



Cet article décrit les conversions les plus intéressantes qu'une chaîne de deux
transpilateurs effectue (le premier traduit le code Python en code dans le
nouveau langage de programmation 11l , et le second traduit le code en 11l en C ++), et compare également les performances avec d'autres outils d'accélération / Exécution de code Python (PyPy, Cython, Nuitka).
Remplacement des tranches \ tranches par des plages
L'indication explicite pour l'indexation à partir de la fin du tableau
s[(len)-2] au lieu de simplement
s[-2] nécessaire pour éliminer les erreurs suivantes:
- Lorsque, par exemple, il est nécessaire d'obtenir le caractère précédent par
s[i-1] , mais pour i = 0 tel / cet enregistrement au lieu d'une erreur retournera silencieusement le dernier caractère de la chaîne [ et en pratique j'ai rencontré une telle erreur - commit ] . - L'expression
s[i:] après i = s.find(":") ne fonctionnera pas correctement lorsque le caractère n'est pas trouvé dans la chaîne [ au lieu de '' une partie de la chaîne commençant par le premier caractère : puis '' le dernier caractère de la chaîne sera pris ] (et généralement , Je pense que retourner -1 avec la fonction find() en Python est également incorrect [ devrait retourner null / None [ et si -1 est requis, il devrait être écrit explicitement: i = s.find(":") ?? -1 ] ] ) - L'écriture de
s[-n:] pour obtenir les n derniers caractères d'une chaîne ne fonctionnera pas correctement lorsque n = 0.
Chaînes d'opérateurs de comparaison
À première vue, c'est une caractéristique exceptionnelle du langage Python, mais en pratique, il peut être facilement abandonné / distribué en utilisant l'opérateur
in et les plages:
Compréhension des listes
De même, comme il s'est avéré, vous pouvez refuser une autre fonctionnalité intéressante de Python: les listes de compréhension.
Alors que certains
glorifient la compréhension des listes et suggèrent même d'abandonner `filter ()` et `map ()` , j'ai trouvé que:
Dans tous les endroits où j'ai vu la compréhension de la liste de Python, vous pouvez facilement vous débrouiller avec les fonctions `filter ()` et `map ()`. dirs[:] = [d for d in dirs if d[0] != '.' and d != exclude_dir] dirs[:] = filter(lambda d: d[0] != '.' and d != exclude_dir, dirs) '[' + ', '.join(python_types_to_11l[ty] for ty in self.type_args) + ']' '[' + ', '.join(map(lambda ty: python_types_to_11l[ty], self.type_args)) + ']'
`filter ()` et `map ()` en 11l sont plus jolis qu'en Python dirs[:] = filter(lambda d: d[0] != '.' and d != exclude_dir, dirs) dirs = dirs.filter(d -> d[0] != '.' & d != @exclude_dir) '[' + ', '.join(map(lambda ty: python_types_to_11l[ty], self.type_args)) + ']' '['(.type_args.map(ty -> :python_types_to_11l[ty]).join(', '))']' outfile.write("\n".join(x[1] for x in fileslist if x[0])) outfile.write("\n".join(map(lambda x: x[1], filter(lambda x: x[0], fileslist)))) outfile.write(fileslist.filter(x -> x[0]).map(x -> x[1]).join("\n"))
et par conséquent, le besoin de compréhension de liste en 11l disparaît réellement [le remplacement de la compréhension de liste par filter() et / ou map() est effectué pendant la conversion du code Python en 11l automatiquement ] .
Convertir la chaîne if-elif-else en commutateur
Bien que Python ne contienne pas d'instruction switch, c'est l'une des plus belles constructions de 11l, et j'ai donc décidé d'insérer automatiquement switch:
Pour être complet, voici le code C ++ généré switch (instr[i]) { case u'[': nesting_level++; break; case u']': if (--nesting_level == 0) goto break_; break; case u''': ending_tags.append(u"'"_S); break; // '' case u''': assert(ending_tags.pop() == u'''); break; }
Convertir de petits dictionnaires en code natif
Considérez cette ligne de code Python:
tag = {'*':'b', '_':'u', '-':'s', '~':'i'}[prev_char()]
Très probablement, cette forme d'enregistrement n'est pas très efficace
[ en termes de performances ] , mais elle est très pratique.
En 11l, l'entrée correspondant à cette ligne
[ et obtenue par le transporteur Python → 11l ] est non seulement pratique
[ cependant, pas aussi élégante qu'en Python ] , mais aussi rapide:
var tag = switch prev_char() {'*' {'b'}; '_' {'u'}; '-' {'s'}; '~' {'i'}}
La ligne ci-dessus est traduite en:
auto tag = [&](const auto &a){return a == u'*' ? u'b'_C : a == u'_' ? u'u'_C : a == u'-' ? u's'_C : a == u'~' ? u'i'_C : throw KeyError(a);}(prev_char());
[ L'appel de fonction lambda sera compilé par le compilateur C ++ \ inline pendant le processus d'optimisation et seule la chaîne d'opérateurs restera ?/: ]Dans le cas où une variable est affectée, le dictionnaire est laissé tel quel:
Capture \ Ca pture variables externes
En Python, pour indiquer qu'une variable n'est pas locale, mais doit être prise en dehors de
[ de la fonction actuelle ] , le mot-clé non local est utilisé
[ sinon, par exemple, found = True sera traité comme créant une nouvelle variable locale found , plutôt que d'attribuer une valeur déjà variable externe existante ] .
