Exemples de reconstruction d'un fragment vidéo compressé par différents codecs avec approximativement la même valeur BPP (bits par pixel). Résultats de test comparatifs voir sous catLes chercheurs de WaveOne
affirment être proches d'une révolution dans la compression vidéo. Lors du traitement de la vidéo haute définition 1080p, leur
nouveau codec d'apprentissage automatique comprime la vidéo environ 20% mieux que les codecs vidéo traditionnels les plus modernes tels que H.265 et VP9. Et dans une vidéo «définition standard» (SD / VGA, 640 × 480), la différence atteint 60%.
Les développeurs appellent les méthodes de compression vidéo actuelles, mises en œuvre dans H.265 et VP9, «anciennes» selon les normes des technologies modernes: «Au cours des 20 dernières années, les fondements des algorithmes de compression vidéo existants n'ont pas changé de manière significative», écrivent les auteurs de l'article scientifique dans l'introduction de leur article. «Bien qu'ils soient très bien conçus et soigneusement réglés, ils restent codés en dur et en tant que tels ne peuvent pas s'adapter à la demande croissante et à une gamme d'applications de plus en plus polyvalente pour les matériaux vidéo, qui incluent l'échange dans les médias sociaux, la détection d'objets, la diffusion en réalité virtuelle, etc.»
L'utilisation de l'apprentissage automatique devrait enfin amener la technologie de compression vidéo au 21e siècle. Le nouvel algorithme de compression est nettement supérieur aux codecs vidéo existants. «À notre connaissance, il s'agit de la première méthode d'apprentissage automatique qui a montré un tel résultat», disent-ils.
L'idée principale de la compression vidéo est de supprimer les données redondantes et de les remplacer par une description plus courte qui vous permet de lire la vidéo plus tard. La plupart de la compression vidéo se déroule en deux étapes.
La première étape est la compression de mouvement, lorsque le codec recherche des objets en mouvement et essaie de prédire où ils seront dans la prochaine image. Ensuite, au lieu d'enregistrer les pixels associés à cet objet en mouvement, dans chaque image, l'algorithme code uniquement la forme de l'objet ainsi que la direction du mouvement. En effet, certains algorithmes examinent les futures images pour déterminer le mouvement encore plus précisément, bien que cela ne fonctionnera évidemment pas pour les diffusions en direct.
La deuxième étape de compression supprime les autres redondances entre une image et la suivante. Ainsi, au lieu d'enregistrer la couleur de chaque pixel dans le ciel bleu, l'algorithme de compression peut déterminer la zone de cette couleur et indiquer qu'elle ne change pas au cours des prochaines images. Ainsi, ces pixels restent de la même couleur jusqu'à ce qu'on leur dise de changer. C'est ce qu'on appelle la compression résiduelle.
La nouvelle approche que les scientifiques ont introduite utilise pour la première fois l'apprentissage automatique pour améliorer ces deux méthodes de compression. Ainsi, lors de la compression du mouvement, les méthodes d'apprentissage automatique de l'équipe ont trouvé de nouvelles redondances basées sur le mouvement, que les codecs conventionnels n'ont jamais pu détecter, et encore moins utiliser. Par exemple, tourner la tête d'une personne d'une vue frontale vers un profil donne toujours un résultat similaire: «Les codecs traditionnels ne peuvent pas prédire le profil d'une personne sur la base d'une vue frontale», écrivent les auteurs de l'article scientifique. Au contraire, le nouveau codec étudie ces types de modèles spatio-temporels et les utilise pour prédire les trames futures.
Un autre problème est l'allocation de la bande passante disponible entre le mouvement et la compression résiduelle. Dans certaines scènes, la compression de mouvement est plus importante, tandis que dans d'autres, la compression résiduelle offre le plus grand gain. Le compromis optimal entre eux diffère d'un cadre à l'autre.
Les algorithmes traditionnels traitent les deux processus séparément l'un de l'autre. Cela signifie qu'il n'y a pas de moyen facile de donner un avantage à l'un ou à l'autre et de trouver un compromis.
Les auteurs contournent cela en compressant les deux signaux en même temps et, en fonction de la complexité de la trame, déterminent comment répartir la bande passante entre les deux signaux de la manière la plus efficace.
Ces améliorations et d'autres ont permis aux chercheurs de créer un algorithme de compression qui dépasse de loin les codecs traditionnels (voir les repères ci-dessous).
