L'une des fonctions discrètes mais importantes de
nos sites publicitaires est d'enregistrer et d'afficher le nombre de leurs vues. Nos sites regardent les annonces depuis plus de 10 ans. L'implémentation technique de la fonctionnalité a réussi à changer plusieurs fois pendant ce temps, et maintenant c'est un (micro) service sur Go, travaillant avec Redis comme cache et file d'attente de tâches, et avec MongoDB comme stockage persistant. Il y a quelques années, il a appris à travailler non seulement avec la somme des vues d'annonces, mais aussi avec les statistiques de chaque jour. Mais il a appris à faire tout cela très rapidement et de manière fiable tout récemment.

Au total, le service traite ~ 300 000 requêtes de lecture et ~ 9 000 requêtes d'écriture par minute, dont 99% sont exécutées jusqu'à 5 ms. Ce ne sont bien sûr pas des indicateurs astronomiques et non le lancement de fusées sur Mars - mais ce n'est pas non plus une tâche aussi banale qu'un simple stockage de nombres pourrait sembler. Il s'est avéré que faire tout cela, assurer un stockage de données sans perte et lire des valeurs cohérentes et pertinentes, nécessite un certain effort, dont nous discuterons ci-dessous.
Tâches et vue d'ensemble du projet
Bien que les compteurs de vues ne soient pas aussi critiques pour les entreprises que, par exemple, le traitement des paiements ou des
demandes de prêt , ils sont tout d'abord importants pour nos utilisateurs. Les gens sont fascinés par le suivi de la popularité de leurs annonces: certains appellent même le support lorsqu'ils remarquent des informations de visualisation inexactes (cela s'est produit avec l'une des implémentations de service précédentes). De plus, nous stockons et affichons des statistiques détaillées dans les comptes personnels des utilisateurs (par exemple, pour évaluer l'efficacité de l'utilisation des services payants). Tout cela nous fait prendre soin de sauvegarder chaque événement de visualisation et d'afficher les valeurs les plus pertinentes.
En général, la fonctionnalité et les principes du projet ressemblent à ceci:
- L'écran de la page Web ou de l'application fait une demande derrière les compteurs d'affichage des annonces (la demande est généralement asynchrone pour hiérarchiser la sortie des informations de base). Et si la page de l'annonce elle-même est affichée, le client vous demandera plutôt d'augmenter et de renvoyer le nombre de vues mis à jour.
- En traitant les demandes de lecture, le service essaie d'obtenir des informations du cache Redis et complète l'inconnu en complétant une demande à MongoDB.
- Les demandes d'écriture sont envoyées à 2 structures dans le radis: la file d'attente de mise à jour incrémentielle (traitée en arrière-plan, de manière asynchrone) et le cache du nombre total de vues.
- Un processus d'arrière-plan du même service lit les éléments de la file d'attente, les accumule dans le tampon local et les écrit périodiquement dans MongoDB.
Compteurs de vues d'enregistrement: pièges
Bien que les étapes décrites ci-dessus semblent assez simples, le problème ici est l'organisation de l'interaction entre la base de données et les instances de microservices afin que les données ne soient pas perdues, pas dupliquées et pas retardées.
L'utilisation d'un seul référentiel (par exemple, seulement MongoDB) résoudrait certains de ces problèmes. En fait, le service fonctionnait auparavant, jusqu'à ce que nous rencontrions des problèmes de mise à l'échelle, de stabilité et de vitesse.
Une implémentation naïve du déplacement des données entre les stockages pourrait conduire, par exemple, à de telles anomalies:
- Perte de données lors d'une écriture compétitive dans le cache:
- Le processus A augmente le nombre de vues dans le cache Redis, mais découvre qu'il n'y a toujours pas de données pour cette entité (il peut s'agir d'une nouvelle déclaration ou d'une ancienne qui a été extrudée du cache), donc le processus doit d'abord obtenir cette valeur de MongoDB.
- Le processus A obtient le nombre de vues de MongoDB - par exemple, le nombre 5; puis y ajoute 1 et va écrire dans Redis 6 .
- Le processus B (initié, par exemple, par un autre utilisateur du site qui a également entré la même annonce) fait de même simultanément.
- Le processus A écrit une valeur de 6 dans Redis.
