Ceph est un stockage d'objets conçu pour aider à créer un cluster de basculement. Pourtant, des échecs se produisent. Tous ceux qui travaillent avec Ceph connaissent la légende de CloudMouse ou Rosreestr. Malheureusement, il n'est pas habituel de partager avec nous une expérience négative, les causes des échecs sont le plus souvent étouffées et ne permettent pas aux générations futures d'apprendre des erreurs des autres.
Eh bien, mettons en place un cluster de test, mais proche du vrai, et analysons la catastrophe par os. Nous mesurerons tous les baisses de performances, trouverons les fuites de mémoire et analyserons le processus de récupération du service. Et tout cela sous la direction d'Artemy Kapitula, qui a passé près d'un an à étudier les pièges, a fait échouer les performances du cluster à zéro et la latence ne pas atteindre des valeurs indécentes. Et j'ai un graphique rouge, ce qui est bien mieux.
Ensuite, vous trouverez une version vidéo et texte de l'un des meilleurs rapports de
DevOpsConf Russia 2018.
À propos du conférencier: Artemy Kapitula architecte système RCNTEC. La société propose des solutions de téléphonie IP (collaboration, organisation d'un bureau à distance, systèmes de stockage définis par logiciel et systèmes de gestion / distribution d'énergie). L'entreprise travaille principalement dans le secteur des entreprises, elle n'est donc pas très connue sur le marché DevOps. Néanmoins, une certaine expérience a été accumulée avec Ceph, qui dans de nombreux projets est utilisé comme élément de base de l'infrastructure de stockage.
Ceph est un référentiel défini par logiciel avec de nombreux composants logiciels.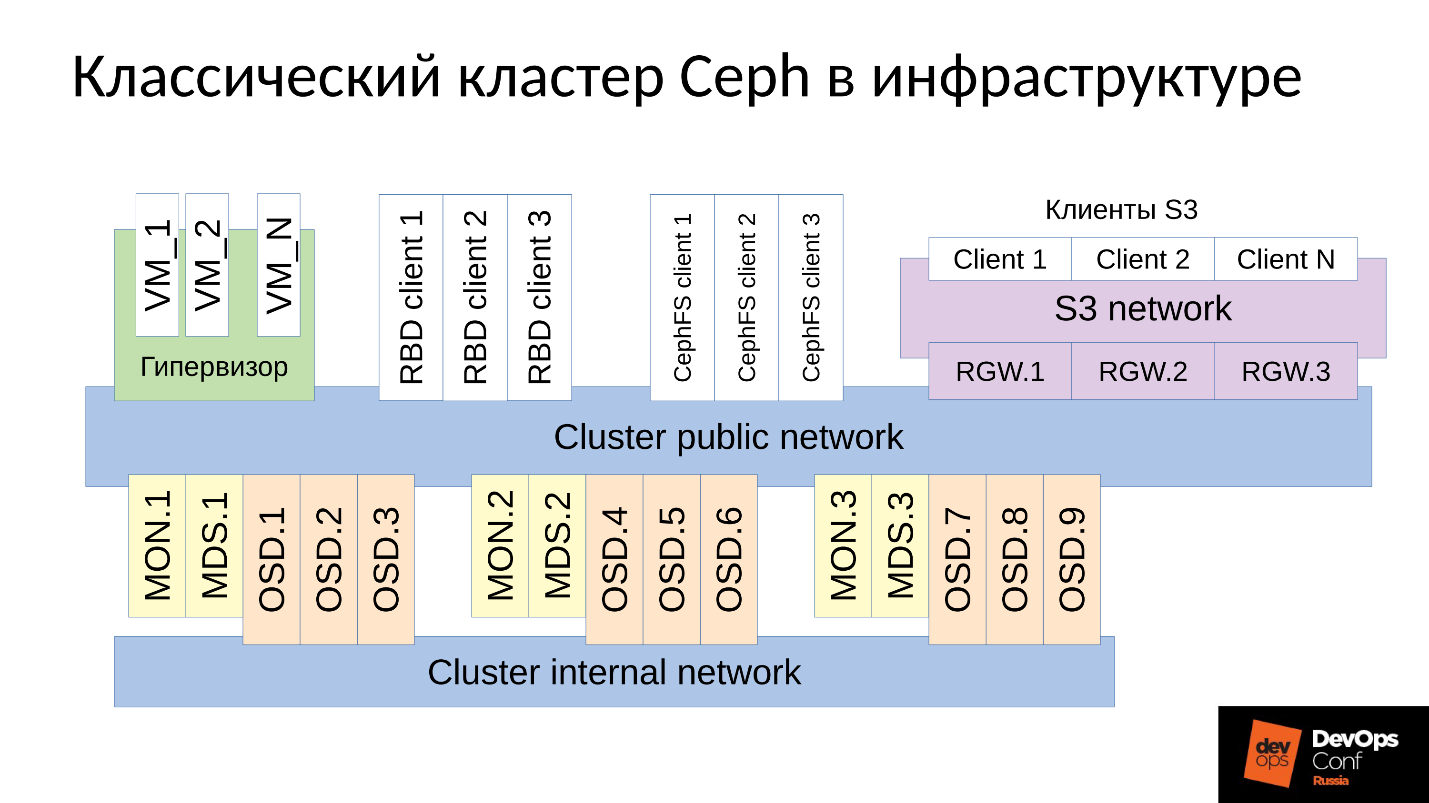
Dans le diagramme:
- Le niveau supérieur est le réseau de cluster interne par lequel le cluster lui-même communique;
- Le niveau inférieur - en fait Ceph - est un ensemble de démons internes de Ceph (MON, MDS et OSD) qui stockent les données.
En règle générale, toutes les données sont répliquées. Dans le diagramme, j'ai délibérément sélectionné trois groupes, chacun avec trois OSD, et chacun de ces groupes contient généralement une réplique de données. En conséquence, les données sont stockées en trois copies.
Un réseau de cluster de niveau supérieur est le réseau par lequel les clients Ceph accèdent aux données. Grâce à lui, les clients communiquent avec le moniteur, avec MDS (qui en a besoin) et avec OSD. Chaque client fonctionne avec chaque OSD et avec chaque moniteur indépendamment. Par conséquent, le
système est dépourvu d'un seul point de défaillance , ce qui est très agréable.
Les clients
● Clients S3
S3 est une API pour HTTP. Les clients S3 fonctionnent via HTTP et se connectent aux composants Ceph Rados Gateway (RGW). Ils communiquent presque toujours avec un composant via un réseau dédié. Ce réseau (je l'ai appelé réseau S3) utilise uniquement HTTP, les exceptions sont rares.
● Hyperviseur avec machines virtuelles
Ce groupe de clients est souvent utilisé. Ils travaillent avec des moniteurs et avec OSD, d'où ils reçoivent des informations générales sur l'état du cluster et la distribution des données. Pour les données, ces clients accèdent directement aux démons OSD via le réseau public du cluster.
● Clients RBD
Il existe également des hôtes physiques de métaux BR, qui sont généralement Linux. Ce sont des clients RBD et accèdent aux images stockées dans un cluster Ceph (images de disque de machine virtuelle).
● Clients CephFS
Le quatrième groupe de clients, qui ne sont pas encore nombreux mais qui suscitent un intérêt croissant, sont les clients du système de fichiers de cluster CephFS. Le système de cluster CephFS peut être monté simultanément à partir de nombreux nœuds, et tous les nœuds ont accès aux mêmes données, en travaillant avec chaque OSD. Autrement dit, il n'y a pas de passerelles en tant que telles (Samba, NFS et autres). Le problème est qu'un tel client ne peut être que Linux et une version assez moderne.

