
Habr, ceci est un rapport de l'ingénieur logiciel Alexei Starkov lors de la conférence Moscow Python Conf ++ 2018 à Moscou. Vidéo à la fin du post.
Bonjour à tous! Je m'appelle Alexei Starkov - c'est moi, dans mes meilleures années, je travaille dans une usine.
Maintenant, je travaille chez Qrator Labs. En gros, toute ma vie, j'ai étudié le C et le C ++ - j'adore Alexandrescu, The Gang of Four, les principes de SOLID - c'est tout. Ce qui fait de moi un astronaute architectural. J'écris du Python depuis quelques années parce que j'aime ça.
En fait, qui sont les «cosmonautes architecturaux»? La première fois que j'ai rencontré ce terme avec Joel Spolsky, vous l'avez probablement lu. Il décrit les «astronautes» comme des gens qui veulent construire une architecture idéale qui tient à l'abstraction, à l'abstraction, à l'abstraction, qui devient de plus en plus générale. En fin de compte, ces niveaux vont si haut qu'ils décrivent tous les programmes possibles, mais ne résolvent aucun problème pratique. En ce moment, "l'astronaute" (c'est la dernière fois que ce terme est entouré de guillemets) manque d'air et il meurt.
J'ai également des tendances vers l'exploration spatiale architecturale, mais dans ce rapport, je vais parler un peu de la façon dont cela m'a mordu et ne m'a pas permis de construire un système avec les performances nécessaires. L'essentiel est de savoir comment je l'ai surmonté.
Résumé de mon rapport: était / était.

Une augmentation de milliers et de millions de fois. Quand j'ai fait cette diapositive, la seule pensée que j'avais était "Comment?"

Où pourrais-je tant bousiller? Si vous ne voulez pas foirer comme moi, lisez la suite.

Je vais parler du système de configuration. Le système de configuration est un outil interne dans Qrator Labs qui stocke les configurations pour le Software Defined Network (SDN) - notre réseau de filtrage. Il s'engage à synchroniser la configuration entre les composants et à surveiller son état.

En quoi consiste-t-il, en bref,? Nous avons une base de données qui stocke un instantané de notre configuration pour l'ensemble du réseau, et nous avons un serveur qui traite les commandes qui lui parviennent et modifie en quelque sorte la configuration.
Nos administrateurs techniques et nos clients viennent sur ce serveur et via la console, via les API de point d'extrémité, les API REST, JSON RPC et d'autres choses, émettent des commandes vers le serveur, ce qui modifie notre configuration.
Les équipes peuvent être très simples ou plus compliquées. Ensuite, nous avons un certain ensemble de récepteurs qui composent notre SDN et le serveur envoie la configuration à ces récepteurs. Cela semble assez simple. Fondamentalement, je vais parler de cette partie.
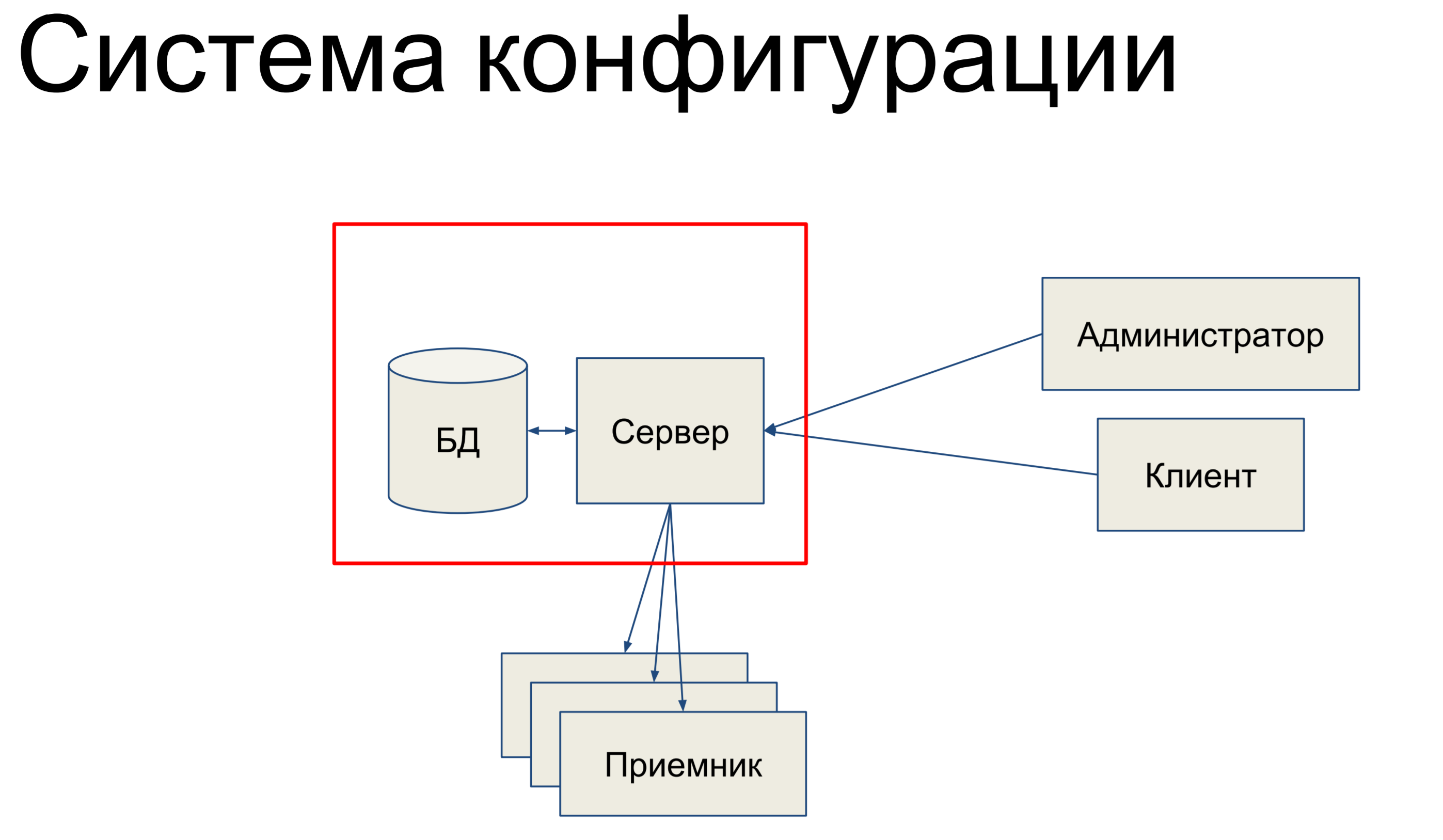
Puisque c'est elle qui est liée à la base de données et à l'alchimie.

Quelle est la particularité de ce système? C'est assez petit - médiocre. Des centaines de milliers, voire des millions, d'entités sont stockées dans cette base de données. La particularité est que le graphe des relations entre entités est assez complexe. Il existe plusieurs hiérarchies d'héritage entre les entités, il y a des inclusions, il y a simplement des dépendances entre elles. Toutes ces restrictions sont déterminées par la logique métier et nous devons nous y conformer.
Le rapport des demandes d'écriture aux demandes de lecture est d'environ 15: 1. Ici, c'est clair: il y a beaucoup de commandes pour changer la configuration et une fois dans un certain laps de temps, nous avons poussé la configuration aux points finaux.
MySQL est utilisé en interne - il est également disponible dans d'autres produits de notre société, nous avons une expertise assez sérieuse sur cette base de données, il y a des gens qui peuvent travailler avec elle: construire un schéma de données, concevoir des requêtes et tout le reste. Par conséquent, nous avons pris MySQL comme une base de données relationnelle universelle.

Quel était le problème après avoir conçu ce système? L'exécution d'une commande a duré de une à trente secondes, selon la complexité de l'équipe. En conséquence, le retard dans l'exécution a atteint cinq minutes. Une équipe est arrivée - 30 secondes, la seconde et ainsi de suite, une pile de accumulés - un retard de 5 minutes.
Le retard dans l'application de la configuration peut aller jusqu'à dix minutes. Il a été décidé que cela ne nous suffisait pas et qu'une optimisation était nécessaire.

Tout d'abord, avant de procéder à toute optimisation, il est nécessaire de mener une enquête et de découvrir en fait quel est le problème.

Il s'est avéré que nous n'avions pas l'élément le plus important pour l'enquête - nous n'avions pas de télémétrie. Par conséquent, si vous concevez une sorte de système, tout d'abord, au stade de la conception, mettez-y de la télémétrie. Même si le système est initialement petit, puis un peu plus, puis encore plus - à la fin, tout le monde arrive à une situation où vous devez regarder des pistes, mais il n'y a pas de télémétrie.
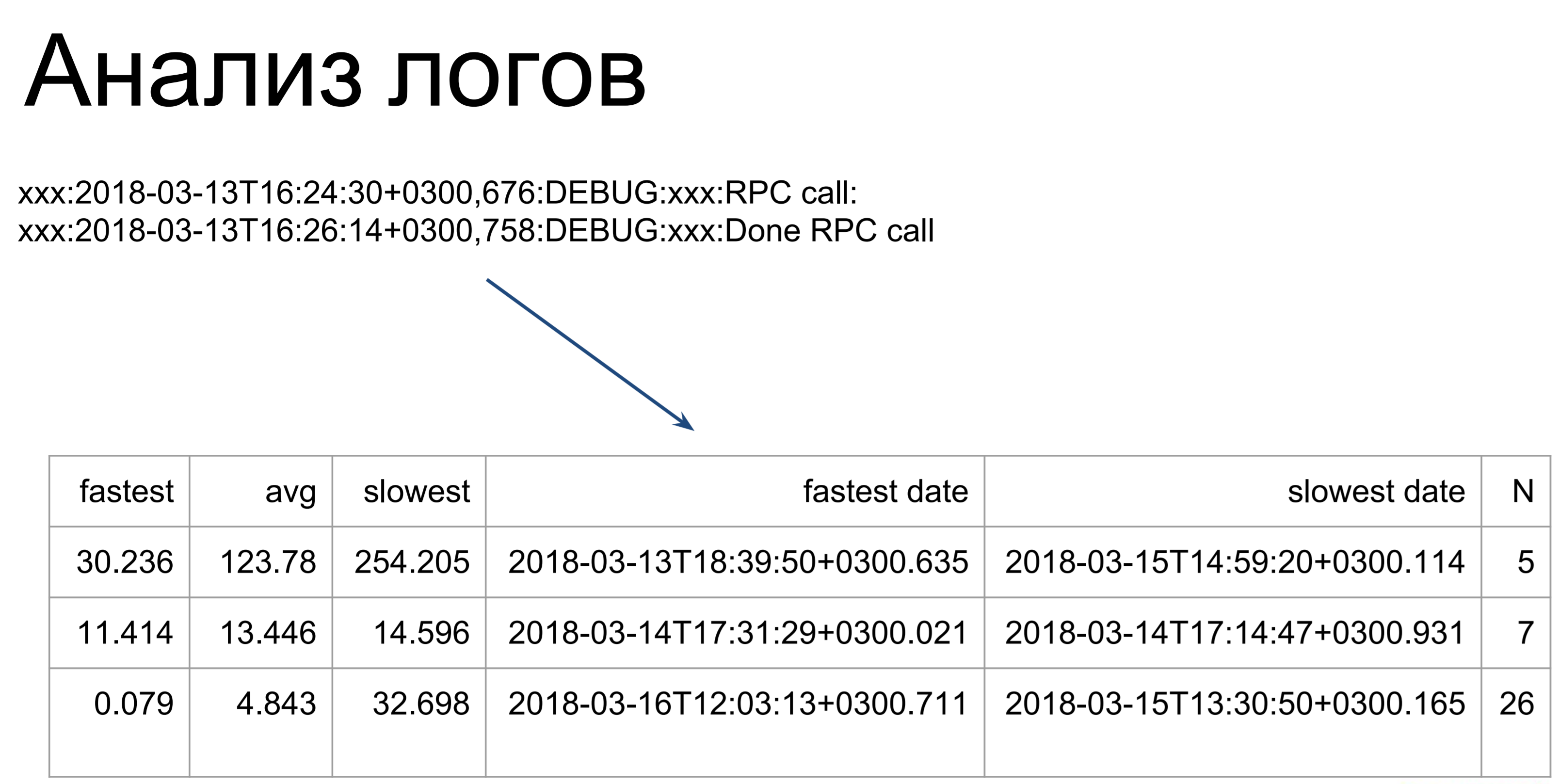
Que faire ensuite si vous n'avez pas de télémétrie? Vous pouvez analyser les journaux. Ici, des scripts assez simples parcourent nos journaux et les transforment en un tel tableau, illustrant les temps d'exécution des commandes les plus rapides, les plus lents et les plus moyens. À partir d'ici, nous pouvons déjà voir dans quels endroits nous avons des gags: quelles équipes mettent plus de temps à exécuter, lesquelles plus rapidement.

