Le 1er novembre 2017, je suis devenu le chef de l'équipe de développement au sein du département de développement logiciel Timeweb. Et le 12 novembre 2018, le chef du département a demandé quand l'article pour Habrahabr serait prêt, parce que le département marketing a demandé, les volontaires étaient terminés et le plan de contenu exigeait autre chose)
Par conséquent, je veux donner une rétrospective de la façon dont les processus de développement, de test et de livraison de nos produits ont changé au cours de la dernière année. À propos des processus et outils hérités, docker, gitlab et comment nous nous développons.
Timeweb Hoster existe depuis 2006. Pendant tout ce temps, l'entreprise investit beaucoup d'efforts pour fournir aux clients un service unique et pratique qui le distinguerait de ses concurrents. Timeweb a ses propres applications mobiles, une interface de messagerie Web, des panneaux de contrôle d'hébergement virtuel, VDS, un programme d'affiliation, ses outils de support et bien plus encore.
Il y a environ 250 projets dans notre gitlab: ce sont des applications clientes, des outils internes, des bibliothèques, des référentiels de configuration. Des dizaines d'entre eux sont activement développés et soutenus: ils s'engagent pendant la semaine de travail, les testent, les collectent et les publient.
Outre la grande quantité de code hérité, tout cela s'accompagne d'un nombre approprié de processus hérités et d'outils associés. Comme tout héritage, ils doivent également être maintenus, optimisés, refactorisés et parfois remplacés.
De toute cette abondance de projets, les panneaux de contrôle sont les plus proches des clients d'hébergement. Et c'est précisément dans le projet «Panneau de configuration» que nous effectuons le plus souvent diverses améliorations d'infrastructure et déployons beaucoup d'efforts pour maintenir l'infrastructure connectée en forme. Diffuser l'expérience acquise et les pratiques appréciées aux autres produits et à leurs équipes.
À propos des différents changements d'outils et de processus au cours de la dernière année, je vais vous le dire.
Vagrant → docker-compose
Le problème
Le premier jour ouvrable, j'ai essayé de relever les panneaux de contrôle localement. À cette époque, il y avait cinq applications Web dans un référentiel:
- Hébergement virtuel PU 3.0,
- PU VDS 2.0,
- Webmasters PU,
- PERSONNEL (supports d'outils),
- Lignes directrices (démonstration des composants frontaux standardisés).
Pour exécuter, Vagrant utilisé localement. Vagrant a lancé ansible. Pour démarrer et configurer, il a fallu l'aide de collègues et environ une journée de temps de nettoyage. J'ai dû installer une version spéciale de Virtual Box (il y avait des problèmes sur la version stable actuelle), le travail à partir de la console à l'intérieur de la machine virtuelle était très énervant: les commandes triviales comme l'installation de npm / composer ont considérablement ralenti.
Les performances des applications elles-mêmes dans la machine virtuelle étaient loin d'être possibles, compte tenu de la pile technologique utilisée et de la puissance de la machine. Sans oublier qu'une machine virtuelle est une machine virtuelle, et par définition elle occupe une part importante des ressources de votre PC.
Solution
L'environnement de développement local a été réécrit pour s'exécuter dans des conteneurs Docker. La conteneurisation basée sur Docker est la solution la plus courante pour isoler l'environnement d'application à toutes les étapes de son cycle de vie. Par conséquent, il n'y a pas d'alternatives spéciales.
Conclusions
Des pros:
- localement, l'application est devenue plus réactive, les conteneurs nécessitent moins que les VMs,
- le lancement d'une nouvelle instance, comme la pratique l'a montré, prend quelques minutes et ne nécessite que docker (-compose) pas inférieur à certaines versions. Après le clonage, faites simplement:
make install-dev make run-dev
Il y avait quelques compromis:
- J'ai dû écrire des liaisons shell pour les commandes dockées (compositeur, npm, etc.). Comme docker-compose.yml, ils ne sont pas entièrement multiplateformes par rapport à Vagrant. Par exemple, le lancement sous Mac nécessite des efforts supplémentaires et sous Windows, il sera probablement plus facile d'exécuter une distribution avec docker dans la machine virtuelle Linux. Mais c'est un compromis acceptable, l'équipe utilise uniquement des distributions basées sur Debian, ceci est une limitation acceptable pour le développement commercial,
- pour prendre en charge les hôtes virtuels, un conteneur basé sur
github.com/jwilder/nginx-proxy est lancé localement. Ce n'est pas une béquille, mais un logiciel supplémentaire, dont il faut parfois se souvenir, bien qu'il ne pose pas de problème.
