Dans l' un des articles précédents, j'ai expliqué comment créer un exécuteur de programme pour une machine à pile virtuelle à l'aide d'approches de programmation fonctionnelles et orientées langage. La structure mathématique du langage a suggéré la structure de base pour la mise en œuvre de son traducteur, basée sur le concept de semi-groupes et de monoïdes. Cette approche m'a permis de construire une implémentation magnifique et extensible et de briser les applaudissements, mais la première question du public m'a fait descendre de la tribune et remonter dans Emacs.

J'ai effectué un test simple et je me suis assuré que sur des tâches simples qui n'utilisent que la pile, la machine virtuelle fonctionne intelligemment et lorsque vous utilisez la "mémoire" - un tableau à accès aléatoire - de gros problèmes commencent. La façon dont nous avons réussi à les résoudre sans changer les principes de base de l'architecture du programme et à atteindre une accélération de mille fois le programme sera discutée dans l'article qui est porté à votre attention.
Haskell est une langue particulière avec une niche spéciale. L'objectif principal de sa création et de son développement était la nécessité pour la lingua franca d'exprimer et de tester des idées de programmation fonctionnelle. Cela justifie ses caractéristiques les plus frappantes: la paresse, l'extrême pureté, l'accent mis sur les types et les manipulations avec eux. Il n'a pas été conçu pour le développement quotidien, ni pour la programmation industrielle, ni pour une utilisation généralisée. Le fait qu'il soit vraiment utilisé pour créer des projets à grande échelle dans l'industrie des réseaux et dans le traitement des données est la bonne volonté des développeurs, preuve de concept, si vous voulez. Mais jusqu'à présent, le produit le plus important, largement utilisé et incroyablement puissant écrit en Haskell est ... le compilateur ghc. Et cela est parfaitement justifié du point de vue de sa finalité - être un outil de recherche dans le domaine de l'informatique. Le principe proclamé par Simon Payton-Johnson: «Eviter le succès à tout prix» est nécessaire pour que la langue reste un tel instrument. Haskell est comme une chambre stérile dans le laboratoire d'un centre de recherche développant des technologies semi-conductrices ou des nanomatériaux. Il est terriblement gênant de travailler, et pour la pratique quotidienne, il restreint également la liberté d'action, mais sans ces inconvénients, sans une adhésion sans compromis aux restrictions, il ne sera pas possible d'observer et d'étudier les effets subtils qui deviendront plus tard la base des développements industriels. Dans le même temps, dans l'industrie, la stérilité ne sera nécessaire que dans le volume le plus nécessaire, et les résultats de ces expériences apparaîtront dans nos poches sous forme de gadgets. Nous étudions les étoiles et les galaxies non pas parce que nous nous attendons à en tirer des avantages directs, mais parce qu'à l'échelle de ces objets impraticables, les effets quantiques et relativistes deviennent observables et étudiés, à tel point que plus tard nous pourrons utiliser ces connaissances pour développer quelque chose de très utilitaire. Donc, Haskell avec ses "fausses" lignes, la paresse impraticable des calculs, la rigidité de certains algorithmes d'inférence de type, avec une courbe d'entrée extrêmement raide, ne vous permet finalement pas de créer facilement une application intelligente sur le genou ou un système d'exploitation. Cependant, les lentilles, les monades, l'analyse syntaxique combinatoire, l'utilisation généralisée des monoïdes, les méthodes de démonstration automatique des théorèmes, les gestionnaires de paquets fonctionnels déclaratifs, les types linéaires et dépendants approchent du monde pratique. Cela trouve une application dans des conditions moins stériles dans les langages Python, Scala, Kotlin, F #, Rust et bien d'autres. Mais je n'utiliserais aucun de ces merveilleux langages pour enseigner les principes de la programmation fonctionnelle: j'emmènerais l'élève au laboratoire, montrerais comment cela fonctionne dans des exemples clairs et nets, et ensuite vous pouvez voir ces principes en action dans l'usine une machine grande et incompréhensible, mais très rapide. Éviter le succès à tout prix est une protection contre les tentatives de placer une cafetière dans un microscope électronique afin de la populariser. Et dans les compétitions où la langue est plus cool, Haskell sera toujours en dehors des nominations habituelles.