La seule chose à noter est que lors de l'analyse des journaux, nous ne considérons que le temps d'exécution de ces commandes sur le serveur. Il s'agit de la première étape - celle marquée comme t2. t1 - c'est ainsi que le client verra le temps d'exécution de notre équipe: mise en file d'attente, attente, exécution sur le serveur. Ce temps sera plus long, nous optimisons donc le temps t2, puis utilisons le temps t1 pour déterminer si nous avons atteint l'objectif.
t1 est la métrique de qualité de notre performance.

En conséquence, c'est ainsi que nous avons profilé toutes les équipes - c'est-à-dire que nous avons pris le journal du serveur, l'avons parcouru à travers nos scripts, regardé et identifié les composants qui fonctionnaient le plus lentement. Le serveur est construit de manière assez modulaire, un composant distinct est responsable de chaque commande, et nous pouvons profiler les composants individuellement - et faire des tests de performances pour eux. Nous avons donc eu ici une classe - pour chaque composant problématique que nous avons écrit dans lequel dans code_under_test () nous avons fait une activité décrivant l'utilisation au combat du composant. Et il y avait deux méthodes: profile () et bench (). Le premier appelle cProfile, montrant combien de fois ce qui a été appelé, où se trouvent les goulots d'étranglement.
bench () a été exécuté plusieurs fois et a considéré différentes mesures pour nous - c'est ainsi que nous avons évalué les performances.
Mais il s'est avéré que ce n'est pas le problème!

Le principal problème était le nombre de requêtes de base de données. Il y avait beaucoup de demandes, et pour comprendre pourquoi il y en avait tellement, regardons comment tout était organisé.
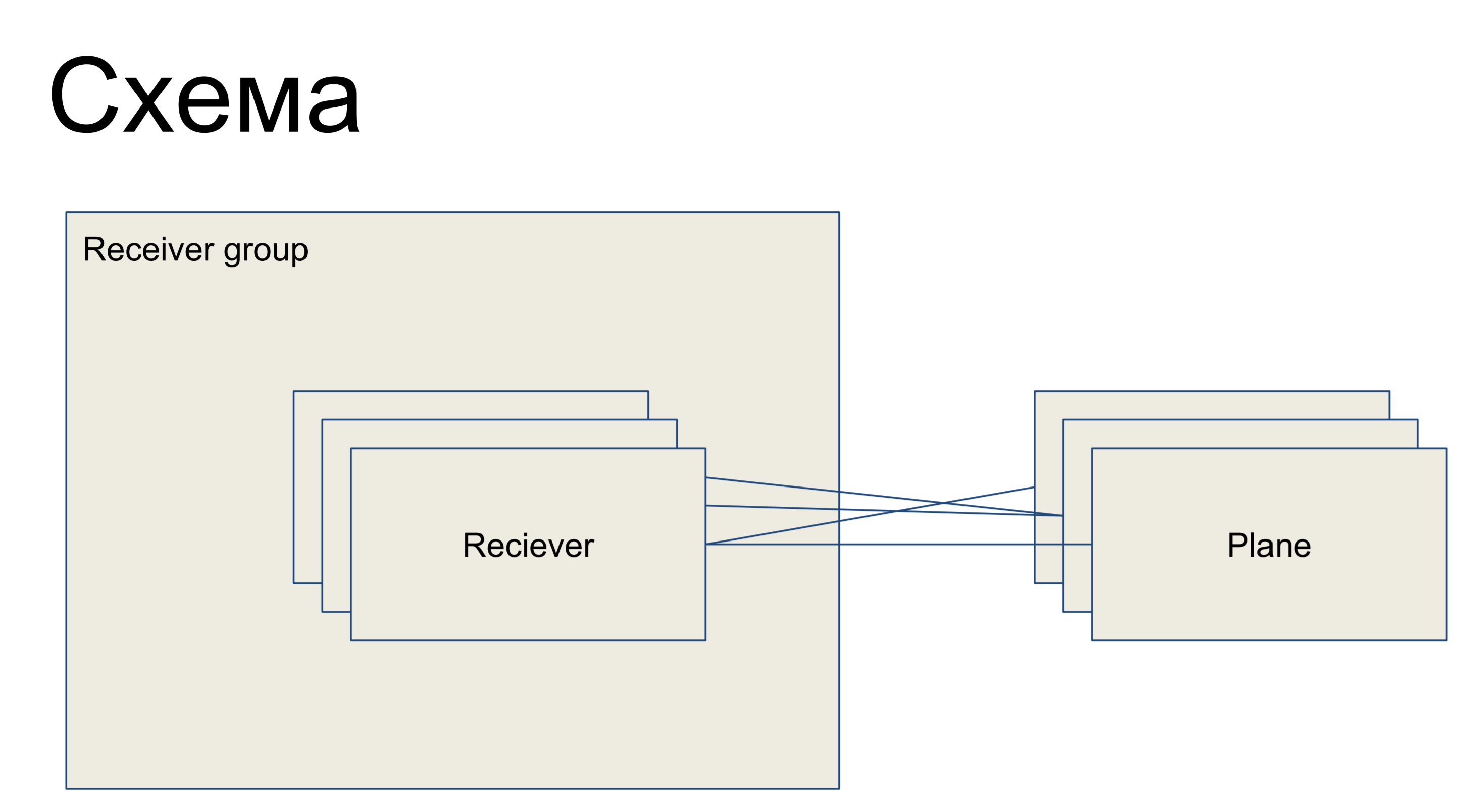
Devant nous est un morceau d'un circuit simple représentant nos récepteurs, présenté sous la forme de la classe Récepteur. Ils sont unis dans un groupe - groupe récepteur. Et, en conséquence, il existe certains plans de configuration - des tranches de la configuration, qui sont un sous-ensemble des configurations qui sont responsables d'un «rôle» de ce récepteur. Par exemple, pour le routage - plan de routage. Les plaines avec des récepteurs peuvent être connectées dans n'importe quel ordre - c'est-à-dire qu'il s'agit d'une relation plusieurs-à-plusieurs.
Ceci est une partie du grand schéma que je présente ici afin que les exemples puissent être mieux compris.
Que veut faire chaque cosmonaute architectural lorsqu'il voit l'API de quelqu'un d'autre? Il veut le cacher, résumer et écrire son interface afin de pouvoir supprimer cette API, ou plutôt la cacher.
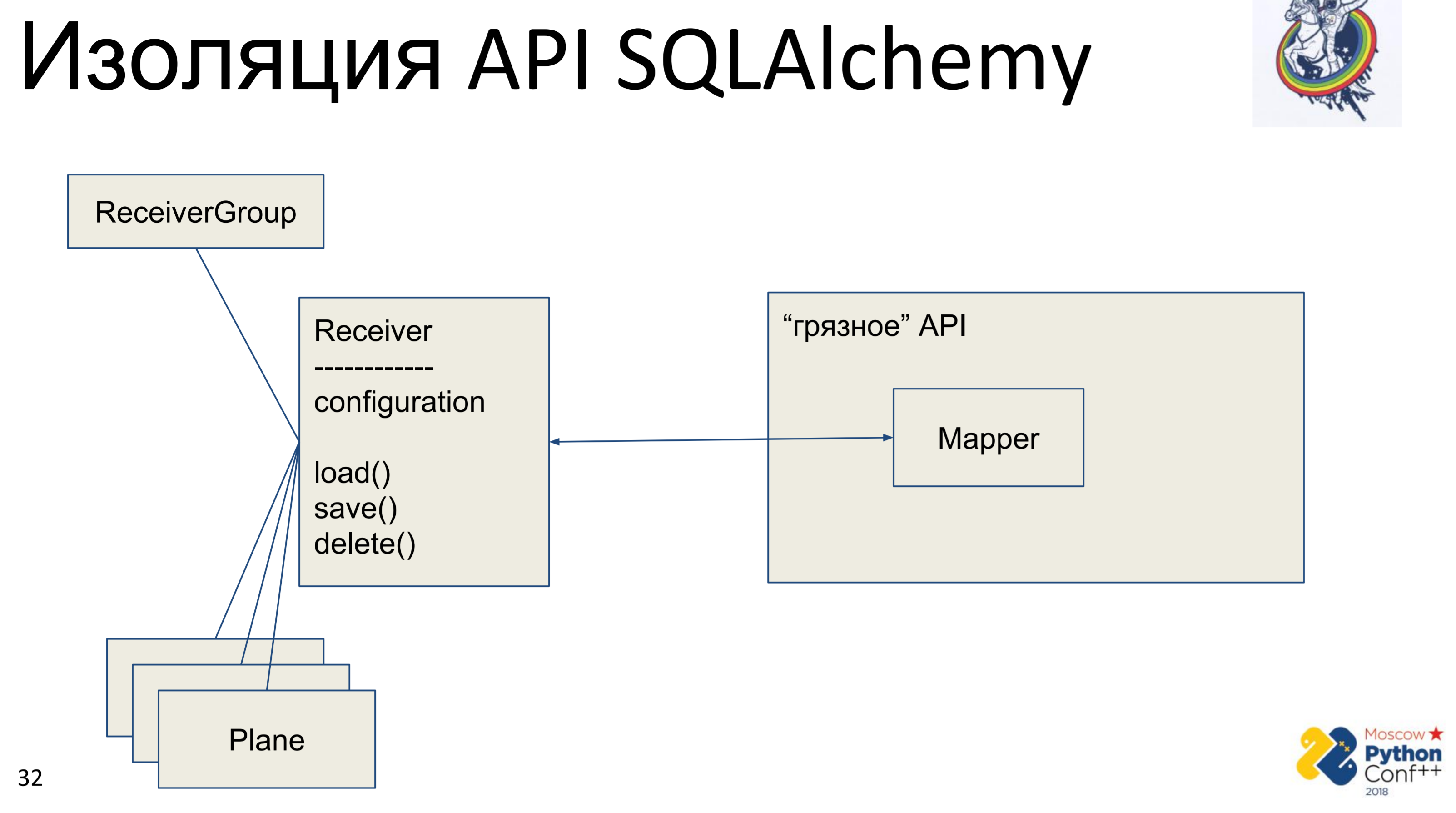
En conséquence, il existe une API d'alchimie «sale», dans laquelle il y a, en fait, des mappeurs et notre classe «pure» - Receiver, dans laquelle une certaine configuration est stockée et il existe des méthodes: load (), save (), delete (). Et toutes les autres classes qui lui sont associées. Nous obtenons un graphique des objets Python, en quelque sorte connectés les uns aux autres - chacun d'eux a une méthode load (), save (), delete (), qui fait référence au mappeur d'alchimie, qui, à son tour, appelle l'API.

