GitHub utilise MySQL comme son principal entrepôt de données pour tout ce qui n'est pas lié à git , donc la disponibilité de MySQL est la clé du fonctionnement normal de GitHub. Le site lui-même, l'API GitHub, le système d'authentification et de nombreuses autres fonctionnalités nécessitent un accès aux bases de données. Nous utilisons plusieurs clusters MySQL pour gérer divers services et tâches. Ils sont configurés selon le schéma classique avec un nœud principal disponible pour l'enregistrement et ses répliques. Les répliques (autres nœuds de cluster) reproduisent de manière asynchrone les modifications apportées au nœud principal et fournissent un accès en lecture.
La disponibilité des sites hôtes est critique. Sans le nœud principal, le cluster ne prend pas en charge l'enregistrement, ce qui signifie que vous ne pouvez pas enregistrer les modifications nécessaires. Corriger les transactions, enregistrer les problèmes, créer de nouveaux utilisateurs, des référentiels, des avis et bien plus sera tout simplement impossible.
Pour prendre en charge l'enregistrement, un nœud accessible correspondant est requis - le nœud principal du cluster. Cependant, la capacité d'identifier ou de détecter un tel nœud est tout aussi importante.
En cas de panne du nœud principal actuel, il est important de s'assurer de l'apparition rapide d'un nouveau serveur pour le remplacer, ainsi que de pouvoir notifier rapidement tous les services de ce changement. Le temps d'arrêt total correspond au temps nécessaire pour détecter une défaillance, basculer et notifier un nouveau nœud principal.

Cette publication décrit une solution pour assurer une haute disponibilité de MySQL sur GitHub et découvrir le service principal, ce qui nous permet d'effectuer de manière fiable des opérations couvrant plusieurs centres de données, de maintenir l'opérabilité lorsque certains de ces centres ne sont pas disponibles et de garantir un temps d'arrêt minimum en cas de panne.
Objectifs de haute disponibilité
La solution décrite dans cet article est une nouvelle version améliorée des précédentes solutions haute disponibilité (HA) implémentées sur GitHub. À mesure que nous grandissons, nous devons adapter la stratégie MySQL HA pour changer. Nous nous efforçons de suivre des approches similaires pour MySQL et d'autres services sur GitHub.
Pour trouver la bonne solution pour la haute disponibilité et la découverte de services, vous devez d'abord répondre à quelques questions spécifiques. En voici un exemple:
- Quel temps d'arrêt maximum n'est pas critique pour vous?
- Quelle est la fiabilité des outils de détection de pannes? Les faux positifs (traitement des défaillances prématurées) sont-ils critiques pour vous?
- Quelle est la fiabilité du système de basculement? Où une panne peut-elle se produire?
- Quelle est l'efficacité de la solution dans plusieurs centres de données? Quelle est l'efficacité de la solution dans les réseaux à latence faible et élevée?
- La solution continuera-t-elle de fonctionner en cas de panne complète du centre de données (DPC) ou d'isolement du réseau?
- Quel mécanisme (le cas échéant) empêche ou atténue les conséquences de l'émergence de deux serveurs principaux dans le cluster qui enregistrent indépendamment?
- La perte de données est-elle critique pour vous? Si oui, dans quelle mesure?
Afin de démontrer, considérons d'abord la solution précédente et discutons des raisons pour lesquelles nous avons décidé de l'abandonner.
Refus d'utiliser VIP et DNS pour la découverte
Dans le cadre de la solution précédente, nous avons utilisé:
- orchestrateur pour la détection des pannes et le basculement;
- VIP et DNS pour la découverte d'hôte.
Dans ce cas, les clients ont découvert un nœud d'enregistrement par son nom, par exemple, mysql-writer-1.github.net . Le nom a été utilisé pour déterminer l'adresse IP virtuelle (VIP) du nœud principal.
Ainsi, dans une situation normale, les clients devaient simplement résoudre le nom et se connecter à l'adresse IP reçue, où le nœud principal les attendait déjà.