- Le processus B écrit une valeur de 6 dans Redis.
- Par conséquent, une vue est perdue en raison de la course lors de l'enregistrement des données.
Le scénario n'est pas si improbable: par exemple, nous avons un service payant qui place une annonce sur la page principale du site. Pour une nouvelle annonce, un tel déroulement des événements peut entraîner la perte de nombreuses vues à la fois en raison de leur afflux soudain.
- Un exemple d'un autre scénario est la perte de données lors du déplacement de vues de Redis vers MongoDb:
- Le processus récupère une valeur en attente de Redis et la stocke en mémoire pour une écriture ultérieure dans MongoDB.
- Une demande d'écriture échoue (ou le processus se bloque avant d'être exécuté).
- Les données sont à nouveau perdues, ce qui deviendra apparent la prochaine fois que la valeur mise en cache sera poussée et remplacée par la valeur de la base de données.
D'autres erreurs peuvent se produire, dont les raisons résident également dans la nature non atomique des opérations entre les bases de données, par exemple, un conflit lors de la suppression et de l'augmentation des vues de la même entité.
Enregistrement du nombre de vues: solution
Notre approche du stockage et du traitement des données dans ce projet est basée sur l'hypothèse qu'à tout moment, MongoDB peut échouer plus probablement que Redis. Bien sûr, ce n'est pas une
règle absolue - du moins pas pour chaque projet - mais dans notre environnement, nous sommes vraiment habitués à observer des délais d'expiration périodiques pour les requêtes dans MongoDB causés par la performance des opérations sur disque, ce qui était auparavant l'une des raisons de la perte de certains événements.
Pour éviter bon nombre des problèmes mentionnés ci-dessus, nous utilisons des files d'attente de tâches pour l'enregistrement différé et des lua-scripts, qui permettent de modifier atomiquement les données dans plusieurs structures de radis à la fois. Dans cet esprit, les détails de l'enregistrement des vues sont les suivants:
- Lorsqu'une demande d'écriture tombe dans le microservice, elle exécute le script lua IncrementIfExists pour augmenter le compteur uniquement s'il existe déjà dans le cache. Le script renvoie immédiatement -1 s'il n'y a pas de données pour l'entité visualisée dans le radis; sinon, il augmente la valeur des vues dans le cache via HINCRBY , ajoute l'événement à la file d'attente pour un stockage ultérieur dans MongoDB (appelé file d'attente en attente par nous) via LPUSH , et renvoie la quantité de vues mise à jour.
- Si IncrementIfExists renvoie un nombre positif, cette valeur est renvoyée au client et la demande se termine.
Sinon, le microservice récupère le compteur de vues de MongoDb, l'incrémente de 1 et l'envoie au radis.
- L'écriture sur le radis se fait via un autre lua-script - Upsert - qui enregistre la quantité de vues dans le cache s'il est encore vide, ou les augmente de 1 si quelqu'un d'autre a réussi à remplir le cache entre les étapes 1 et 3.
- Upsert ajoute également un événement d'affichage à la file d'attente en attente et renvoie un montant mis à jour, qui est ensuite envoyé au client.
Du fait que les scripts lua
sont exécutés de manière atomique , nous évitons de nombreux problèmes potentiels qui pourraient être causés par une écriture compétitive.
Un autre détail important est d'assurer le transfert sécurisé des mises à jour de la file d'attente en attente vers MongoDB. Pour ce faire, nous avons utilisé le modèle de «file d'attente fiable» décrit dans la
documentation Redis , qui réduit considérablement les risques de perte de données en créant une copie des éléments traités dans une autre file d'attente jusqu'à ce qu'ils soient finalement stockés dans un stockage persistant.
