
Récemment, un client nous a demandé de mettre en place un système de comptabilité de capacité de disque. La tâche consistait à combiner les informations de plus de soixante-dix baies de disques de différents fournisseurs, des commutateurs SAN et des hôtes VMware ESX. Ensuite, les données devaient être systématisées, analysées et pouvoir être affichées sur un tableau de bord et divers rapports, par exemple sur le volume d'espace disque libre et occupé dans toutes les baies ou prises séparément.
Nous avons décidé de mettre en œuvre le projet en utilisant le système d'analyse opérationnelle - Splunk.
Pourquoi splunk?
Splunk est puissant pour visualiser les données qu'il recueille. Il vous permet de créer des rapports interactifs - tableaux de bord - mis à jour en temps réel. Nous avons affiché des informations sur l'espace disque total sur eux, affiché immédiatement toutes les baies avec la possibilité de trier par différents filtres, par exemple, par capacité. En cliquant sur le tableau, nous obtenons immédiatement des informations sur toutes les connexions. Dans un panneau séparé, vous pouvez entrer le nom de la machine virtuelle et voir sur quel hôte ESX elle vit, à partir de quelles baies elle reçoit des données et d'autres paramètres.
À mon avis, Splunk n'a jusqu'à présent aucun analogue qui fonctionnerait avec n'importe quel système de stockage prêt à l'emploi. Il y a quelques années, le CommandCentral payant est apparu, mais il n'a pas la flexibilité nécessaire, il ne sait pas comment générer des rapports arbitraires (dans les premières versions des rapports il n'y en avait pas du tout) et avec une visualisation boiteuse. En général, il ne s'agit pas d'un outil d'inventaire, mais de suivi et de contrôle de l'état des systèmes. Pour accomplir la tâche fixée par le client, il faudrait la raffiner longtemps et cher.
Dans le même temps, Splunk possède des capacités impressionnantes d'affichage des informations: les graphiques peuvent être librement disposés entre eux, surveiller l'état de tous les systèmes dans un mode de fenêtre unique et, ainsi, simplifier leur maintenance. Pour tout le reste - pour notre tâche, nous avons utilisé la version gratuite.

Qu'avez-vous fait?
Jusqu'à présent, notre équipe n'avait aucune expérience avec Splunk. Heureusement, le système s'est avéré convivial et intuitif, et des solutions aux problèmes émergents ont été facilement trouvées en utilisant une aide régulière ou dans un moteur de recherche.
Splunk a construit un certain nombre d'outils dont nous avons besoin. Par exemple, le système vous permet de combiner des données provenant de différentes sources pour n'importe quel champ via les soi-disant Lookups (répertoires). Ainsi, dans un tableau, les hôtes ESX étaient affichés en IP, dans un autre - en tant que noms DNS. Au début, nous voulions créer une recherche maison et utiliser l'utilitaire nslookup pour sélectionner les enregistrements DNS et collecter les tables, mais il s'est avéré que Splunk avait un répertoire qui compare DNS sur IP et vice versa. Cette recherche intégrée n'a pas besoin d'être configurée, elle extrait elle-même les données sur les serveurs DNS à partir des paramètres système, peu importe si c'est Windows ou Linux, et les données sur les enregistrements DNS sont toujours à jour.

L'un des scénarios intéressants mis en œuvre avec Splunk est le contrôle des modifications (RFC) dans le système. Par exemple, un gestionnaire RFC reçoit une demande d'un ingénieur pour entretenir l'un des commutateurs SAN. Il entre le nom du commutateur dans Splunk et voit quels stockages lui sont connectés et quels serveurs reçoivent des données de ces stockages. Dans le même temps, le gestionnaire voit le plan de travail que l'ingénieur a écrit et peut évaluer comment la désactivation de ce commutateur pendant la maintenance affectera les performances des baies et des serveurs.
Nous configurons le chargement quotidien d'informations sur la connexion de tous les commutateurs et baies à Splunk. Le client est satisfait de ce taux de mise à jour. Il avait déjà un outil de surveillance Stor2RRD, mais il ne sait pas comment combiner les données de différentes sources et les visualiser. Par conséquent, nous avons configuré le système d'acquisition de données dans Splunk comme suit:
- Nous recevons des informations sur les stockages de Stor2RRD;
- Des commutateurs, nous recevons des informations sur le SAN;
- Grâce à vCenter à l'aide de scripts PowerCLI, nous collectons des données à partir des hôtes ESX.
Les données reçues sont automatiquement regroupées dans un seul formulaire, traitées et affichées sous forme de rapports nécessaires.
Avec quoi avez-vous dû vous battre?
Splunk est un système puissant, mais il y a des tâches qui ne peuvent pas être résolues hors de la boîte, et pour résoudre certains problèmes, nous avons besoin d'une connaissance approfondie de VMware.
