
Bonjour, Habr! Il y a deux ans, nous avons
écrit comment nous sommes passés à PHP 7.0 et avons économisé un million de dollars. Sur notre profil de charge, la nouvelle version s'est avérée deux fois plus efficace dans l'utilisation du processeur: la charge que nous utilisions pour desservir ~ 600 serveurs, après que la transition a commencé à servir ~ 300. En conséquence, pendant deux ans, nous avions une réserve de capacités.
Mais Badoo grandit. Le nombre d'utilisateurs actifs est en constante augmentation. Nous améliorons et développons nos fonctionnalités, grâce auxquelles les utilisateurs passent de plus en plus de temps dans l'application. Et cela, à son tour, se reflète dans le nombre de demandes qui, au cours des deux dernières années, ont augmenté de 2 à 2,5 fois.
Nous nous sommes retrouvés dans une situation où un gain de performance double a été compensé par plus d'une double augmentation des demandes, et nous avons recommencé à approcher les limites de notre cluster. Au cœur de PHP, des
optimisations utiles (JIT, préchargement) sont à nouveau attendues, mais elles ne sont prévues que pour PHP 7.4, et cette version sera publiée au plus tôt dans un an. Par conséquent, l'astuce de transition ne peut pas être répétée maintenant - vous devez optimiser le code d'application lui-même.
Sous la coupe, je vais vous dire comment nous abordons ces tâches, quels outils nous utilisons, et donner des exemples d'optimisations, d'idées et d'approches que nous appliquons et qui nous ont aidés à notre époque.
Pourquoi optimiser
Le moyen le plus simple et le plus évident de résoudre le problème de performances est d'ajouter du fer. Si votre code s'exécute sur le même serveur, l'ajout d'un autre doublera les performances de votre cluster. En transférant ces coûts sur le temps de travail du développeur, nous nous demandons: sera-t-il en mesure d’obtenir une double augmentation de la productivité pendant cette période grâce aux optimisations? Peut-être oui, mais peut-être pas: cela dépend de la façon optimale dont le système fonctionne déjà et de la qualité du développeur. En revanche, le serveur acheté restera la propriété de l'entreprise et le temps passé ne sera pas restitué.
Il s'avère que sur de petits volumes, la bonne solution sera souvent l'ajout de fer.
Mais prenez notre situation. Maintenant, après que le gain du passage à PHP 7.0 a été compensé par la croissance de l'activité et du nombre d'utilisateurs, nous avons à nouveau 600 serveurs servant les requêtes à l'application PHP. Afin d'augmenter la capacité d'une fois et demie, nous devons ajouter 300 serveurs.
Prenez pour calcul le coût moyen d'un serveur - 4 000 $. 300 * 4000 = 1 200 000 $ - le coût d'une augmentation de la capacité d'une fois et demie.
Autrement dit, dans nos conditions, nous pouvons investir une quantité importante de temps de travail dans l'optimisation du système, et il sera toujours plus rentable que l'achat de fer.
Planification des capacités
Avant d'entreprendre quoi que ce soit, il est important de comprendre s'il y a un problème. Si elle n'est pas là, alors il vaut la peine d'essayer de prédire quand elle peut apparaître. Ce processus est appelé planification des capacités.
Un indicateur concret de la présence de problèmes de performances est le temps de réponse. En effet, peu importe si le CPU (ou d'autres ressources) est chargé à 6% ou 146%: si un client reçoit un service de la qualité requise dans un délai satisfaisant, alors tout fonctionne bien.
L'inconvénient de se concentrer sur le temps de réponse est qu'il ne commence généralement à augmenter que lorsque le problème est déjà apparu. Si ce n'est pas encore fait, il est difficile de prédire son apparition. De plus, le temps de réponse reflète les résultats de l'influence de tous les facteurs (services de freinage, réseau, variateurs, etc.) et ne permet pas de comprendre les causes des problèmes.