Considérez la topologie de réplication suivante qui couvre trois centres de données différents:
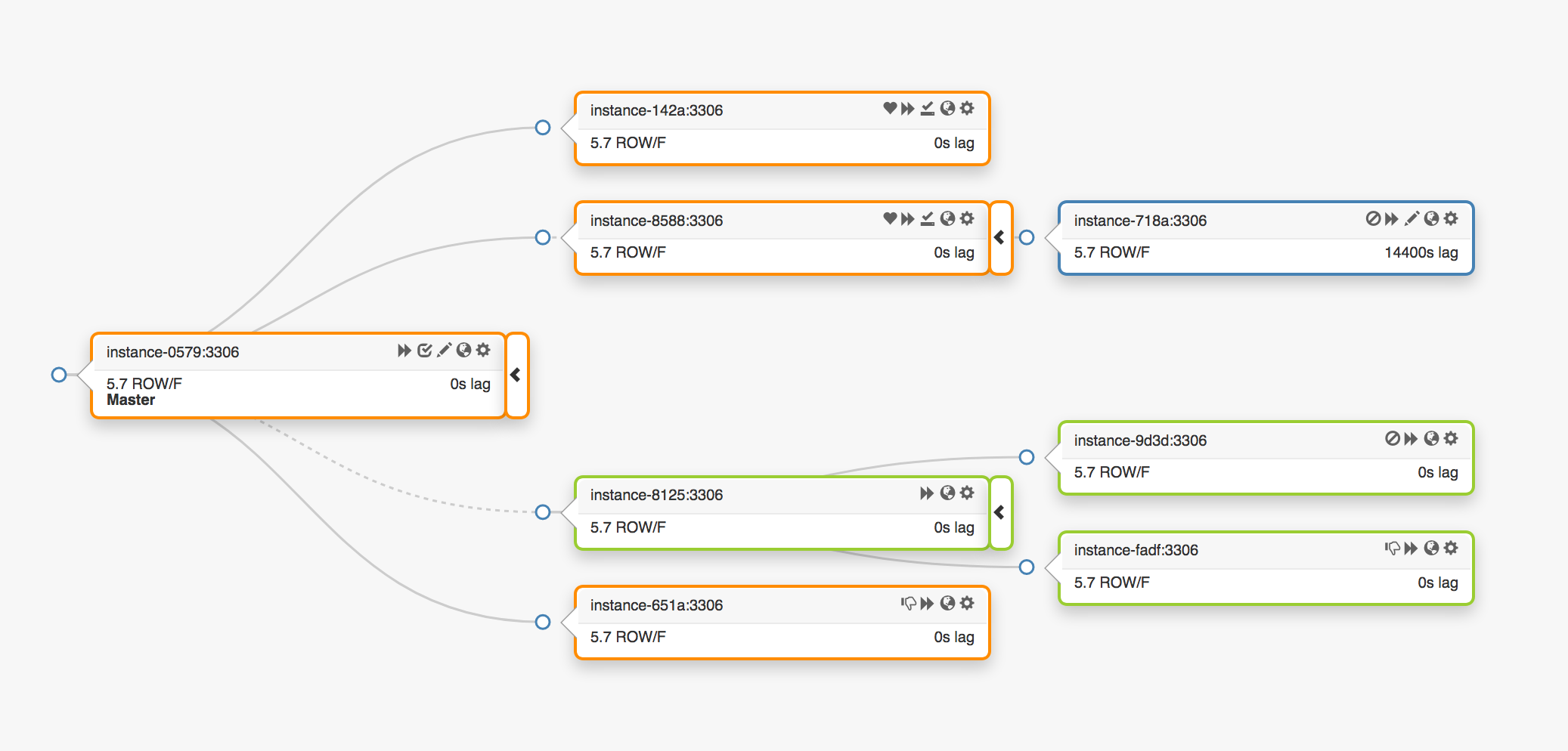
En cas de panne du nœud principal, un nouveau serveur doit être affecté à sa place (une des répliques).
orchestrator détecte une défaillance, sélectionne un nouveau nœud maître, puis attribue le nom / VIP. En réalité, les clients ne connaissent pas l'identité du nœud principal, ils ne connaissent que le nom, qui devrait désormais pointer vers le nouveau nœud. Attention cependant à cela.
