Le jeu de Revenge de Montezuma sur Habré n'a pas été écrit autant. C'est un jeu classique complexe qui était auparavant très populaire, mais maintenant il est joué soit par ceux avec qui il évoque des sentiments nostalgiques, soit par des chercheurs développant l'IA.
Cet été, il a été
rapporté que DeepMind était capable d'enseigner à son IA comment jouer à des jeux pour Atari, y compris Montezuma's Revenge. En utilisant l'exemple du même jeu, les créateurs d'OpenAI ont également
enseigné leur développement. Maintenant, Uber a entrepris un projet similaire.
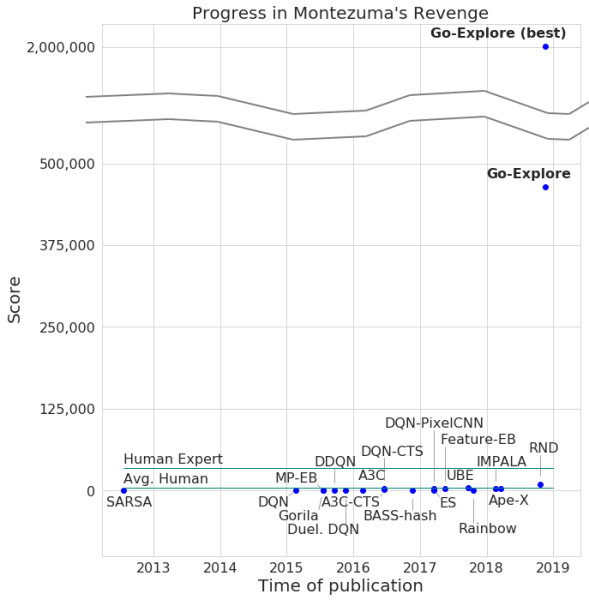
Les développeurs ont annoncé le passage du jeu par leur réseau de neurones, avec un nombre maximum de points de 2 millions. Certes, le système ne gagnait en moyenne pas plus de 400 000 pour chaque tentative. Quant au passage, l'ordinateur a atteint le niveau 159.
De plus, Go-Explore a appris à passer par Pitfall, avec un excellent résultat supérieur au joueur moyen, sans parler des autres agents de l'IA. Le nombre de points marqués par Go-Explore dans ce jeu est de 21 000.
La différence entre Go-Explore et ses «collègues» est que les réseaux de neurones n'ont pas besoin de démontrer le passage de différents niveaux pour la formation. Le système apprend tout lui-même pendant le jeu, montrant des résultats bien supérieurs à ceux démontrés par les réseaux de neurones qui nécessitent un entraînement visuel. Selon les développeurs de Go-Explore, la technologie est sensiblement différente de toutes les autres, et ses capacités permettent l'utilisation d'un réseau neuronal dans un certain nombre de domaines, y compris la robotique.
La plupart des algorithmes ont du mal à gérer la vengeance de Montezuma car le jeu n'a pas de retour très explicite. Par exemple, un réseau de neurones «affûté» pour recevoir des récompenses en passant un niveau combattra plutôt l'ennemi que de sauter sur une échelle qui mène à la sortie et vous permet d'avancer plus rapidement. D'autres systèmes d'intelligence artificielle préfèrent recevoir une récompense ici et maintenant, et ne pas aller de l'avant dans «l'espoir» d'en savoir plus.
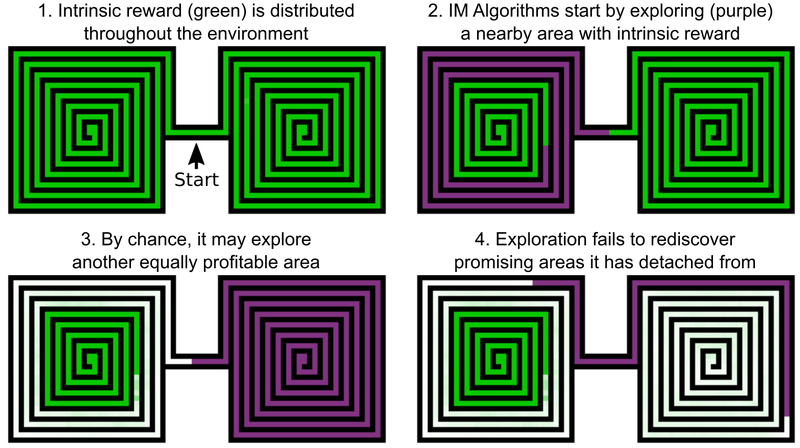
L'une des décisions des ingénieurs Uber est d'ajouter des bonus pour explorer le monde du jeu, cela peut être appelé la motivation interne de l'IA. Mais même les éléments de l'IA avec une motivation intrinsèque supplémentaire ne fonctionnent pas bien avec la vengeance et le piège de Montezuma. Le problème est que l'IA "oublie" les lieux prometteurs après les avoir dépassés. En conséquence, l'agent de l'IA est bloqué à un niveau où tout semble avoir été enquêté.
Un exemple est l'agent de l'IA, qui doit étudier deux labyrinthes - oriental et occidental. Il commence à passer par l'un d'eux, mais décide soudain qu'il serait possible de passer par le second. Le premier reste étudié à 50%, le second à 100%. Et l'agent ne revient pas dans le premier labyrinthe - simplement parce qu'il a «oublié» qu'il n'a pas été achevé jusqu'au bout. Et comme le passage entre le labyrinthe oriental et occidental a déjà été étudié, l'IA n'a aucune motivation à revenir.
Selon les développeurs d'Uber, la solution à ce problème comprend deux étapes: la recherche et l'amplification. Comme pour la première partie, l'IA crée ici une archive de différents états de jeu - cellules (cellules) - et de diverses trajectoires qui y conduisent. L'IA choisit l'opportunité d'obtenir le nombre maximum de points lors de la détection de la trajectoire optimale.
Les cellules sont des cadres de jeu simplifiés - des images de 11 x 8 dans des tons de gris avec une intensité de 8 pixels, avec des cadres suffisamment différents - pour ne pas gêner le passage du jeu.

