Le 8 novembre, dans le hall principal de la conférence
HighLoad ++ 2018 , dans le cadre de la section DevOps et opérations, un rapport a été établi intitulé Bases de données et Kubernetes. Il parle de la haute disponibilité des bases de données et des approches de tolérance aux pannes pour Kubernetes et avec lui, ainsi que des options pratiques pour placer le SGBD dans les clusters Kubernetes et les solutions existantes pour cela (y compris Stolon pour PostgreSQL).

Par tradition, nous sommes heureux de présenter une
vidéo avec un rapport (environ une heure,
beaucoup plus informatif
que l' article) et la principale compression sous forme de texte. C'est parti!
Théorie
Ce rapport est apparu comme une réponse à l'une des questions les plus populaires que nous avons posées sans relâche ces dernières années à différents endroits: commentaires sur Habr ou YouTube, réseaux sociaux, etc. Cela semble simple: "Est-il possible d'exécuter la base de données dans Kubernetes?", Et si nous répondions généralement "généralement oui, mais ...", alors il n'y avait clairement pas assez d'explications pour ces "en général" et "mais", mais pour les adapter dans un court message n'a pas réussi.
Cependant, pour commencer, je résume le problème de la "base de données [données]" à l'état dans son ensemble. Un SGBD n'est qu'un cas particulier de décisions avec état, dont une liste plus complète peut être représentée comme suit:
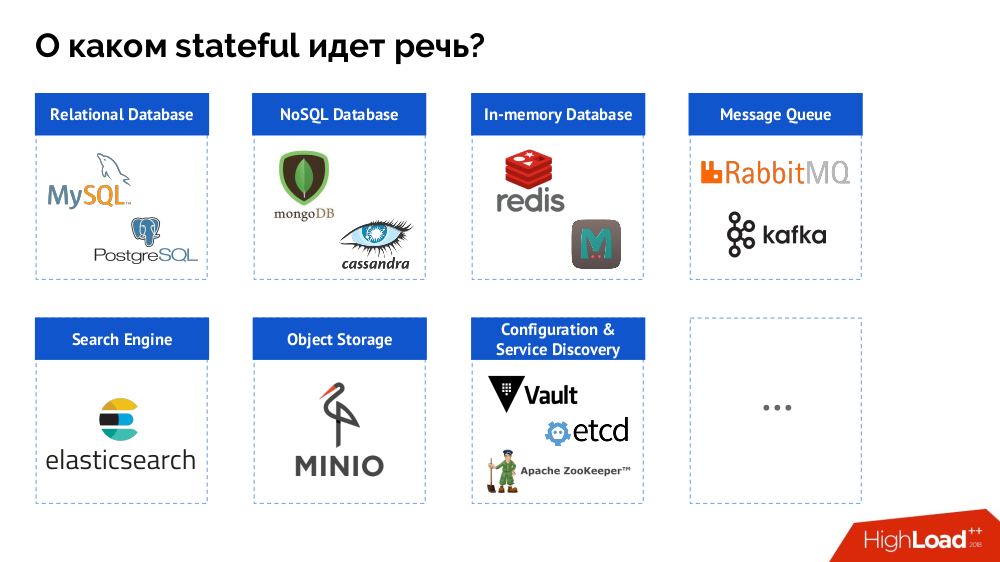
Avant d'examiner des cas spécifiques, je parlerai de trois caractéristiques importantes du travail / de l'utilisation de Kubernetes.
1. Philosophie de haute disponibilité de Kubernetes
Tout le monde connaît l'analogie «animaux de compagnie
vs bétail » et comprend que si Kubernetes est une histoire du monde du troupeau, alors les SGBD classiques ne sont que des animaux de compagnie.
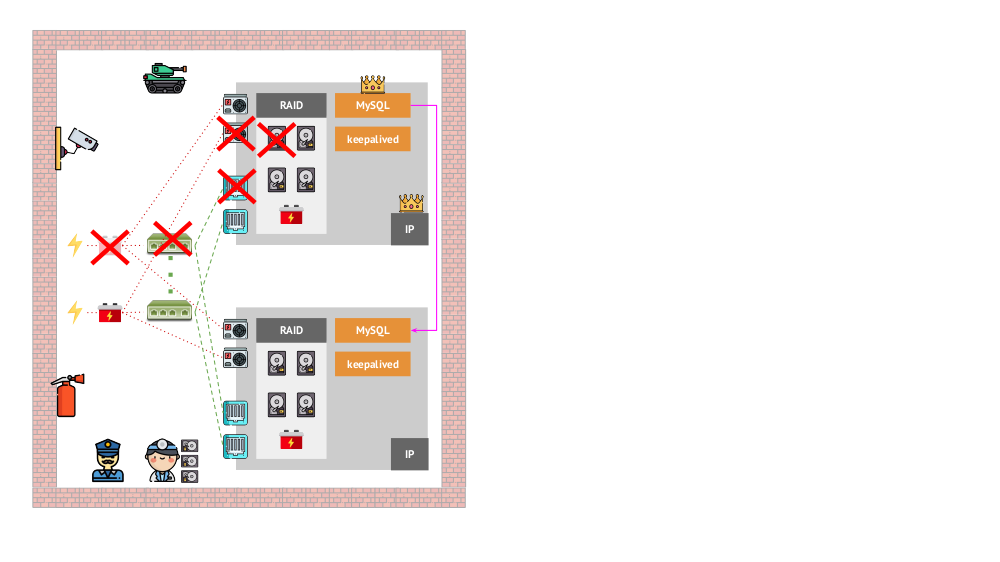
Et à quoi ressemblait l'architecture des «animaux de compagnie» dans la version «traditionnelle»? Un exemple classique d'installation de MySQL est la réplication sur deux serveurs de fer avec une alimentation redondante, un disque, un réseau ... et tout le reste (y compris un ingénieur et divers outils auxiliaires), qui nous aideront à être sûrs que le processus MySQL n'échouera pas, et s'il y a un problème avec l'un des éléments critiques pour ses composants, la tolérance aux pannes sera respectée:
À quoi ressemblera la même chose dans Kubernetes? Ici, il y a généralement beaucoup plus de serveurs de fer, ils sont plus simples et ils n'ont pas d'alimentation et de réseau redondants (dans le sens où la perte d'une machine n'affecte rien) - tout cela est combiné dans un cluster. Sa tolérance aux pannes est fournie par le logiciel: si quelque chose arrive au nœud, Kubernetes détecte et démarre les instances nécessaires sur l'autre nœud.