La mise en œuvre ici est très simple. Nous avons une méthode de chargement qui fait une requête dans la base de données et pour chaque objet reçu crée son propre objet Python. Il existe une méthode de sauvegarde qui effectue l'opération inverse - elle recherche s'il y a un objet dans la base de données à l'aide de la clé primaire, sinon - elle crée, ajoute, puis nous enregistrons l'état de cet objet. supprimer sur la clé primaire reçoit et supprime l'objet de la base de données.

Le problème principal est immédiatement visible - c'est la cartographie. D'abord, nous le faisons une fois de l'objet Python au mappeur, puis du mappeur à la base. Le mappage supplémentaire est un ou deux appels, ce qui n'est peut-être pas encore si effrayant. Le problème principal était la synchronisation manuelle. Nous avons deux objets de notre interface «propre» et l'un d'eux change l'attribut - comment voyons-nous que l'attribut a changé dans l'autre? Pas question. Il est nécessaire de fusionner les modifications dans la base de données et d'obtenir l'attribut dans un autre objet. Bien sûr, si nous savons que les objets sont présents dans le même contexte, nous pouvons en quelque sorte suivre cela. Mais si nous avons deux sessions dans des endroits différents - uniquement via la base, ou bloquons la base en mémoire, ce que nous n'avons pas fait.
Ce chargement / enregistrement / suppression est un autre mappeur qui duplique complètement l'intérieur de l'alchimie, qui est bien écrit et testé. Cet outil a de nombreuses années, il y a beaucoup d'aide sur Internet et sa duplication n'est pas très bonne non plus.
Vous voyez l'icône dans le coin supérieur droit? Je vais donc marquer les diapositives sur lesquelles quelque chose est fait pour la "pureté", pour augmenter le niveau d'abstraction, pour l'astronautique architecturale. Autrement dit, les diapositives sans cette icône sont pragmatiques et ennuyeuses, sans intérêt et ne peuvent pas être lues.
Que faire si de nombreuses requêtes sont lentes. Combien? En fait beaucoup. Imaginez une chaîne d'héritage: un objet, il a un parent, celui-ci a un autre parent. Nous synchronisons l'objet enfant - pour ce faire, vous devez d'abord synchroniser les parents. Pour synchroniser un parent, vous devez synchroniser son parent. Eh bien, tout le monde était synchronisé. En fait, selon la façon dont nous avons construit le graphe, nous pourrions parcourir et synchroniser tous ces objets cent fois - d'où un grand nombre de requêtes.
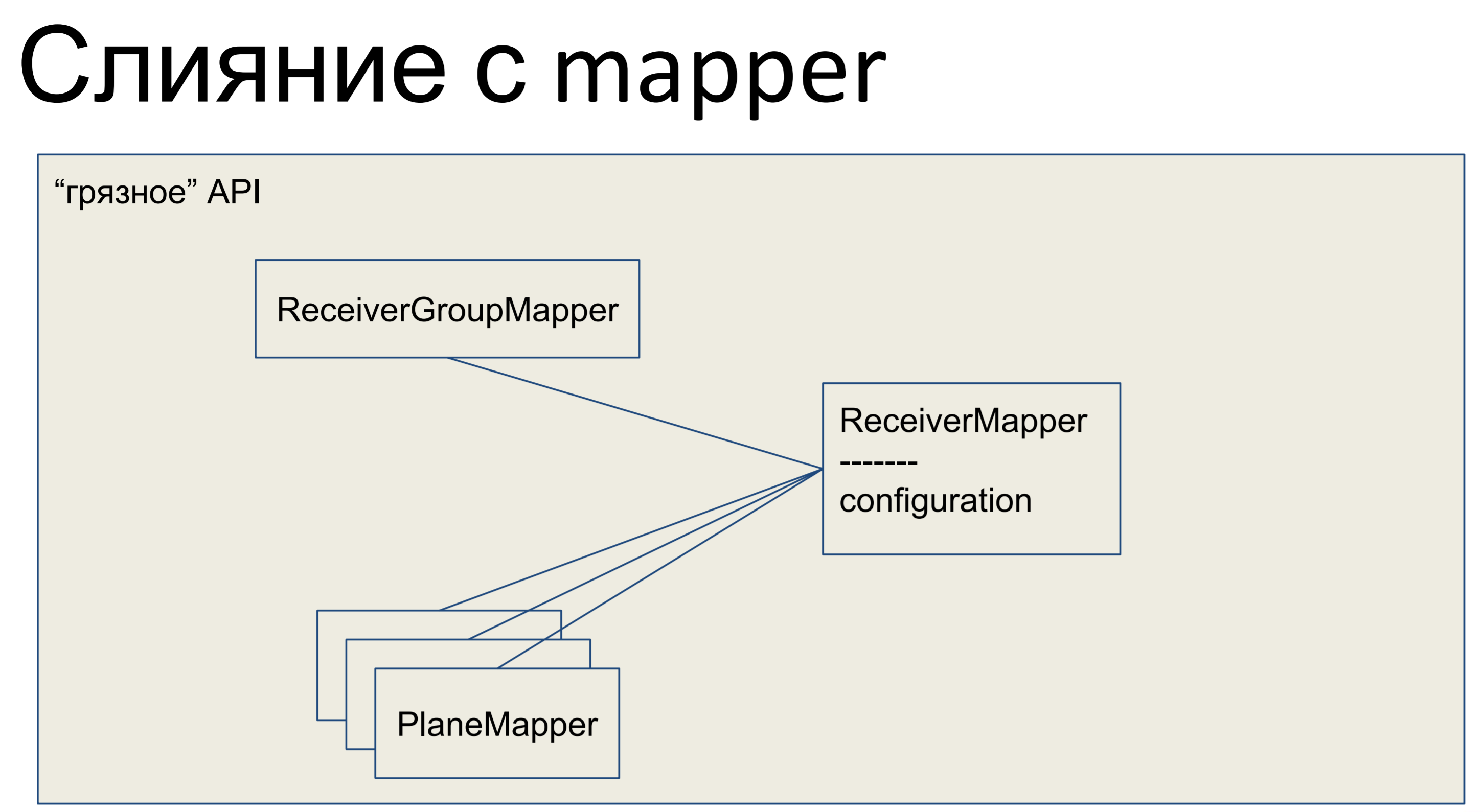
Qu'avons-nous fait? Nous avons pris toute notre logique métier et l'avons coincée dans le mappeur. Tous les autres objets ici ont également fusionné avec les mappeurs, et notre API entière, toute la couche d'abstraction des données, s'est avérée sale.

Voici à quoi cela ressemble en Python - notre mappeur a une sorte de logique métier, il y a une description déclarative de cette plaque là. Les colonnes sont répertoriées, les relations. Ici, nous avons une telle classe.

Bien sûr, du point de vue de tout astronaute, une API sale est un inconvénient. Logique métier dans une description déclarative de la base. Les schémas sont mélangés avec la logique métier. Ouf. Laid.
La description du circuit est encombrée. C'est en fait un problème - si la logique métier n'a pas deux lignes, mais un plus grand volume, alors dans cette classe, nous devons faire défiler ou rechercher très longtemps afin d'obtenir des descriptions spécifiques. Avant cela, tout était beau: à un endroit la description de la base, déclarative, la description des schémas, à un autre endroit la logique métier. Et puis le circuit est encombré.
Mais, d'autre part, nous obtenons immédiatement les mécanismes de l'alchimie: unité de travail, qui vous permet de suivre quels objets sont sales et quels relais doivent être mis à jour; nous obtenons une relation qui nous permet de nous débarrasser des questions supplémentaires dans la base de données, sans nous assurer que les collections pertinentes sont remplies; et la carte d'identité qui nous a le plus aidés. La carte d'identité garantit que deux objets Python seront le même objet Python s'ils ont la même clé primaire.
En conséquence, nous avons immédiatement réduit la complexité à linéaire.

