
La boutique en ligne Ozon a à peu près tout: réfrigérateurs, aliments pour bébés, ordinateurs portables pour 100 000, etc. Cela signifie que tout cela se trouve également dans les entrepôts de l'entreprise - et plus les marchandises sont longues, plus l'entreprise coûte cher. Pour savoir combien et ce que les gens voudraient commander, et Ozon devrait acheter, nous avons utilisé l'apprentissage automatique.
Prévisions de ventes: défis
Avant de plonger dans l'énoncé du problème, nous commençons par un exemple. Il s'agit d'un véritable calendrier de vente Ozon pendant un certain temps. Question: où ira-t-il ensuite?
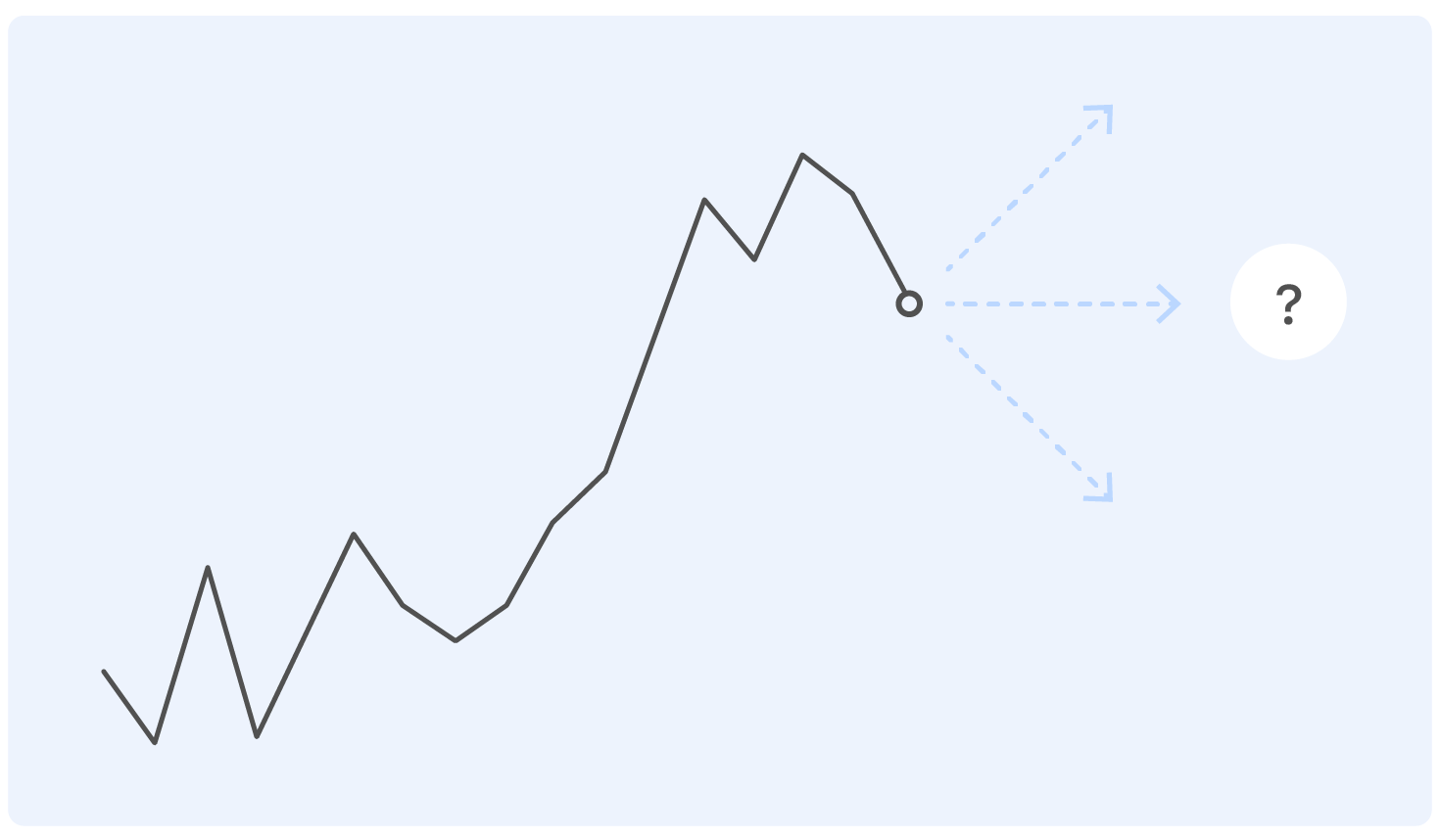
Une personne ayant une formation quasi technique pour une telle formulation du problème aura des questions: Où sont les axes? Et quel genre de produit? Et dans quelles unités? De quel institut avez-vous obtenu votre diplôme? - et bien d'autres non inclus dans cet article pour des raisons éthiques.
En fait, personne ne peut répondre correctement à la question dans une telle déclaration, et si quelqu'un le peut, il est fort probable qu'il se trompera.
Ajoutez plus d'informations à ce graphique: axes et changements de prix sur le site web d'Ozon (bleu) et le site du concurrent (orange).
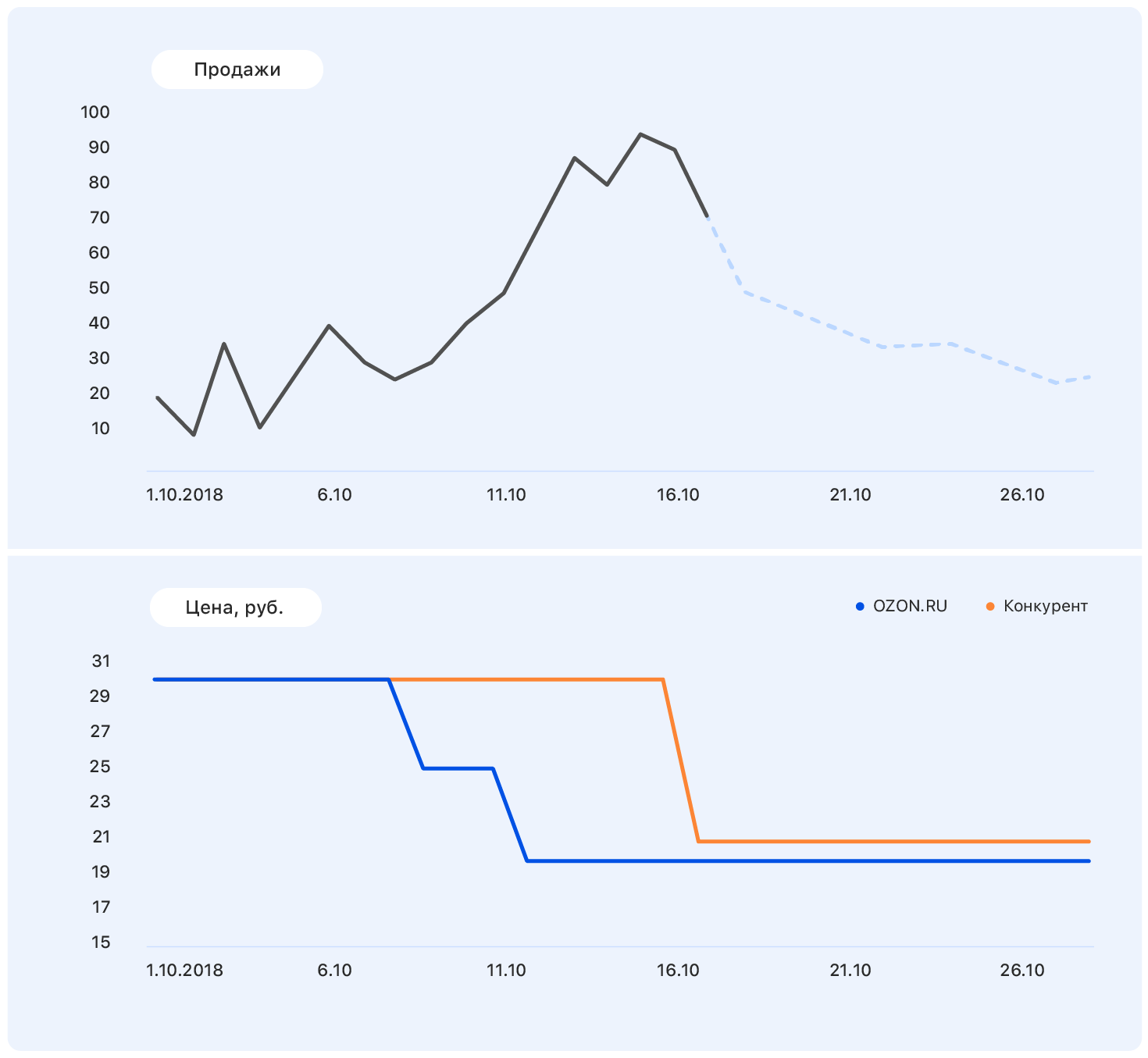
Notre prix a chuté à un moment donné, mais la concurrence est restée la même - et les ventes d'Ozon ont augmenté. Nous connaissons les plans tarifaires: notre prix restera au même niveau, mais le concurrent, après Ozon, a baissé le prix à presque le nôtre.
Ces données sont suffisantes pour faire une hypothèse significative - par exemple, que les ventes reviendront au niveau précédent. Et si vous regardez le tableau, il s'avère que ce sera le cas.
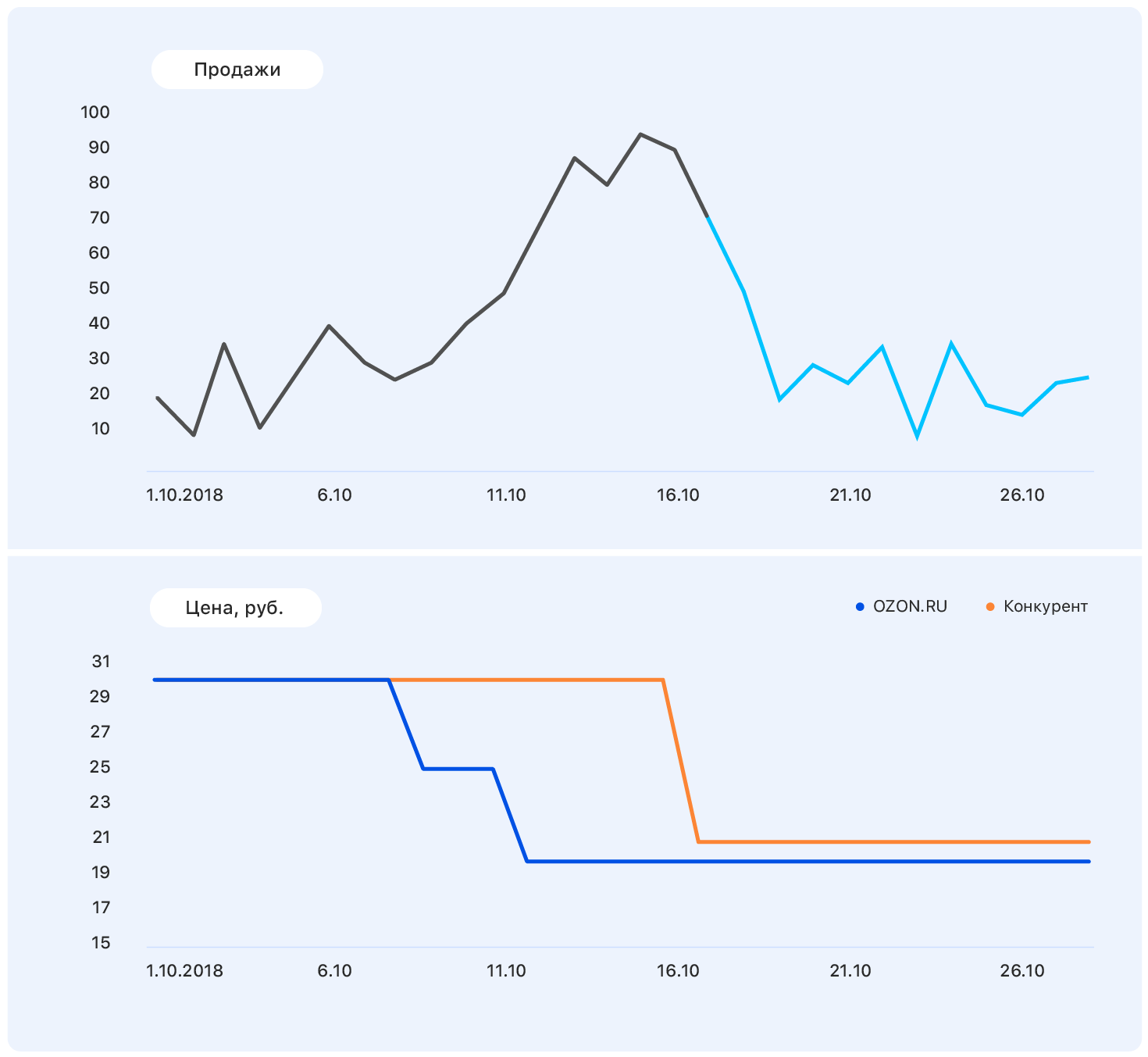
Le problème est qu'en fait, la demande pour ce produit n'est pas tellement affectée par le prix, et la croissance des ventes a été causée, entre autres, par l'absence de la plupart des concurrents de ce produit dans notre magasin. Il y a encore de nombreux facteurs que nous n'avons pas pris en compte: les marchandises ont-elles été annoncées à la télévision? ou peut-être que ce sont des bonbons, et bientôt le 8 mars?
Une chose est claire: faire des prévisions "à genoux" ne fonctionnera pas. Nous avons suivi le chemin standard d'un
râteau et de béquilles pour construire n'importe quel algorithme ML. Et c'est comme ça.
Sélection métrique
Le choix d'une métrique est par où commencer si au moins une autre personne que vous utilisera vos prévisions.
Prenons un exemple: nous avons trois options de prévision. Quel est le meilleur?
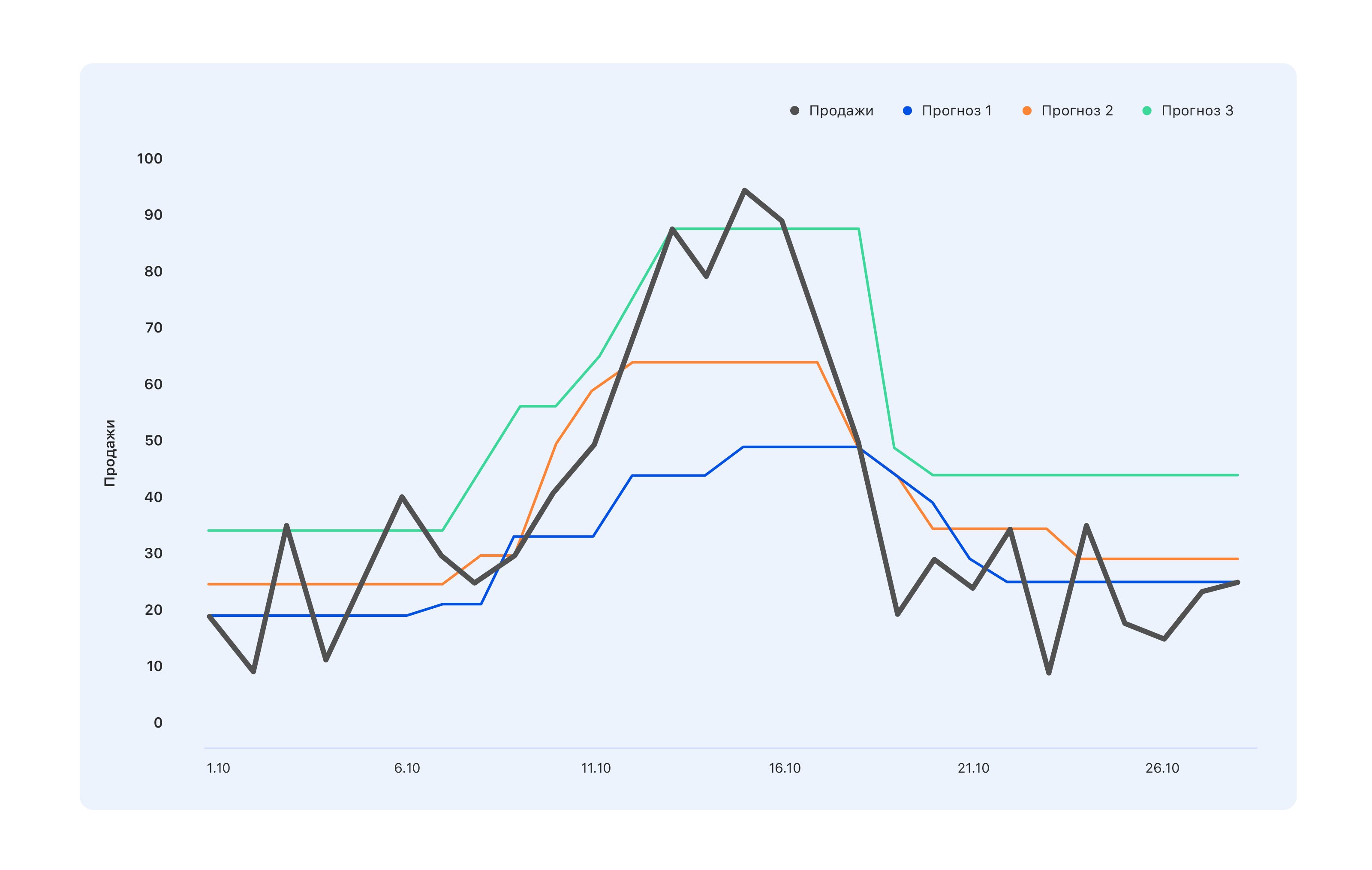
Du point de vue des spécialistes de l'entrepôt, nous avons besoin d'une prévision bleue - nous achèterons un peu moins, et nous manquerons le pic de la mi-octobre, mais rien ne restera dans l'entrepôt. Les experts dont les KPI sont liés aux ventes sont d'un avis contraire: même la prévision turquoise n'est pas tout à fait correcte, tous les sauts de demande ne se sont pas reflétés - allez la modifier. Mais du point de vue d'une personne, de l'extérieur, quelque chose de mieux est généralement en ordre - pour que tout le monde se sente bien ou vice versa.
Par conséquent, avant de faire une prévision, il est nécessaire de déterminer qui l'utilisera et pourquoi. Autrement dit, choisissez une métrique et comprenez à quoi vous attendre d'une prévision basée sur une telle métrique. Et attendez juste ça.
Nous avons choisi MAE - l'erreur absolue moyenne. Cette métrique convient à notre échantillon d'entraînement très déséquilibré. Étant donné que l'assortiment est très large (1,5 million d'articles), chaque produit individuellement dans une région particulière est vendu en petites quantités. Et si au total nous vendons des centaines de robes vertes, alors une robe verte particulière avec des chats est vendue 2-3 fois par jour. En conséquence, l'échantillon se déplace vers de petites valeurs. D'autre part, il y a des iPhones, des filateurs, un nouveau livre d'Olga Buzova (une blague), etc. - et ils sont vendus dans n'importe quelle ville en grandes quantités. MAE vous permet de ne pas obtenir d'énormes amendes sur les iPhones conditionnels et fonctionne généralement bien sur la majeure partie des marchandises.
Premiers pas
Nous avons commencé par construire la prévision la plus stupide qui pourrait être: un nombre aléatoire de 0 à 1000 sera vendu au cours de la semaine prochaine et obtiendra la métrique MAE = 496. Probablement, cela peut être pire, mais c'est déjà très mauvais. Nous avons donc eu une directive: si nous obtenons une telle valeur métrique, alors évidemment nous faisons quelque chose de mal.
Ensuite, nous avons commencé à jouer avec des gens qui savent faire des prévisions sans apprentissage automatique, et avons essayé de prédire les ventes de marchandises au cours de la semaine prochaine égales aux ventes moyennes de toutes les dernières semaines, et nous avons obtenu la métrique MAE = 1,45 - ce qui est beaucoup mieux.
Toujours dans la même logique, nous avons décidé que les ventes de la semaine dernière ne seraient pas plus pertinentes pour prévoir les ventes de la semaine prochaine. Pour une telle prévision, le MAE était de 1,26. Lors de la prochaine série de réflexions pronostiques, nous avons décidé de prendre en compte les deux facteurs et de prédire les ventes de la semaine prochaine comme la somme de 50% des ventes moyennes et de 50% des ventes de la semaine dernière - nous avons obtenu MAE = 1,23.
Mais cela nous a paru trop simple, et nous avons décidé de compliquer les choses. Nous avons recueilli un petit échantillon de formation dans lequel les signes étaient des ventes passées et moyennes, et les cibles étaient des ventes au cours de la semaine suivante, et nous avons formé sur lui une régression linéaire simple. Nous avons obtenu des poids de 0,46 et 0,55 pour la moyenne et les dernières semaines et le MAE sur l'échantillon d'essai égal à 1,2.
Conclusion: nos données ont un potentiel prédictif.
Ingénierie des fonctionnalités
Après avoir décidé que la construction d'une prévision sur deux bases n'est pas notre niveau, nous nous sommes assis pour générer de nouvelles fonctionnalités complexes. Il s'agit d'informations sur les ventes passées - il y a 1, 2, 3, 4 semaines, une semaine il y a exactement un an, etc. Et les vues des dernières semaines, les ajouts au panier, la conversion des vues et les ajouts au panier en commandes - et tout cela pour différentes périodes.
Nous devions fournir un modèle de connaissances sur la façon dont un produit dans son ensemble est vendu, comment la dynamique de ses ventes a changé récemment, comment son intérêt évolue, comment ses ventes dépendent des prix et d'autres facteurs qui, à notre avis, peuvent être utiles.
Lorsque nos idées se sont épuisées, nous sommes allés voir les experts du service commercial. Là, par exemple, nous avons appris que l'année suivante est l'année du porc, par conséquent, les produits ressemblant au moins à des porcs à distance seront très populaires. Ou, par exemple, que «sans gel», nos gens n'achètent pas à l'avance, mais exactement le jour des premières gelées - veuillez donc tenir compte des prévisions météorologiques. En général, tout le monde était satisfait. Nous - parce que nous avons reçu un tas d'idées nouvelles auxquelles nous n'aurions jamais pensé, nous et les hommes d'affaires - que bientôt il sera possible de faire quelque chose de plus intéressant que les prévisions de ventes.
Mais c'est encore trop simple - et nous avons ajouté des symptômes combinés:
- conversion des vues en ventes - comment c'était, comment ça a changé;
- le rapport des ventes sur 4 semaines aux ventes de la semaine dernière (si ce chiffre est très différent de 4, la demande de ce produit est actuellement soumise à des "turbulences");
- le rapport des ventes de produits aux ventes dans toute la catégorie - si ce chiffre est proche de un, alors le produit est un «monopole».
À ce stade, vous devez trouver autant que possible - jetez les panneaux non informatifs au stade de la formation.
En conséquence, nous avons obtenu 170 signes. Pour l’avenir, la plus grande importance
- Ventes de la semaine dernière (pour deux, trois et quatre).
- La disponibilité du produit la semaine dernière est le pourcentage de temps pendant lequel le produit était présent sur le site.
- Le coefficient angulaire du calendrier des ventes de marchandises pour les 7 derniers jours.
- Le rapport du prix passé à l'avenir - avec une remise énorme, commencez à acheter des marchandises plus activement.
- Le nombre de concurrents directs sur notre site. Si, par exemple, ce stylo est le seul de sa catégorie, les ventes seront plutôt stationnaires.
- Dimensions du produit - il s'est avéré que la longueur et la largeur affectent considérablement la prévisibilité des ventes. Pour une raison quelconque, pour les objets longs et étroits - parapluies ou cannes à pêche, par exemple - le calendrier est beaucoup plus volatil. Nous ne savons pas encore comment l'expliquer.
- Numéro de jour de l'année - il indique si la nouvelle année arrive, le 8 mars, le début d'une augmentation saisonnière des ventes, etc.
