SDRAM DDR3 moderne. Source: BY-SA / 4.0 par KjerishLors d'une récente visite au
Computer History Museum de Mountain View, un ancien échantillon de
mémoire en ferrite a attiré mon attention.
Source: BY-SA / 3.0 par Konstantin LanzetJe suis rapidement arrivé à la conclusion que je n'ai aucune idée de la façon dont ces choses fonctionnent. Les anneaux tournent-ils (non) et pourquoi trois fils passent-ils dans chaque anneau (je ne comprends toujours pas comment ils fonctionnent). Plus important encore, j'ai réalisé que j'avais très peu d'idée du fonctionnement de la RAM dynamique moderne!
Source: Cycle de mémoire d'Ulrich DrapperJ'étais particulièrement intéressé par l'une des conséquences du fonctionnement de la RAM dynamique. Il s'avère que chaque bit de données est stocké par une charge (ou son absence) sur un minuscule condensateur dans la puce RAM. Mais ces condensateurs perdent progressivement leur charge au fil du temps. Pour éviter la perte de données stockées, celles-ci doivent être mises à jour régulièrement pour restaurer la charge (le cas échéant) à son niveau d'origine. Ce
processus de mise à jour implique la lecture de chaque bit, puis sa réécriture. Pendant cette «mise à jour», la mémoire est occupée et ne peut pas effectuer d'opérations normales, telles que l'écriture ou le stockage de bits.
Cela m'a longtemps dérangé, et je me suis demandé ... est-il possible de constater un retard dans la mise à jour au niveau du programme?
Base de formation pour la mise à niveau de la RAM dynamique
Chaque module DIMM se compose de «cellules» et de «lignes», de «colonnes», de «côtés» et / ou de «rangs».
Cette présentation de l'Université de l'Utah explique la nomenclature. La configuration de la mémoire de l'ordinateur peut être vérifiée avec la
decode-dimms . Voici un exemple:
$ decode-dimms
Taille 4096 MB
Banques x rangées x colonnes x bits 8 x 15 x 10 x 64
Rangs 2
Nous n'avons pas besoin de comprendre l'ensemble du schéma DDR DIMM, nous voulons comprendre le fonctionnement d'une seule cellule qui stocke un bit d'information. Plus précisément, nous ne sommes intéressés que par le processus de mise à jour.
Considérez deux sources:
Chaque bit de la mémoire dynamique doit être mis à jour: cela se produit généralement toutes les 64 ms (la mise à jour dite statique). C'est une opération assez coûteuse. Pour éviter un arrêt majeur toutes les 64 ms, le processus est divisé en 8192 opérations de mise à jour plus petites. Dans chacun d'eux, le contrôleur de mémoire de l'ordinateur envoie des commandes de mise à jour aux puces DRAM. Après avoir reçu les instructions, la puce mettra à jour 1/8192 cellules. Si vous comptez, alors 64 ms / 8192 = 7812,5 ns ou 7,81 μs. Cela signifie ce qui suit:
- Une commande de mise à jour est exécutée toutes les 7812,5 ns. Il s'appelle tREFI.
- Le processus de mise à jour et de récupération prend un certain temps, de sorte que la puce peut à nouveau effectuer des opérations de lecture et d'écriture normales. Le soi-disant tRFC est égal à 75 ns ou 120 ns (comme dans la documentation Micron mentionnée).
Si la mémoire est chaude (plus de 85 ° C), le temps de stockage des données en mémoire diminue et le temps de mise à jour statique est réduit de moitié à 32 ms. En conséquence, le tREFI chute à 3906,25 ns.
Une puce de mémoire typique est occupée à se mettre à jour pendant une partie importante de sa durée de vie: de 0,4% à 5%. De plus, les puces mémoire sont responsables de la part non négligeable de la consommation d'énergie d'un ordinateur typique, et la majeure partie de cette énergie est consacrée aux mises à niveau.
La puce mémoire entière est bloquée lors de la mise à jour. C'est-à-dire que chaque bit en mémoire est verrouillé pendant plus de 75 ns toutes les 7812 ns. Mesurons-le.
Préparation à l'expérience
Pour mesurer des opérations avec une précision en nanosecondes, vous avez besoin d'un cycle très serré, peut-être en C. Cela ressemble à ceci:
for (i = 0; i < ...; i++) {
Le code complet est disponible sur GitHub.Le code est très simple. Effectuez la lecture de la mémoire. Nous vidons les données du cache CPU. Nous mesurons le temps.
(Remarque: dans la
deuxième expérience, j'ai essayé d'utiliser MOVNTDQA pour charger des données, mais cela nécessite une page mémoire spéciale non-cache et des droits root).
