[partie 2 de 2]
[partie 1 de 2]

Comment l'avons-nous fait
Nous avons décidé de passer à GCP pour améliorer les performances des applications - tout en augmentant l'échelle, mais sans coûts importants. L'ensemble du processus a pris plus de 2 mois. Pour résoudre ce problème, nous avons formé un groupe spécial d'ingénieurs.
Dans cette publication, nous parlerons de l'approche choisie et de sa mise en œuvre, ainsi que de la manière dont nous avons réussi à atteindre l'objectif principal - mener à bien ce processus le plus harmonieusement possible et transférer l'intégralité de l'infrastructure vers la plateforme Google Cloud, sans compromettre la qualité du service aux utilisateurs.
Planification
- Une liste de contrôle détaillée a été préparée pour identifier chaque étape possible. Un organigramme a été créé pour décrire la séquence.
- Un plan de réinitialisation a été élaboré que nous pourrions éventuellement utiliser.
Quelques séances de brainstorming - et nous avons identifié l'approche la plus compréhensible et la plus simple pour mettre en œuvre le schéma actif-actif. Elle consiste dans le fait qu'un petit ensemble d'utilisateurs est hébergé sur un cloud, et le reste sur un autre. Cependant, cette approche a causé des problèmes, en particulier du côté client (liés à la gestion DNS), et a entraîné des retards dans la réplication de la base de données. Pour cette raison, il était presque impossible de le mettre en œuvre en toute sécurité. La méthode évidente n'a pas apporté la solution nécessaire et nous avons dû développer une stratégie spécialisée.
Sur la base du diagramme de dépendance et des exigences de sécurité opérationnelle, nous avons divisé les services d'infrastructure en 9 modules.
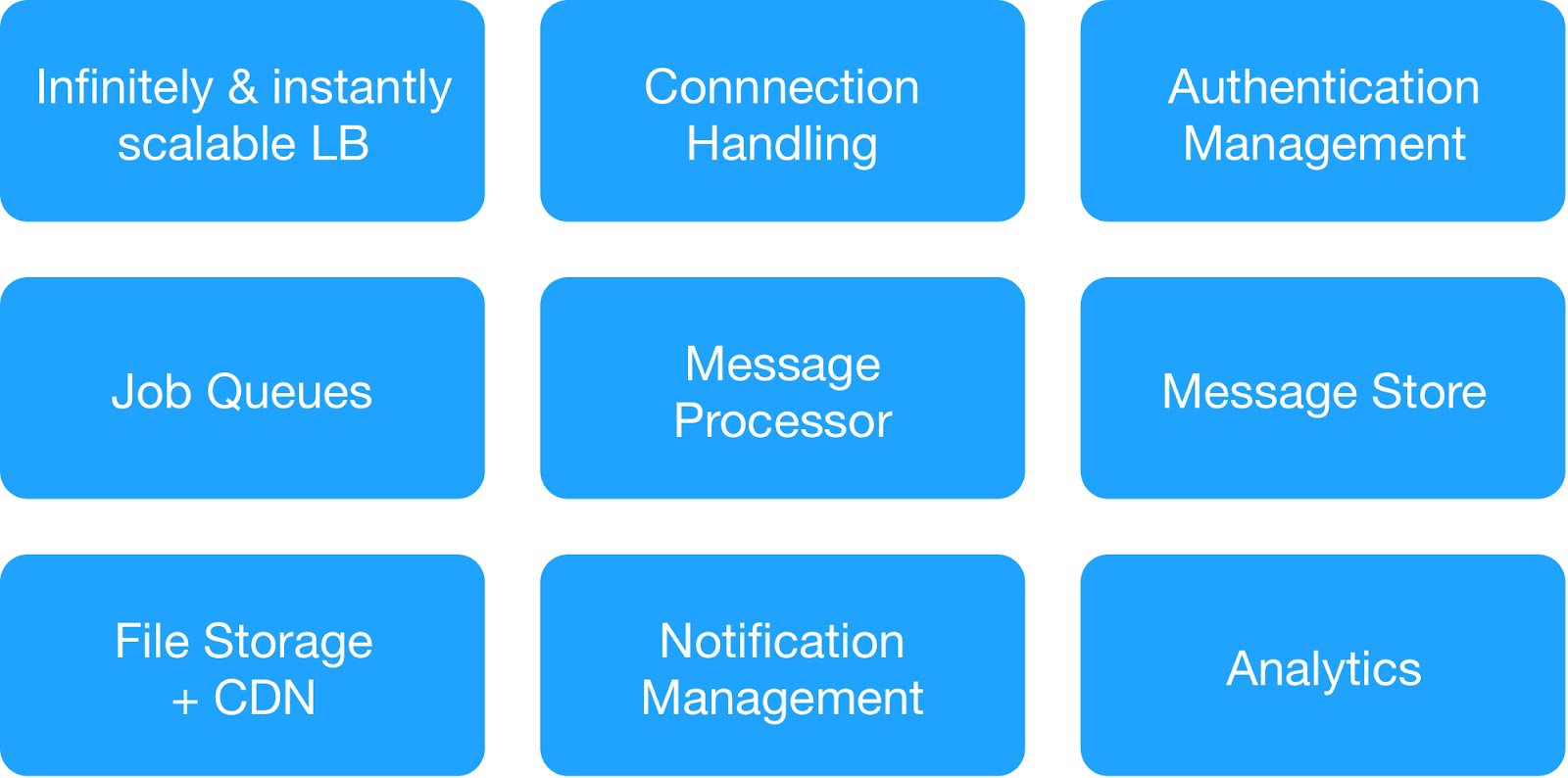
(Modules de base pour déployer l'infrastructure d'hébergement)
Chaque groupe d'infrastructure gérait des services internes et externes communs.
