Avertissement: cet article décrit une solution non évidente à un problème non évident. Avant de se précipiter oeufs mettre en pratique, je recommande de lire l'article à la fin et d'y réfléchir à deux fois.

Bonjour à tous! Lorsque vous travaillez avec du code, nous devons souvent faire face à l' état . Un tel cas est le cycle de vie des objets. La gestion d'un objet avec plusieurs états possibles peut être une tâche très simple. Ajoutez ici une exécution asynchrone et la tâche est compliquée par un ordre de grandeur. Il existe une solution efficace et naturelle. Dans cet article, je vais parler de la machine d'événements et de la façon de l'implémenter dans Go.
Pourquoi gérer l'État?
Pour commencer, définissons le concept lui-même. L'exemple le plus simple d'un état: fichiers et diverses connexions. Vous ne pouvez pas simplement prendre et lire un fichier. Il doit d'abord être ouvert, et à la fin de préférence assurez-vous de fermer. Il s'avère que l'action en cours dépend du résultat de l'action précédente: la lecture dépend de l'ouverture. Le résultat enregistré est l'état.
Le principal problème avec l'État est la complexité. Tout état complique automatiquement le code. Vous devez stocker les résultats des actions en mémoire et ajouter diverses vérifications à la logique. C'est pourquoi les architectures sans état sont si attrayantes pour les programmeurs - personne ne veut des ennuis difficultés. Si les résultats de vos actions n'affectent pas la logique d'exécution, vous n'avez pas besoin d'un état.
Cependant, il existe une propriété qui vous fait tenir compte des difficultés. Un état vous oblige à suivre un ordre spécifique d'actions. En général, de telles situations doivent être évitées, mais ce n'est pas toujours possible. Un exemple est le cycle de vie des objets de programme. Grâce à une bonne gestion des états, on peut obtenir un comportement prévisible des objets avec un cycle de vie complexe.
Voyons maintenant comment le faire cool .
Automatique pour résoudre les problèmes

Lorsque les gens parlent d'états, les machines à états finis viennent immédiatement à l'esprit. C’est logique, car un automate est le moyen le plus naturel de gérer un état.
Je ne m'attarderai pas sur la théorie des automates , il y a plus qu'assez d'informations sur Internet.
Si vous cherchez des exemples de machines à états finis pour Go, vous rencontrerez certainement un lexer de Rob Pike . Un excellent exemple d'automate dans lequel les données traitées sont l'alphabet d'entrée. Cela signifie que les transitions d'état sont provoquées par le texte que le lexeur traite. Solution élégante à un problème spécifique.
La principale chose à comprendre est qu'un automate est une solution à un problème strictement spécifique. Par conséquent, avant de le considérer comme un remède à tous les problèmes, vous devez bien comprendre la tâche. Plus précisément, l'entité que vous souhaitez contrôler:
- états - cycle de vie;
- événements - ce qui provoque exactement la transition vers chaque état;
- résultat du travail - données de sortie;
- mode d'exécution (synchrone / asynchrone);
- principaux cas d'utilisation.
Le lexer est beau, mais il ne change d'état qu'en raison des données qu'il traite lui-même. Mais qu'en est-il de la situation où l'utilisateur invoque des transitions? C'est là que la machine événementielle peut vous aider.
Exemple réel
Pour plus de clarté, j'analyserai un exemple de la bibliothèque phono .
Pour une immersion complète dans le contexte, vous pouvez lire l' article d'introduction . Ce n'est pas nécessaire pour ce sujet, mais cela aidera à mieux comprendre ce que nous gérons.
Et que gérons-nous?