Sur mon ordinateur, le programme affiche les données suivantes:
# horodatage, durée du cycle
3101895733, 134
3101895865, 132
3101896002, 137
3101896134, 132
3101896268, 134
3101896403, 135
3101896762, 359
3101896901, 139
3101897038, 137
Habituellement, un cycle d'une durée d'environ 140 ns est obtenu, périodiquement le temps passe à environ 360 ns. Parfois, des résultats étranges apparaissent plus de 3200 ns.
Malheureusement, les données sont trop bruyantes. Il est très difficile de voir s'il y a un retard notable associé aux cycles de mise à jour.
Transformation de Fourier rapide
À un moment donné, il m'est apparu. Puisque nous voulons trouver un événement avec un intervalle fixe, nous pouvons soumettre des données à l'algorithme FFT (transformée de Fourier rapide), qui décrypte les fréquences principales.
Je ne suis pas le premier à y penser: Mark Seaborn avec la fameuse vulnérabilité
Rowhammer a mis en œuvre cette technique même en 2015. Même après avoir regardé le code de Mark, mettre la FFT au travail était plus difficile que ce à quoi je m'attendais. Mais à la fin, j'ai rassemblé toutes les pièces.
Vous devez d'abord préparer les données. La FFT nécessite une entrée avec un intervalle d'échantillonnage constant. Nous voulons également rogner les données pour réduire le bruit. Par essais et erreurs, j'ai constaté que le meilleur résultat est obtenu après un traitement préliminaire des données:
- Les petites valeurs (moins de 1,8 en moyenne) d'itérations de boucle sont coupées, ignorées et remplacées par des zéros. Nous ne voulons vraiment pas faire de bruit.
- Toutes les autres lectures sont remplacées par des unités, car l'amplitude du retard causé par un certain bruit n'est vraiment pas importante pour nous.
- J'ai choisi un intervalle d'échantillonnage de 100 ns, mais n'importe quel nombre jusqu'à la fréquence de Nyquist (double fréquence attendue) fera l'affaire .
- Les données doivent être échantillonnées à un moment fixe avant d'être soumises à la FFT. Toutes les méthodes d'échantillonnage raisonnables fonctionnent bien, j'ai opté pour une interpolation linéaire de base.
L'algorithme est quelque chose comme ceci:
UNIT=100ns A = [(timestamp, loop_duration),...] p = 1 for curr_ts in frange(fist_ts, last_ts, UNIT): while not(A[p-1].timestamp <= curr_ts < A[p].timestamp): p += 1 v1 = 1 if avg*1.8 <= A[p-1].duration <= avg*4 else 0 v2 = 1 if avg*1.8 <= A[p].duration <= avg*4 else 0 v = estimate_linear(v1, v2, A[p-1].timestamp, curr_ts, A[p].timestamp) B.append( v )
Lequel sur mes données produit un vecteur plutôt ennuyeux comme celui-ci:
[0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ...]
Cependant, le vecteur est assez grand, généralement environ 200 000 points de données. Avec de telles données, vous pouvez utiliser FFT!
C = numpy.fft.fft(B) C = numpy.abs(C) F = numpy.fft.fftfreq(len(B)) * (1000000000/UNIT)
Assez simple, non? Cela produit deux vecteurs:
- C contient un nombre complexe de composantes de fréquence. Nous ne nous intéressons pas aux nombres complexes, et vous pouvez les lisser avec la commande
abs() . - F contient des étiquettes, dont l'étendue de fréquence se situe à quelle place du vecteur C. Nous normalisons l'exposant en hertz en multipliant par la fréquence d'échantillonnage du vecteur d'entrée.