Échantillonnage
L'échantillon d'entraînement est la douleur. Nous l'avons recueilli pendant environ 4 semaines, dont deux sont simplement allés à différents dépositaires de données et ont demandé à voir ce qu'ils avaient. Cela se produit chaque fois que vous avez besoin de données pendant une longue période. Même dans un système de collecte de données idéal, pendant longtemps, quelque chose se passera dans l'esprit de «nous avions l'habitude de penser cette chose comme ça, mais ensuite nous avons commencé à penser différemment et à écrire les données dans la même colonne». Il y a un an ou deux, le serveur est tombé en panne, mais personne n'a noté exactement quand - et les zéros ne signifient plus qu'il n'y a eu aucune vente.
En conséquence, nous avons eu des informations sur ce que les gens ont fait sur le site, quoi et en quelles quantités, ils ont été ajoutés aux favoris et à un panier, et achetés. Nous avons collecté un échantillon d'environ 15 millions d'échantillons de 170 fonctionnalités chacun, l'objectif était le nombre de ventes pour la semaine prochaine.
Nous avons écrit 2 000 lignes de code sur Spark. Cela a fonctionné lentement, mais a permis de mâcher d'énormes quantités de données. Il semble simplement que le calcul de la pente d'une ligne droite soit simple. Et pour le faire 10kk fois lorsque les ventes sont tirées de plusieurs bases - la tâche n'est pas pour les faibles de cœur.
Pendant une autre semaine, nous avons été engagés dans le nettoyage des données afin que le modèle ne soit pas distrait par les émissions et les caractéristiques d'échantillonnage local, mais extrait uniquement les véritables dépendances inhérentes aux ventes d'Ozon. Voici 3 sigma et des méthodes plus astucieuses pour rechercher des anomalies. Le cas le plus difficile est de rétablir les ventes pendant les périodes de manque de marchandises en stock. La solution la plus simple est de jeter les semaines où le produit était sorti pendant la semaine «ciblée».
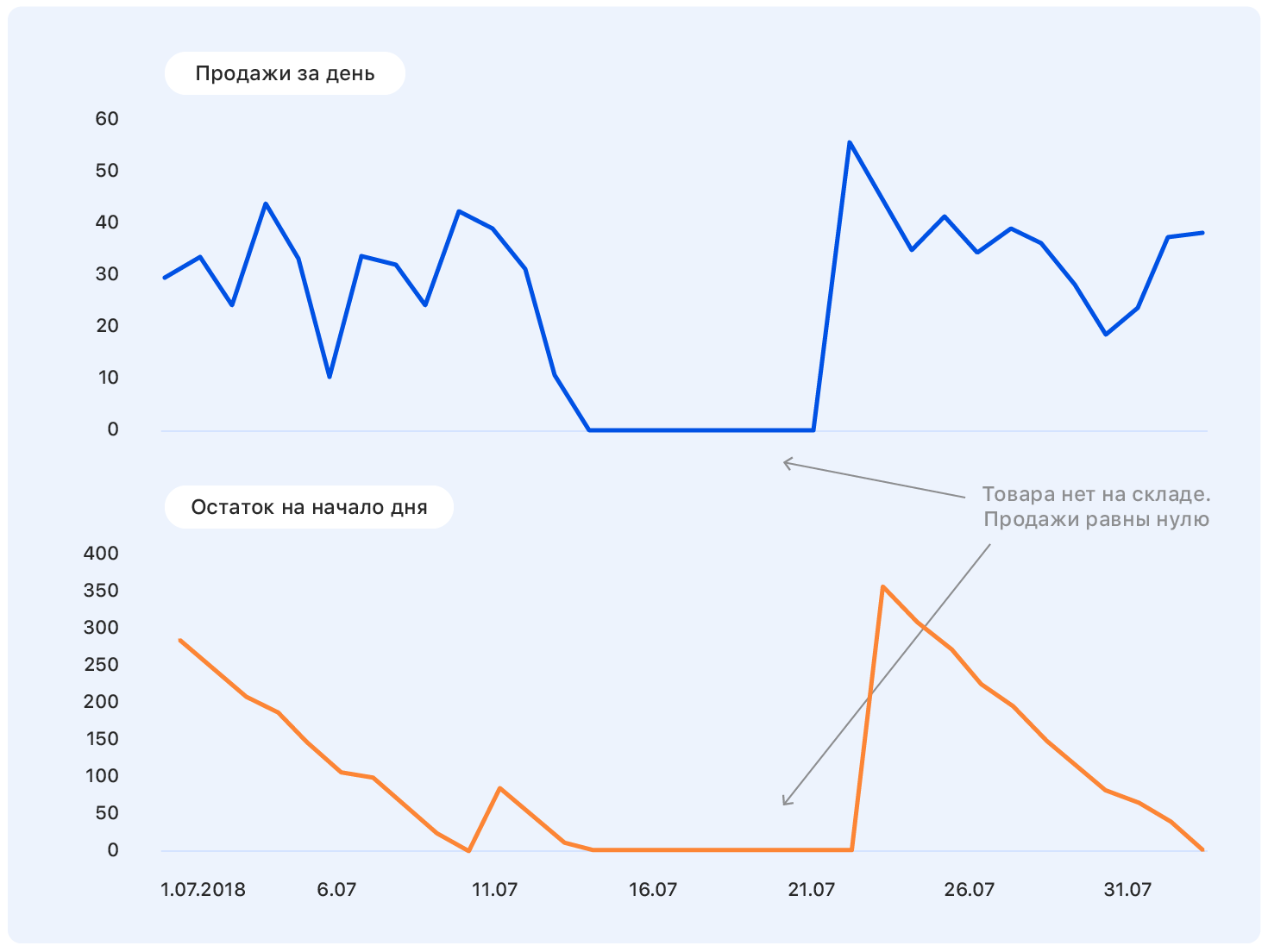
En conséquence, sur 15 millions d'échantillons, il en reste 10 millions. Il importe ici de ne pas se laisser emporter et de ne pas perdre l'intégralité de l'échantillon (en fait, le manque de marchandises dans l'entrepôt est une caractéristique indirecte de son importance pour l'entreprise; retirer ces marchandises de l'échantillon n'est pas la même chose que jeter des échantillons aléatoires )
Temps ML
Sur un échantillon propre et a commencé à former des modèles. Naturellement, nous avons commencé par une régression linéaire et avons obtenu MAE = 1,15. Il semble que ce soit une très petite augmentation, mais lorsque vous avez un échantillon de 10 millions dans lequel les valeurs moyennes sont de 5 à 10, même un petit changement dans la valeur métrique donne une augmentation incommensurable de la qualité visuelle de la prévision. Et comme vous devrez éventuellement présenter la solution aux clients professionnels, augmenter leur niveau de joie est un facteur important.