Cependant, la personne est faible et un démon vit également en moi, ce qui me donne envie de comparer, d'évaluer et de défendre «ma langue préférée» devant les autres. Donc, après avoir écrit une implémentation élégante d'une machine empilée, basée sur une composition monoïdale, dans le seul but de voir si cette idée fonctionne pour moi, j'ai immédiatement été bouleversé de constater que l'implémentation fonctionnait brillamment, mais terriblement inefficacement! C’est comme si j’allais vraiment l’utiliser pour des tâches sérieuses, ou pour vendre ma machine empilée sur le même marché où les machines virtuelles Python ou Java sont proposées. Mais bon sang, l'article sur le porcelet avec lequel toute cette conversation a commencé donne des chiffres aussi savoureux: des centaines de millisecondes pour le porcelet, des secondes pour Python ... et mon beau monoïde ne peut pas faire face à la même tâche en une heure! Je dois réussir! Mon microscope préparera un expresso pas pire qu'une machine à café dans le couloir de l'institut! Le Crystal Palace peut être dispersé et lancé dans l'espace!
Mais qu'êtes-vous prêt à abandonner, me demande l'ange mathématicien? La pureté et la transparence de l'architecture du palais? La flexibilité et l'extensibilité que les homomorphismes des programmes vers d'autres solutions offrent? Le démon et l'ange sont tous deux têtus, et le sage taoïste, que je me permets également de vivre, a proposé de prendre le chemin qui leur convient et de le suivre le plus longtemps possible. Cependant, non dans le but d'identifier le vainqueur, mais afin de connaître le chemin lui-même, de savoir jusqu'où il mène et d'acquérir une nouvelle expérience. Et j'ai donc connu la tristesse et la joie vaines de l'optimisation.
Avant de commencer, nous ajoutons que les comparaisons de langues en termes d'efficacité sont inutiles. Vous devez comparer les traducteurs (interprètes ou compilateurs) ou les performances d'un programmeur qui utilise la langue. Au final, l'affirmation selon laquelle les programmes C sont les plus rapides est facile à réfuter en écrivant un interpréteur C complet en BASIC, par exemple. Donc, nous ne comparons pas Haskell et javascript, mais les performances des programmes exécutés par un traducteur compilé par ghc et des programmes exécutés, disons, dans un navigateur particulier. Toute la terminologie porcine provient d'un article inspirant sur les machines empilées. Tout le code Haskell accompagnant l'article peut être étudié dans le référentiel .
Nous quittons la zone de confort
La position de départ sera la mise en œuvre d'une machine de pile monoïdale sous la forme d' EDSL - un petit langage simple qui permet de combiner deux douzaines de primitives pour rendre les programmes d'une machine de pile virtuelle. Dès qu'il est entré dans le deuxième article, nous lui donnons le nom monopig . Il est basé sur le fait que les langages pour les machines empilées forment un monoïde avec une opération de concaténation et une opération vide en tant qu'unité. En conséquence, il a lui-même été construit sous la forme d'une transformation monoïde de l'état de la machine. L'état comprend une pile, une mémoire sous forme de vecteur (une structure fournissant un accès aléatoire aux éléments), un indicateur d'arrêt d'urgence et une batterie monoïdale pour accumuler des informations de débogage. Toute cette structure est transmise le long d'une chaîne d'endomorphismes d'une opération à l'autre, réalisant un processus de calcul. Une structure isomorphe de codes de programme a été construite à partir de la structure que les programmes forment, et à partir de celle-ci des homomorphismes en d'autres structures utiles représentant les exigences du programme en termes de nombre d'arguments et de mémoire. La dernière étape de la construction a été la création de monoïdes de transformation dans la catégorie Claysley, qui vous permettent d'immerger les calculs dans une monade arbitraire. La machine a donc les capacités d'entrées-sorties et de calculs ambigus. Nous allons commencer par cette implémentation. Son code se trouve ici .