Les adresses VIP sont partagées, les serveurs de bases de données eux-mêmes en font la demande et en sont propriétaires. Pour recevoir ou libérer un VIP, le serveur doit envoyer une demande ARP. Le serveur propriétaire du VIP doit d'abord le libérer avant que le nouveau maître puisse accéder à cette adresse. Cette approche entraîne des conséquences indésirables:
- En mode normal, le système de basculement contactera d'abord le nœud principal défaillant et lui demandera de libérer le VIP, puis se tournera vers le nouveau serveur principal avec une demande d'affectation VIP. Mais que faire si le premier nœud principal n'est pas disponible ou refuse une demande de libération de l'adresse VIP? Étant donné que le serveur est actuellement en état de défaillance, il est peu probable qu'il puisse répondre à une demande à temps ou y répondre du tout.
- En conséquence, une situation peut survenir lorsque deux hôtes revendiquent leurs droits sur le même VIP. Différents clients peuvent se connecter à n'importe lequel de ces serveurs en fonction du chemin réseau le plus court.
- Le bon fonctionnement dans cette situation dépend de l'interaction de deux serveurs indépendants et une telle configuration n'est pas fiable.
- Même si le premier nœud principal répond aux demandes, nous perdons un temps précieux: le basculement vers le nouveau serveur principal ne se produit pas lorsque nous contactons l'ancien.
- De plus, même en cas de réaffectation de VIP, il n'y a aucune garantie que les connexions client existantes sur l'ancien serveur seront déconnectées. Encore une fois, nous courons le risque d'être dans une situation avec deux nœuds principaux indépendants.
Ici et là, dans notre environnement, les adresses VIP sont associées à un emplacement physique. Ils sont affectés à un commutateur ou un routeur. Par conséquent, nous ne pouvons réaffecter une adresse VIP qu'à un serveur situé dans le même environnement que l'hôte d'origine. En particulier, dans certains cas, nous ne pourrons pas attribuer un serveur VIP dans un autre centre de données et nous devrons apporter des modifications au DNS.
- La distribution des modifications au DNS prend plus de temps. Les clients stockent les noms DNS pour une période prédéfinie. Le basculement impliquant plusieurs centres de données implique un temps d'arrêt plus long, car il faut plus de temps pour fournir à tous les clients des informations sur le nouveau nœud principal.
Ces restrictions ont été suffisantes pour nous obliger à commencer la recherche d'une nouvelle solution, mais nous avons également dû tenir compte des éléments suivants:
- Les nœuds principaux ont transmis indépendamment des paquets d'impulsions via le service
pt-heartbeat pour mesurer le retard et la régulation de charge . Le service a dû être transféré au nœud principal nouvellement nommé. Si possible, il aurait dû être désactivé sur l'ancien serveur. - De même, les nœuds principaux contrôlaient indépendamment le fonctionnement du Pseudo-GTID . Il était nécessaire de démarrer ce processus sur le nouveau nœud principal et de préférence de s'arrêter sur l'ancien.
- Le nouveau nœud maître est devenu accessible en écriture. L'ancien nœud (si possible) devrait avoir
read_only (lecture seule).
Ces étapes supplémentaires ont entraîné une augmentation des temps d'arrêt globaux et ajouté leurs propres points de défaillance et de problèmes.
La solution a fonctionné et GitHub a réussi à gérer les échecs MySQL en arrière-plan, mais nous voulions améliorer notre approche de HA comme suit:
- garantir l'indépendance vis-à-vis de centres de données spécifiques;
- garantir l'opérabilité en cas de panne du centre de données;
- Abandonnez les workflows collaboratifs peu fiables
- réduire les temps d'arrêt totaux;
- Effectuez, dans la mesure du possible, le basculement sans perte.
