Récemment, Yegor Budnikov, analyste de systèmes au département technologique d'ABBYY, a pris la parole à Yandex lors de la conférence
Data & Science: Law and Records Management . Il a expliqué comment fonctionne la vision par ordinateur, le traitement de texte, ce qui est important de faire attention lors de l'extraction d'informations à partir de documents juridiques et bien plus encore.
- Une entreprise peut avoir développé des méthodologies pour l'analyse des données et la gestion électronique des documents, tandis que les documents créés dans Word peuvent provenir de clients ou des services voisins de l'entreprise, lorsqu'ils sont imprimés, photocopiés, numérisés et amenés sur une clé USB.
Que faire du flux de documents, qui est maintenant, avec des documents «sales», avec du stockage papier, jusqu'au fait que les documents peuvent être stockés jusqu'à 70 ans avant d'être numérisés et doivent être reconnus?
ABBYY développe des technologies d'intelligence artificielle pour les tâches commerciales. L'intelligence artificielle devrait être capable de faire à peu près la même chose qu'une personne dans ses activités quotidiennes ou professionnelles, à savoir: lire des informations sur le monde réel à partir d'une image ou d'un flux d'images. Il peut s'agir non seulement de la vision par ordinateur, mais aussi de l'audition ou de la reconnaissance de données provenant de capteurs, par exemple, de capteurs de fumée ou de température. De plus, les données de ces capteurs entrent dans le système et doivent participer à la décision. Pour réussir à implémenter cette fonction, le système doit éviter les erreurs logiques stupides, comme dans l'image:

Les textes sont difficiles à analyser: la diversité et l'évolution de la langue les rendent beaux et expressifs, mais cela complique la tâche de leur traitement automatique. Habituellement, l'ambiguïté des mots est surmontée par le fait que nous pouvons déterminer par le contexte ce que signifie un mot particulier, mais parfois le contexte laisse place à l'interprétation. Dans la phrase «
Ces types d'acier sont en stock », il est impossible de comprendre avec une précision absolue en termes de contexte: si ce sont les gens dans la pièce qui déjeunent, ou ce sont des types d'acier qui sont stockés dans l'entrepôt. Afin de résoudre cette ambiguïté, un contexte plus large est nécessaire.
La partie inférieure du collage est une image du film "Opération" Y "et des autres aventures de Shurik."Dans le cas général, l'intelligence artificielle ou un robot intelligent doit être capable de se déplacer dans l'espace et d'interagir avec succès avec des objets - par exemple, ramasser la boîte encore et encore, que l'instructeur lui fait tomber des mains.
Enfin, l'intelligence générale et la représentation des connaissances: les connaissances diffèrent des informations en ce que leurs parties interagissent activement les unes avec les autres, générant de nouvelles connaissances. Afin de résoudre efficacement le problème du mélange des cocktails, vous pouvez procéder de la manière la plus simple: lister les ingrédients et indiquer dans quel ordre les mélanger. Dans ce cas, le système ne pourra pas répondre à des questions arbitraires sur le sujet qui l'intéresse. Par exemple, que se passe-t-il si vous remplacez le jus de tomate par de l'ananas. Pour que le système maîtrise mieux le matériel, les bases de données, les taxonomies (arbres conceptuels liés logiquement les uns aux autres), une procédure d'inférence logique doit être ajoutée. Dans ce cas, nous pouvons vraiment dire que le système comprend ce qu'il fait et qu'il pourra répondre à une question arbitraire sur le processus.
L'intelligence artificielle développée par ABBYY traite les documents, c'est-à-dire transforme les supports papier, numérisés et électroniques en informations structurées extraites de ces documents. Arrêtons-nous sur deux volets, comme la vision par ordinateur et le traitement de texte. La vision par ordinateur vous permet de transformer des fichiers PDF, des images numérisées et des images en formats de texte modifiables. Pourquoi est-ce une tâche difficile? Premièrement, les documents peuvent avoir une structure arbitraire.