phono est basé sur le pipeline DSP. Il se compose de trois étapes de traitement. Chaque étape peut comprendre un à plusieurs composants:
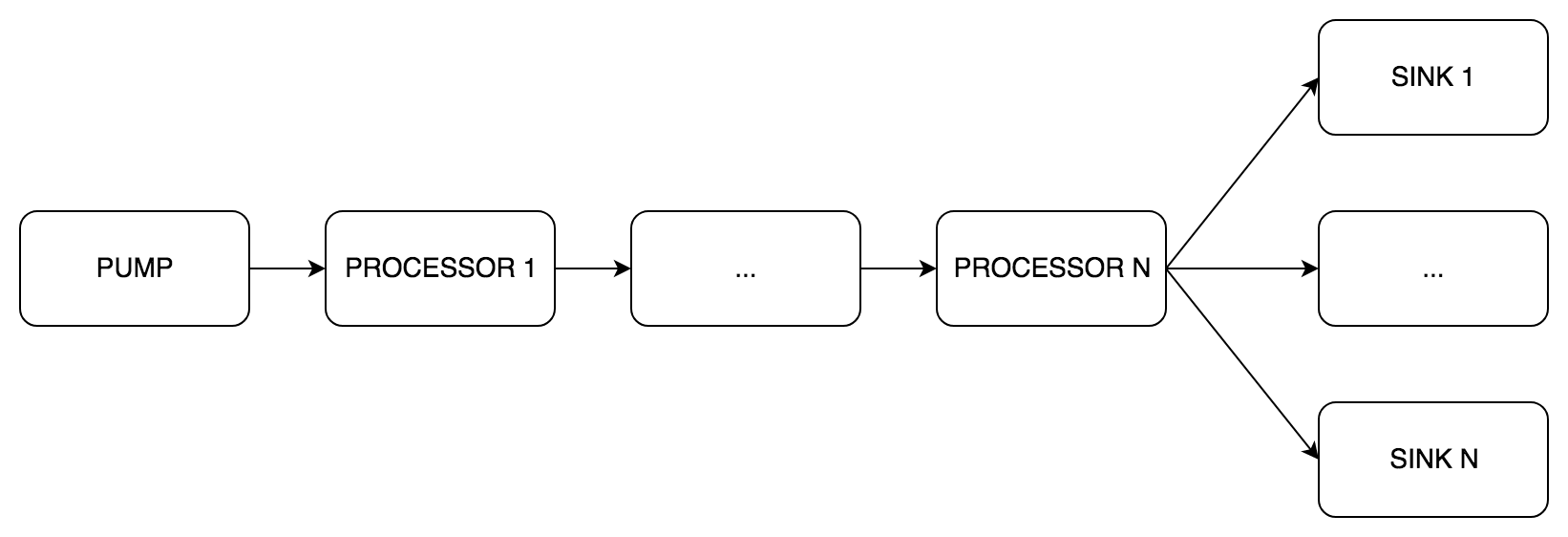
pipe.Pump (pompe anglaise) est une étape obligatoire de réception du son, toujours un seul composant.pipe.Processor (gestionnaire anglais) - une étape facultative de traitement du son, de 0 à N composants.pipe.Sink (English sink) - une étape obligatoire de transmission du son, de 1 à N composants.
En fait, nous gérerons le cycle de vie du convoyeur.
Cycle de vie
Voici à quoi ressemble le diagramme d'état du pipe.Pipe .
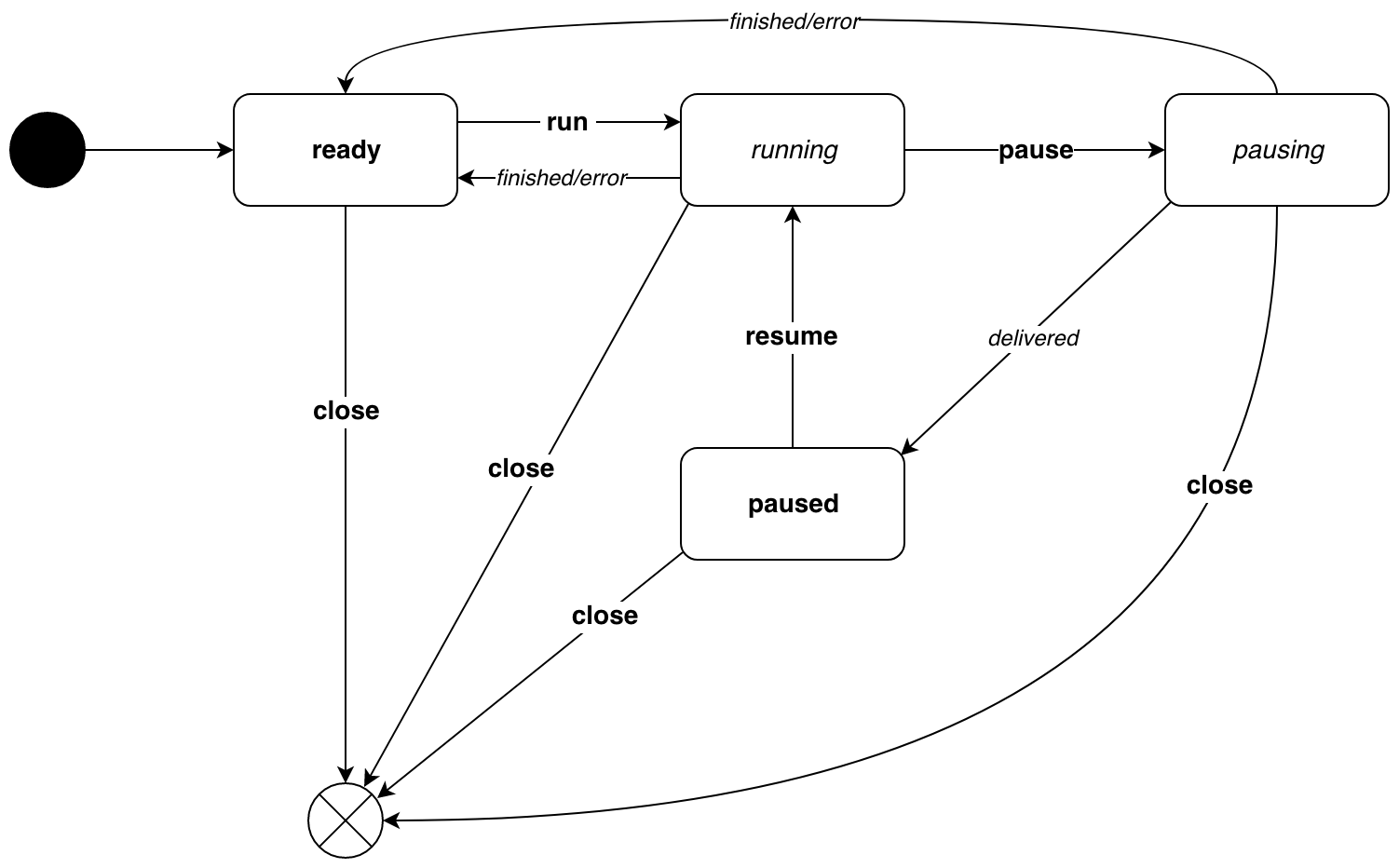
Les italiques indiquent les transitions causées par la logique d'exécution interne. Gras - transitions causées par les événements. Le diagramme montre que les états sont divisés en 2 types:
- états de repos -
ready et en paused , vous ne pouvez les sauter que par événement - états actifs - en
running et en pausing , transitions par événement et en raison de la logique d'exécution
Avant une analyse détaillée du code, un exemple clair de l'utilisation de tous les états:
Maintenant, tout d'abord.
Tout le code source est disponible dans le référentiel .
États et événements
Commençons par la chose la plus importante.
Grâce à des types distincts, les transitions sont également déclarées séparément pour chaque état. Cela évite l'énorme saucisses fonctions de transition avec des switch imbriquées. Les états eux-mêmes ne contiennent aucune donnée ni logique. Pour eux, vous pouvez déclarer des variables au niveau du package afin de ne pas le faire à chaque fois. L'interface d' state est nécessaire pour le polymorphisme. activeState parlerons d' activeState et idleState peu plus tard.
Les événements sont la deuxième partie la plus importante de notre machine.