Dans notre cas, le CPU est généralement le goulot d'étranglement, donc lors de la planification de la taille et des performances des clusters, nous prêtons principalement attention aux métriques associées à son utilisation. Nous collectons l'utilisation du processeur de toutes nos machines et créons des graphiques avec la valeur moyenne, la médiane, le 75e et le 95e centile:
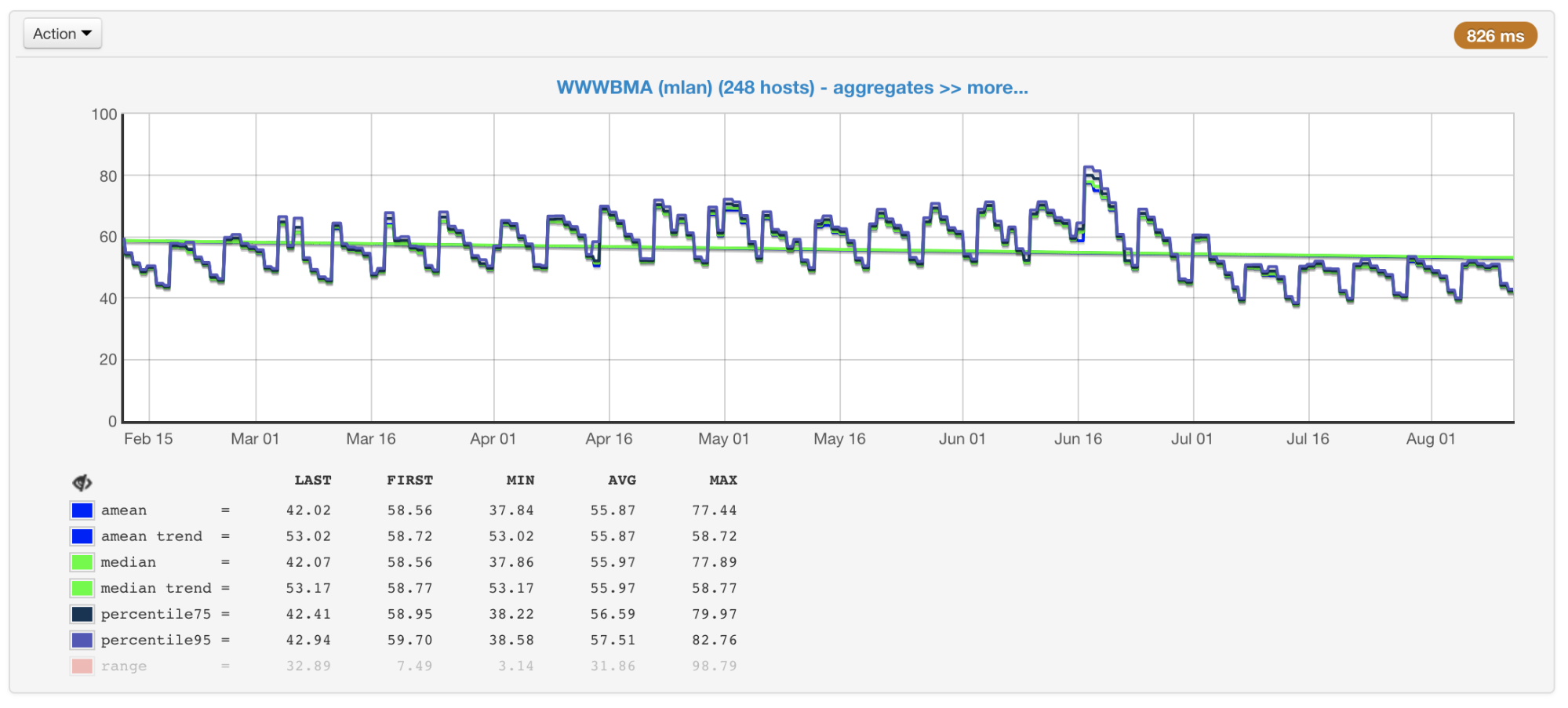 Utilisation CPU des machines du cluster en pourcentage: moyenne, médiane, centiles
Utilisation CPU des machines du cluster en pourcentage: moyenne, médiane, centilesIl y a des centaines de machines dans nos clusters qui y ont été ajoutées depuis de nombreuses années. Ils sont différents dans la configuration et les performances (le cluster n'est pas homogène). Notre équilibreur en tient compte (
article et
vidéo ) et charge les machines en fonction de leurs capacités. Afin de contrôler ce processus, nous avons également un programme de machines chargées maximum et minimum.
 Les machines de cluster les plus et les moins chargées
Les machines de cluster les plus et les moins chargéesSi vous regardez ces graphiques (ou simplement à la sortie de la commande supérieure) et voyez la charge CPU de 50%, vous pourriez penser que nous avons encore une marge pour une augmentation de charge double. Mais en réalité, ce n'est généralement pas le cas. Et voici pourquoi.
Hyper threading
Imaginez un seul cœur sans hypertreading. Nous le chargeons avec un thread lié au CPU. Nous verrons 100% de chargement en haut.
Maintenant, activez l'hyper-lecture sur ce noyau et chargez-le exactement de la même manière. En haut, nous verrons déjà deux cœurs logiques, et la charge totale sera de 50% (généralement sur un 0%, et sur l'autre - 100%).
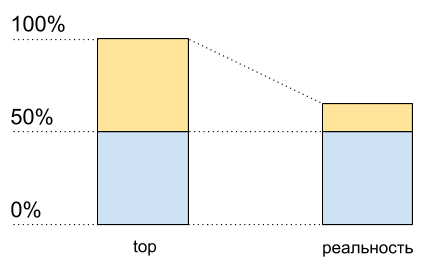 Utilisation du processeur: les meilleures données et ce qui se passe réellement
Utilisation du processeur: les meilleures données et ce qui se passe réellementComme si le processeur n'était chargé qu'à 50%. Mais physiquement, aucun noyau gratuit supplémentaire n'est apparu. L'hypertreading permet
dans certains cas d'exécuter sur un cœur physique plusieurs processus à la fois. Mais cela est loin de doubler les performances dans des situations typiques, bien que sur le graphique d'utilisation du CPU cela ressemble à la moitié des ressources: de 50% à 100%.
Cela signifie qu'après 50% de l'utilisation du processeur lorsque l'hypertreading est activé, il n'augmentera pas de la même manière qu'auparavant.