Quels sont les mécanismes de haute disponibilité dans les K8?
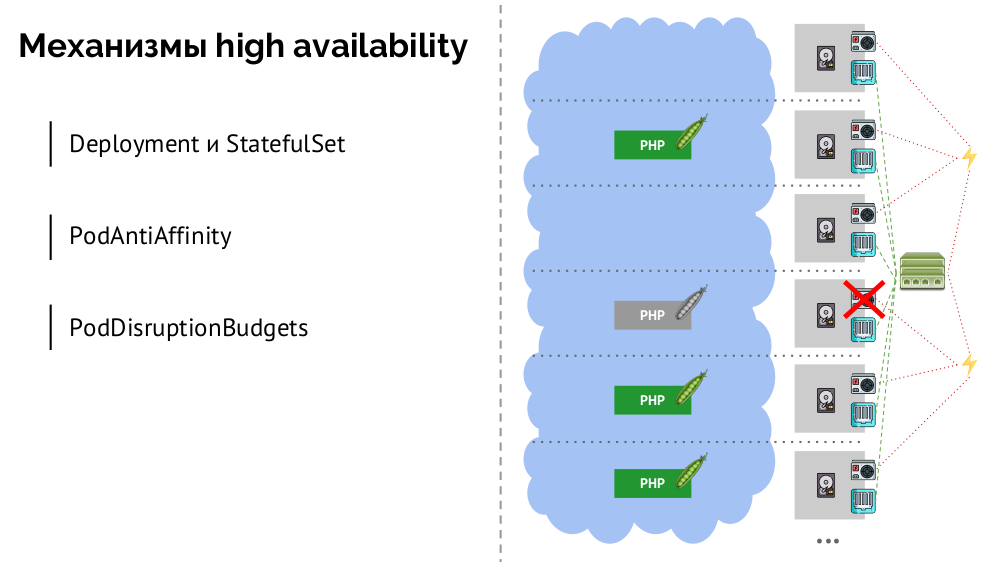
- Contrôleurs Il en existe de nombreux, mais deux principaux:
Deployment (pour les applications sans état) et StatefulSet (pour les applications avec état). Ils stockent toute la logique des actions entreprises en cas de panne d'un nœud (inaccessibilité du pod). PodAntiAffinity - la possibilité de spécifier des pods spécifiques afin qu'ils ne se trouvent pas sur le même noeud.PodDisruptionBudgets - limite le nombre d'instances de pod qui peuvent être désactivées en même temps en cas de travail planifié.
2. Garantie de cohérence Kubernetes
Comment fonctionne le schéma de tolérance de panne à maître unique familier? Deux serveurs (maître et secours), dont l'un est constamment accessible par l'application, qui à son tour est utilisé via l'équilibreur de charge. Que se passe-t-il en cas de problème de réseau?
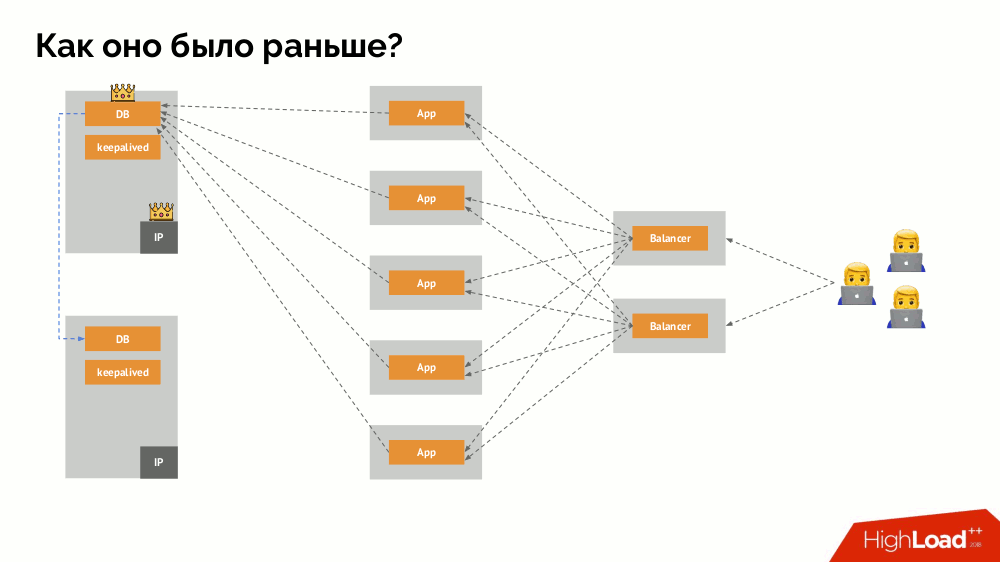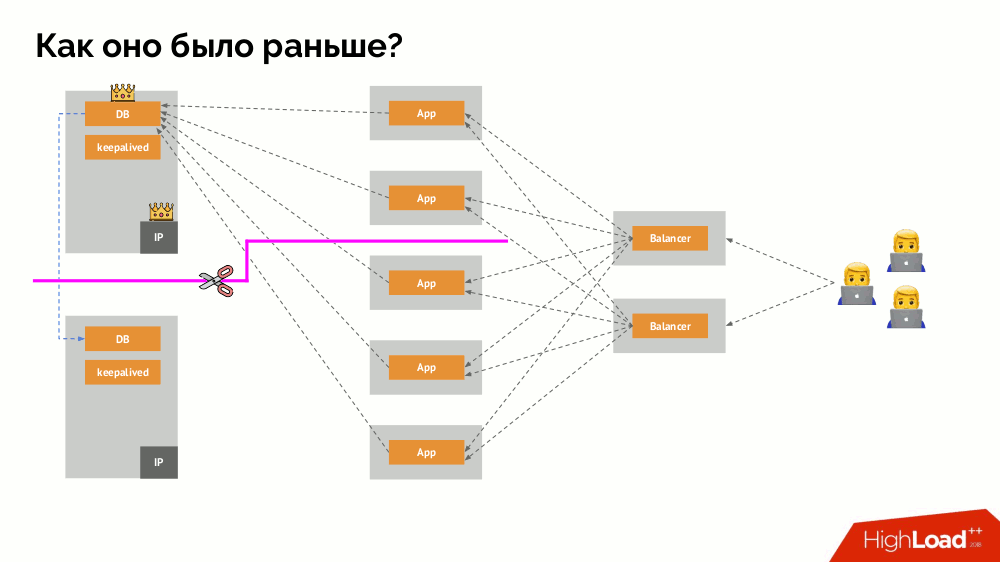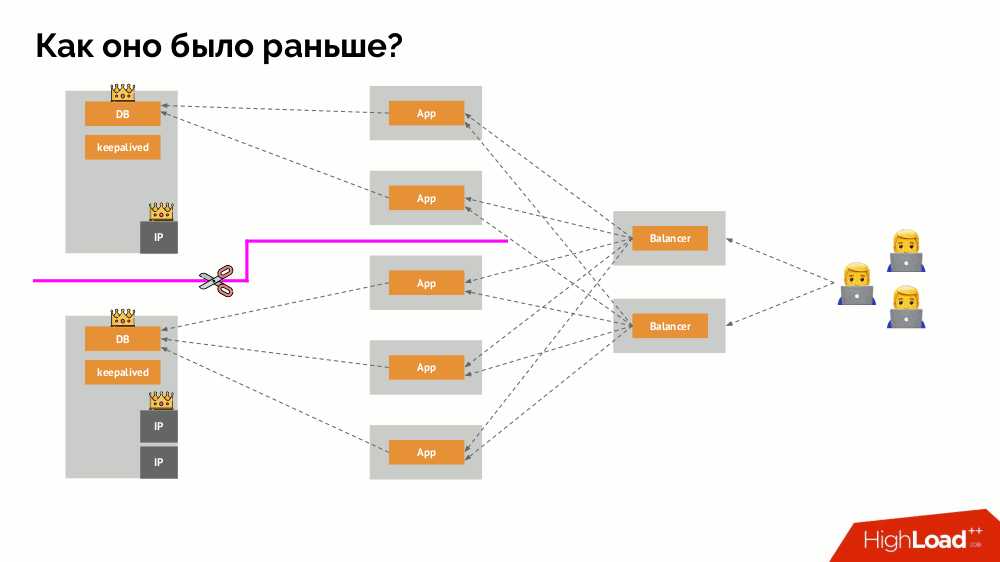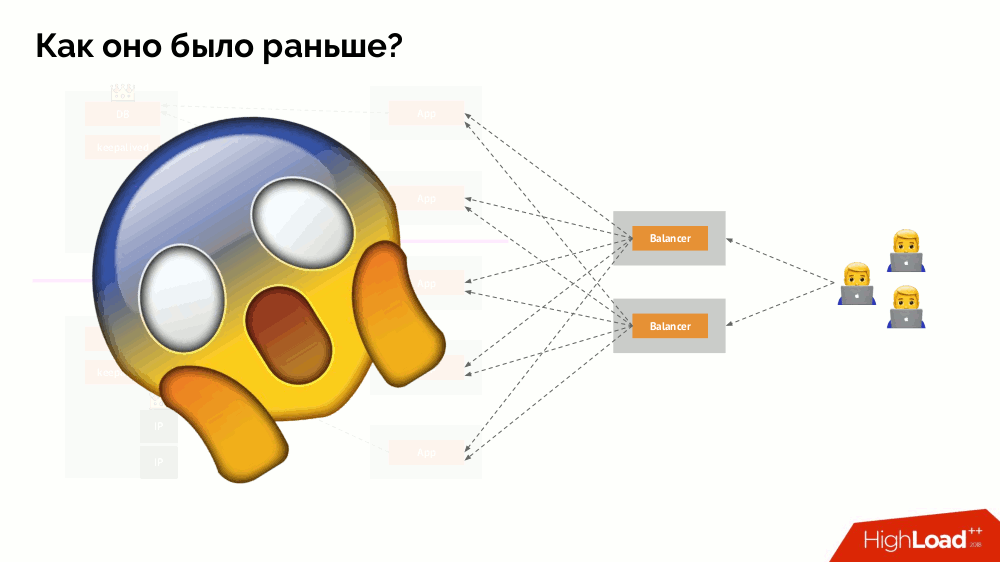 Split-brain