Ensuite, sklearn.ensemble.RandomForestRegressor, qui après une courte sélection d'hyperparamètres a montré MAE = 1,10. Ensuite, nous avons essayé XGBoost (où sans lui) - tout irait bien et MAE = 1,03 - seulement très longtemps. Malheureusement, nous n'avions pas accès au GPU pour former XGBoost, et sur les processeurs un modèle a été formé pendant très longtemps. Nous avons essayé de trouver quelque chose de plus rapide et nous nous sommes installés sur LightGBM - il s'est entraîné deux fois plus vite et a montré MAE encore un peu moins - 1.01.
Nous avons divisé tous les produits en 13 catégories, comme dans le catalogue sur le site: tables, ordinateurs portables, bouteilles, et pour chaque catégorie, nous avons formé des modèles avec différentes profondeurs de prévision - de 5 à 16 jours.
La formation a duré environ cinq jours, et pour cela, nous avons créé d'énormes grappes informatiques. Nous avons développé un tel pipeline: la recherche aléatoire fonctionne depuis longtemps, donne les 10 premiers ensembles d'hyperparamètres, puis le scientifique travaille avec eux manuellement - construit des métriques de qualité supplémentaires (nous avons calculé le MAE pour différentes plages de cibles), construit des courbes d'apprentissage (par exemple, nous avons jeté une partie de la formation échantillons et formés à nouveau, en vérifiant pour voir si les nouvelles données réduisent la perte sur l'échantillon de test) et d'autres graphiques.
Un exemple d'analyse détaillée pour l'un des ensembles d'hyperparamètres:
Métrique de qualité détailléeCoffret de train:
| Ensemble de test:
|
| Pour cible = 0, MAE = 0,142222484602 | Pour 0 MAE = 0,141900737761 |
| Pour la cible> 0, MAPE = 45.168530676 | Pour> 0 MAPE = 45.5771812826 |
| Erreurs supérieures à 0 - 67,931341691% | Erreurs supérieures à 0 - 51,6405939896% |
| Erreurs supérieures à 1 - 19,0346986379% | Erreurs supérieures à 1 - 12,1977096603% |
| Erreurs supérieures à 2 - 8,94313926245% | Erreurs supérieures à 2 - 5,16977226441% |
| Erreurs supérieures à 3 - 5,42406856507% | Erreurs supérieures à 3 - 3,12760834969% |
Erreurs supérieures à 4 - 3,667938161595%
| Erreurs supérieures à 4 - 2,10263125679% |
Erreurs supérieures à 5 - 2,67322988948%
| Erreurs supérieures à 5 - 1,56473158807%
|
Erreurs supérieures à 6 - 2,0618556701%
| Erreurs supérieures à 6 - 1,19599209102%
|
| Erreurs supérieures à 7 - 1,65887701209% | Erreurs supérieures à 7 - 0,949300173983%
|
Erreurs supérieures à 8 - 1,36821095777%
| Erreurs supérieures à 8 - 0,78310772461% |
| Erreurs supérieures à 9 - 1,15368611519% | Erreurs supérieures à 9 - 0,659205318158%
|
| Erreurs supérieures à 10 - 0,99199395014% | Erreurs supérieures à 10 - 0,554593106723% |
| Erreurs supérieures à 11 - 0,863969667827% | Erreurs supérieures à 11 - 0,490045146476%
|
Erreurs supérieures à 12 - 0,764347266082%
| Erreurs supérieures à 12 - 0,428835873827%
|
| Erreurs supérieures à 13 - 0,68086818247% | Erreurs supérieures à 13 - 0,386545830907%
|
| Erreurs supérieures à 14 - 0,613446089087% | Erreurs supérieures à 14 - 0,343884822697%
|
Erreurs supérieures à 15 - 0,556297016335%
| Erreurs supérieures à 15 - 0,316433391328%
|
Pour cible = 0, MAE = 0,142222484602
| Pour cible = 0, MAE = 0,141900737761
|
Pour cible = 1, MAE = 0,63978556493
| Pour cible = 1, MAE = 0,660823509405 |
| Pour cible = 2, MAE = 1,01528075312 | Pour cible = 2, MAE = 1.01098070566 |
| Pour cible = 3, MAE = 1,43762342295 | Pour cible = 3, MAE = 1,44836233499 |
Pour cible = 4, MAE = 1,82790678437
| Pour cible = 4, MAE = 1,86539223382
|
Pour cible = 5, MAE = 2,15369976552
| Pour cible = 5, MAE = 2.16017884573 |
Pour cible = 6, MAE = 2,51629758129
| Pour cible = 6, MAE = 2,51987403661
|
Pour cible = 7, MAE = 2,80225497415
| Pour cible = 7, MAE = 2,97580015564
|
Pour cible = 8, MAE = 3,09405048248
| Pour cible = 8, MAE = 3,21914648525
|
Pour l'objectif = 9, MAE = 3,39256765159
| Pour cible = 9, MAE = 3,54572928241
|
| Pour objectif = 10, MAE = 3,6640339953 | Pour cible = 10, MAE = 3,84409605282
|
Pour cible = 11, MAE = 4,02797747118
| Pour cible = 11, MAE = 4,21828735273
|
Pour cible = 12, MAE = 4,17163467899
| Pour cible = 12, MAE = 3,92536509115
|
Pour cible = 14, MAE = 4,78590364522
| Pour cible = 14, MAE = 5.11290428675 |
Pour cible = 15, MAE = 4,89409916994
| Pour cible = 15, MAE = 5.20892023117
|
Perte de train = 0,535842111392
Perte d'essai = 0,895529959873
Prédiction de graphique (cible) pour l'ensemble d'entraînement Prédiction graphique (cible) pour l'échantillon de test Erreur de prédiction de temps en temps Trier l'erreur ascendante sur l'échantillon de test Si aucune ne correspond, effectuez une nouvelle recherche aléatoire. C'est ainsi que nous avons formé le modèle pendant 5 ou 5 jours au rythme industriel. Nous étions de service, quelqu'un la nuit, quelqu'un s'est réveillé le matin, a regardé les 10 principaux paramètres, a redémarré ou enregistré le modèle et s'est couché plus loin. Dans ce mode, nous avons travaillé pendant une semaine et formé 130 modèles - 13 types de marchandises et 10 profondeurs de prévisions, chacune comptant 170 fonctionnalités. Le MAE moyen pour la série chronologique 5 fois cv est égal à 1.