J'ai écrit ce code pour le démontrer (il s'agit d'une sorte de boîtier synthétique, en réalité les résultats différeront):
Code de script<?php $concurrency = $_SERVER['argv'][1] ?? 1; $hashes = 100000000; $chunkSize = intval($hashes / $concurrency); $t1 = microtime(true); $children = array(); for ($i = 0; $i < $concurrency; $i++) { $pid = pcntl_fork(); if (0 === $pid) { $first = $i * $chunkSize; $last = ($i + 1) * $chunkSize - 1; for ($j = $first; $j < $last; $j++) { $dummy = md5($j); } printf("[%d]: %d hashes in %0.4f sec\n", $i, $last - $first, microtime(true) - $t1); exit; } else { $children[$pid] = 1; } } while (count($children) > 0) { $pid = pcntl_waitpid(-1, $status); if ($pid > 0) { unset($children[$pid]); } else { exit("Got a error pid=$pid"); } }
J'ai deux cœurs physiques sur mon ordinateur portable. Exécutez ce code avec différentes données d'entrée afin de mesurer ses performances avec un nombre différent de processus C parallèles.
Nous traçons les résultats des lancements:
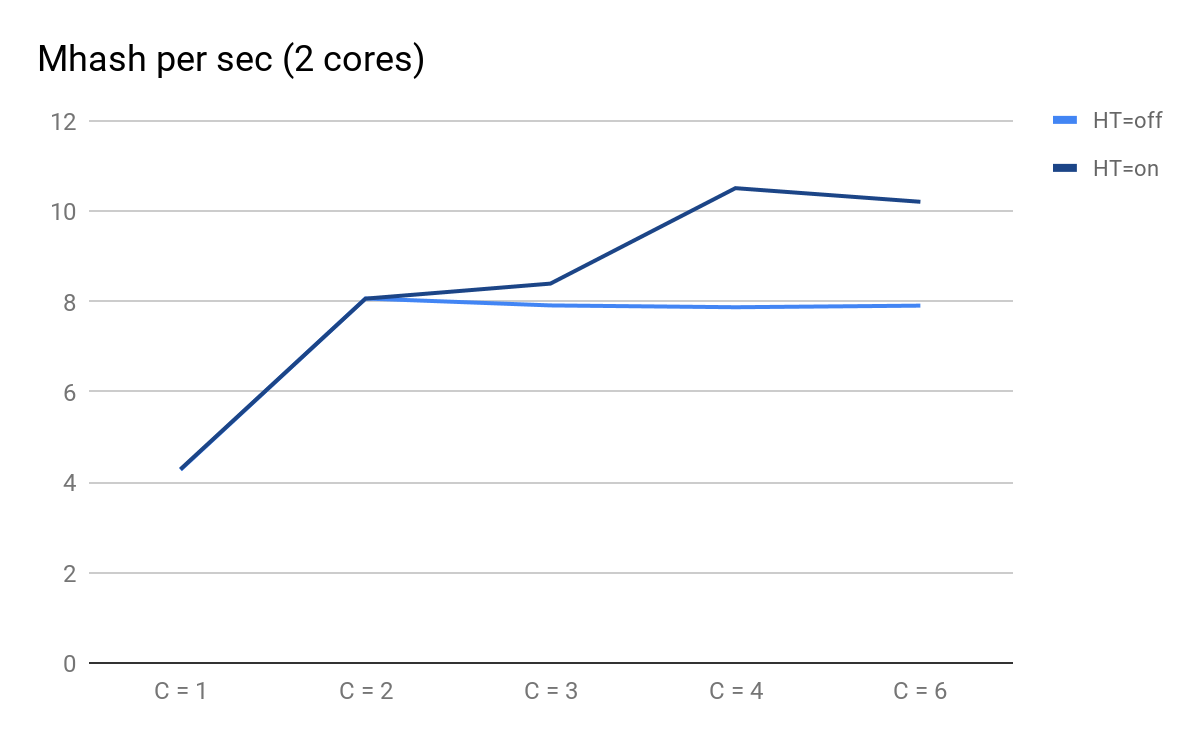 Performances du script en fonction du nombre de processus parallèles
Performances du script en fonction du nombre de processus parallèlesÀ quoi vous pouvez faire attention:
- C = 1 et C = 2 sont les mêmes pour HT = on et HT = off, les performances doublent lorsqu'un noyau physique est ajouté;
- sur C = 3, les avantages de HT deviennent perceptibles: pour HT = on, nous avons pu obtenir des performances supplémentaires, tandis que pour HT = off avec C = 3, il commence à diminuer lentement et de manière prévisible;
- à C = 4, nous voyons tous les avantages de HT; nous avons pu extraire 30% de productivité supplémentaires, mais en comparaison avec C = 2 à ce moment, l'utilisation du processeur est passée de 50% à 100%.
Au total, en voyant dans les 50% supérieurs de la charge CPU, lors de l'exécution de ce script, nous obtenons 8 065 Mhash / sec, et à 100% - 10 511 Mhash / sec. Cela signifie qu'à environ 50% du sommet, nous obtenons 8,065 / 10,511 ~ 77% des performances maximales du système et en fait, il nous reste environ 100% dans la réserve - 77% = 23%, et non 50%, comme cela peut sembler.
Ce fait doit être pris en compte lors de la planification.