Split-brain classique: l'application commence à accéder aux deux instances du SGBD, dont chacune se considère comme la principale. Pour éviter cela, keepalived a été remplacé par corosync avec déjà trois instances pour atteindre un quorum lors du vote pour le maître. Cependant, même dans ce cas, il y a des problèmes: si une instance de SGBD tombée en panne tente de "se tuer" de toutes les manières possibles (supprimer l'adresse IP, traduire la base de données en lecture seule ...), alors l'autre partie du cluster ne sait pas ce qui est arrivé au maître - cela pourrait arriver, que ce noeud fonctionne toujours et que les requêtes y parviennent, ce qui signifie que nous ne pouvons toujours pas changer d'assistant.
Pour résoudre cette situation, il existe un mécanisme pour isoler le nœud afin de protéger l'ensemble du cluster contre un fonctionnement incorrect - ce processus est appelé
clôture . L'essence pratique se résume au fait que nous essayons par des moyens externes de "tuer" la voiture tombée. Les approches peuvent être différentes: de la mise hors tension de la machine via IPMI et du blocage du port du commutateur à l'accès à l'API du fournisseur de cloud, etc. Et ce n'est qu'après cette opération que vous pouvez changer d'assistant. Cela garantit une garantie
au plus une fois qui nous assure la
cohérence .