Notre entreprise travaille sur le marché des entreprises, et là, la balle est dirigée par ESXi, HyperV et autres. En conséquence, le cluster Ceph, qui est en quelque sorte utilisé dans le secteur des entreprises, est nécessaire pour soutenir les techniques appropriées. Ce n'était pas suffisant pour nous à Ceph, nous avons donc dû affiner et étendre le cluster Ceph avec nos composants, en fait construire quelque chose de plus que Ceph, notre propre plate-forme de stockage de données.
De plus, les clients du secteur des entreprises ne sont pas sous Linux, mais la plupart d'entre eux Windows, parfois Mac OS, ne peuvent pas accéder au cluster Ceph eux-mêmes. Ils doivent passer par une sorte de passerelles, qui dans ce cas deviennent des goulots d'étranglement.
Nous avons dû ajouter tous ces composants et nous avons obtenu un cluster légèrement plus large.

Nous avons deux composants centraux: le
groupe SCSI Gateways , qui permet d'accéder aux données d'un cluster Ceph via FibreChannel ou iSCSI. Ces composants sont utilisés pour connecter HyperV et ESXi à un cluster Ceph. Les clients PROXMOX travaillent toujours à leur manière - via RBD.
Nous ne laissons pas les clients de fichiers directement dans le réseau de cluster; plusieurs passerelles tolérantes aux pannes leur sont allouées. Chaque passerelle permet d'accéder au système de cluster de fichiers via NFS, AFP ou SMB. En conséquence, presque tous les clients, que ce soit Linux, FreeBSD ou non seulement un client, un serveur (OS X, Windows), ont accès à CephFS.
Pour gérer tout cela, nous avons dû développer notre propre orchestre Ceph et tous nos composants, qui y sont nombreux. Mais en parler maintenant n'a aucun sens, car c'est notre développement. La plupart seront probablement intéressés par le Ceph «nu» lui-même.
Ceph est beaucoup utilisé là où, et parfois des pannes se produisent. Certes, tous ceux qui travaillent avec Ceph connaissent la légende de CloudMouse. C'est une terrible légende urbaine, mais tout n'est pas si mal qu'il n'y paraît. Il y a un nouveau conte de fées sur Rosreestr. Ceph tournait partout, et partout il échouait. Quelque part, cela s'est terminé fatalement, quelque part a réussi à éliminer rapidement les conséquences.
Malheureusement, il n'est pas habituel pour nous de partager des expériences négatives, tout le monde essaie de cacher les informations pertinentes. Les entreprises étrangères sont un peu plus ouvertes, en particulier, DigitalOcean (un fournisseur bien connu qui distribue des machines virtuelles) a également subi une défaillance Ceph pendant presque une journée, c'était le 1er avril - une journée merveilleuse! Ils ont publié certains des rapports, un court journal ci-dessous.

Les problèmes ont commencé à 7 heures du matin, à 11 heures, ils ont compris ce qui se passait et ont commencé à éliminer l'échec. Pour ce faire, ils ont alloué deux commandes: l'une pour une raison quelconque a parcouru les serveurs et y a installé de la mémoire, et la seconde pour une raison quelconque a démarré manuellement un serveur après l'autre et surveillé attentivement tous les serveurs. Pourquoi? Nous sommes tous habitués à tout allumé en un seul clic.
Que se passe-t-il fondamentalement dans un système distribué lorsqu'il est effectivement construit et fonctionne presque à la limite de ses capacités?Pour répondre à cette question, nous devons examiner comment fonctionne le cluster Ceph et comment la panne se produit.

Scénario d'échec de Ceph
Au début, le cluster fonctionne bien, tout va bien. Ensuite, quelque chose se produit, après quoi les démons OSD, où les données sont stockées, perdent le contact avec les composants centraux du cluster (moniteurs). À ce stade, un délai d'attente se produit et l'ensemble du cluster obtient un enjeu. Le cluster reste un moment jusqu'à ce qu'il se rende compte que quelque chose ne va pas avec lui, et ensuite il corrige ses connaissances internes. Après cela, le service client est restauré dans une certaine mesure et le cluster fonctionne à nouveau en mode dégradé. Et le plus drôle, c'est que cela fonctionne plus rapidement qu'en mode normal - c'est un fait étonnant.
Ensuite, nous éliminons l'échec. Supposons que nous perdions de l'énergie, le rack a été complètement coupé. Les électriciens sont venus en courant, ils ont tous restauré, ils ont fourni l'électricité, les serveurs allumés et
le plaisir commence .
Tout le monde est habitué au fait que lorsqu'un serveur tombe en panne, tout devient mauvais, et lorsque nous allumons le serveur, tout devient bon. Tout est complètement faux ici.
Le cluster s'arrête pratiquement, effectue la synchronisation principale, puis commence une récupération douce et lente, revenant progressivement au mode normal.