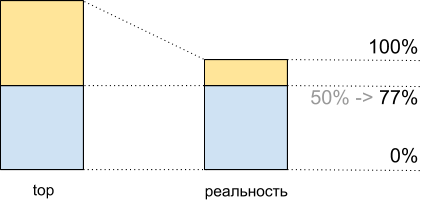 Utilisation du processeur pour la démonstration: les meilleures données et ce qui se passe réellement
Utilisation du processeur pour la démonstration: les meilleures données et ce qui se passe réellementIncohérence du trafic
En plus de l'hypertreading, la planification complique également l'inégalité du trafic en fonction de l'heure de la journée, du jour de la semaine, de la saison et d'autres fréquences. Pour nous, par exemple, le pic est le dimanche soir.
 Nombre de demandes par seconde, pic dimanche soir
Nombre de demandes par seconde, pic dimanche soirLe nombre de demandes ne change pas toujours de manière évidente. Par exemple, les utilisateurs peuvent en quelque sorte interagir avec d'autres utilisateurs: l'activité de certains peut générer des push / e-mails à d'autres et donc les impliquer dans le processus. À cela s'ajoutent des campagnes promotionnelles qui augmentent le trafic et auxquelles vous devez également vous préparer.
Tout cela est également important à prendre en compte lors de la planification: par exemple, pour construire une tendance par jours de pointe et garder à l'esprit l'éventuelle non-linéarité de la croissance de pointe.
Outils de profilage et de mesure
Supposons que nous découvrions qu'il y a des problèmes de performances, comprenons que ce n'est pas la base de données / services / trucs, et pourtant nous avons décidé d'optimiser le code. Pour ce faire, tout d'abord, nous avons besoin d'un profileur ou de quelques outils pour trouver les goulots d'étranglement et voir ensuite les résultats de nos optimisations.
Malheureusement, pour PHP aujourd'hui, il n'y a pas de bon outil universel.
perf
perf est un outil de profilage intégré au noyau Linux. Il s'agit d'un profileur d'
échantillonnage qui est lancé par un processus distinct, il n'ajoute donc pas directement de surcharge au programme profilé. Les frais généraux ajoutés indirectement sont uniformément «tachés», de sorte qu'ils ne faussent pas les mesures.
Pour tous ses avantages, perf est capable de fonctionner uniquement avec du code compilé et avec JIT et n'est pas capable de travailler avec du code fonctionnant "sous une machine virtuelle". Par conséquent, le code PHP lui-même ne peut pas être profilé, mais vous pouvez clairement voir comment PHP fonctionne à l'intérieur, y compris diverses extensions PHP, et combien de ressources y sont dépensées.
Par exemple, avec perf, nous avons trouvé plusieurs goulots d'étranglement, dont un lieu de compression, dont je parlerai ci-dessous.
Un exemple:
perf record --call-graph dwarf,65528 -F 99 -p $(pgrep php-cgi | paste -sd "," -) -- sleep 20
perf report(si le processus et perf sont exécutés sous différents utilisateurs, alors perf doit être exécuté sous sudo).
 Exemple de sortie de rapport Perf pour PHP-FPM
Exemple de sortie de rapport Perf pour PHP-FPMAgrégateur XHProf et XHProf
XHProf est une extension pour PHP qui place des temporisateurs autour de tous les appels aux fonctions / méthodes, et contient également des outils pour visualiser les résultats ainsi obtenus. Contrairement à perf, il vous permet de fonctionner avec des termes de code PHP (en même temps, ce qui se passe dans les extensions n'est pas visible).
Les inconvénients comprennent deux choses:
- toutes les mesures sont collectées dans le cadre d'une seule demande, elles ne fournissent donc pas d'informations sur l'image dans son ensemble
- la surcharge, bien qu'elle ne soit pas aussi importante que, par exemple, lors de l'utilisation de Xdebug, mais elle l'est, et dans certains cas, les résultats sont fortement déformés (plus une fonction est appelée et plus elle est simple, plus la distorsion est importante).
Voici un exemple illustrant le dernier point:
function child1() { return 1; } function child2() { return 2; } function parent1() { child1(); child2(); return; } for ($i = 0; $i < 1000000; $i++) { parent1(); }
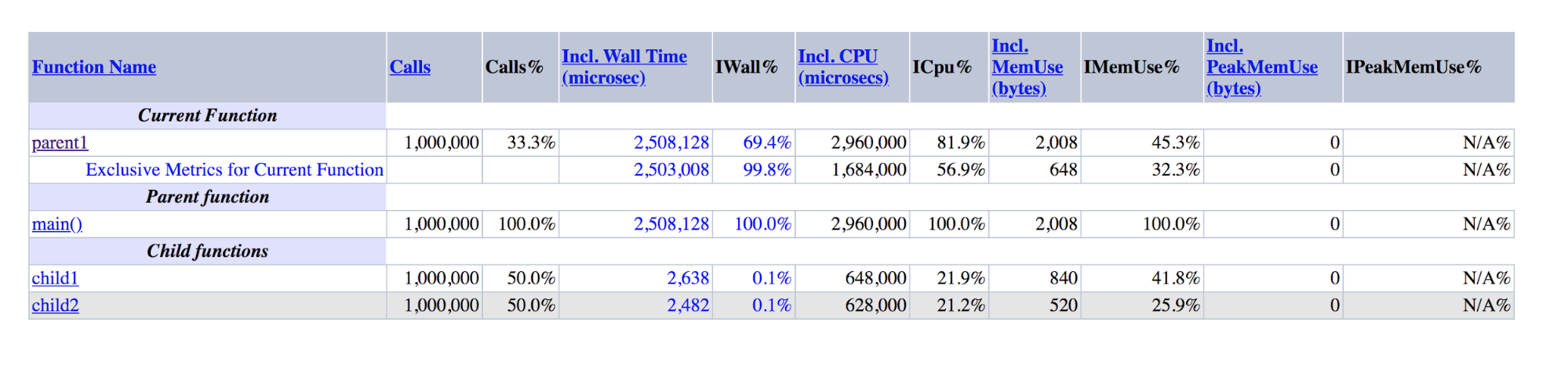 Sortie XHProf pour les démos: parent1 est un ordre de grandeur supérieur à la somme de child1 et child2
Sortie XHProf pour les démos: parent1 est un ordre de grandeur supérieur à la somme de child1 et child2On peut voir que parent1 () a été exécuté ~ 500 fois plus longtemps que child1 () + child2 (), bien qu'en réalité ces nombres devraient être approximativement égaux, comme sont égaux à main () et parent1 ().
