Les systèmes distribués sont utilisés lorsqu'il existe un besoin de mise à l'échelle horizontale pour fournir des indicateurs de performance accrus qu'un système à échelle verticale n'est pas en mesure de fournir suffisamment d'argent.
Comme la transition d'un paradigme à un seul thread à un multi-thread, la migration vers un système distribué nécessite une sorte d'immersion et une compréhension de son fonctionnement à l'intérieur, ce à quoi vous devez faire attention.
L'un des problèmes auxquels est confrontée une personne qui souhaite migrer un projet vers un système distribué ou démarrer un projet dessus est le produit à choisir.
En tant qu'entreprise qui a «mangé un chien» dans le développement de systèmes de ce type, nous aidons nos clients à prendre des décisions éclairées concernant les systèmes de stockage distribués. Nous publions également une
série de webinaires pour un public plus large qui se concentrent sur les principes de base dans un langage simple, et quelles que soient les préférences alimentaires spécifiques aident à cartographier les fonctionnalités importantes pour le rendre plus facile à choisir.
Cet article est basé sur nos documents sur la cohérence et les garanties ACID dans les systèmes distribués.
Qu'est-ce que c'est et pourquoi est-il nécessaire?
«
La cohérence des données (parfois
la cohérence des données ) est
la cohérence des données entre elles, l'intégrité des données et la cohérence interne.» (
Wikipedia )
La cohérence implique qu'à tout moment donné, les applications peuvent être sûres qu'elles travaillent avec la version correcte et techniquement pertinente des données, et peuvent s'y fier pour prendre des décisions.
Dans les systèmes distribués, assurer la cohérence devient de plus en plus difficile et plus coûteux, car toute une série de nouveaux défis se posent liés à l'échange de réseau entre différents nœuds, la possibilité de défaillance de nœuds individuels et - souvent - le manque d'une mémoire unique pouvant servir de vérification.
Par exemple, si j'ai un système de 4 nœuds: A, B, C et D, qui sert les transactions bancaires, et que les nœuds C et D sont séparés de A et B (disons, en raison de problèmes de réseau), il est fort possible que je ne le sois plus maintenant J'ai accès à une partie de la transaction. Comment dois-je agir dans cette situation? Différents systèmes adoptent des approches différentes.
Au niveau supérieur, il y a 2 directions clés qui sont exprimées dans le théorème CAP.
«
Le théorème de CAP (également connu sous le nom
de théorème de Brewer ) est une déclaration heuristique selon laquelle dans toute implémentation de l'informatique distribuée, il est possible de ne pas fournir plus de deux des trois propriétés suivantes:
- cohérence des données (cohérence angl.) - dans tous les nœuds de calcul à un moment donné, les données ne se contredisent pas;
- disponibilité (disponibilité en anglais) - toute demande à un système distribué se termine par une réponse correcte, mais sans garantie que les réponses de tous les nœuds du système correspondent;
- tolérance de partition - la division d'un système distribué en plusieurs sections isolées n'entraîne pas une réponse incorrecte de chaque section.
(
Wikipedia )
Lorsque le théorème CAP parle de cohérence, il implique une définition assez stricte, y compris la linéarisation des enregistrements et des lectures, et ne stipule que la cohérence lors de l'écriture de valeurs individuelles. (
Martin Kleppman )
Le théorème du CAP dit que si nous voulons être résistants aux problèmes de réseau, alors en général nous devons choisir de sacrifier: cohérence ou accessibilité. Il existe également une version étendue de ce théorème - PACELC (
Wikipedia ), qui parle en outre du fait que même en l'absence de problèmes de réseau, nous devons choisir entre la vitesse de réponse et la cohérence.
Et même si, à première vue, originaire du monde des SGBD classiques, il semble que le choix soit évident et que la cohérence soit la chose la plus importante que nous ayons, c'est loin d'être toujours le cas, ce qui illustre clairement la croissance explosive d'un certain nombre de SGBD NoSQL qui ont fait un choix différent et Malgré cela, ils ont une énorme base d'utilisateurs. Apache Cassandra avec sa fameuse consistance éventuelle en est un bon exemple.
Tout cela est dû au fait que c'est un
choix qui implique que nous sacrifions quelque chose, et nous ne sommes pas toujours prêts à le sacrifier.
Souvent, le problème de cohérence dans les systèmes distribués est résolu simplement en abandonnant cette cohérence.
Mais il est nécessaire et important de comprendre quand le rejet de cette cohérence est acceptable, et quand il s'agit d'une exigence métier critique.
