Bonjour à tous! Je travaille chez Veeam sur le projet Veeam Agent pour Linux. Avec ce produit, vous pouvez sauvegarder une machine Linux. «Agent» dans le nom signifie que le programme vous permet de sauvegarder des machines physiques. Virtualalkans sauvegarde également, mais il se trouve sur le système d'exploitation invité.
L'inspiration pour cet article a été mon rapport à la conférence
Linux Piter , que j'ai décidé de publier comme article pour tous les habragiteli intéressés.
Dans l'article, je vais révéler le sujet de la création d'un instantané qui vous permet de sauvegarder et de parler des problèmes que nous avons rencontrés lors de la création de notre propre mécanisme pour créer des instantanés de périphériques de bloc.
Tous les intéressés, demandez une coupe!

Un peu de théorie au début
Historiquement, il existe deux approches pour créer des sauvegardes: la sauvegarde de fichiers et la sauvegarde de volumes. Dans le premier cas, nous copions chaque fichier comme un objet séparé, dans le second, nous copions le contenu entier du volume comme une sorte d'image.
Les deux méthodes présentent de nombreux avantages et inconvénients, mais nous les considérerons à travers le prisme de la récupération après une défaillance:
- Dans le cas de la sauvegarde de fichiers, pour récupérer entièrement le serveur entier, nous devrons d'abord installer le système d'exploitation, puis les services nécessaires, puis seulement restaurer les fichiers à partir de la sauvegarde.
- Dans le cas de la sauvegarde de volume, pour une récupération complète, il suffit de restaurer simplement tous les volumes de la machine sans efforts inutiles de la part de la personne.
De toute évidence, dans le cas de la sauvegarde de volume, vous pouvez restaurer le système plus rapidement, et c'est une
caractéristique importante
du système . Par conséquent, pour nous-mêmes, nous considérons la sauvegarde de volume comme l'option préférée.
Comment prenons-nous et enregistrons-nous l'intégralité du volume? Bien sûr, le simple fait de copier ne permettra rien de bon. Pendant la copie, une certaine activité avec les données se produira sur le volume, par conséquent, les données incohérentes apparaîtront dans la sauvegarde. La structure du système de fichiers sera violée, les fichiers de base de données seront corrompus, ainsi que d'autres fichiers avec lesquels des opérations seront effectuées pendant la copie.
Pour éviter tous ces problèmes, l'humanité progressive a mis au point une technologie d'instantané - l'instantané. En théorie, tout est simple: nous créons une copie inchangée - un instantané - et en sauvegardons les données. Une fois la sauvegarde terminée, nous détruisons l'instantané. Cela semble simple, mais, comme d'habitude, il y a des nuances.
Grâce à eux, de nombreuses implémentations de cette technologie sont nées. Par exemple, les solutions basées sur le
mappeur de périphériques , telles que LVM et Thin Provisioning, fournissent des instantanés de volume complet, mais nécessitent une disposition de disque spéciale au stade de l'installation du système, ce qui signifie qu'en général, ils ne conviennent pas.
BTRFS et ZFS permettent de créer des instantanés de sous-structures de système de fichiers, ce qui est très cool, mais pour le moment leur part sur les serveurs est petite, et nous essayons de faire une solution universelle.
Supposons qu'il y ait un EXT banal sur notre périphérique de bloc. Dans ce cas, nous pouvons utiliser
dm-snap (soit dit en passant,
dm-bow est en cours de développement), mais voici sa propre nuance. Vous devez avoir un périphérique de bloc gratuit prêt afin de pouvoir déposer les données d'instantanés où.
En faisant attention aux solutions de sauvegarde alternatives, nous avons remarqué qu'en règle générale, ils utilisent leur module de noyau pour créer des instantanés des périphériques de bloc. Nous avons décidé de suivre cette voie en écrivant notre module. Il a été décidé de le distribuer sous licence GPL, afin qu'il soit accessible au public sur
github .
Comment ça marche - en théorie
Instantané du microscope
Nous allons donc maintenant examiner le principe général de fonctionnement du module et nous attarder sur les questions clés plus en détail.
En fait, veeamsnap (comme nous appelions notre module noyau) est un filtre de pilote de périphérique de bloc.

Son travail consiste à intercepter les demandes d'un pilote de périphérique de bloc.