Si le dernier inconvénient est difficile à combattre, alors pour combattre le premier, nous avons créé un module complémentaire sur XHProf, qui agrège les profils des différentes demandes et visualise les données agrégées.
En plus de XHProf, il existe de nombreux autres profileurs moins connus fonctionnant sur un principe similaire. Ils ont des avantages et des inconvénients similaires.
Pinba
Pinba vous permet de
surveiller les performances par des scripts (actions) et par des minuteries prédéfinies. Toutes les mesures dans le contexte des scripts sont faites hors de la boîte; pour cela, aucune étape supplémentaire n'est requise. Pour chaque script et temporisateur,
getrusage est
exécuté , nous savons donc exactement combien de temps processeur a été consacré à un morceau de code particulier (contrairement aux profileurs d'échantillonnage, où ce temps peut se révéler être réseau, disque, etc.). Pinba est idéal pour enregistrer des données historiques et obtenir une image à la fois en général et dans des types spécifiques de requêtes.
 La ruse générale de tous les scripts obtenus de Pinba
La ruse générale de tous les scripts obtenus de PinbaLes inconvénients incluent le fait que les temporisateurs qui profilent des sections spécifiques du code, et non les scripts entiers, doivent être organisés à l'avance dans le code, ainsi que la présence d'une surcharge qui (comme dans XHProf) peut déformer les données.
phpspy
phpspy est un projet relativement nouveau (le premier commit sur GitHub était il y a
six mois), qui semble prometteur, nous le
suivons donc de près.
Du point de vue de l'utilisateur, phpspy est similaire à perf: un processus parallèle est lancé, qui copie périodiquement les parties mémoire du processus PHP, les analyse et en reçoit des traces de pile et d'autres données. Cela se fait d'une manière assez spécifique. Afin de minimiser les frais généraux, phpspy n'arrête pas le processus PHP et copie la mémoire directement pendant son exécution. Cela conduit au fait que le profileur peut obtenir un état incohérent, les traces de pile peuvent être rompues. Mais phpspy peut détecter cela et élimine ces données.
À l'avenir, en utilisant cet outil, il sera possible de collecter à la fois des données sur l'image dans son ensemble et des profils de types spécifiques de requêtes.
Tableau de comparaison
Pour structurer les différences entre les outils, créons un tableau croisé dynamique:
 Comparaison des principales caractéristiques des profileursGraphes de flamme
Comparaison des principales caractéristiques des profileursGraphes de flammeOptimisation et approches
Avec ces outils, nous surveillons en permanence les performances et l'utilisation de nos ressources. Lorsqu'ils sont utilisés de manière injustifiée ou que nous approchons du seuil (pour le CPU, nous avons choisi empiriquement une valeur de 55% afin d'avoir une marge de temps en cas de croissance), comme je l'ai écrit plus haut, l'une des solutions au problème est l'optimisation.
Eh bien, si l'optimisation a déjà été effectuée par quelqu'un d'autre, comme ce fut le cas avec PHP 7.0, lorsque cette version s'est avérée beaucoup plus productive que les précédentes. Nous essayons généralement d'utiliser des technologies et des outils modernes, y compris des mises à jour opportunes des dernières versions de PHP. Selon
les benchmarks publics , PHP 7.2 est 5-12% plus rapide que PHP 7.1. Mais cette transition, hélas, nous a donné beaucoup moins.
Pour tout le temps, nous avons mis en œuvre un grand nombre d'optimisations. Malheureusement, la plupart d'entre eux sont fortement liés à notre logique métier. Je vais parler de celles qui peuvent être pertinentes non seulement pour nous, ou des idées et des approches qui peuvent être utilisées en dehors de notre code.
Compression Zlib => zstd
Nous utilisons la compression pour les grandes clés memkey. Cela nous permet de dépenser trois à quatre fois moins de mémoire pour le stockage en raison des coûts supplémentaires du processeur pour la compression / décompression. Nous avons utilisé zlib pour cela (notre extension pour travailler avec les memekes est différente de celles qui viennent avec PHP, mais les officielles
utilisent également zlib).
