Pour ceux qui ont aimé mon
article précédent , je continue à partager mes impressions sur l'outil de test de stress acridien.
Je vais essayer de démontrer clairement les avantages de l'écriture d'un python de test de charge avec du code dans lequel vous pouvez facilement préparer toutes les données pour le test et traiter les résultats.
Traitement des réponses du serveur
Parfois, lors des tests de charge, il ne suffit pas d'obtenir simplement 200 OK du serveur HTTP. Arrive, il est nécessaire de vérifier le contenu de la réponse pour s'assurer que sous charge le serveur émet les données correctes ou effectue des calculs précis. Juste pour de tels cas, Locust a ajouté la possibilité de remplacer les paramètres de réussite de la réponse du serveur. Prenons l'exemple suivant:
from locust import HttpLocust, TaskSet, task import random as rnd class UserBehavior(TaskSet): @task(1) def check_albums(self): photo_id = rnd.randint(1, 5000) with self.client.get(f'/photos/{photo_id}', catch_response=True, name='/photos/[id]') as response: if response.status_code == 200: album_id = response.json().get('albumId') if album_id % 10 != 0: response.success() else: response.failure(f'album id cannot be {album_id}') else: response.failure(f'status code is {response.status_code}') class WebsiteUser(HttpLocust): task_set = UserBehavior min_wait = 1000 max_wait = 2000
Il n'a qu'une seule demande, ce qui créera une charge dans le scénario suivant:
À partir du serveur, nous demandons des objets photos avec un identifiant aléatoire compris entre 1 et 5000 et vérifions l'identifiant de l'album dans cet objet, en supposant qu'il ne peut pas être un multiple de 10
Ici, vous pouvez immédiatement donner quelques explications:
- la construction impressionnante avec request () comme réponse: vous pouvez le remplacer avec succès par response = request () et travailler tranquillement avec l'objet de réponse
- L'URL est formée en utilisant la syntaxe de format de chaîne ajoutée en python 3.6, si je ne me trompe pas - f '/ photos / {photo_id}' . Dans les versions précédentes, cette conception ne fonctionnera pas!
- un nouvel argument que nous n'avions pas utilisé auparavant, catch_response = True , indique à Locust que nous déterminerons nous-mêmes le succès de la réponse du serveur. Si vous ne le spécifiez pas, nous recevrons l'objet réponse de la même manière et nous pourrons traiter ses données, mais pas redéfinir le résultat. Voici un exemple détaillé.
- Un autre nom d' argument = '/ photos / [id]' . Il est nécessaire de regrouper les demandes en statistiques. Le nom peut être n'importe quel texte, la répétition de l'url n'est pas nécessaire. Sans cela, chaque demande avec une adresse ou des paramètres uniques sera enregistrée séparément. Voici comment cela fonctionne:
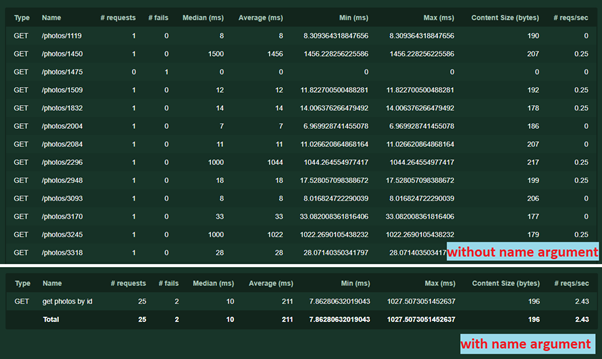
En utilisant le même argument, vous pouvez effectuer une autre astuce - il arrive parfois qu'un service avec différents paramètres (par exemple, différents contenus de requêtes POST) exécute une logique différente. Pour que les résultats du test ne se mélangent pas, vous pouvez écrire plusieurs tâches distinctes, en spécifiant pour chacune son propre
nom d' argument.