Après avoir intercepté une demande d'écriture, le module copie les données du périphérique de bloc d'origine dans la zone de données de cliché. Nous appelons cette zone snapstore.
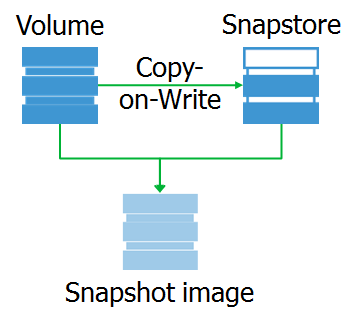
Et quel est l'instantané lui-même? Il s'agit d'un périphérique de bloc virtuel, une copie du périphérique d'origine à un moment donné. Lorsque vous accédez à des blocs de données sur cet appareil, ils peuvent être lus soit à partir du composant logiciel enfichable, soit à partir de l'appareil d'origine.
Je tiens à noter que l'instantané est exactement le périphérique de bloc qui est complètement identique à l'original au moment où l'instantané a été supprimé. Grâce à cela, nous pouvons monter le système de fichiers sur un instantané et effectuer le prétraitement nécessaire.
Par exemple, nous pouvons obtenir une carte des blocs occupés à partir du système de fichiers. La façon la plus simple de le faire est d'utiliser ioctl
GETFSMAP .
Les données sur les blocs occupés vous permettent de lire uniquement les dernières données d'un instantané.
Vous pouvez également exclure certains fichiers. Eh bien, une action complètement facultative: indexez les fichiers qui tombent dans la sauvegarde, pour la possibilité d'un restaurant granulaire à l'avenir.
CoW vs RoW
Arrêtons-nous un peu sur le choix de l'algorithme d'instantané. Le choix n'est pas très large ici:
Copier sur écriture ou Rediriger sur écriture .
La redirection sur écriture lors de l'interception d'une demande d'écriture la redirigera vers le composant logiciel enfichable, après quoi toutes les demandes de lecture de ce bloc y iront également. Un excellent algorithme pour les systèmes de stockage construits sur la base d'arbres B +, tels que BTRFS, ZFS et Thin Provisioning. La technologie est aussi ancienne que le monde, mais elle se manifeste particulièrement bien dans les hyperviseurs, où vous pouvez créer un nouveau fichier et y écrire de nouveaux blocs pendant la durée de l'instantané. Les performances sont excellentes par rapport à CoW. Mais il y a un gros inconvénient - la structure du périphérique d'origine change, et lors de la suppression de l'instantané, vous devez copier tous les blocs de l'instantané à l'emplacement d'origine.
La copie sur écriture, lors de l'interception d'une demande, copie les données dans le magasin d'instantanés qui doivent subir une modification, après quoi elles peuvent être écrasées à l'emplacement d'origine. Utilisé pour créer des instantanés pour les volumes LVM et les clichés instantanés de VSS. De toute évidence, il est plus approprié pour créer des instantanés de périphériques de bloc, car ne modifie pas la structure du périphérique d'origine et lorsque vous supprimez (ou plantez) l'instantané peut simplement être supprimé sans risquer de perdre des données. L'inconvénient de cette approche est la dégradation des performances, car deux opérations de lecture / écriture sont ajoutées à chaque opération d'écriture.
La sécurité des données étant notre priorité absolue, nous nous sommes concentrés sur CoW.
Jusqu'à présent, tout semble simple, alors passons en revue les problèmes de la vie réelle.
Comment ça marche - en pratique
Condition cohérente
Pour lui, tout a été conçu.
Par exemple, si au moment de créer un instantané (dans une première approximation, nous pouvons supposer qu'il est créé instantanément) un enregistrement sera enregistré dans un fichier, puis dans un instantané le fichier sera incomplet, ce qui signifie qu'il sera endommagé et vide de sens. La situation est similaire avec les fichiers de base de données et le système de fichiers lui-même.
Mais nous vivons au 21e siècle! Il existe des mécanismes de journalisation qui protègent contre de tels problèmes! Certes, la vérité est qu'il y a un «mais» important: cette protection n'est pas contre l'échec, mais contre ses conséquences. Lors de la restauration dans un état cohérent selon le journal, les opérations incomplètes seront ignorées, ce qui signifie qu'elles seront perdues. Par conséquent, il est important de déplacer la priorité vers la protection contre la cause, plutôt que de traiter les conséquences.
