Imaginez: un appel téléphonique à trois heures du matin, vous décrochez le téléphone et entendez un cri que personne d'autre n'utilise votre produit. Effrayant Dans la vie, bien sûr, ce n'est pas le cas, mais si vous ne prêtez pas l'attention voulue au problème de la sortie des utilisateurs, vous pouvez vous retrouver dans une situation similaire.
Nous avons déjà décrit en détail ce qu'est un flux sortant: nous nous sommes plongés dans la théorie et avons montré comment transformer un réseau neuronal en un oracle numérique. Les experts de Plarium Krasnodar connaissent une autre façon de prédire. Nous allons parler de lui.

Ce n'est pas le RFM dont nous avons besoin.
RFM est une méthode utilisée pour segmenter les clients et analyser leur comportement. Sur la base des données obtenues, vous pouvez créer un programme de fidélité pour chaque groupe, construire une répartition des utilisateurs et prévoir quand ils reviendront pour les achats.
L'histoire du développement RFM a commencé en 1987 lorsque l'article
Counting Your Customers: Who Are They and What Will They Do Next a été publié. Il a décrit une méthode d'analyse basée sur la distribution de Pareto (une famille à deux paramètres de distributions absolument continues).
Le modèle s'appelait Pareto / NBD et ne prenait en compte que l'historique d'achat des utilisateurs. Dans l'interprétation classique, le travail de cette méthode a été construit sur cinq piliers, ou approximations:
- Tant que les utilisateurs sont actifs, le nombre de transactions effectuées par l'acheteur au cours de la période t obéit à la distribution de Pareto avec un λt moyen.
- L'hétérogénéité du paramètre λ (taux de transaction) suit une distribution gamma avec les paramètres r et α.
- Chaque acheteur a une durée de vie illimitée τ. Le point auquel l'utilisateur devient inactif est distribué de façon exponentielle avec le paramètre μ (taux de décrochage).
- L'hétérogénéité du paramètre μ parmi les utilisateurs suit une distribution gamma avec les paramètres s (forme) et β (échelle).
- Les paramètres λ et μ peuvent varier indépendamment d'un acheteur à l'autre.
Les inconvénients de ce modèle étaient à la fois la grande complexité du calcul des fonctions hypergéométriques de Gauss et la recherche de la fonction de vraisemblance maximale.
Dans un article de 2003,
«Compter vos clients», Easy Way: une alternative au modèle Pareto / NBD , l'idée de mettre en œuvre un meilleur modèle a été publiée. En plus de l'historique des achats, deux paramètres supplémentaires ont été utilisés: la fréquence et la prescription. Sa principale différence avec Pareto / NBD était la façon dont le moment du départ du client est déterminé.
Dans le cadre classique, on a supposé que l'utilisateur était en mesure de partir à tout moment, quelles que soient la fréquence et le schéma de ses achats dans le passé. La nouvelle approche est basée sur l'hypothèse que l'acheteur pourrait commencer à perdre de l'intérêt immédiatement après la conclusion de la transaction.
Cela a simplifié le calcul et conduit au modèle bêta-géométrique (BG / NBD). Il utilise trois paramètres principaux: récence, fréquence, monétaire, - ainsi que quatre paramètres supplémentaires: r, α, a, b (les paramètres a et b ont été ajoutés à partir de la
distribution bêta ).
RFM permet de prévoir si un client effectuera un achat à l'avenir. Les spécialistes du Plarium Krasnodar ont modifié cette méthode.
Prédisez l'écoulement simplement et avec goût
Pour les calculs, nous avons besoin d'un tableau de données sur les sessions de jeu. Il est recalculé en une matrice composée de paramètres RFM et en quatre coefficients supplémentaires, qui sont sélectionnés par le modèle dans le processus d'apprentissage.
Dans le cadre d'un jeu, les paramètres acquièrent les significations suivantes:
- R ecency - combien de temps l'utilisateur jouait au moment de la dernière connexion;
- F requency - la fréquence à laquelle l'utilisateur a réintégré le jeu;
- M onétaire - depuis combien de temps l'utilisateur joue (durée de vie).
Les paramètres sont agrégés dans une matrice. Ensuite, il est chargé dans un modèle qui calcule la probabilité de «vie» des utilisateurs - la chance qu'ils continueront à jouer.