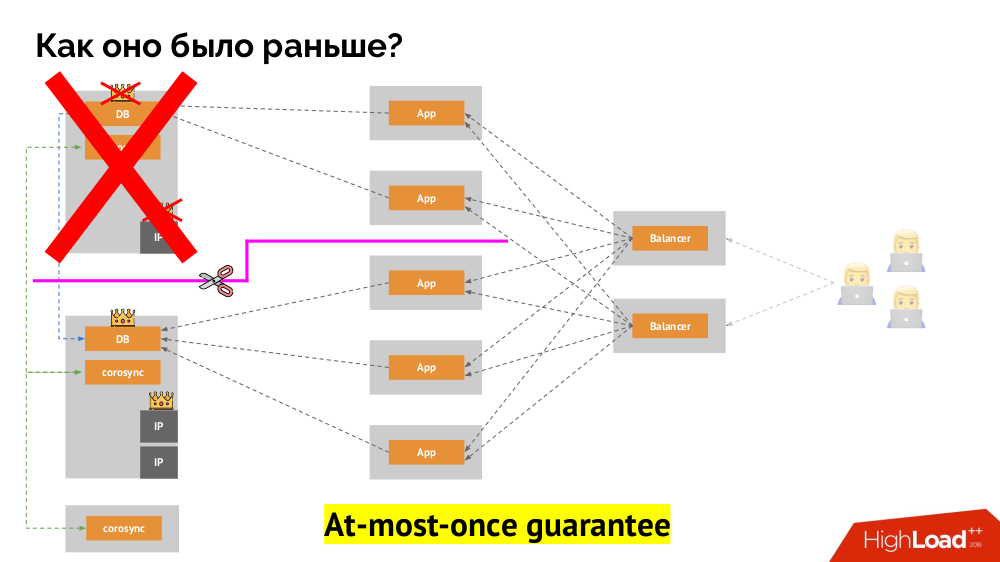
Comment réaliser la même chose dans Kubernetes? Pour ce faire, il existe déjà des contrôleurs dont le comportement en cas d'inaccessibilité d'un nœud est différent:
Deployment : "On m'a dit qu'il devrait y avoir 3 pods, et maintenant il n'y a plus que 2 pods - j'en créerai un nouveau";StatefulSet : "Pod disparu?" J'attendrai: soit ce nœud reviendra, soit ils nous diront de le tuer ", les conteneurs eux-mêmes (sans action de l'opérateur) ne sont pas recréés. C'est ainsi que la même garantie au plus une fois est obtenue.
Cependant, ici, dans ce dernier cas, une clôture est nécessaire: nous avons besoin d'un mécanisme qui confirme que ce nœud est définitivement parti. Le rendre automatique est, d'une part, très difficile (de nombreuses implémentations sont nécessaires), et d'autre part, pire encore, il tue généralement les nœuds lentement (l'accès à IPMI peut prendre des secondes ou des dizaines de secondes, voire des minutes). Peu de gens sont satisfaits de l'attente par minute pour passer de la base au nouveau maître. Mais il existe une autre approche qui ne nécessite pas de mécanisme de clôture ...