En perf, la production était quelque chose comme ça:
+ 4.03% 0.22% php-cgi libz.so.1.2.11 [.] inflate
+ 3.38% 0.00% php-cgi libz.so.1.2.11 [.] deflate7 à 8% du temps a été consacré à la compression / décompression.
Nous avons décidé de tester différents niveaux et algorithmes de compression. Il s'est avéré que zstd s'exécute sur nos données presque dix fois plus vite, perdant en place ~ 1,1 fois. Un changement assez simple dans l'algorithme nous a permis d'économiser environ 7,5% de CPU (cela, je le rappelle, sur nos volumes équivaut à environ 45 serveurs).
Il est important de comprendre que le rapport des performances des différents algorithmes de compression peut varier considérablement en fonction des données d'entrée. Il existe diverses
comparaisons , mais plus précisément, cela ne peut être estimé qu'en utilisant des exemples réels.
IS_ARRAY_IMMUTABLE en tant que référentiel de données rarement modifiées
Lorsque vous travaillez avec des tâches réelles, vous devez traiter de telles données dont vous avez besoin souvent et en même temps rarement changer et avoir une taille limitée. Nous avons beaucoup de données similaires, un bon exemple est la configuration des
tests fractionnés . Nous vérifions si l'utilisateur tombe dans les conditions d'un test particulier, et en fonction de cela nous lui montrons des fonctionnalités expérimentales ou normales (cela se produit presque à chaque demande). Dans d'autres projets, les configurations et divers répertoires peuvent être un tel exemple: pays, villes, langues, catégories, marques, etc.
Étant donné que ces données sont souvent demandées, leur réception peut créer une charge supplémentaire notable à la fois sur l'application elle-même et sur le service dans lequel ces données sont stockées. Ce dernier problème peut être résolu, par exemple, en utilisant APCu, qui utilise la mémoire de la même machine exécutant PHP-FPM comme stockage. Mais même alors:
- il y aura des coûts de sérialisation / désérialisation;
- vous devez en quelque sorte invalider les données lors de la modification;
- Il y a une surcharge par rapport à l'accès à une variable en PHP.
PHP 7.0 introduit l'optimisation
IS_ARRAY_IMMUTABLE . Si vous déclarez un tableau, dont tous les éléments sont connus au moment de la compilation, alors il sera traité et placé une fois dans la mémoire OPCache, les travailleurs PHP-FPM se référeront à cette mémoire partagée sans passer leur temps avant d'essayer de changer. Il s'ensuit également que l'inclusion d'un tel réseau prendra un temps constant quelle que soit sa taille (généralement ~ 1 microseconde).
À titre de comparaison: un exemple du temps nécessaire pour obtenir un tableau de 10 000 éléments via include et apcu_fetch:
$t0 = microtime(true); $a = include 'test-incl-1.php'; $t1 = microtime(true); printf("include (%d): %d microsec\n", count($a), ($t1-$t0) * 1e6); $t0 = microtime(true); $a = apcu_fetch('a'); $t1 = microtime(true); printf("apcu_fetch (%d): %d microsec\n", count($a), ($t1-$t0) * 1e6);
Vérifier si cette optimisation a été appliquée peut être très simple si vous regardez les opcodes générés:
$ cat immutable.php <?php return [ 'key1' => 'val1', 'key2' => 'val2', 'key3' => 'val3', ]; $ cat mutable.php <?php return [ 'key1' => \SomeClass::CONST_1, 'key2' => 'val2', 'key3' => 'val3', ]; $ php -d opcache.enable=1 -d opcache.enable_cli=1 -d opcache.opt_debug_level=0x20000 immutable.php $_main: ; (lines=1, args=0, vars=0, tmps=0) ; (after optimizer) ; /home/ubuntu/immutable.php:1-8 L0 (4): RETURN array(...) $ php -d opcache.enable_cli=1 -d opcache.opt_debug_level=0x20000 mutable.php $_main: ; (lines=5, args=0, vars=0, tmps=2) ; (after optimizer) ; /home/ubuntu/mutable.php:1-8 L0 (4): T1 = FETCH_CLASS_CONSTANT string("SomeClass") string("CONST_1") L1 (4): T0 = INIT_ARRAY 3 T1 string("key1") L2 (5): T0 = ADD_ARRAY_ELEMENT string("val2") string("key2") L3 (6): T0 = ADD_ARRAY_ELEMENT string("val3") string("key3") L4 (6): RETURN T0
Dans le premier cas, on peut voir qu'il n'y a qu'un seul opcode dans le fichier - le retour du tableau fini. Dans le second cas, sa formation élément par élément se produit à chaque exécution de ce fichier.
Ainsi, il est possible de générer des structures sous une forme qui ne nécessite pas de transformation supplémentaire lors de l'exécution. Par exemple, au lieu de désassembler les noms de classe par les signes «_» et «\» à chaque fois pour le chargement automatique, vous pouvez pré-générer la carte de correspondance «Class => Path». Dans ce cas, la fonction de conversion sera réduite à un seul appel de table de hachage. Composer effectue ce type d'optimisation si vous activez l'
option Optimize-autoloader .