Par exemple, si je conçois un composant qui est responsable du stockage des sessions utilisateur, ici, très probablement, la cohérence n'est pas si importante pour moi, et la perte de données n'est pas critique si elle ne se produit que dans des cas problématiques - très rarement. Le pire qui puisse arriver est que l'utilisateur devra se connecter, et pour de nombreuses entreprises, cela aura peu d'effet sur ses performances financières.
Si je fais des analyses sur le flux de données à partir de capteurs, dans de nombreux cas, il n'est absolument pas critique pour moi de perdre certaines données et d'obtenir un sous-échantillonnage pendant une courte période, surtout si je vois enfin les données.
Mais si je fais un système bancaire, la cohérence des transactions en espèces est critique pour mon entreprise. Si j’ai accumulé une pénalité sur le prêt d’un client parce que je n’ai tout simplement pas vu le paiement effectué à temps, même s’il était dans le système, c’est très, très mauvais. De même que si le client peut retirer tout l'argent de ma carte de crédit plusieurs fois, car j'ai eu des problèmes de réseau au moment de la transaction et les informations de retrait n'ont pas atteint une partie de mon cluster.
Si vous effectuez un achat coûteux dans une boutique en ligne, vous ne voulez pas que votre commande soit oubliée, malgré le rapport de réussite sur la page Web.
Mais si vous optez pour la cohérence, vous sacrifiez l'accessibilité. Et souvent, cela est attendu, très probablement, vous l'avez rencontré personnellement plus d'une fois.
Il vaut mieux que le panier de la boutique en ligne indique «essayez plus tard, un SGBD distribué n'est pas disponible» que s'il signale le succès et oublie la commande. Il vaut mieux obtenir un refus dans une transaction en raison de l’indisponibilité des services de la banque qu’un battement sur le succès puis la procédure avec la banque du fait qu’il a oublié que vous avez payé le prêt.
Enfin, si nous regardons le théorème PACELC étendu, nous comprenons que même dans le cas d'un fonctionnement régulier du système, en choisissant la cohérence, nous pouvons sacrifier de faibles latences, obtenant un niveau potentiellement inférieur de performances maximales.
Par conséquent, répondre à la question «pourquoi est-ce nécessaire?»: Il est nécessaire s'il est essentiel que votre tâche dispose de données à jour et cohérentes, et l'alternative vous apportera des pertes significatives supérieures à l'indisponibilité temporaire du service pendant la période de l'incident ou à ses performances inférieures.
Comment fournir cela?
Par conséquent, la première décision que vous devez prendre est de savoir où vous en êtes dans le théorème du CAP, vous voulez de la cohérence ou de la disponibilité en cas d'incident.
Ensuite, vous devez comprendre à quel niveau vous souhaitez apporter des modifications. Peut-être que vous avez juste assez d'enregistrements atomiques affectant un seul objet, comme MongoDB en était capable (maintenant il étend cela en plus avec la prise en charge des transactions à part entière). Permettez-moi de vous rappeler que le théorème CAP ne dit rien sur la cohérence des opérations d'écriture impliquant plusieurs objets: le système peut bien être CP (c'est-à-dire préférer la cohérence d'accessibilité) et en même temps ne fournir que des enregistrements atomiques uniques.
Si cela ne vous suffit pas, nous commençons à aborder le concept de transactions ACID distribuées à part entière.
Je note que même lorsque nous entrons dans le nouveau monde courageux des transactions ACID distribuées, nous devons souvent sacrifier quelque chose. Par exemple, un certain nombre de systèmes de stockage distribués ont des transactions distribuées, mais uniquement dans une seule partition. Ou, par exemple, le système peut ne pas prendre en charge la partie «I» au niveau dont vous avez besoin, sans isolement ou avec un nombre insuffisant de niveaux d'isolement.
Ces restrictions ont souvent été faites pour une raison quelconque: soit pour simplifier l'implémentation, soit, par exemple, pour améliorer les performances, soit pour autre chose. Ils sont suffisants pour un grand nombre de cas, vous ne devez donc pas les considérer comme des inconvénients à eux seuls.
Vous devez comprendre si ces restrictions sont un problème pour votre scénario spécifique. Sinon, vous avez plus de choix et vous pouvez donner plus de poids, par exemple, aux indicateurs de performance ou à la capacité du système à fournir une tolérance aux catastrophes, etc. Enfin, il ne faut pas oublier que dans un certain nombre de systèmes ces paramètres peuvent être ajustés au point que le système peut être CP ou AP selon la configuration.
Si notre produit vise à être CP, il a généralement soit une approche de quorum pour la sélection des données, soit des nœuds dédiés qui sont les principaux propriétaires des enregistrements, toutes les modifications de données les traversent, et en cas de problèmes de réseau, si ces nœuds maîtres ne peuvent pas donner la réponse, on pense que les données, en principe, ne peuvent pas être obtenues, ou l'arbitrage, lorsqu'un composant externe hautement accessible (par exemple, le cluster ZooKeeper) peut dire lequel des segments de cluster est le principal, contient la version actuelle des données et peut effectivement répondre à la demande s.
Enfin, si nous nous intéressons non seulement au CP, mais à la prise en charge de transactions ACID distribuées à part entière, alors souvent une seule source de vérité est souvent utilisée, par exemple, le stockage sur disque centralisé, où nos nœuds, en fait, n'agissent qu'en tant que caches, qui peuvent être désactivés dans temps de validation, ou le protocole de validation multiphase est appliqué.
La première approche à disque unique simplifie également la mise en œuvre, donne de faibles latences sur les transactions distribuées, mais échange en échange une évolutivité très limitée sur les charges avec des volumes d'enregistrement importants.
La deuxième approche donne beaucoup plus de liberté dans la mise à l'échelle et, à son tour, est divisée en protocoles de validation en deux phases (
Wikipedia ) et en trois phases (
Wikipedia ).
Considérez une validation en deux phases qui utilise, par exemple, Apache Ignite.
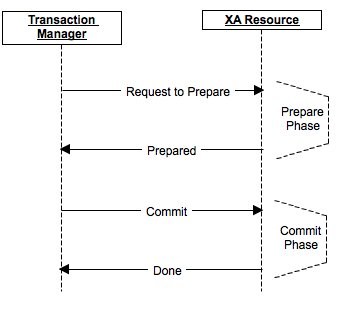

La procédure de validation est divisée en 2 phases: préparation et validation.
Dans la phase de préparation, un message est préparé sur la préparation de la validation, et chaque participant, si nécessaire, verrouille, effectue toutes les opérations jusqu'à la validation réelle et y compris, et envoie la préparation à ses répliques, si cela est supposé par le produit. Si au moins l'un des participants a répondu par un refus pour une raison quelconque ou s'est révélé indisponible - les données n'ont pas réellement changé, il n'y a pas eu de validation. Les participants annulent les modifications, libèrent les verrous et reviennent à leur état d'origine.
Dans la phase de validation, l'exécution réelle de la validation est envoyée aux nœuds du cluster. Si, pour une raison quelconque, certains des nœuds n'étaient pas disponibles ou ont répondu avec une erreur, alors les données ont été entrées dans leur fichier de journalisation (car la préparation a réussi) et la validation peut dans tous les cas être terminée au moins dans un état en attente.
Enfin, si le coordinateur échoue, au stade de la préparation, la validation sera annulée, au stade de la validation un nouveau coordinateur peut être sélectionné, et si tous les nœuds ont terminé la préparation, il peut vérifier et s'assurer que la phase de validation est terminée.
Différents produits ont leurs propres fonctionnalités d'implémentation et d'optimisation. Ainsi, par exemple, certains produits sont capables, dans certains cas, de réduire une validation en 2 phases à une validation en une phase, gagnant considérablement en performances.
Conclusions
Conclusion principale: les systèmes de stockage distribué sont un marché assez développé et les produits qui s'y trouvent peuvent fournir une grande cohérence des données.
De plus, les produits de cette catégorie sont situés à différents points de l'échelle de cohérence, des produits entièrement AP sans aucune transactionnalité aux produits CP qui fournissent en outre des transactions ACID à part entière. Certains produits peuvent être configurés d'une manière ou d'une autre.
Lorsque vous choisissez ce dont vous avez besoin, vous devez tenir compte des besoins de votre cas et bien comprendre quels sacrifices et compromis vous êtes prêt à faire, car rien ne se passe gratuitement, et en choisissant un, vous refuserez très probablement autre chose.
Lors de l'évaluation des produits de ce côté, il convient de prêter attention aux éléments suivants:
- où ils se trouvent dans le théorème CAP;
- Prend-il en charge les transactions ACID distribuées?
- quelles restrictions imposent-ils aux transactions distribuées (par exemple, uniquement dans une seule partition, etc.);
- Commodité et efficacité de l'utilisation des transactions distribuées, leur intégration dans d'autres composants du produit.