Solution GitHub HA: orchestrateur, Consul, GLB
Notre nouvelle stratégie, ainsi que les améliorations qui l'accompagnent, éliminent la plupart des problèmes mentionnés ci-dessus ou atténuent leurs conséquences. Notre système HA actuel se compose des éléments suivants:
- orchestrateur pour la détection des pannes et le basculement. Nous utilisons le schéma orchestrateur / raft avec plusieurs centres de données, comme indiqué dans la figure ci-dessous;
- Hashicorp Consul pour la découverte de services;
- GLB / HAProxy comme couche proxy entre les clients et les nœuds d'enregistrement. Le code source du GLB Director est ouvert;
anycast technologie anycast pour le routage réseau.
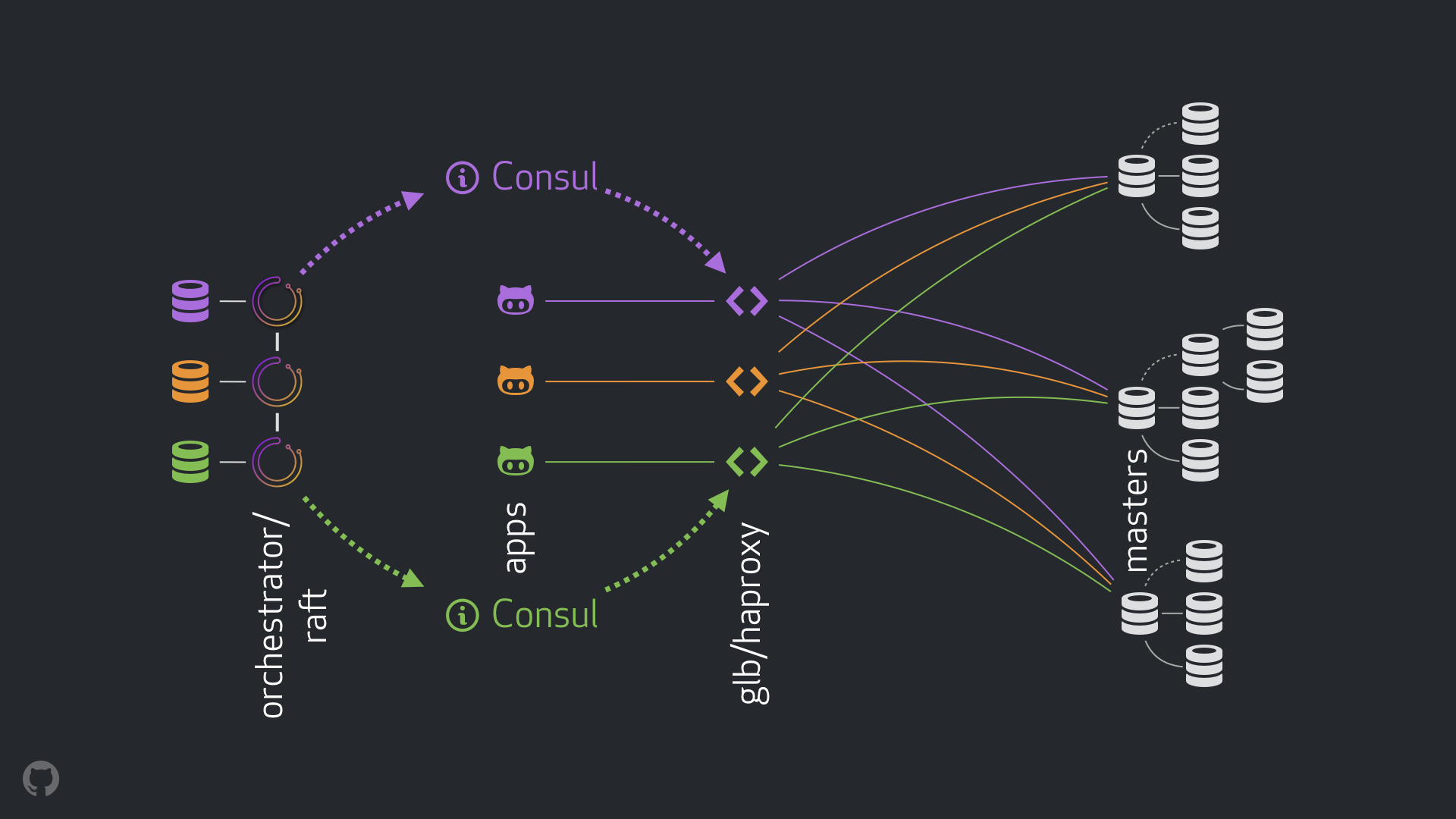
Le nouveau schéma a permis d'abandonner complètement les modifications apportées au VIP et au DNS. Désormais, lors de l'introduction de nouveaux composants, nous pouvons les séparer et simplifier la tâche. De plus, nous avons eu l'opportunité d'utiliser des solutions fiables et stables. Une analyse détaillée de la nouvelle solution est donnée ci-dessous.