Je vais commencer sa description en dehors de Kubernetes. Il utilise un équilibreur de charge spécial à travers lequel les backends accèdent au SGBD. Sa spécificité réside dans le fait qu'il a la propriété de la cohérence, c'est-à-dire protection contre les pannes de réseau et le split-brain, car il vous permet de supprimer toutes les connexions au maître actuel, d'attendre la synchronisation (réplique) sur un autre nœud et de basculer vers celui-ci. Je n'ai pas trouvé de terme établi pour cette approche et je l'ai appelé
Switchover cohérent .
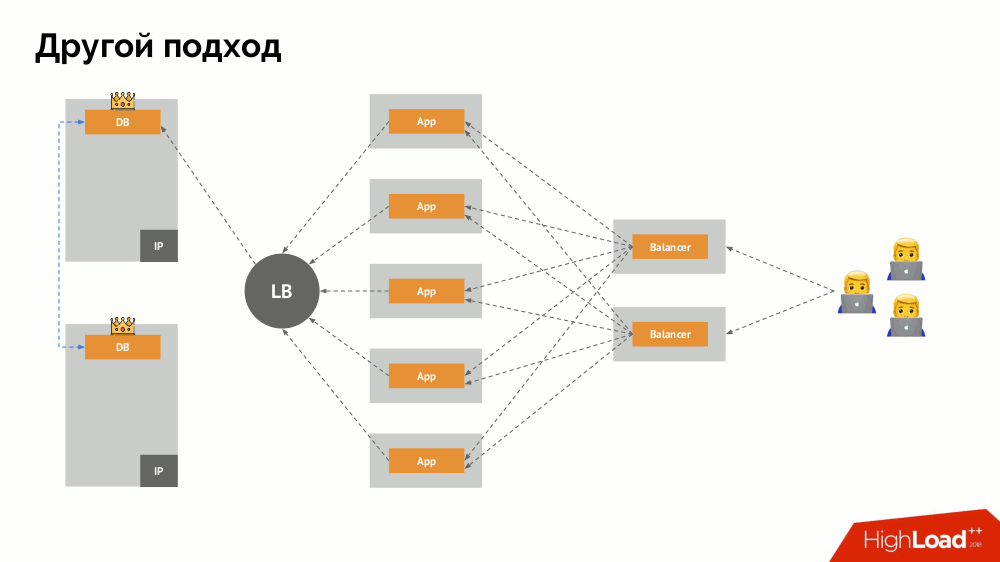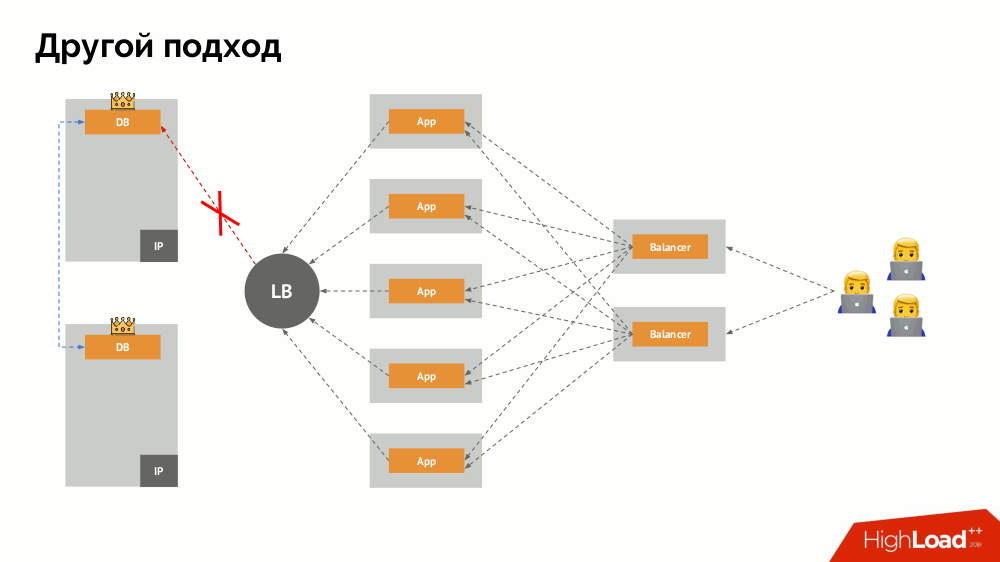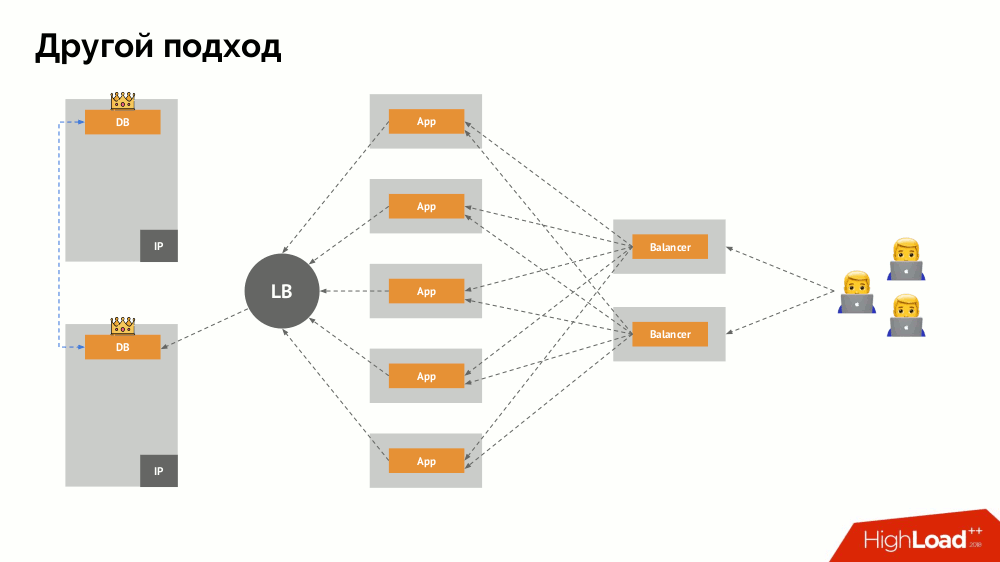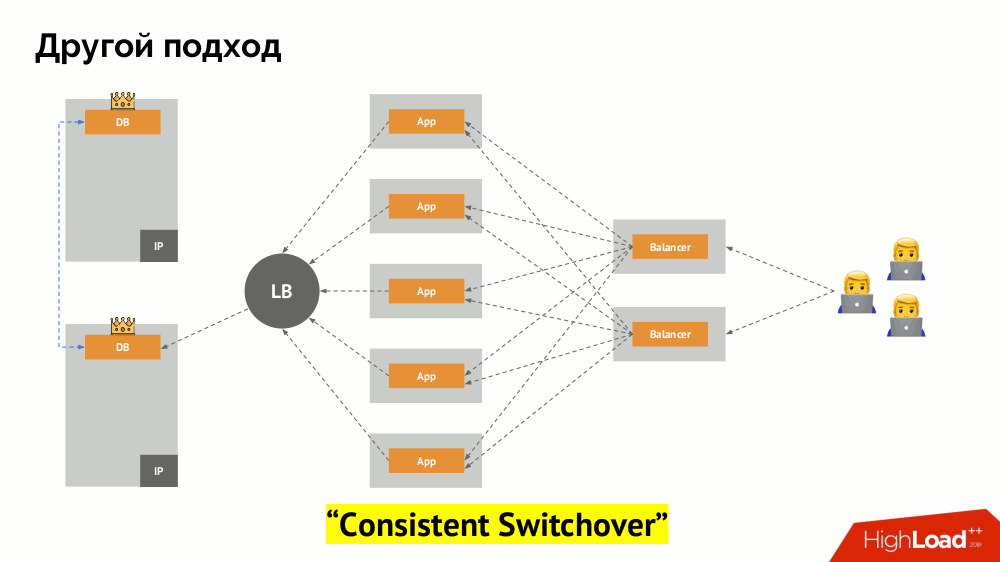
La question principale avec lui est de savoir comment la rendre universelle, en fournissant un support aux fournisseurs de cloud et aux installations privées. Pour cela, des serveurs proxy sont ajoutés aux applications. Chacun d'eux acceptera les demandes de sa candidature (et les transmettra au SGBD), et un quorum sera recueilli de chacun d'eux. Dès qu'une partie du cluster échoue, les mandataires qui ont perdu le quorum suppriment immédiatement leurs connexions au SGBD.