Ci-dessus, un graphique des performances du cluster Ceph au fur et à mesure de la défaillance. Veuillez noter qu'ici, les intervalles dont nous avons parlé sont tracés très clairement:
- Fonctionnement normal jusqu'à environ 70 secondes;
- Échec d'une minute à environ 130 secondes;
- Un plateau nettement supérieur au fonctionnement normal est l'œuvre de clusters dégradés;
- Ensuite, nous activons le nœud manquant - il s'agit d'un cluster de formation, il n'y a que 3 serveurs et 15 SSD. Nous démarrons le serveur quelque part environ 260 secondes.
- Le serveur s'est allumé, est entré dans le cluster - IOPS'y est tombé.
Essayons de comprendre ce qui s'est réellement passé là-bas. La première chose qui nous intéresse est une baisse au tout début du graphique.
Échec de l'OSD
Prenons un exemple de cluster avec trois racks, plusieurs nœuds dans chacun. Si le rack gauche tombe en panne, tous les démons OSD (pas les hôtes!) Se pinglent avec des messages Ceph à un certain intervalle. En cas de perte de plusieurs messages, un message est envoyé au moniteur: "Je, OSD tel ou tel, ne peux pas atteindre l'OSD tel ou tel."

Dans ce cas, les messages sont généralement regroupés par hôtes, c'est-à-dire que si deux messages provenant d'OSD différents arrivent sur le même hôte, ils sont combinés en un seul message. Par conséquent, si l'OSD 11 et l'OSD 12 indiquent qu'ils ne peuvent pas atteindre l'OSD 1, cela sera interprété comme l'hôte 11 se plaignant de l'OSD 1. Lorsque l'OSD 21 et l'OSD 22 ont été signalés, il est interprété comme l'hôte 21 insatisfait de l'OSD 1 Après quoi le moniteur considère que l'OSD 1 est à l'état bas et informe tous les membres du cluster (en changeant la carte OSD), le travail se poursuit en mode dégradé.
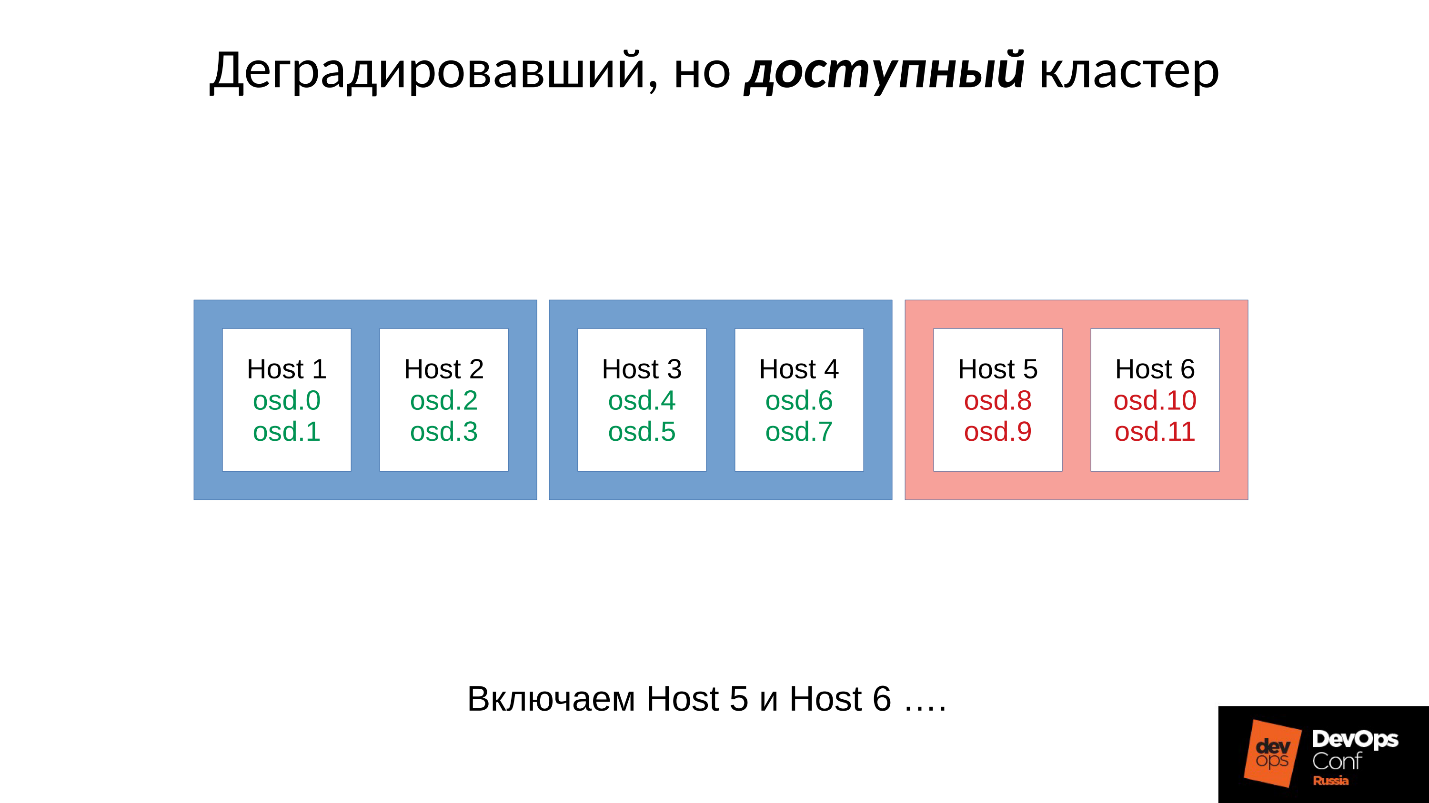
Voici donc notre cluster et notre rack défaillant (hôte 5 et hôte 6). Nous activons l'hôte 5 et l'hôte 6, au fur et à mesure que la puissance est apparue, et ...
Comportement interne de Ceph
Et maintenant, la partie la plus intéressante est que nous commençons la
synchronisation initiale des données . Comme il existe de nombreuses répliques, elles doivent être synchrones et être dans la même version. En cours de démarrage du démarrage OSD:
- OSD lit les versions disponibles, l'historique disponible (pg_log - pour déterminer les versions actuelles des objets).
- Après quoi, il détermine sur quel OSD les dernières versions des objets dégradés (missing_loc) sont activées et lesquelles sont derrière.
- Lorsque les versions antérieures sont stockées, une synchronisation est nécessaire et de nouvelles versions peuvent être utilisées comme référence pour lire et écrire des données.
Une histoire est utilisée qui est collectée à partir de tous les OSD, et cette histoire peut être beaucoup; l'emplacement réel de l'ensemble d'objets dans le cluster où se trouvent les versions correspondantes est déterminé. Combien d'objets sont dans le cluster, combien d'enregistrements sont obtenus, si le cluster est resté longtemps en mode dégradé, alors l'histoire est longue.
À titre de comparaison: la taille typique d'un objet lorsque nous travaillons avec une image RBD est de 4 Mo. Lorsque nous travaillons en effacement codé - 1 Mo. Si nous avons un disque de 10 To, nous obtenons un million d'objets mégaoctets sur le disque. Si nous avons 10 disques sur le serveur, alors il y a déjà 10 millions d'objets, s'il y a 32 disques (nous construisons un cluster efficace, nous avons une allocation serrée), alors 32 millions d'objets doivent être conservés en mémoire. De plus, en fait, les informations sur chaque objet sont stockées en plusieurs copies, car chaque copie indique qu'à cet endroit, elle se trouve dans cette version, et dans celle-ci - dans celle-ci.
Il s'avère qu'une énorme quantité de données, qui se trouve dans la RAM:
- plus il y a d'objets, plus l'histoire de missing_loc est grande;
- plus PG - plus pg_log et carte OSD;
en plus:
- plus la taille du disque est grande;
- plus la densité est élevée (le nombre de disques dans chaque serveur);
- plus la charge sur le cluster est élevée et plus votre cluster est rapide;
- plus l'OSD est arrêté (en mode hors ligne);
en d'autres termes,
plus le cluster que nous avons construit est raide et plus la partie du cluster ne répond plus, plus il faudra de RAM au démarrage .
Les optimisations extrêmes sont à l'origine de tout mal
"... et le MOO noir vient aux mauvais garçons et filles la nuit et tue tous les processus à gauche et à droite"
Légende du sysadmin de la ville
Ainsi, la RAM nécessite beaucoup, la consommation de mémoire augmente (nous avons commencé tout de suite dans un tiers du cluster) et le système peut en théorie passer en SWAP, si vous l'avez créé bien sûr. Je pense que beaucoup de gens pensent que SWAP est mauvais et qu’ils ne le créent pas: «Pourquoi? Nous avons beaucoup de mémoire! » Mais ce n'est pas la bonne approche.
Si le fichier SWAP n'a pas été créé à l'avance, car il a été décidé que Linux fonctionnerait plus efficacement, tôt ou tard, cela se produirait par manque de mémoire (OOM-killer). Et pas le fait qu'il tue celui qui a mangé toute la mémoire, non celui qui a été le premier malchanceux. Nous savons ce qu'est un endroit optimiste - nous demandons un souvenir, ils nous le promettent, nous disons: "Maintenant, donnez-nous-en un", en réponse: "Mais non!" - et tueur de mémoire.
Il s'agit d'un travail Linux normal, sauf s'il est configuré dans la zone de mémoire virtuelle.
Le processus sort du tueur de mémoire et tombe rapidement et sans pitié. De plus, aucun autre processus qu'il est décédé ne sait. Il n'a pas eu le temps d'informer quiconque de quoi que ce soit, ils l'ont simplement licencié.
Ensuite, bien sûr, le processus va redémarrer - nous avons systemd, il lance également, si nécessaire, les OSD qui sont tombés. Les OSD tombés commencent et ... une réaction en chaîne commence.
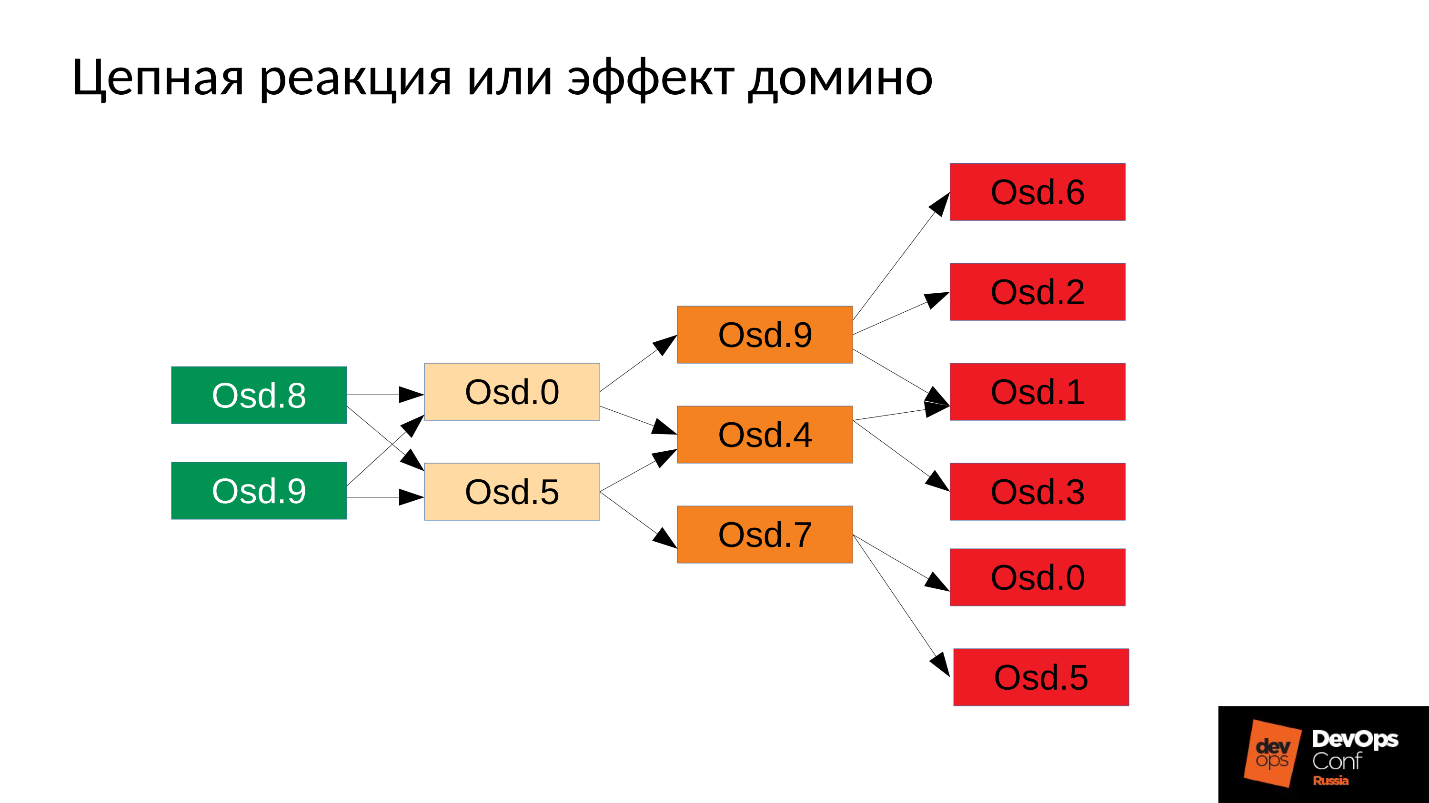
Dans notre cas, nous avons commencé OSD 8 et OSD 9, ils ont commencé à tout écraser, mais pas de chance OSD 0 et OSD 5. Un tueur en mémoire a volé vers eux et les a mis fin. Ils ont redémarré - ils ont lu leurs données, ont commencé à synchroniser et à écraser le reste. Trois autres malchanceux (OSD 9, OSD 4 et OSD 7). Ces trois ont redémarré, ont commencé à faire pression sur l'ensemble du cluster, le pack suivant n'a pas eu de chance.
Le cluster commence à s'effondrer littéralement sous nos yeux . La dégradation se produit très rapidement, et ce «très rapide» s'exprime généralement en minutes, maximum dizaines de minutes. Si vous avez 30 nœuds (10 nœuds par rack) et coupez le rack en raison d'une panne de courant - après 6 minutes, la moitié du cluster se trouve.
Donc, nous obtenons quelque chose comme ce qui suit.
Sur presque tous les serveurs, nous avons un OSD défectueux. Et si c'est sur chaque serveur, c'est-à-dire dans chaque domaine de défaillance que nous avons pour l'OSD défaillant, alors la
plupart de nos données ne sont pas disponibles . Toute demande est bloquée - pour écrire, pour lire - cela ne fait aucune différence. C’est tout! Nous nous sommes levés.
Que faire dans une telle situation? Plus précisément,
que fallait-il faire ?
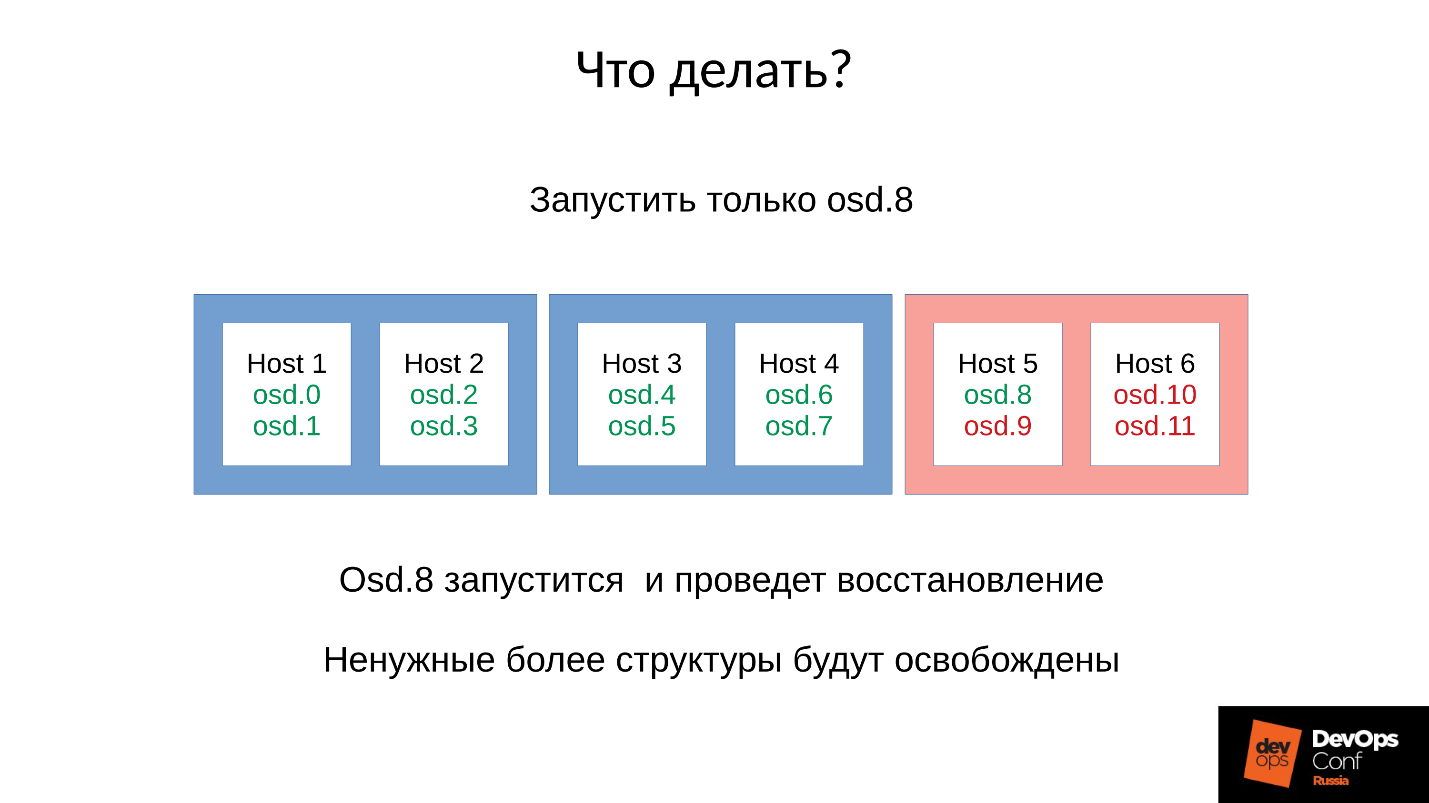
Réponse: Ne démarrez pas le cluster immédiatement, c'est-à-dire l'ensemble du rack, mais élevez soigneusement un démon chacun.
Mais nous ne le savions pas. Nous avons commencé tout de suite et avons obtenu ce que nous avons obtenu. Dans ce cas, nous avons lancé l'un des quatre démons (8, 9, 10, 11), la consommation mémoire augmentera d'environ 20%. En règle générale, nous faisons un tel bond. Ensuite, la consommation de mémoire commence à diminuer, car certaines des structures utilisées pour contenir les informations sur la façon dont le cluster s'est dégradé quittent. Autrement dit, une partie des groupes de placement est revenue à son état normal, et tout ce qui est nécessaire pour maintenir l'état dégradé est libéré -
en théorie, il est libéré .
Voyons un exemple. Le code C à gauche et à droite est presque identique, la différence ne concerne que les constantes.