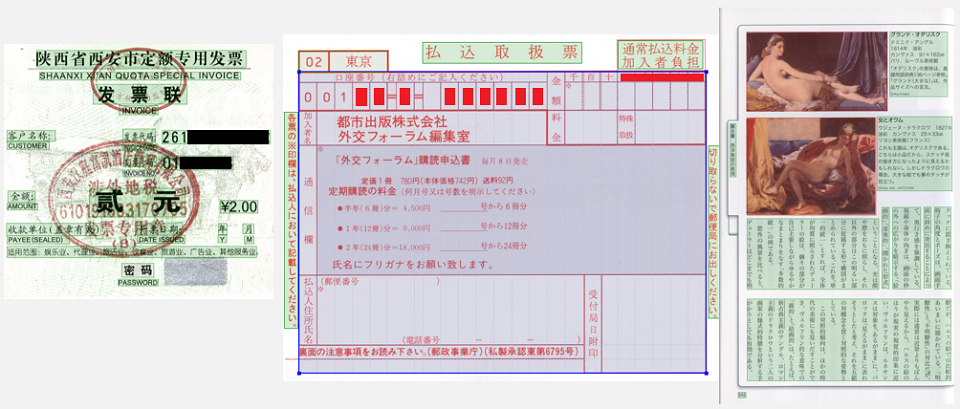
Cela signifie que vous devez d'abord résoudre le problème de l'analyse structurelle des documents: comprendre où se trouvent les blocs de texte, les images, les tableaux, les listes, puis déterminer comment ils interagissent les uns avec les autres. Deuxièmement, les documents peuvent être dans différentes langues. Cela signifie qu'il est nécessaire de prendre en charge la détection de différents types d'écriture et la capacité de reconnaître des mots et des caractères qui peuvent être très différents les uns des autres. Troisièmement, les images nous viennent du monde réel, ce qui signifie que tout peut leur arriver. Ils peuvent être déformés, photographiés avec la mauvaise perspective, ils peuvent avoir des taches de café, des stries de l'imprimante puis du scanner. Tout cela doit être géré d'une manière ou d'une autre afin d'extraire ultérieurement des informations.
Comment fonctionne la reconnaissance d'image avec nous? Dans un premier temps, nous recevons et traitons des images. Le document est nivelé, les distorsions sont corrigées. Ensuite, une analyse de la structure de la page est effectuée, à ce stade, les types de blocs sont trouvés et déterminés. Lorsque les blocs sont définis, les lignes ou les colonnes sont alignées, vous pouvez diviser ces lignes en mots et en caractères - par exemple, des histogrammes verticaux et horizontaux de la distribution de la couleur noire.
Ainsi, il est possible de déterminer où se trouvent les limites des symboles et des mots, puis de reconnaître ce que sont ces symboles et ces mots. Enfin, les blocs reconnus sont synthétisés dans des documents texte simples et exportés.
Vous pouvez regarder ce processus du point de vue d'entités de différents niveaux. Nous avons d'abord un document paginé. Ensuite, ces pages doivent être divisées en blocs, blocs en lignes, lignes en mots, mots en caractères, puis ces caractères doivent être reconnus. Après cela, nous collectons les caractères reconnus en mots, les mots en lignes, les lignes en blocs, les blocs en pages, les pages en document. De plus, au retour, la partition initiale peut varier. L'exemple le plus simple est si les blocs initialement cassés appartenaient à la même liste numérotée, donc ils devraient finalement appartenir au même bloc avec le type de liste structurée. En d'autres termes, les étapes adjacentes peuvent s'influencer mutuellement afin d'améliorer la qualité de reconnaissance.
Le document a été reconnu, vous devez alors en extraire des informations. Les documents peuvent être divisés en documents plus structurés et moins structurés. Les plus structurés comprennent les cartes de visite, les chèques, les factures. Les moins structurés comprennent la procuration, les chartes, les articles dans les magazines. Si le type du document est fixe, il est plus ou moins structuré et les documents de ce type diffèrent peu les uns des autres dans la structure, vous pouvez appliquer des méthodes qui apprennent à extraire directement les attributs nécessaires d'un document texte à l'aide d'attributs texte et graphiques. Par exemple, en utilisant des réseaux de neurones récurrents, vous pouvez extraire des articles de produits de factures. Les factures sont des documents dans lesquels les positions des marchandises et une description des modes de paiement de ces marchandises sont présentées.