⊹ Service de messagerie d'infrastructure : MQTT, HTTPs, Thrift, serveur Gunicorn, module de mise en file d'attente, client Async, serveur Jetty, cluster Kafka.
⊹ Services d'entrepôt de données : cluster distribué MongoDB, Redis, Cassandra, Hbase, MySQL et MongoDB.
⊹ Service d'analyse d'infrastructure : cluster Kafka, cluster d'entrepôt de données (HDFS, HIVE).
Se préparer pour une journée importante:
✓ Un plan détaillé pour passer au GCP pour chaque service: séquence, entrepôt de données, plan de réinitialisation.
✓ Interactions réseau entre projets (VPC cloud privé virtuel partagé [XPN]) dans GCP pour isoler différentes parties de l'infrastructure, optimiser la gestion, améliorer la sécurité et la connectivité.
✓ Plusieurs tunnels VPN entre le GCP et le cloud privé virtuel (VPC) en cours d'exécution pour simplifier le transfert de grandes quantités de données sur le réseau pendant la réplication, ainsi que pour le déploiement ultérieur possible d'un système parallèle.
✓ Automatisez l'installation et la configuration de la pile entière à l'aide du système Chef.
✓ Scripts et outils d'automatisation pour le déploiement, la surveillance, la journalisation, etc.
✓ Configurez tous les sous-réseaux requis et les règles de pare-feu gérées pour le flux système.
✓ Réplication dans plusieurs centres de données (Multi-DC) pour tous les systèmes de stockage.
✓ Configurer des équilibreurs de charge (GLB / ILB) et des groupes d'instances gérés (MIG).
✓ Scripts et code pour transférer le conteneur de stockage d'objets vers GCP Cloud Storage avec des points de contrôle.
Bientôt, nous avons rencontré tous les prérequis nécessaires et préparé une liste de contrôle des éléments pour déplacer l'infrastructure vers la plateforme GCP. Après de nombreuses discussions, ainsi que le nombre de services et leurs diagrammes de dépendance, nous avons décidé de transférer l'infrastructure cloud vers GCP en trois nuits pour couvrir tous les services côté serveur et de stockage de données.