Il peut sembler que ce n'est pas très cool - et c'est le cas, sauf si vous avez une grande partie dans la sélection des unités. Comme le montre une analyse des résultats, les unités sont prédites le pire de toutes - le fait qu'un produit ait été acheté une fois par semaine ne dit rien sur la demande. Une fois que tout peut être vendu - il y a une personne qui achètera une figurine en porcelaine sous la forme d'un dentiste, et cela ne dit rien des ventes futures ou des ventes passées. En général, nous ne nous sommes pas énervés à ce sujet.
Trucs et astuces
Qu'est-ce qui a mal tourné et comment éviter cela?
Le premier problème est la sélection des paramètres. Nous avons commencé à utiliser RandomizedSearchCV - un outil bien connu de sklearn pour trier les hyperparamètres. C'est là que la première surprise nous attendait.
Comme çafrom sklearn.model_selection import ParameterSampler
from sklearn.model_selection import RandomizedSearchCV
estimator = lightgbm.LGBMRegressor(application='regression_l1', is_training_metric = True, objective = 'regression_l1', num_threads=72)
param_grid = {'boosting_type': boosting_type, 'num_leaves': num_leaves, 'max_depth': max_depth, 'learning_rate':learning_rate, 'n_estimators': n_estimators, 'subsample_for_bin': subsample_for_bin, 'min_child_samples': min_child_samples, 'colsample_bytree': colsample_bytree, 'reg_alpha': reg_alpha, 'max_bin': max_bin}
rscv = RandomizedSearchCV(estimator, param_grid, refit=False, n_iter=100, scoring='neg_mean_absolute_error', n_jobs=1, cv=10, verbose=3, pre_dispatch='1*n_jobs', error_score=-1, return_train_score='warn')
rscv .fit(X_train.values, y_train['target'].values)
print('Best parameters found by grid search are:', rscv.best_params_)
Le calcul se bloque simplement (ce qui est important, il ne tombe pas, mais continue de fonctionner, mais sur un nombre toujours plus petit de cœurs et à un moment donné il s'arrête juste).
J'ai dû paralléliser le processus en raison de RandomizedSearchCVestimator = lightgbm.LGBMRegressor(application='regression_l1', is_training_metric = True, objective = 'regression_l1', num_threads=1)
rscv = RandomizedSearchCV(estimator, param_grid, refit=False, n_iter=100, scoring='neg_mean_absolute_error', n_jobs=72, cv=10, verbose=3, pre_dispatch='1*n_jobs', error_score=-1, return_train_score='warn')
rscv .fit(X_train.values, y_train['target'].values)
print('Best parameters found by grid search are:', rscv.best_params_)
Mais RandomizedSearchCV récupère la quasi-totalité de l'ensemble de données pour chaque «travail». Par conséquent, il est nécessaire d'augmenter considérablement la quantité de RAM, sacrifiant éventuellement le nombre de cœurs.
Qui nous parlerait alors de choses aussi merveilleuses que l'hyperopté! Depuis que nous avons appris, nous l'utilisons uniquement.
Une autre astuce qui nous est venue à l'esprit vers la fin du projet était de choisir des modèles qui avaient le paramètre colsample_bytree (c'est le paramètre LightGBM, qui dit quel pourcentage de fonctionnalités donner à chaque lerner) dans la région de 0,2-0,3, car lorsque la voiture Cela fonctionne en production, il peut ne pas y avoir de tables et les fonctionnalités individuelles peuvent ne pas être comptées correctement. Une telle régularisation vous permet de vous assurer que ces fonctionnalités non comptabilisées affectent au moins pas tous les lerners du modèle.
Sur le plan empirique, nous sommes arrivés à la conclusion que nous devons faire plus d'estimateurs et tordre la régularisation plus durement. Ce n'est pas une règle de travail avec LightGBM, mais un tel schéma a fonctionné pour nous.
Et bien sûr, Spark. Par exemple, il y a un bogue que Spark lui-même connaît: si vous prenez plusieurs colonnes d'une table et en créez une nouvelle, puis en prenez d'autres de la même table et en créez une nouvelle, puis accordez les tables que vous recevez, tout se cassera, même si cela ne devrait pas. Vous ne pouvez être sauvé qu'en vous débarrassant de tous les calculs paresseux. Nous avons même écrit une fonction spéciale - bumb_df, elle transforme le Data Frame en RDD en Data Frame. Autrement dit, il réinitialise tous les calculs paresseux. Cela peut vous protéger de la plupart des problèmes Spark.
bumb_dfdef bump_df(df):
# to avoid problem: AnalysisException: resolved attribute(s)
df_rdd = df.rdd
if df_rdd.isEmpty():
df = df_rdd.toDF(schema=df.schema)
return df
else:
return df_rdd.toDF(schema=df.schema)
Les prévisions sont prêtes: combien commanderons-nous?
La prévision des ventes est une tâche purement mathématique, et si la distribution normale d'une erreur à moyenne nulle est une victoire pour un mathématicien, alors pour les commerçants qui comptent chaque rouble, cela est inacceptable.
Si un iPhone supplémentaire ou une robe à la mode dans l'entrepôt n'est pas un problème, mais plutôt un stock d'assurance, alors l'absence du même iPhone dans l'entrepôt est une perte d'au moins la marge, et comme un maximum d'image, et cela ne peut pas être autorisé.
