ma propre approche pour évaluer les ressources. Pour commencer, nous considérons la ressource totale de l'équipe en heures de travail. Nous multiplions les heures par les développeurs, nous enlevons les vacances et les jours de congé. Supposons que vous en obteniez 750.
Mais tout développement n'est pas le développement lui-même.
Ci-dessus, des données réelles utilisant l'une des commandes comme exemple:
- 36,9% du temps consacré à la communication sont des réunions, des discussions, des revues techniques, des revues de code, etc.
- 63,1% - directement pour résoudre des problèmes.
Le produit peut-il compter sur ces 63,1%? Non, ce n'est pas possible, car les tâches du produit ne sont qu'une partie. Il y a encore un
quota (environ 20%) pour corriger les bugs et refactoring . C'est ce que distribue le timlid, et le produit ne compte plus sur ce temps.

De même, toutes les tâches du produit ne sont pas celles que le produit a planifiées. Il y a des tâches de produit d'autres équipes qui demandent une aide urgente à cause de la sortie. Nous estimons environ
8 à
10% des tâches provenant d'autres équipes .

Et maintenant nous avons 287 heures! Tout serait cool si nous nous inscrivions toujours dans nos notes. Mais dans cette équipe, le dépassement moyen a été comptabilisé - 1,51, c'est-à-dire qu'en moyenne, la tâche a pris une fois et demie plus de temps que prévu.
 Un total de 750 reste 189 heures pour accomplir les tâches principales
Un total de 750 reste 189 heures pour accomplir les tâches principales . Bien sûr, il s'agit d'une approximation, mais cette formule comporte des variables qui peuvent être modifiées. Par exemple, si vous consacrez un mois à la refactorisation, vous pouvez remplacer cette valeur et savoir sur quoi vous pouvez compter.
J'ai consacré toute la journée à cela - j'ai pris des tâches, dans Excel j'ai calculé le temps moyen, l'ai analysé - j'ai passé beaucoup de temps et décidé que je ne le referais plus jamais. J'ai besoin d'une approche rapide pour cela, afin de ne pas le faire avec mes mains à chaque fois.
On m'a conseillé un plugin pour Jira et
EazyBI . C'est un outil super compliqué, ou je n'avais pas assez de compétences, mais au milieu j'ai abandonné.
J'ai trouvé un moyen de créer rapidement des rapports.
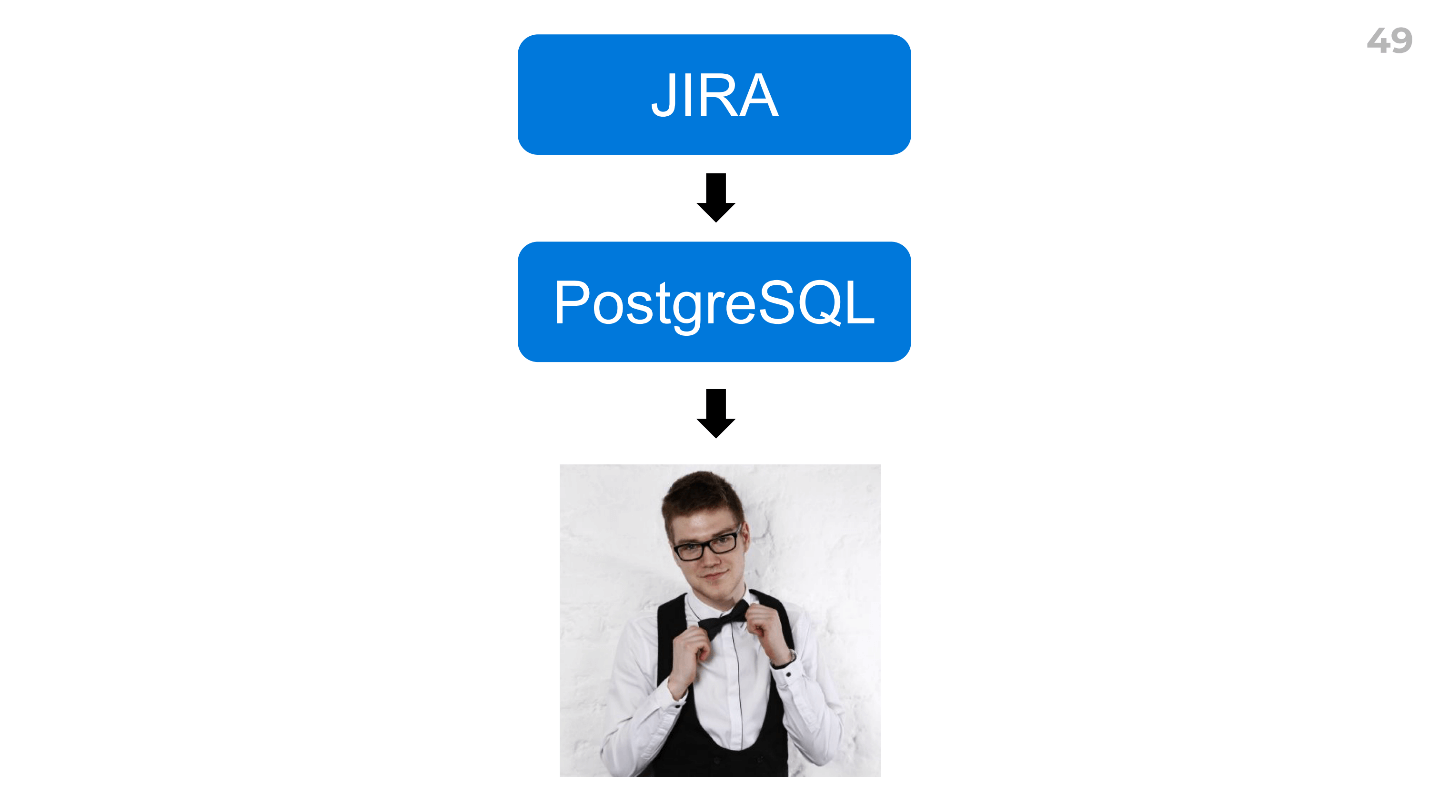
Téléchargez les données de votre traqueur de tâches vers n'importe quel SGBD que vous connaissez (PostgreSQL pour nous), puis demandez à l'analyste de tout calculer. Nous l'avons Dima, et il a tout calculé en 2 heures.