Nous testerons l'efficacité du programme sur l'implémentation naïve du tamis d'Eratosthène, qui remplit la mémoire (tableau) de zéros et de uns, dénotant les nombres premiers par zéro. Nous donnons le code procédural de l'algorithme en javascript :
var memSize = 65536; var arr = []; for (var i = 0; i < memSize; i++) arr.push(0); function sieve() { var n = 2; while (n*n < memSize) { if (!arr[n]) { var k = n; while (k < memSize) { k+=n; arr[k] = 1; } } n++; } }
L'algorithme est immédiatement légèrement optimisé. Il élimine la mauvaise marche à travers les cellules mémoire déjà remplies. Mon ange mathématicien n'a pas accepté une version vraiment naïve d'un exemple du projet PorosenokVM , car cette optimisation ne coûte que cinq instructions du langage de pile. Voici comment l'algorithme se traduit par monopig :
sieve = push 2 <> while (dup <> dup <> mul <> push memSize <> lt) (dup <> get <> branch mempty fill <> inc) <> pop fill = dup <> dup <> add <> while (dup <> push memSize <> lt) (dup <> push 1 <> swap <> put <> exch <> add) <> pop
Et voici comment vous pouvez écrire une implémentation équivalente de cet algorithme sur le Haskell idiomatique, en utilisant les mêmes types que dans monopig :
sieve' :: Int -> Vector Int -> Vector Int sieve' km | k*k < memSize = sieve' (k+1) $ if m ! k == 0 then fill' k (2*k) m else m | otherwise = m fill' :: Int -> Int -> Vector Int -> Vector Int fill' knm | n < memSize = fill' k (n+k) $ m // [(n,1)] | otherwise = m
Il utilise le type Data.Vector et des outils pour travailler avec, qui ne sont pas trop courants pour le travail quotidien dans Haskell. Expression m ! k m ! k renvoie le m ! k -ème élément du vecteur m et m // [(n,1)] - définit l'élément avec le nombre n à 1. J'écris ceci ici parce que je devais leur demander de l'aide, même si je travaille à Haskell presque tous les jours. Le fait est que les structures à accès aléatoire dans une implémentation fonctionnelle sont inefficaces et pour cette raison mal aimées.
Selon les conditions de compétition spécifiées dans l'article sur le porcelet, l'algorithme est exécuté 100 fois. Et pour se débarrasser d'un ordinateur spécifique, comparons les vitesses d'exécution de ces trois programmes, en les référant aux performances du programme javascript qui a été exécuté dans Chrome.
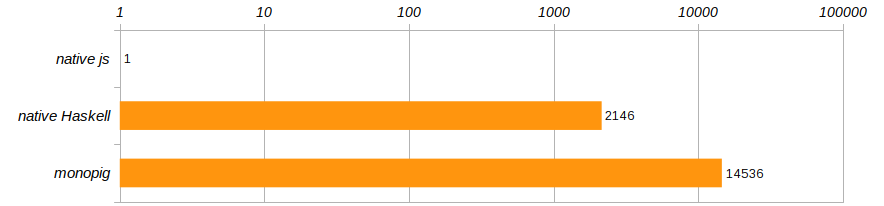
Horreur horreur !!! Non seulement monopig ralentit impie, mais la version native n'est pas beaucoup mieux! Haskell, bien sûr, est cool, mais pas tellement inférieur à un programme fonctionnant dans un navigateur?! Comme nous l’enseignent les entraîneurs, vous ne pouvez pas vivre comme ça, il est temps de quitter la zone de confort que Haskell nous offre!
Surmonter la paresse
Faisons les choses correctement. Pour ce faire, compilez un programme sur monopig avec l'indicateur -rtsopts pour garder une -rtsopts statistiques d'exécution et voir ce dont nous avons besoin pour exécuter le tamis Eratosthenes une fois:
$ ghc -O -rtsopts ./Monopig4.hs [1 of 1] Compiling Main ( Monopig4.hs, Monopig4.o ) Linking Monopig4 ... $ ./Monopig4 -RTS -sstderr "Ok" 68,243,040,608 bytes allocated in the heap 6,471,530,040 bytes copied during GC 2,950,952 bytes maximum residency (30667 sample(s)) 42,264 bytes maximum slop 15 MB total memory in use (7 MB lost due to fragmentation) Tot time (elapsed) Avg pause Max pause Gen 0 99408 colls, 0 par 2.758s 2.718s 0.0000s 0.0015s Gen 1 30667 colls, 0 par 57.654s 57.777s 0.0019s 0.0133s INIT time 0.000s ( 0.000s elapsed) MUT time 29.008s ( 29.111s elapsed) GC time 60.411s ( 60.495s elapsed) <-- ! EXIT time 0.000s ( 0.000s elapsed) Total time 89.423s ( 89.607s elapsed) %GC time 67.6% (67.5% elapsed) Alloc rate 2,352,591,525 bytes per MUT second Productivity 32.4% of total user, 32.4% of total elapsed
La dernière ligne nous indique que le programme n'était engagé dans l'informatique productive qu'un tiers du temps. Pour le reste du temps, le garbage collector a couru de la mémoire et nettoyé pour les calculs paresseux. Combien de fois nous a-t-on dit dans l'enfance que la paresse n'est pas bonne! Ici, la principale caractéristique de Haskell nous a rendu un mauvais service, essayant de créer plusieurs milliards de transformations vectorielles et empilées différées.