Pour comprendre pourquoi le type target est nécessaire, considérons un exemple simple. Nous avons créé un nouveau convoyeur, il est ready . Maintenant, exécutez-le avec p.Run() . L'événement d' run est envoyé à la machine, le pipeline passe à l'état d' running . Comment savoir quand le convoyeur est terminé? C'est là que le type target nous aidera. Il indique à quel état de repos s'attendre après l'événement. Dans notre exemple, une fois le travail terminé, le pipeline passera à nouveau à l'état ready . La même chose dans le diagramme:
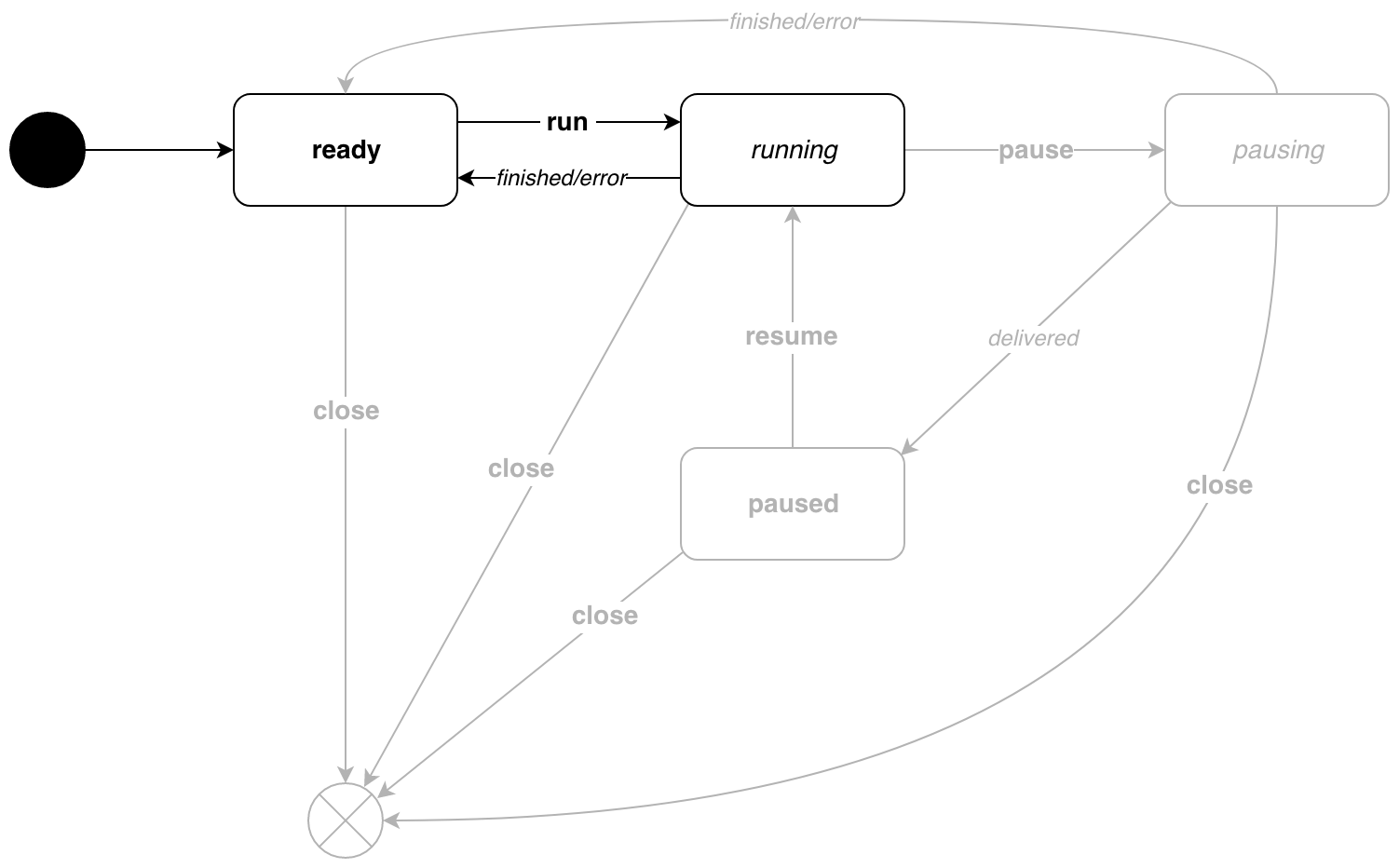
Maintenant, plus sur les types d'états. Plus précisément, sur les activeState idleState et activeState . Regardons les fonctions d' listen(*Pipe, target) (state, target) pour différents types d'étapes:
pipe.Pipe a différentes fonctions pour attendre une transition! Qu'y a-t-il?
Ainsi, nous pouvons écouter différentes chaînes dans différents états. Par exemple, cela vous permet de ne pas envoyer de messages pendant une pause - nous n'écoutons tout simplement pas le canal correspondant.
Constructeur et démarrage de la machine
En plus de l'initialisation et des options fonctionnelles , il y a le début d'une goroutine séparée avec le cycle principal. Eh bien, regardez-le:
Le convoyeur est créé et figé en prévision des événements.