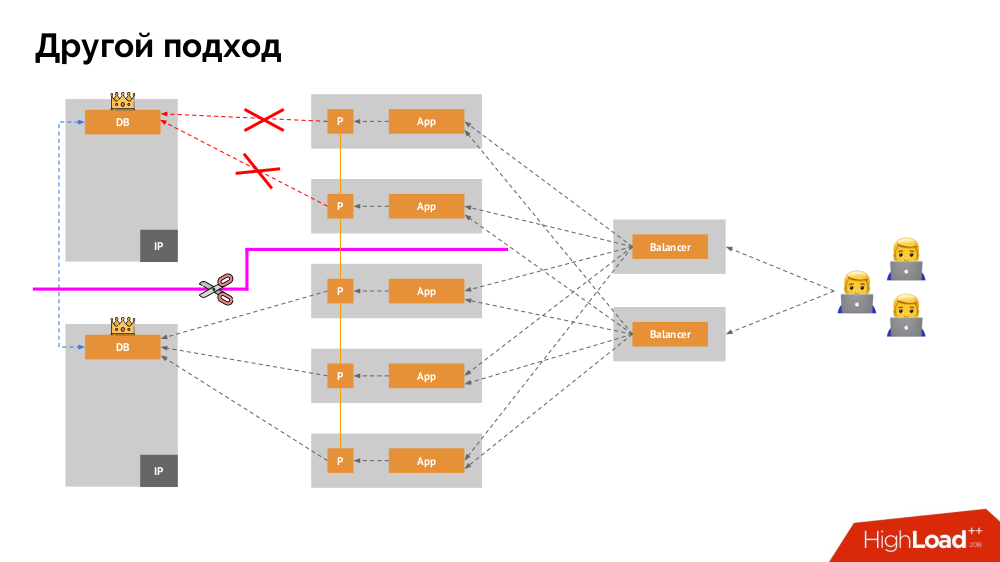
3. Stockage de données et Kubernetes
Le mécanisme principal est le lecteur réseau
Network Block Device (aka SAN) dans diverses implémentations pour les options de cloud souhaitées ou le bare metal. Cependant, le fait de mettre une base de données chargée (par exemple, MySQL, qui nécessite 50 000 IOPS) dans le cloud (AWS EBS) ne fonctionnera pas en raison de la
latence .
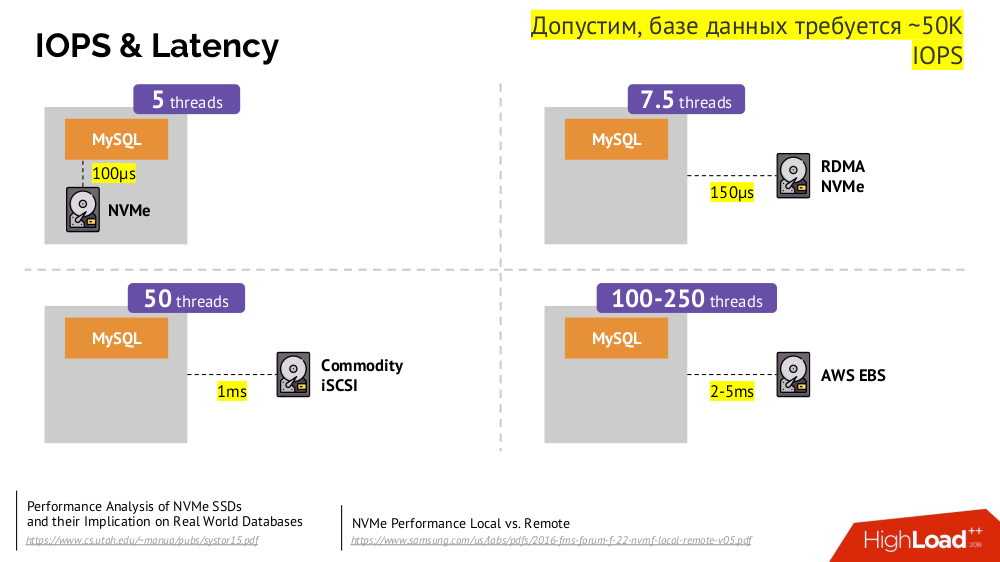
Kubernetes pour de tels cas a la capacité de connecter un disque dur
local -
Stockage local . Si une panne se produit (le disque n'est plus disponible dans le pod), nous sommes alors obligés de réparer cette machine - similaire au schéma classique en cas de panne d'un serveur fiable.
Les deux options (
Network Block Device et
Local Storage ) appartiennent à la catégorie
ReadWriteOnce : le stockage ne peut pas être monté à deux endroits (pods) - pour cette mise à l'échelle, vous devrez créer un nouveau disque et le connecter à un nouveau pod (il existe un mécanisme K8 intégré pour cela) , puis remplissez avec les données nécessaires (déjà effectuées par nos forces).
Si nous avons besoin du mode
ReadWriteMany , des implémentations
Network File System (ou NAS) sont disponibles: pour le cloud public, ce sont
AzureFile et
AWSElasticFileSystem , et pour leurs installations CephFS et Glusterfs pour les fans de systèmes distribués, ainsi que NFS.

Pratique
1. Autonome
Cette option concerne le cas où rien ne vous empêche de démarrer le SGBD en mode serveur séparé avec stockage local. Il n'est pas question de haute disponibilité ... bien qu'elle puisse être dans une certaine mesure (c'est-à-dire suffisante pour cette application) mise en œuvre au niveau du fer. Il existe de nombreux cas pour cette application. Tout d'abord, ce sont toutes sortes d'environnements de développement et de développement, mais pas seulement: les services secondaires arrivent également ici, leur désactivation pendant 15 minutes n'est pas critique. Dans Kubernetes, ceci est implémenté par
StatefulSet avec un pod:
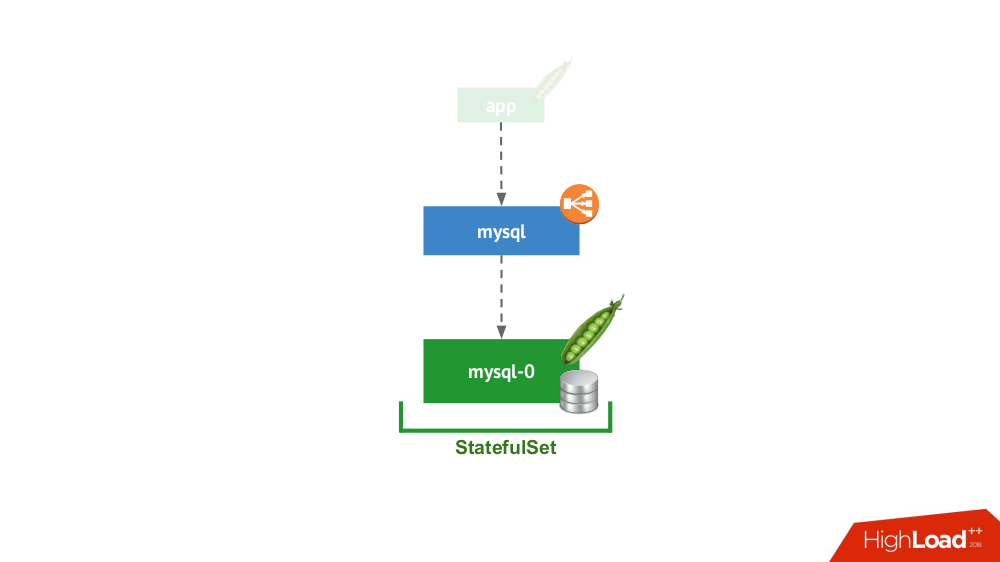
En général, c'est une option viable, qui, de mon point de vue, n'a aucun inconvénient par rapport à l'installation d'un SGBD sur une machine virtuelle distincte.