 Des exemples de reconstruction d'un fragment compressé par différents codecs avec approximativement la même valeur BPP montrent un avantage significatif du codec WaveOne
Des exemples de reconstruction d'un fragment compressé par différents codecs avec approximativement la même valeur BPP montrent un avantage significatif du codec WaveOne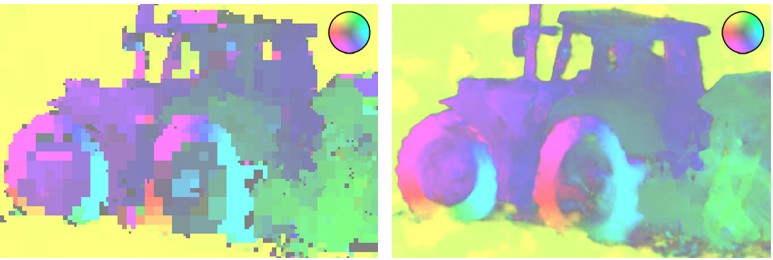 Cartes de flux optique H.265 (à gauche) et codec WaveOne (à droite) au même débit binaire
Cartes de flux optique H.265 (à gauche) et codec WaveOne (à droite) au même débit binaireCependant, la nouvelle approche n'est pas sans inconvénients,
note le MIT Technology Review . Le principal inconvénient est peut-être la faible efficacité de calcul, c'est-à-dire le temps requis pour l'encodage et le décodage de la vidéo. Sur la plate-forme Nvidia Tesla V100 et sur la vidéo de taille VGA, le nouveau décodeur fonctionne à une vitesse moyenne d'environ 10 images par seconde, et l'encodeur fonctionne à une vitesse d'environ 2 images par seconde. De telles vitesses sont tout simplement impossibles à utiliser dans les diffusions vidéo en direct, et avec l'encodage hors ligne des matériaux, le nouvel encodeur aura une portée très limitée.
De plus, la vitesse du décodeur n'est même pas suffisante pour
regarder une vidéo compressée avec ce codec sur un ordinateur personnel classique. Autrement dit, pour regarder ces vidéos, même en qualité SD minimale, un cluster informatique complet avec plusieurs accélérateurs graphiques est actuellement requis. Et pour regarder des vidéos en qualité HD (1080p), vous avez besoin d'une batterie de serveurs complète.