Le temps de travailler
Appelez p.Run() !
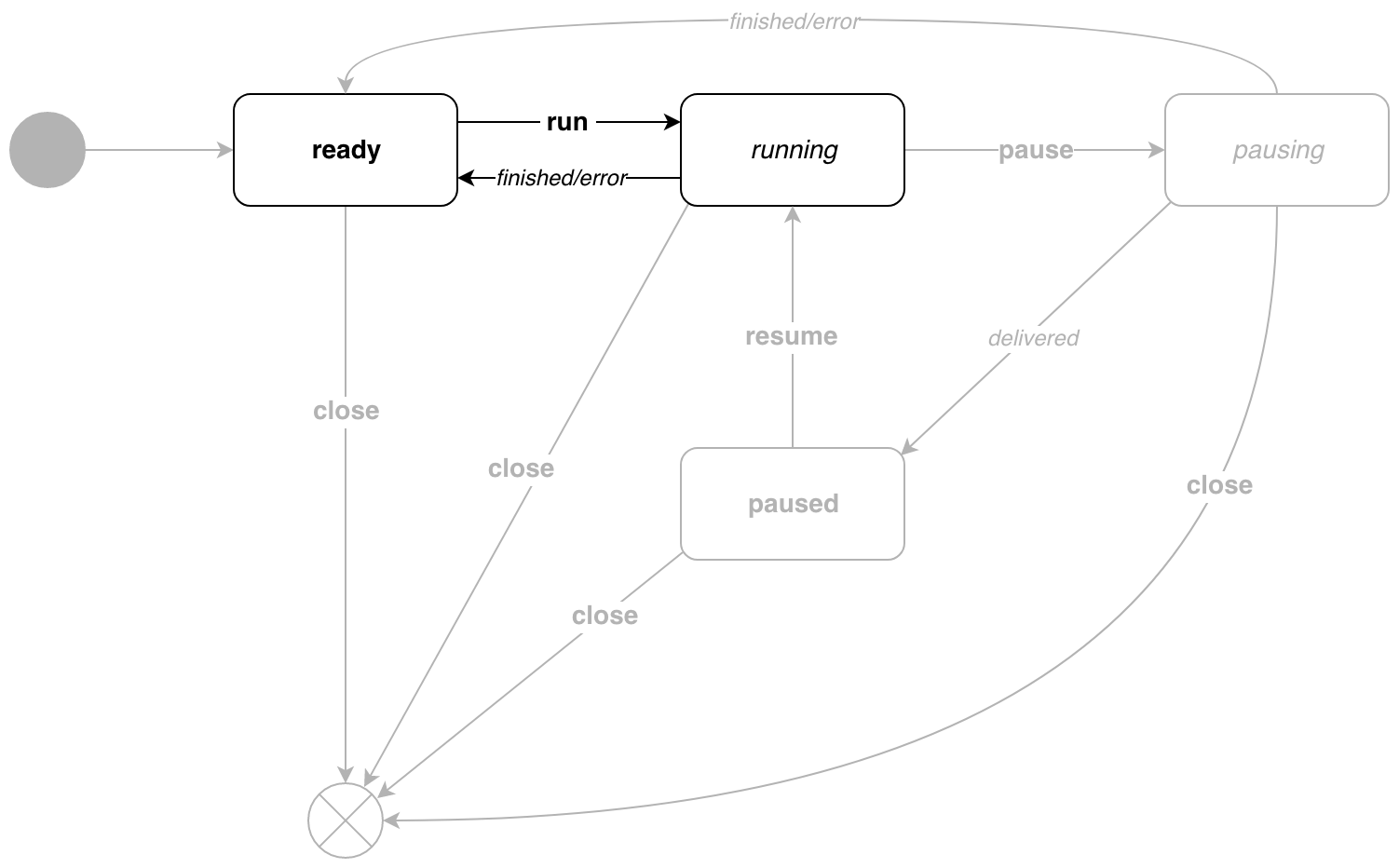
running génère des messages et s'exécute jusqu'à la fin du pipeline.
Pause
Pendant l'exécution du convoyeur, nous pouvons le mettre en pause. Dans cet état, le pipeline ne générera pas de nouveaux messages. Pour ce faire, appelez la méthode p.Pause() .