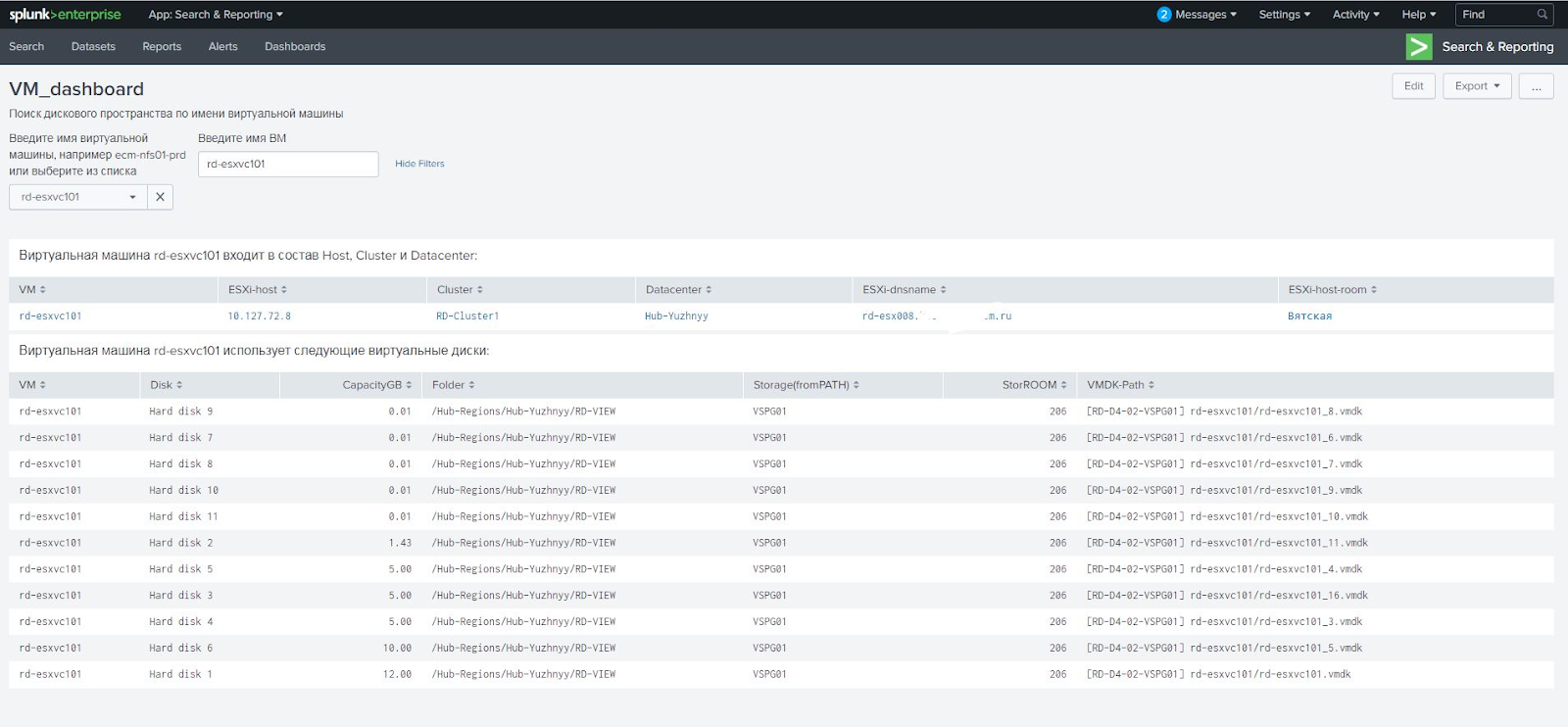
Par exemple, un client utilise à la fois des disques RDM alloués directement et des banques de données virtuelles virtuelles pour les machines virtuelles. Ces deux types de disques doivent être traités différemment. Au début, nous avons résolu le problème par nous-mêmes, mais nous avons ensuite dû faire face à une situation où la machine virtuelle recevait à la fois des disques RAW et des disques virtuels. Il s'est avéré que nous obtenions le mauvais champ Path dans le rapport de vCenter et le mauvais lien vers la baie de disques RAW. Le schéma fonctionne avec les banques de données ordinaires, mais ne fonctionne pas avec les disques RAW. Pour eux, vous devez utiliser la propriété de disque RAW Disk ID, qui contient l'attribut disk. J'ai dû me tourner vers des experts VMware qui ont refait le script pour qu'il calcule la matrice correcte via l'ID de disque RAW.
De plus, nous n'avons pas immédiatement appris à travailler de manière optimale avec les scripts PowerCLI, plus tard les algorithmes ont dû être développés davantage. Initialement, les scripts ont traité les données de plusieurs milliers de machines virtuelles pendant trois heures! Après raffinement, la durée des scripts a été réduite à quarante minutes.
Quel est le résultat?
N'ayant aucune expérience avec Splunk, nous avons rapidement implémenté sur sa base un système de comptabilisation des capacités des disques, qui reçoit des informations de nombreuses sources, les consolide et fournit une large gamme de graphiques pratiques et intuitifs. Si vous n'avez jamais eu à choisir ou à créer un tel système auparavant, alors Splunk est un bon candidat pour ce rôle. Il fonctionne rapidement, est configuré de manière simple et flexible et ne nécessite aucune connaissance spécialisée pour résoudre la grande majorité des tâches.
Vladislav Semenov, chef du groupe Architecture du système, Centre de conception de complexes informatiques, Jet Infosystems