Ce sont des résultats intermédiaires. Les performances ont immédiatement augmenté de 10 fois, le nombre de requêtes vers la base de données a diminué d'environ 40 à 80 fois et le RPS est passé à 1 à 5. Et bien. Mais l'API est sale. Que faire
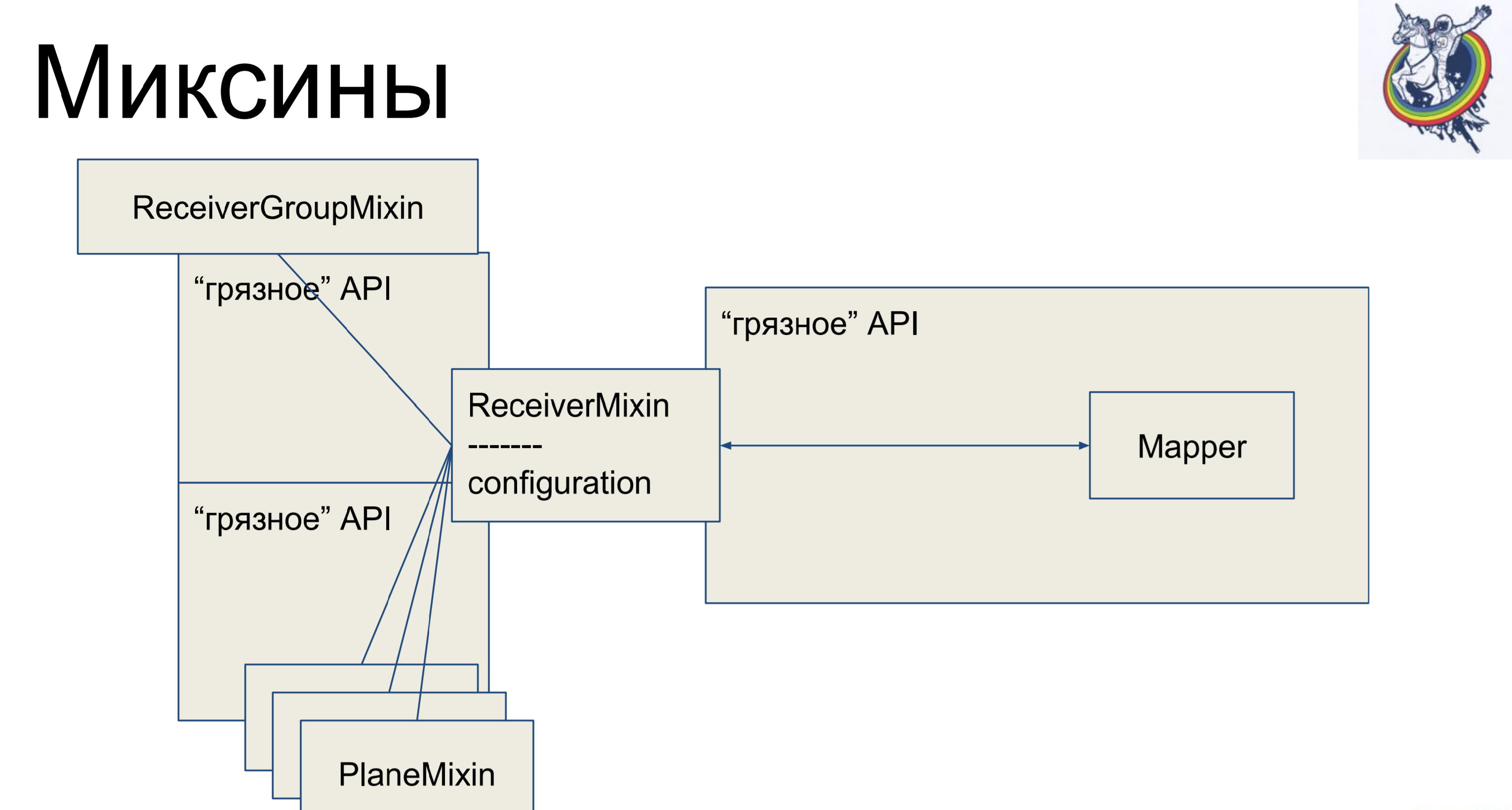
Mixins. Nous prenons la logique métier, nous la supprimons à nouveau de notre mappeur, mais pour qu'il n'y ait plus de mappage, nous hériterons de notre mappeur d'alchimie de notre mix. Pourquoi pas l'inverse? Cela ne fonctionnera pas en alchimie, elle jurera et dira: "Vous avez deux classes différentes faisant référence à une tablette, il n'y a pas de polyformisme - allez d'ici." Et donc - c'est possible.
Ainsi, nous avons une description déclarative dans le mappeur, qui est héritée du mixin et reçoit toute la logique métier. Très confortable. Et le reste des classes sont exactement les mêmes. Il semblerait - cool, tout est propre. Mais il y a une mise en garde - les connexions et les relais restent à l'intérieur de l'alchimie, et lorsque nous avons, disons, rejoint par une table secondaire de plaque intermédiaire, le mappeur de cette plaque sera en quelque sorte présent dans le code client, ce qui n'est pas très beau.
L'alchimie n'aurait pas été un cadre aussi bon et célèbre si elle ne m'avait pas donné l'occasion de lutter contre cela.

À quoi ressemble un mixin. Il a une logique métier, des mappeurs séparément, une description déclarative de la plaque. Les connexions restent dans l'alchimie, mais la logique métier est distincte.
À quoi ressemble le plan général?
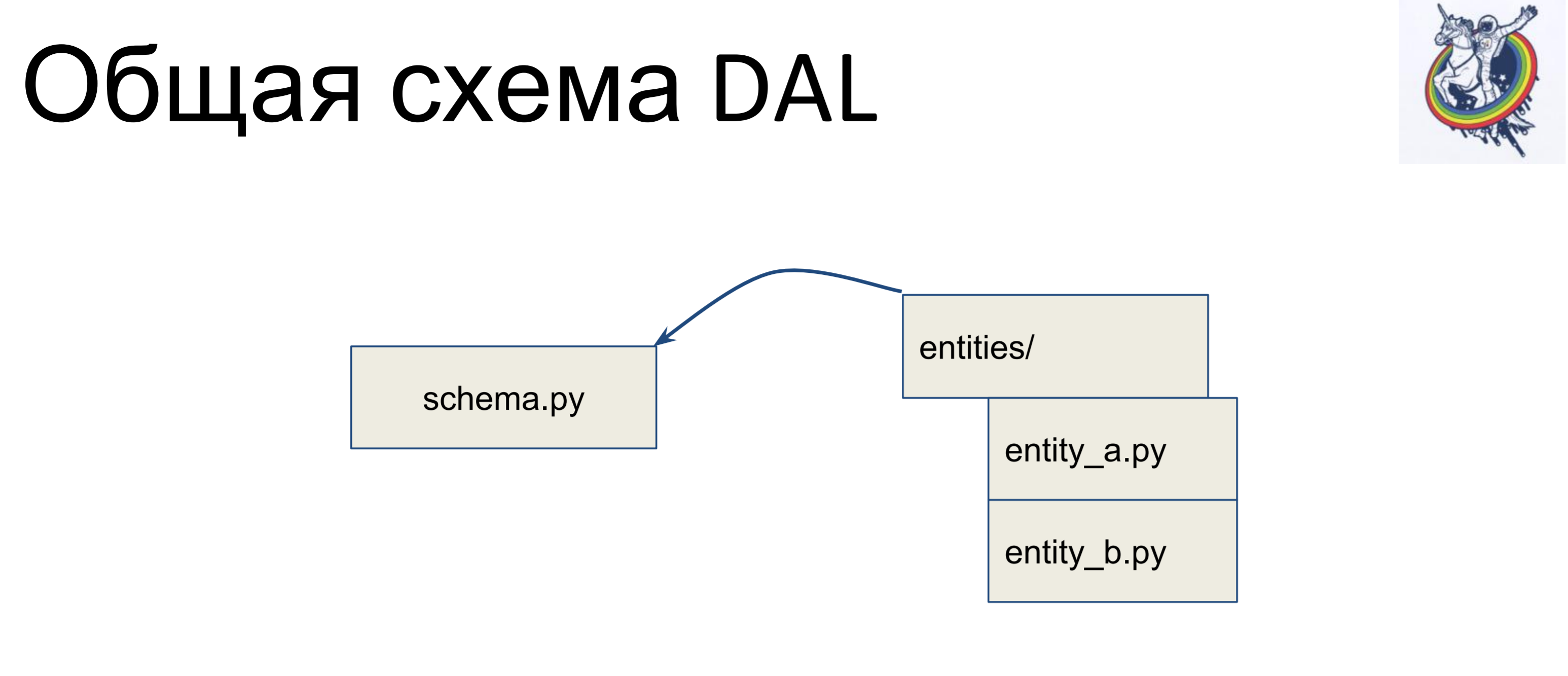
Nous avons un fichier avec un schéma dans lequel toutes nos classes déclaratives sont collectées - appelons-le schema.py. Et nous avons des entités dans la logique métier, séparément. Et, ces entités sont héritées à l'intérieur du fichier de schéma - nous écrivons une classe distincte pour chaque entité et l'héritons dans le schéma. Ainsi, la logique métier réside dans un tas, le schéma dans un autre et ils peuvent être modifiés indépendamment.
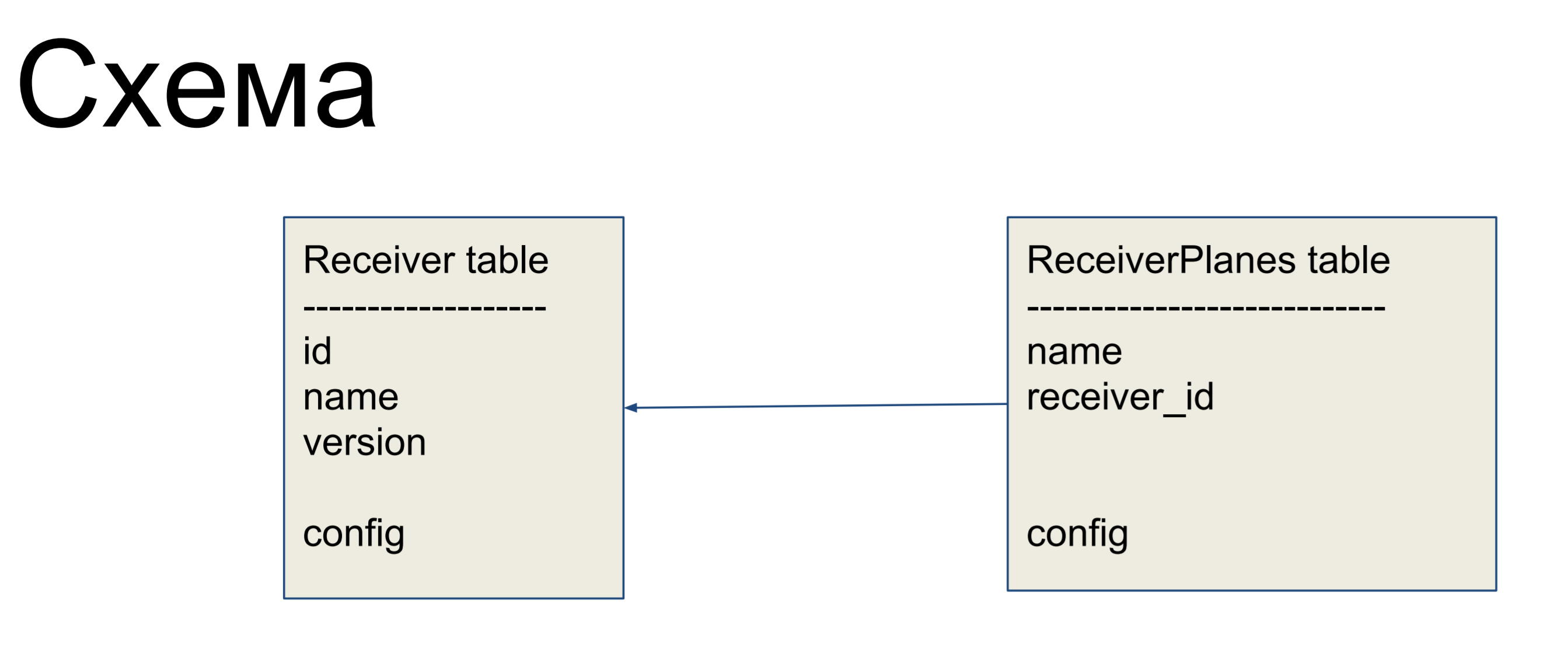
Comme exemple d'amélioration, nous considérerons un schéma simple de deux étiquettes: récepteurs (table Receiver) et tranches de la configuration (table ReceiverPlanes). Des tranches de configuration plusieurs à un sont associées à l'étiquette du récepteur. Il n'y a rien de particulièrement compliqué.
Afin de cacher les relations au sein de l'interface «sale» de l'alchimie, nous utilisons des relations et des collections.

