 datacenterknowledge.com
datacenterknowledge.comL'année dernière, la plus grande installation de stockage basée sur RAIDIX du moment a été mise en œuvre. Un système de 11 clusters de basculement a été déployé à l'Institut RIKEN des sciences informatiques (Japon). Le principal objectif du système est le stockage de l'infrastructure HPC (HPCI), qui est mis en œuvre dans le cadre de l'échange académique à grande échelle d'informations académiques Academic Cloud (basé sur le réseau SINET).
Une caractéristique importante de ce projet est son volume total de 65 PB, dont le volume utilisable du système est de 51,4 PB. Pour mieux comprendre cette valeur, nous ajoutons qu'il s'agit de 6512 disques de 10 To chacun (les plus modernes au moment de l'installation). C’est beaucoup.
Les travaux sur le projet se sont poursuivis tout au long de l'année, après quoi le suivi de la stabilité du système s'est poursuivi pendant environ un an. Les indicateurs obtenus répondaient aux exigences énoncées, et maintenant nous pouvons parler du succès de ce record et du projet significatif pour nous.
Supercalculateur au RIKEN Institute Computing Center
Pour l'industrie des TIC, le RIKEN Institute est principalement connu pour son légendaire «K-computer» (du japonais «kei», qui signifie 10 quadrillions), qui, au moment de son lancement (juin 2011) était considéré comme le supercalculateur le plus puissant au monde.
En savoir plus sur l'ordinateur K Le supercalculateur aide le Center for Computational Sciences dans la mise en œuvre de recherches complexes à grande échelle: il permet de modéliser le climat, les conditions météorologiques et le comportement moléculaire, de calculer et d'analyser les réactions en physique nucléaire, la prévision des séismes, et bien plus encore. Les capacités de superordinateurs sont également utilisées pour des recherches plus «quotidiennes» et appliquées - pour rechercher des gisements de pétrole et prévoir les tendances des marchés boursiers.
De tels calculs et expériences génèrent une énorme quantité de données, dont la valeur et la signification ne peuvent être surestimées. Pour en tirer le meilleur parti, les scientifiques japonais ont développé le concept d'un espace d'information unique dans lequel les professionnels du HPC de différents centres de recherche auront accès aux ressources HPC reçues.
Infrastructure de calcul haute performance (HPCI)
HPCI fonctionne sur la base de SINET (The Science Information Network), un réseau de base pour l'échange de données scientifiques entre les universités japonaises et les centres de recherche. Actuellement, SINET rassemble environ 850 instituts et universités, créant d'énormes opportunités d'échange d'informations dans la recherche qui affecte la physique nucléaire, l'astronomie, la géodésie, la sismologie et l'informatique.
HPCI est un projet d'infrastructure unique qui forme un système d'échange d'informations unifié dans le domaine du calcul haute performance entre les universités et les centres de recherche au Japon.
En combinant les capacités du supercalculateur «K» et d'autres centres de recherche sous une forme accessible, la communauté scientifique reçoit des avantages évidents pour travailler avec des données précieuses créées par le calcul supercalculateur.
Afin de fournir un accès utilisateur conjoint efficace à l'environnement HPCI, des exigences élevées ont été imposées au stockage pour la vitesse d'accès. Et grâce à «l'hyperproductivité» du K-computer, le cluster de stockage du Center for Computational Sciences de l'Institut RIKEN a été calculé pour être créé avec un volume de travail d'au moins 50 PB.
L'infrastructure du projet HPCI a été construite sur la base du système de fichiers Gfarm, qui a permis de fournir un haut niveau de performances et de combiner des clusters de stockage disparates en un seul espace de partage.
Système de fichiers Gfarm
Gfarm est un système de fichiers distribués open source développé par des ingénieurs japonais. Gfarm est le fruit du développement de l'Institute for Advanced Industrial Science and Technology (AIST), et le nom du système fait référence à l'architecture utilisée par Grid Data Farm.
Ce système de fichiers combine un certain nombre de propriétés apparemment incompatibles:
- Haute évolutivité en volume et en performances
- Distribution de réseau longue distance avec prise en charge d'un espace de noms unique pour plusieurs centres de recherche divers
- Prise en charge de l'API POSIX
- Haute performance requise pour le calcul parallèle
- Sécurité du stockage des données
Gfarm crée un système de fichiers virtuel en utilisant les ressources de stockage de plusieurs serveurs. Les données sont distribuées par le serveur de métadonnées et le schéma de distribution lui-même est caché aux utilisateurs. Je dois dire que Gfarm se compose non seulement d'un cluster de stockage, mais également d'une grille de calcul qui utilise les ressources des mêmes serveurs. Le principe de fonctionnement du système ressemble à Hadoop: le travail soumis est «abaissé» au nœud où se trouvent les données.