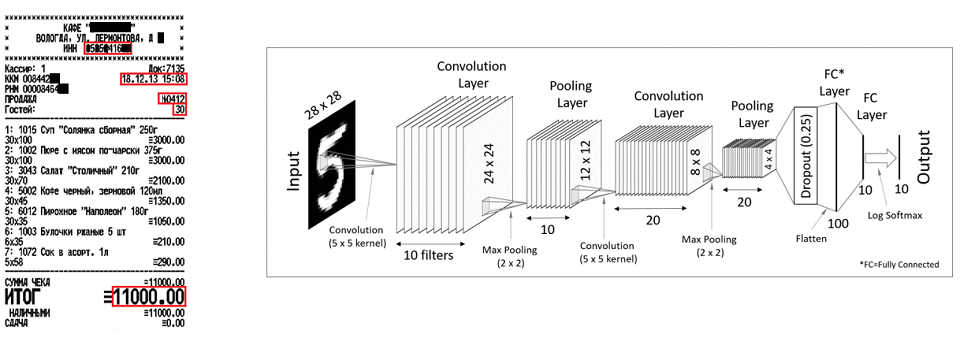
Un autre exemple est celui des chèques. À l'aide de réseaux de neurones convolutifs, vous pouvez récupérer des attributs uniques, tels que le TIN, le numéro de contrôle, la date-heure, le score total. Franchement, les méthodes et les chèques sont utilisés dans les chèques et les factures, mais à des fins différentes. Les réseaux de neurones convolutifs sont bons pour les attributs uniques qui ont une sorte de position, et les réseaux récurrents sont pour les éléments répétés.
Si les documents sont moins structurés, le traitement en langage naturel, le traitement en langage naturel ou les méthodes PNL entrent en jeu. Pourquoi est-ce difficile? J'ai déjà parlé de la polysémie des mots. Le mot adresse, par exemple, peut signifier l'adresse d'une entreprise ou son engagement à résoudre certains problèmes des clients.
De plus, les textes sont souvent omis, mais les mots sont implicites. Pour extraire des informations, vous devez récupérer ces mots manquants. Cet effet en linguistique est appelé «points de suspension».
La langue est diverse et il existe généralement d'innombrables façons d'exprimer une seule et même pensée. Afin de traiter automatiquement les textes, il est nécessaire de réduire en quelque sorte cette variabilité: l'utilisation de synonymes et de constructions similaires afin de remplacer un seul mot ou expression; permutation de mots ou changement de voix grammaticale. Par exemple, «les entreprises ont conclu un accord» et «un accord a été conclu entre les entreprises» afin de dire la même chose. Dans le cas des synonymes, on peut introduire ce qu'on appelle l'espace sémantique, un espace vectoriel dans lequel les mots sont représentés sous forme de points. Les points de fermeture indiquent des concepts liés, les points éloignés indiquent des concepts plus éloignés. Pour réduire la variabilité des formulations, vous pouvez introduire des arbres d'analyse syntaxique et sémantique. Dans ce cas, un problème similaire est également résolu et l'algorithme d'extraction d'informations est capable d'extraire des informations, même s'il rencontre des constructions ou des mots qui n'étaient pas trouvés auparavant dans l'ensemble d'apprentissage.
Comment les informations sont-elles extraites? Dans un premier temps, une analyse lexicale du document est réalisée. Le texte est divisé en paragraphes, paragraphes en phrases, phrases en mots. Cela peut ne pas être trivial: ceux d'entre vous qui connaissent la PNL savent peut-être que même une tâche apparemment aussi simple que de décomposer du texte en phrases peut être difficile: les points n'indiquent pas toujours la fin d'une phrase. Ces abréviations peuvent être inconnues, par conséquent, dans l'analyse lexicale, nous essayons de trier toutes les options possibles pour décomposer les phrases en mots et laisser la plus probable. Ce problème, en règle générale, nous rencontrons dans les langues dans lesquelles un petit nombre ou une absence totale d'espaces, comme le japonais ou le chinois. Ou qui ont une riche formation de mots. C'est, par exemple, une langue comme l'allemand: elle a des mots très longs qui se composent de plusieurs mots (ces mots sont appelés composites). De plus, pour tous ces mots, toutes les interprétations possibles sont calculées. Par exemple, si «g» apparaît dans le texte avec un point, cela peut signifier beaucoup: ville, année, gramme, gentleman et même le quatrième paragraphe (a, b, c, d).

Ensuite, la segmentation est effectuée, c'est-à-dire une recherche des sections qui nous intéressent. Il est produit pour diverses raisons, par exemple, pour accélérer le traitement des documents ou trouver des informations qui nous intéressent; pour trouver une partie du document qui décrit les obligations de la partie. Ou c'est une accélération du traitement, par exemple, notre document peut être composé de plusieurs dizaines voire centaines de pages dans des cas particulièrement avancés, alors que des informations intéressantes ne sont contenues que dans quelques pages. La segmentation vous permet de trouver ces pièces intéressantes et de les analyser uniquement. Ensuite, une analyse sémantique du document peut ou non être effectuée, cela dépend de la tâche, et à ce stade, la recherche est faite pour les meilleures interprétations des phrases, toutes les phrases du document ou seulement celles que nous avons trouvées à l'étape précédente. Les caractéristiques sémantiques pour le classificateur sont également générées à l'étape suivante.
Enfin, l'étape d'extraction directe des attributs. Des modèles formés à la machine sont utilisés ici ou des modèles simples sont écrits. D'une manière ou d'une autre, ils s'appuient sur des signes générés par les étapes précédentes. Ce sont des caractéristiques structurelles, à la fois lexicales et sémantiques. Selon la complexité de la tâche, nous utilisons de nombreuses méthodes différentes: méthodes d'apprentissage automatique et méthodes d'écriture de modèles. A ce stade, nous recherchons les attributs qui nous intéressent. Il peut s'agir des noms des parties, des obligations, de la date de signature, etc.
Enfin, certains attributs peuvent nécessiter un post-traitement. Mise en forme normale ou casting vers un modèle de date. Certains attributs peuvent être calculés en principe, ils ne sont pas extraits du contrat, mais sont calculés sur la base des attributs extraits du contrat. Par exemple, la durée du contrat en fonction du début de l'action et de sa fin.
Considérez cela dans l'un des scénarios, cela s'appelle «Ouvrir un compte avec une entité juridique». Quel est le défi? Une personne morale, ou plutôt son représentant, vient à la banque et apporte une lourde pile de documents. Dans un bon cas, il a déjà scanné ces documents, mais on ne sait pas avec quelle qualité. Afin d'optimiser le processus, de réduire le nombre d'erreurs dans la saisie de ces informations dans le système, d'accélérer ce processus et donc d'accélérer la prise de décision et de fidéliser la clientèle, le schéma suivant a été proposé:
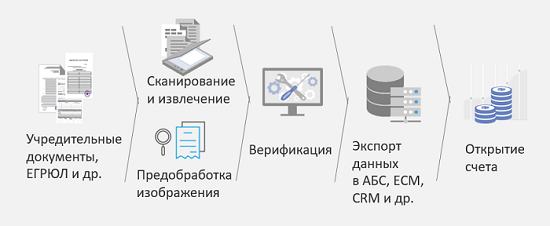
Les documents constitutifs, qui comprennent de nombreux types différents, sont d'abord numérisés, puis reconnus. De plus, après la reconnaissance, ils sont classés par différents types, et selon le type, différents algorithmes peuvent être utilisés pour reconnaître et extraire des informations. Ensuite, ces informations extraites, si nécessaire, sont envoyées aux gens pour vérification, et après cela, il est déjà possible de prendre une décision: ouvrir un compte ou d'autres documents supplémentaires sont nécessaires. Le principal résultat de cette décision est de réduire de moitié le coût de la saisie des données lors de l'ouverture d'un compte. Résultats basés sur les mesures de notre client.
Quels attributs devez-vous récupérer? Beaucoup de choses. Supposons que nous ayons une sorte de charte. Nous le reconnaissons d'abord. Comme nous nous en souvenons, cela peut être assez problématique s'il s'agit d'une numérisation ou d'une photographie. Ensuite, nous déterminons le type de document, ce qui est important car les informations dont nous avons besoin peuvent être contenues dans un chapitre ou un paragraphe spécifique, et donc la connaissance du début ou de la fin de ce chapitre ou de ce paragraphe aide grandement l'algorithme d'extraction d'informations.
Ensuite, la machine récupère toutes les entités de base qu'elle peut atteindre:
Cela est nécessaire pour qu'à l'étape suivante d'extraction d'attributs ou de définition de rôles, l'algorithme puisse utiliser non seulement le contexte, mais aussi les caractéristiques qui ont été générées dans les étapes précédentes. Par exemple, cela peut grandement simplifier la tâche de déterminer qui est le directeur d'une entité juridique, information qu'il s'agit d'une sorte de personne. En conséquence, parmi l'ensemble des personnes qui apparaissent dans le document, il faut les classer, le réalisateur ou non le réalisateur. Lorsque nous avons un nombre limité d'objets, cela simplifie considérablement la tâche.
Au cours des deux dernières années, nous avons rencontré plusieurs autres tâches de clients et les avons résolues avec succès. Par exemple, la surveillance des médias pour les risques d'entreprise.
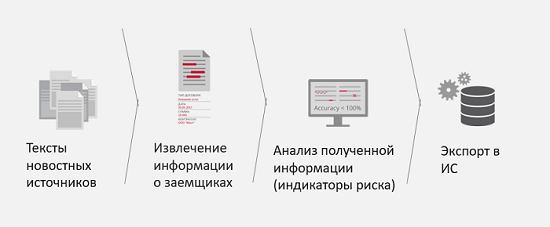
Quel est le défi commercial ici? Par exemple, vous avez un partenaire ou un client potentiel qui souhaite vous contracter un prêt. Afin d'accélérer le traitement des données de ce client et de réduire les risques d'un mauvais partenariat ou de la faillite future de cette entité juridique, il est suggéré de surveiller les médias pour les références à cette personne physique ou morale et pour la présence de soi-disant indicateurs de risque dans l'actualité. Autrement dit, si, par exemple, dans les actualités, il apparaît constamment qu'une entité juridique est impliquée dans une procédure judiciaire ou qu'une entreprise est brisée par des conflits entre actionnaires, il est préférable de le savoir plus tôt afin de transmettre ces informations aux analystes ou au système analytique et de comprendre à quel point c'est mauvais ou bon pour votre entreprise. . Le résultat de la résolution de ce problème est d'obtenir des informations plus complètes et précises sur l'emprunteur, et le temps nécessaire pour obtenir ces informations est également réduit.

Un autre exemple d'une application dans laquelle il est nécessaire de réduire la quantité de routine et le nombre d'erreurs lors de la saisie d'informations dans le système est l'extraction des données des contrats. Il est proposé que les contrats les reconnaissent, en extraient des informations et les envoient immédiatement au système. Après cela, le service du personnel vous remercie en larmes et vous souhaite la bienvenue à chaque réunion.
Non seulement le département des ressources humaines souffre de beaucoup de travail de routine avec la documentation entrante, mais aussi les départements comptables, les départements des ventes et les départements des achats. Les employés doivent passer beaucoup de temps à saisir les informations des factures, des actes entrants, etc.

En fait, tous ces documents sont structurés et il est donc facile de les reconnaître et d'en extraire des informations. La vitesse de saisie des données est augmentée jusqu'à 5 fois et le nombre d'erreurs est réduit, car le facteur humain est exclu. Conditionnellement, si un employé revient après le déjeuner, il peut commencer à saisir des données de manière inattentive. Nos propres mesures et l'industrie, qui d'une manière ou d'une autre est impliquée dans la saisie manuelle d'informations dans les systèmes, suggèrent que si une personne saisit des données à partir d'un document, et le fait de manière continue et dans un flux, elle obtient rarement une qualité supérieure à 95%, et plus souvent et plus de 90%. Par conséquent, une personne doit être comptée, revérifiée encore plus que derrière une machine.
De plus, si la machine donne une sorte d’évaluation de la confiance qu’elle n’a pas extraite - par exemple, certains documents peuvent être sales - et la machine n’est pas sûre qu’elle l’a fait, mais elle peut signaler au vérificateur qu’elle n’est pas très sûre de ce résultat. : "Veuillez vérifier." Et une personne revérifie les informations individuelles afin qu'elles soient de haute qualité. Ce n'est pas une telle opération de routine: il ne vérifie que les moments vraiment importants et difficiles, ses yeux ne sont pas flous.
Si des informations peuvent être extraites de documents, ces informations peuvent être comparées.
Ceci est important dans deux cas. Premièrement, pour comparer différentes versions d'un même document, par exemple un contrat qui a longtemps été cohérent, des modifications y sont constamment apportées des deux côtés. Deuxièmement, il s'agit d'une comparaison de documents de différents types, par exemple, s'il existe un accord qui indique ce qui devrait venir de notre partenaire, d'autre part, il existe différentes factures et rapports, estimations, etc. Nous devons les corréler et comprendre que tout est en ordre, et sinon, signaler d'une manière ou d'une autre aux personnes responsables.
Le développement actuel de la technologie en vision par ordinateur, le traitement des documents structurés et non structurés est si élevé que même maintenant et dans les années à venir, il y aura une transformation numérique des processus de routine dans les entreprises, car elle est moins chère, plus rapide et souvent meilleure.
De plus, toutes ces méthodes ne sont nullement destinées à remplacer des personnes. Au contraire, j'aime l'exemple de comparaison avec l'outil Excel, dans lequel vous pouvez faire beaucoup et cet outil n'est pas destiné à remplacer les analystes, les gestionnaires ou quiconque. Il est conçu pour étendre les capacités humaines et simplifier la solution des tâches pour lui.
Ainsi, les solutions liées à l'intelligence artificielle sont également conçues pour réduire le nombre d'opérations de routine répétitives dans lesquelles une personne fait souvent plus d'erreurs qu'une machine afin de décharger les ressources de l'entreprise et de les orienter vers la résolution de tâches plus créatives et intellectuelles. Et il semble que nous nous y déplacions à toute vapeur. Je vous remercie