Ils nous permettent de masquer nos mappeurs du code client.

En particulier, deux collections très utiles sont association_proxy et attribute_mapped_collection. Nous les utilisons ensemble. Comment fonctionne la relation classique en alchimie: nous avons une relation - il s'agit d'une certaine collection, liste, cartographes. Les mappeurs sont des objets de relation distants. Attribute_mapped_collection vous permet de remplacer cette liste par un dict, les clés dans lesquelles seront certains des attributs des mappeurs, et les valeurs sont les mappeurs eux-mêmes.
Ceci est la première étape.
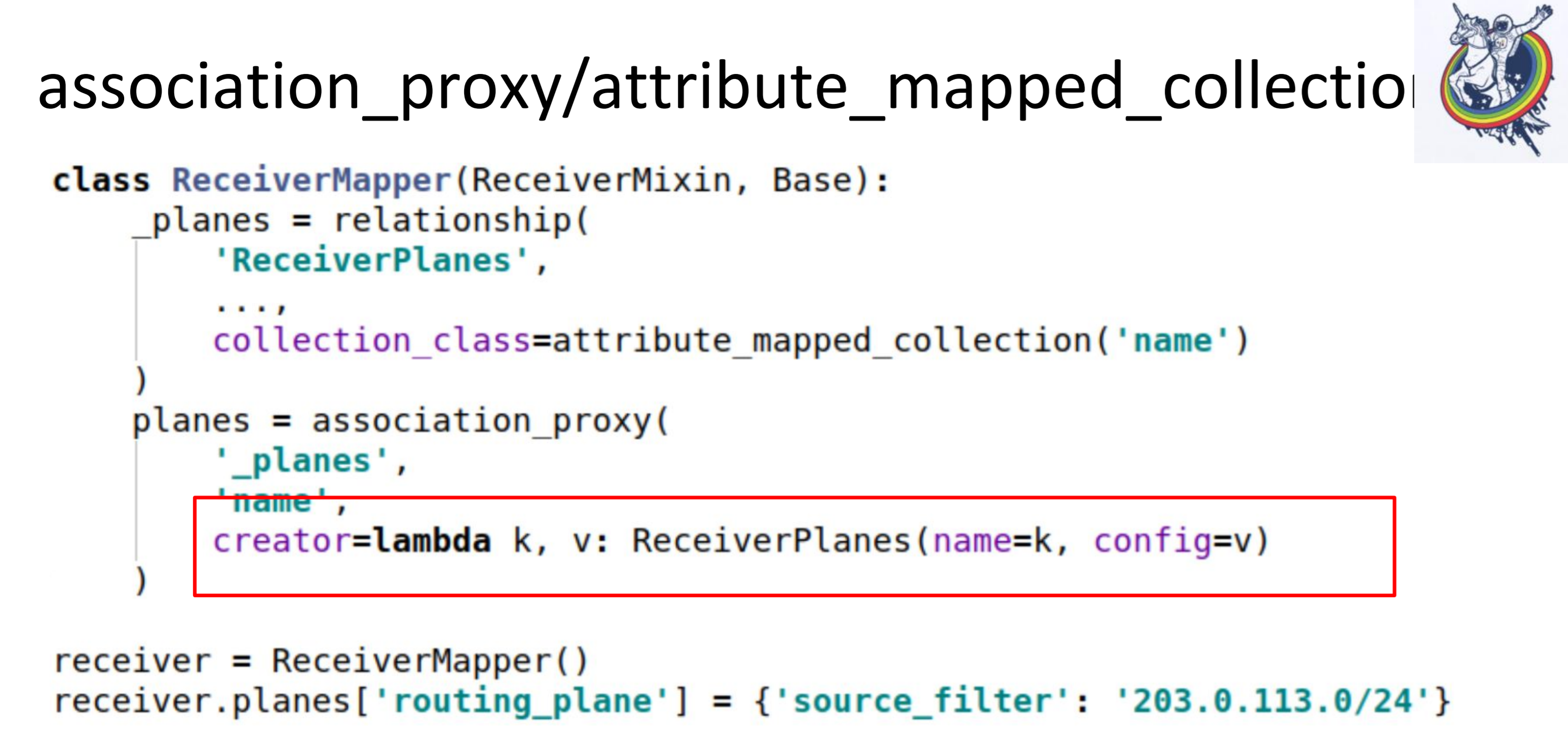
La deuxième étape, nous faisons association_proxy sur cette relation. Cela nous permet de ne pas transmettre le mappeur à la collection, mais de transmettre une valeur qui sera utilisée ultérieurement pour initialiser notre mappeur, ReceiverPlanes.
Ici, nous avons lambda, dans lequel nous transmettons la clé et la valeur. La clé devient le nom de la tranche de configuration et la valeur la valeur de la tranche de configuration. Par conséquent, dans le code client, tout ressemble à ceci.

Nous avons simplement mis une sorte de dictée dans une sorte de dictionnaire. Tout fonctionne: pas de mappeurs, pas d'alchimie, pas de bases de données.
Certes, il y a des pièges.