À ce stade, un ange mathématicien lève le doigt et parle avec bonheur du fait que depuis l'époque d'Alonzo Church, il existe un théorème selon lequel la stratégie de calcul n'affecte pas leur résultat, ce qui signifie que nous sommes libres de le choisir pour des raisons d'efficacité. Changer les calculs en strict n'est pas difficile du tout - mettez un signe ! dans la déclaration du type de pile et de mémoire, et ainsi rendre ces champs stricts.
data VM a = VM { stack :: !Stack , status :: Maybe String , memory :: !Memory , journal :: !a }
Nous ne changerons rien d'autre et vérifierons immédiatement le résultat:
$ ./Monopig41 +RTS -sstderr "Ok" 68,244,819,008 bytes allocated in the heap 7,386,896 bytes copied during GC 528,088 bytes maximum residency (2 sample(s)) 25,248 bytes maximum slop 16 MB total memory in use (14 MB lost due to fragmentation) Tot time (elapsed) Avg pause Max pause Gen 0 129923 colls, 0 par 0.666s 0.654s 0.0000s 0.0001s Gen 1 2 colls, 0 par 0.001s 0.001s 0.0006s 0.0007s INIT time 0.000s ( 0.000s elapsed) MUT time 13.029s ( 13.048s elapsed) GC time 0.667s ( 0.655s elapsed) EXIT time 0.001s ( 0.001s elapsed) Total time 13.700s ( 13.704s elapsed) %GC time 4.9% (4.8% elapsed) Alloc rate 5,238,049,412 bytes per MUT second Productivity 95.1% of total user, 95.1% of total elapsed
La productivité a considérablement augmenté. Le coût total de la mémoire est resté impressionnant en raison de l'immuabilité des données, mais surtout, maintenant que nous avons limité la paresse des données, le garbage collector a la possibilité d'être paresseux, seulement 5% du travail reste dessus. Entrez une nouvelle entrée dans la note.

Eh bien, des calculs rigoureux nous ont rapprochés de la vitesse du code natif Haskell, qui ralentit honteusement sans aucune machine virtuelle. Cela signifie que les frais généraux liés à l'utilisation d'un vecteur immuable dépassent considérablement le coût de maintenance d'une machine empilée. Et cela signifie qu'il est temps de dire au revoir à l'immuabilité de la mémoire.
Laisser les changements prendre vie
Le type Data.Vector bon, mais en l'utilisant, nous passons beaucoup de temps à copier, au nom de la préservation de la pureté du processus informatique. En le remplaçant par le type Data.Vector.Unpacked nous économisons au moins sur l'emballage de la structure, mais cela ne change pas fondamentalement l'image. La bonne solution serait de supprimer la mémoire de l'état de la machine et de donner accès au vecteur externe en utilisant la catégorie Kleisley. En même temps, avec des vecteurs purs, vous pouvez utiliser les vecteurs dits mutables (mutables) Data.Vector.Mutable .