L'architecture du système de fichiers est asymétrique. Les rôles sont clairement attribués: serveur de stockage, serveur de métadonnées, client. Mais en même temps, les trois rôles peuvent être exécutés par la même machine. Les serveurs de stockage stockent de nombreuses copies de fichiers et les serveurs de métadonnées fonctionnent en mode maître-esclave.
Travail de projet
Core Micro Systems, partenaire stratégique et fournisseur exclusif de RAIDIX au Japon, a implémenté la mise en œuvre au RIKEN Institute of Computing Sciences Center. Pour mettre en œuvre le projet, il a fallu environ 12 mois de travail minutieux, auxquels non seulement les employés de Core Micro Systems, mais aussi les spécialistes techniques de l'équipe Reydix ont pris une part active.
Dans le même temps, la transition vers un autre système de stockage semblait peu probable: le système existant avait beaucoup de fixations techniques, ce qui a compliqué la transition vers une nouvelle marque.
Au cours de longs tests, de vérifications et d'améliorations, RAIDIX a démontré des performances et une efficacité constamment élevées lors de l'utilisation d'une quantité de données aussi impressionnante.
À propos des améliorations, il vaut la peine d'en dire un peu plus. Il fallait non seulement créer l'intégration des systèmes de stockage avec le système de fichiers Gfarm, mais aussi étendre certaines caractéristiques fonctionnelles du logiciel. Par exemple, afin de répondre aux exigences établies des spécifications techniques, il était nécessaire de développer et de mettre en œuvre la technologie de l'écriture automatique dès que possible.