Si nous attribuons deux ou plusieurs valeurs différentes à la même clé deux fois - lambda est appelé pour chacun de ces éléments, un objet est créé - un mappeur. Et, selon la structure du système, cela peut entraîner diverses conséquences, allant de «simples violations des constantes» à des conséquences imprévisibles. Par exemple, vous avez en quelque sorte supprimé un objet de la collection, mais il y est resté: vous n'en avez supprimé qu'un. Quand j'ai commencé, j'ai tué beaucoup de temps sur de telles choses.
Et une petite synchronisation implicite. Association_proxy et attribute_mapped_collection peuvent être un peu retardés: lorsque nous créons un objet mappeur, il est ajouté à la base de données, mais il n'est pas encore présent dans l'attribut collection. Il n'y apparaîtra que lorsque l'attribut expirera dans cette session. À son expiration, une nouvelle synchronisation avec la base de données aura lieu et y arrivera.
Pour surmonter cela, nous avons utilisé nos propres collections auto-écrites. Ce n'est même pas de l'alchimie - vous pouvez simplement créer votre propre collection pour surmonter tout cela.
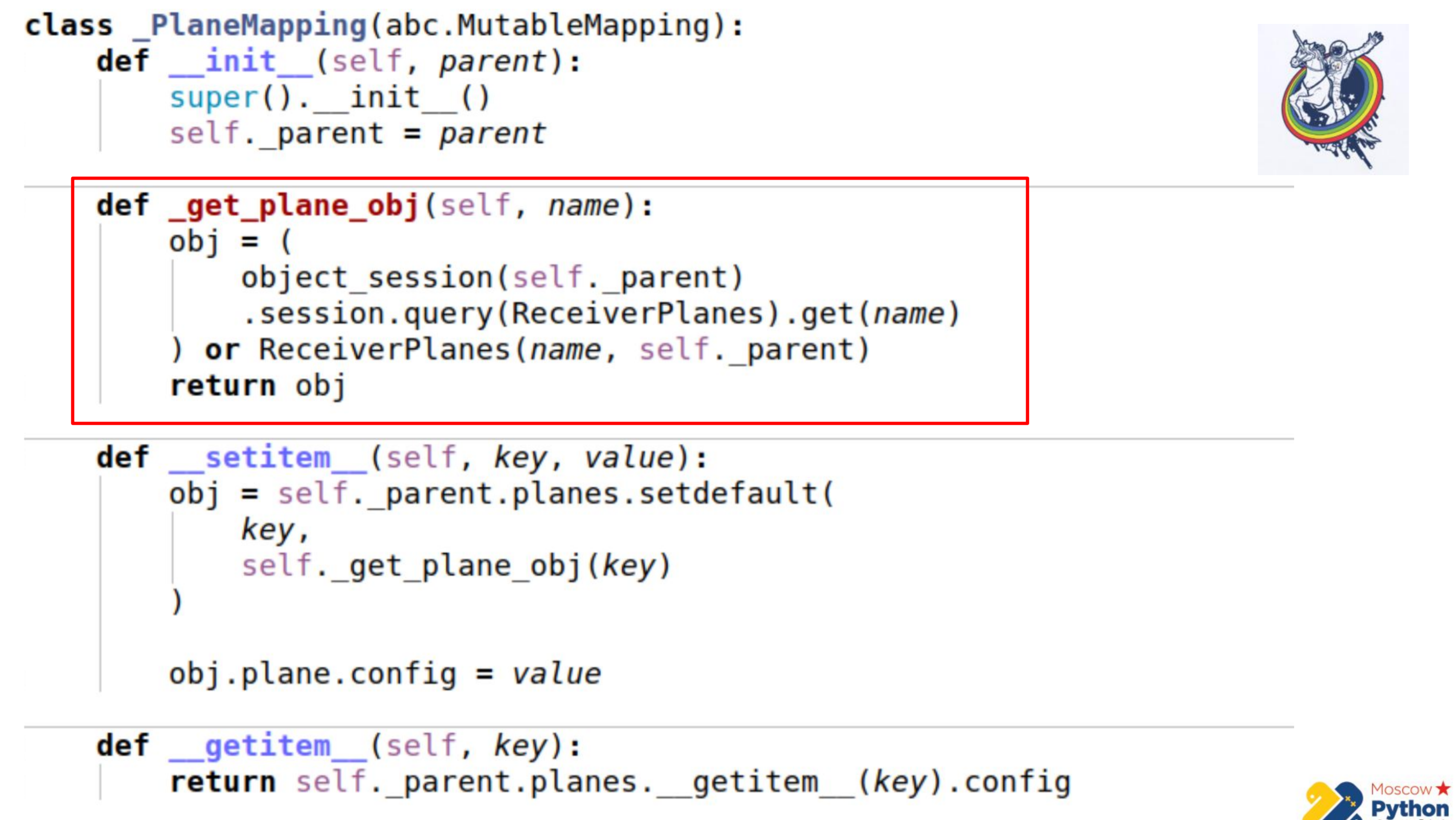
Il y a plus de code et la partie la plus importante est mise en évidence. Nous avons une certaine collection qui hérite de la cartographie mutable - c'est un dict, dans les clés duquel vous pouvez changer les valeurs. Et il existe une méthode _get_plane_obj - pour obtenir l'objet tranche de configuration.
Ici, nous faisons des choses simples - nous essayons de l'obtenir par nom, par une clé primaire et, si ce n'est pas le cas, nous créons et renvoyons cet objet.
Ensuite, nous redéfinissons seulement deux méthodes: __setitem__ et __getitem__
Dans __setitem__, nous mettons ces objets dans notre collection, en relation. La seule chose est que nous attribuons de la valeur à la toute fin. Ainsi, nous implémentons le même mécanisme que association_proxy - passez la valeur, dictez-la, et elle est affectée à l'attribut correspondant.
__getitem__ fait la manipulation inverse. Il reçoit par clé un objet du relais et retourne son attribut. Il y a aussi un petit piège ici - si vous mettez en cache la collection à l'intérieur de notre cartographie, il est possible de se désynchroniser un peu. Parce que lorsque l'attribut de la collection expire en alchimie, la collection est remplacée par une autre, après expiration. Par conséquent, nous pouvons conserver la référence à l'ancienne collection et ne pas savoir que l'ancienne a expiré et qu'une nouvelle est déjà apparue. Par conséquent, dans la dernière partie, nous allons directement à l'instance d'alchimie, encore une fois, nous obtenons la collection via __getattr__ et nous faisons __getitem__ avec. Autrement dit, nous ne pouvons pas mettre en cache la collection Planes ici.
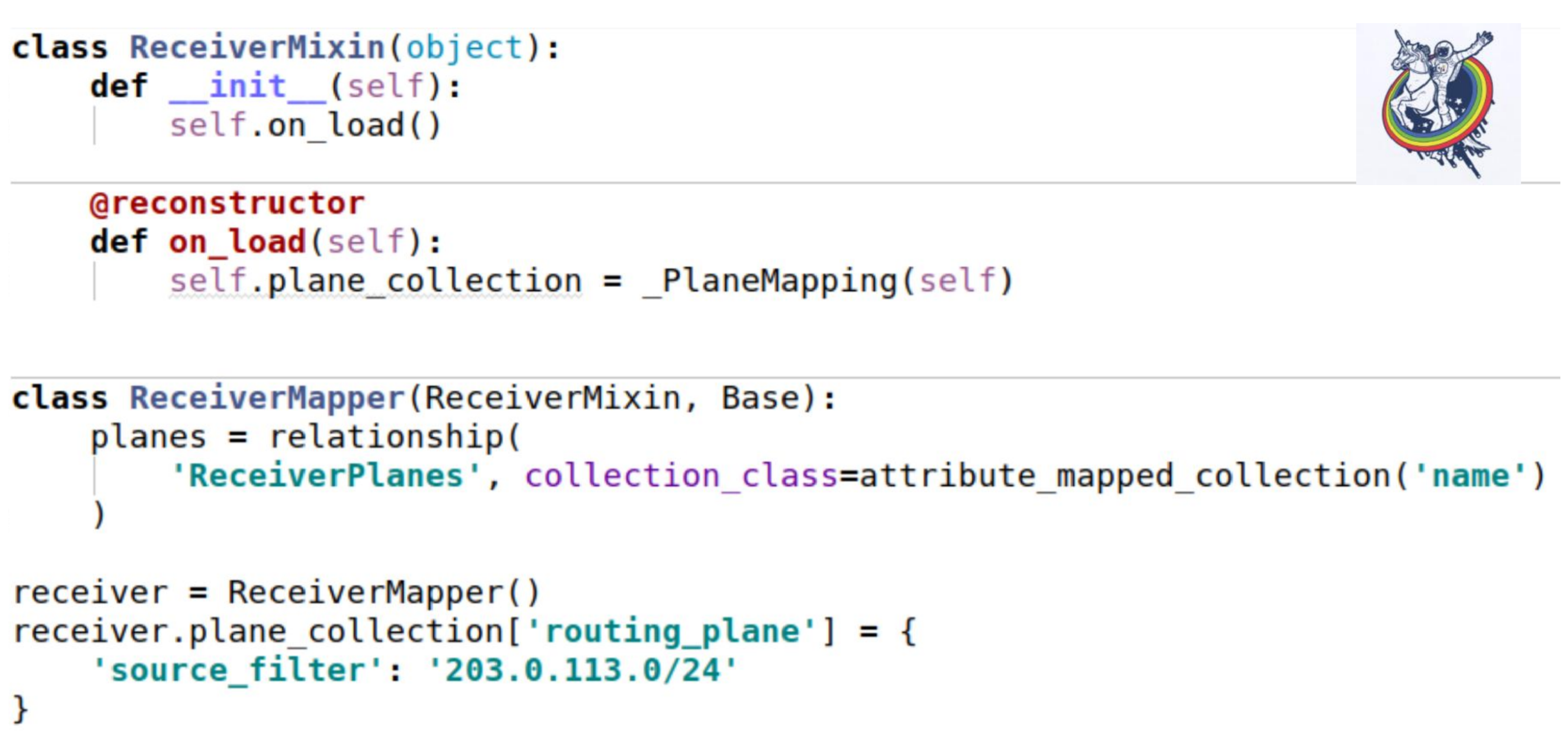
Comment cette collection gifle-t-elle nos mixins? Comme d'habitude - configurez un attribut de collection. Le seul endroit intéressant est que lorsque nous chargeons une instance à partir de la base de données, la méthode __init__ n'est pas appelée. Tous les attributs sont substitués ex post.
Alchemy propose un décorateur reconstructeur standard, qui vous permet de marquer une méthode comme étant appelée après le chargement d'un objet à partir de la base de données. Et juste au moment du démarrage, nous devons initialiser notre collection. Le moi n'est que cet exemple. L'utilisation est exactement la même que dans l'exemple précédent.
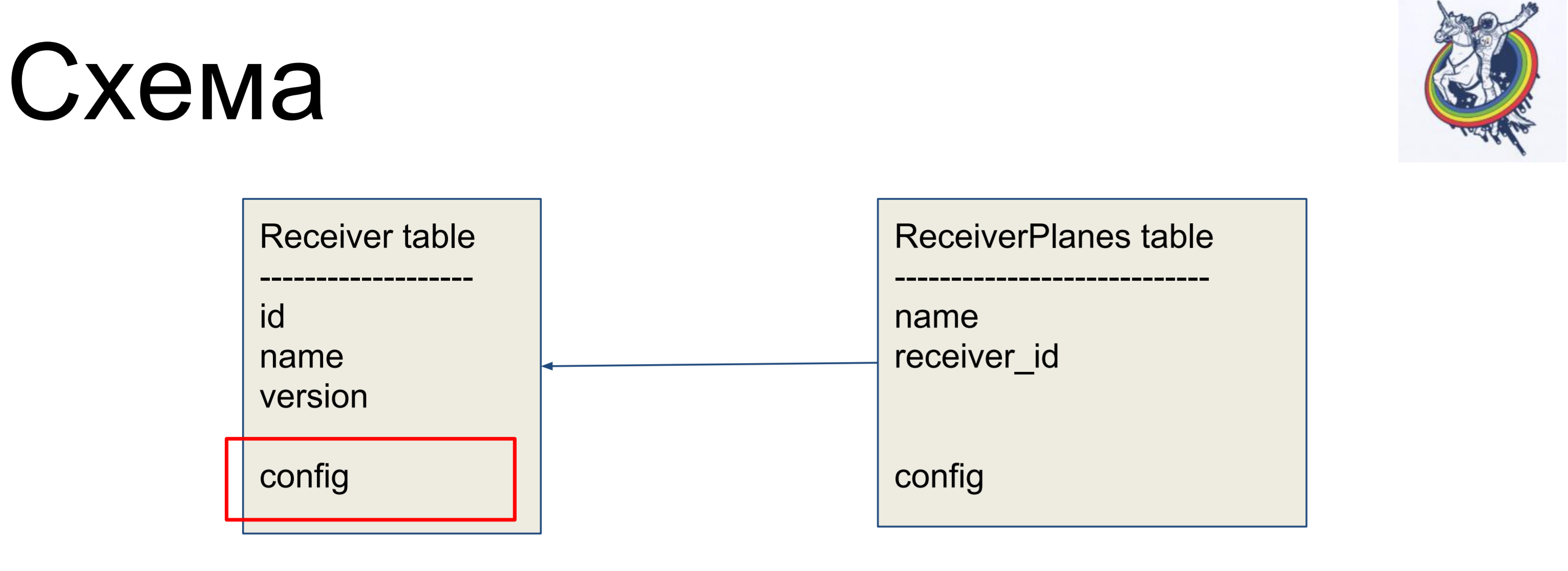
Mais dans notre schéma, les oreilles de la base de données sont toujours visibles - c'est la configuration. Quel type de configuration? Est-ce varchar ou blob? En fait, le client n'est pas intéressé.
Il doit travailler avec des entités abstraites de son niveau. Pour cela, l'alchimie propose une décoration de type. Un exemple simple. Notre base de données stocke IPAddress sous forme de varchar. Nous utilisons la classe TypeDecorator, qui fait partie de l'alchimie, qui permet, d'une part, d'indiquer quel type de base de données sous-jacent sera utilisé pour ce type et, d'autre part, de définir deux paramètres: process_bind_param convertissant la valeur en type de base de données et process_result_value lorsque nous évaluons à partir du type de base de données, convertissez en un objet Python.L'attribut from address prend le type python IPAddress. Et nous pouvons à la fois appeler des méthodes de ce type, et lui affecter des objets de ce type, et tout fonctionne pour nous. Et il est stocké dans la base de données ... Je ne sais pas ce qui est stocké, varchar (45), mais nous pouvons remplacer cette ligne et le blob sera stocké. Ou si un type natif prend en charge les adresses IP, vous pouvez l'utiliser.Le code client ne dépend pas de cela, il n'a pas besoin d'être réécrit.
Un exemple simple. Notre base de données stocke IPAddress sous forme de varchar. Nous utilisons la classe TypeDecorator, qui fait partie de l'alchimie, qui permet, d'une part, d'indiquer quel type de base de données sous-jacent sera utilisé pour ce type et, d'autre part, de définir deux paramètres: process_bind_param convertissant la valeur en type de base de données et process_result_value lorsque nous évaluons à partir du type de base de données, convertissez en un objet Python.L'attribut from address prend le type python IPAddress. Et nous pouvons à la fois appeler des méthodes de ce type, et lui affecter des objets de ce type, et tout fonctionne pour nous. Et il est stocké dans la base de données ... Je ne sais pas ce qui est stocké, varchar (45), mais nous pouvons remplacer cette ligne et le blob sera stocké. Ou si un type natif prend en charge les adresses IP, vous pouvez l'utiliser.Le code client ne dépend pas de cela, il n'a pas besoin d'être réécrit.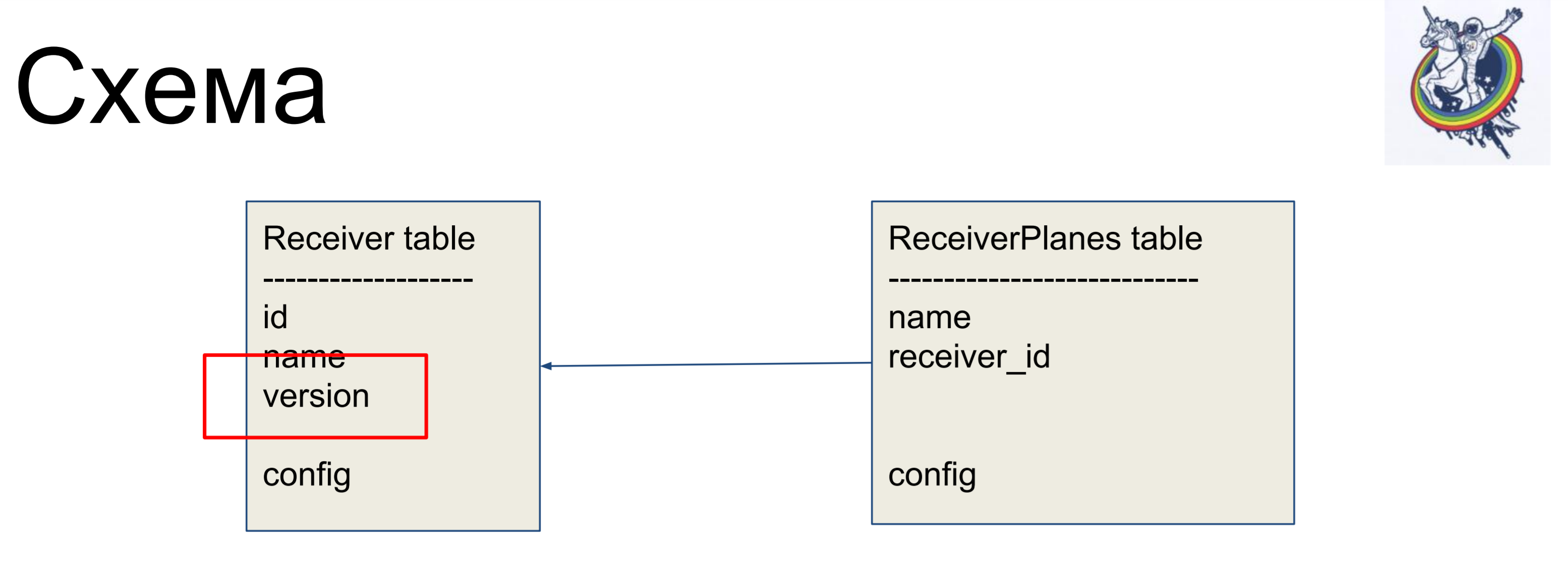 Une autre chose intéressante est que nous avons une version. Nous voulons que dès que nous changeons d'objet, la version augmente immédiatement. Nous avons un compteur de versions, nous avons changé d'objet - il a changé, la version a augmenté. Nous le faisons automatiquement pour ne pas oublier.
Une autre chose intéressante est que nous avons une version. Nous voulons que dès que nous changeons d'objet, la version augmente immédiatement. Nous avons un compteur de versions, nous avons changé d'objet - il a changé, la version a augmenté. Nous le faisons automatiquement pour ne pas oublier. Pour cela, nous avons utilisé des événements. Les événements sont des événements qui se produisent à différentes étapes de la vie d'un mappeur et ils peuvent être déclenchés lorsque les attributs changent, lorsqu'une entité passe d'un état à un autre, par exemple, «créé», «enregistré dans la base de données», «chargé à partir de la base de données», «supprimé»; et également - lors d'événements de niveau session, avant que le code sql ne soit émis dans la base de données, avant la validation, après la validation et également après la restauration.Alchemy nous permet d'affecter des gestionnaires à tous ces événements, mais l'ordre dans lequel les gestionnaires sont exécutés pour le même événement n'est pas garanti. Autrement dit, il est spécifique, mais on ne sait pas lequel. Par conséquent, si l'ordre d'exécution est important pour vous, vous devez faire un mécanisme d'enregistrement.