Le système peut être averti qu'un instantané sera désormais créé. Pour cela, le noyau a les fonctions
freeze_bdev et
thaw_bdev . Ils tirent les fonctions du système de fichiers freeze_fs et unfreeze_fs. Lorsque vous appelez le premier, le système doit réinitialiser le cache, suspendre la création de nouvelles demandes sur le périphérique de bloc et attendre la fin de toutes les demandes générées précédemment. Et lorsque unfreeze_fs est appelé, le système de fichiers rétablit son fonctionnement normal.
Il s'avère que nous pouvons avertir le système de fichiers. Et les applications? Ici, malheureusement, tout va mal. Alors que sous Windows, il existe un mécanisme
VSS qui, avec l'aide de Writers, fournit une interaction avec d'autres produits, sous Linux, chacun suit sa propre voie. Pour le moment, cela a conduit à la situation que la tâche de l'administrateur système d'écrire (copier,
voler , acheter, etc.) pré-geler et post-décongeler les scripts par eux-mêmes, ce qui préparera leur application pour l'instantané. Pour notre part, dans la prochaine version, nous introduirons la prise en charge d'Oracle Application Processing, la fonctionnalité la plus fréquemment demandée par nos clients. Ensuite, d'autres applications peuvent être prises en charge, mais dans l'ensemble, la situation est plutôt triste.
Où placer le composant logiciel enfichable?
Il s'agit du deuxième problème qui nous gêne. À première vue, le problème n'est pas évident, mais après un peu de compréhension, on constate qu'il s'agit toujours d'un éclat.
Bien sûr, la solution la plus simple consiste à placer le composant logiciel enfichable dans la RAM. Pour le développeur, l'option est tout simplement géniale! Tout est rapide, très pratique pour faire le débogage, mais il y a un montant: la RAM est une ressource précieuse, et personne ne nous donnera un gros coup là-bas.
OK, faisons de snap-file un fichier normal. Mais un autre problème se pose: vous ne pouvez pas sauvegarder le volume sur lequel se trouve le snapstop. La raison est simple: nous interceptons les demandes d'enregistrement, ce qui signifie que nous intercepterons nos propres demandes d'enregistrement dans le composant logiciel enfichable. Les chevaux ont couru de manière scientifique - impasse. Ensuite, il y a un désir aigu d'utiliser un disque séparé pour cela, mais personne n'ajoutera de disques à notre serveur pour notre bien. Vous devez être capable de travailler sur ce qui est.
Positionner à distance le composant logiciel enfichable est une excellente idée, mais il peut être mis en œuvre dans des cercles très étroits de réseaux à large bande passante et à latence microscopique. Sinon, tout en maintenant l'instantané sur la machine, il y aura une stratégie au tour par tour.
Donc, vous devez en quelque sorte placer délicatement le composant logiciel enfichable sur le disque local. Mais, en règle générale, tout l'espace sur les disques locaux est déjà réparti entre les systèmes de fichiers, et en même temps, vous devez réfléchir sérieusement à la manière de contourner le problème de blocage.
La direction de la réflexion est en principe une: vous devez en quelque sorte allouer de l'espace dans le système de fichiers, mais travailler directement avec le périphérique de bloc. La solution à ce problème a été implémentée dans le code de l'espace utilisateur, dans le service.
Il existe un
appel système
fallocate qui vous permet de créer un fichier vide de la taille souhaitée. Cependant, en fait, seules les métadonnées sont créées sur le système de fichiers qui décrit l'emplacement du fichier sur le volume. Et ioctl
FIEMAP nous permet d'obtenir une carte de l'emplacement des blocs de fichiers.
Et le tour est joué: nous créons un fichier sous snap en utilisant fallocate, FIEMAP nous donne une carte de l'emplacement des blocs de ce fichier, que nous pouvons transférer pour travailler dans notre module veeamsnap. De plus, lors de l'accès au snapstor, le module fait des requêtes directement au périphérique de bloc dans des blocs connus de nous, et pas de blocages.
Mais il y a une nuance. L'appel système fallocate n'est pris en charge que par XFS, EXT4 et BTRFS. Pour d'autres systèmes de fichiers comme EXT3, vous devez l'écrire complètement pour allouer le fichier. La fonctionnalité est affectée par une augmentation du temps de préparation des snappads, mais il n'y a pas de choix. Encore une fois, vous devez être capable de travailler sur ce qui est.
Que faire si ioctl FIEMAP n'est pas non plus pris en charge? C'est la réalité de NTFS et FAT32, où il n'y a même pas de support pour l'ancien FIBMAP. J'ai dû implémenter un certain algorithme générique, dont le fonctionnement ne dépend pas des fonctionnalités du système de fichiers. En un mot, l'algorithme est:
- Le service crée un fichier et commence à y écrire un modèle spécifique.
- Le module intercepte les demandes d'écriture, vérifie les données en cours d'écriture.
- Si les données du bloc correspondent au modèle donné, le bloc est marqué comme appartenant au snapstop.
Oui, difficile, oui, lentement, mais mieux que rien. Il est utilisé dans de rares cas pour les systèmes de fichiers sans prise en charge FIEMAP et FIBMAP.
Débordement d'instantané
Au contraire, l'endroit que nous avons attribué sous le snapstore se termine. L'essence du problème est qu'il n'y a nulle part où jeter de nouvelles données, ce qui signifie que l'instantané devient inutilisable.
Que faire
De toute évidence, vous devez augmenter la taille des vivaneaux. Combien? Le moyen le plus simple de définir la taille des snappants est de déterminer le pourcentage d'espace libre sur le volume (comme pour VSS). Pour un volume de 20 To, 10% sera de 2 To - ce qui est beaucoup pour un serveur non chargé. Pour un volume de 200 Go, 10% correspond à 20 Go, ce qui peut être trop peu pour un serveur qui met à jour intensivement ses données. Et il y a encore des volumes minces ...
En général, seul l'administrateur système du serveur peut déterminer à l'avance la taille optimale du composant logiciel enfichable requis, c'est-à-dire que vous devez faire réfléchir la personne et donner son avis d'expert. Cela ne respecte pas le principe «ça marche juste».
Pour résoudre ce problème, nous avons développé l'algorithme d'étirement instantané. L'idée est de casser le composant logiciel enfichable en portions. Dans le même temps, de nouvelles portions sont créées après la création d'un instantané si nécessaire.

Encore une fois, brièvement l'algorithme:
- Avant de créer un instantané, la première partie de l'instantané est créée et donnée au module.
- Lorsque l'instantané est créé, la partie commence à se remplir.
- Dès que la moitié de la portion est pleine, une demande est envoyée au service pour en créer une nouvelle.
- Le service le crée, donne les données au module.
- Le module commence à remplir le lot suivant.
- L'algorithme est répété jusqu'à ce que la sauvegarde soit terminée, ou jusqu'à ce que nous rencontrions la limite d'utilisation de l'espace disque libre.
Il est important de noter que le module doit avoir le temps de créer de nouvelles portions de snapposts selon les besoins, sinon - débordement, réinitialisation des snapshots et aucune sauvegarde. Par conséquent, le fonctionnement d'un tel algorithme n'est possible que sur les systèmes de fichiers avec prise en charge fallocate, où vous pouvez rapidement créer un fichier vide.
Que faire dans les autres cas? Nous essayons de deviner la taille requise et de créer entièrement le snappast. Mais selon nos statistiques, la grande majorité des serveurs Linux utilisent désormais EXT4 et XFS. EXT3 se trouve sur les anciennes machines. Mais dans SLES / openSUSE, vous pouvez tomber sur BTRFS.
Modifier le suivi des blocs (CBT)
Sauvegarde incrémentielle ou différentielle (au fait, le raifort au radis est plus doux ou non, je suggère de le lire
ici ) - sans lui, vous ne pouvez pas imaginer de produit de sauvegarde pour adulte. Et pour que cela fonctionne, vous avez besoin de CBT. Si quelqu'un a manqué: CBT vous permet de suivre les modifications et d'écrire dans la sauvegarde uniquement les données modifiées depuis la dernière sauvegarde.

Beaucoup ont leur propre expérience dans ce domaine. Par exemple, dans VMware vSphere, cette fonctionnalité est disponible depuis la version 4 en 2009. Dans Hyper-V, la prise en charge a été introduite avec Windows Server 2016 et pour prendre en charge les versions antérieures, son propre pilote VeeamFCT a été développé en 2012. Par conséquent, pour notre module, nous ne sommes pas devenus originaux et avons utilisé des algorithmes déjà fonctionnels.
À propos de son fonctionnement.
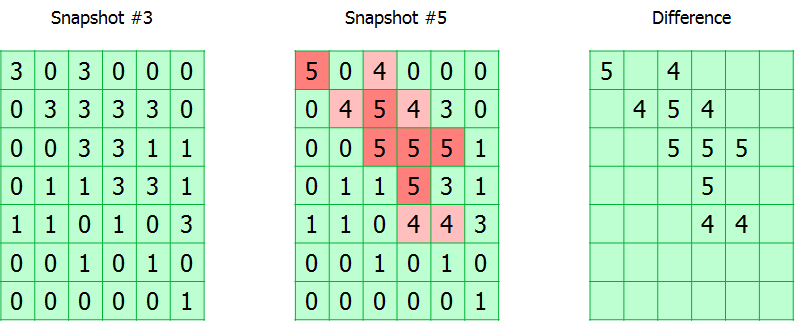
L'ensemble du volume suivi est divisé en blocs. Le module garde simplement une trace de toutes les demandes d'écriture, marquant les blocs modifiés dans le tableau. En fait, la table CBT est un tableau d'octets, où chaque octet correspond à un bloc et contient le numéro de l'instantané dans lequel il a été modifié.
Pendant la sauvegarde, le numéro de l'instantané est enregistré dans les métadonnées de sauvegarde. Ainsi, en connaissant les numéros de l'instantané actuel et celui à partir duquel la sauvegarde réussie précédente a été effectuée, vous pouvez calculer la carte de l'emplacement des blocs modifiés.
Il y a deux nuances.
Comme je l'ai dit, un octet est alloué pour le numéro d'instantané dans la table CBT, ce qui signifie que la longueur maximale de la chaîne incrémentielle ne peut pas dépasser 255. Lorsque ce seuil est atteint, la table est réinitialisée et une sauvegarde complète se produit. Cela peut sembler gênant, mais en fait, une chaîne de 255 incréments est loin d'être la meilleure solution lors de la création d'un plan de sauvegarde.
La deuxième caractéristique est le stockage de la table CBT uniquement dans la RAM. Ainsi, lorsque vous redémarrez la machine cible ou déchargez le module, il sera réinitialisé, et encore une fois, vous devrez créer une sauvegarde complète. Une telle solution permet de ne pas résoudre le problème de démarrage du module au démarrage du système. De plus, il n'est pas nécessaire d'enregistrer les tables CBT lorsque vous éteignez le système.
Problème de performance
La sauvegarde est toujours une si bonne charge sur les E / S de votre équipement. S'il y a déjà suffisamment de tâches actives dessus, le processus de sauvegarde peut transformer votre système en une sorte de
paresse .
Voyons pourquoi.
Imaginez que le serveur écrit simplement de façon linéaire certaines données. La vitesse d'enregistrement dans ce cas est maximale, tous les retards sont minimisés, les performances tendent au maximum. Maintenant, nous ajoutons ici le processus de sauvegarde, qui à chaque écriture doit encore terminer l'algorithme de copie sur écriture, et il s'agit d'une opération de lecture supplémentaire avec l'écriture suivante. Et n'oubliez pas que pour la sauvegarde, vous devez toujours lire les données du même volume. En un mot, votre bel accès linéaire se transforme en un accès aléatoire sans merci avec toutes les conséquences.
Nous devons évidemment faire quelque chose avec cela, et nous avons mis en place un pipeline pour traiter les demandes non pas une à la fois, mais en paquets entiers. Cela fonctionne comme ça.