Nous allons connecter les modules appropriés et réfléchir à la façon de traiter les données mutables dans un programme fonctionnel propre.
import Control.Monad.Primitive import qualified Data.Vector.Unboxed as V import qualified Data.Vector.Unboxed.Mutable as M
Ces types sales sont censés être isolés du pur public. Ils sont contenus dans les monades de la classe PrimMonad (celles-ci incluent ST ou IO ), où des programmes propres insèrent soigneusement des instructions pour des actions écrites dans un langage fonctionnel cristallin sur un parchemin précieux. Ainsi, le comportement de ces animaux impurs est déterminé par des scénarios strictement orthodoxes et n'est pas dangereux. Tous les programmes de notre machine n'utilisent pas de mémoire, il n'est donc pas nécessaire de condamner toute l'architecture à l'immersion dans la monade IO . Parallèlement à un sous-ensemble propre du langage monopig nous créerons quatre instructions qui donnent accès à la mémoire, et seules elles auront accès au territoire dangereux.
Le type de machine propre se raccourcit:
data VM a = VM { stack :: !Stack , status :: Maybe String , journal :: !a }
Les concepteurs de programmes et les programmes eux-mêmes ne remarqueront guère ce changement, mais leurs types changeront. De plus, il est logique de définir plusieurs types de synonymes pour simplifier les signatures.
type Memory m = M.MVector (PrimState m) Int type Logger ma = Memory m -> Code -> VM a -> m (VM a) type Program' ma = Logger ma -> Memory m -> Program ma
Les constructeurs auront un autre argument représentant l'accès à la mémoire. Les exécuteurs changeront considérablement, en particulier ceux qui conservent un journal de calcul, car ils doivent maintenant demander l'état du vecteur variable pour cela. Le code complet peut être vu et étudié dans le référentiel, mais ici je donnerai le plus intéressant: l'implémentation des composants de base pour travailler avec la mémoire pour montrer comment cela est fait.
geti :: PrimMonad m => Int -> Program' ma geti i = programM (GETI i) $ \mem -> \s -> if (0 <= i && i < memSize) then \vm -> do x <- M.unsafeRead mem i setStack (x:s) vm else err "index out of range" puti :: PrimMonad m => Int -> Program' ma puti i = programM (PUTI i) $ \mem -> \case (x:s) -> if (0 <= i && i < memSize) then \vm -> do M.unsafeWrite mem ix setStack s vm else err "index out of range" _ -> err "expected an element" get :: PrimMonad m => Program' ma get = programM (GET) $ \m -> \case (i:s) -> \vm -> do x <- M.read mi setStack (x:s) vm _ -> err "expected an element" put :: PrimMonad m => Program' ma put = programM (PUT) $ \m -> \case (i:x:s) -> \vm -> M.write mix >> setStack s vm _ -> err "expected two elemets"
Le démon optimiseur a immédiatement proposé d'économiser un peu plus sur la vérification des valeurs d'index autorisées en mémoire, car pour les geti puti et geti indices sont connus au stade de la création du programme et les valeurs incorrectes peuvent être éliminées à l'avance. Les index définis dynamiquement pour les commandes put et get ne garantissent pas la sécurité, et l'ange mathématicien n'a pas permis de leur faire des appels dangereux.
Tout ce tapage avec la mise en mémoire dans un argument séparé semble compliqué. Mais cela montre très clairement que les données doivent être modifiées à leur place - elles devraient être à l'extérieur . Je vous rappelle que nous essayons d'amener un livreur de pizza dans un laboratoire stérile. Les fonctions pures savent quoi en faire, mais ces objets ne deviendront jamais des citoyens de première classe, et cela ne vaut pas la peine de préparer une pizza directement dans le laboratoire.