Pour cela, nous avons utilisé des événements. Les événements sont des événements qui se produisent à différentes étapes de la vie d'un mappeur et ils peuvent être déclenchés lorsque les attributs changent, lorsqu'une entité passe d'un état à un autre, par exemple, «créé», «enregistré dans la base de données», «chargé à partir de la base de données», «supprimé»; et également - lors d'événements de niveau session, avant que le code sql ne soit émis dans la base de données, avant la validation, après la validation et également après la restauration.Alchemy nous permet d'affecter des gestionnaires à tous ces événements, mais l'ordre dans lequel les gestionnaires sont exécutés pour le même événement n'est pas garanti. Autrement dit, il est spécifique, mais on ne sait pas lequel. Par conséquent, si l'ordre d'exécution est important pour vous, vous devez faire un mécanisme d'enregistrement.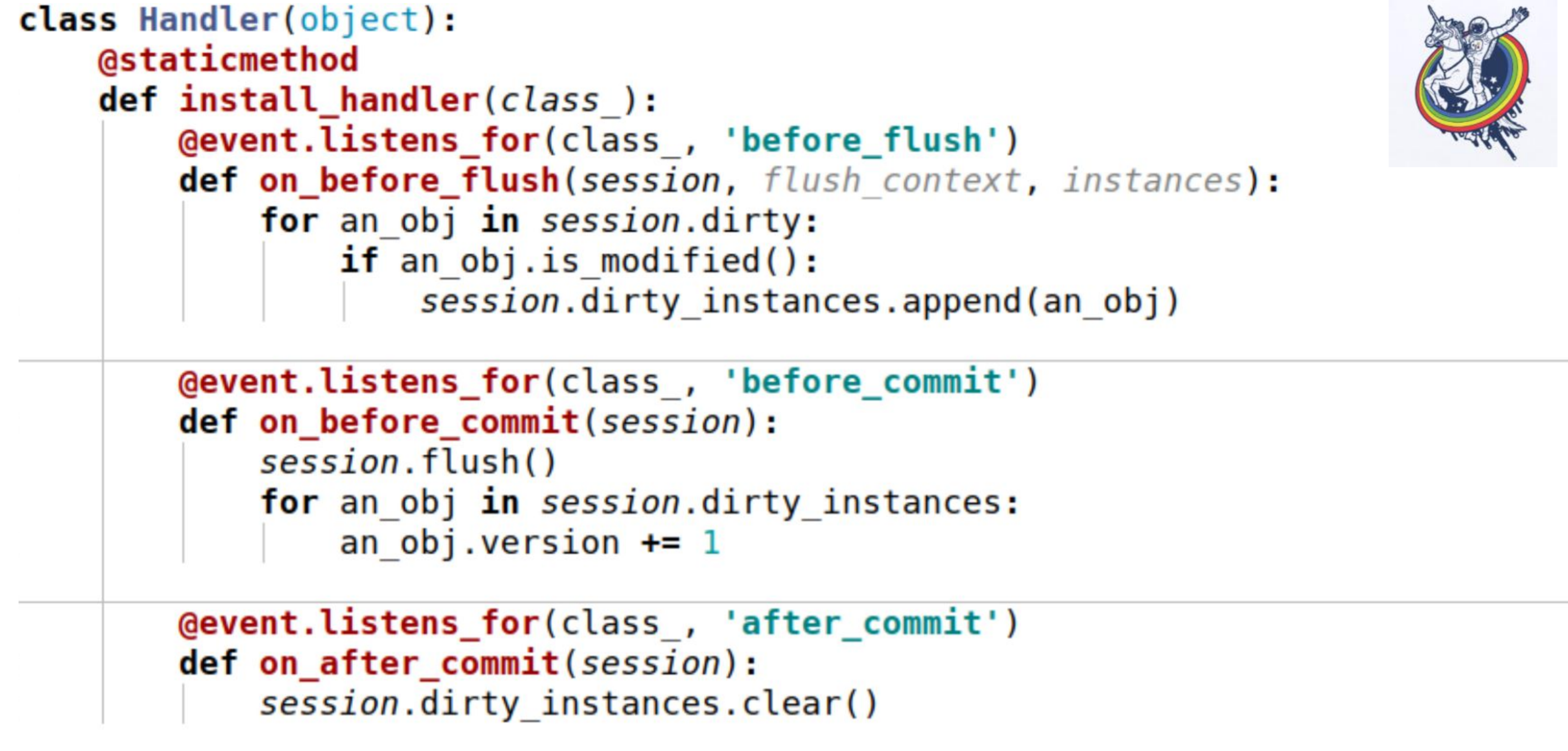 Voici un exemple. Trois événements sont utilisés ici:on_before_flush - avant que le code SQL ne soit émis dans la base de données, nous passons en revue tous les objets que l'alchimie a marqués comme sales dans cette session et vérifions si cet objet est modifié ou non. Pourquoi est-ce nécessaire si l'alchimie a déjà tout marqué? L'alchimie marque un objet sale dès qu'un attribut a changé. Si nous attribuons la même valeur à cet attribut qu'il avait, il sera marqué comme sale. Il existe une méthode de session is_modified pour cela - elle est utilisée en interne, je ne l'ai pas dessinée. De plus, du point de vue de notre sémantique, du point de vue de notre logique métier, même si l'attribut a changé, l'objet peut rester inchangé. Par exemple, il existe une certaine liste dans laquelle deux éléments sont échangés - du point de vue de l'alchimie, l'attribut a changé, mais cela n'a pas d'importance pour la logique métier si, disons,une sorte.Et, à la fin, nous appelons une autre méthode spécifique à chaque objet pour comprendre si l'objet est modifié ou non. Et nous les ajoutons à une certaine variable associée à la session que nous avons créée nous-mêmes - c'est notre variable dirty_instances, dans laquelle nous ajoutons cet objet.L'événement suivant se produit avant le commit - before_commit. Ici aussi, il y a un petit piège: si pour la transaction entière nous n'avons pas eu un seul flush, alors flush sera appelé avant le commit - dans mon cas, le gestionnaire a été appelé avant le commit avant flush.Comme vous pouvez le voir, ce que nous avons fait dans le paragraphe précédent peut ne pas nous aider et session.dirty_instances sera vide. Par conséquent, à l'intérieur du gestionnaire, nous effectuons à nouveau le vidage afin que tous les gestionnaires soient appelés avant le vidage et incrémentons simplement la version d'une unité.after_commit, after_soft_rollback - après le commit, nous le nettoyons juste pour qu'il n'y ait pas d'excès la prochaine fois.Ainsi, vous voyez - cette méthode install_handler installe des gestionnaires pour trois événements à la fois. En tant que classe, nous passons la session ici, car il s'agit d'un événement de son niveau.
Voici un exemple. Trois événements sont utilisés ici:on_before_flush - avant que le code SQL ne soit émis dans la base de données, nous passons en revue tous les objets que l'alchimie a marqués comme sales dans cette session et vérifions si cet objet est modifié ou non. Pourquoi est-ce nécessaire si l'alchimie a déjà tout marqué? L'alchimie marque un objet sale dès qu'un attribut a changé. Si nous attribuons la même valeur à cet attribut qu'il avait, il sera marqué comme sale. Il existe une méthode de session is_modified pour cela - elle est utilisée en interne, je ne l'ai pas dessinée. De plus, du point de vue de notre sémantique, du point de vue de notre logique métier, même si l'attribut a changé, l'objet peut rester inchangé. Par exemple, il existe une certaine liste dans laquelle deux éléments sont échangés - du point de vue de l'alchimie, l'attribut a changé, mais cela n'a pas d'importance pour la logique métier si, disons,une sorte.Et, à la fin, nous appelons une autre méthode spécifique à chaque objet pour comprendre si l'objet est modifié ou non. Et nous les ajoutons à une certaine variable associée à la session que nous avons créée nous-mêmes - c'est notre variable dirty_instances, dans laquelle nous ajoutons cet objet.L'événement suivant se produit avant le commit - before_commit. Ici aussi, il y a un petit piège: si pour la transaction entière nous n'avons pas eu un seul flush, alors flush sera appelé avant le commit - dans mon cas, le gestionnaire a été appelé avant le commit avant flush.Comme vous pouvez le voir, ce que nous avons fait dans le paragraphe précédent peut ne pas nous aider et session.dirty_instances sera vide. Par conséquent, à l'intérieur du gestionnaire, nous effectuons à nouveau le vidage afin que tous les gestionnaires soient appelés avant le vidage et incrémentons simplement la version d'une unité.after_commit, after_soft_rollback - après le commit, nous le nettoyons juste pour qu'il n'y ait pas d'excès la prochaine fois.Ainsi, vous voyez - cette méthode install_handler installe des gestionnaires pour trois événements à la fois. En tant que classe, nous passons la session ici, car il s'agit d'un événement de son niveau. Eh bien ici. Je vous rappellerai ce que nous avons accompli - vitesse de 30 à 40 secondes pour les équipes complexes et grandes. Pas du tout, certains ont été achevés en une seconde, d'autres en 200 millisecondes, comme vous pouvez le voir sur RPS. Les requêtes de base de données ont commencé à être comptées par centaines.
Eh bien ici. Je vous rappellerai ce que nous avons accompli - vitesse de 30 à 40 secondes pour les équipes complexes et grandes. Pas du tout, certains ont été achevés en une seconde, d'autres en 200 millisecondes, comme vous pouvez le voir sur RPS. Les requêtes de base de données ont commencé à être comptées par centaines. Le résultat est un système assez équilibré. Il y avait cependant une mise en garde. Certaines demandes viennent de nous par lots, émissions. Autrement dit, environ 30 demandes arrivent et chacune d'elles est comme ça! (le haut-parleur montre le pouce)Si nous les traitons une seconde à la fois, la dernière demande dans la file d'attente fonctionnera pendant 30 secondes. Le premier, les deux seconds, etc.