Pour invalider de telles données, vous n'avez rien à faire de particulier - PHP lui-même recompilera le fichier lors de la modification, comme il le ferait avec un déploiement de code normal. Le seul inconvénient que vous ne devez pas oublier: si le fichier est très volumineux, la première demande après l'avoir modifié entraînera une recompilation, ce qui peut prendre un temps tangible.
Les performances incluent / nécessitent
Contrairement à l'exemple de tableau statique, joindre des fichiers avec des déclarations de classe et de fonction n'est pas si rapide. Malgré la présence d'OPCache, le moteur PHP doit les copier dans la mémoire du processus, en connectant les dépendances de manière récursive, ce qui peut finalement prendre des centaines de microsecondes voire des millisecondes par fichier.
Si vous créez un nouveau projet vide sur
Symfony 4.1 et mettez
get_included_files () comme première ligne de l'action, vous pouvez voir que 310 fichiers sont déjà connectés. Dans un projet réel, ce nombre peut atteindre des milliers par demande. Il convient de prêter attention aux éléments suivants.
Manque de fonctionnalités de chargement automatiqueIl existe une
fonction de chargement automatique RFC , mais aucun développement n'a été observé depuis plusieurs années. Par conséquent, si une dépendance dans Composer définit des fonctions en dehors de la classe et que ces fonctions doivent être accessibles à l'utilisateur, cela se fait en
connectant obligatoirement un fichier avec ces fonctions à chaque initialisation de l'autochargeur.
Par exemple, en supprimant l'une des dépendances de composer.json, qui déclare de nombreuses fonctions et est facilement remplacée par une centaine de lignes de code, nous avons gagné quelques pour cent du processeur.
Le chargeur automatique est appelé plus souvent qu'il n'y paraît.Pour illustrer l'idée, créez un tel fichier avec une classe:
<?php class A extends B implements C { use D; const AC1 = \E::E1; const AC2 = \F::F1; private static $as3 = \G::G1; private static $as4 = \H::H1; private $a5 = \I::I1; private $a6 = \J::J1; public function __construct(\K $k = null) {} public static function asf1(\L $l = null) :? LR { return null; } public static function asf2(\M $m = null) :? MR { return null; } public function af3(\N $n = null) :? NR { return null; } public function af4(\P $p = null) :? PR { return null; } }
Enregistrer le chargeur automatique: spl_autoload_register(function ($name) { echo "Including $name...\n"; include "$name.php"; });
Et nous allons faire plusieurs cas d'utilisation pour cette classe: include 'A.php' Including B... Including D... Including C... \A::AC1 Including A... Including B... Including D... Including C... Including E... new A() Including A... Including B... Including D... Including C... Including E... Including F... Including G... Including H... Including I... Including J...
Vous remarquerez peut-être que lorsque nous connectons simplement la classe, mais ne créons pas son instance, le parent, les interfaces et les traits seront connectés. Cela se fait récursivement pour tous les fichiers connectés en tant que résolution.
Lors de la création d'une instance, la résolution de toutes les constantes et champs est ajoutée à cela, ce qui conduit à la connexion de tous les fichiers nécessaires à cela, ce qui, à son tour, provoquera également la connexion récursive des traits, parents et interfaces des classes nouvellement connectées.
 Connexion de classes connexes pour le processus de création d'instance et d'autres cas
Connexion de classes connexes pour le processus de création d'instance et d'autres casIl n'y a pas de solution universelle à ce problème, il vous suffit de le garder à l'esprit et de surveiller les connexions entre les classes: une ligne peut tirer la connexion de centaines de fichiers.
Paramètres OPCacheSi vous utilisez la méthode de
déploiement atomique en modifiant le lien symbolique proposé par Rasmus Lerdorf, le créateur de PHP, alors pour
résoudre le problème de «coller» le lien symbolique sur l'ancienne version, vous devez inclure opcache.revalidate_path, comme recommandé, par exemple, dans cet
article sur OPCache traduit par Mail .Ru Group.
Le problème est que cette option augmente considérablement (en moyenne, une fois et demie à deux fois) le temps d'inclusion de chaque fichier. Au total, cela peut consommer une quantité importante de ressources (dans notre cas, la désactivation de cette option a donné un gain de 7 à 9%).
Pour le désactiver, vous devez faire deux choses:
- faire en sorte que le serveur Web résolve les liens symboliques;
- arrêtez de connecter des fichiers à l'intérieur du script PHP le long des chemins contenant des liens symboliques, ou forcez-les à travers readlink () ou realpath ().
Si tous les fichiers sont connectés avec l'autochargeur Composer, le deuxième élément sera exécuté automatiquement une fois le premier terminé: omposer utilise la constante __DIR__, qui sera résolue correctement.
OPCache propose quelques options supplémentaires qui peuvent améliorer les performances en échange de flexibilité. Vous pouvez en savoir plus à ce sujet dans l'
article que j'ai mentionné ci-dessus.
Malgré toutes ces optimisations, include ne sera toujours pas gratuit. Pour lutter contre cela, PHP 7.4 prévoit d'ajouter une
précharge .
Verrou APCu
Bien que nous ne parlions pas ici de bases de données et de services, divers types de verrous peuvent également se produire dans le code, ce qui augmente le temps d'exécution du script.