2. Paire répliquée avec commutation manuelle
StatefulSet nouveau utilisé, mais le schéma général ressemble à ceci:
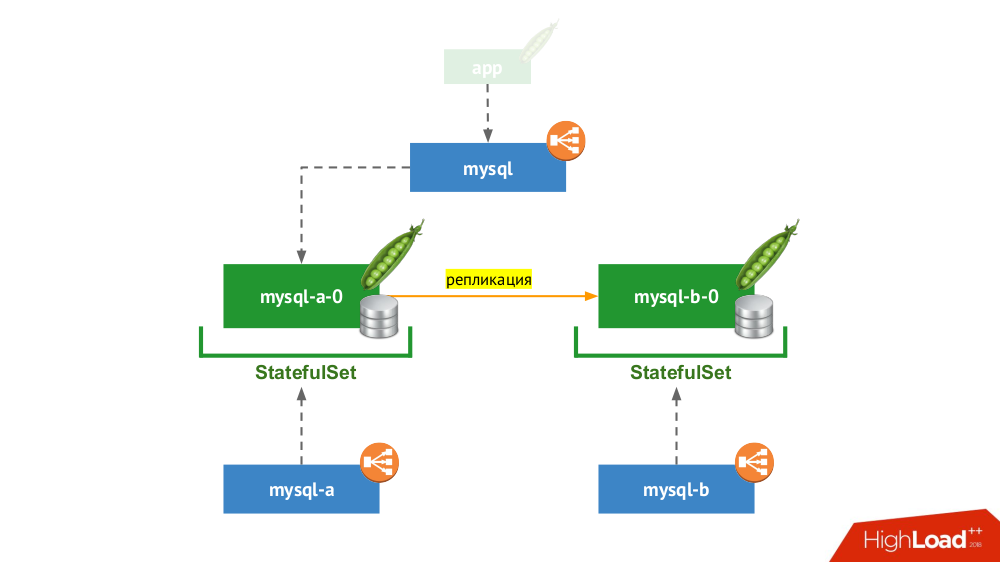
Si l'un des nœuds plante (
mysql-a-0 ), un miracle ne se produit pas, mais nous avons une réplique (
mysql-b-0 ) vers laquelle nous pouvons commuter le trafic. Dans ce cas, même avant de commuter le trafic, il est important de ne pas oublier non seulement de supprimer les requêtes SGBD du service
mysql , mais également de se connecter manuellement au SGBD et de s'assurer que toutes les connexions sont terminées (les tuer), et aussi d'aller au deuxième nœud du SGBD et reconfigurer la réplique dans la direction opposée.
Si vous utilisez actuellement la version classique avec deux serveurs (maître + veille) sans
basculement automatique, cette solution est l'équivalent dans Kubernetes. Convient pour MySQL, PostgreSQL, Redis et autres produits.
3. Mise à l'échelle de la charge de lecture
En fait, ce cas n'est pas avec état, car nous ne parlons que de lecture. Ici, le serveur SGBD principal est en dehors du schéma considéré, et dans le cadre de Kubernetes, une "batterie de serveurs esclaves" est créée, qui est en lecture seule. Le mécanisme général - l'utilisation de conteneurs init pour remplir les données du SGBD sur chaque nouveau pod de cette batterie (en utilisant un vidage à chaud ou l'habituel avec des actions supplémentaires, etc. - dépend du SGBD utilisé). Pour être sûr que chaque instance ne traîne pas trop loin du maître, vous pouvez utiliser des tests de vivacité.

4. Client intelligent
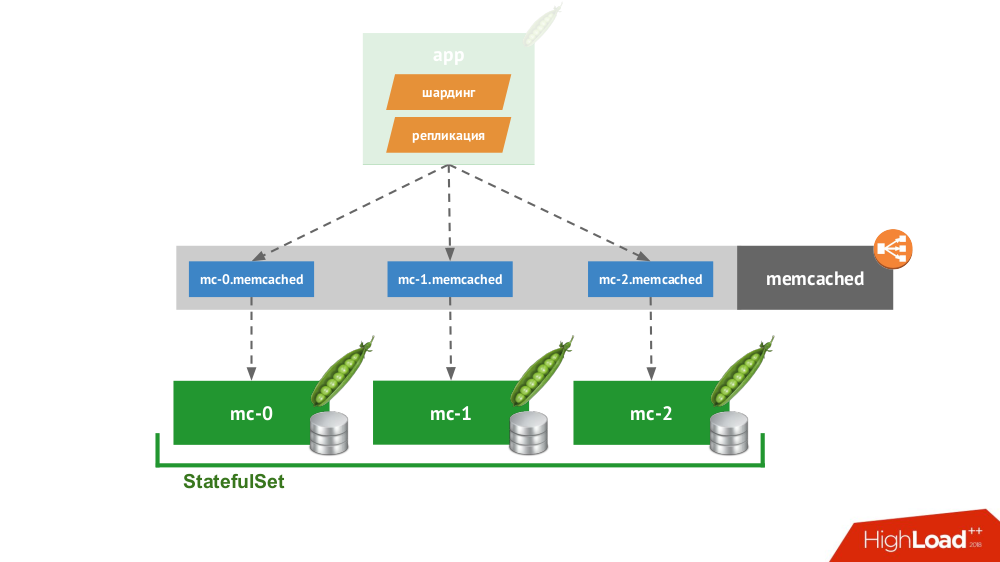
Si vous créez un
StatefulSet de trois memcaches, Kubernetes fournit un service spécial qui n'équilibrera pas les demandes, mais créera chaque pod pour son propre domaine. Le client pourra travailler avec eux s'il est lui-même capable de partitionnement et de réplication.