Le résultat peut être tracé sur un graphique:
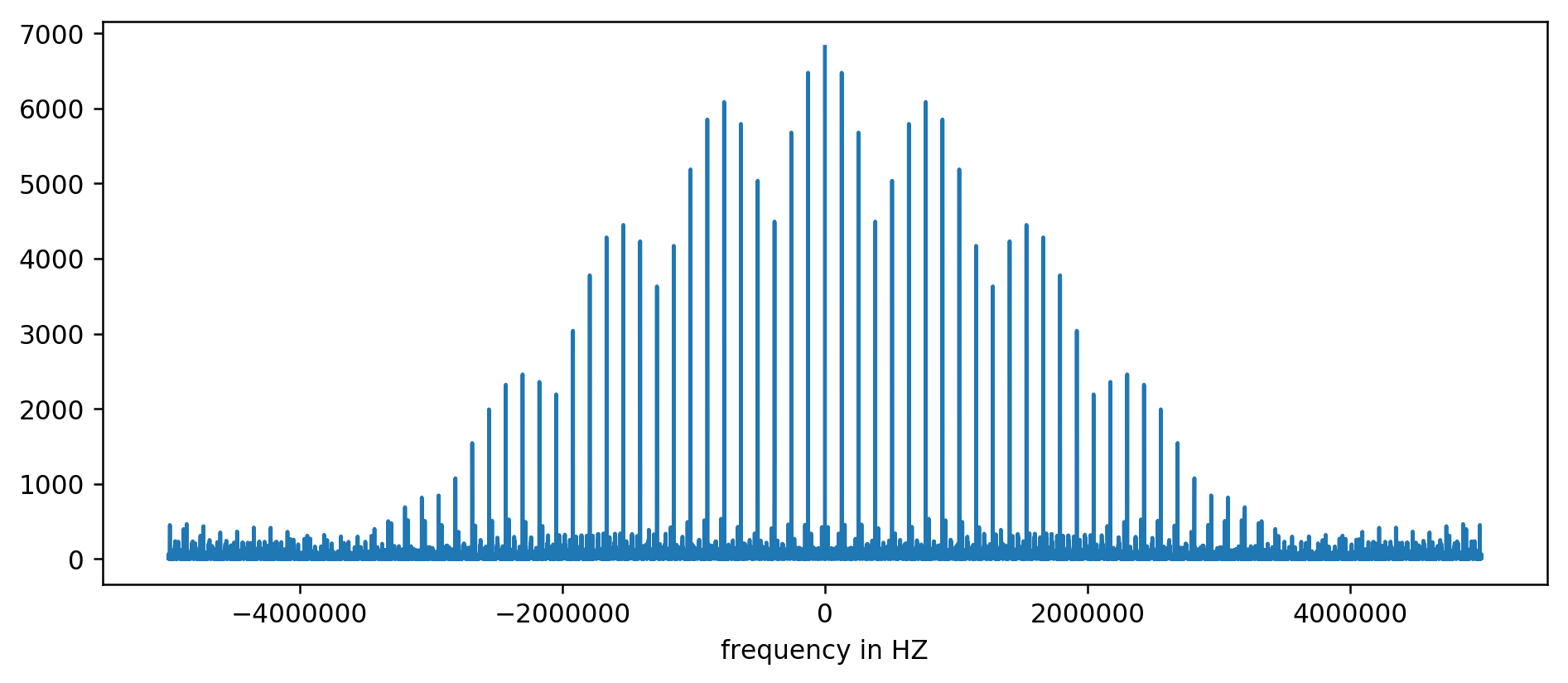
Axe Y sans unités, car nous avons normalisé le temps de retard. Malgré cela, les salves sont clairement visibles dans certaines gammes de fréquences fixes. Examinons-les de plus près:
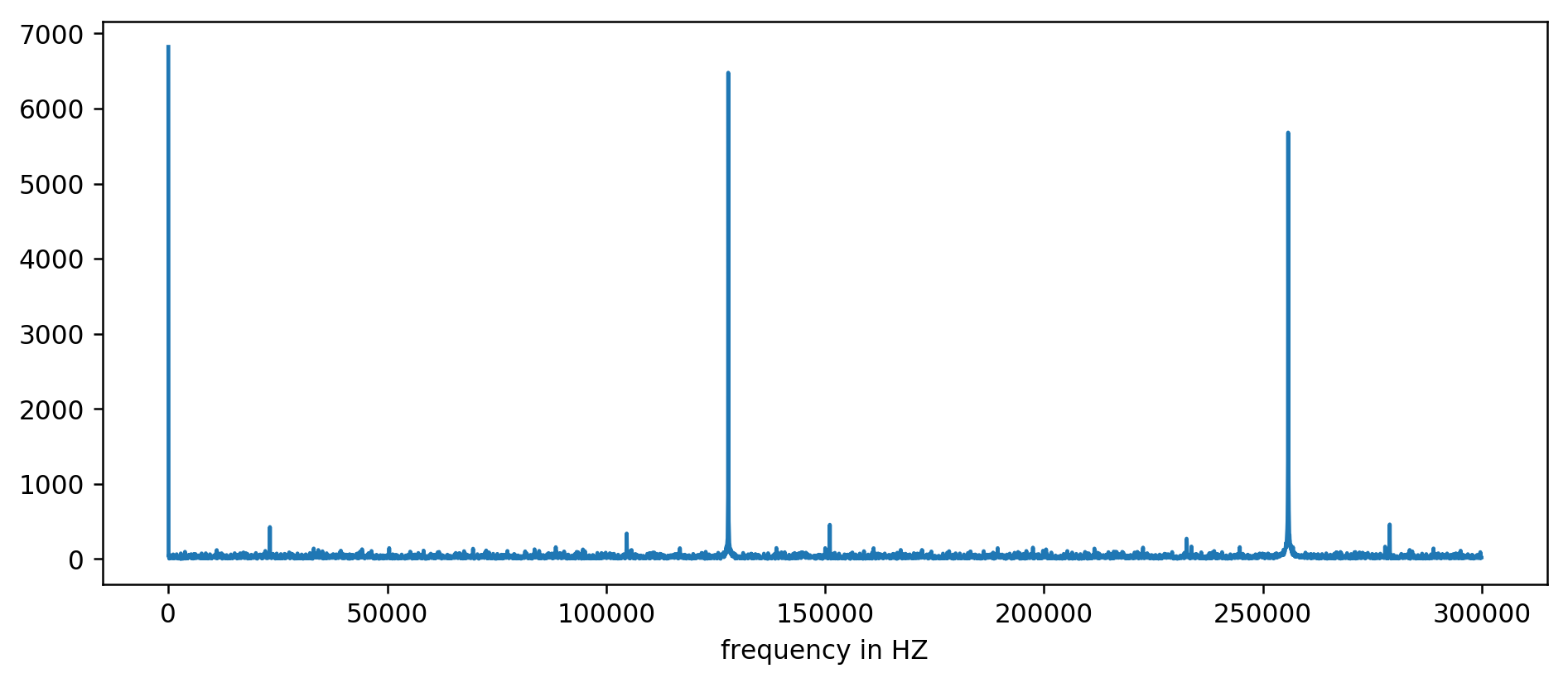
Nous voyons clairement les trois premiers pics. Après un peu d'arithmétique inexpressive, incluant un filtrage de lecture au moins dix fois la moyenne, vous pouvez extraire les fréquences de base:
127850.0
127900.0
127950.0
255700.0
255750.0
255800.0
255850.0
255900.0
255950.0
383600.0
383650.0
On considère: 1000000000 (ns / s) / 127900 (Hz) = 7818,6 ns
Hourra! Le premier saut de fréquence est vraiment ce que nous recherchions, et il est vraiment en corrélation avec le temps de mise à jour.
Les pics restants à 256 kHz, 384 kHz, 512 kHz sont les soi-disant harmoniques qui sont des multiples de notre fréquence de base de 128 kHz. C'est l'effet secondaire pleinement attendu de l'
application de la FFT à quelque chose comme une onde carrée .
Pour faciliter les expériences, nous avons fait une
version pour la ligne de commande . Vous pouvez exécuter le code vous-même. Voici un exemple de lancement sur mon serveur:
~ / 2018-11-memory-refresh $ make
gcc -msse4.1 -ggdb -O3 -Mur -Wextra mesure-dram.c -o mesure-dram
./measure-dram | python3 ./analyze-dram.py
[*] Vérification de l'ASLR: main = 0x555555554890 stack = 0x7fffffefe2ec
[] Fait amusant. J'ai fait 40663553 clock_gettime () par seconde
[*] Mesure du temps MOVQ + CLFLUSH. Exécution d'itérations 131072.
[*] Écriture des données