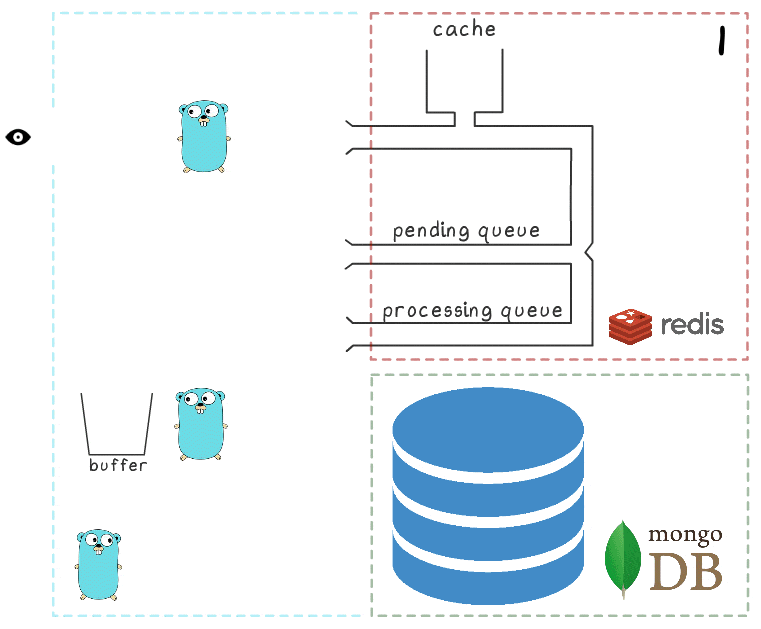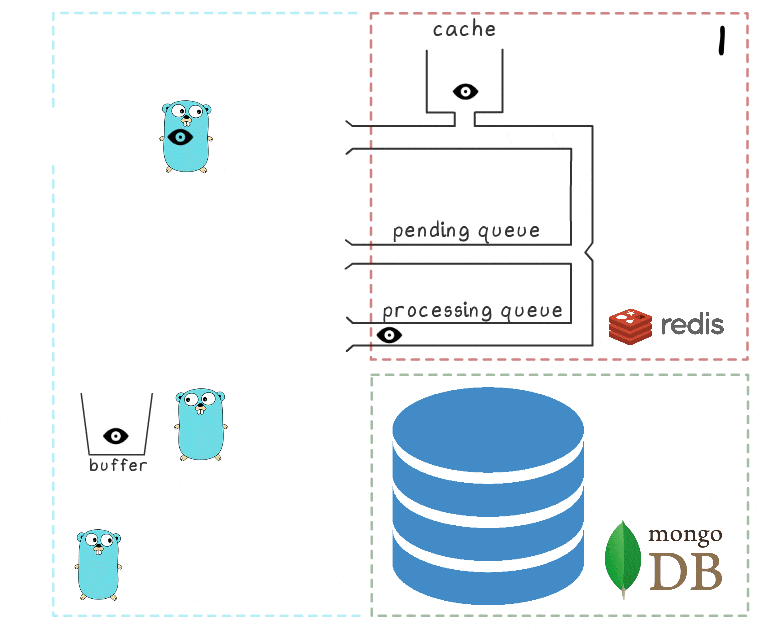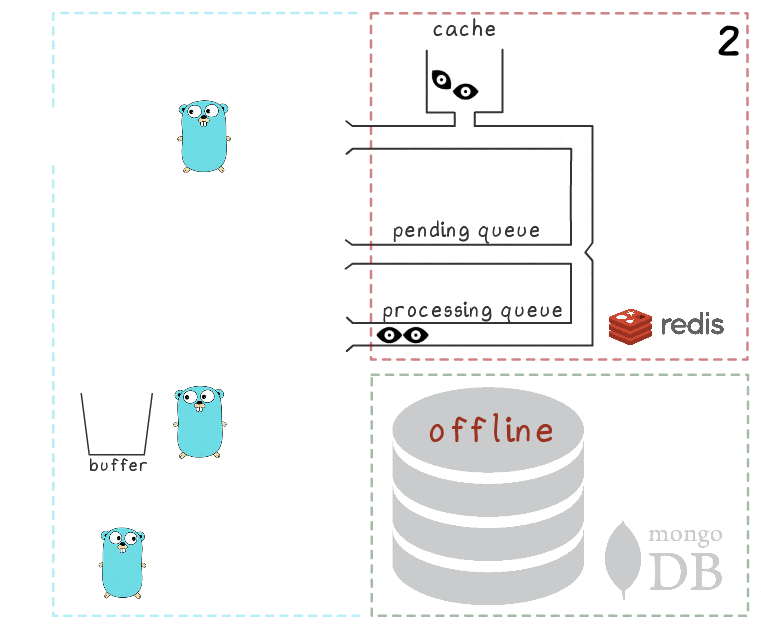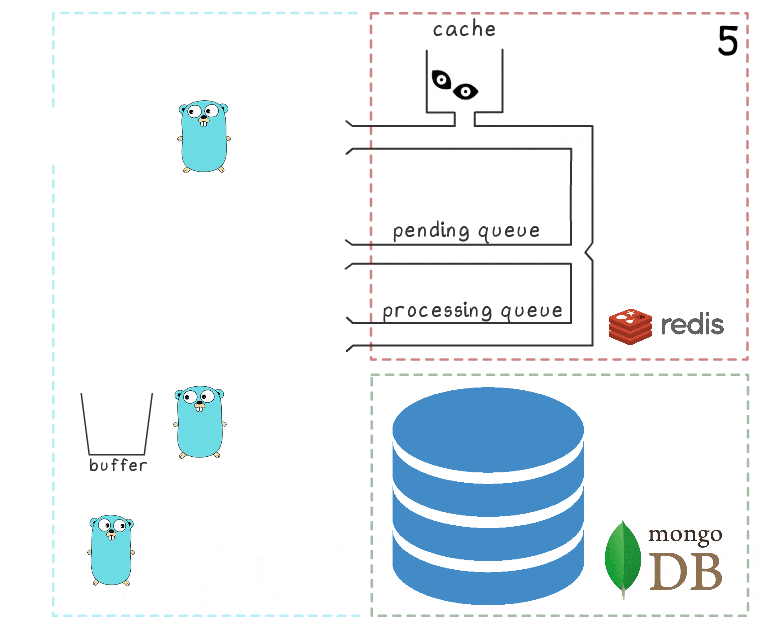
Pour mieux comprendre l'ensemble des étapes du processus, nous avons préparé une petite visualisation. Tout