Les calculs sont effectués selon la formule:
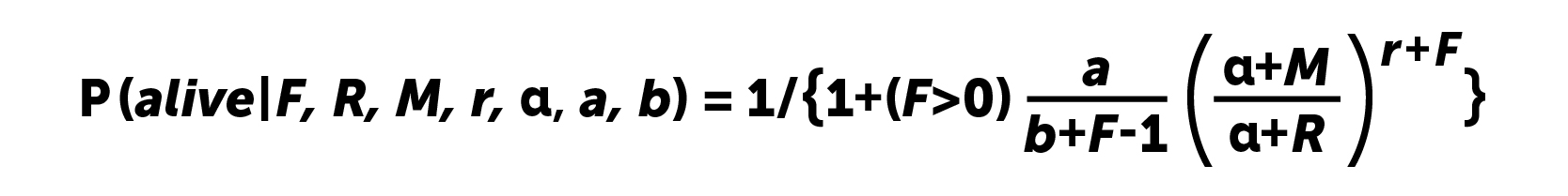
De toute évidence, pour les utilisateurs sans rentrées, la probabilité de «vie» sera de un. En 2008, les auteurs de l'article
Computing P (vivant) utilisant le modèle BG / NBD ont proposé une solution à ce problème. Les sociétés de jeux peuvent utiliser deux options qui donnent des résultats similaires.
Méthode 1 - Le paramètre π est entré pour tous les utilisateurs. Il montre quels joueurs sont considérés comme inactifs.
Méthode 2 - une unité est ajoutée au paramètre Frequency. Cette mesure évite la dégénérescence de la formule à Frequency = 0, mais ajoute artificiellement une entrée de plus dans le jeu pour chaque utilisateur.
Comment adapter la méthode RFM pour le développement de jeux
Supposons que nous ayons un nouvel utilisateur. Il vient d'entrer dans le match. Paramètre
F = 1 (ou 0, selon les calculs), car la première entrée n'est pas prise en compte et le joueur n'a pas encore eu d'entrées répétées.
L'utilisateur joue trois jours. Les paramètres changent:
F ne prend en compte que les entrées journalières, donc sa valeur est 2, et les indicateurs
M et
R sont 3. En utilisant ces données, nous obtenons une probabilité de "vie" proche de l'unité.
Le lendemain, l'utilisateur n'entre pas dans le jeu. Le paramètre
M est mis à jour, tandis que
F et
R restent les mêmes. En remplaçant toutes les valeurs de la formule, nous voyons que l'indicateur de probabilité est devenu plus bas.
Si l'utilisateur ne joue pas pendant la semaine, alors l'indicateur
M est à nouveau mis à jour et la probabilité de «vie» diminue encore plus.
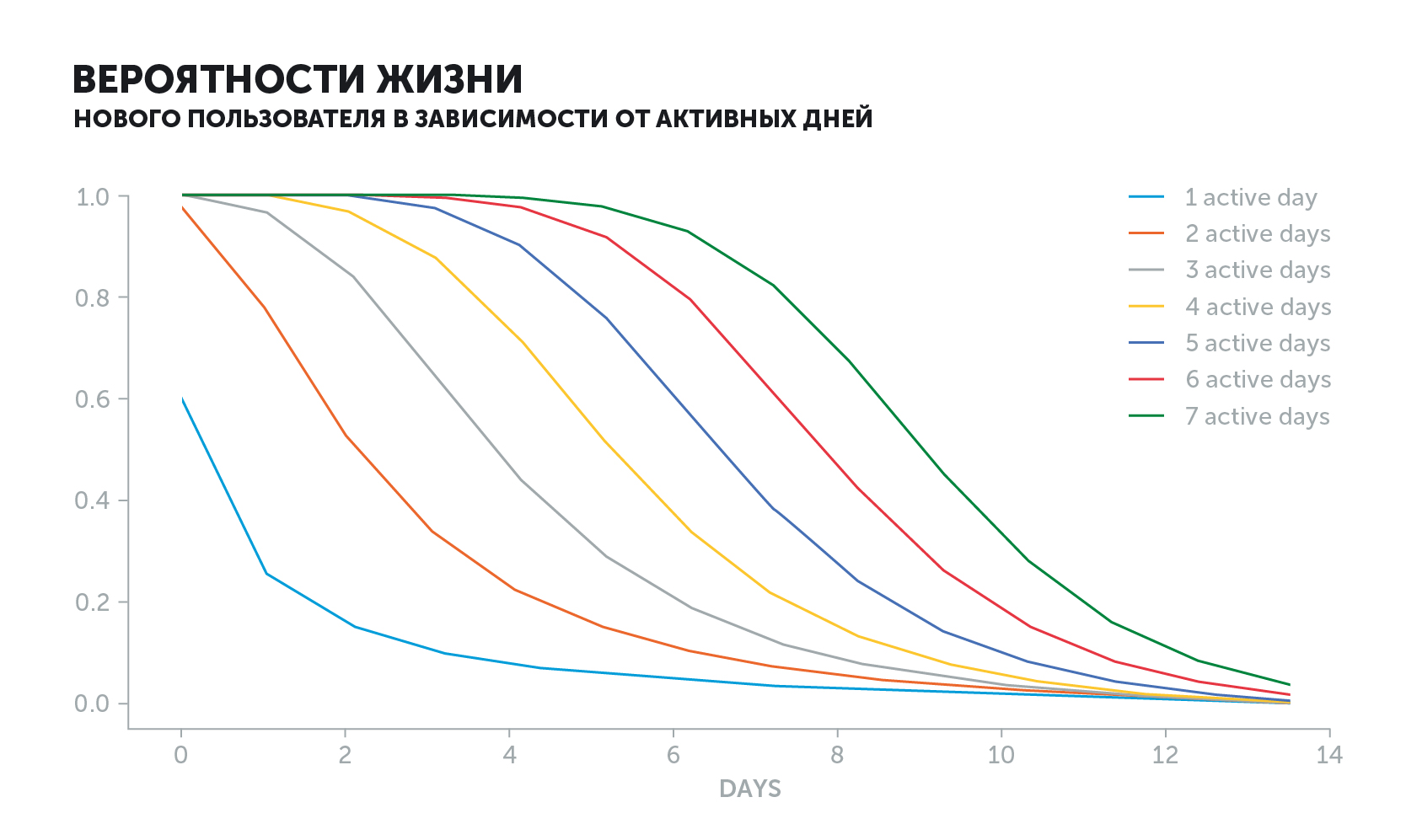
Le graphique de l'utilisateur actif est différent. La probabilité d'une "vie" diminuera en fonction de son histoire. S'il entrait dans le jeu tous les jours et s'arrêtait soudainement, la valeur de l'indicateur chuterait beaucoup plus rapidement que s'il jouait tous les deux jours.