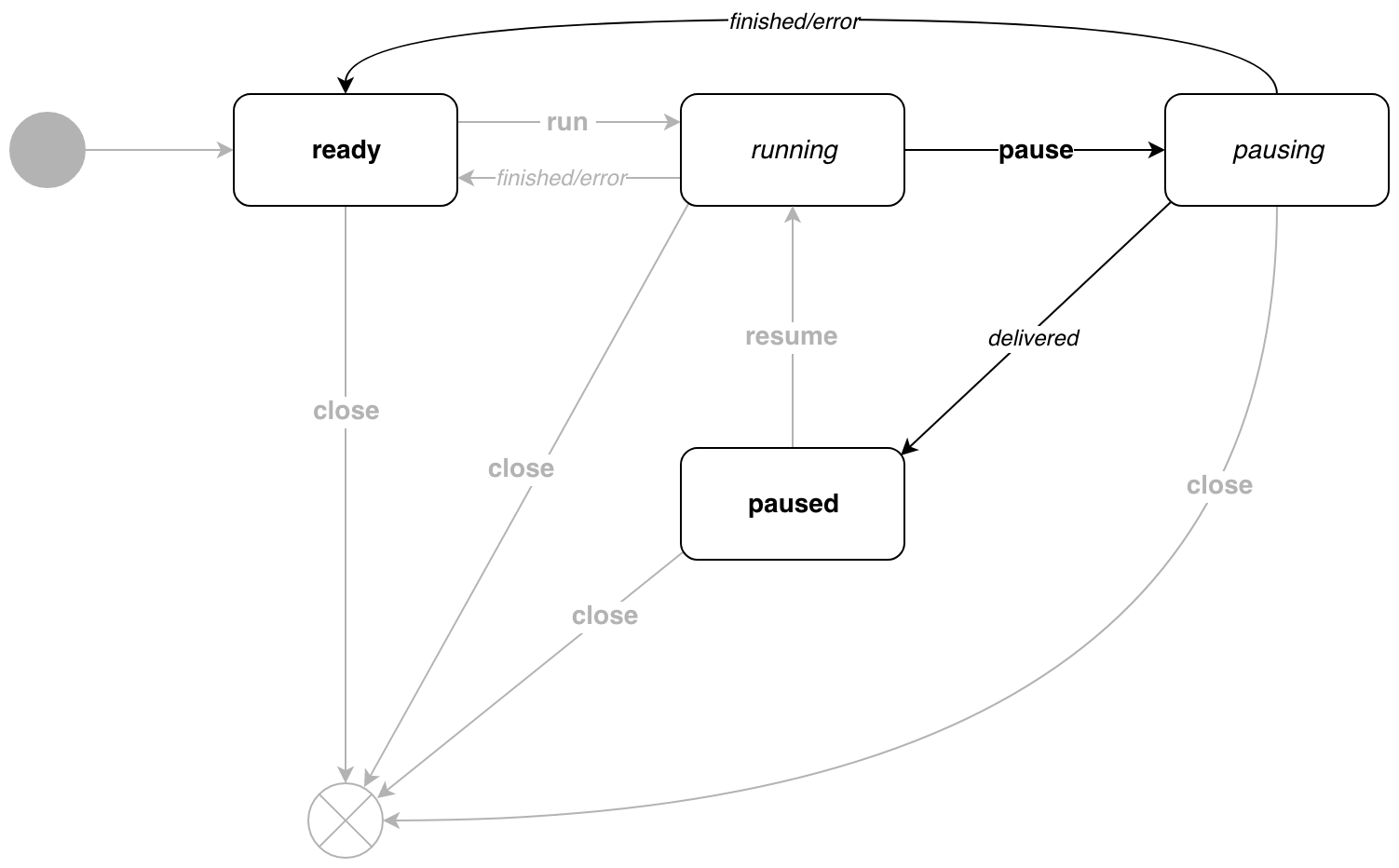
Dès que tous les destinataires reçoivent le message, le pipeline passe à paused état paused . Si le message est le dernier, la transition vers l'état ready se produit.
De retour au travail!
Pour quitter l'état paused , appelez p.Resume() .