d'abord, regardons un scénario normal et réussi (les étapes sont numérotées dans le coin supérieur droit et sont décrites en détail ci-dessous):
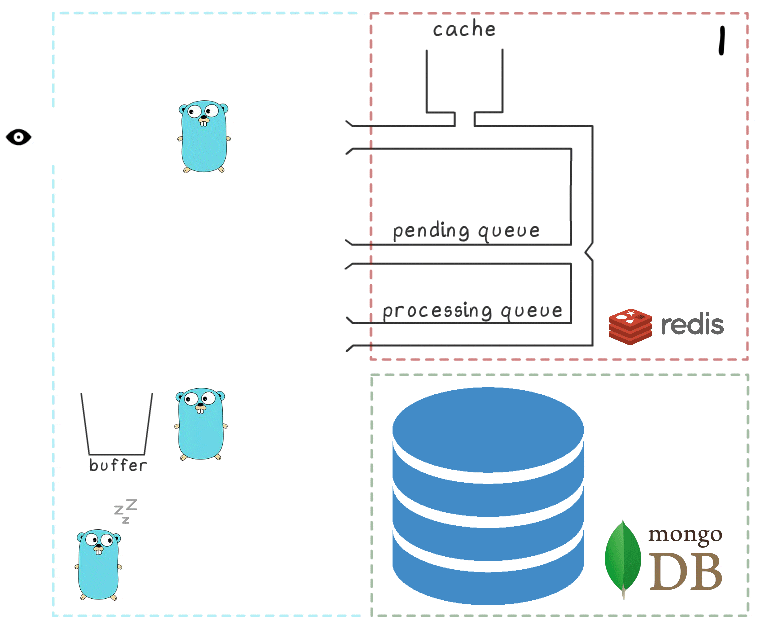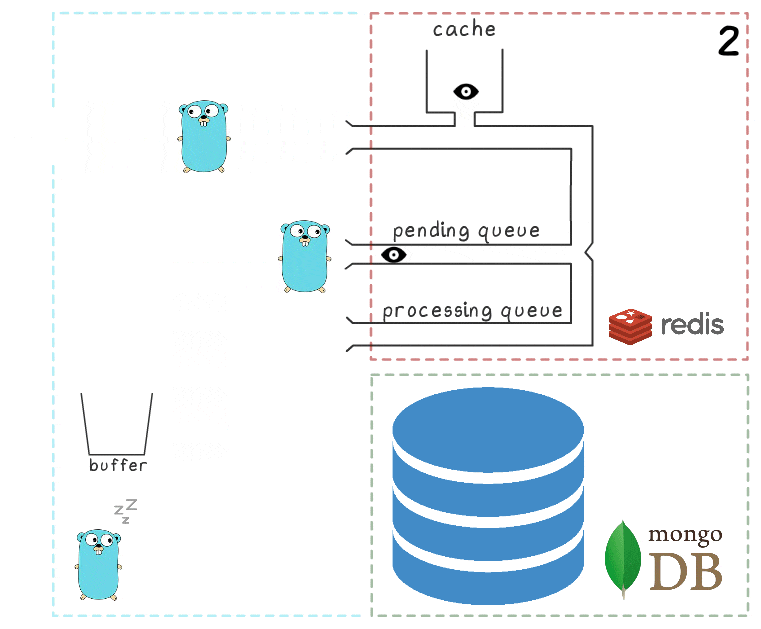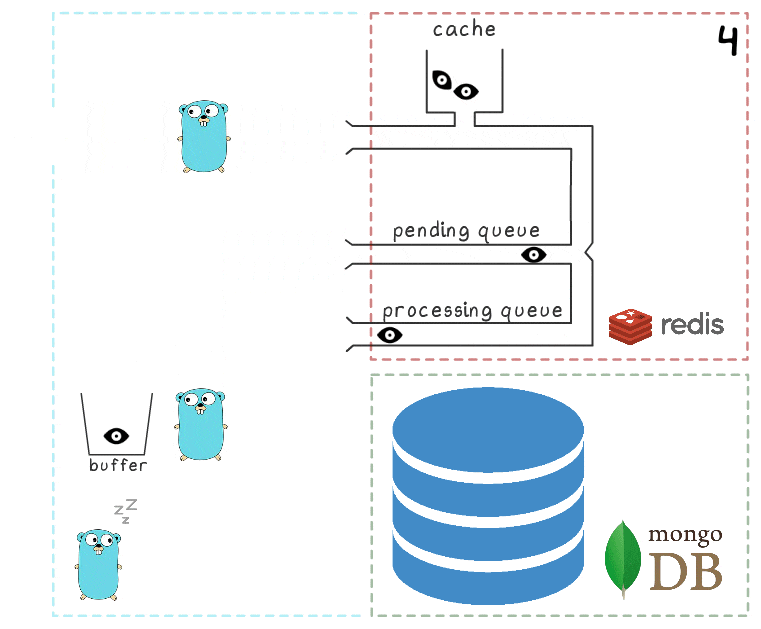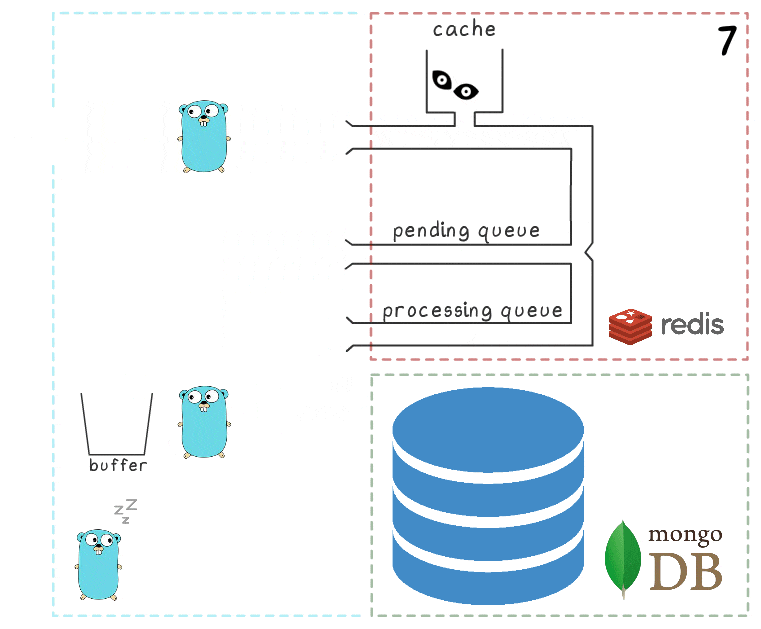
- Le microservice reçoit une demande d'écriture
- Le gestionnaire de requêtes la transmet à un lua-script qui écrit la recherche dans le cache (la rendant immédiatement lisible) et dans la file d'attente pour un traitement ultérieur.
- Le goroutine d'arrière-plan effectue (périodiquement) l'opération BRPopLPush , qui déplace atomiquement un élément d'une file d'attente à une autre (nous l'appelons «file d'attente de traitement» - une file d'attente avec des éléments actuellement traités). Le même élément est ensuite stocké dans un tampon de la mémoire de processus.
- Une autre demande d'écriture arrive et est en cours de traitement, ce qui nous laisse 2 éléments dans le tampon et 2 éléments dans la file d'attente de traitement.
- Après un certain délai, le processus d'arrière-plan décide de vider le tampon dans MongoDB. L'écriture de plusieurs valeurs à partir du tampon est effectuée par une seule demande, ce qui affecte positivement le débit. De plus, avant l'enregistrement, le processus essaie de combiner plusieurs vues en une seule, en résumant leurs valeurs pour les mêmes annonces.
Sur chacun de nos projets, 3 instances de microservices sont utilisées, chacune avec son propre tampon, qui est enregistré dans la base de données toutes les 2 secondes. Pendant ce temps, environ 100 éléments sont accumulés dans un seul tampon.
- Après une écriture réussie, le processus supprime les éléments de la file d'attente de traitement, signalant que le traitement s'est terminé avec succès.
Lorsque tous les sous-systèmes sont en ordre, certaines de ces étapes peuvent sembler redondantes. Et le lecteur attentif peut également avoir une question sur ce que fait le gopher dormant dans le coin inférieur gauche.
Tout est expliqué lorsque l'on considère le scénario où MongoDB n'est pas disponible:
- La première étape est identique aux événements du scénario précédent: le service reçoit 2 demandes d'enregistrement des vues et les traite.
- Le processus perd la connexion avec MongoDB (le processus lui-même, bien sûr, ne le sait pas encore).
Le gestionnaire Gorutin, comme précédemment, essaie de vider son tampon dans la base de données - mais cette fois sans succès. Elle revient à attendre la prochaine itération.
- Un autre goroutine d'arrière-plan se réveille et vérifie la file d'attente de traitement. Elle découvre que les éléments lui ont été ajoutés il y a longtemps; concluant que leur traitement a échoué, elle les replace dans la file d'attente.
- Après un certain temps, la connexion avec MongoDB est rétablie.
- Le premier goroutine d'arrière-plan essaie à nouveau d'effectuer une opération d'écriture - cette fois avec succès - et supprime définitivement les éléments de la file d'attente de traitement.
Dans ce schéma, il existe plusieurs délais d'attente et heuristiques importants dérivés des tests et du bon sens: par exemple, les éléments sont déplacés de la file d'attente de traitement vers la file d'attente en attente après 15 minutes d'inactivité. De plus, le goroutine responsable de cette tâche effectue un
verrouillage avant l'exécution afin que plusieurs instances du microservice n'essaient pas de restaurer les vues «figées» en même temps.
À strictement parler, même ces mesures n'offrent pas de garanties théoriquement justifiées (par exemple, nous ignorons des scénarios comme le processus se bloque pendant 15 minutes) - mais en pratique, cela fonctionne de manière assez fiable.
De plus, dans ce schéma, il y a au moins 2 autres vulnérabilités connues que nous devons connaître:
- Si le microservice est tombé en panne immédiatement après avoir enregistré avec succès dans MongoDb, mais avant d'effacer la liste de files d'attente de traitement, ces données seront considérées comme non enregistrées - et après 15 minutes seront à nouveau enregistrées.
Pour réduire la probabilité d'un tel scénario, nous avons fourni des tentatives répétées de suppression de la file d'attente de traitement en cas d'erreurs. En réalité, nous n'avons pas encore observé de tels cas en production.
- Lorsque vous redémarrez, le radis peut perdre non seulement le cache, mais également certaines vues non enregistrées des files d'attente, car il est configuré pour enregistrer périodiquement des instantanés RDB toutes les quelques minutes.
Bien qu'en théorie cela puisse être un problème sérieux (surtout si le projet traite de données vraiment critiques), en pratique les nœuds sont extrêmement rarement redémarrés. Dans le même temps, selon la surveillance, les éléments passent dans les files d'attente pendant moins de 3 secondes, c'est-à-dire que le montant possible des pertes est très limité.
Il peut sembler qu'il y a plus de problèmes que nous ne le souhaiterions. Cependant, en fait, il s'avère que le scénario que nous avons initialement défendu - l'échec de MongoDB - est en effet une menace bien plus réelle, et le nouveau schéma de traitement des données garantit avec succès la disponibilité du service et évite les pertes.
Un exemple frappant de cela était lorsque l'instance MongoDB à l'un des projets était absurdement indisponible toute la nuit. Pendant tout ce temps, le nombre de vues accumulées et tournées dans un radis d'une file d'attente à une autre, jusqu'à ce qu'elles soient finalement enregistrées dans la base de données après la résolution de l'incident; la plupart des utilisateurs n'ont même pas remarqué l'échec.
Lecture en lecture compte
Les demandes de lecture sont beaucoup plus simples que les demandes d'écriture: le microservice vérifie d'abord le cache dans le radis; tout ce qui ne se trouve pas dans le cache est rempli avec des données de MongoDb et retourné au client.
Il n'y a pas d'écriture de bout en bout dans le cache pendant les opérations de lecture pour éviter la surcharge de protection contre les écritures concurrentes. Le taux de réussite du cache reste bon, car le plus souvent, il sera déjà réchauffé grâce à d'autres demandes d'écriture.
Les statistiques de vue quotidiennes sont lues directement à partir de MongoDB, car elles sont demandées beaucoup moins souvent et la mise en cache est plus difficile. Cela signifie également que lorsque la base de données n'est pas disponible, la lecture des statistiques cesse de fonctionner; mais cela n'affecte qu'une petite partie des utilisateurs.
Schéma de stockage des données MongoDB
Le schéma de collecte MongoDB pour le projet est basé sur
ces recommandations des développeurs de bases de données eux -
mêmes et ressemble à ceci:
- Les vues sont enregistrées dans 2 collections: dans l'une il y a leur montant total, dans l'autre - les statistiques par jour.
- Les données de la collecte de statistiques sont organisées sur la base d' un document par annonce et par mois . Pour les nouvelles annonces, un document rempli de trente et un zéro pour le mois en cours est inséré dans la collection; Selon l'article mentionné ci-dessus, cela vous permet d'allouer immédiatement suffisamment d'espace pour un document sur le disque afin que la base de données n'ait pas à le déplacer lors de l'ajout de données.
Cet élément rend le processus de lecture des statistiques un peu délicat (les demandes doivent être générées par mois du côté du microservice), mais dans l'ensemble, le schéma reste assez intuitif.
- L'opération upsert est utilisée pour l'enregistrement, afin de mettre à jour et, si nécessaire, de créer un document pour l'entité souhaitée dans la même requête.
Nous n'utilisons pas les capacités transactionnelles de MongoDb pour mettre à jour plusieurs collections en même temps, ce qui signifie que nous risquons que les données puissent être écrites dans une seule collection. Pour le moment, nous nous connectons simplement à de tels cas; il y en a peu, et jusqu'à présent, cela ne présente pas le même problème important que d'autres scénarios.
Test
Je ne ferais pas confiance à mes propres mots que les scénarios décrits fonctionnent vraiment s'ils n'étaient pas couverts par des tests.
Étant donné que la plupart du code du projet fonctionne en étroite collaboration avec les radis et MongoDb, la plupart des tests qu'il contient sont des tests d'intégration. L'environnement de test est pris en charge par docker-compose, ce qui signifie qu'il peut être déployé rapidement, offre une reproductibilité en réinitialisant et en restaurant l'état à chaque démarrage, et permet d'expérimenter sans affecter les bases de données d'autres personnes.
Dans ce projet, il existe 3 principaux domaines de test:
- Validation de la logique métier dans des scénarios typiques, les soi-disant chemin heureux. Ces tests répondent à la question - lorsque tous les sous-systèmes sont en ordre, le service fonctionne-t-il conformément aux exigences fonctionnelles?
- Vérification des scénarios négatifs dans lesquels le service devrait poursuivre son travail. Par exemple, le service ne perd-il vraiment pas de données lorsque MongoDb plante?
Sommes-nous sûrs que les informations restent cohérentes avec les délais d'expiration périodiques, les blocages et les opérations d'enregistrement concurrentielles? - Vérification des scénarios négatifs dans lesquels nous ne nous attendons pas à ce que le service continue, mais un niveau minimum de fonctionnalité doit toujours être fourni. Par exemple, il n'y a aucune chance que le service continue d'enregistrer et de renvoyer des données lorsque ni radis ni mongo ne sont disponibles - mais nous voulons être sûrs que, dans de tels cas, il ne se bloque pas, mais attend la récupération du système, puis revient au travail.
Pour vérifier les scénarios infructueux, le code de logique métier de service fonctionne avec les interfaces client de base de données, qui dans les tests nécessaires sont remplacées par des implémentations qui renvoient des erreurs et / ou simulent des retards réseau. Nous simulons également le fonctionnement parallèle de plusieurs instances de service en utilisant le modèle "
objet environnement ". Il s'agit d'une variante de l'approche bien connue «d'inversion de contrôle», où les fonctions n'accèdent pas aux dépendances elles-mêmes, mais les reçoivent via l'objet d'environnement passé dans les arguments. Entre autres avantages, l'approche vous permet de simuler plusieurs copies indépendantes du service en un seul test, chacune ayant son propre pool de connexions à la base de données et reproduisant plus ou moins efficacement l'environnement de production. Certains tests exécutent chacune de ces instances en parallèle et s'assurent qu'ils voient tous les mêmes données, et il n'y a pas de conditions de concurrence.
Nous avons également effectué un test de résistance rudimentaire, mais toujours très utile, basé sur
siège , qui a permis d'estimer approximativement la charge admissible et la vitesse de réponse du service.
À propos des performances
Pour 90% des demandes, le temps de traitement est très court et, surtout, stable; Voici un exemple de mesures sur l'un des projets sur plusieurs jours:
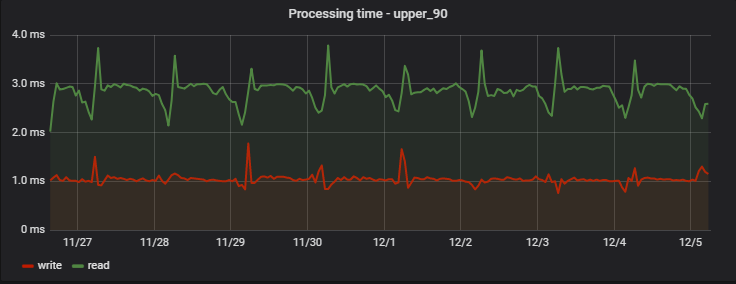
Fait intéressant, un enregistrement (qui est en fait une opération d'écriture + lecture, car il renvoie des valeurs mises à jour) est légèrement plus rapide que la lecture (mais uniquement du point de vue d'un client qui n'observe pas l'écriture en attente réelle).
Une augmentation régulière des retards le matin est un effet secondaire du travail de notre équipe d'analyse, qui recueille quotidiennement ses propres statistiques sur la base des données du service, créant pour nous une «surcharge artificielle».
: ( — MongoDB), ( ), :
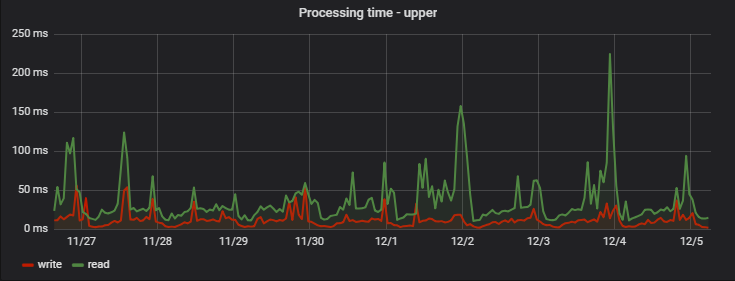
Conclusion
, - , , Redis .
, 95% , . , . 5.
Go, Redis MongoDB . , . , — .