Le résultat est un système assez équilibré. Il y avait cependant une mise en garde. Certaines demandes viennent de nous par lots, émissions. Autrement dit, environ 30 demandes arrivent et chacune d'elles est comme ça! (le haut-parleur montre le pouce)Si nous les traitons une seconde à la fois, la dernière demande dans la file d'attente fonctionnera pendant 30 secondes. Le premier, les deux seconds, etc. Par conséquent, nous devons encore accélérer. Que ferons-nous?En fait, l'alchimie a deux parties. Le premier est une abstraction sur une base de données SQL appelée SQLAlchemy Core. Le second est ORM, le mappage réel entre la base de données relationnelle et la représentation d'objet. En conséquence, le noyau d'alchimie coïncide à peu près avec sql - si vous connaissez ce dernier, vous n'aurez pas de problèmes avec le noyau. Si vous ne connaissez pas sql - apprenez sql.De plus, le noyau représente le plus petit surcoût. Il n'y a pratiquement pas de pompage - les requêtes sont générées à l'aide du générateur de requêtes, puis exécutées. Les frais généraux sur dbapi sont minimes.Nous pouvons construire des demandes de toute complexité, de tout type, nous pouvons les optimiser pour la tâche. Autrement dit, si dans le cas général, ORM ne se soucie pas de la façon dont le schéma de base de données est construit - il y a une description des tables, il génère des requêtes, sans savoir que dans ce cas, par exemple, il sera optimal de sélectionner d'ici, dans un autre - à partir de là, tel appliquer le filtre, et là - un autre, alors ici, nous pouvons faire des demandes pour la tâche.L'inconvénient est que nous sommes à nouveau arrivés à la synchronisation manuelle. Tous les événements, relais - tout cela dans le noyau ne fonctionne pas. Nous avons fait une sélection, des objets nous sont arrivés, nous avons fait quelque chose avec eux, puis mis à jour, inséré ... vous devez incrémenter la version avec vos mains, vérifier les constantes vous-même. Core ne permet pas de faire tout cela de manière pratique, à un niveau élevé.Eh bien, nous ne vivons pas le premier jour.
Par conséquent, nous devons encore accélérer. Que ferons-nous?En fait, l'alchimie a deux parties. Le premier est une abstraction sur une base de données SQL appelée SQLAlchemy Core. Le second est ORM, le mappage réel entre la base de données relationnelle et la représentation d'objet. En conséquence, le noyau d'alchimie coïncide à peu près avec sql - si vous connaissez ce dernier, vous n'aurez pas de problèmes avec le noyau. Si vous ne connaissez pas sql - apprenez sql.De plus, le noyau représente le plus petit surcoût. Il n'y a pratiquement pas de pompage - les requêtes sont générées à l'aide du générateur de requêtes, puis exécutées. Les frais généraux sur dbapi sont minimes.Nous pouvons construire des demandes de toute complexité, de tout type, nous pouvons les optimiser pour la tâche. Autrement dit, si dans le cas général, ORM ne se soucie pas de la façon dont le schéma de base de données est construit - il y a une description des tables, il génère des requêtes, sans savoir que dans ce cas, par exemple, il sera optimal de sélectionner d'ici, dans un autre - à partir de là, tel appliquer le filtre, et là - un autre, alors ici, nous pouvons faire des demandes pour la tâche.L'inconvénient est que nous sommes à nouveau arrivés à la synchronisation manuelle. Tous les événements, relais - tout cela dans le noyau ne fonctionne pas. Nous avons fait une sélection, des objets nous sont arrivés, nous avons fait quelque chose avec eux, puis mis à jour, inséré ... vous devez incrémenter la version avec vos mains, vérifier les constantes vous-même. Core ne permet pas de faire tout cela de manière pratique, à un niveau élevé.Eh bien, nous ne vivons pas le premier jour. Un cas d'utilisation simple. Chaque mappeur contient en interne un objet __table__, qui est utilisé dans le noyau. Ensuite, vous voyez - nous prenons la sélection habituelle, listons les colonnes, joignons deux plaques, indiquons la gauche et la droite, indiquons par quelle condition nous la joignons, eh bien, pour le goût, nous ajoutons un ordre d'achat. Ensuite, nous introduisons cette requête générée dans la session et elle nous est renvoyée, dans laquelle les objets de type tap sont indexés à la fois par nom de colonne et par numéro. Le numéro correspond à l'ordre dans lequel ils sont répertoriés dans la sélection.
Un cas d'utilisation simple. Chaque mappeur contient en interne un objet __table__, qui est utilisé dans le noyau. Ensuite, vous voyez - nous prenons la sélection habituelle, listons les colonnes, joignons deux plaques, indiquons la gauche et la droite, indiquons par quelle condition nous la joignons, eh bien, pour le goût, nous ajoutons un ordre d'achat. Ensuite, nous introduisons cette requête générée dans la session et elle nous est renvoyée, dans laquelle les objets de type tap sont indexés à la fois par nom de colonne et par numéro. Le numéro correspond à l'ordre dans lequel ils sont répertoriés dans la sélection. C'est devenu beaucoup mieux. Dans le pire des cas, les performances sont tombées à 2-4 secondes, la demande la plus complexe et la plus longue contenait 14 commandes et RPS 10-15. C'est solide.
C'est devenu beaucoup mieux. Dans le pire des cas, les performances sont tombées à 2-4 secondes, la demande la plus complexe et la plus longue contenait 14 commandes et RPS 10-15. C'est solide. Ce que je voudrais dire en conclusion.Ne produisez pas d'entités là où elles ne sont pas nécessaires - ne vissez pas la vôtre là où elle est prête.Utilisez SQLA ORM - c'est un outil très pratique qui vous permet de suivre des événements à un niveau élevé, de répondre à divers événements liés à la base de données, de cacher toutes les oreilles de l'alchimie.Si tout le reste échoue, les performances ne sont pas suffisantes - utilisez SQLA Core. C'est encore mieux que d'utiliser du SQL brut pur car il fournit une abstraction relationnelle sur la base de données. Échappe automatiquement les paramètres, fonctionne correctement les classeurs, peu importe la base de données qui s'y trouve - elle peut être modifiée et Core prend en charge différents dialectes.
Ce que je voudrais dire en conclusion.Ne produisez pas d'entités là où elles ne sont pas nécessaires - ne vissez pas la vôtre là où elle est prête.Utilisez SQLA ORM - c'est un outil très pratique qui vous permet de suivre des événements à un niveau élevé, de répondre à divers événements liés à la base de données, de cacher toutes les oreilles de l'alchimie.Si tout le reste échoue, les performances ne sont pas suffisantes - utilisez SQLA Core. C'est encore mieux que d'utiliser du SQL brut pur car il fournit une abstraction relationnelle sur la base de données. Échappe automatiquement les paramètres, fonctionne correctement les classeurs, peu importe la base de données qui s'y trouve - elle peut être modifiée et Core prend en charge différents dialectes. C'est très pratique.
C'est tout ce que je voulais vous dire aujourd'hui.