Avantages et inconvénients importants de RFM
Le principal avantage de cette méthode est sa simplicité:
- pour les calculs, vous n'avez pas besoin d'utiliser un appareil mathématique complexe;
- les indicateurs sont calculés à l'aide d'une formule relativement simple;
- Vous pouvez vous passer de pipelines complexes pour les données;
- tous les paramètres optimaux du modèle sont sélectionnés automatiquement.
De plus, les données RFM sont faciles à interpréter. En étudiant l'histoire de l'utilisateur, on peut comprendre pourquoi il a une telle probabilité de "vie". Souvent, lorsque vous travaillez avec des méthodes plus complexes, il est plus difficile de tirer des conclusions spécifiques.
RFM présente également des inconvénients.
Premièrement , ce n'est pas la méthode la plus précise. Cela fonctionne bien, mais un certain nombre de paramètres ne sont pas utilisés dans les calculs. Par exemple, de nombreux utilisateurs qui commencent à se désintéresser par habitude entrent dans le jeu. Autrement dit, le nombre moyen de sessions de jeu par jour diminue et la fréquence des réinscriptions ne change pas.
Deuxièmement , la méthode ne prend pas en compte l'activité de l'utilisateur: combien de ressources il a transférées, qu'il ait attaqué l'ennemi ou créé des troupes. Si l'on prend tous les joueurs avec une probabilité de "vie" égale à ~ 0,8, alors en fonction des paramètres et de leur historique, en plus des actifs, il y aura ceux qui entrent tous les trois jours.
Troisièmement , l'utilisateur disparu devient «vivant» lorsqu'il recommence le jeu. Que doit-il faire un mois après la dernière connexion? De telles situations compliquent la détection des joueurs avec de grandes pauses entre les sessions. En général, ce n'est pas critique, même si cela introduit un certain déséquilibre lorsque nous essayons de comprendre si l'utilisateur est «vivant» ou non.
N'est-il pas préférable d'utiliser un réseau de neurones?
Mieux, mais tout d'abord, vous devez comprendre comment mettre en œuvre le projet: résoudre des tâches à grande échelle en un clin d'œil ou progresser progressivement vers l'objectif.
L'analyse RFM montre la probabilité de «vie» de l'utilisateur au moment du calcul. Nous ne pourrons pas comprendre si le joueur partira dans deux ou trois semaines, et le réseau de neurones le pourra. Compte tenu de l'ensemble de l'infrastructure, la création d'un tel système intégré pour analyser le comportement des joueurs à partir de zéro est beaucoup plus difficile. De plus, vous avez besoin d'une ligne de base avec laquelle vous pouvez comparer la qualité du réseau neuronal. Une telle approche est susceptible d'entraîner des pertes financières si vous ne calculez pas la force.
Notre expérience montre que les tâches globales doivent être mises en œuvre progressivement. La création d'un prototype fonctionnel n'est pas difficile, mais la collecte et le traitement des données, la mise en place et la formation d'un réseau de neurones sont une autre affaire. Ces processus peuvent durer longtemps, ce qui fait toujours défaut.
C'est pourquoi nous avons décidé d'utiliser d'abord un modèle plus simple: nous avons mené des recherches, identifié les avantages et les inconvénients, et testé en travail. Les résultats nous convenaient. RFM a des défauts, mais ils sont généreusement compensés par la facilité d'utilisation. Et le réseau neuronal est la prochaine étape vers l'amélioration du système.