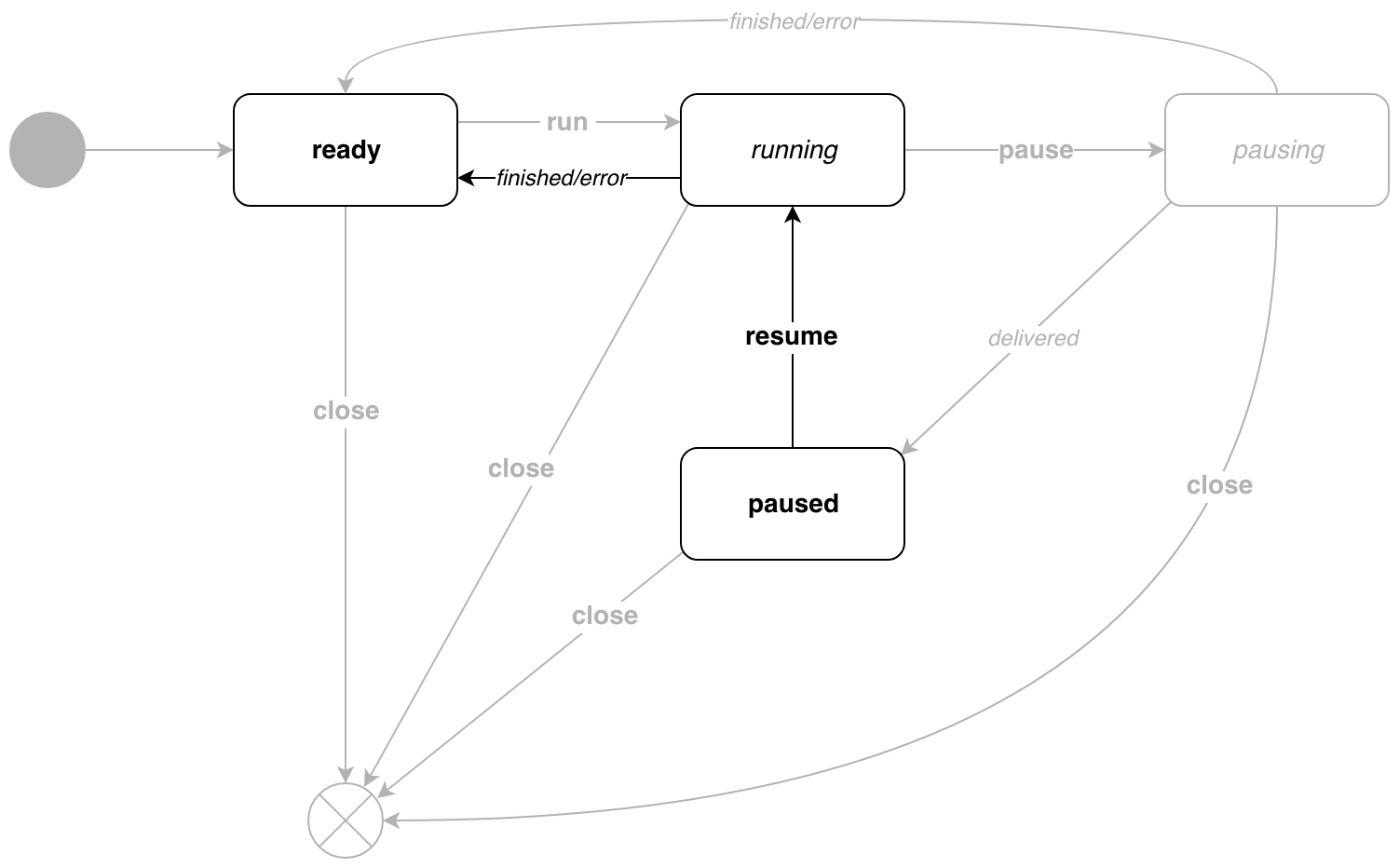
Tout est trivial ici, le pipeline passe à nouveau en état de running .
Détendez-vous
Le convoyeur peut être arrêté depuis n'importe quel état. Il y a p.Close() .