Transition
Stratégie de transfert d'équilibrage de charge:
Nous avons remplacé le cluster géré HAProxy précédemment utilisé par un équilibreur de charge global pour traiter quotidiennement des dizaines de millions de connexions utilisateur actives.
⊹ Étape 1:
- Les MIG sont créés avec des règles de transfert de paquets pour transférer tout le trafic vers les adresses IP MQTT dans le cloud existant.
- Un équilibreur de proxy SSL et TCP a été créé avec MIG comme partie serveur.
- Pour MIG, HAProxy est lancé avec des serveurs MQTT comme partie serveur.
- Dans DNS, une stratégie de routage basée sur le poids a ajouté une adresse IP GLB externe.
Les connexions utilisateurs sont progressivement déployées tout en suivant leurs performances.
⊹ Étape 2: transition jalon, commencez à déployer des services dans GCP.
⊹ Étape 3: étape finale de la transition, tous les services sont transférés au GCP.
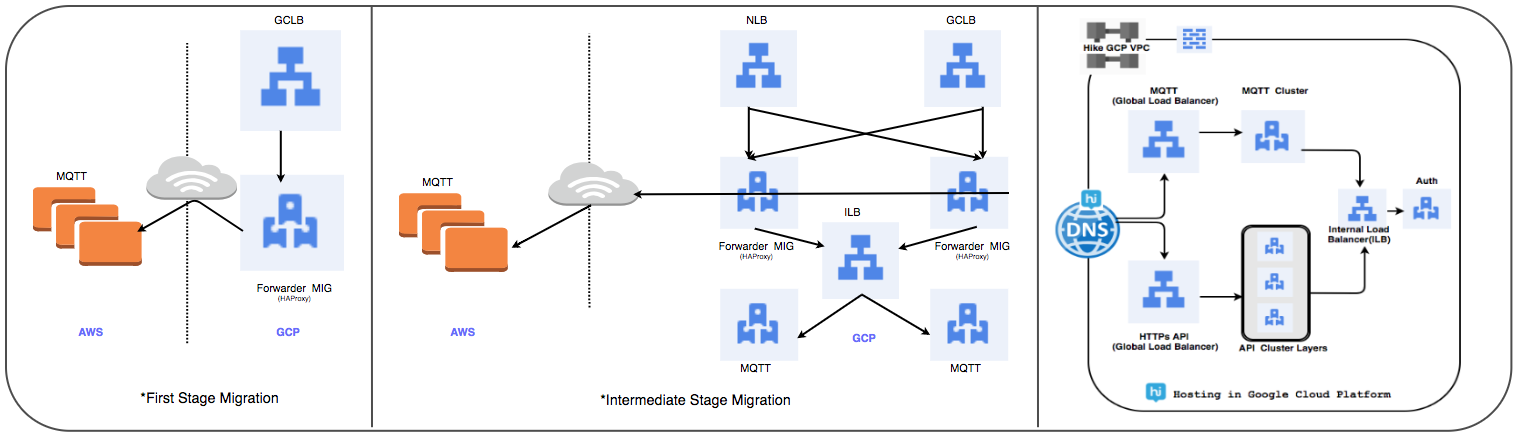
(Étapes de transfert de l'équilibreur de charge)
À ce stade, tout a fonctionné comme prévu. Bientôt, il était temps de déployer plusieurs services HTTP internes dans GCP avec routage - étant donné le poids des coefficients. Nous avons suivi de près tous les indicateurs. Lorsque nous avons commencé à augmenter progressivement le trafic, la veille de la transition prévue, les retards d'interaction VPC via VPN (des retards de 40 ms à 100 ms ont été enregistrés, même s'ils étaient auparavant inférieurs à 10 ms) ont augmenté.