En conséquence, l'IA se souvient des emplacements prometteurs et y revient après avoir examiné d'autres parties du monde du jeu. Le «désir» d'explorer le monde du jeu et les lieux prometteurs de Go-Explore est plus fort que le désir de recevoir un prix ici et maintenant. Go-Explore utilise également des informations sur les cellules dans lesquelles l'agent IA est formé. Pour la vengeance de Montezuma, ce sont les données de pixels comme leurs coordonnées X et Y, la pièce actuelle et le nombre de clés trouvées.
L'étage d'amplification fonctionne comme une protection contre le «bruit». Si les solutions d'IA sont instables au «bruit», l'IA les renforce à l'aide d'un réseau neuronal à plusieurs niveaux, fonctionnant sur l'exemple des neurones du cerveau humain.

Lors des tests, Go-Explore fonctionne très bien - en moyenne, l'IA étudie 37 chambres et résout 65% des puzzles de premier niveau. C'est bien mieux que les tentatives précédentes pour conquérir le jeu - alors l'IA a étudié en moyenne 22 chambres du premier niveau.

En ajoutant du gain à l'algorithme existant, l'IA a commencé à réussir en moyenne 29 niveaux (pas les chambres) avec un score moyen de 469,209.
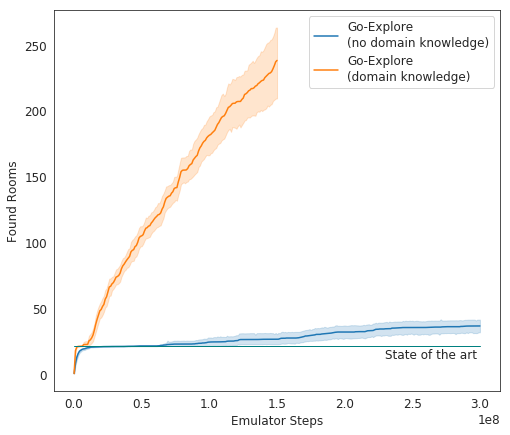
L'incarnation finale de l'IA d'Uber a commencé à faire fonctionner le jeu beaucoup mieux que les autres agents de l'IA, et mieux que les humains. Maintenant, les développeurs améliorent leur système afin qu'il montre un résultat encore plus impressionnant.