On ne peut qu'espérer une augmentation de la puissance des processeurs graphiques à l'avenir et une amélioration de la technologie: "La vitesse actuelle n'est pas suffisante pour un déploiement en temps réel, mais devrait être considérablement améliorée dans les travaux futurs", écrivent-ils.
Repères
HEVC/H.265, AVC/H.264, VP9 HEVC HM 16.0 . Ffmpeg, — . , . , B- H.264/5
bframes=0,
-auto-alt-ref 0 -lag-in-frames 0 . MS-SSIM, ,
-ssim.
SD HD, . SD- VGA e Consumer Digital Video Library (CDVL). 34 15 650 . HD Xiph 1080p: 22 11 680 . 1080p 1024 ( , 32 ).
:
- MS-SSIM ;
- MS-SSIM ;
- WaveOne ( ).
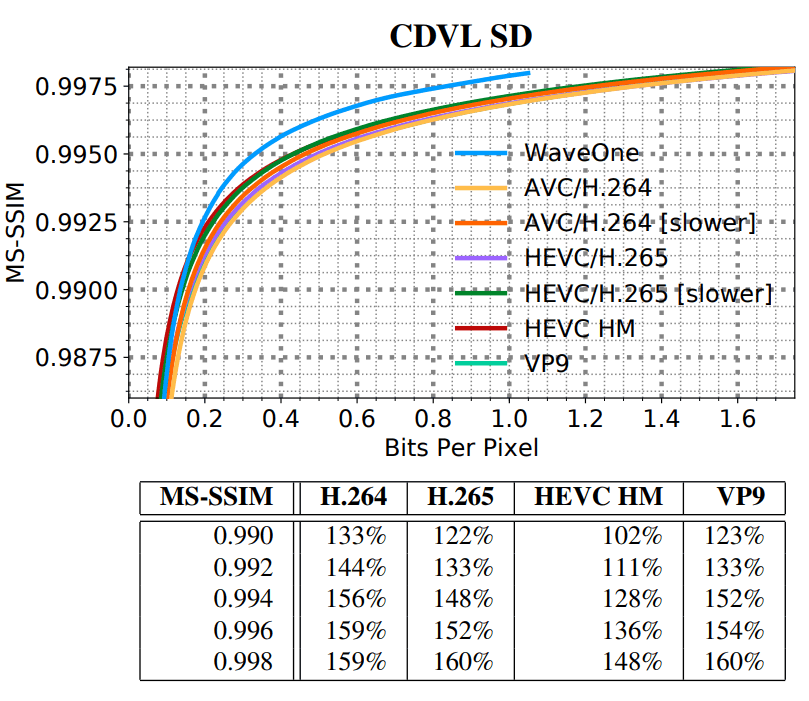 (SD)
(SD)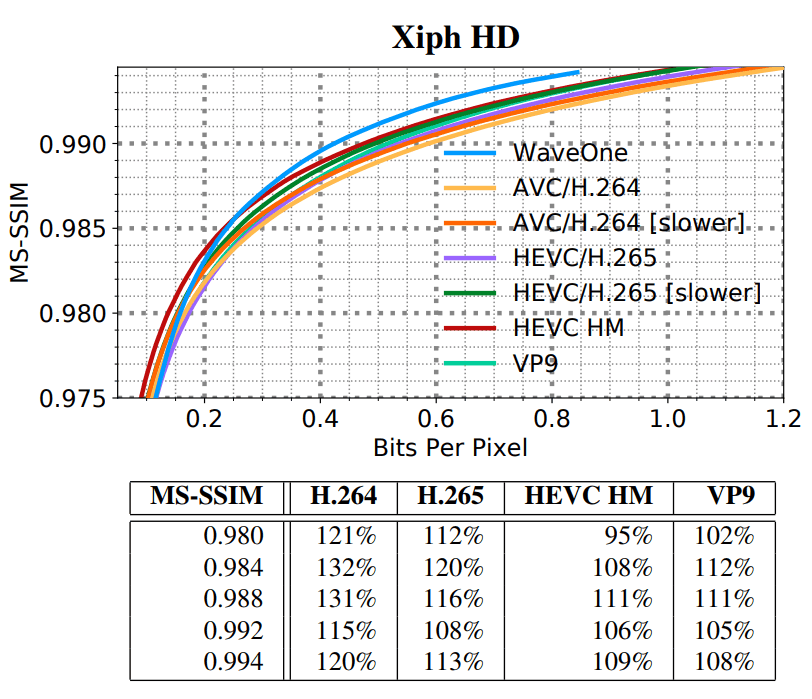 (HD)
(HD)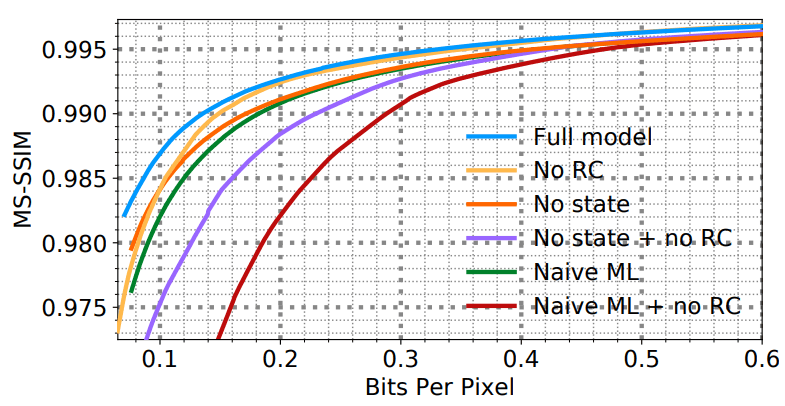 WaveOne
WaveOne. , . . , . G. Toderici, S. M. O’Malley, S. J. Hwang, D. Vincent, D. Minnen, S. Baluja, M. Covell, R. Sukthankar.
Variable rate image compression with recurrent neural networks, 2015; G. Toderici, D. Vincent, N. Johnston, S. J. Hwang, D. Minnen, J. Shor, M. Covell.
Full resolution image compression with recurrent neural networks, 2016; J. Balle, V. Laparra, E. P. Simoncelli.
End-to-end optimized image compression, 2016; N. Johnston, D. Vincent, D. Minnen, M. Covell, S. Singh, T. Chinen, S. J. Hwang, J. Shor, G. Toderici.
Improved lossy image compression with priming and spatially adaptive bit rates for recurrent networks, 2017 . , , .
ML- , . . . C.-Y. Wu, N. Singhal, and P. Krahenbuhl.
Video compression through image interpolation, ECCV (2018). , . AVC/H.264. , .
« » 16 2018 arXiv.org (arXiv:1811.06981). — (Oren Rippel), (Sanjay Nair), (Carissa Lew), (Steve Branson), (Alexander G. Anderson), (Lubomir Bourdev).
Stas911:
Altaisky: . ?
Stas911: . .