Ces deux exemples demandent une quantité de mémoire différente du système:
- gauche - 2 048 morceaux de 1 Mo chacun;
- à droite - 2097152 pièces de 1 kilo-octet.
Ensuite, les deux exemples nous attendent pour les photographier en haut. Et après avoir appuyé sur ENTER, ils libèrent de la mémoire - tout sauf le dernier morceau. C'est très important - la dernière pièce reste. Et encore une fois, ils attendent que nous les photographions.
Voici ce qui s'est réellement passé.

- Tout d'abord, les deux processus ont démarré et ont mangé la mémoire. Sonne comme la vérité - 2 Go RSS.
- Appuyez sur ENTER et soyez surpris. Le premier programme qui s'est démarqué en gros morceaux a rendu la mémoire. Mais le deuxième programme n'est pas revenu.
La raison pour laquelle cela s'est produit réside dans le malloc Linux.
Si nous demandons de la mémoire en gros morceaux, elle est émise à l'aide du mécanisme mmap anonyme, qui est donné à l'espace d'adressage du processeur, d'où la mémoire nous est ensuite coupée. Lorsque nous faisons free (), la mémoire est libérée et les pages sont retournées au cache de pages (système).
Si nous allouons de la mémoire en petits morceaux, nous faisons sbrk (). sbrk () déplace le pointeur vers la queue du tas; en théorie, la queue décalée peut être renvoyée en renvoyant des pages de mémoire au système si la mémoire n'est pas utilisée.
Regardez maintenant l'illustration. Nous avions de nombreux enregistrements dans l'histoire de la localisation des objets dégradés, puis la session utilisateur - un objet à longue durée de vie. Nous nous sommes synchronisés et toutes les structures supplémentaires ont disparu, mais l'objet à longue durée de vie est resté et nous ne pouvons pas reculer sbrk ().

