Bonjour les vagabonds. Nous, en tant que voyageurs dans nos pensées et analyseurs de notre condition, devons comprendre où c'est bon et où sinon, où nous sommes exactement, et je veux attirer l'attention des lecteurs sur ce point.
Comment assembler des chaînes de pensées, séquentiellement?, En supposant la conclusion de chaque étape, en contrôlant le flux de contrôle et l'état des cellules en mémoire? Ou tout simplement en décrivant l'énoncé du problème, dites au programme quelle tâche particulière vous souhaitez résoudre, et cela suffit pour compiler tous les programmes. Ne transformez pas le codage en un flux de commandes qui changera l'état interne du système, mais exprimez le principe comme le concept de tri, car vous n'avez pas besoin d'imaginer quel type d'algorithme y est caché, il vous suffit d'obtenir les données triées. Ce n'est pas pour rien que le président américain peut citer la Bulle, il exprime l'idée qu'il a compris quelque chose en programmation. Il vient de découvrir qu'il existe un algorithme de tri, et les données du tableau sur son bureau, par elles-mêmes, ne peuvent pas s'aligner, d'une manière magique, par ordre alphabétique.
Cette idée que je suis bien disposé envers la manière déclarative d'exprimer des pensées, et de tout exprimer avec une séquence de commandes et de transitions entre elles, semble archaïque et dépassée, parce que nos grands-pères l'ont fait, les grands-pères ont câblé les contacts sur le panneau de brassage et ont fait clignoter les lumières, et nous avons un moniteur et une reconnaissance vocale, car à ce niveau d'évolution, vous pouvez toujours penser à suivre les commandes ... Il me semble que si vous exprimez le programme dans un langage logique, il sera plus compréhensible, et cela peut être fait en technologie, un pari a été fait dans les années 80.
Eh bien, l'introduction a traîné en longueur ...
Je vais essayer, pour commencer, de raconter à nouveau le mécanisme de tri rapide. Pour trier une liste, vous devez la diviser en deux sous-listes et combiner la sous-liste triée avec une autre sous-liste triée .
L'opération de fractionnement doit pouvoir transformer la liste en deux sous-listes, l'une d'entre elles contient tous les éléments moins basiques et la seconde liste ne contient que des éléments volumineux. Exprimant cela, seules deux lignes sont écrites sur Erlang:
qsort([])->[]; qsort([H|T])->qsort([X||X<-T,X<H])++[H|qsort([X||X<-T,X>=H])].
Ces expressions du résultat du processus de pensée m'intéressent.
Le tri impératif est plus difficile à décrire. Comment pourrait-il y avoir un avantage à cette méthode de programmation, et alors vous ne l'appelez pas, même s'il existe un s-place-place, au moins un fortran. Est-ce parce que javascript, et toutes les tendances des fonctions lambda dans les nouveaux standards de toutes les langues, est une confirmation des inconvénients de l'algorithmicité.
Je vais essayer de mener une expérience pour vérifier les avantages d'une approche et d'une autre, pour les tester. Je vais essayer de montrer que l'enregistrement déclaratif de la définition du tri et son enregistrement algorithmique peuvent être comparés en termes de performances et conclure comment formuler les programmes plus correctement. Peut-être que cela poussera la programmation à l'étagère à travers des algorithmes et un flux de commandes, comme des approches simplement obsolètes, qui ne sont pas du tout pertinentes à utiliser, car il n'est pas moins à la mode de s'exprimer dans un Haskell ou dans une coupe transversale. Et peut-être que non seulement la netteté des fées peut donner aux programmes un aspect clair et compact?
J'utiliserai Python pour la démonstration, car il a plusieurs paradigmes, et ce n'est pas du tout C ++ et ce n'est plus lisp. Vous pouvez écrire un programme clair dans un paradigme différent:
Trier 1
def qsort(S): if S==[]:return [] H,T=S[0],S[1:] return qsort([X for X in T if X<T])+[H]+qsort([X for X in T if X>=T])
Les mots peuvent être prononcés comme ceci: le tri prend le premier élément comme base, puis tous les plus petits sont triés et connectés à tous les plus grands, avant ce tri .
Ou peut-être qu'une telle expression fonctionne plus rapidement qu'un tri écrit sous la forme maladroite d'une permutation de certains éléments à proximité ou non. Est-il possible de l'exprimer plus succinctement et de ne pas exiger autant de mots pour cela? Essayez de formuler à haute voix le principe du tri par bulle et de le dire au président des États-Unis , car il a obtenu ces données sacrées, il a appris les algorithmes et les a formulés, par exemple, comme ceci: pour trier la liste, vous devez prendre quelques éléments, les comparer les uns aux autres et si le premier est supérieur au second, ils doivent être échangés, réorganisés, puis vous devez répéter la recherche de paires de ces éléments depuis le tout début de la liste jusqu'à la fin des permutations .
Oui, le principe du tri d'une bulle sonne même plus longtemps que la version de tri rapide, mais le deuxième avantage réside non seulement dans la brièveté de l'enregistrement, mais aussi dans sa rapidité, l'expression du même tri rapide formulée par l'algorithme sera-t-elle plus rapide que la version exprimée de manière déclarative? Peut-être que nous devons changer notre point de vue sur la programmation de l'enseignement, il est nécessaire comment les Japonais ont essayé d'introduire l'enseignement du Prologue et la pensée connexe dans les écoles. Vous pouvez systématiquement vous éloigner des langages algorithmiques d'expression des pensées.