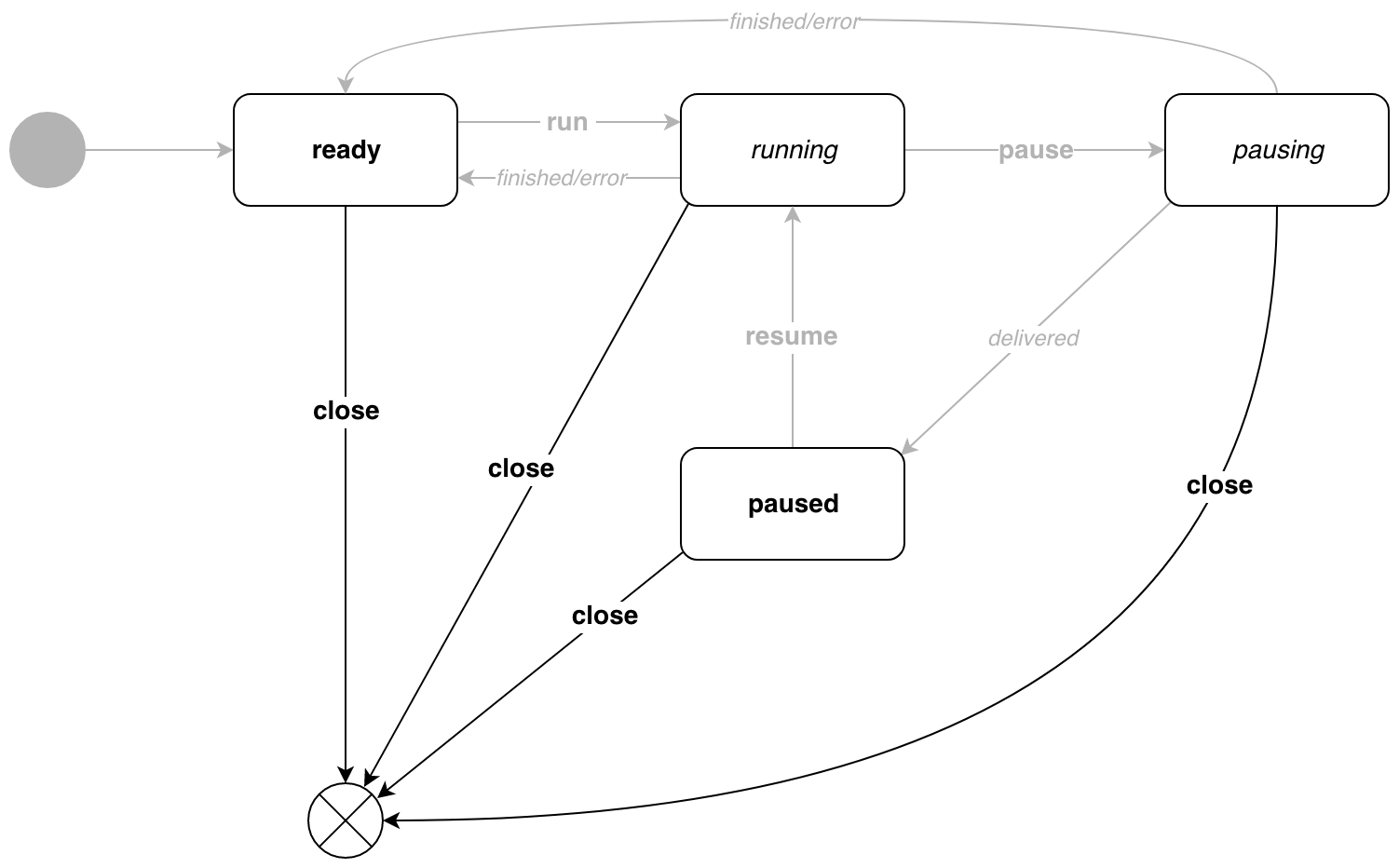
Qui en a besoin?
Pas pour tout le monde. Pour comprendre exactement comment gérer l'état, vous devez comprendre votre tâche. Il existe exactement deux circonstances dans lesquelles vous pouvez utiliser une machine asynchrone basée sur des événements:
- Cycle de vie complexe - il y a trois états ou plus avec des transitions non linéaires.
- L'exécution asynchrone est utilisée.
Bien que la machine événementielle résout le problème, c'est un modèle assez compliqué. Par conséquent, il doit être utilisé avec grand soin et uniquement après une compréhension complète de tous les avantages et inconvénients.
Les références