Ensuite, nous faisons les vérifications. J'en ai 2. Tout d'abord, nous vérifions que le serveur a retourné une réponse si
response.status_code == 200 :
Si oui, vérifiez si l'ID de l'album est un multiple de 10. Si ce n'est pas un multiple, marquez cette réponse comme une
réponse réussie.success ()Dans d'autres cas, nous indiquons pourquoi la réponse a échoué
response.failure («texte d'erreur») . Ce texte sera affiché sur la page Échecs pendant le test.
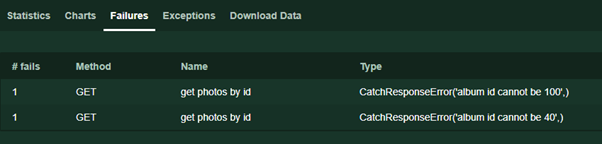
De plus, les lecteurs attentifs pourraient remarquer l'absence d'exceptions caractéristiques du code qui fonctionne avec les interfaces réseau. En effet, en cas de timeout, erreur de connexion et autres incidents imprévus, Locust traitera les erreurs et restituera toujours une réponse, indiquant cependant que le statut du code de réponse est 0.
Si le code lève toujours une exception, il sera écrit dans l'onglet Exceptions au moment de l'exécution afin que nous puissions le gérer. La situation la plus typique est que le json'e de la réponse n'a pas retourné la valeur que nous recherchions, mais nous y effectuons déjà les opérations suivantes.
Avant de fermer le sujet - dans l'exemple, j'utilise le serveur json pour plus de clarté, car il est plus facile de traiter les réponses. Mais vous pouvez travailler avec le même succès avec HTML, XML, FormData, les pièces jointes et autres données utilisées par les protocoles HTTP.
Travailler avec des scénarios complexes
Presque chaque fois que la tâche consiste à effectuer des tests de charge d'une application Web, il devient rapidement clair qu'il est impossible de fournir une couverture décente avec les seuls services GET - qui renvoient simplement des données.
Exemple classique: pour tester une boutique en ligne, il est souhaitable que l'utilisateur
- Ouverture du magasin principal
- Je cherchais des marchandises
- Détails des éléments ouverts
- Article ajouté au panier
- Payé
À partir de l'exemple, nous pouvons supposer que les services d'appel dans un ordre aléatoire ne fonctionneront pas, uniquement de manière séquentielle. De plus, les marchandises, les paniers et les modes de paiement peuvent avoir des identifiants uniques pour chaque utilisateur.
En utilisant l'exemple précédent, avec des modifications mineures, vous pouvez facilement implémenter le test d'un tel scénario. Nous adaptons l'exemple pour notre serveur de test:
- L'utilisateur écrit un nouveau message.
- L'utilisateur écrit un commentaire sur le nouveau message
- L'utilisateur lit le commentaire
from locust import HttpLocust, TaskSet, task class FlowException(Exception): pass class UserBehavior(TaskSet): @task(1) def check_flow(self):
Dans cet exemple, j'ai ajouté une nouvelle classe
FlowException . Après chaque étape, si cela ne s'est pas passé comme prévu, je lance cette classe d'exception pour abandonner le script - si le message n'a pas fonctionné, il n'y aura rien à commenter, etc. Si vous le souhaitez, la construction peut être remplacée par le
retour habituel, mais dans ce cas, au moment de l'exécution et lors de l'analyse des résultats, il ne sera pas si clair où le script exécuté se trouve dans l'onglet Exceptions. Pour la même raison, je n'utilise pas la
méthode try ... except .