Débit normal
Dans une situation normale, les applications se connectent aux nœuds d'enregistrement via GLB / HAProxy.
Les applications ne reçoivent pas l'identité du serveur principal. Comme auparavant, ils n'utilisent que le nom. Par exemple, le nœud principal de cluster1 serait mysql-writer-1.github.net . Cependant, dans notre configuration actuelle, ce nom se résout en l'adresse IP anycast .
Grâce à la technologie anycast , le nom est résolu à la même adresse IP n'importe où, mais le trafic est dirigé différemment, compte tenu de l'emplacement du client. En particulier, plusieurs instances de GLB, notre équilibreur de charge hautement disponible, sont déployées dans chacun de nos centres de données. Le trafic sur mysql-writer-1.github.net toujours acheminé vers le cluster GLB du centre de données local. Pour cette raison, tous les clients sont servis par des mandataires locaux.
Nous exécutons GLB sur HAProxy . Notre serveur HAProxy fournit des pools d'écriture : un pour chaque cluster MySQL. De plus, chaque pool ne possède qu'un seul serveur (le nœud principal du cluster). Toutes les instances GLB / HAProxy dans tous les centres de données ont les mêmes pools, et elles pointent toutes vers les mêmes serveurs dans ces pools. Ainsi, si l'application souhaite écrire des données dans la base de données sur mysql-writer-1.github.net , peu importe le serveur GLB auquel elle se connecte. Dans les deux cas, une redirection vers le nœud de cluster principal réel cluster1 sera effectuée.
Pour les applications, la découverte se termine sur GLB et la redécouverte n'est pas nécessaire. Ce GLB redirige le trafic au bon endroit.
Où le GLB obtient-il des informations sur les serveurs à répertorier? Comment modifions-nous le GLB?
Découverte par le consul
Le service Consul est largement connu comme une solution de découverte de services, et il prend également en charge les fonctions DNS. Cependant, dans notre cas, nous l'utilisons comme un stockage hautement accessible des valeurs clés (KV).
Dans le référentiel KV de Consul, nous enregistrons l'identité des nœuds principaux du cluster. Pour chaque cluster, il existe un ensemble d'enregistrements KV pointant vers les données du nœud principal correspondant: ses adresses fqdn , port, ipv4 et ipv6.
Chaque nœud GLB / HAProxy lance un modèle de consul , un service qui suit les changements dans les données du consul (dans notre cas, les changements dans les données des nœuds principaux). Le consul-template crée un fichier de configuration et peut recharger HAProxy lors de la modification des paramètres.
Pour cette raison, des informations sur la modification de l'identité du nœud principal dans Consul sont disponibles pour chaque instance GLB / HAProxy. Sur la base de ces informations, la configuration des instances est effectuée, les nouveaux nœuds principaux sont indiqués comme la seule entité dans le pool de serveurs de cluster. Après cela, les instances sont rechargées pour que les modifications prennent effet.
