Il existe différentes manières de gérer les erreurs dans les langages de programmation:
- exceptions standard pour de nombreux langages (Java, Scala et autres JVM, python et bien d'autres)
- codes d'état ou drapeaux (Go, bash)
- diverses structures de données algébriques, dont les valeurs peuvent être à la fois des résultats réussis et des descriptions d'erreurs (Scala, haskell et autres langages fonctionnels)
Les exceptions sont très largement utilisées, en revanche elles sont souvent dites lentes. Mais les opposants à une approche fonctionnelle font souvent appel à la performance.
Récemment, j'ai travaillé avec Scala, où je peux également utiliser à la fois des exceptions et divers types de données pour la gestion des erreurs, je me demande donc quelle approche sera plus pratique et plus rapide.
Nous éliminerons immédiatement l'utilisation de codes et de drapeaux, car cette approche n'est pas acceptée dans les langages JVM et, à mon avis, est trop sujette aux erreurs (je suis désolé pour le jeu de mots). Par conséquent, nous comparerons les exceptions et les différents types d'ADT. De plus, l'ADT peut être considéré comme l'utilisation de codes d'erreur dans un style fonctionnel.
MISE À JOUR : des exceptions sans traces de pile sont ajoutées à la comparaison
Concurrents
Un peu plus sur les types de données algébriquesPour ceux qui ne connaissent pas trop l'ADT ( ADT ) - un type algébrique se compose de plusieurs valeurs possibles, chacune pouvant être une valeur composite (structure, enregistrement).
Un exemple est le type Option[T] = Some(value: T) | None Option[T] = Some(value: T) | None , qui est utilisé à la place de nulls: une valeur de ce type peut être Some(t) s'il existe une valeur, ou None si elle ne l'est pas.
Un autre exemple serait Try[T] = Success(value: T) | Failure(exception: Throwable) Try[T] = Success(value: T) | Failure(exception: Throwable) , qui décrit le résultat d'un calcul qui pourrait se terminer avec succès ou avec une erreur.
Alors nos concurrents:
- Bonnes vieilles exceptions
- Exceptions sans trace de pile, car remplir une trace de pile est une opération très lente
Try[T] = Success(value: T) | Failure(exception: Throwable) Try[T] = Success(value: T) | Failure(exception: Throwable) - les mêmes exceptions, mais dans un wrapper fonctionnelEither[String, T] = Left(error: String) | Right(value: T) Either[String, T] = Left(error: String) | Right(value: T) - un type contenant soit le résultat, soit une description de l'erreurValidatedNec[String, T] = Valid(value: T) | Invalid(errors: List[String]) ValidatedNec[String, T] = Valid(value: T) | Invalid(errors: List[String]) - un type de la bibliothèque Cats qui, en cas d'erreur, peut contenir plusieurs messages sur différentes erreurs (pas tout à fait List utilisé ici, mais cela n'a pas d'importance)
NOTE en substance, les exceptions sont comparées à la trace de pile, sans et ATD, mais plusieurs types sont sélectionnés, car Scala n'a pas d'approche unique et il est intéressant d'en comparer plusieurs.
En plus des exceptions, des chaînes sont utilisées pour décrire les erreurs, mais avec le même succès dans une situation réelle, différentes classes seraient utilisées ( Either[Failure, T] ).
Le problème
Pour tester la gestion des erreurs, nous prenons le problème de l'analyse et de la validation des données:
case class Person(name: String, age: Int, isMale: Boolean) type Result[T] = Either[String, T] trait PersonParser { def parse(data: Map[String, String]): Result[Person] }
c'est-à-dire ayant une Map[String, String] données brutes Map[String, String] vous devez obtenir Person ou une erreur si les données ne sont pas valides.
Jeter
Une solution au front en utilisant des exceptions (ci-après je ne donnerai que la fonction person , vous pouvez voir le code complet sur github ):
Throwparser.scala
def person(data: Map[String, String]): Person = { val name = string(data.getOrElse("name", null)) val age = integer(data.getOrElse("age", null)) val isMale = boolean(data.getOrElse("isMale", null)) require(name.nonEmpty, "name should not be empty") require(age > 0, "age should be positive") Person(name, age, isMale) }
ici string , integer et boolean valident la présence et le format des types simples et effectuent la conversion.
En général, c'est assez simple et compréhensible.
ThrowNST (aucune trace de pile)
Le code est le même que dans le cas précédent, mais les exceptions sont utilisées sans trace de pile dans la mesure du possible: ThrowNSTParser.scala
Essayez
La solution intercepte les exceptions plus tôt et permet de combiner les résultats via for (à ne pas confondre avec les boucles dans d'autres langues):
TryParser.scala
def person(data: Map[String, String]): Try[Person] = for { name <- required(data.get("name")) age <- required(data.get("age")) flatMap integer isMale <- required(data.get("isMale")) flatMap boolean _ <- require(name.nonEmpty, "name should not be empty") _ <- require(age > 0, "age should be positive") } yield Person(name, age, isMale)
un peu plus inhabituel pour un œil fragile, mais en raison de l'utilisation de for , il est très similaire à la version avec des exceptions, de plus, la validation de la présence d'un champ et l'analyse du type souhaité se produisent séparément ( flatMap peut être lu ici and then )
Soit
Ici, le type Either est caché derrière l'alias de Result puisque le type d'erreur est fixe:
EitherParser.scala
def person(data: Map[String, String]): Result[Person] = for { name <- required(data.get("name")) age <- required(data.get("age")) flatMap integer isMale <- required(data.get("isMale")) flatMap boolean _ <- require(name.nonEmpty, "name should not be empty") _ <- require(age > 0, "age should be positive") } yield Person(name, age, isMale)
Puisque le standard Either comme Try forme une monade dans Scala, le code est exactement le même, la différence ici est que la chaîne apparaît ici comme une erreur et que les exceptions sont utilisées de manière minimale (uniquement pour gérer les erreurs lors de l'analyse d'un nombre)
Validée
Ici, la bibliothèque Cats est utilisée pour obtenir non pas la première chose qui s'est produite, mais autant que possible (par exemple, si plusieurs champs n'étaient pas valides, le résultat contiendra des erreurs d'analyse pour tous ces champs)
ValidatedParser.scala
def person(data: Map[String, String]): Validated[Person] = { val name: Validated[String] = required(data.get("name")) .ensure(one("name should not be empty"))(_.nonEmpty) val age: Validated[Int] = required(data.get("age")) .andThen(integer) .ensure(one("age should be positive"))(_ > 0) val isMale: Validated[Boolean] = required(data.get("isMale")) .andThen(boolean) (name, age, isMale).mapN(Person) }
ce code est déjà moins similaire à la version originale avec des exceptions, mais la vérification des restrictions supplémentaires n'est pas dissociée des champs d'analyse et nous obtenons toujours plusieurs erreurs au lieu d'une, ça vaut le coup!
Test
Pour les tests, un ensemble de données a été généré avec un pourcentage d'erreurs différent et analysé dans chacune des manières.
Résultat sur tous les pourcentages d'erreurs:

Plus en détail, avec un faible pourcentage d'erreurs (le temps est différent ici car un plus grand échantillon a été utilisé):
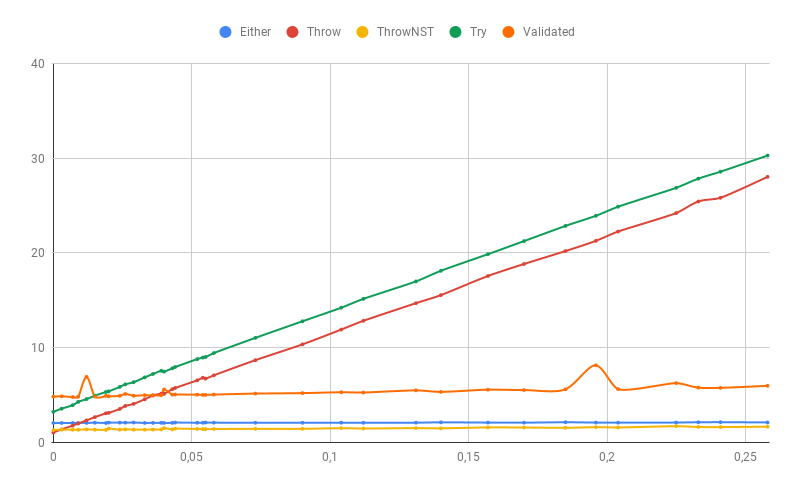
Si une partie des erreurs est toujours une exception avec la trace de pile (dans notre cas, l'erreur d'analyse du nombre sera une exception que nous ne contrôlons pas), alors bien sûr, les performances des méthodes de gestion des erreurs «rapides» se détérioreront considérablement. Validated particulièrement affecté, car il collecte toutes les erreurs et, par conséquent, reçoit une exception lente plus que les autres:

Conclusions
Comme l'expérience l'a montré, les exceptions avec des traces de pile sont vraiment très lentes (100% des erreurs font la différence entre Throw et Either plus de 50 fois!), Et quand il n'y a pratiquement aucune exception, l'utilisation d'ADT a un prix. Cependant, l'utilisation d'exceptions sans traces de pile est aussi rapide (et avec un faible pourcentage d'erreurs plus rapide) que ADT, cependant, si ces exceptions vont au-delà de la même validation, le suivi de leur source ne sera pas facile.
Au total, si la probabilité d'une exception est supérieure à 1%, les exceptions sans traces de pile fonctionnent plus rapidement, Validated ou régulières. Les Either presque aussi rapides. Avec un grand nombre d'erreurs, l'une Either peut être un peu plus rapide que Validated uniquement en raison d'une sémantique rapide.
L'utilisation d'ADT pour la gestion des erreurs offre un autre avantage par rapport aux exceptions: la possibilité d'une erreur est câblée dans le type lui-même et il est plus difficile à manquer, comme lors de l'utilisation d' Option au lieu de null.