Rendre la charge réaliste
Maintenant, on peut me reprocher - dans le cas de la boutique, tout est vraiment linéaire, mais l'exemple des articles et des commentaires est trop tiré par les cheveux - ils lisent les articles 10 fois plus souvent qu'ils n'en créent. Raisonnablement, rendons l'exemple plus viable. Et il y a au moins 2 approches:
- Vous pouvez «coder en dur» la liste des publications que les utilisateurs lisent et simplifier le code de test s'il y a une telle possibilité et la fonctionnalité du backend ne dépend pas de publications spécifiques
- Enregistrez les articles créés et lisez-les s'il n'est pas possible de prédéfinir la liste des articles ou la charge réaliste dépend des articles lus (j'ai supprimé la création de commentaires de l'exemple pour rendre son code plus petit et plus visuel)
from locust import HttpLocust, TaskSet, task import random as r class UserBehavior(TaskSet): created_posts = [] @task(1) def create_post(self): new_post = {'userId': 1, 'title': 'my shiny new post', 'body': 'hello everybody'} post_response = self.client.post('/posts', json=new_post) if post_response.status_code != 201: return post_id = post_response.json().get('id') self.created_posts.append(post_id) @task(10) def read_post(self): if len(self.created_posts) == 0: return post_id = r.choice(self.created_posts) self.client.get(f'/posts/{post_id}', name='read post') class WebsiteUser(HttpLocust): task_set = UserBehavior min_wait = 1000 max_wait = 2000
Dans la classe
UserBehavior, j'ai créé une liste
created_posts . Faites particulièrement attention - il s'agit d'un objet qui n'a pas été créé dans le constructeur de la
classe __init __ (), par conséquent, contrairement à la session client, cette liste est commune à tous les utilisateurs. La première tâche crée un article et écrit son identifiant dans la liste. Le second - 10 fois plus souvent, lit un article sélectionné au hasard dans la liste. Une condition supplémentaire de la deuxième tâche consiste à vérifier s'il existe des postes créés.
Si nous voulons que chaque utilisateur ne fonctionne qu'avec ses propres données, nous pouvons les déclarer dans le constructeur comme suit:
class UserBehavior(TaskSet): def __init__(self, parent): super(UserBehavior, self).__init__(parent) self.created_posts = list()
Quelques fonctionnalités supplémentaires
Pour le lancement séquentiel des tâches, la documentation officielle suggère que nous utilisons également l'annotation de tâche @seq_task (1), en spécifiant le numéro de série de la tâche dans l'argument
class MyTaskSequence(TaskSequence): @seq_task(1) def first_task(self): pass @seq_task(2) def second_task(self): pass @seq_task(3) @task(10) def third_task(self): pass
Dans cet exemple, chaque utilisateur exécutera d'abord
first_task , puis
second_task , puis 10 fois
third_task .
Franchement, la disponibilité d'une telle opportunité plaît, mais, contrairement aux exemples précédents, il n'est pas clair comment transférer les résultats de la première tâche à la seconde si nécessaire.
De plus, pour des scénarios particulièrement complexes, il est possible de créer des ensembles de tâches imbriqués, en fait, en créant plusieurs classes TaskSet et en se connectant entre elles.
from locust import HttpLocust, TaskSet, task class Todo(TaskSet): @task(3) def index(self): self.client.get("/todos") @task(1) def stop(self): self.interrupt() class UserBehavior(TaskSet): tasks = {Todo: 1} @task(3) def index(self): self.client.get("/") @task(2) def posts(self): self.client.get("/posts") class WebsiteUser(HttpLocust): task_set = UserBehavior min_wait = 1000 max_wait = 2000
Dans l'exemple ci-dessus, avec une probabilité de 1 à 6, le script
Todo sera lancé et sera exécuté jusqu'à ce que, avec une probabilité de 1 à 4, il revienne au script
UserBehavior . Il est très important que vous
appeliez self.interrupt () - sans cela, les tests se concentreront sur la sous-tâche.
Merci d'avoir lu. Dans le dernier article, j'écrirai sur les tests distribués et les tests sans interface utilisateur, ainsi que sur les difficultés que j'ai rencontrées lors des tests avec Locust et comment les contourner.