Problème
Presque tous les systèmes d'information nécessitent un stockage de données sur une base continue. Dans la plupart des systèmes à faible et moyenne charge, cette fonction est réalisée par des SGBD relationnels, dont l'avantage incontestable est la garantie de la cohérence des données.
Un exemple classique qui explique ce qu'est la cohérence des données - l'opération de transfert de fonds d'un compte à un autre. Au moment où l'opération de modification du solde d'un compte est déjà terminée et que l'autre n'a pas encore eu le temps, une défaillance peut se produire. Les fonds seront ensuite débités d'un compte, mais ne seront pas crédités sur un autre. Cet état des données du système est appelé incohérent et, peut-être, il n'est pas nécessaire d'expliquer les conséquences que cela peut entraîner. Les SGBD relationnels fournissent un mécanisme de transaction qui garantit la cohérence des données à tout moment. Une transaction est un ensemble fini d'opérations qui transfère un état cohérent à un autre état cohérent.
En cas d'erreur à n'importe quelle étape, le SGBD annule toutes les opérations précédemment effectuées et remet les données à leur état convenu d'origine. En d'autres termes, soit toutes les opérations seront effectuées, soit pas une seule.
Quant aux systèmes à grande échelle, il est loin d'être toujours possible d'y utiliser une seule base de données à cause d'une charge trop lourde. Dans de tels cas, chaque module système (service) est fourni avec sa propre base de données distincte. Dans ce cas, la question se pose de savoir comment garantir la cohérence des données pour une telle architecture de cluster.
Résolution de la cohérence des données
Une solution est les transactions distribuées. Tout d'abord, tous les nœuds du cluster doivent accepter que l'opération est possible, puis les modifications sont validées pour tous les nœuds. Étant donné que les nœuds n'ont pas de périphérique de stockage commun, la seule façon de parvenir à une opinion commune est de convenir en utilisant un protocole de consensus distribué.
Un protocole simple pour capturer des transactions globales est la validation en deux phases (2PC). Le nœud effectuant la transaction est considéré comme le coordinateur. Dans la phase de préparation (prepare), le coordinateur informe les autres nœuds de la validation de transaction et attend de leur confirmation qu'ils sont prêts à s'engager. Si au moins un nœud n'est pas prêt, la transaction est interrompue. Dans la phase de validation, le coordinateur informe tous les nœuds de la décision de valider la transaction. Dès réception de la confirmation de tout le monde que tout va bien, le coordinateur capture également la transaction.

Figure 1 - Schéma général d'un commit en deux phases
Ce protocole évite un minimum de messages, mais n'est pas robuste. Par exemple, si le coordinateur échoue après la phase de préparation, les nœuds restants ne disposent pas d'informations sur la validation ou l'annulation de la transaction (ils devront attendre que l'échec soit corrigé). Un autre inconvénient sérieux de 2PC (et d'autres protocoles de transaction distribués, par exemple 3PC) est qu'à mesure que le nombre de nœuds de cluster augmente, les performances des validations en deux phases diminuent.

Figure 2 - Dépendance de la vitesse d'une validation à deux bases sur le nombre de serveurs dans un cluster SGBD
De plus, l'approche transactionnelle distribuée impose une limitation: tous les modules du système doivent utiliser le même SGBD, ce qui n'est pas toujours pratique.
Une autre option consiste à fournir un mécanisme qui vous permet de travailler avec différentes bases de données (pour les services) en tant que base de données unique (pour résoudre le problème d'intégrité des données dans une base de données distribuée). Dans le même temps, un certain analogue d'une transaction pour un système distribué («transaction commerciale») est requis.
Dans les transactions ordinaires, ainsi que dans les validations en deux phases, toutes les opérations sont contrôlées par le mécanisme de transaction (à l'aide de verrous), et cela est fait afin de fournir la possibilité d'annuler toute opération (approche pessimiste - nous considérons que toute opération est potentiellement à l'origine d'une défaillance). C'est le goulot d'étranglement du système. Une alternative est l'approche dite optimiste: nous pensons que la plupart des opérations sont menées à bien. Nous effectuons également des actions supplémentaires en cas de panne. C'est-à-dire réduire les coûts pour la plupart des opérations, ce qui conduit à une productivité accrue.
Qu'est-ce qu'une saga et comment ça marche
Une alternative aux transactions pour l'architecture de microservices est Saga. Saga (saga) est un ensemble d'étapes effectuées par divers modules du système (services); le service saga est également requis, qui est responsable de l'opération (transaction commerciale) dans son ensemble. Les étapes sont liées via un graphique d'événement. Une fois la saga terminée, le système doit passer d'un état convenu à un autre (en cas de réussite), ou revenir à l'état convenu précédemment (en cas d'annulation).
Comment mettre en œuvre un tel retour ou rollback d'une transaction commerciale? Pour ce faire, la saga utilise le mécanisme d'annulation des étapes (actions compensatoires). Par exemple, l'une des étapes a réussi (par exemple, une entrée a été ajoutée à la table de base de données utilisateur), mais l'une des étapes suivantes a échoué et la saga entière doit être annulée. Ensuite, le même service reçoit une commande - annulez l'action. Mais dans le SGBD de service, la transaction locale est déjà terminée, l'enregistrement utilisateur a été ajouté. Ensuite, pour revenir à l'état précédent, le service doit effectuer une action de compensation (dans notre exemple, supprimer l'enregistrement). L'annulation des étapes permet de mettre en œuvre l'atomicité («tout ou rien») dans le cadre de la saga - toutes les étapes sont réalisées ou compensées.
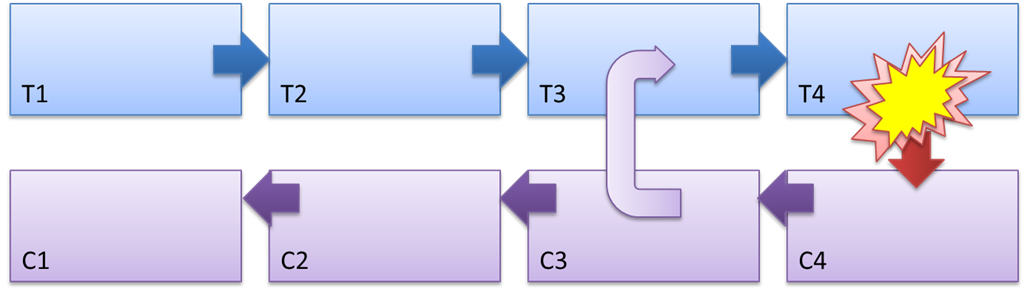
Figure 3 - Le mécanisme de travail de Saga et la nature de l'effet compensatoire
Sur la figure 3, les étapes de la saga sont désignées comme T1 ... T4, actions compensatoires: C1 ... C4.
Les sagas soutiennent l'idempotence des étapes (une action dont la répétition répétée équivaut à une seule). L'approche d'affaissement offre la possibilité de répéter n'importe quelle étape (par exemple, si vous n'avez pas reçu de réponse à la réussite). Idempotency vous permet également de restaurer l'état lorsque des données sont perdues sur n'importe quel nœud (échec et récupération). Lors de l'exécution d'une étape, chaque service doit déterminer (par la clé idempotency) s'il a déjà effectué cette étape ou non (sinon, exécuter, sinon ignorer). Pour les actions de compensation, il est également possible d'ajouter des clés d'idempotence et des répétitions d'opérations (assurant la persistance / stabilité).
Résumé
Des quatre conditions requises pour le système de transaction ACID (atomicité, cohérence, isolation, stabilité), le mécanisme d'affaissement permet d'en implémenter trois - toutes sauf l'isolement. Le manque d'isolement peut entraîner des anomalies («lectures sales», «lectures non répétables», réécriture des changements entre les différentes transactions commerciales, etc.). Pour surmonter de telles situations, il est nécessaire d'utiliser des mécanismes supplémentaires, par exemple, la version des objets mutables.
Les sagas vous permettent de résoudre les tâches suivantes:
- Fournir des modifications de données dépendantes pour les données critiques de l'entreprise;
- Être capable de définir un ordre d'étapes strict;
- Respecter 100% de cohérence (coordonner les données même en cas d'accident);
- Fournir des contrôles de performance à tous les niveaux.
Champ d'application et exemples d'application
Les sagas sont souvent utilisées sur des systèmes avec un grand nombre de demandes. Par exemple, les services de messagerie populaires, les réseaux sociaux. Cependant, l'approche peut trouver une application dans des projets de moindre envergure.
Notre entreprise possède une expérience dans le développement d'un système comptable pour une grande entreprise qui a été conçu pour plusieurs dizaines d'utilisateurs et toutes les données ont été stockées dans un SGBD relationnel. Le problème s'est posé lors de la mise en œuvre du calcul automatique des travaux planifiés: dans certains cas, les calculs étaient très importants et nécessitaient l'insertion de millions d'enregistrements dans les tables SGBD, ce qui a considérablement chargé le SGBD et ralenti le fonctionnement de l'ensemble du système.
Une solution a été trouvée - pour mettre la logique de calcul du travail dans un service séparé avec son propre SGBD pour stocker le travail lui-même et les objets associés. La cohérence des données a été assurée par la saga. Si le calcul a échoué, le module principal de l'application a reçu une commande pour annuler l'opération de calcul logique.
Bibliothèques compatibles Saga
L'application a été développée sur .Net, et pour cette technologie, plusieurs bibliothèques de gestionnaires de services prennent en charge les sagas. Nous avons examiné les bibliothèques NServiceBus, MassTransit et Rebus. En conséquence, nous nous sommes installés sur Rebus - cette bibliothèque est plus facile à apprendre, tout en réalisant pleinement le principe des sagas et est gratuite. NServiceBus et MassTransit sont des outils plus sophistiqués avec des tonnes de fonctionnalités supplémentaires. Ils n'étaient pas requis dans le cadre de notre tâche, mais il peut être conseillé de les utiliser dans de futurs projets avec une logique plus complexe.