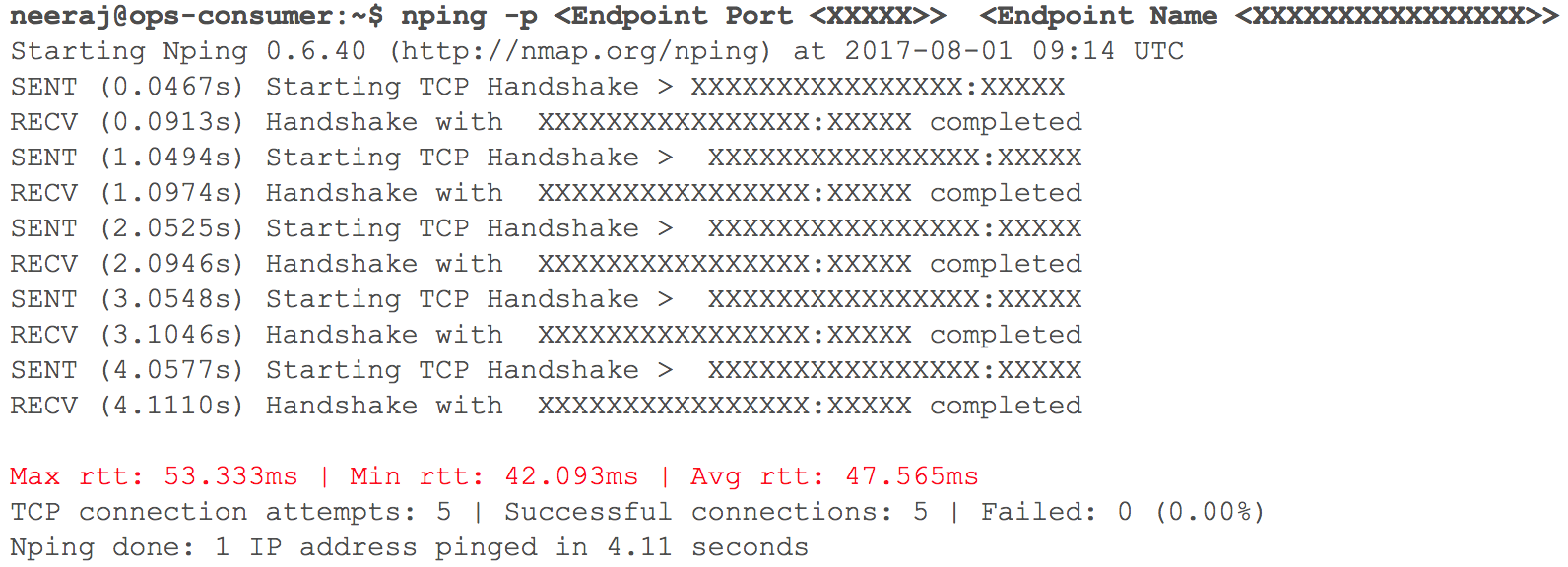
(Instantané de la vérification du retard du réseau lorsque deux VPC interagissent)
La surveillance a clairement montré: quelque chose n'allait pas avec les deux canaux du réseau cloud utilisant des tunnels VPN. Même le débit du tunnel VPN n'a pas atteint la marque optimale. Cette situation a commencé à affecter négativement certains de nos services aux utilisateurs. Nous avons immédiatement renvoyé tous les services HTTP précédemment migrés à leur état d'origine. Nous avons contacté les équipes de support des services cloud et TAM, fourni les données initiales nécessaires et commencé à comprendre pourquoi les retards augmentaient. Les spécialistes du support sont parvenus à la conclusion que la bande passante réseau maximale dans le canal cloud entre deux fournisseurs de services cloud était atteinte. D'où l'augmentation des retards du réseau lors du transfert des systèmes internes.
Cet incident a obligé à suspendre la transition vers le cloud. Les fournisseurs de services cloud ne pouvaient pas doubler la bande passante assez rapidement. Par conséquent, nous sommes revenus à l'étape de la planification et avons révisé la stratégie. Nous avons décidé de transférer l'infrastructure cloud vers GCP en une nuit au lieu de trois et avons inclus dans le plan tous les services de la partie serveur et du stockage des données. Lorsque l'heure «X» est arrivée, tout s'est bien passé: les charges de travail ont été transférées avec succès vers Google Cloud sans être remarquées par nos utilisateurs!
