Nous utilisons tous une sorte de gestionnaire de colis, y compris la femme de ménage Tante Galya, qui a un iPhone dans sa poche en ce moment mis à jour. Mais il n'y a pas d'accord général sur les fonctions des gestionnaires de packages, et les systèmes d'exploitation et les systèmes de build rpm et dpkg standard sont appelés gestionnaires de packages. Nous proposons de réfléchir sur le sujet de leurs fonctions - ce que c'est et pourquoi elles sont nécessaires dans le monde moderne. Et puis nous allons creuser vers Kubernetes et considérer soigneusement Helm en termes de ces fonctions.
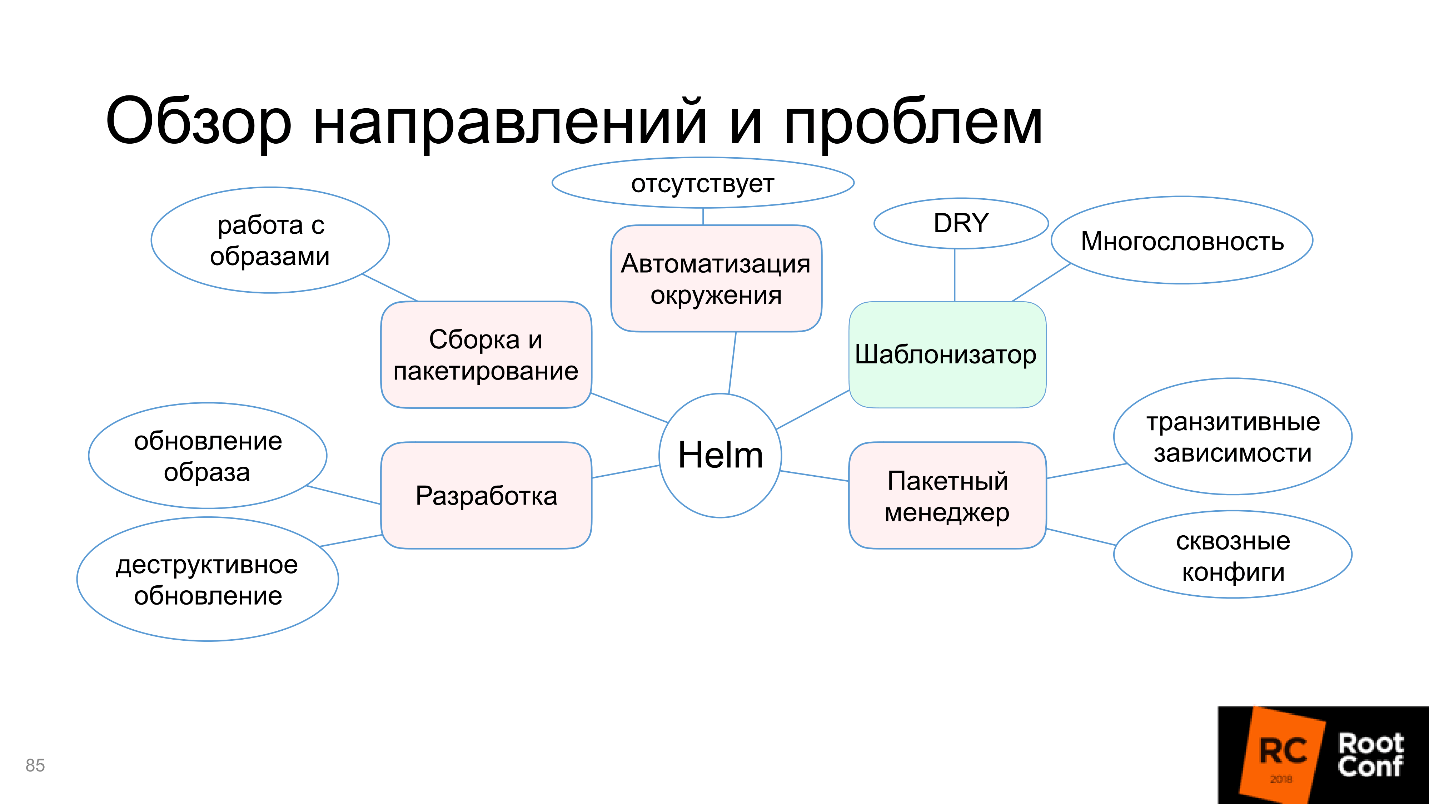
Nous comprendrons pourquoi dans ce diagramme, seule la fonction de modèle est mise en évidence en vert, et quels sont les problèmes d'assemblage et d'emballage, d'automatisation de l'environnement, etc. Mais ne vous inquiétez pas, l'article ne se termine pas par le fait que tout va mal. La communauté n'a pas pu accepter cela et propose des outils et des solutions alternatifs - nous les traiterons.
Ivan Glushkov (
gli ) nous a aidé à cet égard avec son rapport sur RIT ++, une version vidéo et texte de cette présentation détaillée et détaillée ci-dessous.
Des vidéos de ce discours et d'autres discours de DevOps sur RIT ++ sont publiées et ouvertes à la visualisation gratuite sur notre chaîne YouTube - partez à la recherche de réponses à vos questions de travail.
À propos de l'orateur: Ivan Glushkov développe des logiciels depuis 15 ans. J'ai réussi à travailler en MZ, à Echo sur une plateforme de commentaires, à participer au développement de compilateurs pour le processeur Elbrus en MCST. Il participe actuellement à des projets d'infrastructure chez Postmates. Ivan est l'un des principaux podcasts
DevZen dans lequel ils parlent de nos conférences:
voici RIT ++, et
ici HighLoad ++.
Gestionnaires de packages
Bien que tout le monde utilise une sorte de gestionnaire de packages, il n'y a pas d'accord unique sur ce que c'est. Il y a une compréhension commune, et chacune a la sienne.
Rappelons quels types de gestionnaires de packages viennent à l'esprit en premier:
- Gestionnaires de packages standard de tous les systèmes d'exploitation: rpm, dpkg, portage , ...
- Gestionnaires de packages pour différents langages de programmation: cargo, cabal, rebar3, mix , ...
Leur fonction principale est d'exécuter des commandes pour installer un package, mettre à jour un package, désinstaller un package et gérer les dépendances. Dans les gestionnaires de packages à l'intérieur des langages de programmation, les choses sont un peu plus compliquées. Par exemple, il existe des commandes comme «lancer un package» ou «créer une version» (build / run / release). Il s'avère que c'est déjà un système de construction, bien que nous l'appelions également un gestionnaire de paquets.

Tout cela est uniquement dû au fait que vous ne pouvez pas simplement le prendre et ... laissez les amoureux de Haskell pardonner cette comparaison. Vous pouvez exécuter le fichier binaire, mais vous ne pouvez pas exécuter le programme dans Haskell ou C, vous devez d'abord le préparer en quelque sorte. Et cette préparation est plutôt compliquée, et les utilisateurs veulent que tout soit fait automatiquement.
Développement
Celui qui a travaillé avec GNU libtool, qui a été conçu pour un grand projet composé d'un grand nombre de composants, ne se moque pas du cirque. C'est vraiment très difficile, et certains cas ne peuvent pas être résolus en principe, mais peuvent seulement être contournés.
Par rapport à cela, les gestionnaires de langue de package modernes comme cargo for Rust sont beaucoup plus pratiques - vous appuyez sur le bouton et tout fonctionne. Bien qu'en fait, sous le capot, un grand nombre de problèmes soient résolus. De plus, toutes ces nouvelles fonctions nécessitent quelque chose de plus, notamment une base de données. Bien que dans le gestionnaire de paquets lui-même, il puisse être appelé comme vous voulez, je l'appelle une base de données, car les données y sont stockées: sur les packages installés, sur leurs versions, les référentiels connectés, les versions de ces référentiels. Tout cela doit être stocké quelque part, il existe donc une base de données interne.
Développement dans ce langage de programmation, tests pour ce langage de programmation, lancements - tout cela est intégré et situé à l'intérieur, le
travail devient très pratique . La plupart des langues modernes ont soutenu cette approche. Même ceux qui n'ont pas soutenu commencent à soutenir, car la communauté insiste et dit que dans le monde moderne, c'est impossible sans cela.
Mais toute solution présente toujours non seulement des avantages, mais aussi des inconvénients . L'inconvénient ici est que vous avez besoin d'encapsuleurs, d'utilitaires supplémentaires et d'une «base de données» intégrée.
Docker
Pensez-vous que Docker est un gestionnaire de paquets ou non?