Oui, tout le monde dans l'équipe devait comprendre un peu ce qu'est le docker. Bien que grâce aux scripts shell et Makefile mentionnés, les développeurs effectuent 95% de leurs tâches sans penser aux conteneurs, mais dans un environnement identique garanti.
newcp-dev → cp-stands
Ces expressions étranges sont les noms de machines avec des bancs d'essai de panneaux de contrôle, nouveaux et anciens, respectivement.
Le problème
Les recettes Ansible ont été utilisées exclusivement à l'intérieur de Vagrant, donc le principal avantage n'a pas été obtenu: les versions des packages dans la prod et sur les stands étaient différentes de celles sur lesquelles les développeurs ont travaillé.
La non-concordance des versions des progiciels de serveur sur les anciens stands avec ce que les développeurs avaient, a conduit à des problèmes. La synchronisation a été compliquée par le fait que les administrateurs système utilisent un système de gestion de configuration différent et qu'il n'est pas possible de l'intégrer au référentiel des développeurs.
Solution
Après la conteneurisation, il n'a pas été difficile d'étendre la configuration docker-compose pour une utilisation sur des bancs de test. Une nouvelle machine a été créée pour déployer les stands sur DOCKER_HOST.
Conclusions
Les développeurs sont désormais convaincus de la pertinence des environnements locaux et de test.
TeamCity → gitlab-ci
Les problèmes
La configuration de projet dans TeamCity est un processus laborieux et ingrat. La configuration CI a été stockée séparément du code, en xml, auquel le contrôle de version normal n'est pas applicable, et un aperçu des modifications. Nous avons également rencontré des problèmes avec la stabilité du processus de génération sur les agents TeamCity.
Solution
Étant donné que gitlab était déjà utilisé comme référentiel pour les référentiels, commencer à utiliser son CI était non seulement logique, mais aussi facile et agréable. Maintenant, toute la configuration CI / CD est directement dans le référentiel.
Résultat
Au cours de l'année, presque tous les projets assemblés par TeamCity ont été transférés en toute sécurité vers gitlab-ci. Nous avons eu l'occasion d'implémenter rapidement une variété de fonctionnalités pour automatiser les processus CI / CD.
Les captures d'écran des pipelines seront les plus évidentes:
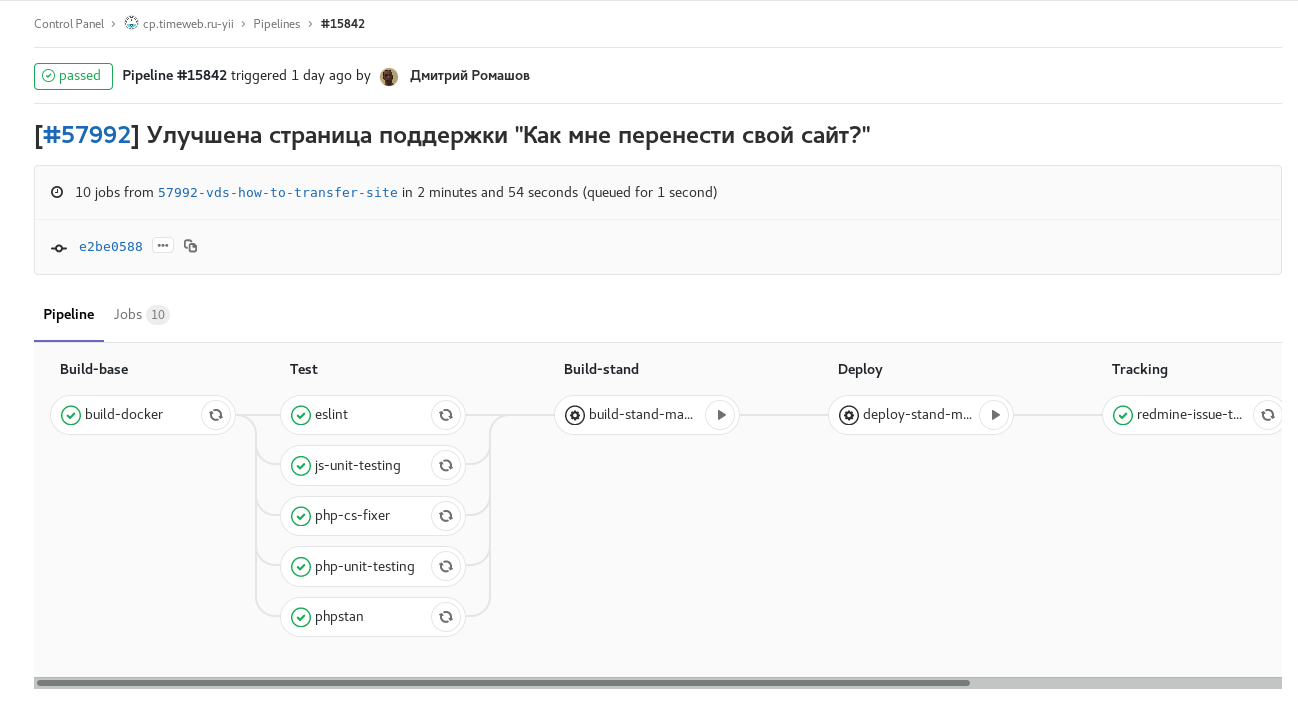 Fig. 1. fonctionnalité-branche: tous les contrôles et tests automatiques disponibles sont inclus. Une fois terminé, envoie un commentaire avec un lien vers le pipeline vers la tâche redmine. Tâches manuelles pour assembler et lancer un stand avec cette branche.
Fig. 1. fonctionnalité-branche: tous les contrôles et tests automatiques disponibles sont inclus. Une fois terminé, envoie un commentaire avec un lien vers le pipeline vers la tâche redmine. Tâches manuelles pour assembler et lancer un stand avec cette branche.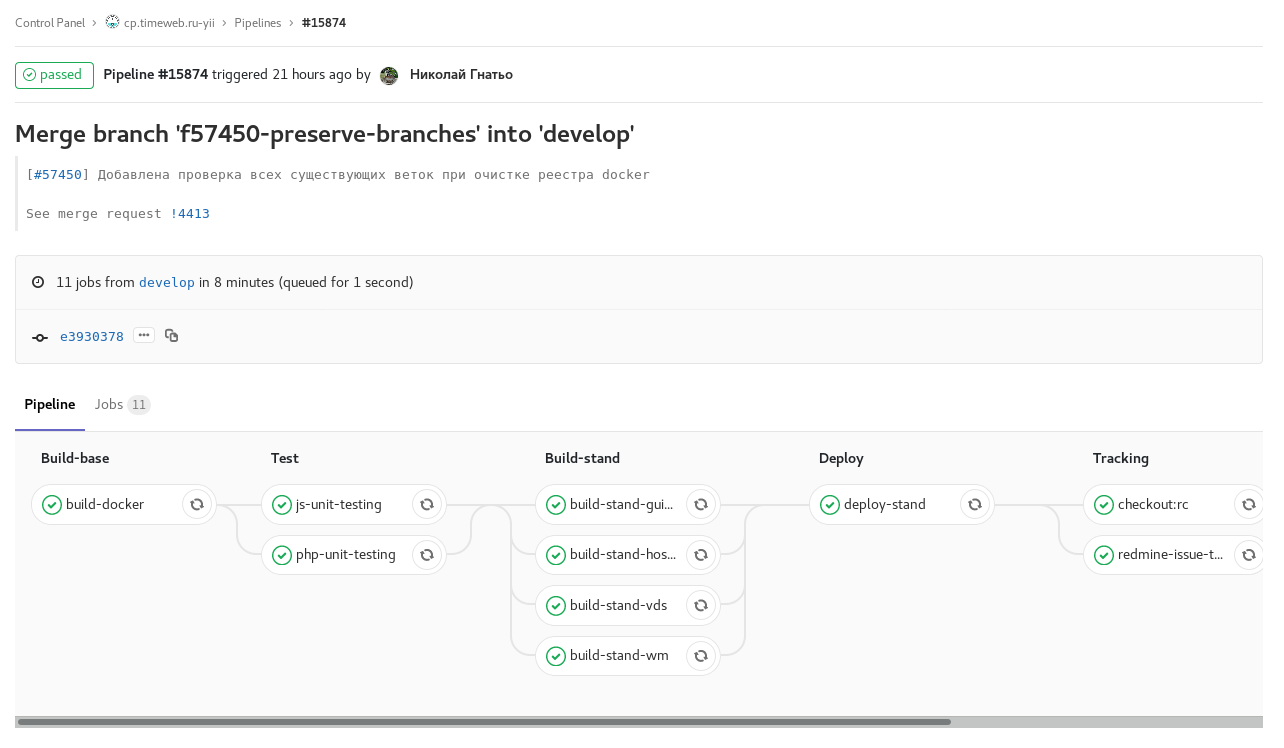 Fig. 2. développer la construction planifiée avec le gel de code (checkout: rc): construire développer selon le calendrier avec le gel de code. L'assemblage d'images pour les stands des panneaux de commande individuels se déroule en parallèle.
Fig. 2. développer la construction planifiée avec le gel de code (checkout: rc): construire développer selon le calendrier avec le gel de code. L'assemblage d'images pour les stands des panneaux de commande individuels se déroule en parallèle.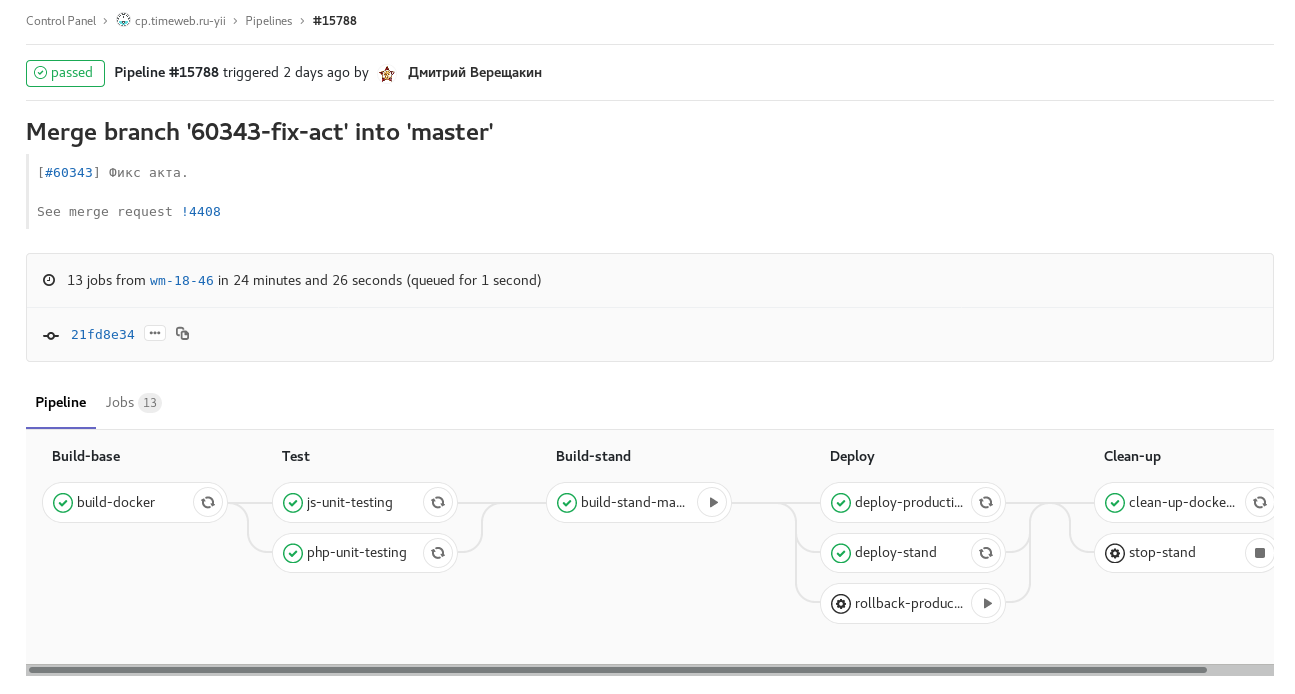 Fig. 3. pipeline de tags: libération d'un des panneaux de contrôle. Tâche manuelle pour la libération de la restauration.