Afin d'apprendre à l'algorithme à acheter autant que nécessaire, nous avons dû calculer le coût de réachat et de sous-achat de chaque produit et former un modèle simple afin de minimiser les éventuelles pertes d'argent.
Le modèle reçoit une prévision des ventes à l'entrée, y ajoute du bruit aléatoire et normalement distribué (nous simulons les imperfections des fournisseurs) et apprend à ajouter exactement autant aux prévisions pour chaque produit particulier afin de minimiser les pertes d'argent.
Ainsi, une commande est un stock prévisionnel + sécurité, qui garantit la couverture de l'erreur de prévision et de l'imperfection du monde extérieur.
Comme dans prod
Ozon possède son propre cluster informatique assez important, sur lequel chaque nuit un pipeline (nous utilisons le flux d'air) de plus de 15 emplois est lancé. Cela ressemble à ceci:

Chaque nuit, l'algorithme est lancé, tire environ 20 Go de données provenant de diverses sources dans les hdfs locaux, sélectionne un fournisseur pour chaque produit, collecte des fonctionnalités pour chaque produit, établit des prévisions de vente et génère des commandes en fonction du calendrier de livraison. À 6 h à 7 h, nous remettons à la table des personnes chargées de travailler avec les fournisseurs des tables prêtes à l'emploi qui s'envolent d'un simple clic vers les fournisseurs.
Pas une seule prévision
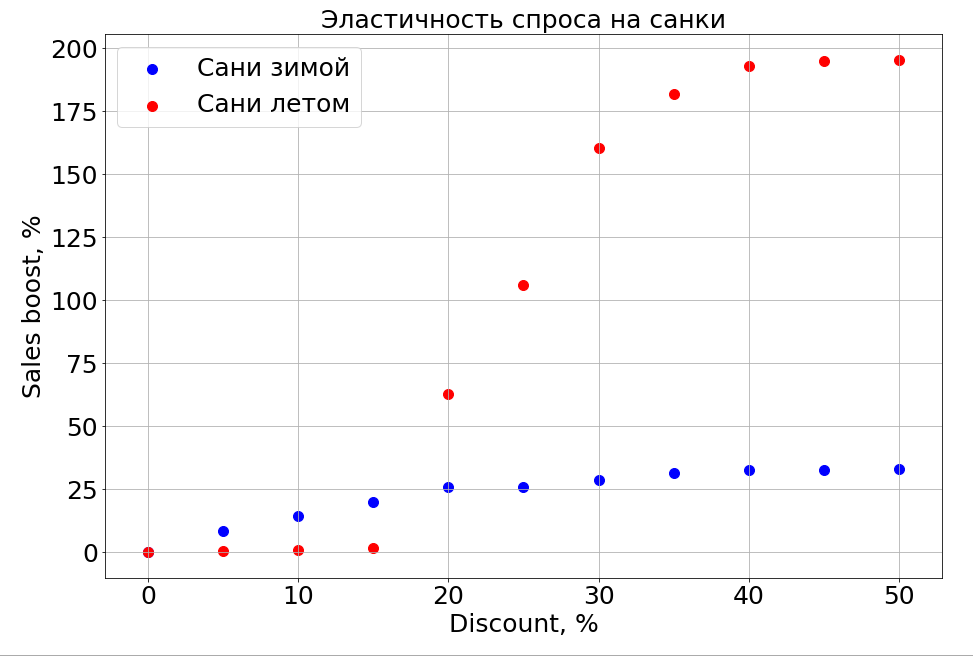
Le modèle entraîné connaît la dépendance des prévisions à l'égard de n'importe quelle entité et, par conséquent, si vous gelez les panneaux N-1 et commencez à en changer un, vous pouvez observer comment cela affecte les prévisions. Bien sûr, la chose la plus intéressante à ce sujet est de savoir comment les ventes dépendent du prix.
Il est important de noter que la demande ne dépend pas seulement du prix. Par exemple, si vous faites de petites remises sur des traîneaux en été, cela ne les aide toujours pas à vendre. Nous faisons un rabais de plus et des gens apparaissent qui "préparent un traîneau en été". Mais jusqu'à un certain niveau de remises, nous ne pouvons toujours pas atteindre la partie du cerveau qui est responsable de la planification. En hiver, il fonctionne comme pour tout produit - vous faites une remise et il se vend plus rapidement.
Plans
Maintenant, nous étudions activement le regroupement des séries chronologiques afin de répartir les marchandises entre les grappes en fonction de la nature de la courbe qui décrit leurs ventes. Par exemple, saisonnière, traditionnellement populaire en été ou, inversement, en hiver. Lorsque nous apprendrons à séparer les produits ayant un long historique de vente, nous prévoyons de mettre en évidence des fonctionnalités basées sur les articles qui vous diront quel sera le modèle de vente d'un nouveau produit qui vient d'apparaître - pour l'instant, c'est notre tâche principale.
Les réseaux de neurones et les modèles paramétriques de séries chronologiques, et tout cela dans l'ensemble, iront sûrement plus loin.
En particulier, grâce au nouveau système de prévision, Ozon est passé de l'achat de marchandises en stock à des livraisons cycliques, lorsque nous achetons d'une offre à une autre et ne stockons pas de soldes en stock.
Nous devons maintenant décider comment enseigner l'algorithme pour prédire les ventes de nouveaux produits et de catégories entières. L'année prochaine, la société prévoit d'augmenter ses ventes x10 dans les catégories et x2,5 dans les domaines de réalisation. Et nous devons dire aux modèles que ces anciennes données sont pertinentes, mais pour un magasin différent et passé. Et pendant que nous réfléchissons à comment le faire.
La deuxième chose par nature irrationnelle que nous devons apprendre à prévoir est la mode. Comment pouvait-on prédire qu'un spinner se vendrait comme ça? Comment prédire les ventes de nouveaux livres de Dan Brown si l'un de ses livres est épuisé et l'autre non? Pendant que nous y travaillons.
Si vous savez faire mieux ou si vous avez des histoires sur l'utilisation de l'apprentissage automatique dans la bataille dans les commentaires, nous en discuterons.