Stratégie de migration de la base de données:
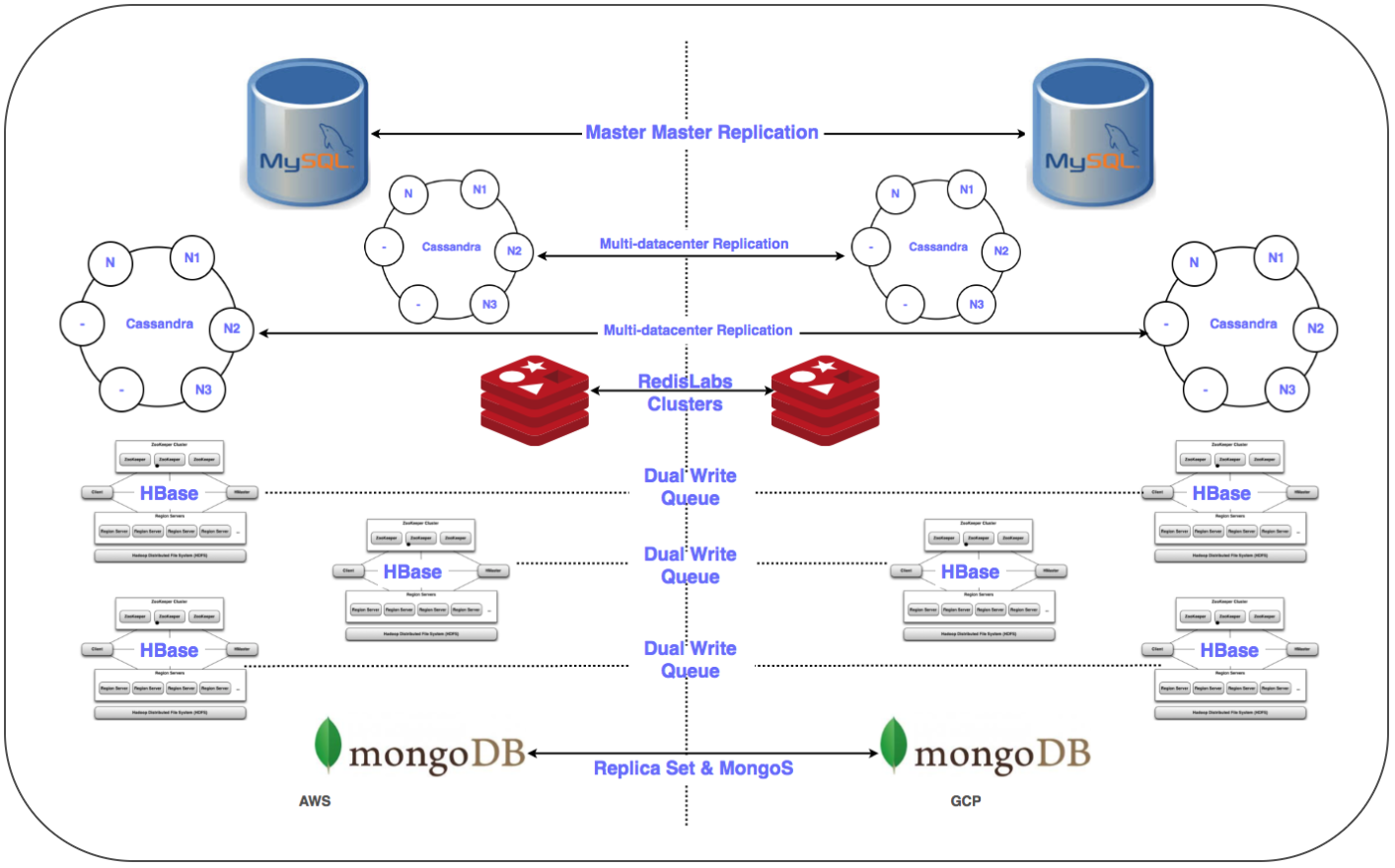
Il était nécessaire de transférer plus de 50 points de terminaison de base de données pour un SGBD relationnel, un stockage en mémoire, ainsi que NoSQL et des clusters distribués et évolutifs à faible latence. Nous avons placé des répliques de toutes les bases de données dans GCP. Cela a été fait pour tous les déploiements sauf HBase.