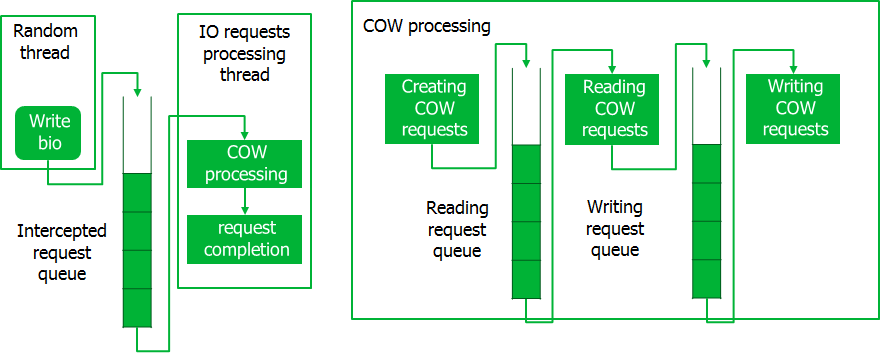
Lors de l'interception de demandes, elles sont placées dans une file d'attente, où un flux spécial les prend en portions. À ce stade, des demandes CoW sont créées, qui sont également traitées par lots. Lors du traitement des demandes de CoW, toutes les opérations de lecture sont d'abord effectuées pour toute la partie, après quoi les opérations d'écriture sont effectuées. Ce n'est qu'après la fin du traitement de la totalité de la demande de CoW que les demandes interceptées sont exécutées. Un tel convoyeur permet d'accéder au disque en gros morceaux de données, ce qui minimise les pertes de temps.
Étranglement
Déjà au stade du débogage, une autre nuance est apparue. Pendant la sauvegarde, le système ne répond plus, c'est-à-dire les demandes d'E / S du système ont commencé à s'exécuter avec de longs délais. Mais, les demandes de lecture de données à partir d'un instantané ont été effectuées à une vitesse proche du maximum.
J'ai dû étrangler un peu le processus de sauvegarde en implémentant le mécanisme de limitation. Pour ce faire, la lecture du processus à partir de l'image instantanée est mise en attente si la file d'attente des requêtes interceptées n'est pas vide. De manière attendue, le système a pris vie.
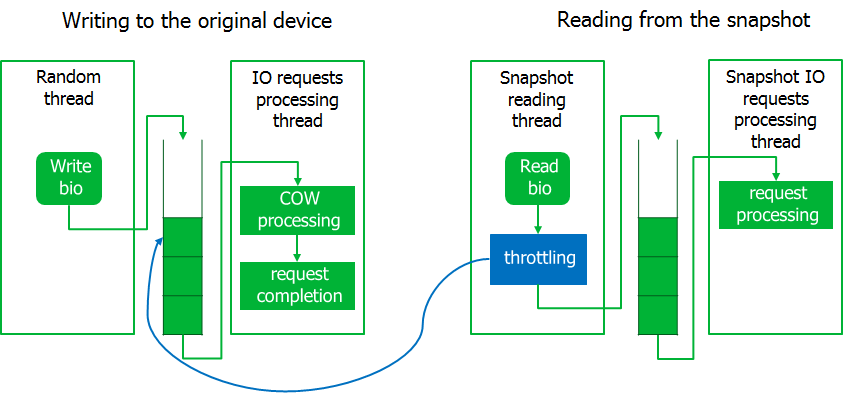
Par conséquent, si la charge sur le système d'E / S augmente fortement, le processus de lecture à partir de l'instantané attendra. Ici, nous avons décidé d'être guidés par le principe selon lequel il est préférable de terminer la sauvegarde avec une erreur plutôt que de perturber le serveur.
Impasse
Je pense que nous devons expliquer plus en détail ce que c'est.
Déjà au stade des tests, nous avons commencé à rencontrer des situations de blocage complet du système avec un diagnostic de sept problèmes - une réinitialisation.
Ils ont commencé à comprendre. Il s'est avéré que cette situation peut être observée si, par exemple, vous créez un instantané du périphérique de bloc sur lequel se trouve le volume LVM et placez l'instantané sur le même volume LVM. Permettez-moi de vous rappeler que LVM utilise le module noyau du mappeur de périphériques.

Dans cette situation, lors de l'interception d'une demande d'écriture, le module, en copiant les données dans le composant logiciel enfichable, enverra la demande d'écriture au volume LVM. Le mappeur de périphérique redirigera cette demande vers le périphérique de blocage. Une demande du mappeur de périphérique sera à nouveau interceptée par le module. Mais une nouvelle demande ne peut pas être traitée tant que la précédente n'a pas été traitée. En conséquence, le traitement des demandes est bloqué, vous êtes accueilli par un blocage.