Trier 2
Pour reproduire cela, j'ai dû me tourner vers la littérature , ceci est une déclaration de Hoar , j'essaie de la transformer en Python:
def quicksort(A, lo, hi): if lo < hi: p = partition(A, lo, hi) quicksort(A, lo, p - 1) quicksort(A, p + 1, hi) return A def partition(A, lo, hi): pivot = A[lo] i = lo - 1 j = hi + 1 while True do: i= i + 1 while A[i] < pivot do : j= j - 1 while A[j] > pivot if i >= j: return j A[i],A[j]=A[j],A[i]
J'admire la pensée, un cycle sans fin est nécessaire ici, il aurait inséré un go-that là)), il y avait des jokers.
Analyse
Faisons maintenant une longue liste et faisons-la trier par les deux méthodes, et comprenons comment exprimer nos pensées plus rapidement et plus efficacement. Quelle approche est la plus facile à adopter?
Créer une liste de nombres aléatoires en tant que problème distinct, voici comment il peut être exprimé:
def qsort(S): if S==[]:return [] H,T=S[0],S[1:] return qsort([X for X in T if X<H])+[H]+qsort([X for X in T if X>=H]) import random def test(len): list=[random.randint(-100, 100) for r in range(0,len)] from time import monotonic start = monotonic() slist=qsort(list) print('qsort='+str(monotonic() - start))
Voici les mesures obtenues:
>>> test(10000) qsort=0.046999999998661224 >>> test(10000) qsort=0.0629999999946449 >>> test(10000) qsort=0.046999999998661224 >>> test(100000) qsort=4.0789999999979045 >>> test(100000) qsort=3.6560000000026776 >>> test(100000) qsort=3.7340000000040163 >>>
Maintenant, je répète cela dans la formulation de l'algorithme:
def quicksort(A, lo, hi): if lo < hi: p = partition(A, lo, hi) quicksort(A, lo, p ) quicksort(A, p + 1, hi) return A def partition(A, lo, hi): pivot = A[lo] i = lo-1 j = hi+1 while True: while True: i=i+1 if(A[i]>=pivot) or (i>=hi): break while True: j=j-1 if(A[j]<=pivot) or (j<=lo): break if i >= j: return max(j,lo) A[i],A[j]=A[j],A[i] import random def test(len): list=[random.randint(-100, 100) for r in range(0,len)] from time import monotonic start = monotonic() slist=quicksort(list,0,len-1) print('quicksort='+str(monotonic() - start))
J'ai dû travailler sur la transformation de l'exemple original de l'algorithme de sources anciennes vers Wikipedia. Donc ceci: vous devez prendre l'élément de support et organiser les éléments dans le sous-tableau de sorte que tout soit de moins en moins à gauche, et de plus en plus à droite. Pour ce faire, échangez la gauche avec l'élément droit. Nous répétons cela pour chaque sous-liste de l'élément de référence divisé par l'indice, s'il n'y a rien à changer, nous terminons .
Total
Voyons quel sera le décalage horaire pour la même liste, qui est triée tour à tour par deux méthodes. Nous allons mener 100 expériences et construire un graphique:
import random def test(len): t1,t2=[],[] for n in range(1,100): list=[random.randint(-100, 100) for r in range(0,len)] list2=list[:] from time import monotonic start = monotonic() slist=qsort(list) t1+=[monotonic() - start]
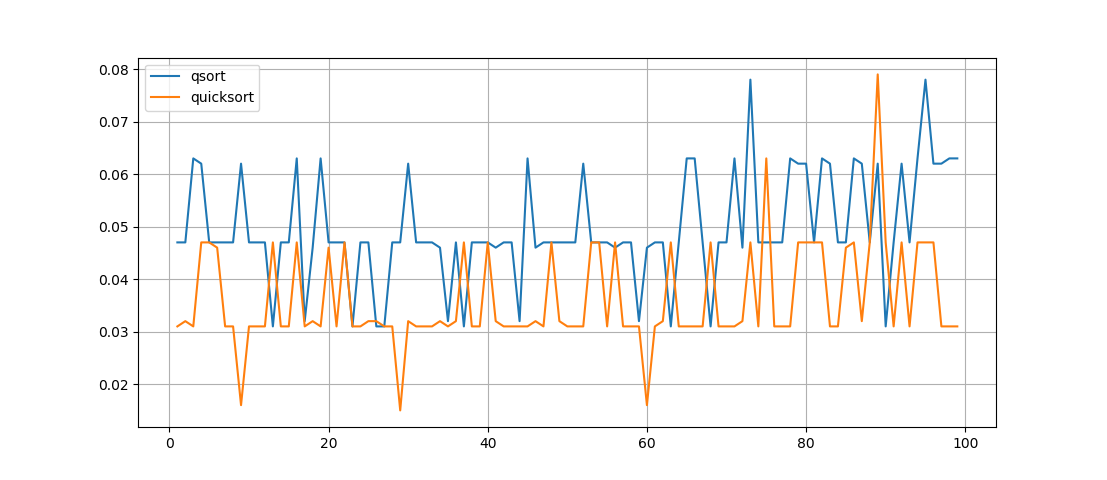
Ce que l'on peut voir ici - la fonction quicksort () fonctionne plus rapidement , mais son enregistrement n'est pas si évident, bien que la fonction soit récursive, mais il n'est pas du tout facile de comprendre le travail des permutations qui y sont effectuées.
Eh bien, quelle expression de la pensée de tri est plus consciente?
Avec une petite différence de performances, nous obtenons une telle différence dans le volume et la complexité du code.
Peut-être que la vérité suffit pour apprendre les langues impératives, mais qu'est-ce qui vous attire le plus?
PS. Et voici le Prologue:
qsort([],[]). qsort([H|T],Res):- findall(X,(member(X,T),X<H),L1), findall(X,(member(X,T),X>=H),L2), qsort(L1,S1), qsort(L2,S2), append(S1,[H|S2],Res).