En 11l, le préfixe @ est utilisé pour cela:
C ++:
auto writepos = 0; auto write_to_pos = [..., &outfile, &writepos](const auto &pos, const auto &npos) { outfile.write(...); writepos = npos; };
Variables globales
Semblable aux variables externes, si vous oubliez de déclarer une variable globale en Python
[en utilisant le mot-clé global ] , vous obtenez un bug invisible:
Le code 11l
[à droite ] , contrairement à Python
[à gauche ], break_label_index erreur "variable
break_label_index non
break_label_index " au
break_label_index compilation.
Index / numéro de l'élément de conteneur actuel
J'oublie toujours l'ordre des variables que la fonction
enumerate Python renvoie {la valeur vient en premier, puis l'index, ou vice versa}. Le comportement analogique dans Ruby -
each.with_index - est beaucoup plus facile à retenir: avec index signifie que l'index vient après la valeur, pas avant. Mais en 11l, la logique est encore plus facile à retenir:
Performances
Le
programme de conversion du balisage PC en HTML est utilisé comme
programme de test, et le code source de l'
article sur le balisage PC est utilisé comme données source
[ car cet article est actuellement le plus grand de ceux écrits sur le balisage PC ] , et est répété 10 fois, c'est-à-dire obtenu à partir d'une taille de fichier d'article de 48,8 kilo-octets de 488 Ko.
Voici un diagramme montrant combien de fois la manière correspondante d'exécuter du code Python est plus rapide que l'implémentation d'origine
[ CPython ] :
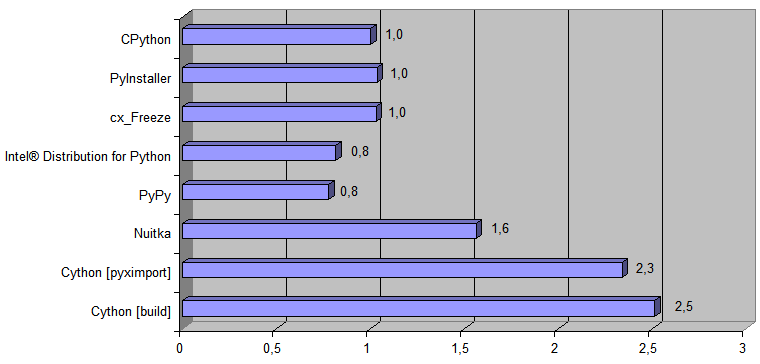
Et maintenant, ajoutez au diagramme l'implémentation générée par le transpilateur Python → 11l → C ++: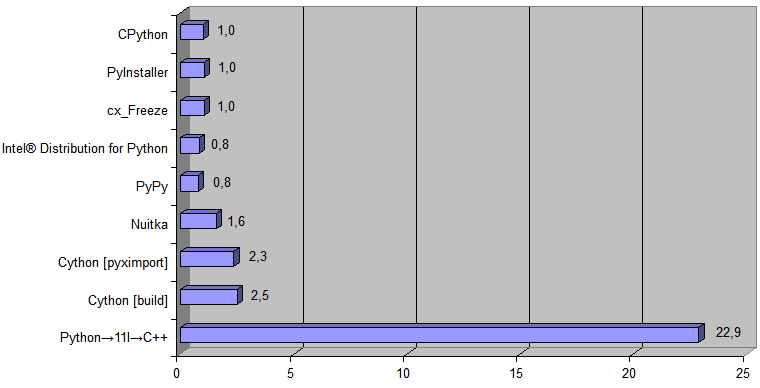
Le temps d'exécution
[ temps de conversion du fichier de 488 Ko ] était de 868 ms pour CPython et de 38 ms pour le code C ++ généré
[ cette fois-ci inclut à part entière [ c. -à- d. pas seulement travailler avec des données en RAM ] exécutant le programme par le système d'exploitation et toutes les entrées / sorties [ lecture du fichier source [ .pq ] et sauvegarde du nouveau fichier [ .html ] sur le disque ] ] .
Je voulais également essayer
Shed Skin , mais il ne prend pas en charge les fonctions locales.
Numba n'a pas pu être utilisé non plus (il génère une erreur «Utilisation de l'opcode inconnu LOAD_BUILD_CLASS»).
Voici l'archive avec le programme utilisé pour comparer les performances
[ sous Windows ] (nécessite Python 3.6 ou supérieur et les packages Python suivants: pywin32, cython).
Code source en Python et sortie des transpilateurs Python -> 11l et 11l -> C ++: