
Un projet d'intégration de système typique pour nous ressemble à ceci: le client a un chariot de systèmes pour les clients comptables, la tâche consiste à collecter les cartes client dans une base de données unique. Et non seulement pour collecter, mais aussi pour éliminer les doublons et les ordures. Pour obtenir des cartes clients propres, structurées et complètes.
Pour les débutants, je vais expliquer que la migration se déroule selon ce schéma:
sources → conversion de données (réponses ETL ou bus ) → récepteur .
Sur un projet, nous avons perdu trois mois simplement parce qu'une équipe tierce d'intégrateurs n'a pas étudié les données dans les systèmes sources. Le plus ennuyeux était que cela aurait pu être évité.
Ils ont travaillé comme ceci:
- Les intégrateurs système personnalisent le processus ETL.
- ETL transforme les données source et me les donne.
- J'étudie le déchargement et envoie des erreurs aux intégrateurs.
- Les intégrateurs corrigent les ETL et recommencent la migration.
Dans l'article, je montrerai comment analyser les données lors de l'intégration du système. J'ai étudié les téléchargements ETL, c'était très utile. Mais sur les données source, les mêmes techniques accéléreraient le travail deux fois.
Les conseils seront utiles aux testeurs, aux développeurs de produits d'entreprise, aux intégrateurs de systèmes et aux analystes. Les réceptions sont universelles pour les bases de données relationnelles et sont entièrement divulguées sur les volumes d'un million de clients.
Mais d'abord, sur l'un des principaux mythes de l'intégration du système.
La documentation et l'architecte vous aideront (en fait pas)
Les intégrateurs n'étudient souvent pas les données avant la migration - ils gagnent du temps. Ils lisent la documentation, regardent la structure, parlent avec l'architecte - et cela suffit. Après cela, ils planifient déjà l'intégration.
Ça tourne mal. Seule l'analyse montrera ce qui se passe réellement dans la base de données. Si vous n'entrez pas dans les données avec des manches retroussées et une loupe, la migration ira de travers.
La documentation ment. Un système d'entreprise typique fonctionne de 5 à 20 ans. Pendant toutes ces années, des changements ont été documentés par divers services et entrepreneurs. Chacun avec son propre clocher. Par conséquent, il n'y a aucune intégrité dans la documentation, personne ne comprend parfaitement la logique et la structure du stockage des données. Sans oublier que les délais sont toujours respectés et qu'il n'y a pas assez de temps pour la documentation.
Une histoire commune: dans la table client il y a un champ "SNILS", sur papier c'est très important. Mais quand je regarde les données, je vois - le champ est vide. En conséquence, le client accepte que la base cible se passe d'un champ pour SNILS, car il n'y a toujours pas de données.
Un cas particulier de la documentation est la réglementation et la description des processus métier: comment les données entrent dans la base de données, dans quelles circonstances, sous quel format. Tout cela n'aidera pas non plus.
Les processus commerciaux ne sont parfaits que sur papier. Au petit matin, l'opérateur endormi Anatoly entre dans le bureau de la banque à la périphérie de Vyksa. Sous la fenêtre, ils ont crié toute la nuit et le matin, Anatoly s'est disputé avec la fille. Il déteste le monde entier.
Les nerfs n'ont pas encore été mis en ordre et Anatoly conduit entièrement le nom du nouveau client dans le champ du nom de famille. Il oublie complètement son anniversaire - le "01.01.1900 g" par défaut reste dans le formulaire. Je m'en fous des règles quand tout autour est si enrageant !!!
Le chaos conquiert les processus métiers, très bien proportionnés sur le papier.
Un architecte système ne sait pas tout. Il s'agit encore une fois de la vénérable durée de vie des systèmes d'entreprise. Au fil des années où ils travaillent, les architectes ont changé. Même si vous parlez avec l'actuel, les décisions des précédentes seront surprenantes pendant le projet.
Et soyez sûr: même un architecte agréable à tous égards gardera secrets sa fakapy et ses béquilles du système.
L'intégration "par instruments" sans analyse des données est une erreur. Je vais montrer comment nous, chez HFLabs, apprenons les données grâce à l'intégration du système. Dans le dernier projet, je n'ai analysé que les téléchargements ETL. Mais lorsque le client donne accès aux données sources, je les vérifie définitivement selon les mêmes principes.
Champs remplis et valeurs nulles
Les vérifications les plus simples concernent l'exhaustivité des tableaux dans leur ensemble et l'exhaustivité des champs individuels. Je commence par eux.
Le nombre total de lignes dans le tableau. La demande la plus simple possible.
SELECT COUNT(*) FROM <table_name>;
J'obtiens le premier résultat.
Ici, je regarde l'adéquation des données. Si seulement deux millions de clients sont venus au déchargement d'une grande banque, alors quelque chose ne va clairement pas. Mais alors que tout semble comme prévu, on continue.
Combien de lignes sont remplies pour chaque champ séparément. Je vérifie toutes les colonnes du tableau.
SELECT <column_name>, COUNT(*) AS <column_name> cnt FROM <table_name> WHERE <column_name> IS NOT NULL;
Le premier est tombé sur un champ de joyeux anniversaire, et immédiatement curieux: pour une raison quelconque, les données ne sont pas venues du tout.
Si toutes les valeurs du champ sont «NULL» dans le téléchargement, la première chose que je regarde est le système source. Peut-être que les données y sont stockées correctement, mais elles ont été perdues lors de la migration.
Je vois que dans le système source, les anniversaires sont en place. Je vais chez les intégrateurs: les gars, erreur. Il s'est avéré que dans le processus ETL, la fonction de décodage ne fonctionnait pas correctement. Le code a été corrigé, lors du prochain téléchargement, nous vérifierons les modifications.
Je vais plus loin sur le terrain avec le TIN.
Il y a 100 millions de personnes dans la base de données, et seulement 65 000 sont remplies de NIF - c'est 0,07%. Une occupation aussi faible indique que le champ dans la base du récepteur peut ne pas être nécessaire du tout.
Je vérifie le système source, tout est correct: les TIN sont similaires aux vrais, mais il n'y en a presque pas. Donc, ce n'est pas une question de migration. Il reste à savoir si le client a besoin d'un champ presque vide sous le TIN dans la base de données cible.
Je suis arrivé au drapeau de suppression du client.
Les drapeaux sont vides. Mais quoi, l'entreprise n'enlève pas de clients? Je regarde le système source, je parle avec le client. Il s'avère que oui: le drapeau est formel, au lieu de supprimer des clients, leurs comptes sont supprimés. Aucun compte - comme si le client avait été supprimé.
Dans le système cible, l'indicateur client distant est requis, il s'agit d'une caractéristique de l'architecture. Ainsi, si le client n'a aucun compte dans le système récepteur, il doit être fermé via une logique supplémentaire ou pas du tout importé. Ensuite, comment le client décide.
Ensuite, la plaque d'adresse. Habituellement, quelque chose ne va pas avec ces tables, car les adresses sont une chose compliquée, elles sont entrées de différentes manières.
Je vérifie l'exhaustivité des éléments de l'adresse.
Les adresses ne sont pas uniformément renseignées, mais il est trop tôt pour tirer des conclusions: je vais d'abord demander au client à quoi il sert. Si pour la segmentation par pays, tout va bien: il y a suffisamment de données. Si pour les listes de diffusion, le problème est: les maisons sont presque vides, il n'y a pas d'appartements.
En conséquence, le client a vu que l'ETL prenait des adresses d'une tablette ancienne et non pertinente. Elle est à la base comme un monument. Mais il y a un autre tableau, nouveau et bon, les données doivent en être tirées.
Lors de l'analyse, je remplis les champs liés aux répertoires avec particularité. La condition «IS NOT NULL» ne fonctionne pas avec eux: au lieu de «NULL», la cellule est généralement «0». Par conséquent, vérifiez les champs de référence séparément.
Changements dans le remplissage des champs. J'ai donc vérifié l'occupation globale et l'occupation de chaque champ. Problèmes détectés, les intégrateurs ont corrigé le processus ETL et ont recommencé la migration.
J'exécute le deuxième déchargement pour toutes les étapes énumérées ci-dessus. J'écris des statistiques dans le même fichier pour voir les changements.
Exhaustivité de tous les domaines.
Entre les téléchargements, 5 millions d'enregistrements ont disparu. Je vais chez les intégrateurs, pose des questions typiques:
- «Pourquoi les records ont-ils été perdus?»;
- "Quelles données ont été éliminées?";
- "Quelles données avez-vous laissées?"
Il s'avère qu'il n'y a pas de problème: ils ont simplement retiré les clients «techniques» du nouveau déchargement. Ils sont dans la base de données pour les tests, ce ne sont pas des personnes vivantes. Mais avec la même probabilité, les données pourraient être perdues par erreur, cela se produit.
Mais les anniversaires du nouveau déchargement sont apparus, comme je m'y attendais.
Mais! Pas nécessairement bon lorsque des données précédemment manquantes sont soudainement apparues dans un nouveau téléchargement. Par exemple, les anniversaires peuvent être remplis de dates par défaut - il n'y a rien à se réjouir. Par conséquent, je vérifie toujours les données fournies.
Quoi vérifier, en un mot.
- Nombre total d'entrées dans les tableaux. Cette quantité est-elle adaptée aux attentes?
- Le nombre de lignes remplies dans chaque champ.
- Rapport entre le nombre de lignes remplies dans chaque champ et le nombre de lignes de la table. S'il est trop petit, c'est l'occasion de réfléchir à la possibilité de faire glisser le champ vers la base cible.
Répétez les trois premières étapes pour chaque téléchargement. Suivez la dynamique: où et pourquoi elle a augmenté ou diminué.Longueur des valeurs dans les champs de chaîne
Je respecte l'une des règles de base des tests - je vérifie les valeurs limites.
Quelles valeurs sont trop courtes. Parmi les valeurs les plus courtes, il y a plein d'ordure, il est donc intéressant de creuser ici.
SELECT * FROM <table_name> WHERE LENGTH(<column_name>) < 3;
De cette façon, je vérifie le nom, le numéro de téléphone, le TIN, OKVED, les adresses de site Web. Un non-sens apparaît comme "A * 1", "0", "11", "-" et "...".
Est-ce que tout va bien avec des valeurs maximales. Le champ de fermeture est un marqueur du fait que les données ne correspondaient pas pendant le transfert, et elles ont été automatiquement coupées. MySQL le craque sans avertissement. Dans le même temps, il semble que la migration se soit bien déroulée.
SELECT * FROM <table_name> WHERE LENGTH(<column_name>) = 65;
De cette façon, j'ai trouvé sur le terrain avec le type de document la ligne "Certificat d'enregistrement de la demande de reconnaissance de l'immigrant pour lui". Elle a dit aux intégrateurs que la longueur du champ a été corrigée.
Comment les valeurs sont réparties sur la longueur. Dans HFLabs, nous appelons la table de distribution de longueur pour les lignes.
SELECT LENGTH(<column_name>), COUNT(<column_name>) FROM <table_name> GROUP BY LENGTH(<column_name>);
Ici je cherche des anomalies dans la distribution le long de la longueur. Par exemple, voici une fréquence pour une table avec des adresses postales.
Les valeurs d'une longueur de 125 sont trop nombreuses. Je regarde la base de données source et constate que pour une raison quelconque, certaines adresses ont été coupées à 125 caractères il y a trois ans. Les autres années, tout va bien. Je vais avec ce problème au client et aux intégrateurs, nous comprenons.
Quoi vérifier, en un mot.
- Les valeurs les plus courtes dans les champs de chaîne. Souvent, les lignes de moins de trois caractères sont des ordures.
- Valeurs qui «butent» sur la longueur de la largeur du champ. Ils sont souvent circoncis.
- Anomalies dans la distribution des rangées sur la longueur.
Valeurs populaires
Je divise en trois catégories les valeurs qui tombent dans le top populaire:
- vraiment commun , comme le nom "Tatyana" ou le deuxième prénom "Vladimirovitch". Ici, il faut se rappeler que dans le cas général, Tatiana ne devrait pas être 100 fois plus populaire qu'Anna, et Ismail ne peut guère être plus populaire qu'Egor;
- ordures , comme ".", "1", "-" et similaires;
- par défaut sur le formulaire de saisie, comme "01/01/1900" pour les dates.
Deux cas sur trois sont des marqueurs du problème, il est utile de les rechercher.
Je recherche des valeurs populaires dans trois types de champs:
- Champs de chaîne ordinaires.
- Champs de chaîne de référence. Ce sont des champs de chaîne ordinaires, mais le nombre de valeurs différentes en eux est bien sûr réglementé. Ces champs stockent les pays, les villes, les mois et les types de téléphone.
- Champs de classificateur - ils contiennent un lien vers une entrée dans une table de classificateur tiers.
J'étudie les domaines de chacun de ces types un peu différemment.
Pour les champs de chaîne - quelles sont les 100 premières valeurs populaires. Si vous le souhaitez, vous pouvez en prendre plus, mais dans les cent premières valeurs, toutes les anomalies sont généralement placées.
SELECT * FROM (SELECT <column_name>, COUNT(*) cnt FROM <table_name> GROUP BY <column_name> ORDER BY 2 DESC) WHERE ROWNUM <= 100;
Je vérifie les champs de cette façon:
- Nom complet, ainsi que les noms de famille, prénoms et patronyme séparément;
- les dates de naissance et généralement toutes les dates;
- adresses L'adresse complète et ses composants individuels, s'ils sont stockés dans la base de données;
- Téléphones
- série, numéro, type, lieu de délivrance des documents.
Presque toujours parmi les valeurs populaires de test et par défaut, certains talons.

Il arrive que le problème trouvé ne soit pas du tout un problème. Une fois, j'ai trouvé un numéro de téléphone étrangement populaire dans la base de données. Il s'est avéré que les clients ont indiqué ce nombre en tant que travailleur, et dans la base de données, il y avait simplement beaucoup d'employés d'une même organisation.
En cours de route, une telle analyse affichera des champs de référence cachés. Logiquement, ces champs ne sont pas censés être des répertoires, mais en fait ils se trouvent dans la base de données. Par exemple, je sélectionne des valeurs populaires dans le champ "Position", et il n'y en a que cinq.
L'entreprise ne sert peut-être que cinq professions. Pas très vrai, non? Au contraire, dans le formulaire pour les opérateurs, au lieu d'une ligne, ils ont créé un répertoire et oublié de vider les valeurs. La question importante ici est la suivante: est-il sage de remplir des messages via l'annuaire? Ainsi, grâce à l'analyse des données, je m'attaque à d'éventuels problèmes avec le logiciel opérateur.
Pour les champs de référence et les classificateurs, je vérifie la popularité de toutes les valeurs. Pour commencer, je détermine quels champs sont des répertoires. Vous ne pouvez pas vous en tirer avec les scripts, je prends la documentation et je fais semblant. En règle générale, les répertoires sont créés pour les valeurs, dont le nombre est bien sûr et relativement petit:
- les pays
- langues
- devises
- mois
- la ville.
Dans un monde idéal, le contenu des champs de référence est clair et cohérent. Mais notre monde n'est pas comme ça, donc je vérifie avec une demande.
SELECT <column_name>, COUNT(*) cnt FROM <table_name> GROUP BY <column_name> ORDER BY 2 DESC;
Habituellement, dans les champs de chaîne des répertoires se trouve ceci.
Problèmes courants:
- fautes de frappe;
- les espaces
- cas différent.
Après avoir trouvé un gâchis, je vais chez les intégrateurs avec des exemples sous la main. Laissez-les laisser les ordures à la source et éliminez les écarts. Ensuite, dans la base de données cible pour la rigueur, il sera possible de transformer les lignes de référence en classificateurs.
Je vérifie les valeurs populaires dans les champs du classificateur pour détecter le manque d'options. Face à de tels cas.
Ces classificateurs semblent très étranges, ils doivent être montrés au client. Chaque fois que j'ai eu une erreur derrière de tels cas: soit quelque chose ne va pas dans la base de données, soit les données ont été téléchargées au mauvais endroit.
Quoi vérifier, en un mot.
- Quels champs de chaîne sont des références et lesquels ne le sont pas.
- Pour les champs de chaîne simples, les principales valeurs populaires. Habituellement dans la poubelle supérieure et les données par défaut.
- Pour les champs de référence de chaîne, la distribution de toutes les valeurs par popularité. La sélection affichera des écarts dans les valeurs de référence.
- Pour les classificateurs - y a-t-il suffisamment d'options dans la base de données.
Cohérence et réconciliation croisée
De l'analyse des données à l'intérieur des tableaux, je passe à l'analyse des relations.
Si les données sont liées ou non. Nous appelons ce paramètre «cohérence». Je prends la table des subordonnés, par exemple, avec les téléphones. Pour cela dans un couple - la table parentale des clients. Et je vois combien de clients dans la table subordonnée sont des identifiants qui ne sont pas dans le parent.
SELECT COUNT(*) FROM ((SELECT <ID1> FROM <table_name_1>) MINUS (SELECT <ID2> FROM <table_name_2>));
Si la demande a donné un delta, cela signifie pas de chance - il y a des données non liées dans le téléchargement. Je vérifie donc les tables avec les téléphones, les contrats, les adresses, les factures, etc. Une fois, lors d'un projet, elle a trouvé 23 millions de numéros simplement suspendus dans l'air.
Cela fonctionne également dans la direction opposée - je recherche des clients qui, pour une raison quelconque, n'ont pas un seul contrat, adresse, numéro de téléphone. Parfois, c'est normal - eh bien, le client n'a pas d'adresse, qu'est-ce qui ne va pas. Ici, vous devez vous renseigner auprès du client, la documentation sera facilement trompeuse.
Y a-t-il des duplications de clés primaires dans différentes tables. Parfois, des entités identiques sont stockées dans des tables différentes. Par exemple, les clients hétérosexuels. (Personne ne sait pourquoi, car Brejnev a toujours revendiqué la structure.) Mais la table dans le récepteur est unique et lors de la migration, les identifiants des clients entreront en conflit.
Je tourne la tête et regarde la structure de la base: où la fragmentation d'entités similaires est possible. Il peut s'agir de tableaux de clients, de téléphones de contact, de passeports, etc.
S'il y a plusieurs tables avec des entités similaires, je fais un recoupement: je vérifie l'intersection des identifiants. Intersection - collez un patch. Par exemple, nous collectons des identifiants pour une seule table selon le schéma «nom de la table source + ID».
Quoi vérifier, en un mot.
- Combien de données non liées se trouvent dans des tables liées.
- Existe-t-il des conflits potentiels de clé primaire?
Quoi d'autre à vérifier
Y a-t-il des caractères latins auxquels ils n'appartiennent pas. Par exemple, dans les noms de famille.
SELECT <column_name> FROM <table_name> WHERE REGEXP_LIKE(<column_name>, '[AZ]', 'i');
J'attrape donc la merveilleuse lettre latine "C", qui coïncide avec le cyrillique. L'erreur est désagréable, car selon le nom avec le latin "C" l'opérateur ne trouvera jamais de client.
Y a-t-il des caractères étrangers dans les champs de chaîne destinés aux nombres? SELECT <column_name> FROM <table_name> WHERE REGEXP_LIKE(<column_name>, '[^0-9]');
Des problèmes apparaissent dans les champs avec le numéro de passeport de la Fédération de Russie ou du TIN. Les téléphones sont les mêmes, mais là j'autorise plus, les crochets et les tirets. La demande révélera également la lettre «O», qui a été définie au lieu de zéro.