Le déploiement du système lui-même a été systématique. Les ingénieurs de Core Micro Systems ont mené avec soin et précision chaque étape du test, augmentant progressivement l'échelle du système.
En août 2017, la première phase de déploiement s'est terminée lorsque le volume du système a atteint 18 PB. En octobre de la même année, la deuxième phase a été mise en œuvre, dans laquelle le volume a atteint un record de 51 PB.
Architecture de la solution
La solution a été créée grâce à l'intégration des systèmes de stockage RAIDIX et du système de fichiers distribué Gfarm. En collaboration avec Gfarm, la possibilité de créer un stockage évolutif à l'aide de 11 systèmes RAIDIX à double contrôleur.
La connexion aux serveurs Gfarm se fait via 8 x SAS 12G.
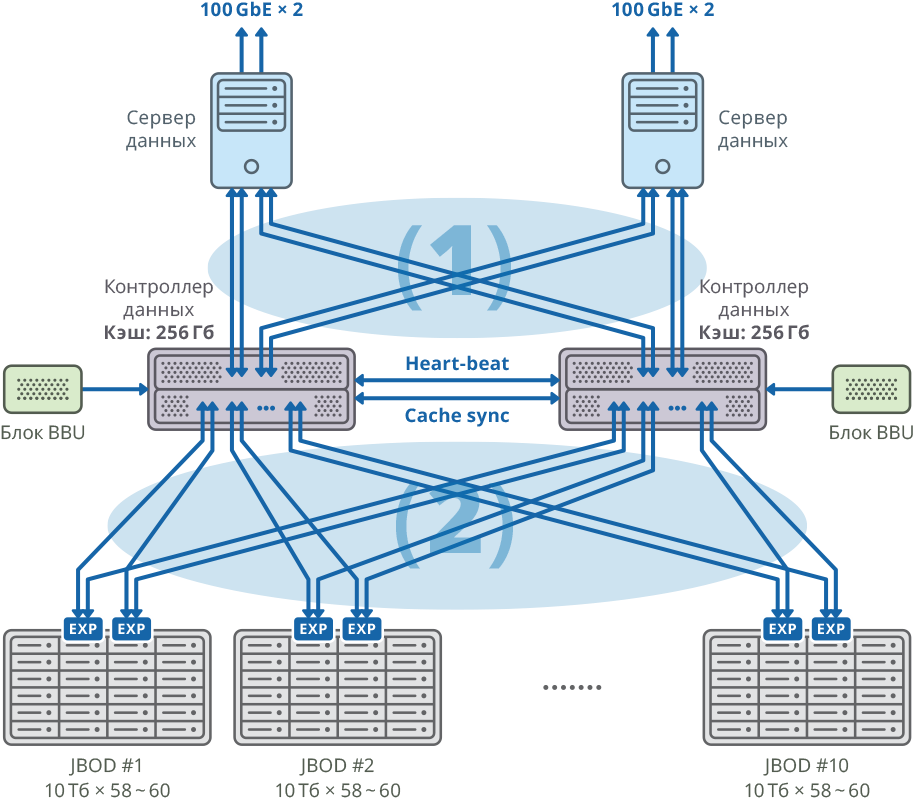 Fig. 1. Image d'un cluster avec un serveur de données distinct pour chaque nœud
Fig. 1. Image d'un cluster avec un serveur de données distinct pour chaque nœud(1) connexions maillées SAN 48 Gbit / s × 8; bande passante: 384 Gbps
(2) connexions 48Gbps × 40 Mesh FABRIC; bande passante: 1920 Gbps
Configuration de plate-forme à double contrôleur
| CPU | Intel Xeon E5-2637 - 4 pièces |
| Carte mère | Compatible avec le modèle de processeur prenant en charge PCI Express 3.0 x8 / x16 |
| Cache interne | 256 Go pour chaque nœud |
| Châssis | 2U |
| Contrôleurs SAS pour connecter les étagères de disques, les serveurs et la synchronisation du cache d'écriture | Broadcom 9305 16e, 9300 8e |