Vous n'avez pas besoin d'aller loin pour un exemple: voici comment le stockage de session fonctionne en PHP. Pour chaque demande de session, des demandes sont faites simultanément à tous les serveurs, après quoi la réponse la plus pertinente est sélectionnée parmi eux (de manière similaire à un enregistrement).
5. Solutions natives cloud
Il existe de nombreuses solutions qui sont initialement axées sur la défaillance des nœuds, c'est-à-dire eux-mêmes peuvent effectuer le
basculement et la récupération des nœuds, fournir des garanties de
cohérence . Ce n'est pas une liste complète d'entre eux, mais seulement une partie d'exemples populaires:

Tous sont simplement placés dans
StatefulSet , après quoi les nœuds se retrouvent et forment un cluster. Les produits eux-mêmes diffèrent dans la façon dont ils mettent en œuvre trois choses:
- Comment les nœuds apprennent-ils les uns des autres? Il existe des méthodes telles que l'API Kubernetes, les enregistrements DNS, la configuration statique, les nœuds spécialisés (semences), la découverte de services tiers ...
- Comment le client se connecte-t-il? Grâce à un équilibreur de charge qui distribue aux hôtes, ou le client doit connaître tous les hôtes, et il décidera de la marche à suivre.
- Comment s'effectue la mise à l'échelle horizontale? Pas du tout, complet ou difficile / avec restrictions.
Quelles que soient les solutions choisies à ces problèmes, tous ces produits fonctionnent bien avec Kubernetes, car ils ont été créés à l'origine en tant que «troupeau»
(bovins) .
6. Stolon PostgreSQL
Stolon vous permet en fait de transformer PostgreSQL, créé comme
animal de
compagnie , en
bétail . Comment y parvient-on?
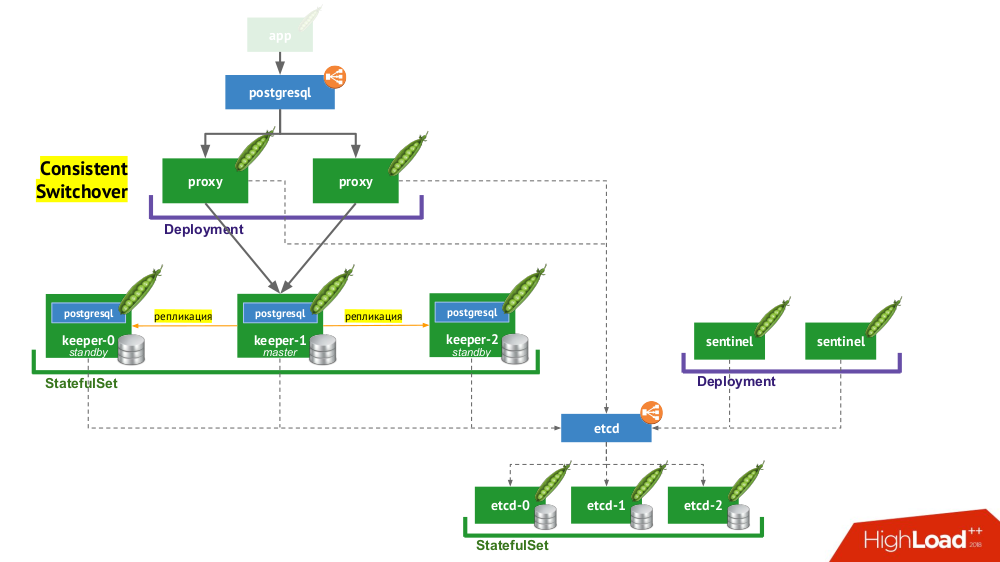
- Tout d'abord, nous avons besoin d'une découverte de service, dans le rôle de laquelle peut être etcd (d'autres options sont disponibles) - un cluster d'entre eux est placé dans un
StatefulSet . - Une autre partie de l'infrastructure est
StatefulSet avec des instances PostgreSQL. En plus du SGBD proprement dit, à côté de chaque installation se trouve également un composant appelé keeper , qui effectue la configuration du SGBD. - Un autre composant, sentinelle, est déployé en tant que
Deployment et surveille la configuration du cluster. C'est lui qui décide qui sera maître et veille, écrit ces informations sur etcd. Et le gardien lit les données de etcd et effectue des actions correspondant à l'état actuel avec une instance de PostgreSQL. - Un autre composant déployé dans le
Deployment et face aux instances PostgreSQL, le proxy, est une implémentation du modèle de basculement cohérent déjà mentionné. Ces composants sont connectés à etcd, et si cette connexion est perdue, le proxy tue immédiatement les connexions sortantes, car à partir de ce moment il ne connaît pas le rôle de son serveur (est-ce maintenant maître ou standby?). - Enfin, les instances proxy font face à l'habituel
LoadBalancer Kubernetes.
Conclusions
Est-il donc possible de s'installer à Kubernetes? Oui, bien sûr, c'est possible, dans certains cas ... Et si c'est approprié, c'est fait comme ça (voir le workflow Stolon) ...
Tout le monde sait que la technologie évolue par vagues. Au départ, tout nouvel appareil peut être très difficile à utiliser, mais au fil du temps, tout change: la technologie devient disponible. Où allons-nous? Oui, cela restera ainsi à l'intérieur, mais nous ne saurons pas comment cela fonctionnera. Kubernetes développe activement des
opérateurs . Jusqu'à présent, il n'y en a pas beaucoup et ils ne sont pas si bons, mais il y a un mouvement dans cette direction.
Vidéos et diapositives
Vidéo de la performance (environ une heure):
Présentation du rapport:
PS Nous avons également trouvé sur le net une très (!) Courte
compression textuelle de ce rapport - merci à Nikolai Volynkin.
PPS
Autres reportages sur notre blog:
Vous pourriez également être intéressé par les publications suivantes: