L'échantillonnage en cuve (par exemple "échantillonnage en réservoir") est un algorithme simple et efficace pour échantillonner au préalable un certain nombre d'éléments à partir d'un vecteur existant de grande taille et / ou de taille inconnue. Je n'ai trouvé aucun article sur cet algorithme sur Habré et j'ai donc décidé de l'écrire moi-même.
Alors, de quoi parle-t-on. La sélection d'un élément aléatoire dans un vecteur est une tâche élémentaire:
La tâche de «renvoyer K éléments aléatoires à partir d'un vecteur de taille N» est déjà plus délicate. Ici, vous pouvez déjà faire une erreur - par exemple, prenez K premiers éléments (cela viole l'exigence de caractère aléatoire) ou prenez chacun des éléments avec une probabilité K / N (cela viole l'exigence de prendre exactement K éléments). De plus, il est possible de mettre en œuvre une solution formellement correcte mais extrêmement inefficace "mélanger au hasard tous les éléments et prendre le K en premier". Et tout devient encore plus intéressant si nous ajoutons la condition que N est un très grand nombre (nous n'avons pas assez de mémoire pour sauvegarder tous les N éléments) et / ou n'est pas connu à l'avance. Par exemple, imaginez que nous ayons une sorte de service externe qui nous envoie des éléments un par un. Nous ne savons pas combien d'entre eux viendront en tout et nous ne pouvons pas tous les enregistrer, mais nous voulons avoir un ensemble d'exactement K éléments sélectionnés au hasard parmi ceux reçus à tout moment.
L'algorithme d'échantillonnage de réservoir nous permet de résoudre ce problème en étapes O (N) et en mémoire O (K). Dans ce cas, il n'est pas nécessaire de connaître N à l'avance et la condition d'échantillonnage aléatoire d'exactement K éléments sera clairement observée.
Commençons par une tâche simplifiée.
Soit K = 1, c'est-à-dire nous devons sélectionner un seul élément parmi tous les entrants - mais pour que chacun des éléments entrants ait la même probabilité d'être sélectionné. L'algorithme se suggère:
Étape 1 : allouez de la mémoire à exactement un élément. Nous y enregistrons le premier élément arrivé.

Jusqu'à présent, tout va bien - un seul élément nous est parvenu, avec une probabilité de 100% (pour le moment), il devrait être sélectionné - il l'est.
Étape 2 : Le deuxième élément entrant est réécrit avec une probabilité de 1/2 comme l'élément sélectionné.

Ici aussi, tout va bien: jusqu'à présent, seuls deux éléments nous sont parvenus. Le premier est resté sélectionné avec une probabilité de 1/2, le second l'a réécrit avec une probabilité de 1/2.
Étape 3 : Le troisième élément entrant avec une probabilité de 1/3 est réécrit comme l'élément sélectionné.
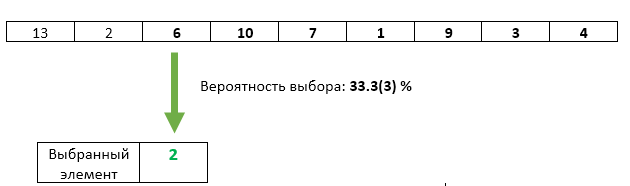
Tout va bien avec le troisième élément - sa chance d'être choisi est exactement 1/3. Mais avons-nous en quelque sorte violé les chances égales des éléments précédents? Non. La probabilité que l'élément sélectionné ne soit pas écrasé à cette étape est de 1 - 1/3 = 2/3. Et comme à l'étape 2, nous avons garanti des chances égales pour chacun des éléments à sélectionner, puis après l'étape 3, chacun d'eux peut être sélectionné avec une chance de 2/3 * 1/2 = 1/3. Exactement la même chance que le troisième élément.
Étape N : Avec une probabilité de 1 / N, le numéro d'élément N est réécrit en celui sélectionné. Chacun des articles précédents qui sont arrivés a la même chance 1 / N de rester sélectionné.
Mais c'était une tâche simplifiée, avec K = 1.
Comment l'algorithme changera-t-il pour K> 1?
Étape 1 : Nous allouons de la mémoire sur K éléments. Nous y écrivons les premiers éléments K arrivés.

La seule façon de prendre K éléments des K éléments arrivés est de les prendre tous :)
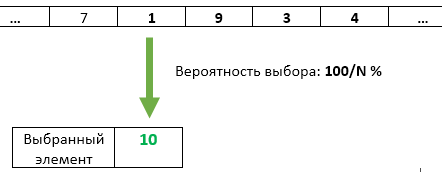
Étape N : (pour chaque N> K): générer un nombre aléatoire X de 1 à N. Si X> K alors nous rejetons cet élément et passons au suivant. Si X <= K, alors réécrivez l'élément avec le nombre X. Puisque la valeur de X sera uniformément aléatoire dans l'intervalle de 1 à N, sous la condition X <= K, elle sera uniformément aléatoire dans l'intervalle de 1 à K. Ainsi, nous assurons l'uniformité sélection d'éléments réinscriptibles.

Comme vous pouvez le voir, chaque élément suivant qui vient a de moins en moins de chances d'être sélectionné. Néanmoins, ce sera toujours exactement K / N (comme pour chacun des éléments précédents arrivés).
L'avantage de cet algorithme est que nous pouvons nous arrêter à tout moment, montrer à l'utilisateur le vecteur K actuel - et ce sera le vecteur d'éléments aléatoires honnêtement sélectionnés dans la séquence d'éléments qui sont arrivés. Peut-être que cela conviendra à l'utilisateur, ou peut-être qu'il voudra continuer à traiter les valeurs entrantes - nous pouvons le faire à tout moment. Dans ce cas, comme mentionné au début, nous n'utilisons jamais plus de mémoire O (K).
Oh oui, j'ai complètement oublié, la fonction
std :: sample , qui fait exactement ce qui est décrit ci-dessus, est finalement incluse dans la bibliothèque C ++ 17 standard. La norme ne l'oblige pas à utiliser uniquement l'échantillonnage du réservoir, mais l'oblige à travailler par étapes O (N) - eh bien, il est peu probable que les développeurs de son implémentation dans la bibliothèque standard choisissent un algorithme qui utilise plus de mémoire O (K) (et moins ne fonctionnera pas non plus - le résultat doit être stocké quelque part).
Matériel connexe