Nous avons encore beaucoup d'espace inutilisé qui pourrait être libéré si nous avions SWAP. Mais nous sommes intelligents - nous avons désactivé SWAP.
Bien sûr, alors une partie de la mémoire du début du tas sera utilisée, mais ce n'est qu'une partie, et un reste très important sera occupé.
Que faire dans une telle situation? La réponse est ci-dessous.
Lancement contrôlé
- Nous démarrons un démon OSD.
- On attend pendant qu'il est synchronisé, on vérifie les budgets mémoire.
- Si nous comprenons que nous survivrons au début du prochain démon, nous commençons le suivant.
- Sinon, redémarrez rapidement le démon qui a pris le plus de mémoire. Il a pu baisser pendant un court instant, il n'a pas beaucoup d'histoire, il manque des locs et d'autres choses, donc il va manger moins de mémoire, le budget mémoire augmentera légèrement.
- Nous courons autour du cluster, le contrôlons et levons progressivement tout.
- Nous vérifions s'il est possible de passer au prochain OSD, allez-y.
DigitalOcean a en fait accompli ceci:
"Notre équipe Datacenter effectue des augmentations de mémoire tandis qu'une autre équipe continue lentement à mettre en place des nœuds tout en gérant manuellement le budget de mémoire de chaque hôte."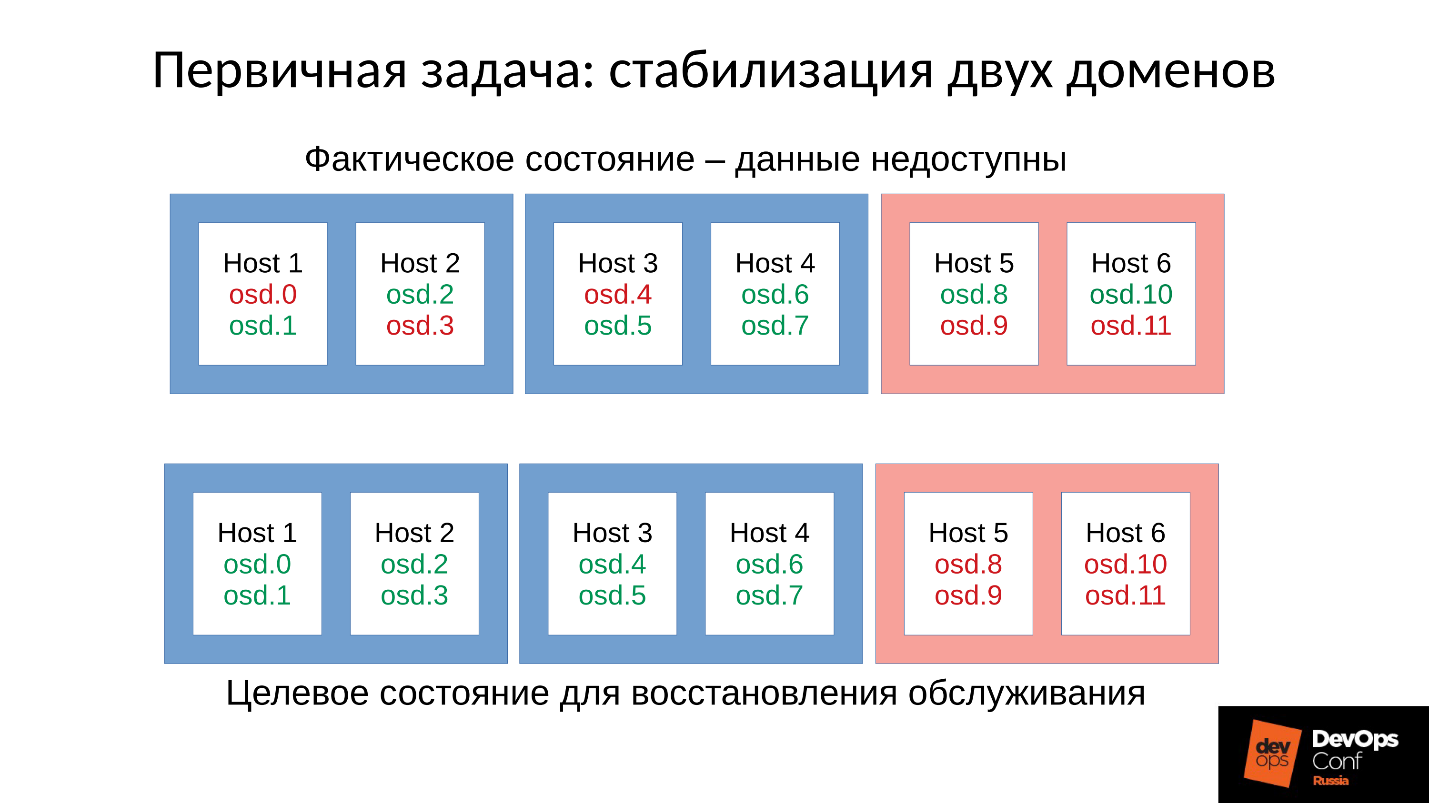
Revenons à notre configuration et à notre situation actuelle. Nous avons maintenant un cluster effondré après une réaction en chaîne de tueur en mémoire. Nous interdisons le redémarrage automatique de l'OSD dans le domaine rouge, et un par un, nous démarrons les nœuds à partir des domaines bleus. Parce que
notre première tâche est toujours de restaurer le service , sans comprendre pourquoi cela s'est produit. Nous comprendrons plus tard, lorsque nous rétablirons le service. En fonctionnement, c'est toujours le cas.
Nous amenons le cluster à l'état cible afin de restaurer le service, puis nous commençons à exécuter un OSD après l'autre selon notre méthodologie. Nous regardons le premier, si nécessaire, redémarrez les autres pour ajuster le budget mémoire, le suivant - 9, 10, 11 - et le cluster semble être synchronisé et prêt à démarrer la maintenance.
Le problème est de savoir comment la
maintenance en écriture est effectuée
dans Ceph .
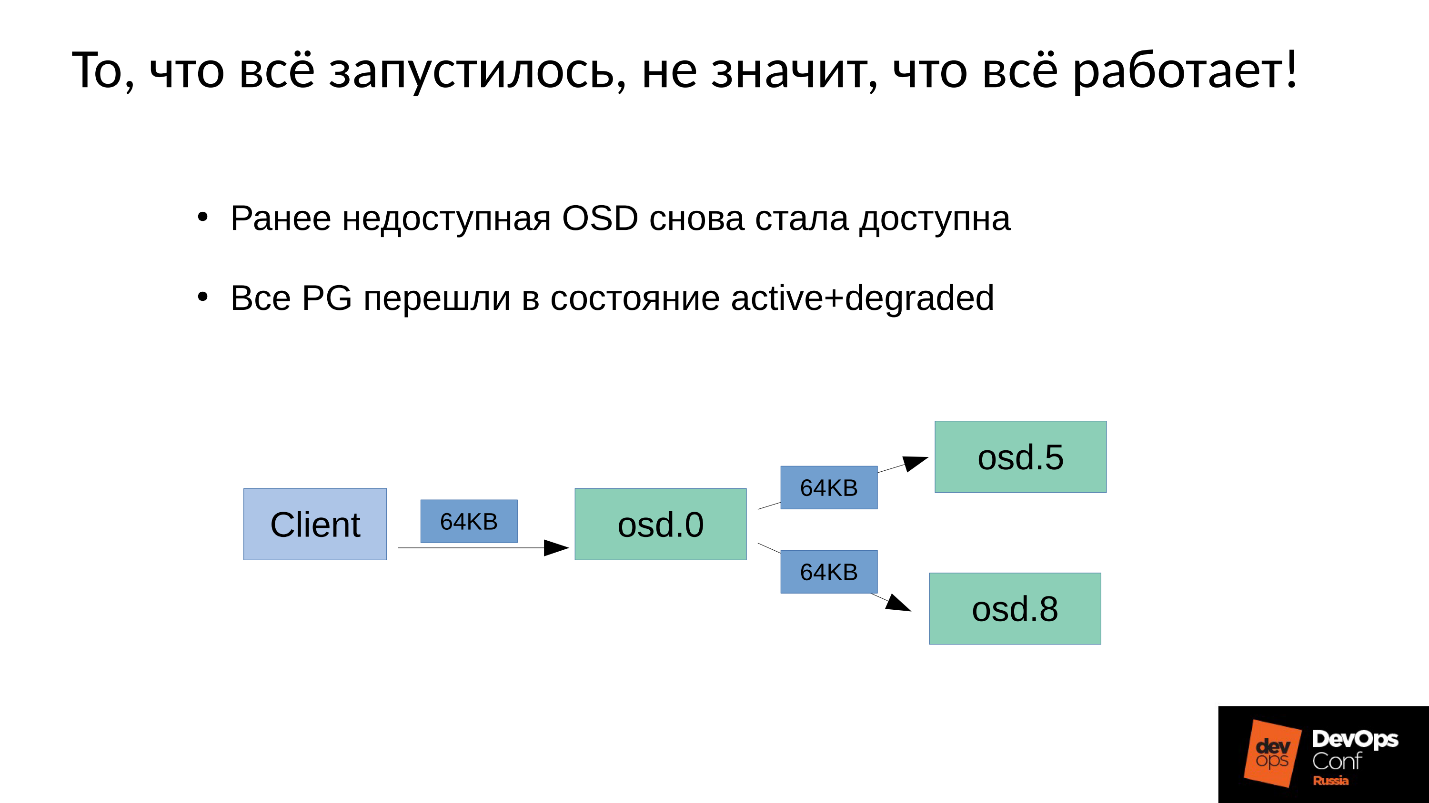
Nous avons 3 répliques: un OSD maître et deux esclaves pour cela. Nous allons préciser que le maître / esclave de chaque groupe de placement a le sien, mais chacun a un maître et deux esclaves.
L'opération d'écriture ou de lecture incombe au maître. Lors de la lecture, si le maître a la bonne version, il la remettra au client. L'enregistrement est un peu plus compliqué, l'enregistrement doit être répété sur toutes les répliques. Par conséquent, lorsque le client écrit 64 Ko dans OSD 0, les mêmes 64 Ko dans notre exemple vont à OSD 5 et OSD 8.
Mais le fait est que notre OSD 8 est très dégradé, car nous avons redémarré de nombreux processus.