Les données sont-elles adéquates? On ne sait jamais d'où viendra le problème, donc je suis toujours sur mes gardes. J'ai rencontré de tels cas:
- "Sofya Vladimirovna" est-elle un client de 50 000 téléphones? Est-ce normal? Réponse: pas normal. Le client est technique, ils lui ont mis des numéros de téléphone «sans propriétaire» pour faire des sms-mailings. Il n'est pas nécessaire de tirer le client vers une nouvelle base;
- Les NIF sont remplis, en fait, la colonne contient «79853617764», «89109462345», «4956780966» et ainsi de suite. Quel genre de téléphones, okuda? Où est l'auberge? Réponse: quel type de chiffres - on ne sait pas qui l'a mis - n'est pas clair. Personne ne les utilise. Le TIN actuel est stocké dans un autre champ d'une autre table, extrait de là;
- le champ «adresse sur une ligne» ne correspond pas aux champs dans lesquels l'adresse est stockée en partie. Pourquoi les adresses sont-elles différentes? Réponse: une fois que les opérateurs ont rempli les adresses avec une seule ligne, et le système externe a trié les adresses dans des champs séparés. Pour la segmentation. Au fil du temps, les gens ont changé d'adresse. Les opérateurs les ont régulièrement mis à jour, mais uniquement sous forme de chaîne: l'adresse est restée ancienne en partie.
Tout ce dont vous avez besoin est SQL et Excel
Pour analyser les données, aucun logiciel coûteux n'est nécessaire. Assez bon vieux Excel et connaissance de SQL.
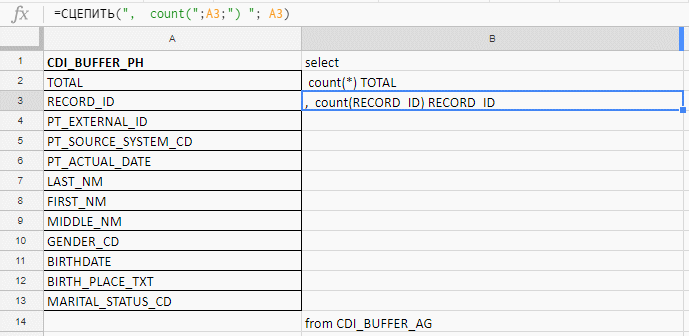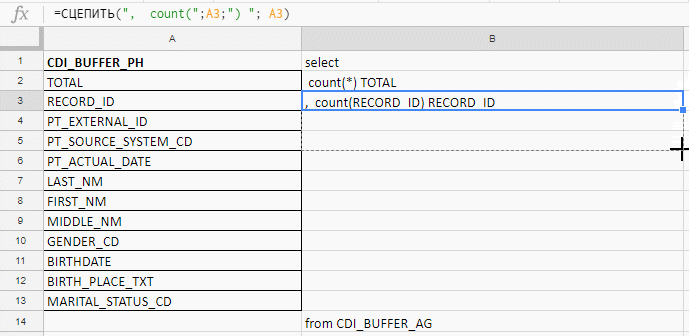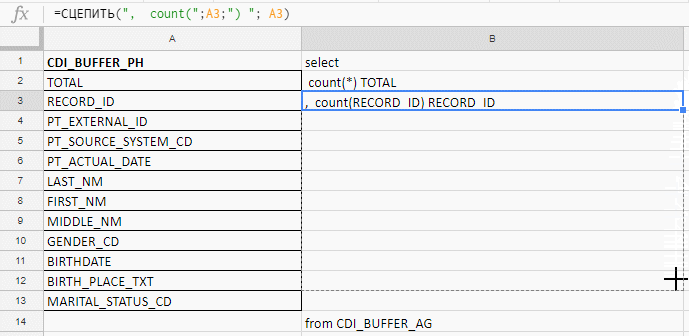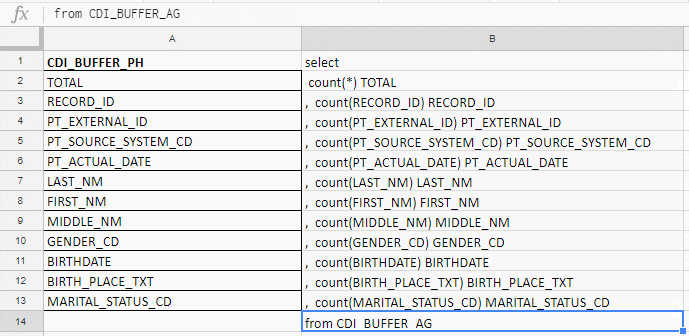
Excel que j'utilise pour compiler une longue requête. Par exemple, je vérifie que les champs sont complets et il y en a 140 dans le tableau. J'écrirai avec mes mains avant le complot de carottes, donc je recueille la demande avec les formules dans la plaque Excel.
