Un beau jour, différentes chaînes du
télégramme ont commencé à jeter un
lien vers le crackmix de LK.Ceux
qui ont réussi la tâche seront invités pour une interview! . Après une déclaration aussi forte, je me suis demandé à quel point l'inverse serait difficile. Comment j'ai résolu cette tâche peut être lu sous la coupe (beaucoup de photos).
De retour à la maison, j'ai relu attentivement le devoir, téléchargé l'archive et commencé à regarder ce qu'il y avait à l'intérieur. Et à l'intérieur c'était:
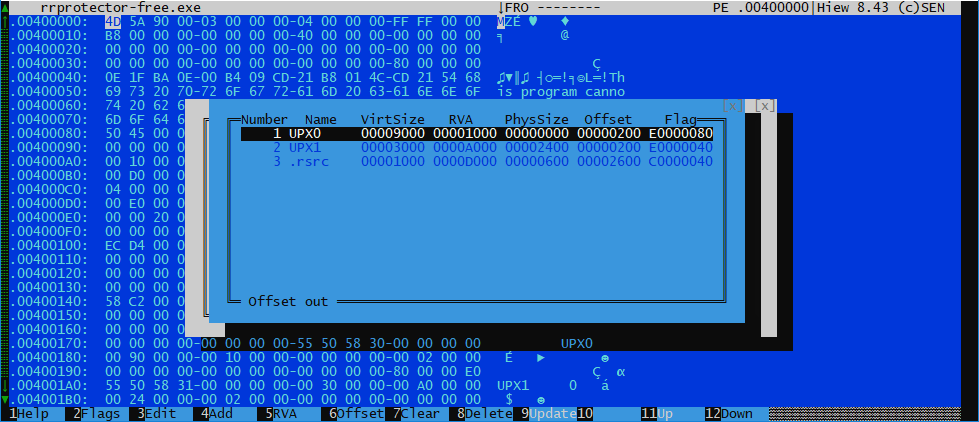
Nous commençons x64dbg, vidons après le déballage, regardons ce qui se trouve réellement à l'intérieur:
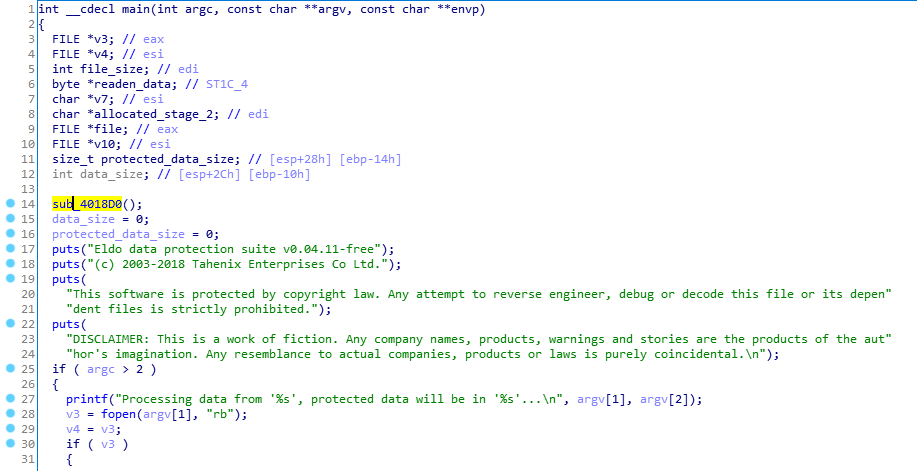

Nous prenons le nom du fichier à partir des arguments de la ligne de commande -> ouvrir, lire -> chiffrer la première étape -> chiffrer la deuxième étape -> écrire dans un nouveau fichier.
C'est simple, il est temps de regarder le cryptage.
Commençons par stage1
À l'adresse 0x4033f4, il y a une fonction que j'ai appelée crypt_64bit_up (plus tard vous comprendrez pourquoi), elle est appelée à partir d'une boucle quelque part à l'intérieur de stage1

Et un résultat de décompilation un peu tordu
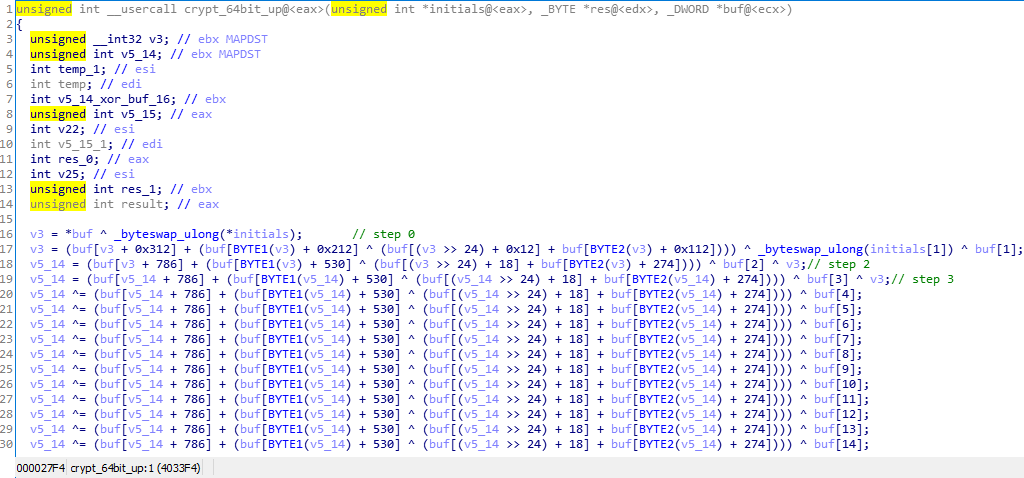
Au début, j'ai essayé de réécrire le même algorithme en python, je l'ai tué pendant plusieurs heures et il s'est avéré quelque chose comme ça (ce qui fait que get_dword et byteswap devraient être clairs d'après les noms)
def _add(x1, x2): return (x1+x2) & 0xFFFFFFFF def get_buf_val(t, buffer): t_0 = t & 0xFF t_1 = (t >> 8) & 0xFF t_2 = (t >> 16) & 0xFF t_3 = (t >> 24) & 0xFF res = _add(get_dword(buffer, t_0 + 0x312), (get_dword(buffer, t_1 + 0x212) ^ _add(get_dword(buffer, t_2+0x112), get_dword(buffer, t_3+0x12))))
Mais alors j'ai décidé de faire attention aux constantes 0x12, 0x112, 0x212, 0x312 (sans hex 18, 274, 536 ... pas très similaire à quelque chose d'inhabituel). Nous essayons de les rechercher sur Google et de trouver un référentiel complet (indice: NTR) avec l'implémentation de fonctions de cryptage et de
décryptage , c'est une bonne chance. Nous essayons de crypter un fichier de test avec un contenu aléatoire dans le programme d'origine, de le vider et de crypter le même fichier avec un petit script, tout devrait fonctionner et les résultats devraient être les mêmes. Après cela, nous essayons de le décrypter (j'ai décidé de ne pas entrer dans les détails et de copier-coller la fonction de décryptage à partir de la source)
def crypt_64bit_down(initials, keybuf): x = initials[0] y = initials[1] for i in range(0x11, 1, -1): z = get_dword(keybuf, i) ^ x x = get_buf_val(z, keybuf) x = y ^ x y = z res_0 = x ^ get_dword(keybuf, 0x01)
Remarque importante: la clé dans le référentiel est différente de la clé dans le programme (ce qui est assez logique). Par conséquent, après l'initialisation de la clé, je viens de la vider dans un fichier, c'est tampon / keybuf
Nous passons à la deuxième partie
Tout est beaucoup plus simple ici: tout d'abord, un tableau de caractères uniques est créé avec une taille 0x55 octets dans la plage (33, 118) (caractères imprimables), puis la valeur 32 bits est compressée en 5 caractères imprimables à partir du tableau créé précédemment.
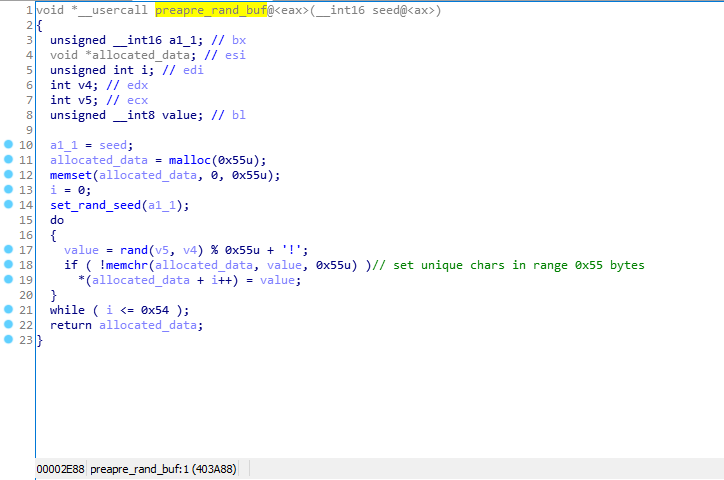
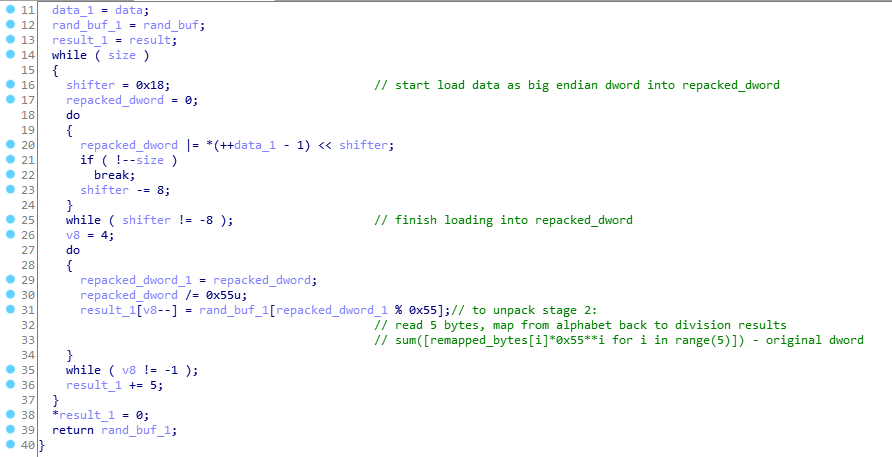
Comme il n'y a pas d'aléatoire lors de la création du tableau mentionné ci-dessus, chaque fois que le programme démarre, ce tableau sera le même, nous le vidons après l'initialisation et nous pouvons décompresser stage_2 avec une fonction simple
def stage2_unpack(packed_data, state):
Nous faisons quelque chose comme ça:
f = open('stage1.state.bin', 'rb') stage1 = f.read() f.close() f = open('stage2.state.bin', 'rb') stage2 = f.read() f.close() f = open('rprotected.dat', 'rb') packed = f.read() f.close() unpacked_from_2 = stage2_unpack(packed, stage2) f = open('unpacked_from_2', 'wb') f.write(unpacked_from_2) f.close() unpacked_from_1 = stage1_unpack(unpacked_from_2, stage1) f = open('unpacked_from_1', 'wb') f.write(unpacked_from_1) f.close()
Et nous obtenons le résultat