Dans le même temps, il a donné un tas de données supplémentaires - heures supplémentaires pour les développeurs, heures supplémentaires pour les types de tâches, certains coefficients, nous a fait part de ses idées et de nouvelles hypothèses - amusantes et évolutives: vous pouvez les utiliser immédiatement dans toutes les équipes.
Comment augmenter la ressource
Maintenant,
comment accélérer une équipe - augmentez ses ressources sans augmenter le nombre de développeurs.
Tout d'abord, pour accélérer quelque chose, vous devez d'abord le mesurer. Nous comptons généralement deux mesures:
- Évaluation sommaire initiale des tâches pour l'itération en heures. Par exemple, nous avons déployé des tâches pendant 100 heures en une semaine.
- Et parfois, le temps de roulement moyen est le temps à partir du moment où la tâche est entrée dans le développement, avant qu'elle ne soit en production. Il s'agit d'une mesure plus commerciale et intéressante pour le produit, pas pour le développeur.
Je ne me lasserai pas de le dire au bot Arseny, que j'ai écrit ce week-end. Chaque semaine, il publie un résumé - combien de tâches nous avons déployées.

Il y a deux choses intéressantes ici:
- Ce que j'appelle l'effet d'observateur - en évaluant un indicateur, nous le changeons déjà. Dès que nous avons commencé à utiliser ce bot, nous avons augmenté le nombre de tâches que nous effectuons pendant l'itération.
- La métrique doit être motivante . J'ai commencé par montrer jusqu'où nous n'avons pas le temps de sprinter. Il s'est avéré que nous n'étions pas à temps de 10%, de 20%. Cela ne motive pas du tout, il n'y aura pas d'effet observateur.
La vitesse est une métrique en retard; nous ne pouvons pas l'influencer directement. Cela montre quelque chose, mais il existe des mesures qui affectent lesquelles, nous pouvons influencer la vitesse. À mon avis, il y en a deux principaux:
1. L'exactitude des tâches d'évaluation.Ici, nous avons de nouveau été aidés par notre analyste chargé Dima, qui a calculé le temps réel de la tâche, en fonction de l'évaluation initiale.

Ce sont de vraies données. Ci-dessus est un graphique du temps réel pour terminer la tâche, et ci-dessous est notre estimation.
Joel Spolsky affirme que 16 heures par tâche est la limite. Pour nous, il est clair qu'après 12 heures, l'évaluation n'a pas de sens, la variance y est trop grande. Nous avons vraiment introduit le soft-limit et essayons de ne pas évaluer les tâches, plus de 12 heures. Après cela, soit la décomposition ou des recherches supplémentaires.
2. Une perte de
temps, c'est-à-dire lorsque les développeurs passent du temps sur quelque chose qu'ils pourraient ne pas consacrer.
Dans l'une de nos équipes, jusqu'à 50% du temps a été consacré à la communication. Nous avons commencé à analyser et à comprendre quelle était la raison. Il s'est avéré que le problème est dans les processus: tous les clients ont écrit directement aux développeurs, posé des questions. Nous avons un peu changé les processus, réduit ce temps et amélioré les indicateurs de vitesse.
Dans votre cas, ce ne sera pas nécessairement des communications, par exemple, il peut être temps pour le déploiement ou l'infrastructure. Mais la condition préalable à cela est que tous vos développeurs doivent enregistrer l'heure. Si personne ne connecte votre temps à Jira, il sera évidemment très coûteux de le mettre en œuvre.
3. Gérer la dette technique
Quand je dis "devoir technique", je le visualise comme quelque chose de flou - on ne sait pas comment le mesurer?

Si je vous dis que nous avons exactement 648 heures de service technique dans l'une des équipes, vous ne me croirez pas. Mais je vais vous dire l'algorithme par lequel nous le mesurons.

Nous nous réunissons une fois par trimestre en équipe (nous appelons cela une réunion de refactoring) et nous proposons des cartes: quelles béquilles (la nôtre et les autres) les gens ont vues dans le code, les décisions douteuses et d'autres mauvaises choses, par exemple, les anciennes versions des bibliothèques - n'importe quoi. Après avoir généré un tas de ces cartes, pour chacune, nous écrivons la résolution - que faire avec. Peut-être ne rien faire, car ce n'est pas du tout un devoir technique, ou vous devez mettre à jour la version de la bibliothèque, refactoriser, etc. Ensuite, nous créons des tickets à Jira, où nous écrivons: "C'est le problème - c'est sa solution."
Et ici, nous avons 150 billets à Jira - que faire avec eux?

Après cela, nous menons une enquête qui prend 10 minutes pour un développeur. Chaque développeur donne une note de 1 à 5, où 1 - "Un jour, nous le ferons dans la prochaine vie", et 5 - "Nous devons le faire maintenant, cela nous ralentit beaucoup." Nous ajoutons cette note directement au ticket à Jira. Nous avons créé un champ personnalisé, appelé «Refactoring Priority», et nous obtenons ainsi une liste prioritaire de nos dettes et problèmes techniques. Après avoir évalué les 10 à 20 premiers, puis multiplié la queue par la note moyenne (nous sommes trop paresseux pour évaluer les 150 tickets), nous obtenons
une dette technique en heures .
Pourquoi en avons-nous besoin? Nous effectuons cette évaluation une fois par trimestre. Si nous avions 700 heures au premier trimestre, puis que cela est devenu, par exemple, 800, alors tout est en ordre. Et s'il est devenu 1400, cela signifie qu'il y a une menace et qu'il est nécessaire d'augmenter le quota de refactoring - d'accord avec l'entreprise que nous allons maintenant refactoriser un mois entier ou 40% du temps.
Eh bien, nous avons résolu le problème de la dette technique, il est sous clé.

Mais parlons des raisons qui ont conduit à son apparition. Il s'agit le plus souvent d'une mauvaise révision du code.
Mauvaise revue de code
L'une des principales raisons de la mauvaise révision du code est le facteur bus.
Nous avons appris à formaliser le facteur bus . Nous prenons une équipe, rédige une liste de domaines pertinents pour cette équipe, par exemple, pour une équipe de plate-forme c'est: la communication vidéo, la synchronisation des exercices, les outils. Chaque développeur donne une note de 1 à 3:
- 1 - "Je ne comprends pas ce que c'est, j'ai entendu plusieurs fois."
- 2 - "Je peux faire des tâches à partir de cette zone."
- 3 - "Je suis un super expert dans ce domaine."
Fait intéressant, pour certains domaines, il n'y avait pas un seul expert dans l'équipe, personne ne savait comment cela fonctionne.
Comment avons-nous résolu le problème avec le facteur bus ?
Ensuite, nous avons calculé la valeur médiane pour chaque domaine et réalisé une série de rapports lors de réunions d'équipe régulières au cours desquelles des experts ont informé l'ensemble de l'équipe de ces domaines. Bien sûr, cette méthode n'est pas très évolutive, mais, d'une part, il existe une vidéo de ces rapports, et d'autre part, c'est un moyen très rapide. Toute l'équipe sait maintenant plus ou moins comment fonctionne l'appel vidéo. Pour certains domaines, nous n'avons pas encore écrit de documentation, mais nous avons fait la tâche de rédiger de la documentation. Un jour, nous écrirons.

Maintenant
sur la révision du code quand il n'y a pas assez de temps. , review code review. pull requests, code review . , , - , review. - — , — , code review .
. —
, .
4.
. , , cross review . -, : , , , . , . , .
, Google Suite : , , , .
—
- .

-, . , , Continuous Integration ..
- — , .
— , . , , , , , , . -.
:
, .
- QA- — 10 , .
- , - Skyeng - . — , , .
- open source, , .
Telegram (@ax8080)
facebook , .
, Call for Papers TeamLead Conf 2019, 25–26 , . , , , .
! , .