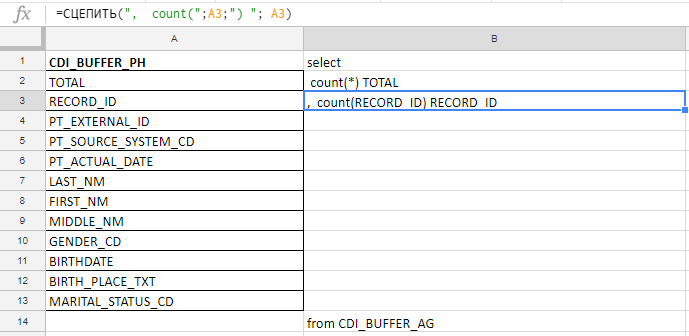 Dans la colonne «A» j'insère les noms des champs, je les prends dans les tables de documentation ou de service. Dans la colonne "B" - une formule pour coller une demande
Dans la colonne «A» j'insère les noms des champs, je les prends dans les tables de documentation ou de service. Dans la colonne "B" - une formule pour coller une demandeJ'insère les noms des champs, écris la première formule dans la colonne "B", tire le coin - et vous avez terminé.
 Fonctionne dans Excel, dans Google Docs et dans Excel Online (disponible sur Yandex.Disk)
Fonctionne dans Excel, dans Google Docs et dans Excel Online (disponible sur Yandex.Disk)L'analyse des données sauve la voiture du temps et sauve les nerfs des managers. Avec elle, il est plus facile de respecter le délai. Si le projet est important, l'analyse permettra d'économiser des millions de roubles et une réputation.
Pas des chiffres, mais des conclusions
Elle a formulé une règle pour elle-même: ne pas montrer de chiffres nus au client, vous n’obtiendrez toujours pas l’effet. Ma tâche consiste à analyser les données et à tirer des conclusions, et à joindre les chiffres comme preuves. Les conclusions sont primaires, les chiffres sont secondaires.
Ce que je collecte pour le rapport:
- la formulation des problèmes sous forme d'hypothèse ou de question : «Le NIF est rempli de 0,07%. Comment utilisez-vous ces données, quelle est leur pertinence, comment les interpréter? Y a-t-il une seule DCI dans une table? " Vous ne pouvez pas blâmer: "Votre NIF n'est pas du tout rempli." En réponse, vous ne recevrez que de l'agression;
- exemples de problèmes. Ce sont les tablettes dont il y a tellement dans l'article;
- options sur la façon de le faire: "Il pourrait être utile de supprimer le TIN de la base cible afin de ne pas produire de champs vides."
Je n'ai pas le droit de décider quoi choisir exactement dans la base de données source et comment modifier les données pendant la migration. Par conséquent, avec le rapport, je vais chez le client ou chez les intégrateurs, et nous découvrons comment procéder.
Parfois, le client, voyant le problème, répond: «Ne vous inquiétez pas, ne faites pas attention. Nous allons acheter un téraoctet supplémentaire de mémoire, c'est tout. C'est moins cher que l'optimisation. " Vous ne pouvez pas accepter cela: si vous prenez tout de suite, il n'y aura pas de qualité dans le récepteur. Toutes les mêmes données inutiles redondantes migrent.
Par conséquent, nous demandons doucement mais régulièrement: "Dites-nous comment vous utiliserez ces données particulières dans le système cible." Pas "pourquoi vous avez besoin", à savoir "comment vous allez l'utiliser". Les réponses «alors nous trouverons» ou «juste au cas où» ne conviennent pas. Tôt ou tard, le client comprend quelles données peuvent être supprimées.
L'essentiel est de trouver et de résoudre tous les problèmes jusqu'à ce que le système soit lancé en prod. Pour changer l'architecture et le modèle de données vivants, vous perdrez la tête.
C'est tout avec des vérifications de base, étudiez les données!