Peu importe comment, mais essentiellement oui. Je ne connais pas d'utilitaire plus correct pour assembler complètement l'application avec toutes les dépendances, et pour la faire fonctionner d'un simple clic. Qu'est-ce que ce n'est pas un gestionnaire de paquets? C'est un excellent gestionnaire de paquets!
Maxim Lapshin a déjà
dit qu'avec Docker, c'est devenu beaucoup plus facile, et c'est ainsi. Docker a un système de build intégré, toutes ces bases de données, liaisons, utilitaires.
Quel est le prix de tous les avantages? Ceux qui travaillent avec Docker réfléchissent peu aux applications industrielles. J'ai une telle expérience, et le prix est en fait très élevé:
- La quantité d'informations (taille d'image) qui doit être stockée dans l'image Docker. Vous avez besoin de toutes les dépendances, parties d'utilitaires, bibliothèques à emballer à l'intérieur, l'image est grande et vous devez pouvoir travailler avec elle.
- Il est beaucoup plus compliqué qu'un changement de paradigme se produise.
Par exemple, j'ai eu la tâche de transférer un programme pour utiliser Docker. Le programme a été développé au fil des ans par une équipe. Je viens, nous faisons tout ce qui est écrit dans les livres: nous peignons des histoires d'utilisateurs, des rôles, voyons ce qu'ils font et comment ils le font, leurs routines standard.
Je dis:
- Docker peut résoudre tous vos problèmes. Regardez comment cela se fait.
- Tout sera sur le bouton - super! Mais nous voulons que SSH fasse à l'intérieur des conteneurs Kubernetes.
- Attendez, pas de SSH n'importe où.
- Oui, oui, tout va bien ... Mais la SSH est-elle possible?
Pour transformer la perception des utilisateurs dans une nouvelle direction, cela prend beaucoup de temps, il faut du travail éducatif et beaucoup d'efforts.
Un autre facteur de prix est que le
registre Docker est un référentiel externe pour les images, il doit être installé et contrôlé d'une manière ou d'une autre. Il a ses propres problèmes, un récupérateur de déchets et ainsi de suite, et il peut souvent tomber si vous ne le suivez pas, mais tout est résolu.
Kubernetes
Enfin, nous sommes arrivés à Kubernetes. Il s'agit d'un système de gestion d'applications OpenSource sympa qui est activement soutenu par la communauté. Bien qu'il ait initialement quitté une entreprise, Kubernetes a maintenant une énorme communauté, et il est impossible de la suivre, il n'y a pratiquement aucune alternative.
Fait intéressant, tous les nœuds Kubernetes fonctionnent dans Kubernetes lui-même via des conteneurs, et toutes les applications externes fonctionnent via des conteneurs -
tout fonctionne via des conteneurs ! C'est à la fois un plus et un moins.
Kubernetes possède de nombreuses fonctionnalités et propriétés utiles: distribution, tolérance aux pannes, capacité à travailler avec différents services cloud et orientation vers l'architecture de microservices. Tout cela est intéressant et cool, mais comment installer l'application dans Kubernetes?
Comment installer l'appli?
Installez l'image Docker dans le registre Docker.
Derrière cette phrase se cache un abîme. Vous imaginez - vous avez une application écrite, disons, en Ruby, et vous devez mettre l'image Docker dans le registre Docker. Cela signifie que vous devez:
- Préparer une image Docker
- comprendre comment cela se passe, sur quelles versions il est basé;
- pouvoir le tester;
- collecter, remplir le Docker-Registry, que vous avez d'ailleurs déjà installé auparavant.
En fait, c'est une très grosse douleur sur une seule ligne.
De plus, vous devez toujours décrire le manifeste de l'application en termes (ressources) de k8s. L'option la plus simple:
- décrire le déploiement + le module, le service + l'entrée (éventuellement);
- exécutez la commande kubectl apply -f resources.yaml et transférez toutes les ressources vers cette commande.

Gandhi se frotte les mains sur la diapositive - on dirait que j'ai trouvé le gestionnaire de paquets dans Kubernetes. Mais kubectl n'est pas un gestionnaire de paquets. Il dit simplement que je veux voir un tel état final du système. Ce n'est pas installer un paquet, ne pas travailler avec des dépendances, pas construire - c'est juste "Je veux voir cet état final".
Heaume
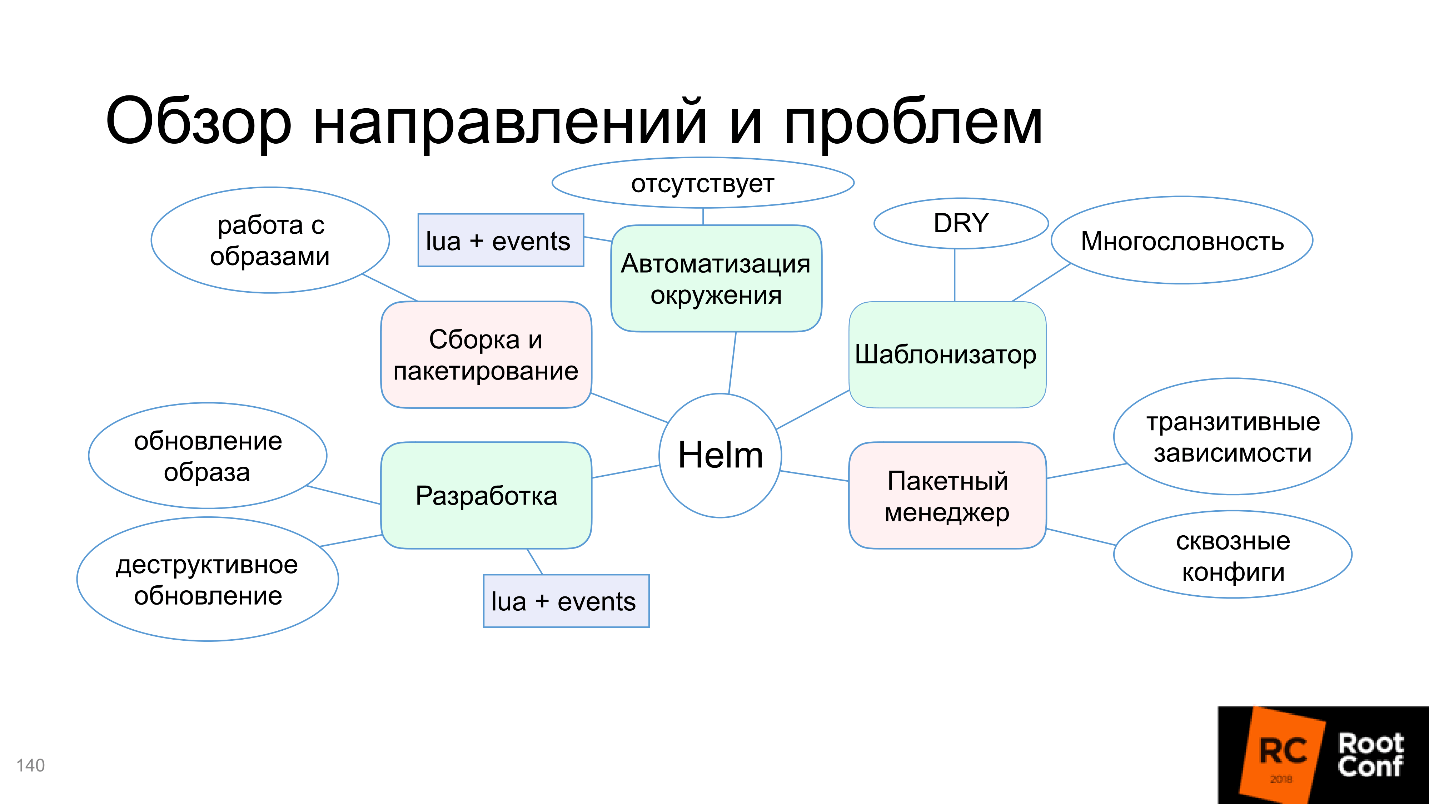
Enfin, nous sommes arrivés à Helm. Helm est un utilitaire polyvalent. Nous allons maintenant examiner quels sont les domaines de développement de Helm et travailler avec.
Moteur de modèle
Premièrement, Helm est un moteur de modèle. Nous avons discuté des ressources à préparer, et le problème est d'écrire en termes de Kubernetes (et pas seulement en yaml). La chose la plus intéressante est que ce sont des fichiers statiques pour votre application spécifique dans cet environnement particulier.
Cependant, si vous travaillez avec plusieurs environnements et que vous disposez non seulement de Production, mais également de Staging, Testing, Development et de différents environnements pour différentes équipes, vous devez disposer de plusieurs manifestes similaires. Par exemple, parce que dans l'un d'eux il y a plusieurs serveurs et que vous devez avoir un grand nombre de répliques, et dans l'autre - une seule réplique. Il n'y a pas de base de données, d'accès à RDS et vous devez installer PostgreSQL à l'intérieur. Et ici, nous avons l'ancienne version, et nous devons tout réécrire un peu.
Toute cette diversité conduit au fait que vous devez prendre votre manifeste pour Kubernetes, le copier partout et le réparer partout: ici remplacez un chiffre, voici autre chose. Cela devient très inconfortable.
La solution est simple - vous devez
saisir des modèles . En d'autres termes, vous formez un manifeste, vous y définissez des variables, puis vous soumettez les variables définies en externe sous forme de fichier. Le modèle crée le manifeste final. Il se révèle réutiliser le même manifeste pour tous les environnements, ce qui est beaucoup plus pratique.
Par exemple, le manifeste pour Helm.

- La partie la plus importante de Helm est Chart.yaml , qui décrit de quel type de manifeste il s'agit, quelles versions, comment cela fonctionne.
- les modèles ne sont que des modèles de ressources Kubernetes qui contiennent en eux-mêmes une sorte de variables. Ces variables doivent être définies dans un fichier externe ou sur la ligne de commande, mais toujours en externe.
- values.yaml est le nom standard du fichier avec des variables pour ces modèles.
La commande de démarrage la plus simple pour installer le graphique est helm install ./wordpress (dossier). Pour redéfinir certains paramètres, nous disons: "Je veux redéfinir précisément ces paramètres et définir telle ou telle valeur".
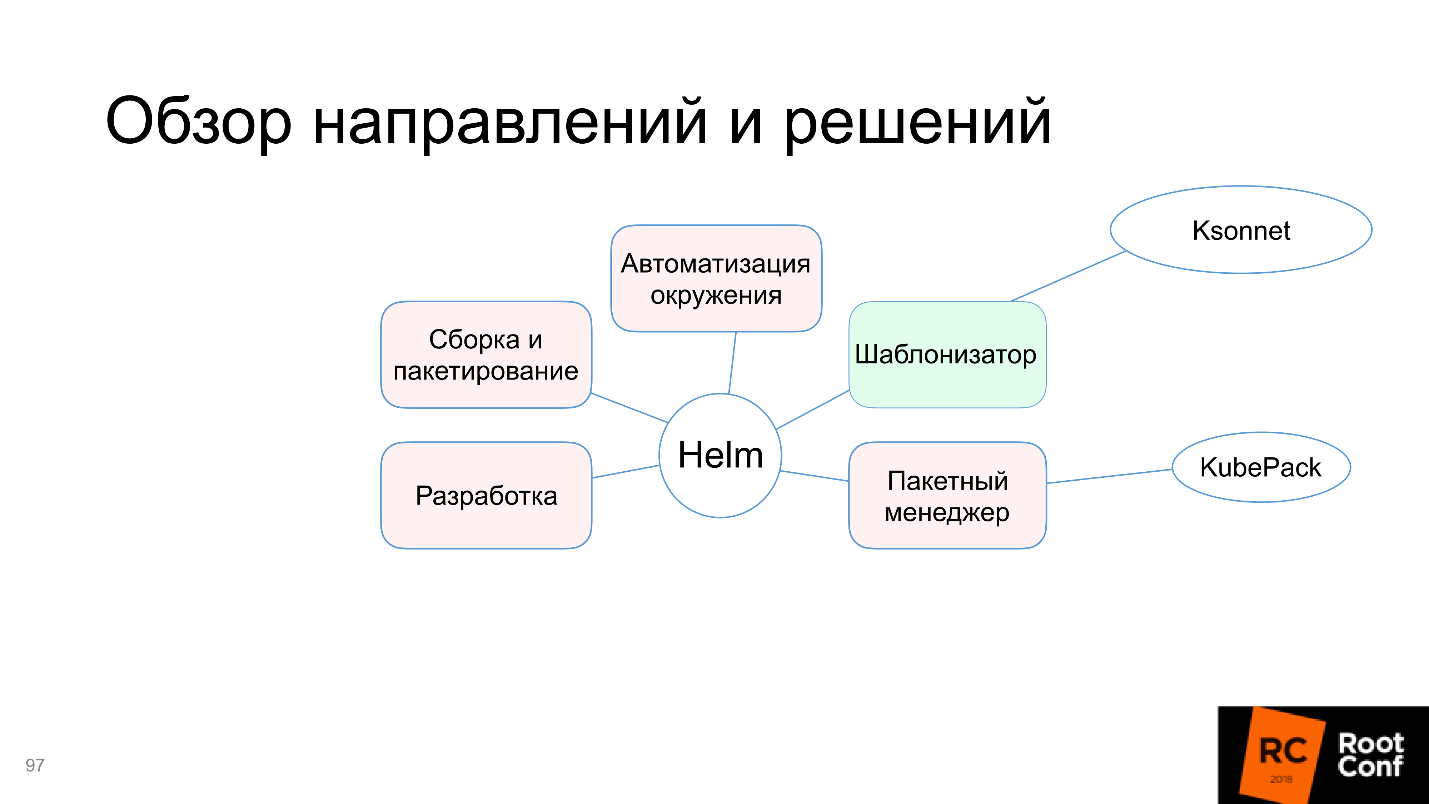
Helm fait face à cette tâche, donc dans le diagramme, nous le marquons en vert.
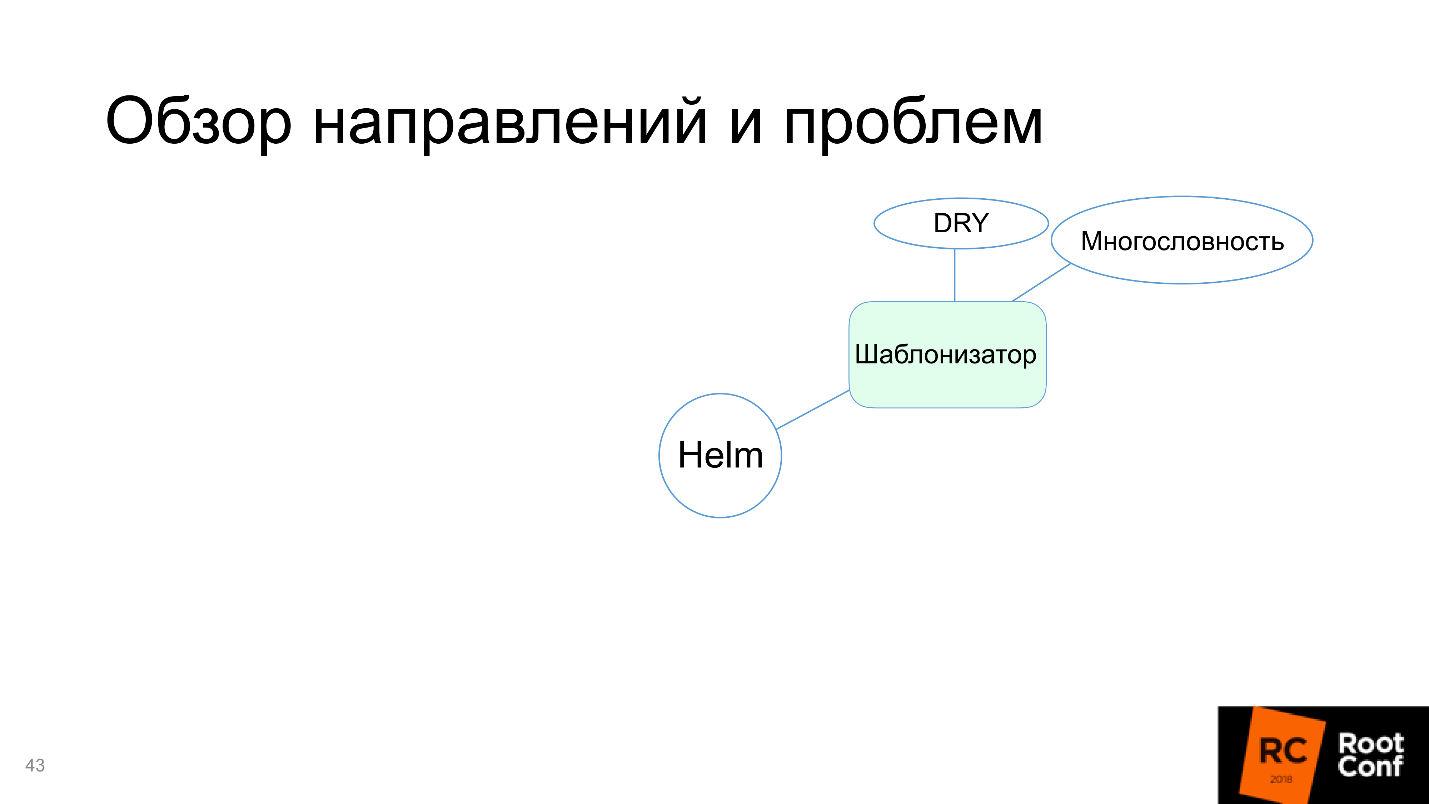
Certes, les inconvénients apparaissent:
- Verbosité . Les ressources sont définies complètement en termes de Kubernetes, les concepts de niveaux supplémentaires d'abstraction ne sont pas introduits: nous écrivons simplement tout ce que nous aimerions écrire pour Kubernetes et y remplaçons des variables.
- Ne vous répétez pas - sans objet. Il est souvent nécessaire de répéter la même chose. Si vous avez deux services similaires avec des noms différents, vous devez copier complètement le dossier entier (le plus souvent, ils le font) et modifier les fichiers nécessaires.
Avant de plonger dans la direction de Helm - un gestionnaire de paquets, pour lequel je vous dis tout cela, voyons comment Helm fonctionne avec les dépendances.
Travailler avec des dépendances
Helm est difficile de travailler avec des dépendances. Tout d'abord, il existe un fichier requirements.yaml qui correspond à ce dont nous dépendons. Tout en travaillant avec les exigences, il fait requirements.lock - c'est l'état actuel (nugget) de toutes les dépendances. Après cela, il les télécharge dans un dossier appelé / charts.
Il existe des outils pour gérer: qui, comment, où se connecter -
balises et conditions , avec lesquelles il est déterminé dans quel environnement, en fonction de quels paramètres externes, pour se connecter ou non pour connecter certaines dépendances.
Disons que vous avez PostgreSQL pour l'environnement de transfert (ou RDS pour la production ou NoSQL pour les tests). En installant ce paquet dans Production, vous n'installerez pas PostgreSQL, car il n'y est pas nécessaire - il suffit d'utiliser des balises et des conditions.
Qu'est-ce qui est intéressant ici?
- Helm mélange toutes les ressources de toutes les dépendances et applications;
- trier -> installer / mettre à jour
Après avoir téléchargé toutes les dépendances dans / charts (ces dépendances peuvent être, par exemple, 100), Helm prend et copie toutes les ressources à l'intérieur. Après avoir rendu les modèles, il rassemble toutes les ressources en un seul endroit et les trie dans une sorte de son propre ordre. Vous ne pouvez pas influencer cet ordre. Vous devez déterminer par vous-même de quoi dépend votre package, et si le package a des dépendances transitives, vous devez tous les inclure dans la description dans requirements.yaml. Il faut garder cela à l'esprit.
Gestionnaire de paquets
Helm installe les applications et les dépendances, et vous pouvez dire à Helm install - et il installera le package. Il s'agit donc d'un gestionnaire de packages.
Dans le même temps, si vous avez un référentiel externe dans lequel vous téléchargez le package, vous pouvez y accéder non pas en tant que dossier local, mais simplement dire: «À partir de ce référentiel, prenez ce package, installez-le avec tel ou tel paramètre».
Il existe des référentiels ouverts avec de nombreux packages. Par exemple, vous pouvez exécuter: helm install -f prod / values.yaml stable / wordpress
Depuis le référentiel stable, vous prendrez wordpress et l'installerez vous-même. Vous pouvez tout faire: rechercher / mettre à niveau / supprimer. Il s'avère que Helm est un gestionnaire de paquets.
Mais il y a des inconvénients: toutes
les dépendances transitives doivent être incluses à l'intérieur. C'est un gros problème lorsque les dépendances transitives sont des applications indépendantes et que vous souhaitez travailler séparément avec elles pour les tests et le développement.
Un autre inconvénient est la
configuration de bout en bout . Lorsque vous avez une base de données et que son nom doit être transféré dans tous les packages, cela peut être le cas, mais c'est difficile à faire.

Plus souvent qu'autrement, vous avez installé un petit paquet et cela fonctionne. Le monde est complexe: l'application dépend de l'application, qui à son tour dépend également de l'application - vous devez les configurer intelligemment. Helm ne sait pas comment soutenir cela, ou le supporte avec de gros problèmes, et parfois vous devez beaucoup danser avec un tambourin pour le faire fonctionner. C'est mauvais, donc le "gestionnaire de paquets" dans le diagramme est surligné en rouge.
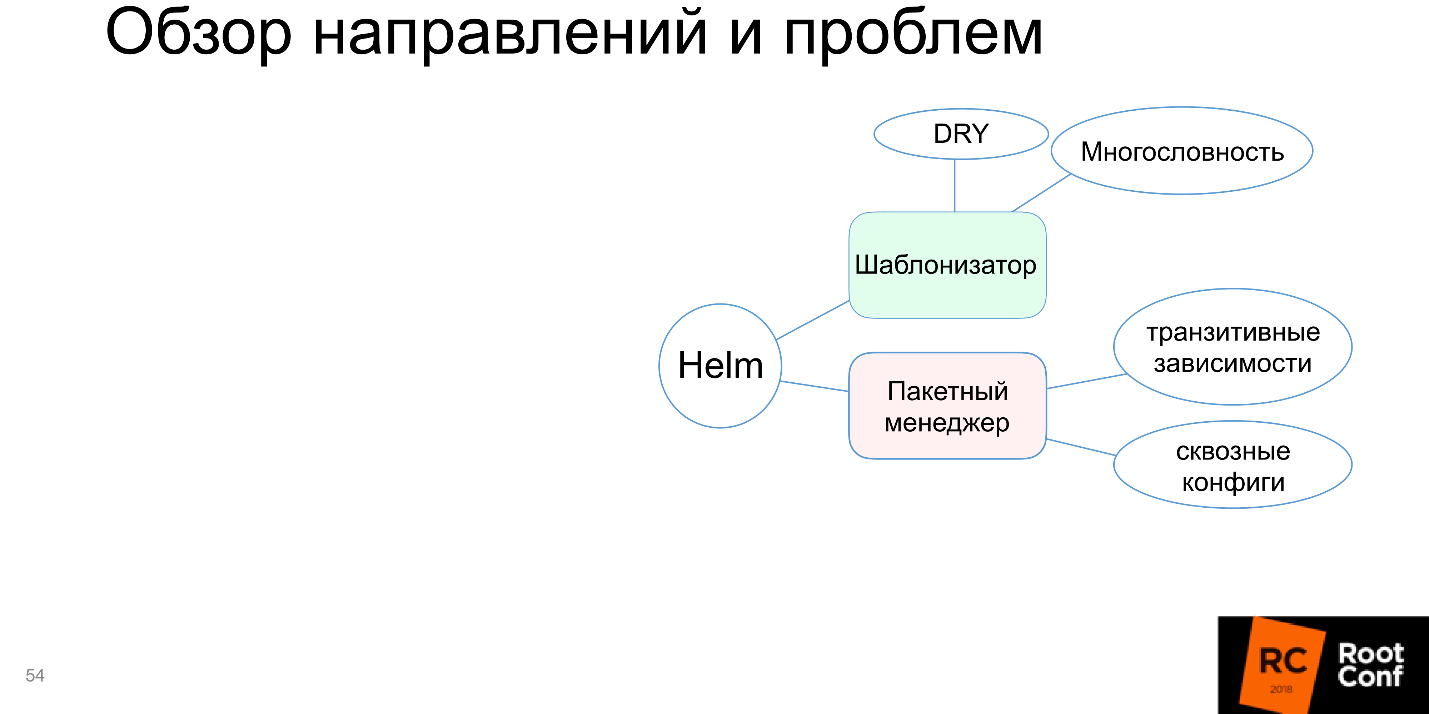
Assemblage et emballage
"Vous ne pouvez pas simplement obtenir et exécuter" l'application dans Kubernetes. Vous devez l'assembler, c'est-à-dire créer une image Docker, l'écrire dans le registre Docker, etc. Bien que la définition de package entière dans Helm soit. Nous déterminons ce qu'est le package, quelles fonctions et quels champs doivent y être, les signatures et l'authentification (le système de sécurité de votre entreprise sera très content). Par conséquent, d'une part, l'assemblage et le conditionnement semblent être pris en charge, et d'autre part, le travail avec les images Docker n'est pas configuré.
Helm ne vous permet pas d'exécuter l'application sans image Docker. Dans le même temps, Helm n'est pas configuré pour l'assemblage et le conditionnement, c'est-à-dire qu'il ne sait pas comment travailler avec les images Docker.
C'est la même chose que si, pour effectuer une installation de mise à niveau pour une petite bibliothèque, vous seriez envoyé dans un dossier distant pour exécuter le compilateur.
Par conséquent, nous disons que Helm ne sait pas comment travailler avec des images.

Développement
Le prochain mal de tête est le développement. En cours de développement, nous voulons changer rapidement et facilement notre code. Le temps a passé lorsque vous avez percé des trous sur des cartes perforées et le résultat a été obtenu après 5 jours. Tout le monde a l'habitude de remplacer une lettre par une autre dans l'éditeur, d'appuyer sur la compilation et le programme déjà modifié fonctionne.
Il s'avère ici que lors du changement de code, de nombreuses actions supplémentaires sont nécessaires: préparer un fichier Docker; Exécutez Docker pour qu'il crée l'image; pour le pousser quelque part; déployer sur le cluster Kubernetes. Et seulement alors, vous obtiendrez ce que vous voulez sur Production, et vous pourrez vérifier le code.
Il y a encore des inconvénients en raison de la
mise à niveau
destructrice du casque de mise à jour. Vous avez regardé comment tout fonctionnait, grâce à kubectl exec, vous avez regardé à l'intérieur du conteneur, tout va bien. À ce moment, vous démarrez la mise à jour, une nouvelle image est téléchargée, de nouvelles ressources sont lancées et les anciennes sont supprimées - vous devez tout recommencer depuis le tout début.
La plus grande douleur est les
grandes images . La plupart des entreprises ne travaillent pas avec de petites applications. Souvent, sinon un supermonolithe, alors au moins un petit monolithique. Au fil du temps, les anneaux annuels se développent, la base de code augmente et progressivement l'application devient assez importante. J'ai rencontré à plusieurs reprises des images Docker supérieures à 2 Go. Imaginez maintenant que vous apportez une modification d'un octet dans votre programme, appuyez sur un bouton et une image Docker de deux gigaoctets commence à s'assembler. Ensuite, vous appuyez sur le bouton suivant et le transfert de 2 Go vers le serveur commence.
Docker vous permet de travailler avec des calques, c'est-à-dire vérifie s'il y a une couche ou une autre et envoie celle qui manque. Mais le monde est tel que le plus souvent ce sera une grande couche. Alors que 2 Go iront au serveur, alors qu'ils iront à Kubernetes avec le registre Docker, ils seront déployés de toutes les manières, jusqu'à ce que vous commenciez enfin, vous pouvez prendre le thé en toute sécurité.
Helm n'offre aucune aide pour les grandes images Docker. Je crois que cela ne devrait pas être le cas, mais les développeurs de Helm le savent mieux que tous les utilisateurs, et Steve Jobs lui sourit.

Le bloc avec le développement est également devenu rouge.
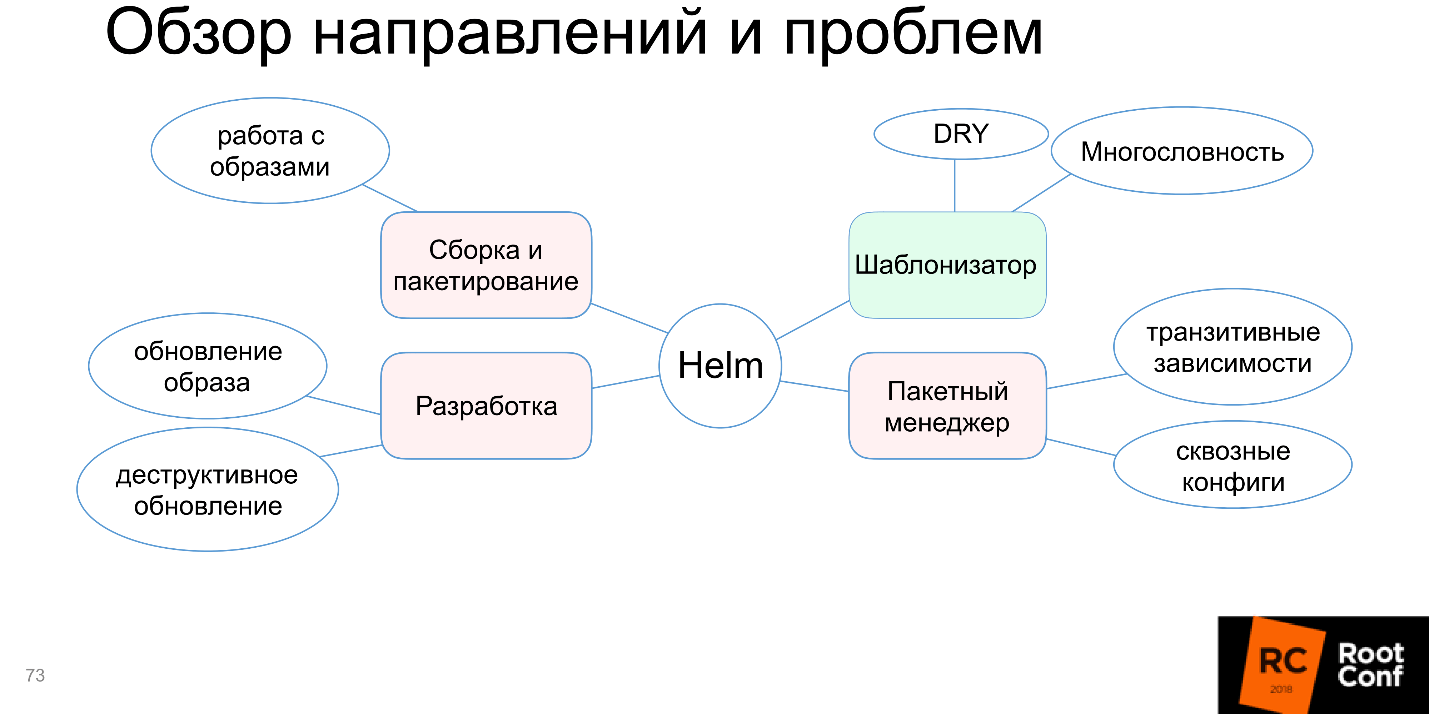
Automatisation de l'environnement
La dernière direction - l'automatisation de l'environnement - est un domaine intéressant. Avant le monde de Docker (et Kubernetes, en tant que modèle connexe), il n'y avait aucun moyen de dire: "Je veux installer mon application sur ce serveur ou sur ces serveurs pour qu'il y ait n répliques, 50 dépendances, et tout cela fonctionne automatiquement!" Tel, pourrait-on dire, ce qui était, mais ne l'était pas!
Kubernetes fournit cela et il est logique de l'utiliser d'une manière ou d'une autre, par exemple pour dire: "Je déploie un nouvel environnement ici et je veux que toutes les équipes de développement qui ont préparé leurs applications puissent simplement cliquer sur un bouton et toutes ces applications seront automatiquement installées sur le nouvel environnement" . Théoriquement, Helm devrait aider à cela, afin que la configuration puisse être prise à partir d'une source de données externe - S3, GitHub - de n'importe où.
Il est conseillé qu'il y ait un bouton spécial dans Helm "Fais-moi du bien déjà enfin!" - et cela deviendrait immédiatement bon. Kubernetes vous permet de le faire.
Ceci est particulièrement pratique car Kubernetes peut être exécuté n'importe où et fonctionne via l'API. En lançant minikube localement, dans AWS ou dans Google Cloud Engine, vous obtenez Kubernetes dès la sortie de la boîte et travaillez de la même manière partout: appuyez sur un bouton et tout va bien tout de suite.
Il semblerait que Helm vous le permette naturellement. Car sinon, à quoi bon créer Helm en général?
Mais il s'avère que non!
Il n'y a pas d'automatisation de l'environnement.
Alternatives
Quand il y a une application de Kubernetes que tout le monde utilise (c'est maintenant en fait la solution numéro 1), mais Helm a les problèmes discutés ci-dessus, la communauté n'a pas pu s'empêcher de répondre. Il a commencé à créer des outils et des solutions alternatifs.
Moteurs de modèles
Il semblerait qu'en tant que moteur de modèle, Helm ait résolu tous les problèmes, mais la communauté crée toujours des alternatives. Permettez-moi de vous rappeler les problèmes du moteur de template: verbosité et réutilisation du code.
Un bon représentant ici est
Ksonnet. Il utilise un modèle de données et de concepts fondamentalement différent et ne fonctionne pas avec les ressources Kubernetes, mais avec ses propres définitions:
prototype (params) -> composant -> application -> environnements.
Il y a des pièces qui composent le prototype. Le prototype est paramétré par des données externes et le composant apparaît. Plusieurs composants constituent une application que vous pouvez exécuter. Il fonctionne dans différents environnements. Il existe des liens clairs vers les ressources Kubernetes ici, mais il n'y a peut-être pas d'analogie directe.
Le principal objectif de Ksonnet était, bien sûr, de
réutiliser les ressources . Ils voulaient s'assurer qu'une fois que vous avez écrit le code, vous pourrez ensuite l'utiliser n'importe où, ce qui augmente la vitesse de développement. Si vous créez une grande bibliothèque externe, les utilisateurs peuvent y publier en permanence leurs ressources et toute la communauté pourra les réutiliser.
Théoriquement, c'est pratique.
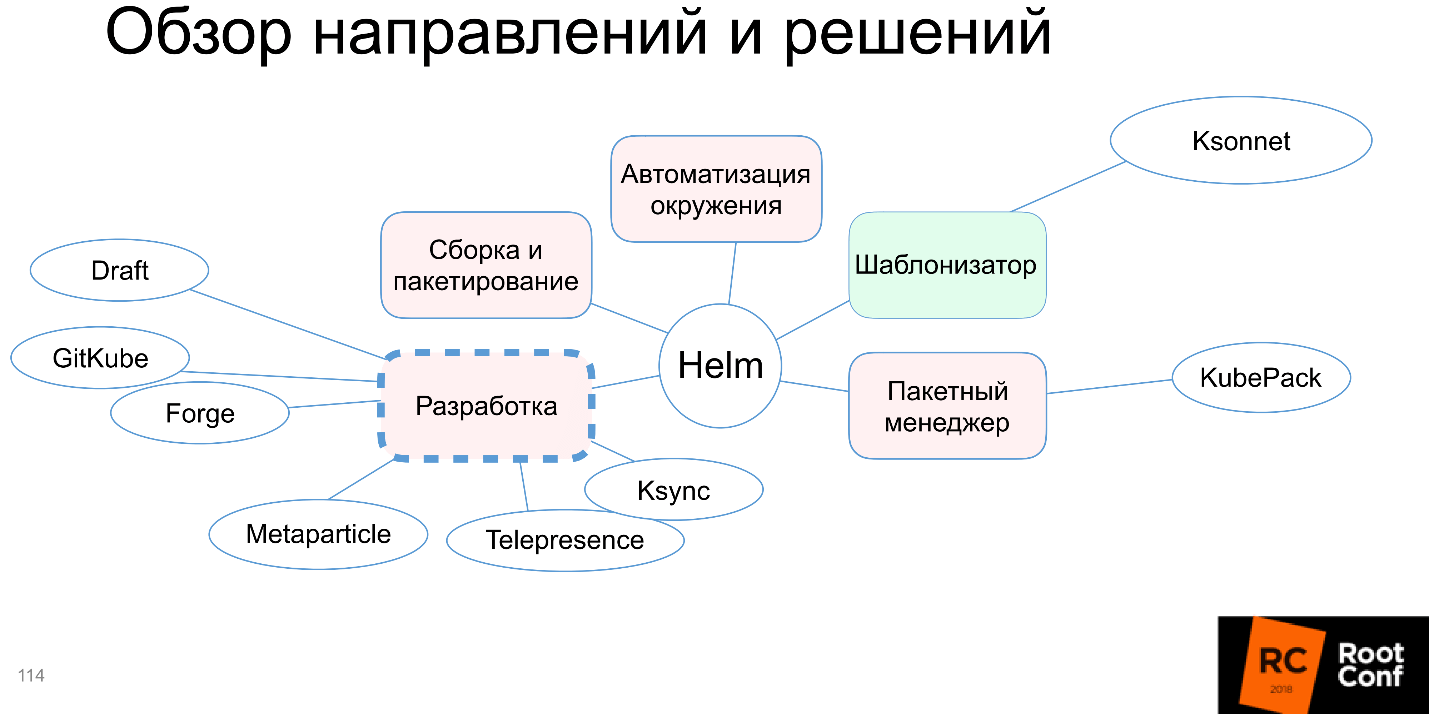
Je ne l'ai pratiquement pas utilisé.Gestionnaires de packages
, — , , . Ksonnet . Ksonnet Helm , , .. , , , .

, , , , . . , , , 0.1. , .
, —
KubePack , .
Développement
:
- Helm;
- Helm;
- , ;
- , .
1. Helm
—
Draft . — , , . Draft — Heroku-style:
- (pack);
- , , Python «Hello, world!»;
- , Docker- ( );
- , , docker-registry, ;
- .
, , .
Helm, Draft Helm-, production ready, , Draft Helm-, . .
, Draft , Helm-. Draft — .
2. Helm
Helm Charts Kubernetes-, Helm Charts. :
Helm, . , , command line interface, Chart , git push .
, docker build, docker push kubectl rollout. , Helm, . .
3.
— . —
Metaparticle . , Python, Python , .
, , , sysconfig .. .
, , , - Kubernetes-.
: , ; , ; ..

, , , - , Python- Kubernetes-. ?
- , . . , , preinstall , - . Kubernetes-, Metaparticle, .
, , Kubernetes- . , , Metaparticle.
Metaparticle, Helm . , .
Telepresence/Ksync — . , , Helm-, . , - , - , , . , Production-, Production - .
Kubernetes , Docker, registry, Kubernetes. . , .
, , , Development . : , , , , — , , , Helm, , .
, .
4. Kubernetes Kubernetes
, Kubernetes Kubernetes. , Helm- , . , . , Docker-compose .
Docker-compose , , , , Docker, Kubernetes, Docker-compose, . , . , Docker. .
minikube , Docker-compose, . , , Docker-compose — 10 . , .
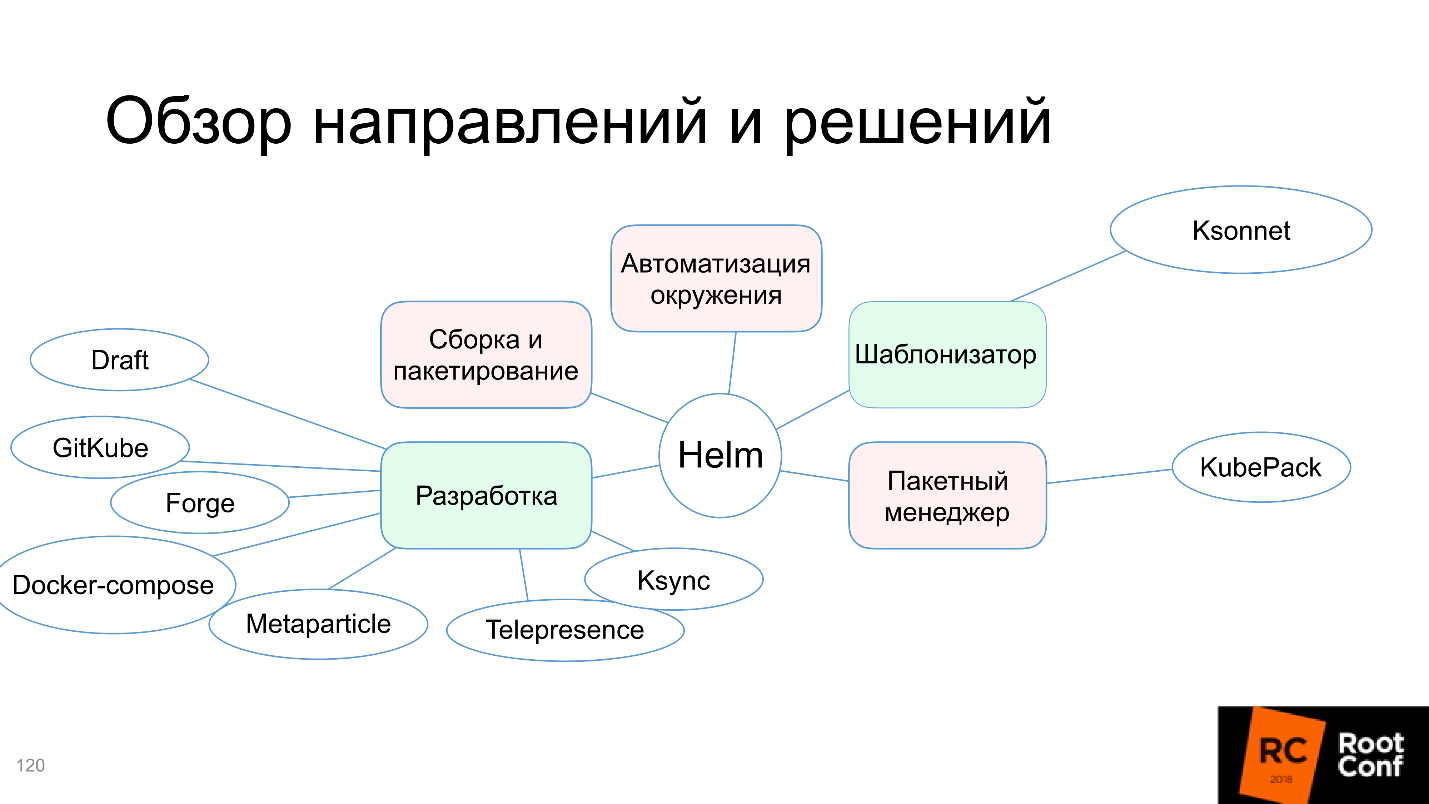
Docker-compose, , .
, — Helm, , , Helm - . CI/CD, , . — Helm, ? , , .
CI/CD, , docker', set-, , — .
CI/CD — , .
Résumé

5 Helm . , . , , . , , , .
Helm
, , Helm . , Helm , . , , , Helm.
, Road Map.
Kuberneres Helm community , ,
Helm V3 .
Tiller, cli
, . Helm :
- , (cmd ..).
- Tiller — , Kubernetes.
Tiller , Command Line Interface. : « Chart» — Helm , , Tiller', : «, - ! , Kubernetes-» — .
Helm, Tiller , . , , , , Tiller' — namespace . Tiller namespace, , . , .
V3 Tiller .
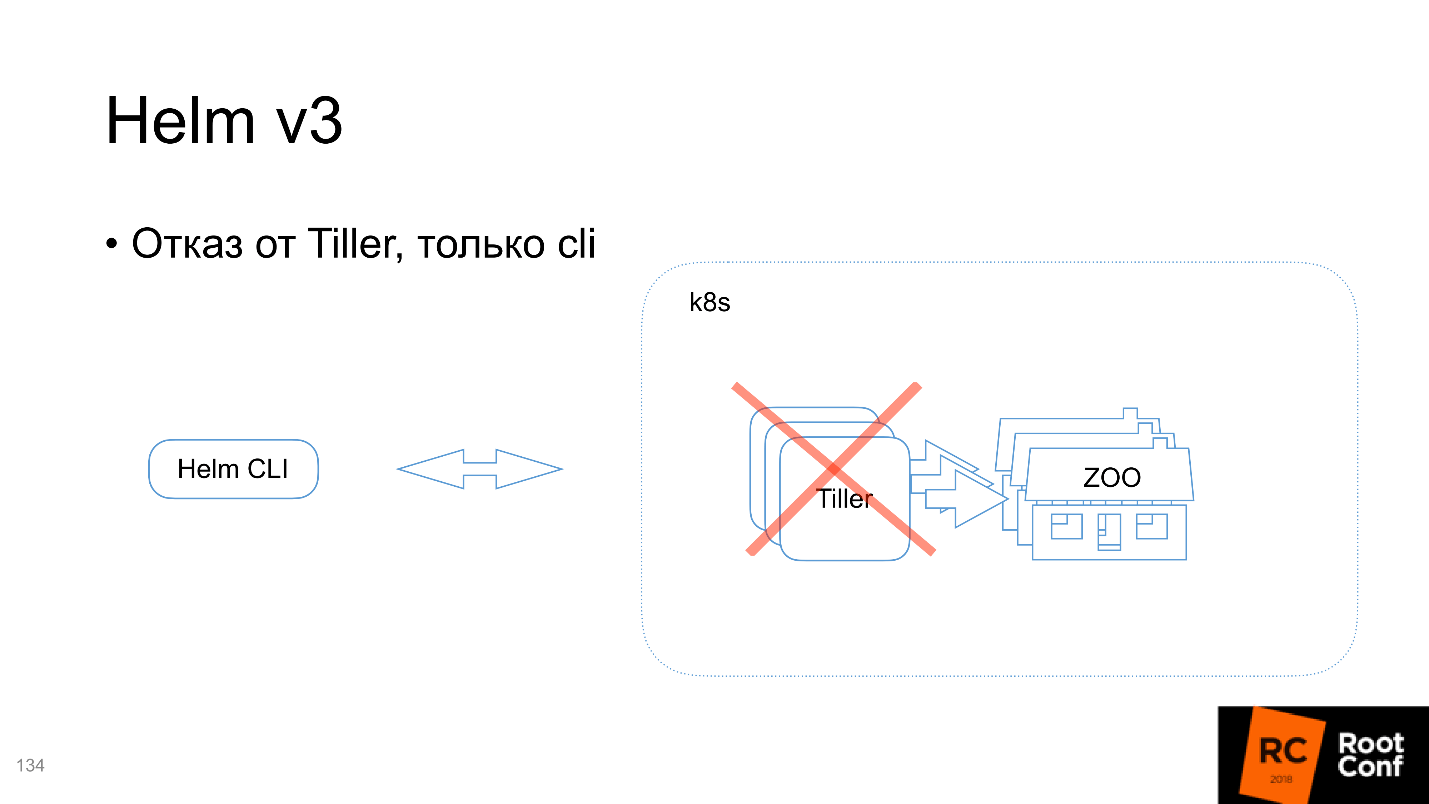
? , , Command Line Interface, , Kubernetes. , Kubernetes , Tiller. kubectl cli .
Tiller
. , Kubernetes Command Line Interface : , , , pre- post-. .
Lua- Chart
, — ,
lua- . Chart lua-, . . , . , , , .
Lua , , , - , , .
, , . , . Kubernetes, - , , , , . Voyons ce qui se passe.
Release- + secret
, ,
Release- , Release . , Release-, , , CRD, , .
namespace
Release- namespace, , -
Tiller' namespace — , .
CRD: controller
, CRD-controller Helm , push-. .
, .

,
Helm . , , , . , , . Helm — - Kubernetes. - , , .
,
CI/CD , .
Slack, nous avons un bot qui signale quand une nouvelle build est passée en master, et que tous les tests ont réussi. Vous lui dites: "Je veux l'installer dans Staging" - et il installe, vous dites: "Je veux y faire un test!" - et il commence. Assez confortable.Pour le développement, utilisez Docker-compose ou Telepresence.Plusieurs versions d'un service
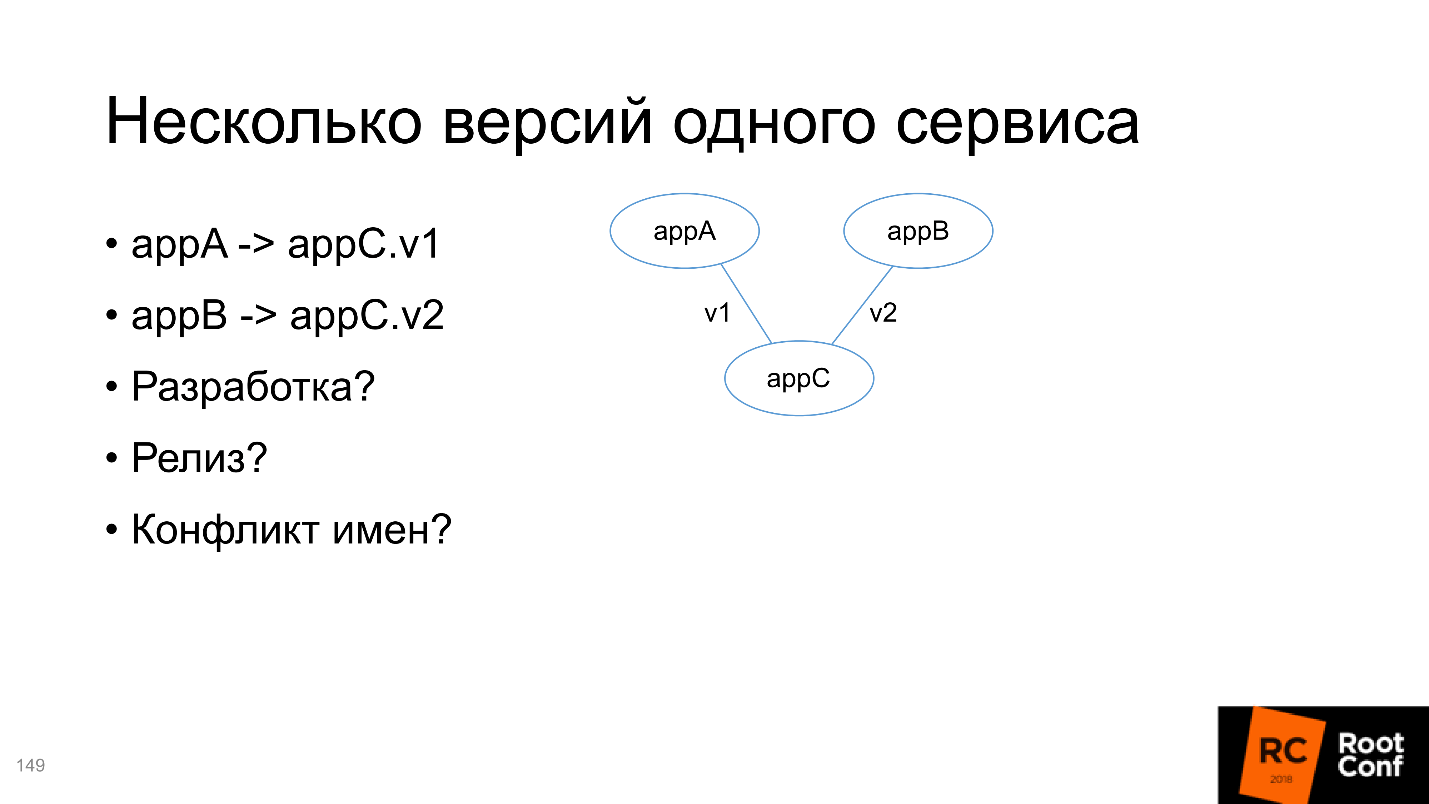
Au final, nous analyserons la situation lorsqu'il y a deux applications A et B, qui dépendent de C, mais C de versions différentes. Besoin de résoudre ce problème:
- pour le développement, car en fait nous devons développer la même chose, mais deux versions différentes;
- pour publication;
- pour un conflit de noms, car dans tous les gestionnaires de packages standard, l'installation de deux packages de versions différentes peut entraîner des problèmes.
En fait, Kubernetes décide de tout pour nous - il vous suffit de l'utiliser correctement.

Je conseillerais de créer 4 graphiques en termes de Helm, 3 référentiels (pour le référentiel C, ce ne seront que deux branches différentes). Ce qui est le plus intéressant, toutes les installations pour v1 et pour v2 doivent contenir en elles-mêmes des informations sur la version ou pour quel service elle a été créée. Une solution sur la diapositive, annexe C; le nom de la version indique qu'il s'agit de la version v1 pour le service A; le nom du service contient également la version. Ceci est l'exemple le plus simple, vous pouvez le faire complètement différemment. Mais la chose la plus importante est que les noms sont uniques.
Le second est les dépendances transitives, et ici c'est plus compliqué.
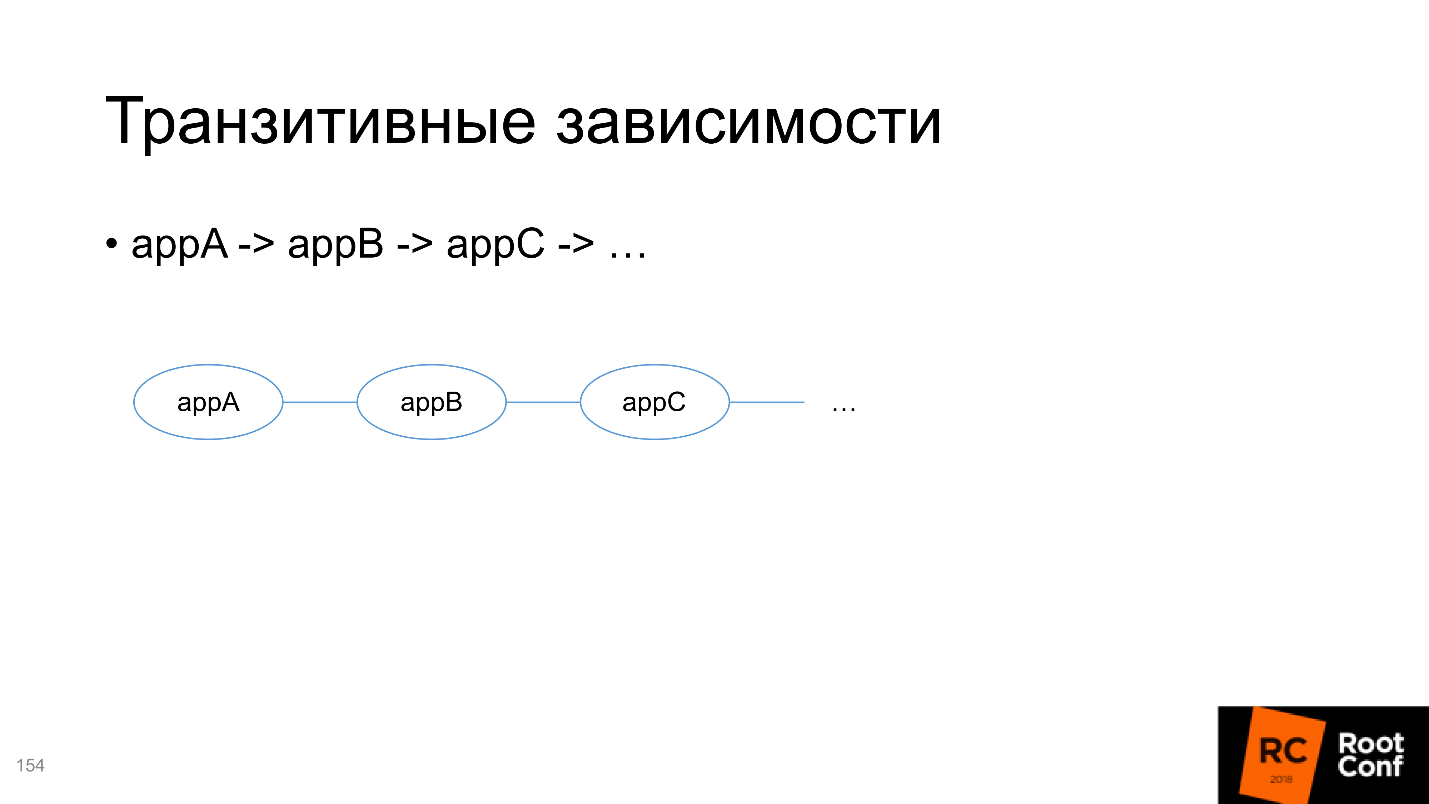
Par exemple, vous développez une chaîne de services et souhaitez tester A. Pour cela, vous devez transférer toutes les dépendances dont dépend A, y compris transitive, dans la définition Helm de votre package. Mais en même temps, vous souhaitez développer B et le tester également - comment le faire est incompréhensible, car vous devez également y mettre toutes les dépendances transitives.
Par conséquent, je vous conseille de ne pas ajouter toutes les dépendances à l'intérieur de chaque package, mais de les rendre indépendantes et du contrôle extérieur de ce qui est en cours d'exécution. C'est gênant, mais c'est le moindre de deux maux.
Liens utiles
•
Brouillon•
GitKube•
Heaume•
Ksonnet• Autocollants de télégramme:
un ,
deux•
Sig-Apps•
KubePack•
Métaparticule•
Skaffold•
Helm v3•
Docker-compose•
Ksync•
Téléprésence•
Drone•
ForgeProfil du conférencier Ivan Glushkov sur
GitHub , sur
Twitter , sur
Habr .
Bonne nouvelle
Sur notre chaîne YouTube, nous avons ouvert une vidéo de tous les reportages sur DevOps du festival RIT ++ . Il s'agit d'une liste de lecture distincte, mais dans la liste complète des vidéos, il y a beaucoup de choses utiles d'autres conférences.
Mieux encore, abonnez-vous à la chaîne et à la newsletter , car l'année prochaine nous aurons beaucoup de devops : en mai, le framework de RIT ++; au printemps, en été et en automne en tant que section de HighLoad ++, et en automne DevOpsConf Russie .