[*] Données d'entrée: min = 117 moyenne = 176 moyenne = 167 max = 8172 éléments = 131072
[*] Plage de coupure 212-inf
[] 127849 éléments en dessous du seuil, 0 éléments au-dessus du seuil, 3223 éléments non nuls
[*] Exécution de FFT
[*] La fréquence maximale au-dessus de 2 kHz en dessous de 250 kHz a une magnitude de 7716
[+] Les pics de fréquence supérieurs à 2 kHz sont à:
127906Hz 7716
255813Hz 7947
383720Hz 7460
511626Hz 7141
Je dois admettre que le code n'est pas complètement stable. En cas de problème, il est recommandé de désactiver Turbo Boost, la mise à l'échelle de la fréquence du processeur et l'optimisation pour les performances.
Conclusion
Il y a deux conclusions principales de ce travail.
Nous avons vu que les données de bas niveau sont assez difficiles à analyser et qu'elles semblent plutôt bruyantes. Au lieu d'évaluer à l'œil nu, vous pouvez toujours utiliser la bonne vieille FFT. Dans la préparation des données, il est nécessaire, en un sens, de faire des voeux pieux.
Plus important encore, nous avons montré qu'il est souvent possible de mesurer le comportement matériel subtil à partir d'un processus simple dans l'espace utilisateur. Ce type de réflexion a conduit à la découverte de la
vulnérabilité originale de Rowhammer , elle a été implémentée dans les attaques Meltdown / Spectre et a de nouveau été montrée dans la récente
réincarnation de Rowhammer pour la mémoire ECC .
Beaucoup reste au-delà de la portée de cet article. Nous avons à peine abordé le fonctionnement interne du sous-système mémoire. Pour plus de lecture, je recommande:
Enfin, voici une bonne description de l'ancienne mémoire ferrite: