Dans le cadre de la récente conférence
DotNext 2018 , BoF on Domain Driven Design a eu lieu. Il a abordé la question du travail avec les exceptions, qui a provoqué un débat houleux, mais n'a pas reçu de discussion détaillée, car ce n'était pas le sujet principal.
En outre, en étudiant de nombreuses ressources, allant des questions sur le stackoverflow et en terminant par des cours d'architecture payants, vous pouvez observer que la communauté informatique a une attitude ambiguë à l'égard des exceptions et de la façon de les utiliser.
Il est le plus souvent mentionné qu'en utilisant des exceptions, il est facile de créer un thread d'exécution ayant une
sémantique d'opérateur goto , ce qui affecte négativement la lisibilité du code.
Il existe différentes opinions quant à la
création de vos propres types d'exceptions ou à l'utilisation
des exceptions standard fournies dans .NET.
Quelqu'un fait la validation des exceptions, et quelqu'un partout
utilise la monade Result . Il est vrai que Result vous permet de comprendre par la signature de la méthode si une exécution réussie est possible ou non. Mais il n'en est pas moins vrai que dans les langages impératifs (qui incluent C #), l'utilisation répandue de Result conduit à du code mal lisible, recouvert de constructions de langage de sorte qu'il est difficile de distinguer le script d'origine.
Dans cet article, je parlerai des pratiques adoptées par notre équipe (en bref - nous utilisons toutes les approches et aucune d'entre elles n'est un dogme).
Nous parlerons d'une application d'entreprise construite sur la base d'ASP.NET MVC + WebAPI. L'application est construite sur une
architecture oignon , communique avec la base de données et le courtier de messages. Il utilise une journalisation structurée vers la pile ELK et la surveillance est configurée à l'aide de Grafana.
Nous examinerons le travail avec les exceptions sous trois angles:
- Règles générales d'exception
- Exceptions, erreurs et architecture des oignons
- Cas particuliers pour les applications Web
Règles générales d'exception
- Les exceptions et les erreurs ne sont pas la même chose. Pour les exceptions, nous utilisons des exceptions, pour les erreurs - Résultat.
- Les exceptions ne concernent que les situations exceptionnelles, qui par définition ne peuvent pas être nombreuses. Donc, moins il y a d'exceptions, mieux c'est.
- La gestion des exceptions doit être aussi granulaire que possible. Comme Richter l'a écrit dans son œuvre monumentale.
- Si l'erreur doit être transmise à l'utilisateur dans sa forme d'origine, utilisez Résultat.
- Une exception ne doit pas laisser les limites du système dans sa forme originale. Ce n'est pas convivial et donne à un attaquant un moyen d'explorer davantage les faiblesses possibles du système.
- Si l'exception levée est gérée par notre application, nous utilisons non pas l'exception, mais Result. L'implémentation sur les exceptions sera masquée par l'opérateur goto et plus elle sera mauvaise, plus le code de traitement sera éloigné du code d'exception. Le résultat déclare explicitement la possibilité d'une erreur et autorise uniquement son traitement «linéaire».
Exceptions, erreurs et architecture des oignons
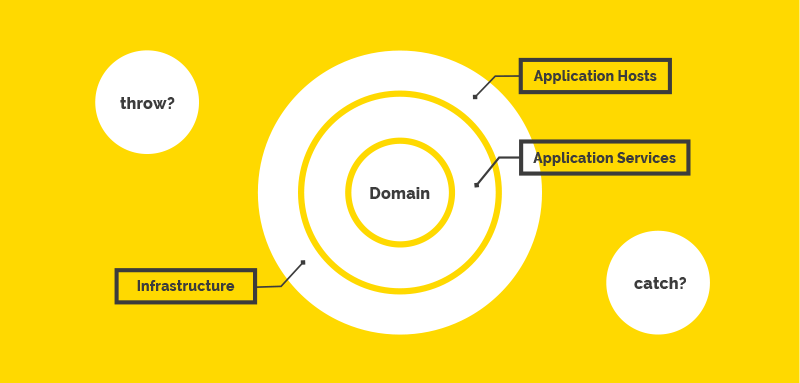
Dans les sections suivantes, nous examinerons les responsabilités et les règles de levée / gestion des exceptions / erreurs pour les couches suivantes:
- Hôtes d'application
- Infrastructure
- Services d'application
- Noyau de domaine
Hôte d'application
De quoi est responsable- Racine de composition , personnalisation du fonctionnement de l'ensemble de l'application.
- La frontière de l'interaction avec le monde extérieur est les utilisateurs, les autres services, le lancement prévu.
Puisqu'il s'agit de responsabilités assez complexes, cela vaut la peine de se limiter. Nous donnons les responsabilités restantes aux couches internes.
Comment gérer les erreurs du résultatDiffusions vers le monde extérieur, conversion au format approprié (par exemple, en réponse http).
Comment le résultat génèrePas question. Cette couche ne contient pas de logique, il n'y a donc nulle part où générer des erreurs.
Comment gérer les exceptions- Masque les détails et convertit dans un format adapté à l'envoi vers le monde extérieur
- Se connecte.
Comment lever des exceptionsPas question, cette couche est la plus externe et ne contient pas de logique - il n'y a personne pour lui lever une exception.
Infrastructure
Qu'est-ce qui est responsable de- Adaptateurs aux ports , ou simplement pour implémenter des interfaces de domaine, donnant accès à l'infrastructure - services tiers, bases de données, annuaire actif, etc. Cette couche doit être aussi stupide que possible et contenir le moins de logique possible.
- Si nécessaire, il peut agir comme une couche anti-corruption .
Comment gérer les erreurs du résultatJe ne connais pas les fournisseurs de base de données et les autres services exécutés sur la monade Result. Cependant, certains services fonctionnent sur des codes retour. Dans ce cas, nous les convertirons au format de résultat requis par le port.
Comment le résultat génèreEn général, cette couche ne contient pas de logique, ce qui signifie qu'elle ne génère pas d'erreurs. Mais s'il est utilisé comme couche anti-corruption, une variété d'options est possible. Par exemple, analyser les exceptions d'un service hérité et convertir en Result les exceptions qui sont de simples messages de validation.
Comment gérer les exceptionsDans le cas général, il le jette plus loin, si nécessaire, après avoir sécurisé les détails. Si le port en cours d'implémentation permet le retour de Result dans le contrat, alors l'infrastructure convertira en Result les types d'exceptions qui peuvent être traitées.
Par exemple, le courtier de messages utilisé dans le projet lève une exception lors de la tentative d'envoi d'un message lorsque le courtier n'est pas disponible. La couche Application Services est prête pour cette situation et peut la gérer avec une stratégie de nouvelle tentative, un disjoncteur ou une restauration manuelle des données.
Dans ce cas, la couche Application Services déclare un contrat qui renvoie Résultat en cas d'erreur. Et la couche Infrastructure implémente ce port, convertissant l'exception du courtier en Résultat. Naturellement, il ne convertit que des types spécifiques d'exceptions, et pas tous d'affilée.
En utilisant cette approche, nous obtenons deux avantages:
- Déclarez explicitement la possibilité d'erreurs dans le contrat.
- Nous nous débarrassons de la situation où le service d'application sait comment gérer l'erreur, mais ne connaît pas le type d'exception, car il est extrait d'un courtier de messages spécifique. Construire un bloc catch sur la base System.Exception signifie capturer tous les types d'exceptions, et pas seulement celles que le service d'application peut gérer.
Comment lever des exceptionsDépend des spécificités du système.
Par exemple, les instructions Single et First LINQ lèvent une InvalidOperationException lors de la demande de données inexistantes. Mais ce type d'exception est utilisé partout dans .NET, ce qui rend impossible le traitement granulaire.
Dans l'équipe, nous avons adopté la pratique de créer une exception ItemNotFoundException personnalisée et de la jeter de la couche infrastructure si les données demandées n'ont pas été trouvées et ne devraient pas l'être selon les règles métier.
Si les données demandées ne sont pas trouvées et que cela est autorisé, elles doivent être explicitement déclarées dans le contrat portuaire. Par exemple, en utilisant la
monade Maybe .
Services d'application
Qu'est-ce qui est responsable de- Validation des données d'entrée.
- Orchestration et coordination des services - début et fin des transactions, implémentation de scripts distribués, etc.
- Téléchargez les objets de domaine et les données externes via les ports vers Infrastructure, appel ultérieur des commandes dans Domain Core.
Comment gérer les erreurs du résultatLes erreurs du cœur du domaine se traduisent dans le monde extérieur sans changement. Les erreurs provenant de l'infrastructure peuvent être gérées via une nouvelle tentative, des politiques de disjoncteur ou diffusées vers l'extérieur.
Comment le résultat génèrePeut implémenter la validation comme résultat.
Peut générer des notifications de réussite partielle de l'opération. Par exemple, des messages à un utilisateur comme «Votre commande a été passée avec succès, mais une erreur s'est produite lors de la vérification de l'adresse de livraison. Un spécialiste vous contactera sous peu pour clarifier les détails de livraison. »
Comment gérer les exceptionsEn supposant que les exceptions d'infrastructure que l'application est capable de gérer sont déjà converties par la couche Infrastructure en résultat, elle ne les gère pas du tout.
Comment lever des exceptionsEn général, pas du tout. Mais il existe des options limites décrites dans la dernière section de l'article.
Noyau de domaine
Qu'est-ce qui est responsable deLa mise en œuvre de la logique métier, le «cœur» du système et le sens principal de son existence.
Comment gérer les erreurs du résultatComme la couche est interne et que les erreurs ne sont possibles qu'à partir d'objets du même domaine, le traitement est réduit soit aux règles métier, soit à la traduction de l'erreur vers le haut dans sa forme d'origine.
Comment le résultat génèreSi vous violez des règles métier encapsulées dans Domain Core et non couvertes par la validation des données d'entrée au niveau des services d'application. En général, dans cette couche, Result est utilisé le plus souvent.
Comment gérer les exceptionsPas question. Les exceptions d'infrastructure ont déjà été traitées par la couche Infrastructure, les données sont déjà arrivées structurées, complètes et validées grâce à la couche Application Services. Par conséquent, toutes les exceptions susceptibles de s'envoler seront de véritables exceptions.
Comment lever des exceptionsHabituellement, une règle générale fonctionne ici: moins il y a d'exceptions, mieux c'est.
Mais avez-vous déjà eu des situations où vous écrivez du code et comprenez que, dans certaines conditions, cela peut faire des affaires terribles? Par exemple, pour annuler deux fois l’argent ou pour gâcher tellement les données que nous ne pourrons pas collecter les ossements.
En règle générale, nous parlons d'exécuter des commandes qui sont inacceptables pour l'état actuel de l'objet.
Bien sûr, le bouton correspondant sur l'interface utilisateur ne doit pas être visible dans cet état. Nous ne devrions pas recevoir de commande du bus dans cet état. Tout cela est vrai à condition que les couches extérieures et les systèmes remplissent
normalement leur fonction. Mais dans Domain Core, nous ne devons pas connaître l'existence de couches externes et croire à l'exactitude de leur travail, nous devons protéger les invariants du système.
Certaines vérifications peuvent être placées dans Application Services au niveau de la validation. Mais cela peut se transformer en
programmation défensive , ce qui dans les cas extrêmes conduit à ce qui suit:
- L'encapsulation est affaiblie, car certains invariants doivent être vérifiés sur la couche externe.
- La connaissance du sujet «coule» dans la couche externe, les contrôles peuvent être dupliqués par les deux couches.
- La validation de l' exécution d'une commande à partir d'une couche externe peut être plus complexe et moins fiable que la vérification qu'un objet de domaine ne peut pas exécuter une commande dans son état actuel.
De plus, si nous plaçons de tels contrôles dans la couche de validation, nous devons indiquer à l'utilisateur la raison de l'erreur. Étant donné que nous parlons d'une opération qui ne peut pas du tout être effectuée dans les conditions actuelles, nous courons le risque d'être dans l'une des deux situations suivantes:
- Nous avons donné à un utilisateur ordinaire un message qu'il ne comprenait pas du tout et irait au support de toute façon, tout comme avec le message "Une erreur inattendue s'est produite".
- Nous avons informé le méchant sous une forme assez intelligible pourquoi il ne peut pas effectuer l'opération qu'il souhaite effectuer et il peut rechercher d'autres solutions.
Mais revenons au sujet principal de l'article. De toute évidence, la situation en discussion est exceptionnelle. Cela ne devrait jamais arriver, mais si c'est le cas, ce sera mauvais.
Dans cette situation, il est plus logique de lever une exception, de promettre les détails nécessaires, de renvoyer à l'utilisateur une erreur de la forme générale «L'opération n'est pas faisable», de mettre en place un suivi de ce type d'erreurs et de s'attendre à ce que nous ne les verrons jamais.
Quel type ou types d'exceptions à utiliser dans ce cas? Logiquement, cela devrait être un type d'exception distinct, afin que nous puissions le distinguer des autres et qu'il ne soit pas accidentellement détecté par la gestion des exceptions de la couche externe. Nous n'avons pas non plus besoin d'une hiérarchie ou de nombreuses exceptions, l'essence est la même - quelque chose d'inacceptable s'est produit. Dans nos projets, nous créons un type CorruptedInvariantException pour cela et nous l'utilisons dans des situations appropriées.
Cas particuliers pour les applications Web
Une différence significative entre les applications Web des autres (bureau, démons et services Windows, etc.) est l'interaction avec le monde extérieur sous la forme d'opérations à court terme (traitement des requêtes HTTP), après quoi l'application «oublie» immédiatement ce qui s'est passé.
De plus, après le traitement de la demande, une réponse est toujours générée. Si l'opération effectuée par notre code ne renvoie pas de données, la plateforme renverra quand même une réponse contenant le code d'état. Si l'opération a été abandonnée par une exception, la plate-forme renvoie toujours une réponse contenant le code d'état correspondant.
Pour implémenter ce comportement, le traitement des demandes dans les plates-formes Web est construit sous la forme de canaux. Tout d'abord, la demande est traitée séquentiellement (demande), puis la réponse est préparée.
Nous pouvons utiliser un middleware, un filtre d'action, un gestionnaire http ou un filtre ISAPI (selon la plateforme) et nous intégrer à ce pipeline à tout moment. Et à n'importe quelle étape du traitement de la demande, nous pouvons interrompre le traitement et le pipeline procédera pour former une réponse.
En règle générale, nous n'implémentons plus la partie métier de l'application dans l'architecture de pipeline, mais écrivons du code qui effectue les opérations de manière séquentielle. Et avec cette approche, il est un peu plus difficile de mettre en œuvre le scénario lorsque nous interrompons l’exécution de la demande et passons immédiatement à la formation de la réponse.
Qu'est-ce que tout cela a à voir avec la gestion des exceptions, demandez-vous?
Le fait est que les règles de travail avec les exceptions décrites dans les parties précédentes de l'article ne correspondent pas bien à ce scénario.
Les exceptions sont mauvaises à utiliser car c'est de la sémantique goto.
L'utilisation répandue de Result conduit au fait que nous le faisons glisser (Result) sur toutes les couches de l'application, et lors de la formation de la réponse, nous devons analyser Result d'une manière ou d'une autre afin de comprendre quel code d'état retourner. Il est également conseillé de généraliser et de pousser ce code d'analyse dans Middleware ou ActionFilter, qui devient une aventure distincte. Autrement dit, le résultat n'est pas beaucoup mieux que les exceptions.
Que faire dans une telle situation?Ne construisez pas d'absolu. Nous fixons les règles à notre profit et non au détriment.
Si vous souhaitez abandonner une opération car sa poursuite est impossible, le lancement d'une exception n'aura pas de sémantique. Nous dirigeons l'exécution vers la sortie, et non vers un autre bloc de code métier.
Si la raison de l'interruption est importante pour déterminer le code d'état souhaité, des types d'exceptions personnalisés peuvent être utilisés.
Plus tôt, nous avons mentionné deux types personnalisés que nous utilisons: ItemNotFoundException (transformation en 404) et CorruptedInvariant (transformation en 500).
Si vous vérifiez les droits des utilisateurs, car ils ne relèvent pas du modèle de rôle ou des revendications, il est autorisé de créer une ForbiddenException personnalisée (code d'état 403).
Et enfin, la validation. Nous ne pouvons toujours rien faire tant que l'utilisateur n'a pas modifié sa demande, cette sémantique
est décrite par le code 422 . Nous interrompons donc l'opération et envoyons la demande directement à la sortie. Cela peut également être fait en utilisant l'exception. Par exemple, la bibliothèque
FluentValidation a déjà un
type d'exception intégré qui transmet au client tous les détails nécessaires pour afficher clairement à l'utilisateur ce qui ne va pas avec la demande.
C’est tout. Comment travaillez-vous avec les exceptions?