Au fur et à mesure de l'augmentation des demandes, nous avons constaté un net ralentissement de la réponse aux heures de pointe. Après avoir découvert les raisons, il s'est avéré que même si APCu est le moyen le plus rapide d'obtenir des données (par rapport à Memcache, Redis et à d'autres types de stockage externe), il peut également fonctionner lentement en remplaçant fréquemment les mêmes clés.
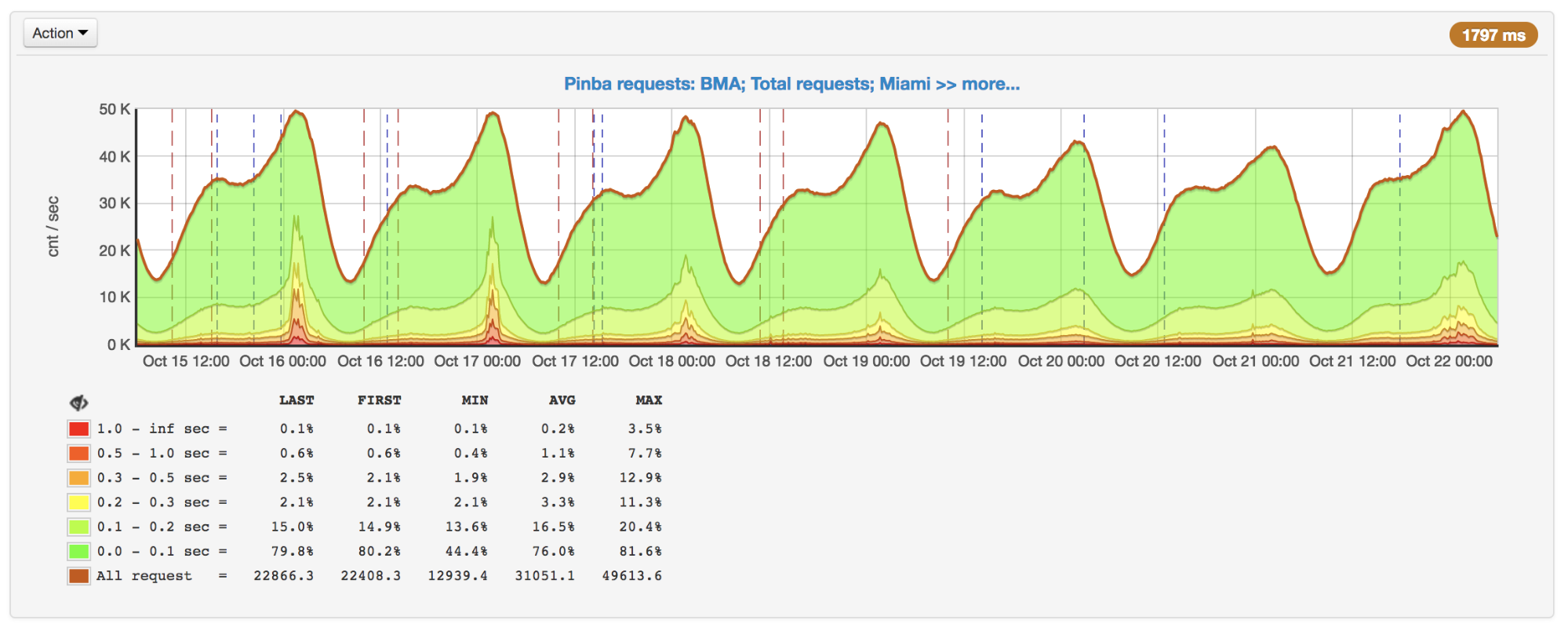 Nombre de requêtes par seconde et temps d'exécution: pics les 16 et 17 octobre
Nombre de requêtes par seconde et temps d'exécution: pics les 16 et 17 octobreLorsque vous utilisez APCu comme cache, ce problème n'est pas si pertinent, car la mise en cache implique généralement une écriture rare et une lecture fréquente. Mais certaines tâches et certains algorithmes (par exemple,
Circuit Breaker (
implémentation en PHP )) impliquent également des enregistrements fréquents, ce qui provoque des verrous.
Il n'y a pas de solution universelle à ce problème, mais dans le cas du disjoncteur, il peut être résolu, par exemple, en le mettant dans un
service séparé installé sur des machines avec PHP.
Traitement par lots
Même si vous ne tenez pas compte de l'inclusion, généralement une partie importante du temps d'exécution de la requête est consacrée à l'initialisation: un framework (par exemple, la construction d'un conteneur DI et l'initialisation de toutes ses dépendances, le routage, l'exécution de tous les écouteurs), l'augmentation de la session, l'utilisateur, etc. plus loin.
Si votre backend est une API interne pour quelque chose, certaines requêtes sur les clients peuvent être regroupées et envoyées en tant que requête unique. Dans ce cas, l'initialisation sera effectuée une seule fois pour plusieurs requêtes.
, , . - , . .
Badoo , . PHP-FPM, CPU, , , : IO, CPU .
PHP-FPM — , PHP.
(CPU, IO), . , , , , - , . , . , , .
Conclusion
. PHP .
:
- ;
- ;
- - , : , ;
- : (, , );
- : ;
- , OPCache PHP, , , ;
- : (, , PHP 7.2 , );
- : , .
?
Merci de votre attention!