Salut C'est une histoire sur les nouveautés de notre plugin de base de données. Nous le
publions en tant que produit
DataGrip distinct et l'expédions à presque tous nos autres IDE. Il y aura de nombreuses photos et gifs. Pour ceux qui sont trop paresseux pour les regarder:
- Assistance Cassandra
- Création de fichiers SQL à partir d'objets de schéma
- Nouvelles inspections
- Beaucoup de nouveaux morceaux de saisie semi-automatique
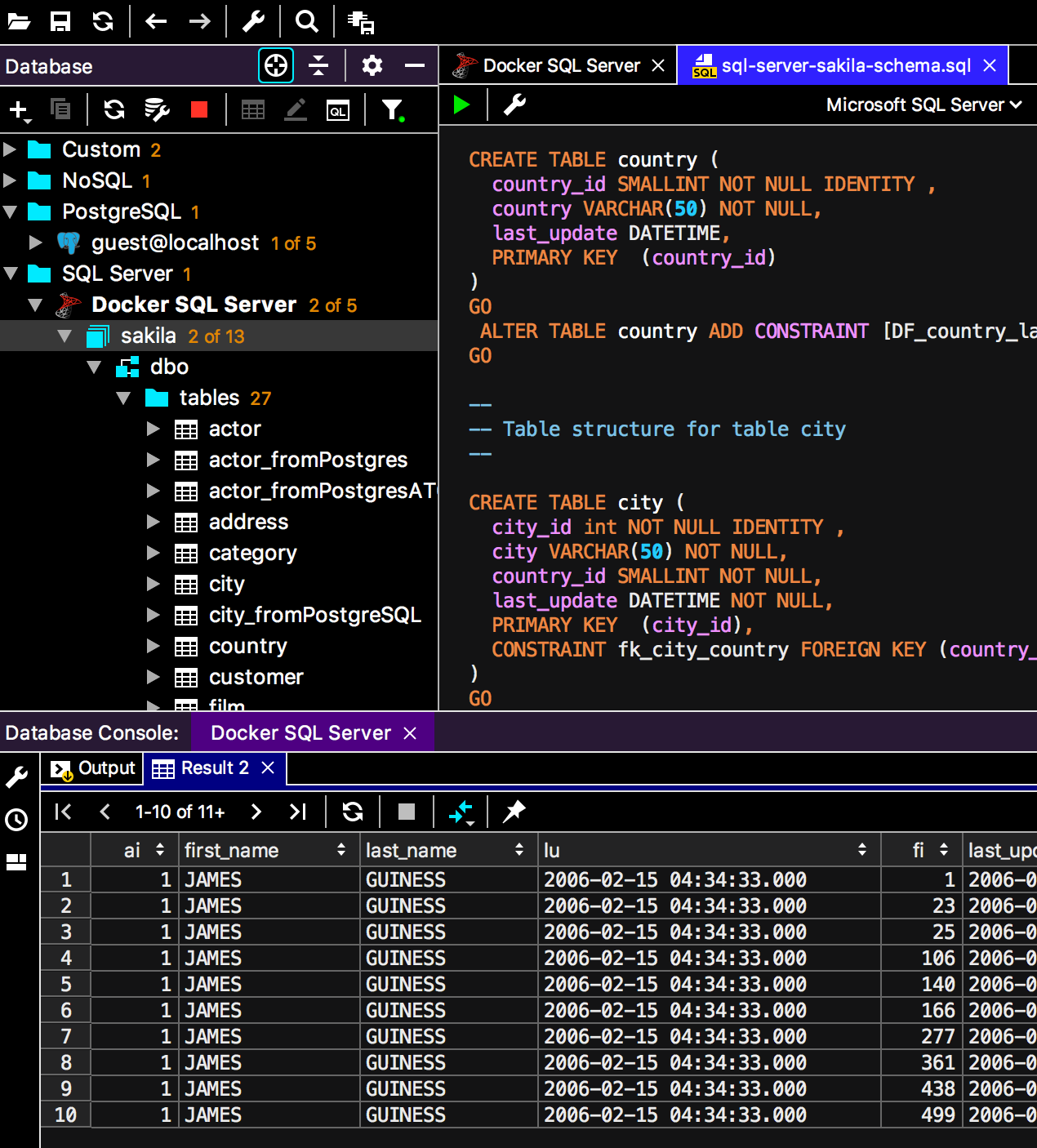
- Travailler avec une source de données via une seule connexion
- Nouvelle recherche
- Jeu de couleurs à contraste élevé
Merci à ceux qui essaient la version EAP et signalent des problèmes à notre tracker: cela aide à ne pas les faire glisser vers la version :) Les utilisateurs actifs ont déjà reçu des abonnements gratuits pendant un an.

Assistance Cassandra
Nous maîtrisons lentement les bases de données NoSQL. Jusqu'à présent, seuls ceux qui utilisent des langages de type SQL pour les requêtes. Nous avons pris en charge Clickhouse en
2018.2.2 , et dans cette version, nous avons ajouté Cassandra.
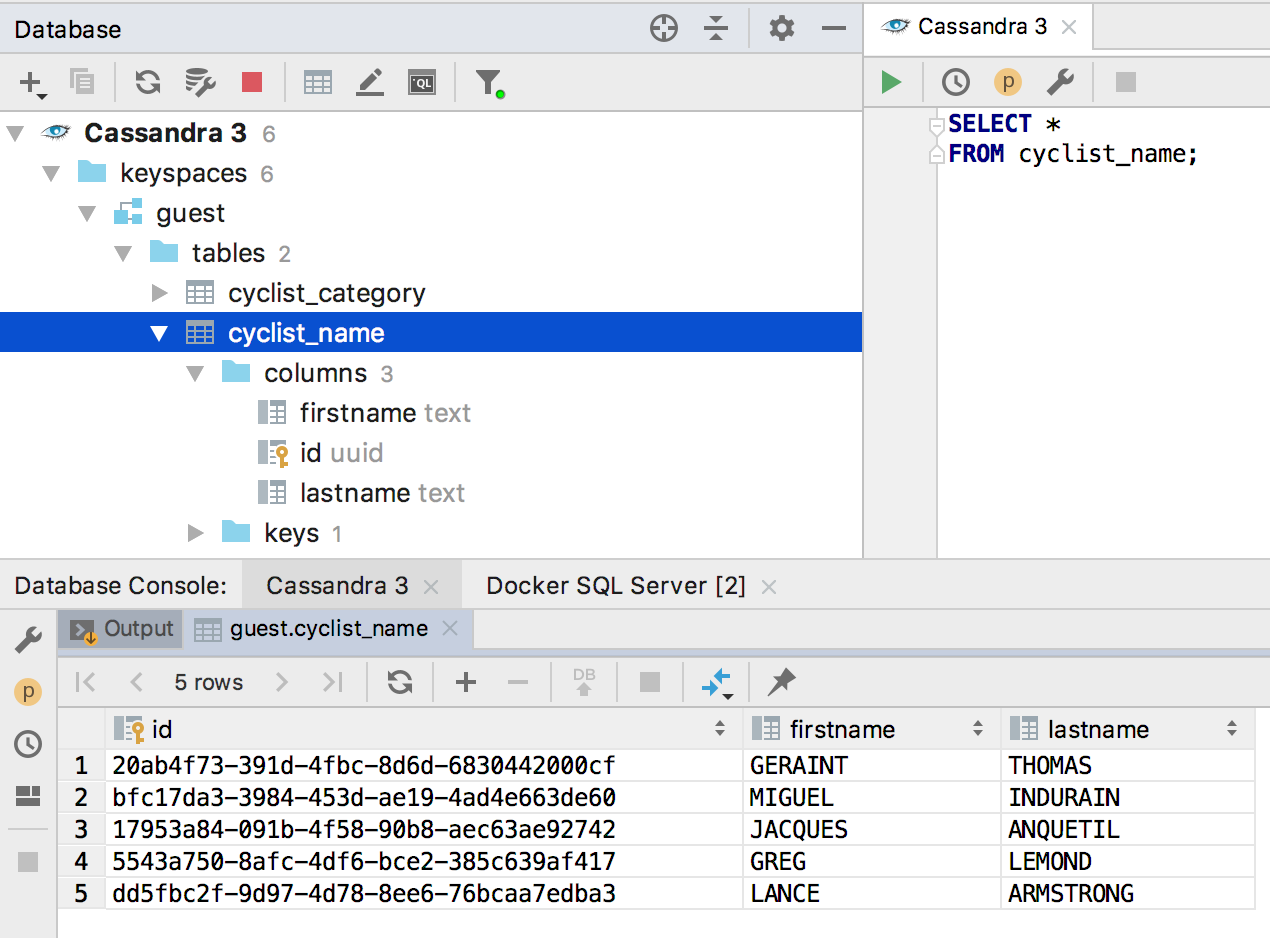
Complétion automatique
Il y a beaucoup de nouveautés dans ce sous-système.
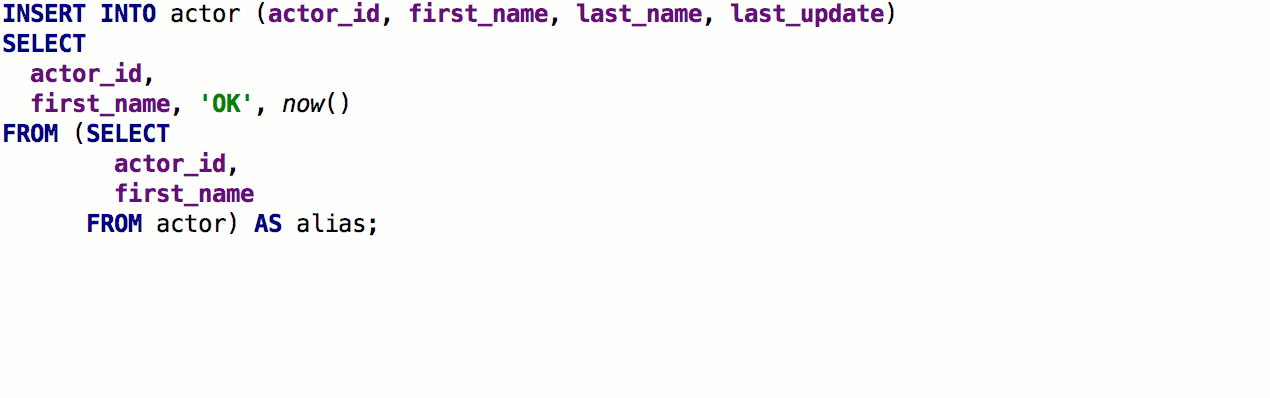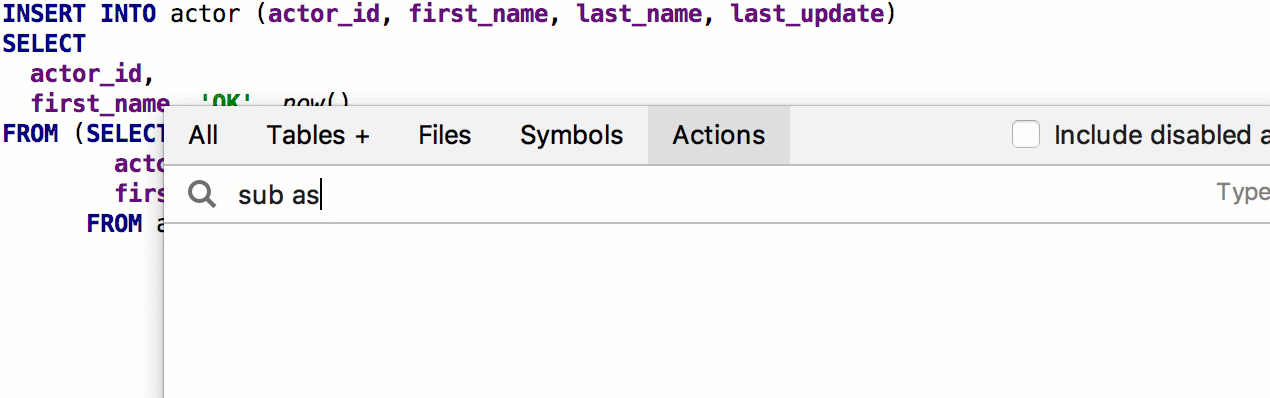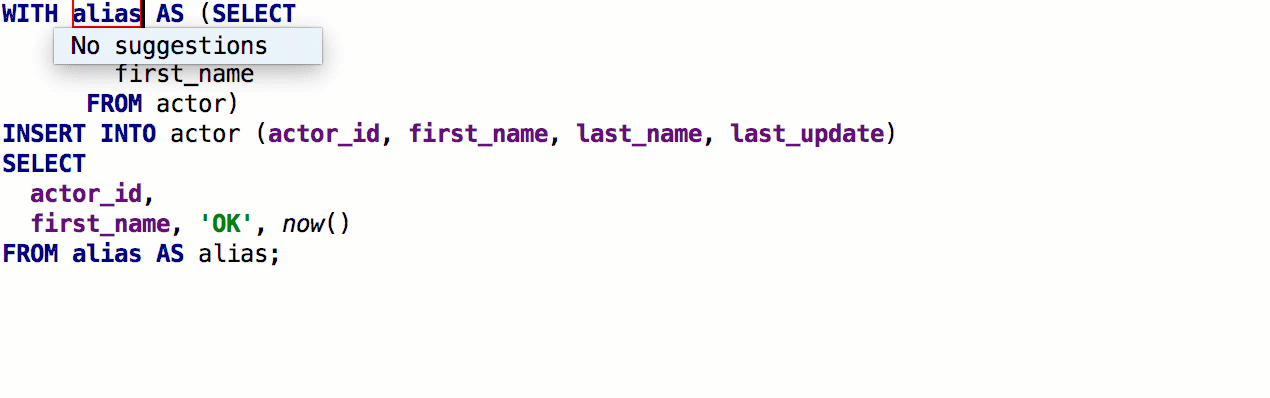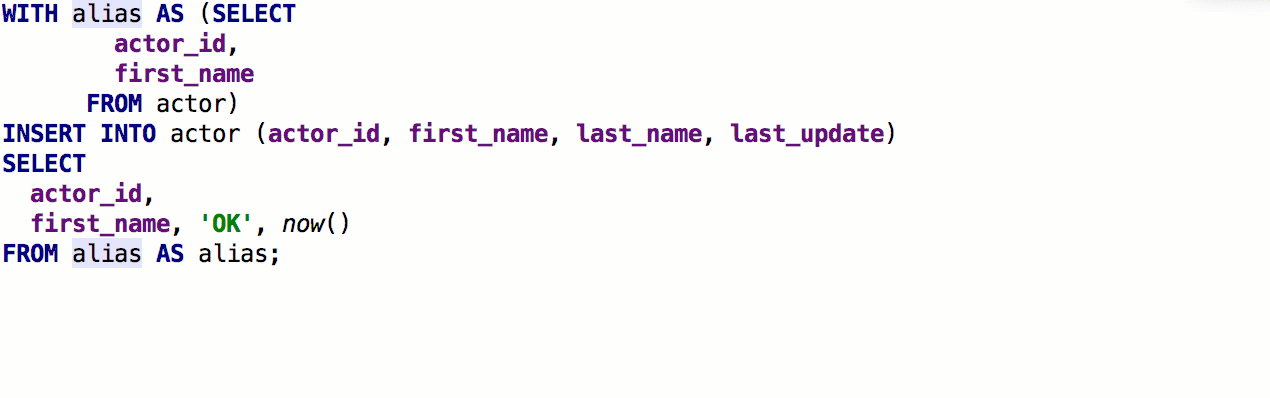
Ajout de la possibilité d'insérer
automatiquement des alias après les noms de table. Si le pseudonyme que nous vous proposons ne vous convient pas, indiquez les pseudonymes à utiliser pour des noms spécifiques.
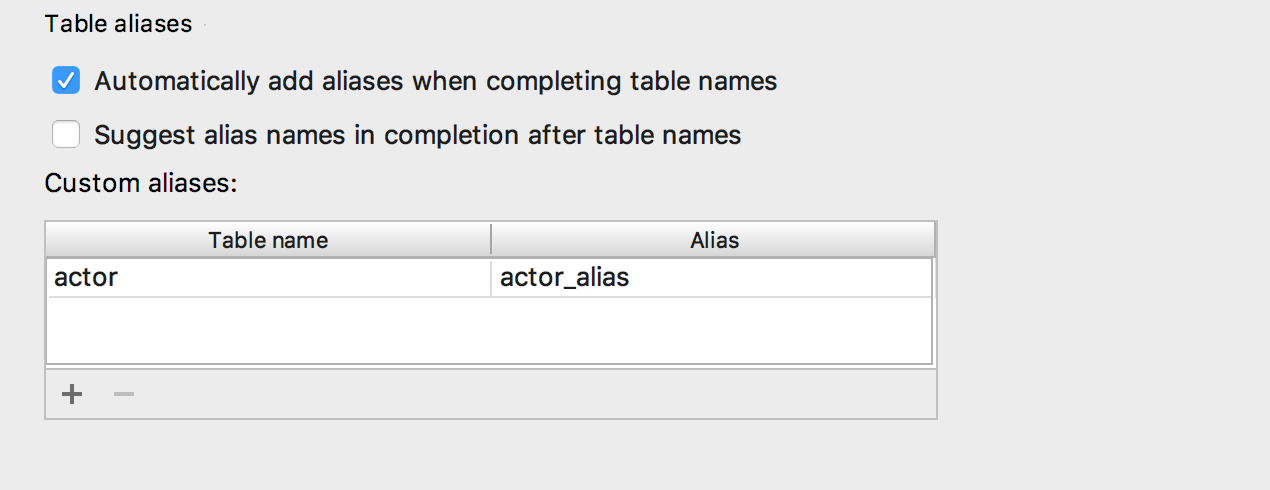
En conséquence, cela fonctionne comme ceci:
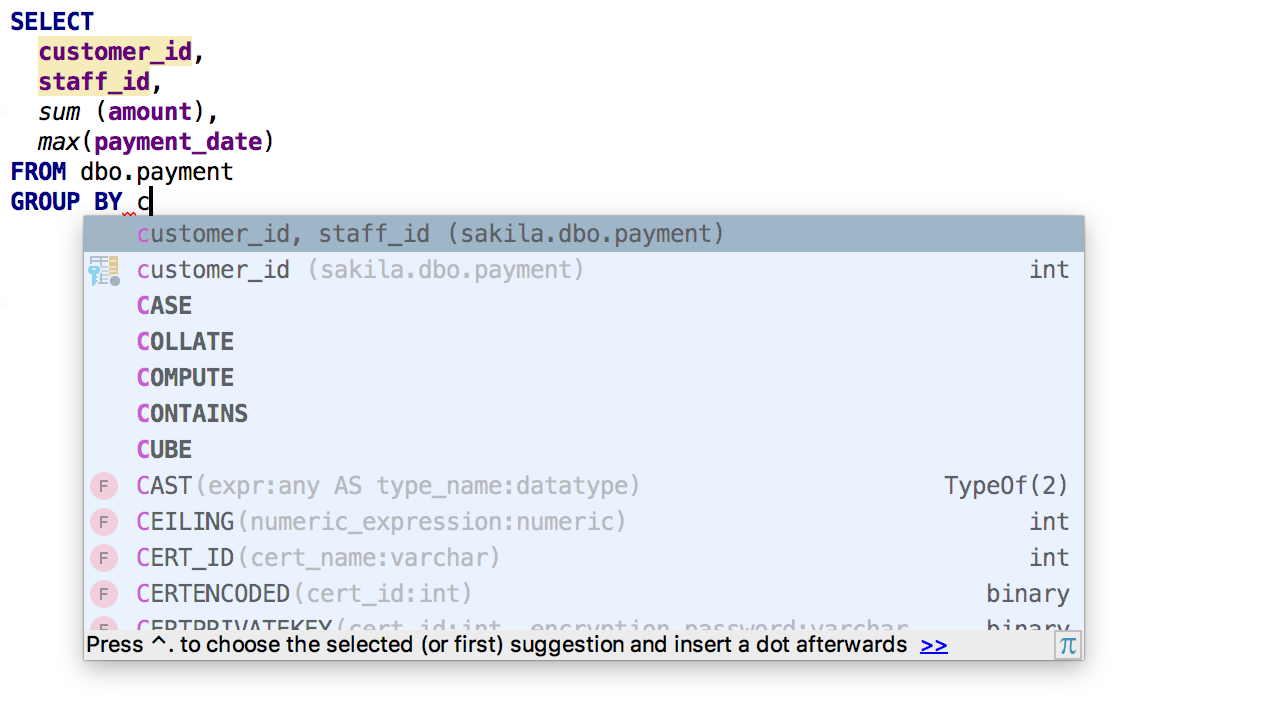
Lorsque vous utilisez
GROUP BY, DataGrip propose une liste de
colonnes non agrégées .
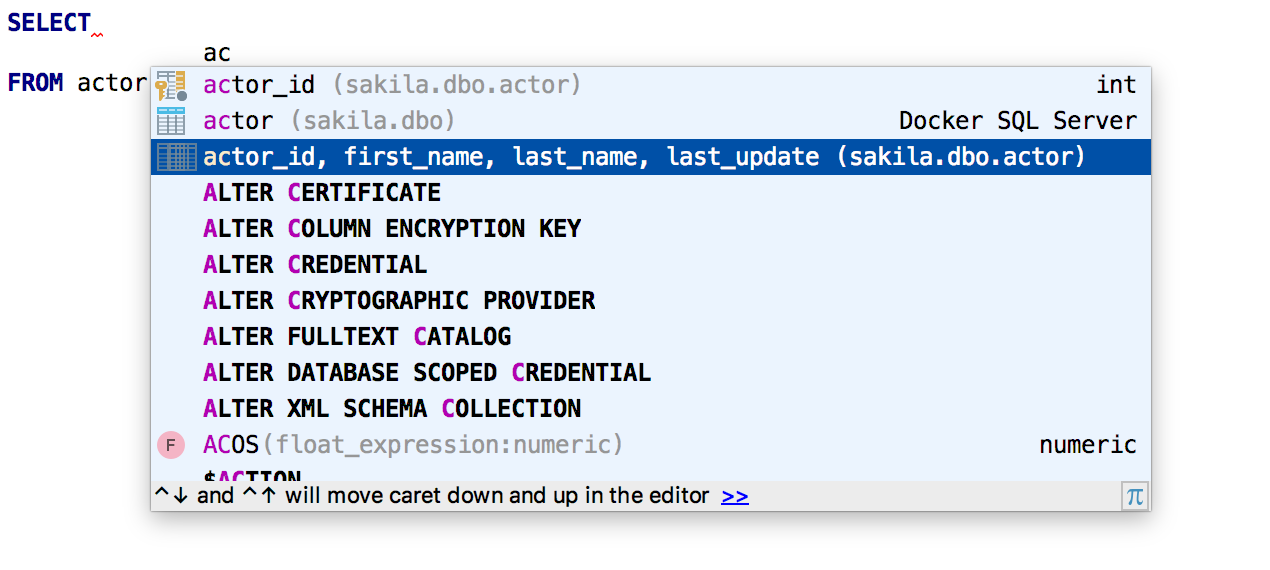
La clause SELECT propose une
liste de toutes les colonnes .
La complétion automatique fonctionne pour les
paramètres nommés .
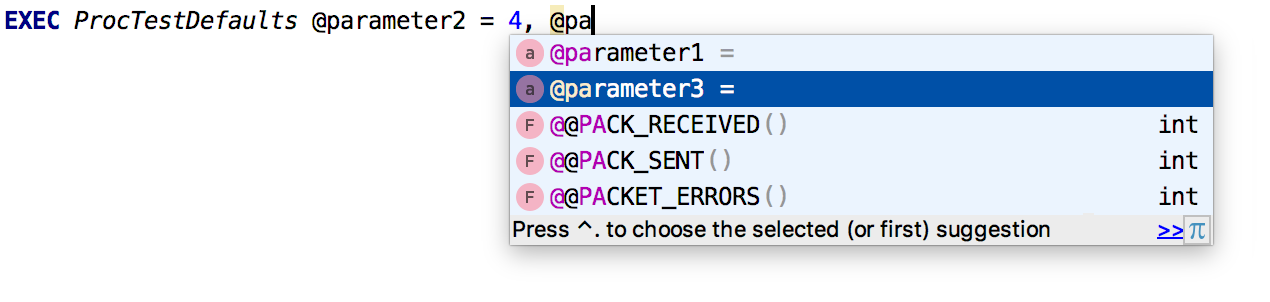
Nous avons également ajouté des informations de
contexte pour des noms identiques.
Finalement terminé le
postfix : c'est à ce moment qu'ils écrivent quelque chose en rapport avec l'objet.

Par exemple, si après
SELECT vous écrivez le nom de Table.afrom, la
clause FROM est développée dans la liste des colonnes. Ou, à notre avis, le plus pratique, vous pouvez ajouter .cast à une colonne ou une variable.
Mieux vaut voir une fois:

La saisie semi-automatique est devenue meilleure pour
les fonctions de fenêtre : OVER () est automatiquement ajouté et le chariot est placé au bon endroit.

Refactoring
Une chose importante qu'il était grand temps de faire
: utiliser un alias au lieu d'une table. Cliquez sur le tableau Alt + Entrée → Introduire l'alias. Les tables d'utilisation seront remplacées par des alias.

Après la version précédente, nous avons reçu un retour détaillé de
speshuric . Par exemple, il a trouvé de nombreux scripts non évidents pour
extraire la sous-requête en tant que CTE. Ce refactoring est appelé via le menu
Refactor → Extract → Subquery as CTE , mais nous vous recommandons de vous habituer à
Find Action (Ctrl + Shift + A).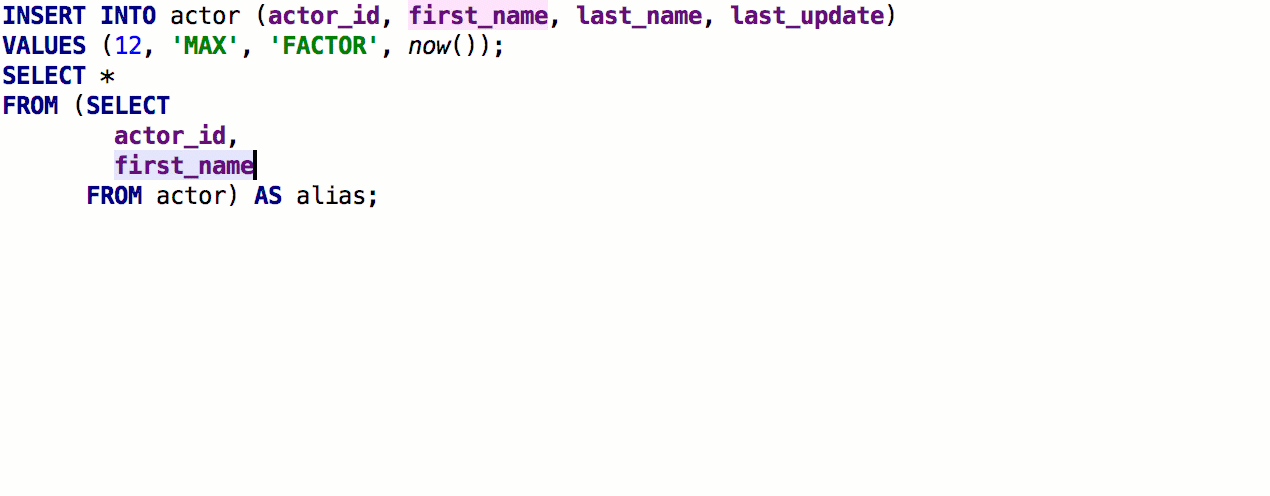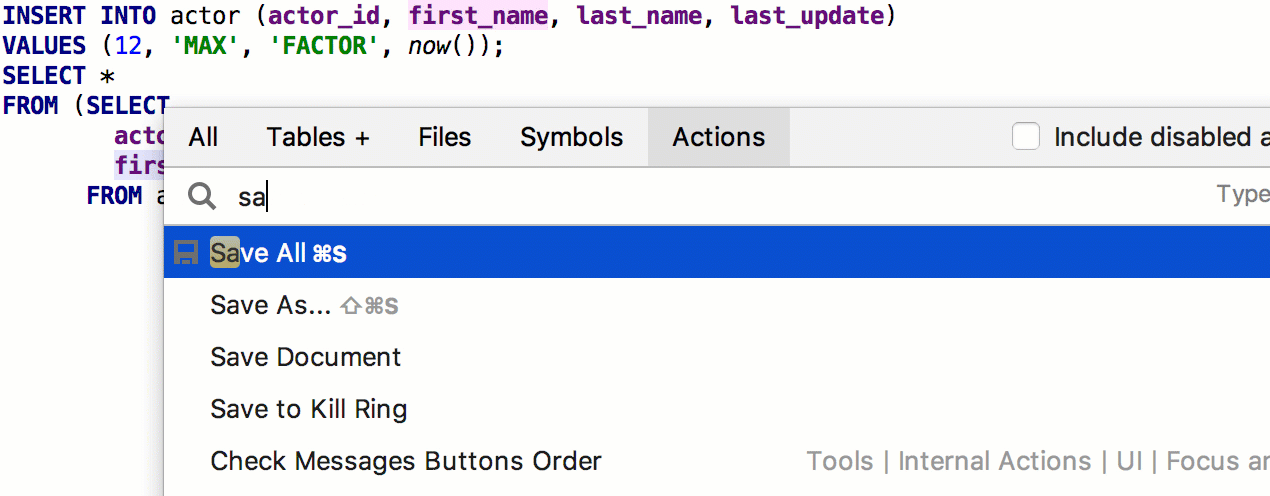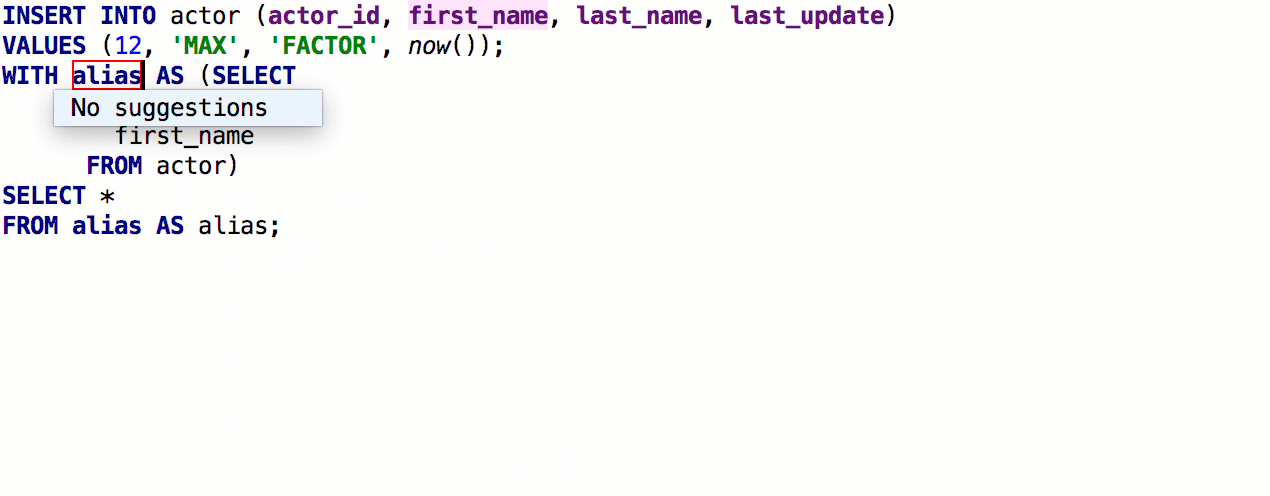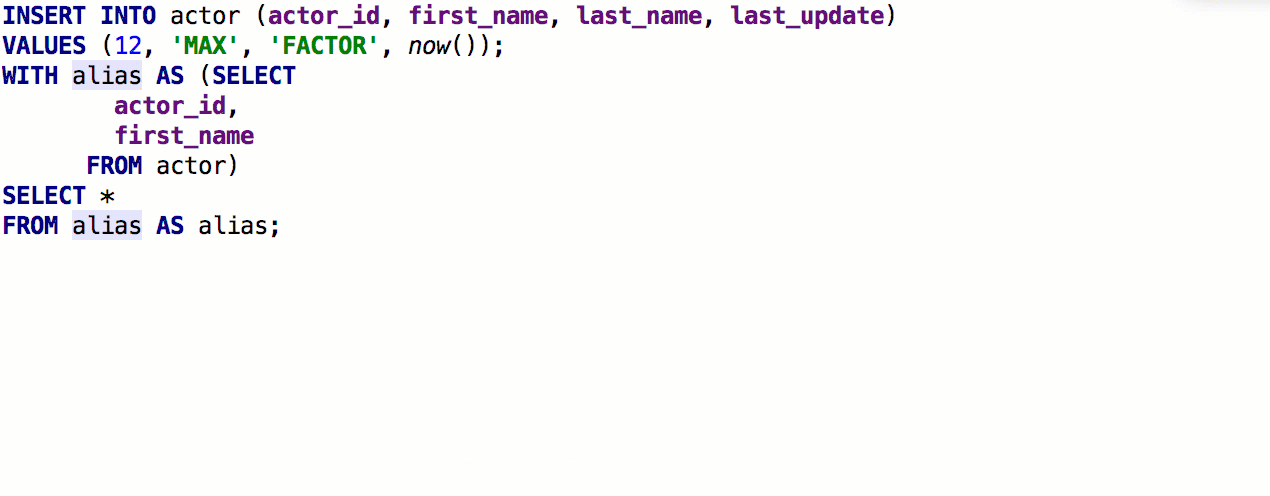
Qu'avons-nous fait:
- Le nouveau nom de CTE n'est pas en conflit avec l'existant:
DBE-6496- Nous déterminons correctement le contexte si la demande est encapsulée dans une autre expression:
DBE-6503 ,
DBE-6517- Nous ne proposons pas de refactoring en cas d'
AS TableName :
DBE-6490- Pris en charge pour MySQL 8.
- Fonctionne comme il se doit avec des sous-requêtes profondes.
DBE-7332 ,
DBE-7333Génération de code
Des modèles de code peuvent être
attachés aux dialectes - un modèle peut fonctionner pour certaines bases et ne pas fonctionner pour d'autres.
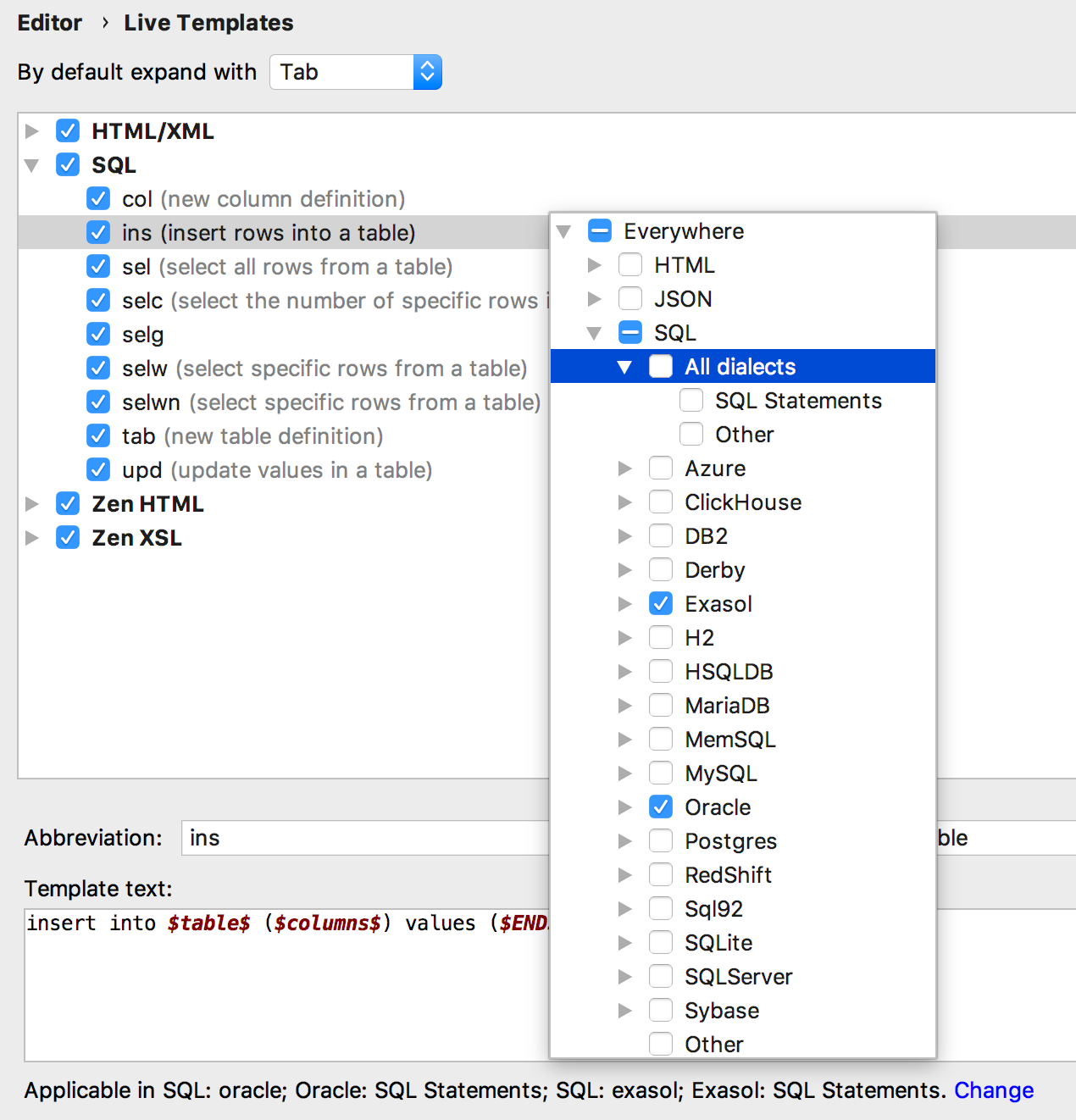
Plus important encore: le même modèle peut générer un code différent pour différentes bases de données. Pour ce faire, créez des groupes de modèles pour chaque dialecte, car les mêmes noms de modèles ne sont pas pris en charge dans le même groupe (par défaut, nous stockons des modèles dans le groupe SQL).
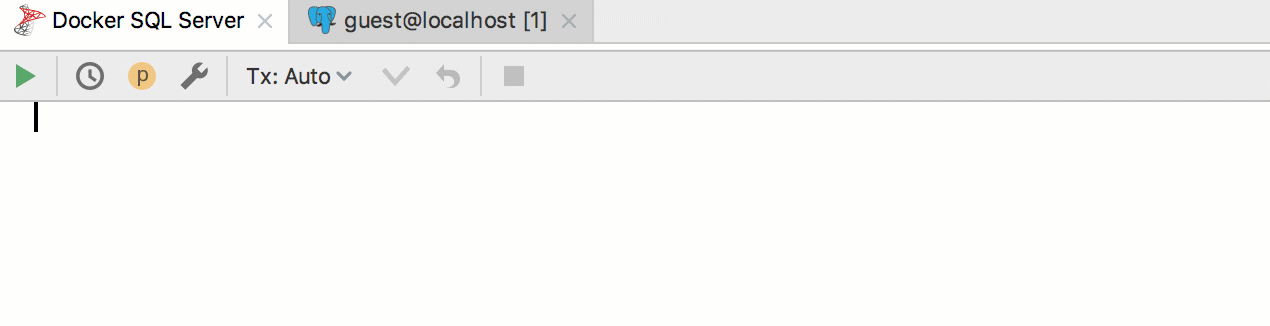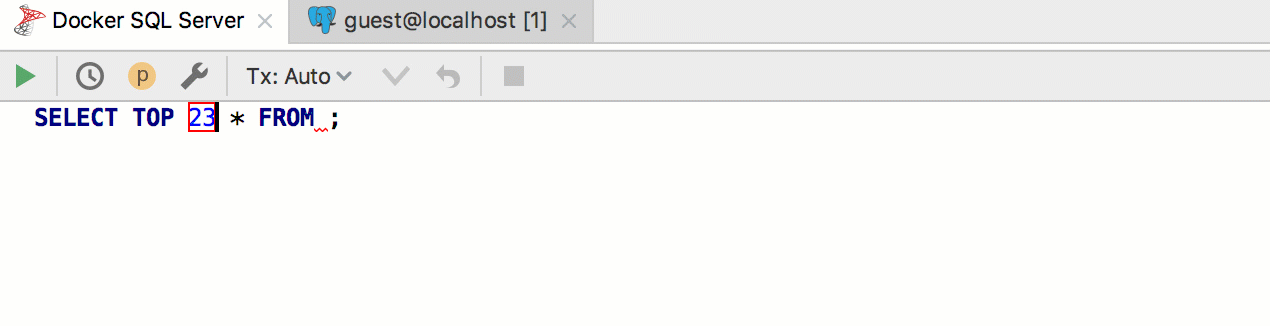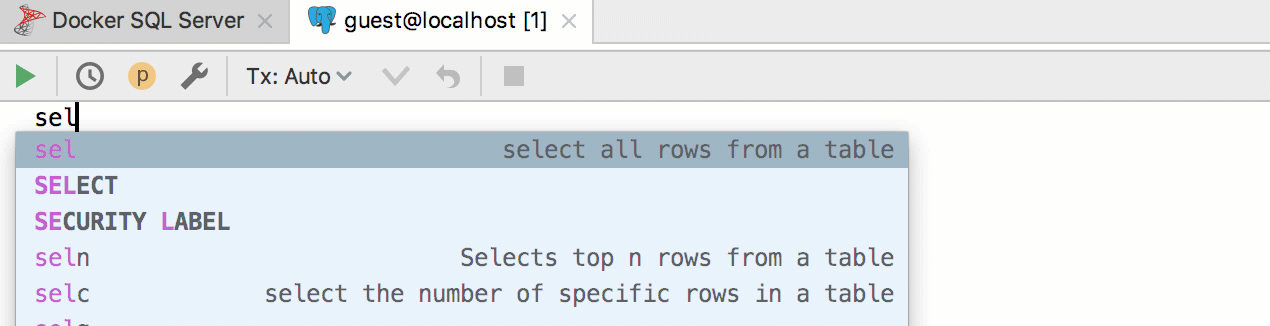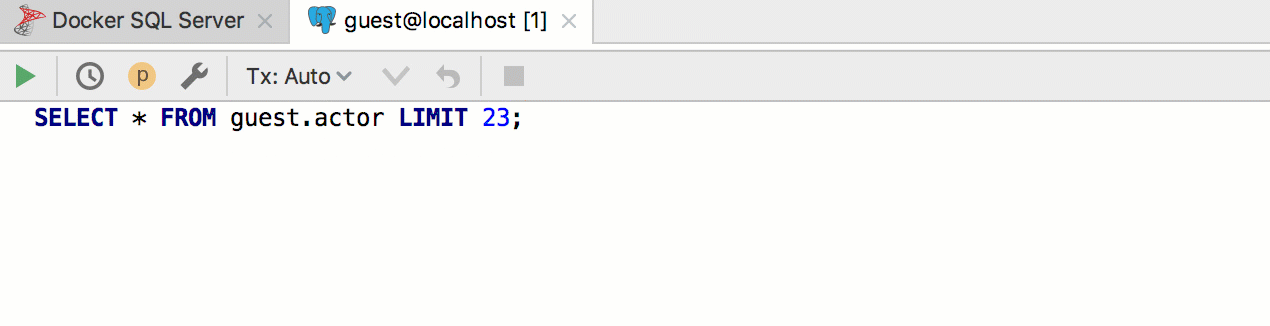
Par exemple, nous voulons créer un modèle pour extraire les n premières lignes d'un tableau. PostgreSQL et SQL Server utilisent une syntaxe différente pour cela, et nous utiliserons toujours le modèle
seln . Par conséquent, implémentez deux modèles dans deux groupes différents et affectez-leur les dialectes correspondants.

Il se présente comme ceci:
À partir de la clause SELECT, vous pouvez maintenant
générer une table avec la même signature. Pour ce faire, appuyez sur
Alt + Entrée -> Créer une définition de table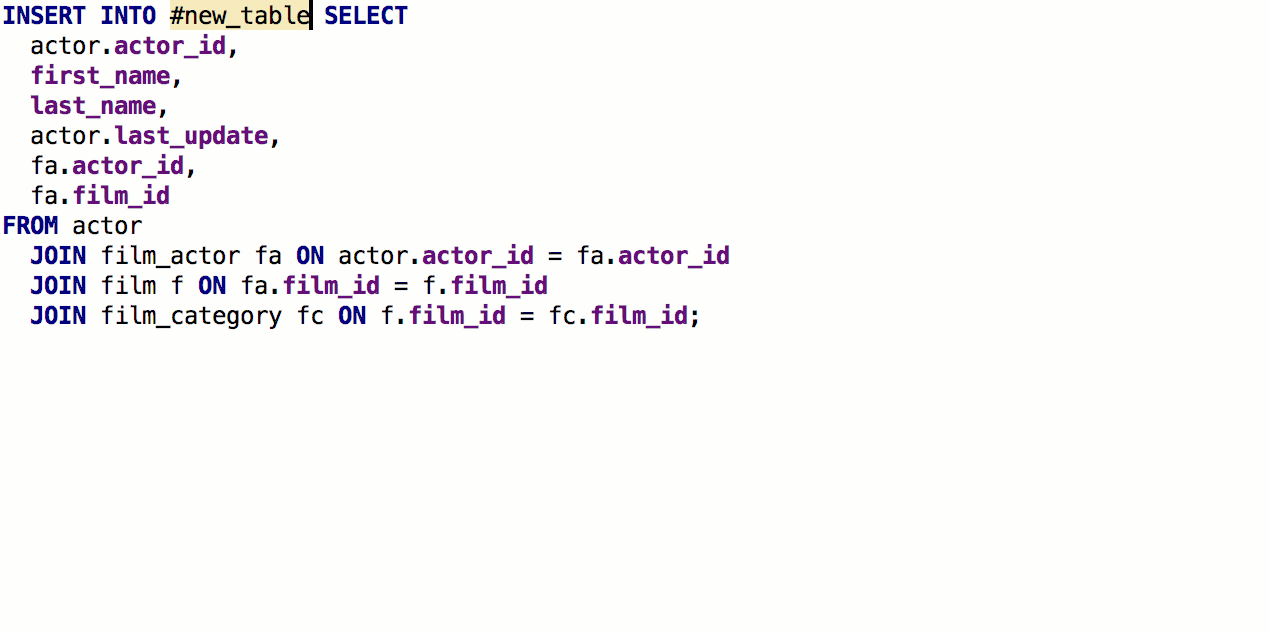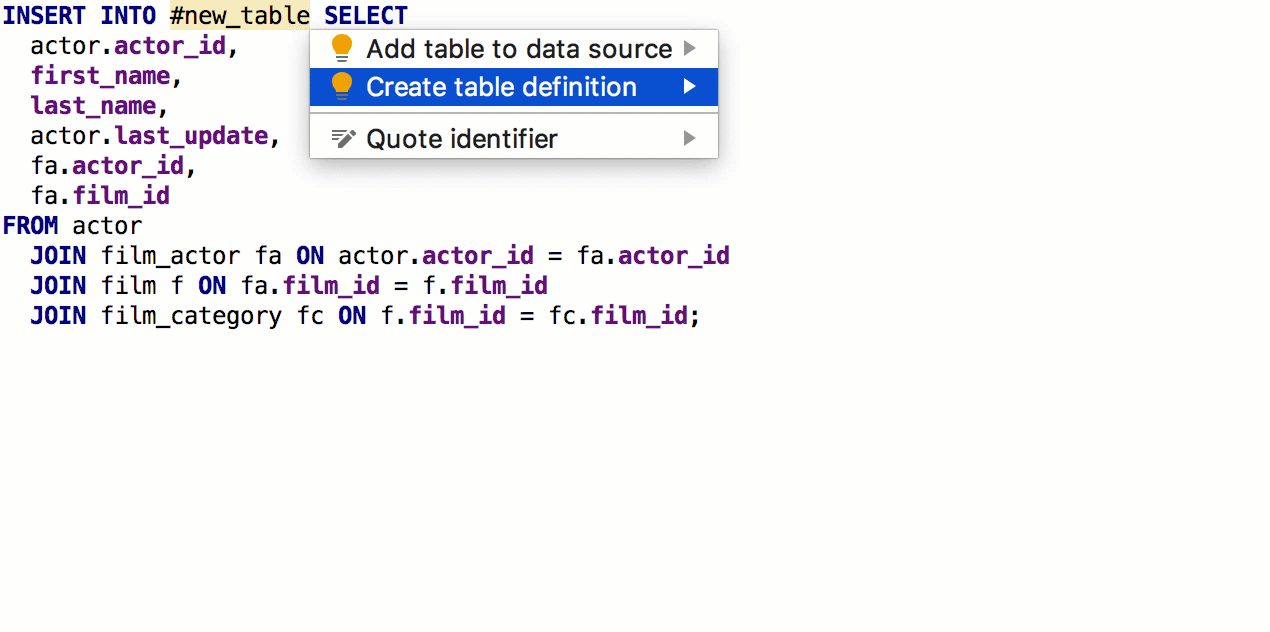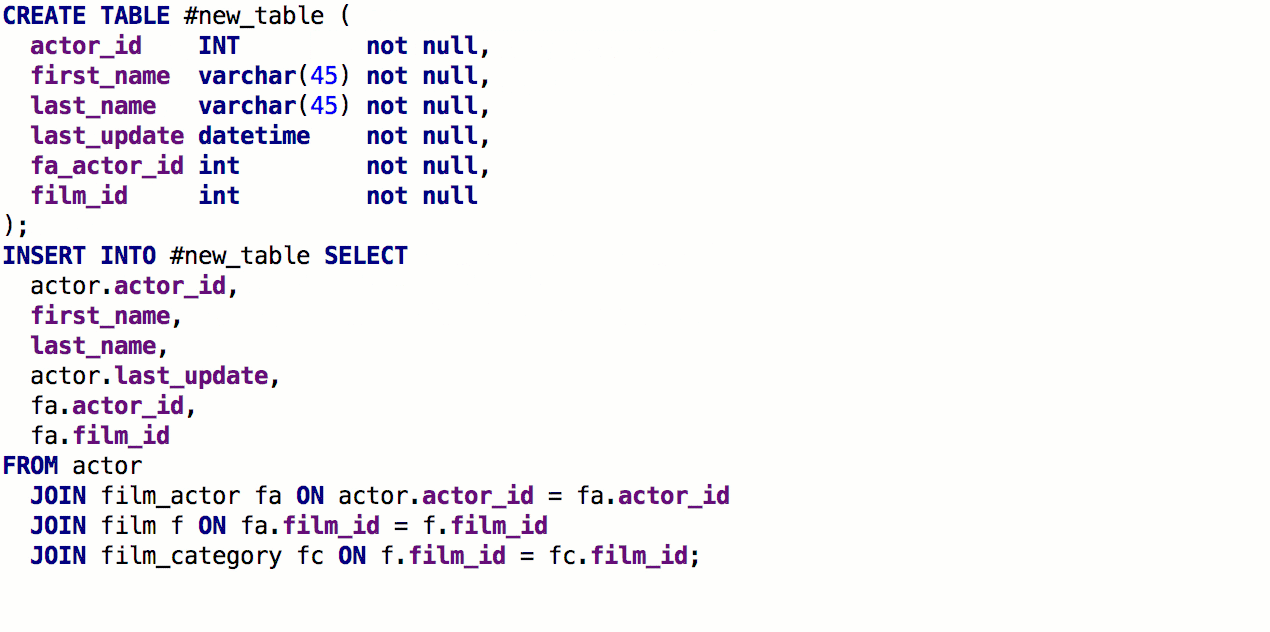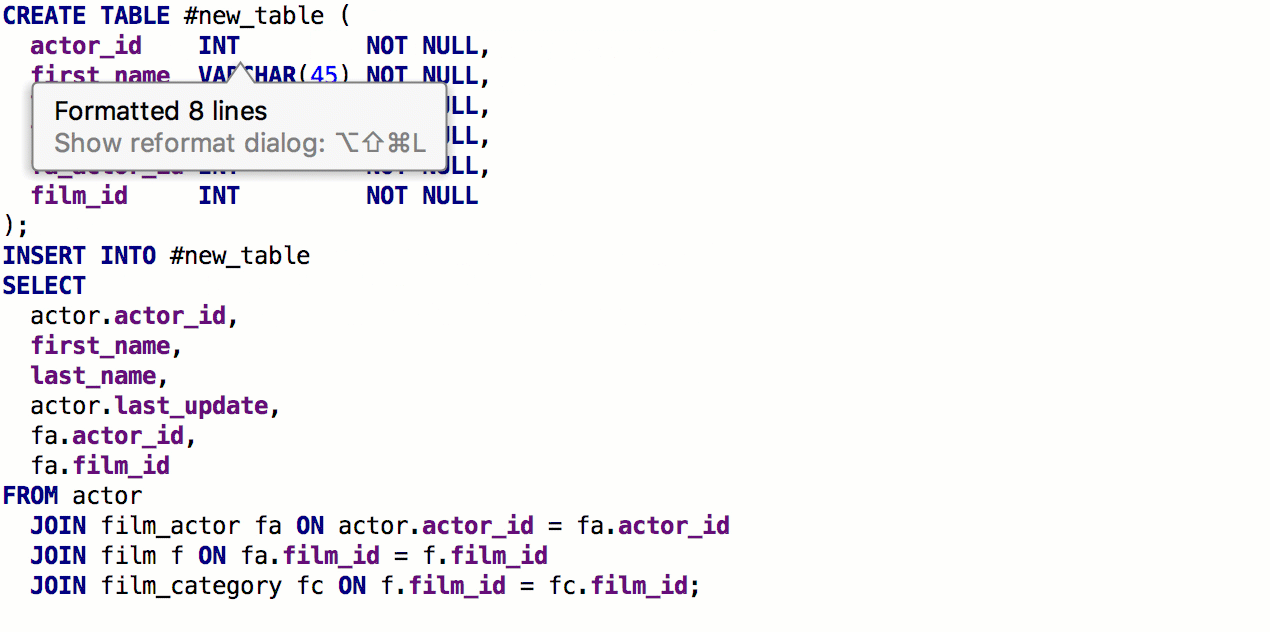
Et un petit correctif pour le modèle
INS - les
info -
bulles pour les noms de colonnes sont affichées automatiquement.

Analyse de code
Nous avons ajouté des inspections concernant la
suppression et la mise à jour
dangereuses - nous vous avertirons que vous perdrez des données.


Et si vous courez, nous clarifierons :)

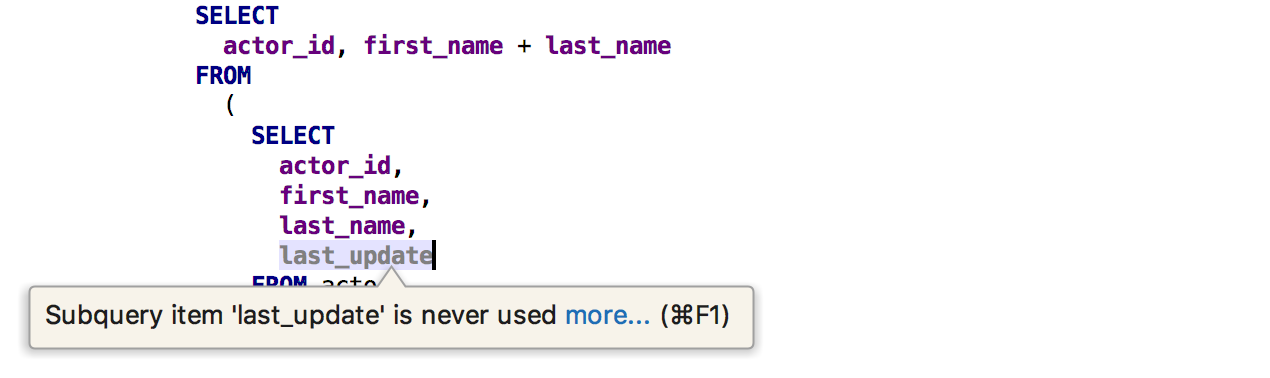
Une autre inspection trouvera les
colonnes inutilisées
de la sous-requête .
Et l'autre est le
code inutilisé.
Objets de base de données
Le générateur SQL (
Ctrl / Cmd + Alt + G ) a appris
à écrire les résultats dans un fichier : pour cela, cliquez sur le bouton
Enregistrer .
Par défaut, deux méthodes d'organisation des fichiers sont disponibles, mais si vous en avez besoin de plus, écrivez dans les commentaires.
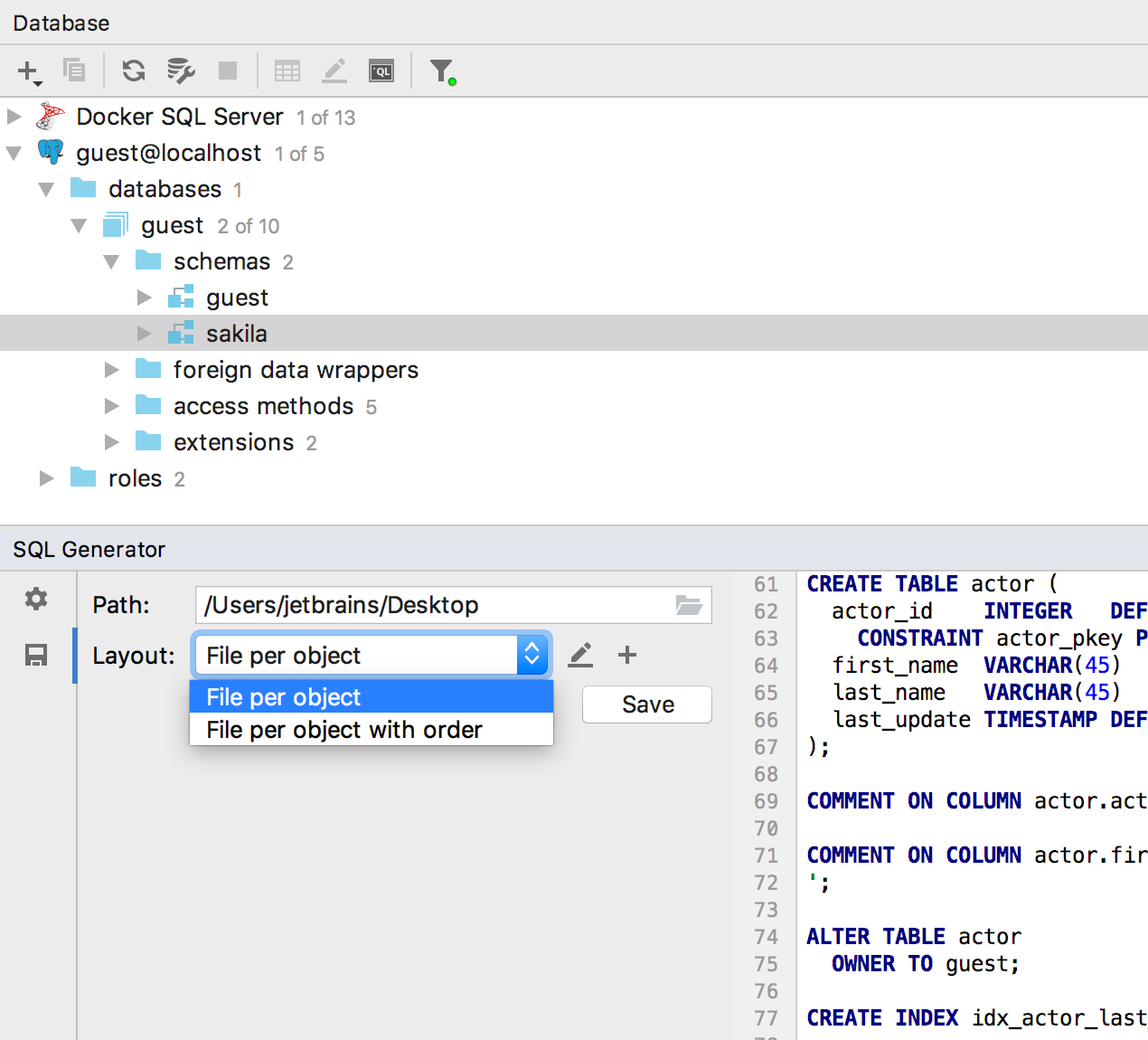
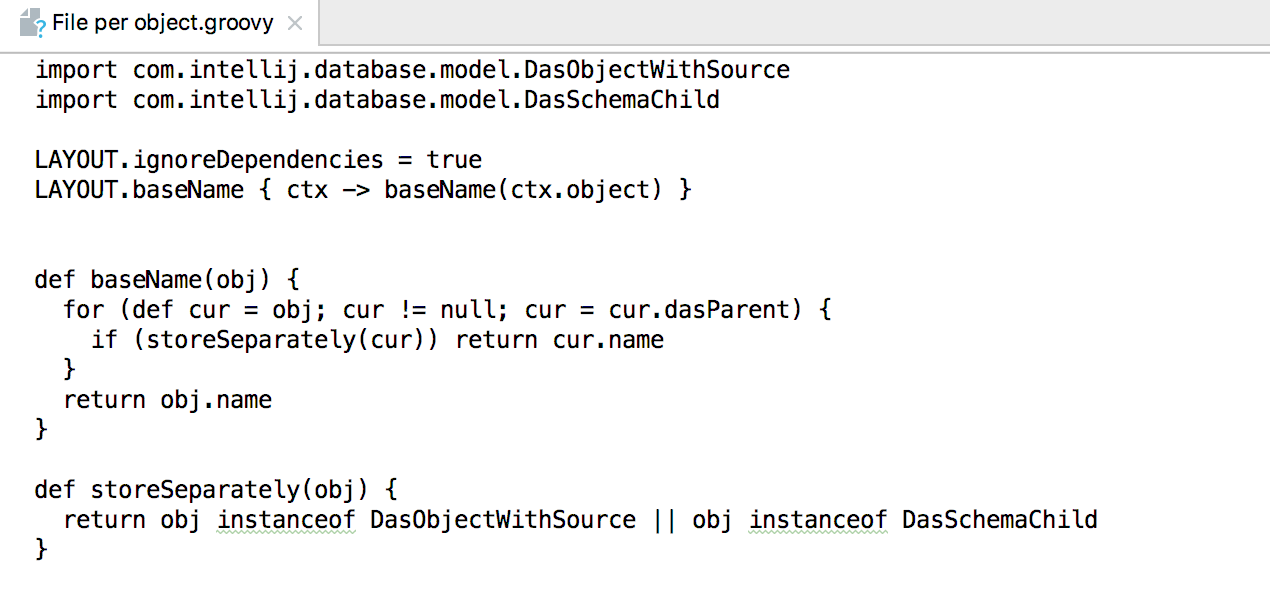
Ou maintenant, si vous cliquez sur le crayon à droite, vous pouvez éditer les scripts correspondants sur groovy. Ou créez le vôtre.
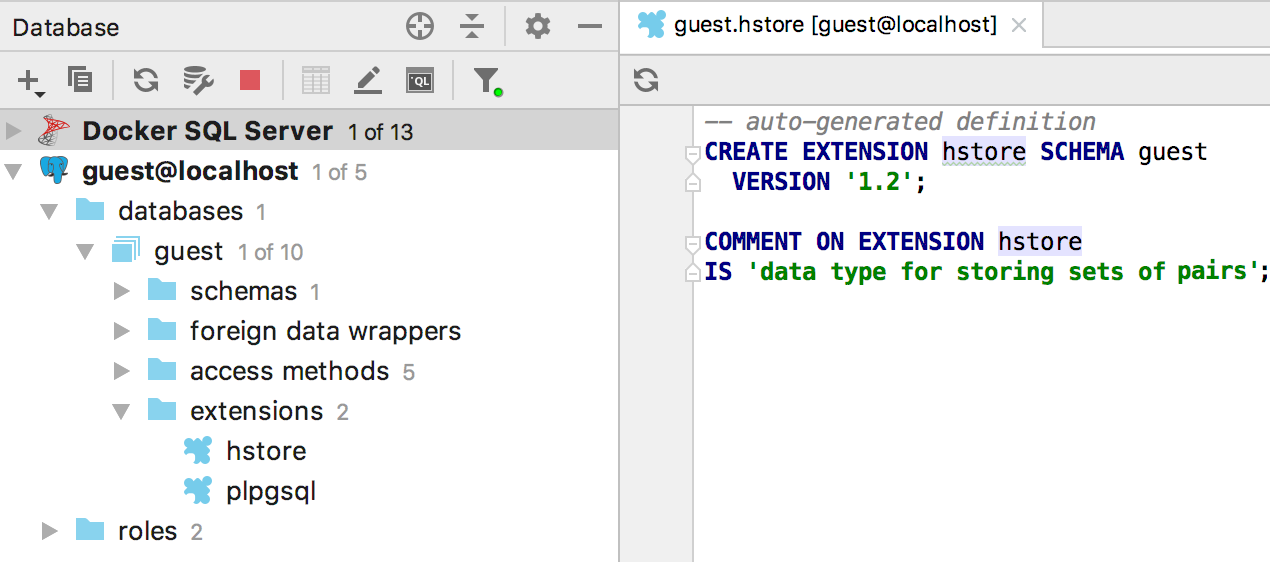
 Extensions
Extensions prises en charge dans PostgreSQL.
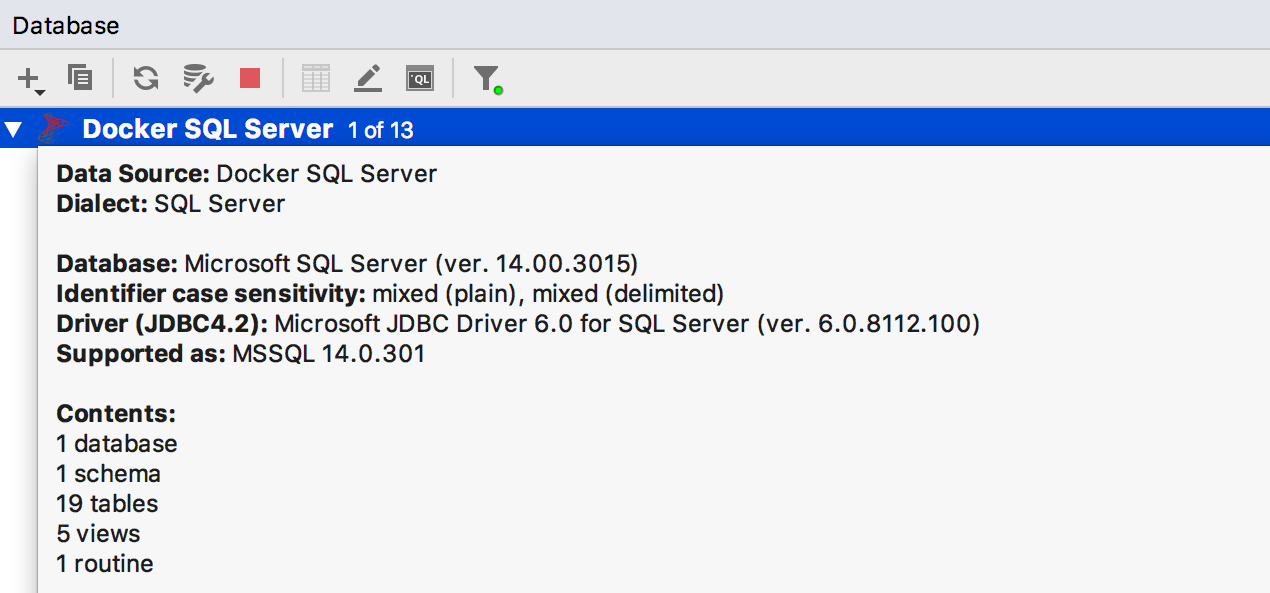
Nous affichons des
statistiques dans la fenêtre d'informations pour la source de données (Ctrl + Q pour Windows / Linux, F1 pour OSX), y compris le nombre d'objets différents.
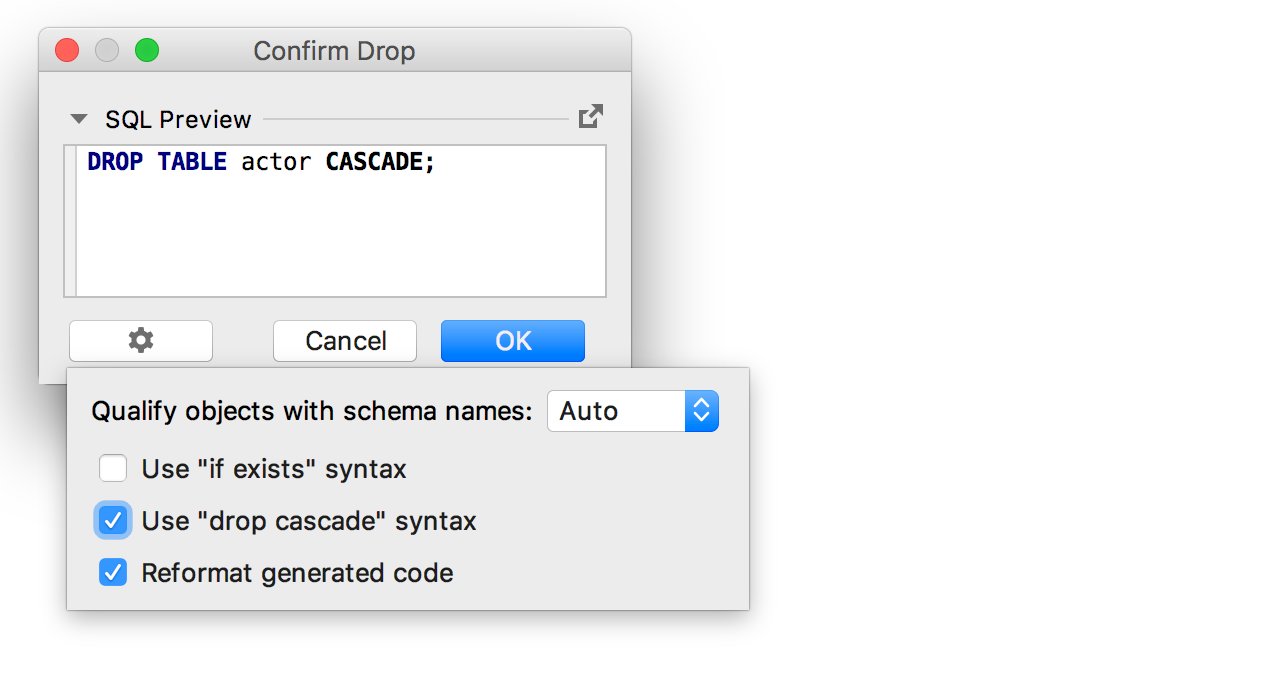
Et lors de la génération du code pour supprimer l'objet, l'option
' Utiliser la syntaxe de cascade de drop ' a été ajoutée.
Connexion
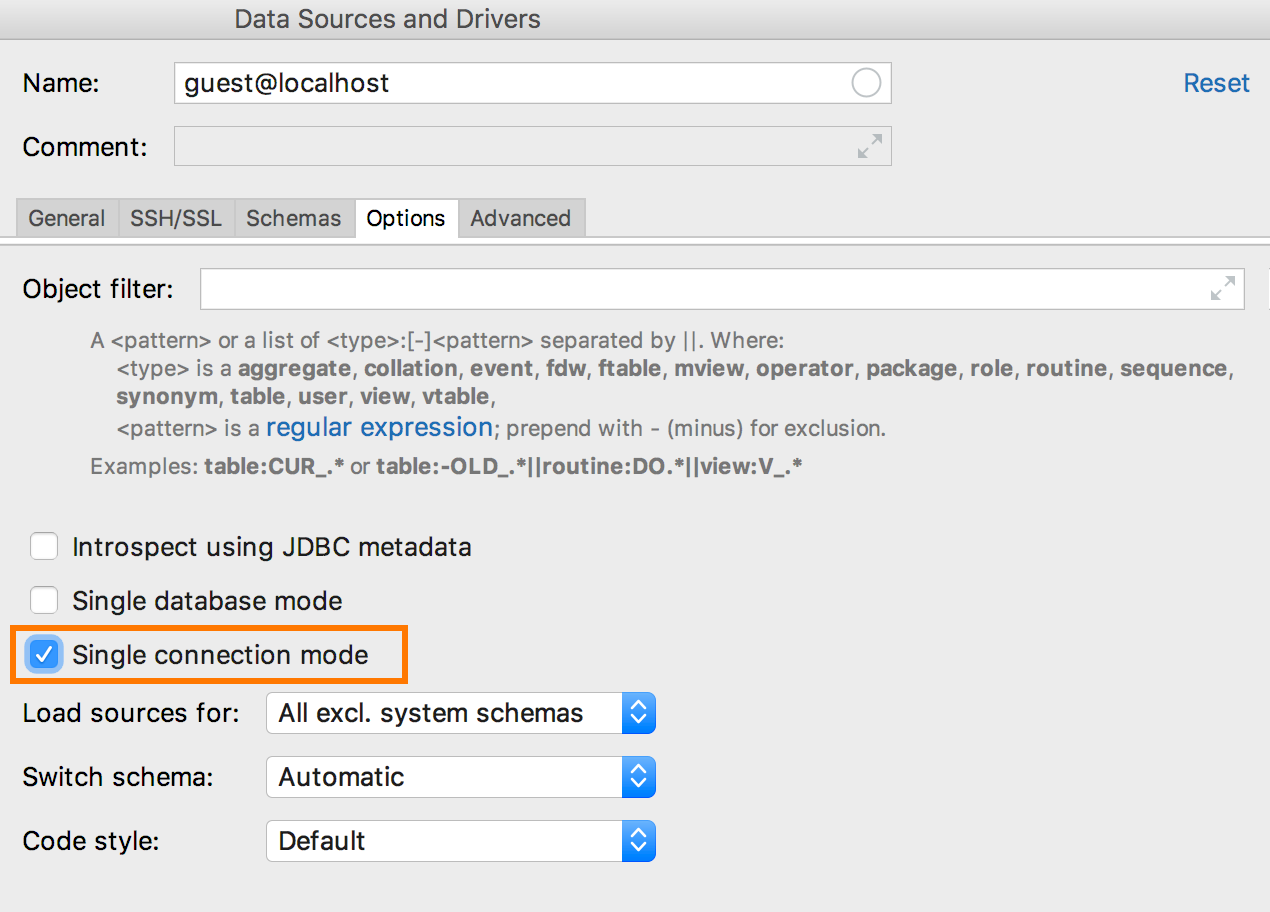
Avant la version actuelle, chaque nouvelle console signifiait une nouvelle connexion. D'autres choses qui ne nécessitaient pas la console ont également créé des connexions distinctes: exécution de scripts, importation, une interface graphique pour créer des tables. Dans 2018.3, si vous activez le
mode de connexion unique dans les propriétés de la source de données, tout le travail se fera via une connexion.
Par conséquent, des objets temporaires apparaîtront dans l'arborescence et les consoles et les éditeurs de données fonctionneront au sein de la même transaction. Il s'agit de la première étape de la gestion complète des connexions que nous allons aborder.
Et ils ont également fait en sorte que l'IDE lui-même se
reconnecte après une période d'inactivité.
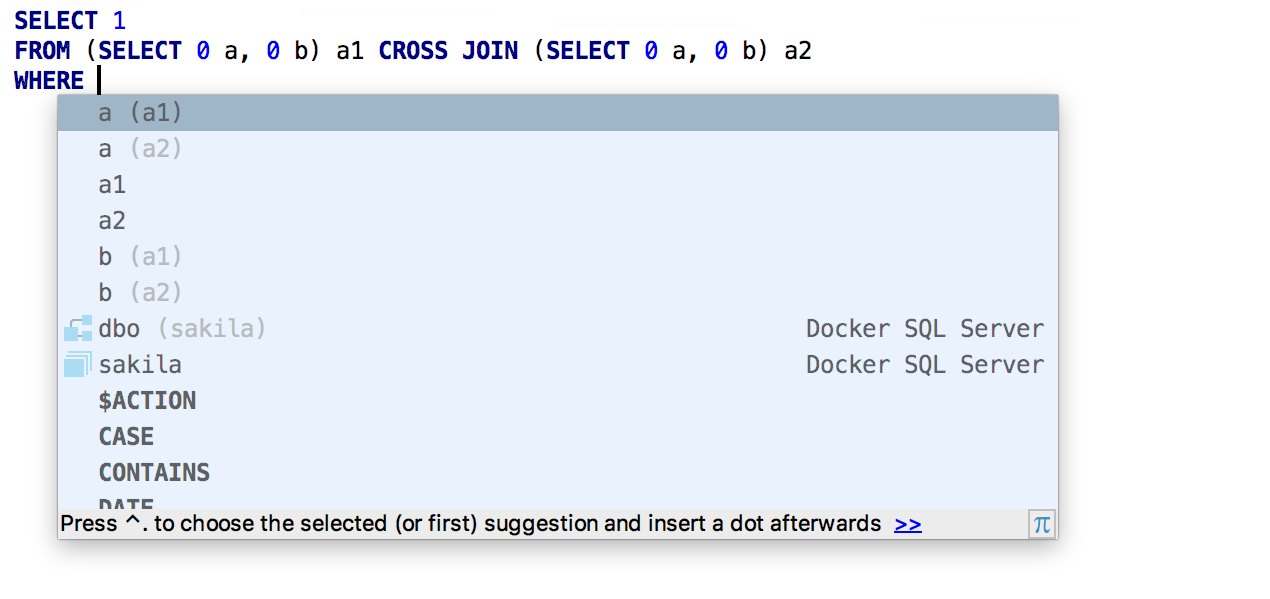
Recherche et navigation
La plateforme IntelliJ a introduit une
nouvelle recherche : elle combine différents types de recherches qui étaient fragmentées:
Rechercher partout ,
Rechercher une action ,
Aller à la table / vue / procédure / ,
Aller au fichier et
Aller au symbole . Dans DataGrip, le deuxième onglet est appelé Tables et dans d'autres IDE, il est appelé Classes. Mais elle fait la même chose: elle recherche à la fois des objets de base de données et des classes. La touche Tab permet de basculer entre les onglets.
Nous n'avons pas sérieusement changé les algorithmes de recherche: si soudainement vous cherchiez bien quelque chose, mais maintenant il est mal recherché, veuillez écrire.
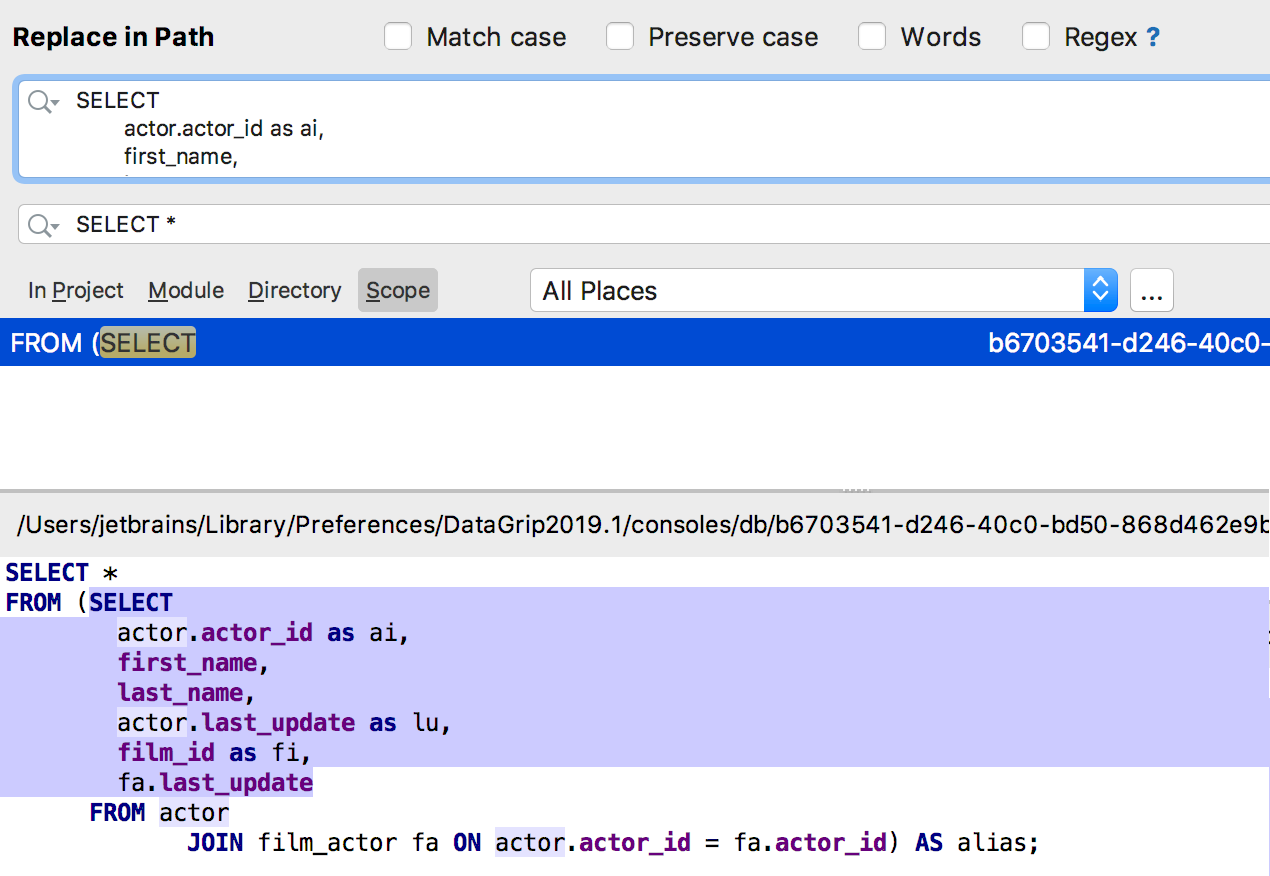
 Plusieurs lignes à la fois
Plusieurs lignes à la fois peuvent désormais être trouvées dans «Rechercher dans le chemin». Particulièrement utile pour SQL - la requête peut être trouvée dans le code source des objets.
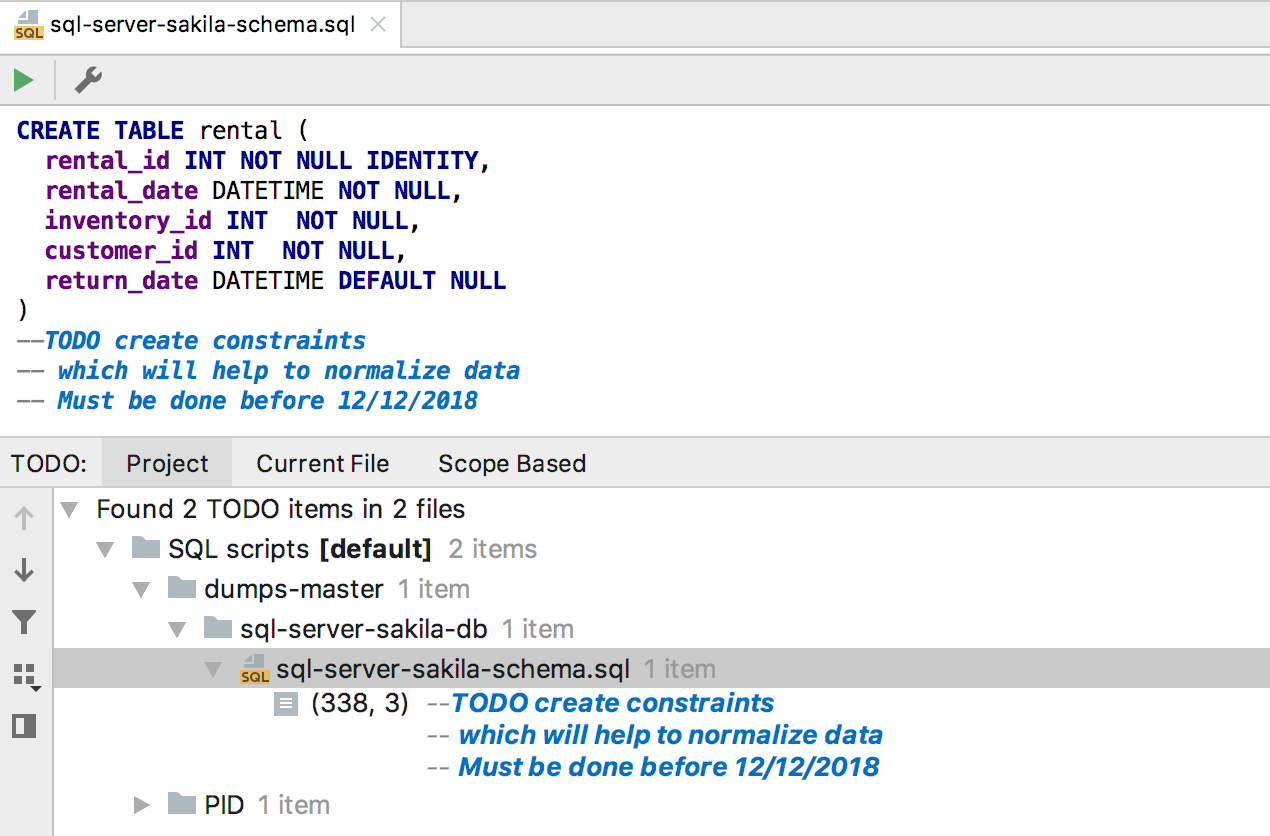
 Les commentaires TODO
Les commentaires TODO peuvent désormais être multi-lignes. Afin d'attraper les lignes suivantes dans un tel commentaire, séparez-les avec un espace du symbole de commentaire. Les tâches ainsi présentées relèvent de la
fenêtre d'outils TODO .
L'image est plus claire:
Interface
La nouvelle palette de couleurs est très contrastée.
Changer de schéma comme celui-ci: Appuyez sur
Ctrl + `et sélectionnez Look and Feel.
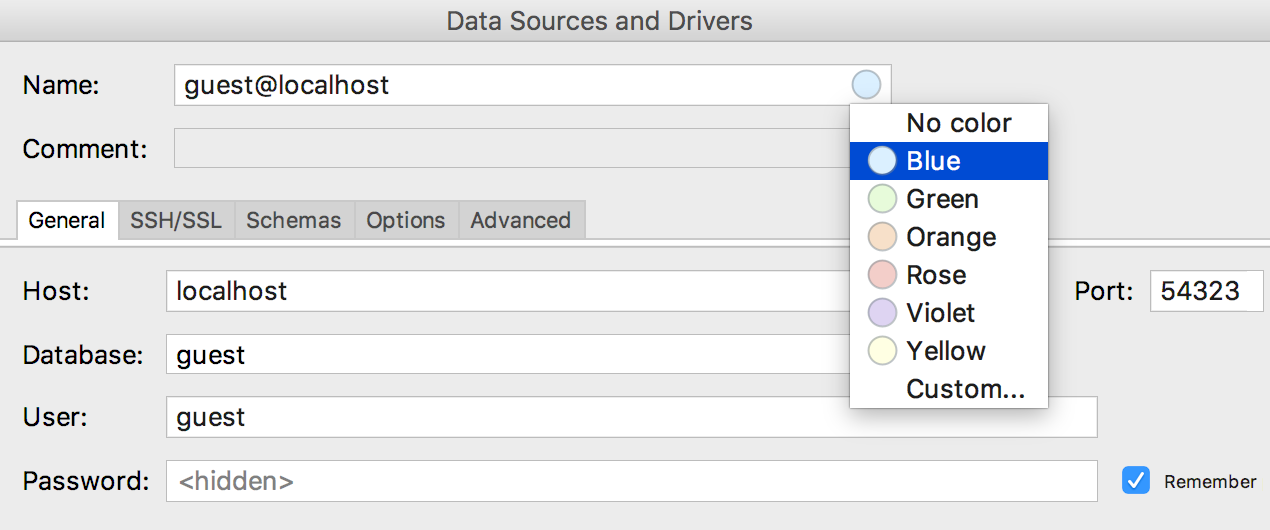
Un menu est apparu pour
sélectionner la couleur de la source de données dans sa fenêtre de propriétés.
Et un peu de convivialité a été ajoutée à la boîte de sélection de ligne sur la page. Auparavant, pour que le résultat affiche toutes les lignes, vous deviez écrire -1 ici :)
Maintenant, il y a une case à cocher.

C’est tout!
→
Plus de détails ici→
Télécharger la version d'essai pendant un mois→ Le
tweeter que nous lisons→ Le
courrier que nous lisons→
Bug TrackerÉquipe DataGrip