Vérifions ce que nous avons acheté avec ces changements:
$ ./Monopig5 +RTS -sstderr "Ok" 9,169,192,928 bytes allocated in the heap 2,006,680 bytes copied during GC 529,608 bytes maximum residency (2 sample(s)) 25,248 bytes maximum slop 2 MB total memory in use (0 MB lost due to fragmentation) Tot time (elapsed) Avg pause Max pause Gen 0 17693 colls, 0 par 0.094s 0.093s 0.0000s 0.0001s Gen 1 2 colls, 0 par 0.000s 0.000s 0.0002s 0.0003s INIT time 0.000s ( 0.000s elapsed) MUT time 7.228s ( 7.232s elapsed) GC time 0.094s ( 0.093s elapsed) EXIT time 0.000s ( 0.000s elapsed) Total time 7.325s ( 7.326s elapsed) %GC time 1.3% (1.3% elapsed) Alloc rate 1,268,570,828 bytes per MUT second Productivity 98.7% of total user, 98.7% of total elapsed
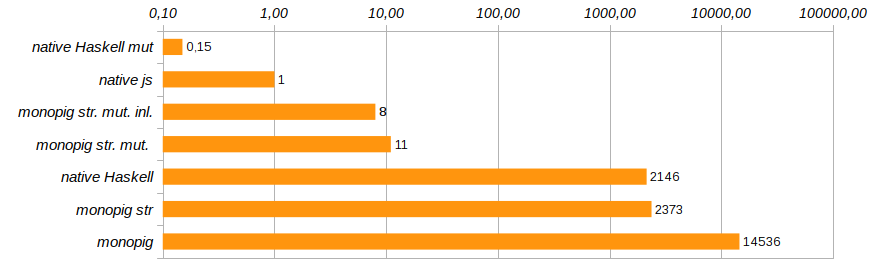
C'est déjà du progrès! L'utilisation de la mémoire a été réduite huit fois, la vitesse d'exécution du programme a augmenté de 180 fois et le garbage collector est resté presque complètement sans travail.

La solution est apparue monopig st. mut. , qui est dix fois plus lent que la solution native sur js , mais à part cela, la solution native sur Haskell, en utilisant des vecteurs mutables. Voici son code:
fill' :: Int -> Int -> Memory IO -> IO (Memory IO) fill' knm | n > memSize-k = return m | otherwise = M.unsafeWrite mn 1 >> fill' k (n+k) m sieve' :: Int -> Memory IO -> IO (Memory IO) sieve' km | k*k < memSize = do x <- M.unsafeRead mk if x == 0 then fill' k (2*k) m >>= sieve' (k+1) else sieve' (k+1) m | otherwise = return m
Cela commence comme suit
main = do m <- M.replicate memSize 0 stimes 100 (sieve' 2 m >> return ()) print "Ok"
Et maintenant, Haskell montre enfin qu'il n'est pas un langage jouet. Vous avez juste besoin de l'utiliser à bon escient. Par ailleurs, le code ci-dessus utilise le fait que le type IO () forme un semi-groupe avec l'opération d'exécution séquentielle des programmes (>>) , et à l'aide de stimes nous avons répété 100 fois le calcul du problème de test.
Maintenant, il est clair pourquoi il y a une telle aversion pour les tableaux fonctionnels et pourquoi personne ne se souvient comment travailler avec eux: dès qu'un programmeur Haskell a vraiment besoin de structures d'accès aléatoire, il se recentre sur les données mutables et travaille dans les monades ST ou IO.
Mettre une partie des commandes dans une zone spéciale remet en cause la légalité de l'isomorphisme le programme . Après tout, nous ne pouvons pas simultanément transformer le code en programmes purs et monadiques, cela ne permet pas au système de type de le faire. Cependant, les classes de types sont suffisamment flexibles pour que cet isomorphisme existe. Code d' homomorphisme le programme est maintenant divisé en plusieurs homomorphismes pour différents sous-ensembles de la langue. Comment exactement cela est fait peut être vu dans le [code] () complet du programme.
Ne vous arrêtez pas là
L'élimination des appels de fonction inutiles et l'intégration directe de leur code à l'aide du pragma {-# INLINE #-} aideront à modifier légèrement la productivité du programme. Cette méthode ne convient pas aux fonctions récursives, mais est idéale pour les composants de base et les fonctions de définition. Il réduit le temps d'exécution du programme de test de 25% supplémentaires (voir Monopig51.hs ).
La prochaine étape raisonnable sera de se débarrasser des outils de journalisation lorsqu'ils ne sont pas nécessaires. Au stade de la formation de l'endomorphisme représentant le programme, nous utilisons un argument externe, que nous déterminons au démarrage. Le program constructeurs intelligents et programM peuvent être avertis qu'il peut n'y avoir aucun enregistreur d'arguments. Dans ce cas, le code convertisseur ne contient rien de superflu: uniquement la fonctionnalité et la vérification de l'état de la machine.
program code f = programM code (const f) programM code f (Just logger) mem = Program . ([code],) . ActionM $ \vm -> case status vm of Nothing -> logger mem code =<< f mem (stack vm) vm _ -> return vm programM code f _ mem = Program . ([code],) . ActionM $ \vm -> case status vm of Nothing -> f mem (stack vm) vm _ -> return vm
Désormais, l'exécution des fonctions doit indiquer explicitement la présence ou l'absence de journalisation non pas en utilisant le stub none , mais en utilisant le type Maybe (Logger ma) . Pourquoi cela devrait-il fonctionner, car s'il y a une journalisation ou non, les composants du programme le sauront "au dernier moment", avant l'exécution? Le code inutile ne serait-il pas cousu au stade de la composition de la programmation? Haskell est une langue paresseuse et ici elle joue entre nos mains. C'est avant l'exécution que le code final est optimisé pour une tâche spécifique. Cette optimisation a réduit le temps d'exécution du programme de 40% supplémentaires (voir Monopig52.hs ).
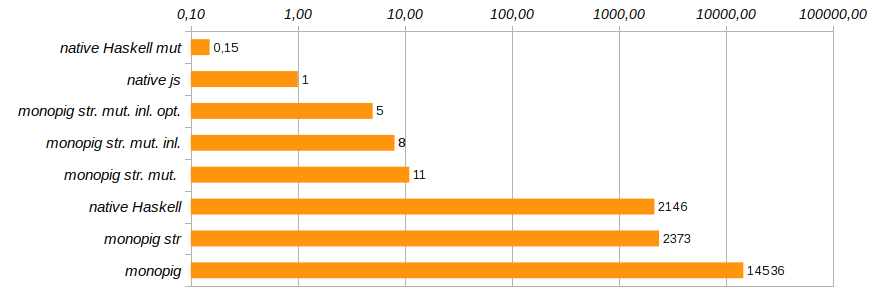
Avec cela, nous terminerons les travaux sur l'accélération du porcelet monoïde. Il court déjà assez vite pour que l'ange et le démon puissent se calmer. Bien sûr, ce n'est pas C, nous utilisons toujours une liste propre comme pile, mais le remplacer par un tableau entraînera une fouille approfondie du code et le refus d'utiliser des modèles élégants dans les définitions des commandes de base. Je voulais m'en sortir avec un minimum de changements, et principalement au niveau des types.
Certains problèmes persistent avec la journalisation. Un simple décompte du nombre d'étapes ou de l'utilisation de la pile fonctionne bien (nous avons rendu le champ de journal strict), mais leur association commence déjà à consommer de la mémoire, vous devez jouer avec les coups de pied en utilisant seq , ce qui est déjà assez ennuyeux. Mais dites-moi, qui enregistrera les 14 milliards d'étapes, si vous pouvez déboguer la tâche dans les premières centaines? Je ne passerai donc pas mon temps à accélérer pour accélérer.
Il ne reste plus qu'à ajouter que dans l'article sur le porcelet, comme l'une des méthodes d'optimisation des calculs, le traçage est donné: l'allocation des sections linéaires de code, les traces à l' intérieur desquelles les calculs peuvent être effectués en contournant le cycle de répartition des commandes principales (bloc de switch ). Dans notre cas, la composition monoïdale des composants du programme crée de telles traces soit lors de la formation du programme à partir des composants EDSL, soit lors du fonctionnement de l'homomorphisme fromCode . Cette méthode d'optimisation nous est gratuite, pour ainsi dire, par construction.
Il existe de nombreuses solutions Conduits et rapides dans l'écosystème Haskell, telles que les flux de Conduits ou de Pipes , il existe d'excellents remplacements de String et des créateurs XML agiles tels que blaze-html, et l'analyseur attoparsec est une norme pour l'analyse combinatoire des grammaires LL (∞). Tout cela est nécessaire pour un fonctionnement normal. Mais la recherche menant à ces décisions est encore plus nécessaire. Haskell a été et demeure un outil de recherche qui répond à des exigences spécifiques dont le grand public n'a pas besoin. J'ai vu au Kamchatka comment les as d'un hélicoptère Mi-4 ont fermé les boîtes d'allumettes lors d'une dispute, poussant le train d'atterrissage avec une roue tout en étant suspendu en l'air. Cela peut être fait, et c'est cool, mais pas nécessaire.
Mais, néanmoins, c'est cool !!