Pour éviter cette situation, le module du noyau lui-même fournit un délai d'expiration pour l'opération de copie des données dans le composant logiciel enfichable. Cela vous permet de détecter un blocage et une sauvegarde sur incident. La logique ici est la même: il vaut mieux ne pas sauvegarder que suspendre le serveur.
Base de données Round Robin
C'est déjà un problème posé par les utilisateurs après la sortie de la première version.
Il s'est avéré qu'il existe de tels services qui sont uniquement engagés dans l'écrasement constant des mêmes blocs.
Un exemple frappant est celui des services de surveillance, qui génèrent constamment des données sur l'état du système et les écrasent en cercle. Pour ces tâches, utilisez des bases de données cycliques spécialisées ( RRD ).Il s'est avéré qu'avec une sauvegarde de telles bases, l'instantané est garanti de déborder. Dans une étude détaillée du problème, nous avons trouvé une faille dans la mise en œuvre de l'algorithme CoW. Si le même bloc a été remplacé, les données ont été copiées à chaque fois dans le composant logiciel enfichable. Résultat: duplication des données dans le snap.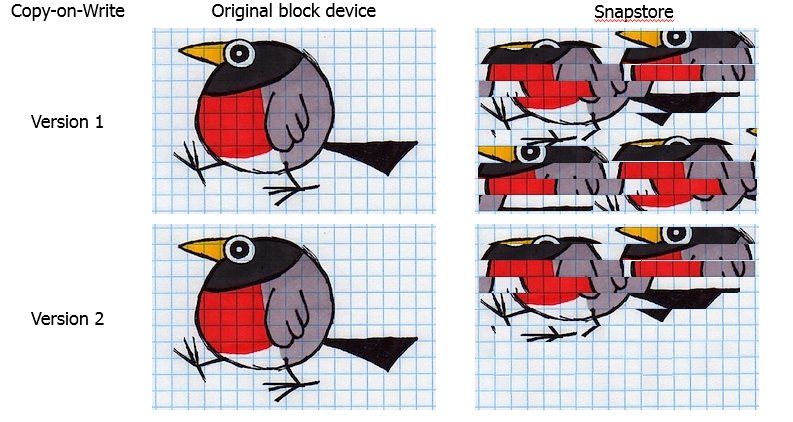 Naturellement, nous avons changé l'algorithme. Le volume est maintenant divisé en blocs et les données sont copiées dans le bloc d'accrochage. Si le bloc a déjà été copié une fois, ce processus n'est pas répété.
Naturellement, nous avons changé l'algorithme. Le volume est maintenant divisé en blocs et les données sont copiées dans le bloc d'accrochage. Si le bloc a déjà été copié une fois, ce processus n'est pas répété.Sélection de la taille des blocs
Maintenant, lorsque le snapstrap est divisé en blocs, la question se pose: quelle est en fait la taille des blocs à faire pour casser les snappoints?Le problème est double. Si le bloc est grand, il est plus facile pour eux de fonctionner, mais si au moins un secteur change, vous devez envoyer le bloc entier à la plate-forme et, par conséquent, les chances de trop remplir la plate-forme sont augmentées. De toute évidence, plus la taille du bloc est petite, plus le pourcentage de données utiles envoyées au snapstore est élevé, mais comment affectera-t-il les performances?Ils ont recherché la vérité empiriquement et ont trouvé 16 Ko. Notez également que Windows VSS utilise également 16 blocs de Kio.
De toute évidence, plus la taille du bloc est petite, plus le pourcentage de données utiles envoyées au snapstore est élevé, mais comment affectera-t-il les performances?Ils ont recherché la vérité empiriquement et ont trouvé 16 Ko. Notez également que Windows VSS utilise également 16 blocs de Kio.Au lieu d'une conclusion
C'est tout pour l'instant. Je laisserai bien d'autres problèmes non moins intéressants, tels que la dépendance aux versions du noyau, le choix des options de distribution des modules, la compatibilité kABI, le travail dans les conditions de backport, etc. L'article s'est avéré volumineux et j'ai donc décidé de m'attarder sur les problèmes les plus intéressants.Nous préparons maintenant la version 3.0, le code du module est sur github , et n'importe qui peut l'utiliser sous la licence GPL.