⊹ Réplication maître-esclave: implémentée pour les clusters MySQL, Redis, MongoDB et MongoS.
Réplication Multi Multi-DC: implémentée pour les clusters Cassandra.
⊹ Clusters doubles: un cluster parallèle a été configuré pour Gbase dans GCP. Les données existantes ont été migrées, la double entrée a été configurée conformément à la stratégie de maintien de la cohérence des données dans les deux clusters.
Dans le cas de HBase, le problème se posait avec Ambari. Nous avons rencontré quelques difficultés lors du placement de clusters dans plusieurs centres de données, par exemple, il y avait des problèmes avec DNS, un script de reconnaissance de rack, etc.
Les dernières étapes (après le déplacement des serveurs) comprenaient le déplacement des répliques vers les serveurs principaux et la fermeture des anciennes bases de données. Comme prévu, déterminant la priorité du transfert de la base de données, nous avons utilisé Zookeeper pour la configuration nécessaire des clusters d'applications.
Stratégie de migration des services d'application
Pour transférer les charges de travail des services d'application de l'hébergement actuel vers le cloud GCP, nous avons utilisé l'approche lift-and-shift. Pour chaque service d'application, nous avons créé un groupe d'instances gérées (MIG) avec mise à l'échelle automatique.
Conformément à un plan détaillé, nous avons commencé à migrer les services vers GCP, en tenant compte de la séquence et des dépendances des entrepôts de données. Tous les services de pile de messagerie ont été migrés vers GCP sans aucun temps d'arrêt. Oui, il y a eu quelques problèmes mineurs, mais nous les avons traités immédiatement.
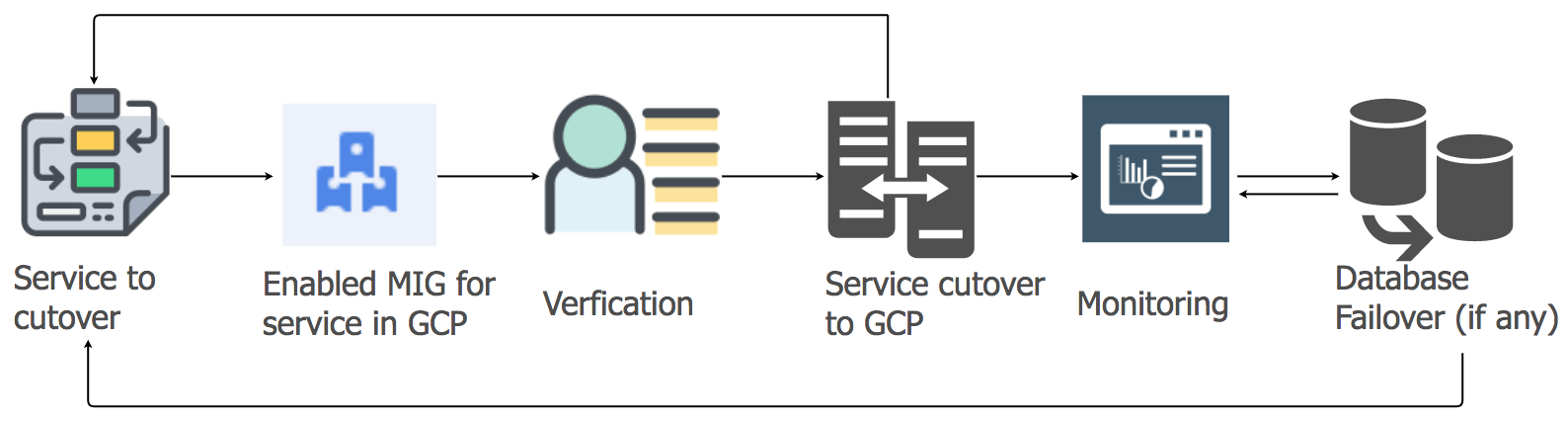
Le matin, alors que l'activité des utilisateurs augmentait, nous avons suivi attentivement tous les tableaux de bord et indicateurs pour identifier rapidement les problèmes. Certaines difficultés ont vraiment surgi, mais nous avons pu les éliminer rapidement. L'un des problèmes était dû aux limites de l'équilibreur de charge interne (ILB), qui ne peut pas gérer plus de 20 000 connexions simultanées. Et il nous en fallait 8 fois plus! Par conséquent, nous avons ajouté des ILB supplémentaires à notre couche de gestion des connexions.
Au cours des premières heures de pointe de charge après la transition, nous avons contrôlé tous les paramètres avec beaucoup de soin, car la totalité de la charge de la pile de messagerie a été transférée vers GCP. Il y a eu quelques problèmes mineurs que nous avons traités très rapidement. Lors de la migration d'autres services, nous avons adopté la même approche.
Migration du stockage d'objets:
Nous utilisons le service de stockage d'objets principalement de trois manières.
⊹ Stockage de fichiers multimédias envoyés à un chat personnel ou de groupe. La période de conservation est déterminée par la politique de gestion du cycle de vie.
⊹ Stockage d'images et de vignettes du profil utilisateur.
⊹ Stockage des fichiers multimédias des sections "Historique" et "Chronologie" et les vignettes correspondantes.
Nous avons utilisé l'outil de transfert de stockage de Google pour copier les anciens objets de S3 vers GCS. Nous avons également utilisé un MIG basé sur Kafka personnalisé pour transférer des objets de S3 vers GCS lorsqu'une logique spéciale était requise.
La transition de S3 à GCS comprenait les étapes suivantes:
● Pour le premier cas d'utilisation du magasin d'objets, nous avons commencé à écrire de nouvelles données à la fois sur S3 et GCS, et après l'expiration, nous avons commencé à lire les données de GCS en utilisant la logique côté application. Le transfert d'anciennes données n'a pas de sens et cette approche est rentable.
● Pour les deuxième et troisième cas d'utilisation, nous avons commencé à écrire de nouveaux objets dans GCS et modifié le chemin de lecture des données afin que la recherche soit d'abord effectuée dans GCS et ensuite, si l'objet n'est pas trouvé, dans S3.
Il a fallu des mois pour planifier, vérifier l'exactitude du concept, préparer et prototyper, mais nous avons ensuite décidé de la transition et l'avons mise en œuvre très rapidement. Nous avons évalué les risques et réalisé que la migration rapide est préférable et presque imperceptible.
Ce projet à grande échelle nous a aidés à acquérir une position forte et à augmenter la productivité de l'équipe dans de nombreux domaines, car la plupart des opérations manuelles sur la gestion de l'infrastructure cloud sont désormais du passé.
● Quant aux utilisateurs, nous avons maintenant reçu tout le nécessaire pour assurer la meilleure qualité de service. Les temps d'arrêt ont presque disparu et les nouvelles fonctionnalités sont mises en œuvre plus rapidement.
● Notre équipe consacre moins de temps aux tâches de maintenance et peut se concentrer sur les projets d'automatisation et la création de nouveaux outils.
● Nous avons eu accès à un ensemble d'outils sans précédent pour travailler avec les mégadonnées, ainsi qu'à des fonctionnalités prêtes à l'emploi pour l'apprentissage et l'analyse automatiques. Voir les détails ici.
● L'engagement de Google Cloud à travailler avec le projet open source Kubernetes est également conforme à notre plan de développement pour cette année.