Nous avons déployé des instances Consul dans chaque centre de données et chaque instance offre une haute disponibilité. Cependant, ces instances sont indépendantes les unes des autres. Ils ne se répliquent pas et n'échangent aucune donnée.
Où Consul obtient-il des informations sur les changements et comment est-il distribué entre les centres de données?
orchestrateur / radeau
Nous utilisons le schéma orchestrator/raft : orchestrator nœuds d' orchestrator communiquent entre eux par le biais d'un consensus radeau . Dans chaque centre de données, nous avons un ou deux nœuds d' orchestrator .
orchestrator est chargé de détecter les pannes, le basculement MySQL et de transférer les données modifiées du nœud maître vers Consul. Le basculement est géré par un seul hôte orchestrator/raft , mais les modifications , nouvelles que le cluster est désormais un nouveau maître, sont propagées à tous orchestrator nœuds d' orchestrator à l'aide du mécanisme raft .
Lorsque les nœuds d' orchestrator reçoivent des informations sur une modification des données du nœud principal, chacun d'eux contacte sa propre instance locale de Consul et lance un enregistrement KV. Les centres de données avec plusieurs instances d' orchestrator recevront plusieurs enregistrements (identiques) dans Consul.
Vue généralisée de l'ensemble du flux
Si le nœud maître échoue:
orchestrator nœuds d' orchestrator détectent les pannes;orchestrator/raft master lance la récupération. Un nouveau nœud maître est attribué;- le schéma
orchestrator/raft transfère les données sur le changement du nœud principal à tous les nœuds du cluster de raft ; - chaque instance d'
orchestrator/raft reçoit une notification concernant un changement de nœud et écrit l'identité du nouveau nœud maître dans le stockage KV local dans Consul; - sur chaque instance GLB / HAProxy, le service de
consul-template est lancé, qui surveille les changements dans le référentiel KV dans Consul, reconfigure et redémarre HAProxy; - Le trafic client est redirigé vers le nouveau nœud maître.
Pour chaque composante, les responsabilités sont clairement réparties et l'ensemble de la structure est diversifié et simplifié. orchestrator n'interagit pas avec les équilibreurs de charge. Le consul n'a pas besoin d'informations sur l'origine des informations. Les serveurs proxy fonctionnent uniquement avec Consul. Les clients ne fonctionnent qu'avec des serveurs proxy.
De plus:
- Pas besoin d'apporter des modifications au DNS et de diffuser des informations à leur sujet;
- TTL n'est pas utilisé;
- le thread n'attend pas les réponses de l'hôte dans un état d'erreur. En général, il est ignoré.
Pour stabiliser le flux, nous appliquons également les méthodes suivantes:
- Le paramètre d'
hard-stop-after fixe HAProxy est défini sur une très petite valeur. Lorsque HAProxy redémarre avec le nouveau serveur dans le pool d'écriture, le serveur met automatiquement fin à toutes les connexions existantes à l'ancien nœud maître.
- La définition du paramètre d'
hard-stop-after urgence vous permet de ne pas attendre d'actions des clients, en outre, les conséquences négatives de l'occurrence possible de deux nœuds principaux dans le cluster sont minimisées. Il est important de comprendre qu'il n'y a pas de magie ici, et en tout cas, un certain temps s'écoule avant que les anciens liens ne soient rompus. Mais il y a un moment où nous pouvons cesser d'attendre des surprises désagréables.
- Nous n'exigeons pas la disponibilité continue du service Consul. En fait, nous avons besoin qu'il soit disponible uniquement pendant le basculement. Si le service Consul ne répond pas, alors GLB continue de travailler avec les dernières valeurs connues et ne prend pas de mesures drastiques.
- Le GLB est configuré pour vérifier l'identité du nœud maître nouvellement affecté. Comme pour nos pools MySQL contextuels , une vérification est effectuée pour confirmer que le serveur est bien accessible en écriture. Si nous supprimons accidentellement l'identité du nœud principal dans Consul, il n'y aura aucun problème, un enregistrement vide sera ignoré. Si nous écrivons par erreur le nom d'un autre serveur (pas le principal) dans Consul, alors dans ce cas, tout va bien: GLB ne le mettra pas à jour et continuera de fonctionner avec le dernier état valide.
Dans les sections suivantes, nous examinons les problèmes et analysons les objectifs de haute disponibilité.
Détection de crash avec orchestrateur / radeau
orchestrator adopte une approche globale de la détection des pannes, ce qui garantit une grande fiabilité de l'outil. Nous ne rencontrons pas de faux résultats positifs, les pannes prématurées ne sont pas effectuées, ce qui signifie que les temps d'arrêt inutiles sont exclus.
Les circuits d' orchestrator/raft également face à des situations d'isolement complet du réseau du centre de données (clôture du centre de données). L'isolement du réseau du centre de données peut être source de confusion: les serveurs à l'intérieur du centre de données peuvent communiquer entre eux. Comment comprendre qui est vraiment isolé - les serveurs d' un centre de données donné ou de tous les autres centres de données?
Dans le schéma orchestrator/raft , le maître de orchestrator/raft est le basculement. Le nœud devient le leader, qui reçoit le soutien de la majorité du groupe (quorum). Nous avons déployé le nœud d' orchestrator de telle manière qu'aucun centre de données unique ne peut fournir la majorité, tandis que n'importe quel centre de données n-1 peut le fournir.
Dans le cas d'une isolation complète du réseau du centre de données, les nœuds d' orchestrator de ce centre sont déconnectés des nœuds similaires d'autres centres de données. Par conséquent, les nœuds d' orchestrator d'un centre de données isolé ne peuvent pas devenir les leaders d'un cluster de raft . Si un tel nœud était le maître, il perd ce statut. Un nouvel hôte se verra attribuer l'un des nœuds des autres centres de données. Ce leader aura le soutien de tous les autres centres de données qui peuvent interagir les uns avec les autres.
De cette façon, le maître d' orchestrator sera toujours en dehors du centre de données isolé du réseau. Si le nœud maître se trouvait dans le centre de données isolé, orchestrator lance un basculement pour le remplacer par le serveur de l'un des centres de données disponibles. Nous atténuons l'impact de l'isolement des centres de données en déléguant des décisions au quorum des centres de données disponibles.
Notification plus rapide
Le temps d'indisponibilité total peut être encore réduit en accélérant la notification d'un changement dans le nœud principal. Comment y parvenir?
Lorsque l' orchestrator démarre le basculement, il considère un groupe de serveurs, dont l'un peut être affecté comme serveur principal. Compte tenu des règles de réplication, des recommandations et des limites, il est en mesure de prendre une décision éclairée sur la meilleure ligne de conduite.
Selon les signes suivants, il peut également comprendre qu'un serveur accessible est un candidat idéal pour une nomination comme principal:
- rien n'empêche le serveur de devenir élevé (et peut-être que l'utilisateur recommande ce serveur);
- il est prévu que le serveur pourra utiliser tous les autres serveurs comme répliques.
Dans ce cas, orchestrator configure d'abord le serveur comme accessible en écriture et annonce immédiatement une augmentation de son état (dans notre cas, il écrit l'enregistrement dans le référentiel KV dans Consul). orchestrator , .
, , GLB , , . : !
MySQL , . : , , , .
, . , , . , , , .
: 500 . . ( ), .
( ) . , .
, . , , . , , , .
, / pt-heartbeat / , . , pt-heartbeat , read_only , .
pt-heartbeat , . . . , pt-heartbeat .
orchestrator
orchestrator :
- Pseudo-GTID;
- , ;
- (
read_only ), .
, . , , , . orchestrator .
- , , . , -, .
, .
, , , - . . STONITH . , , , «» - . , , .
: Consul , . . , , , , .
orchestrator/GLB/Consul :
- ;
- ;
- ;
- ;
- , ( );
- ;
10-13 .
20 , — 25 .
Conclusion
«// » , , . . , .