| Disque dur | Disque dur SAS HGST Helium 10 To |
| Synchronisation du rythme cardiaque | Ethernet 1 GbE |
| CacheSync Sync | 6 x SAS 12G |
Les deux nœuds du cluster de basculement sont connectés à 10 JBOD (60 disques de 10 To chacun) via 20 ports SAS 12G pour chaque nœud. Sur ces étagères de disques, 58 matrices RAID6 de 10 To ont été créées (8 disques de données (D) + 2 disques de parité (P)) et 12 disques ont été alloués pour le «remplacement à chaud».
10 JBOD => 58 × RAID6 (8 disques de données (D) + 2 disques de parité (P)), LUN à partir de 580 HDD + 12 HDD pour «hot swap» (2,06% du volume total)
592 HDD (10 To SAS / 7,2 k HDD) par cluster * HDD: HGST (MTBF: 2 500 000 heures)
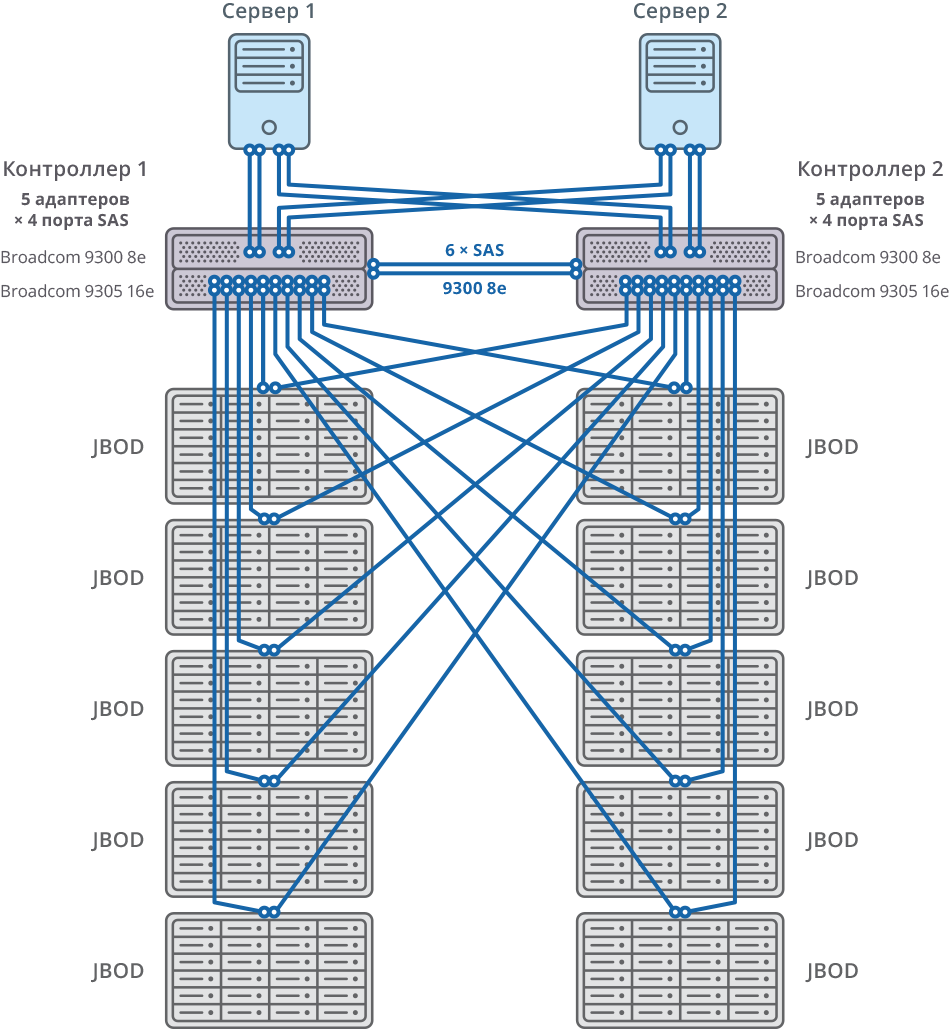 Fig. 2. Cluster de basculement avec schéma de connexion 10 JBOD
Fig. 2. Cluster de basculement avec schéma de connexion 10 JBODSystème général et schéma de connexion
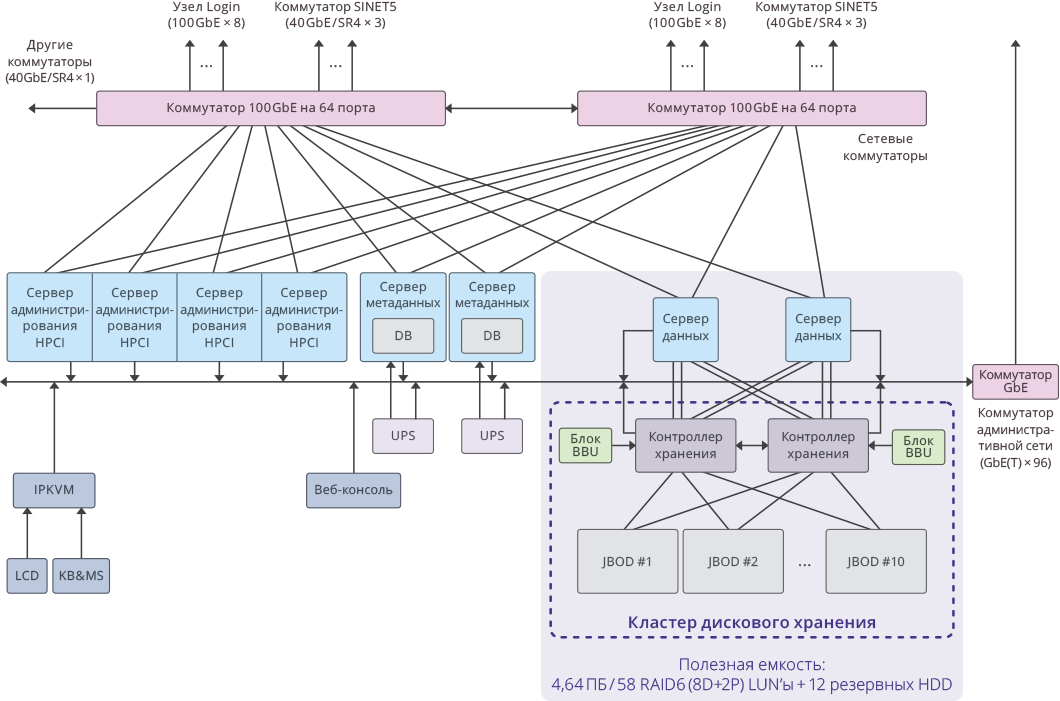 Fig. 3. Image d'un cluster unique dans le système HPCI
Fig. 3. Image d'un cluster unique dans le système HPCIIndicateurs clés du projet
Capacité utile par cluster: 4,64 PB ((RAID6 / 8D + 2P) LUN × 58)
La capacité totale utilisable de l'ensemble du système: 51,04 PB (4,64 PB × 11 grappes).
Capacité totale du système: 65 PB .
Les performances du système étaient: 17 Go / s en écriture, 22 Go / s en lecture.
La performance totale du sous-système de disques du cluster sur 11 systèmes de stockage RAIDIX: 250 Go / s .