Étant donné que dans Ceph, tout changement est une transition d'une version à l'autre, sur OSD 0 et OSD 5, nous aurons une nouvelle version, sur OSD 8 - l'ancienne. , , ( 64 ) OSD 8 — 4 ( ). 4 OSD 0, OSD 8, , . , 64 .
— .

:
- 4 1 , 1000 / 1 .
- 4 ( ) 22 , 45 /.
, , , , .
— .

4 22 , 22 , 1 4 . 45 SSD, 1 —
45 .
, .
- , — (45+1) / 2 = 23 .
- 75% , (45 * 3 + 1) / 4 = 34 .
- 90% —(45 * 9 + 1) / 10 = 41 — 40 , .
Ceph, . , , , .
Ceph .

- — : , , , , .
- — latency. latency , . 100% ( , ). Latency 60 , .

, . 10 , 1 200 /, 300 , , . 10 SSD — 300 , — , - 300 .
, .
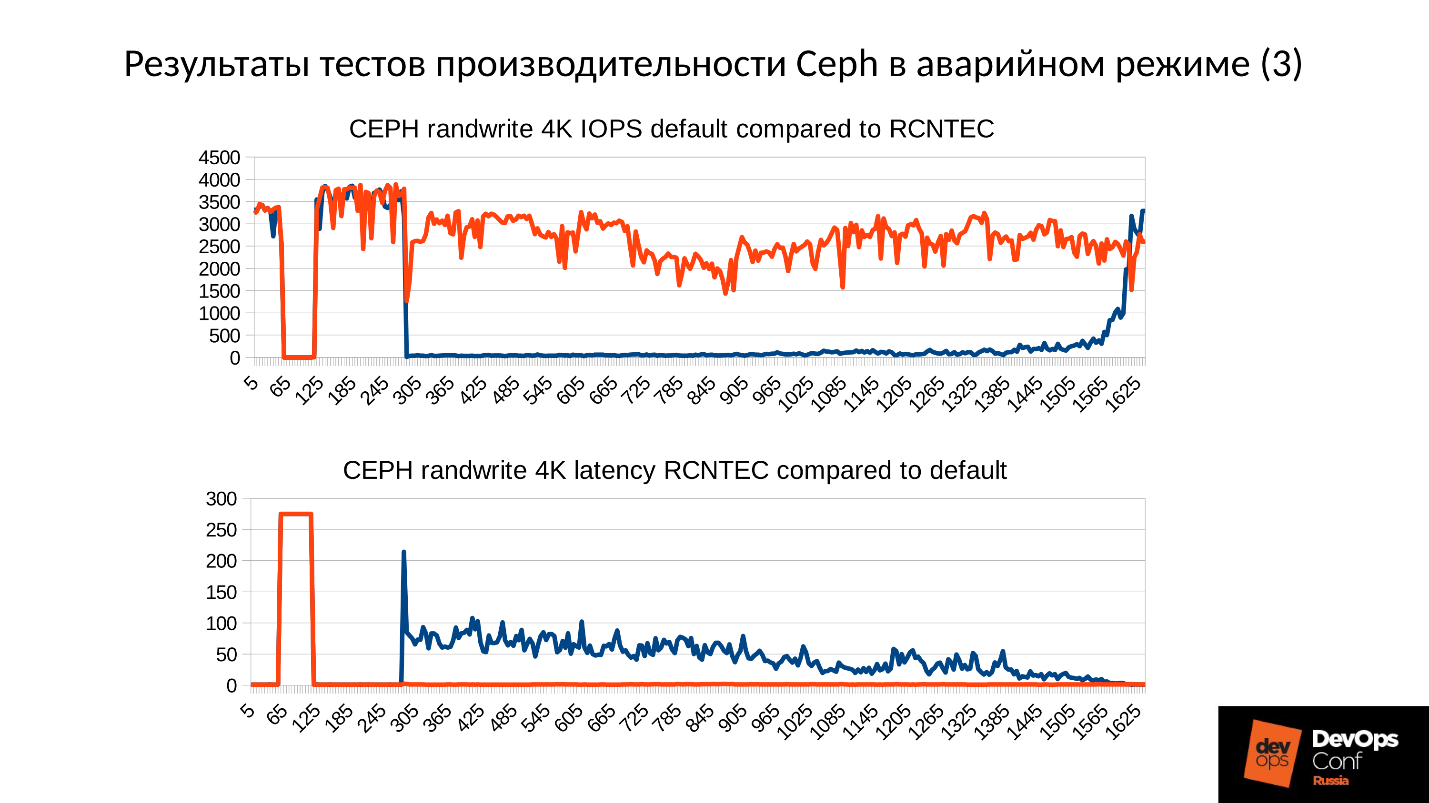
, . 900 / ( SSD). 2 500 128 ( , ESXi HyperV 128 ). degraded, 225 . file store, object store, ( ), 110 , - .
SSD 110 — !
?1: —
.

: ; PG;
.
:
- , 45 — .
- ( . ), 14 .
- , 8 ( 10% PG).
, , , , , .
2: —
(order, objectsize) .
, , , 4 2 1 . , , . Dans ce cas:
:
(32 ) — !
3: —
Ceph .
, -,
Ceph . , , . .
, — Latency. — , — . Latency 30% , , .
Community , preproduction . , . , .
Conclusion
- , . , Ceph - , , .
●
- .
, . ,
. . , , production. , , , DigitalOcean , . , , , .
, , . , : « ! ?!» , , . , : , , down time.
●
(OSD)., , — , , - , .
OSD — — . , .
●
.OSD .
, . , , , .
●
RAM OSD.●
SWAP.SWAP Ceph' , Linux' . .
●
.100%, 10%. , , , .
●
RBD Rados Getway., .
SWAP — . , SWAP — , , , , .
Cet article est une transcription de l'un des meilleurs rapports de DevOpsConf Russia. Bientôt, nous ouvrirons la vidéo et publierons dans une version texte à quel point les sujets sont intéressants. Abonnez-vous ici sur youtube ou dans la newsletter si vous ne voulez pas manquer de tels documents utiles et être au courant des nouvelles de DevOps.