Fig. 3. pipeline de tags: libération d'un des panneaux de contrôle. Tâche manuelle pour la libération de la restauration.De plus, à partir de gitlab-ci, il y a un changement de statut et la nomination d'une personne en redmine aux étapes En cours → Révision → Contrôle qualité, notification dans Slack sur les versions et mises à jour, staging et rollbacks.
C'est pratique, mais nous n'avons pas pris en compte un point méthodologique. Après avoir implémenté une telle automatisation dans un projet, les gens s'y habituent rapidement. Et dans le cas de basculer vers un autre projet où cela n'existe pas encore, ou le processus est différent, vous pouvez oublier de déplacer et de réaffecter la tâche dans redmine ou de laisser un commentaire avec un lien vers la demande de fusion (ce que gitlab-ci fait également), forçant le spectateur à rechercher celui souhaité MR vous-même. En même temps, vous ne voulez tout simplement pas copier les pièces .gitlab-ci.yml et le code shell qui l'accompagne entre les projets, car vous devez prendre en charge le copier-coller.
Conclusion: l' automatisation c'est bien, mais quand c'est la même chose au niveau de toutes les équipes et projets - c'est encore mieux. Je serais reconnaissant au distingué public pour ses idées sur la façon d'organiser magnifiquement la réutilisation d'une telle configuration.
Durée du pipeline: 80 min → 8 min
Progressivement, notre CI a commencé à prendre indécemment beaucoup de temps. Les testeurs en ont beaucoup souffert: chaque correction dans master a dû attendre une heure avant d'être publiée. Cela ressemblait à ceci:
 Fig. 4. durée du pipeline de 80
Fig. 4. durée du pipeline de 80 lvl min.J'ai dû plonger dans l'analyse des lieux lents pendant plusieurs jours et chercher des moyens d'accélérer tout en conservant la fonctionnalité.
Les étapes les plus longues du processus ont été l'installation de packages npm. Sans aucun problème, ils l'ont remplacé par du fil et enregistré en plusieurs endroits jusqu'à 7 minutes.
Ils ont refusé les mises à jour automatiques de la mise en scène, ont préféré le contrôle manuel de l'état de ce stand.
Nous avons également ajouté plusieurs coureurs et divisé en tâches parallèles l'assemblage d'images d'application et tous les contrôles. Après ces optimisations, le pipeline de la branche principale avec la mise à jour de tous les stands a commencé dans la plupart des cas 7 à 8 minutes.
Capistrano → déployeur
Pour le déploiement en production et sur le stand qa, Capistrano a été utilisé (et continue d'être utilisé au moment de la rédaction). Le scénario principal de cet outil est le suivant: clonage du référentiel sur le serveur cible et exécution de toutes les tâches sur celui-ci.
Auparavant, le déploiement était déclenché par les mains d'un ingénieur QA avec les clés ssh nécessaires de Vagrant. Puis, alors que Vagrant abandonnait, Capistrano a emménagé dans un conteneur séparé. Maintenant, le déploiement est fait à partir du conteneur avec Capistrano avec des coureurs gitlab, marqués avec des balises spéciales et ayant les clés nécessaires, automatiquement lorsque les balises nécessaires apparaissent.
Le problème ici est que tout le processus de construction:
a) consomme significativement les ressources du serveur de combat (notamment node / gulp),
b) il n'y a aucun moyen de tenir à jour les versions de npm du compositeur. nœud, etc.
Il est plus logique de construire sur un serveur de build (dans notre cas, il s'agit de gitlab-runner) et de télécharger des artefacts prêts sur le serveur cible. Cela sauvera le serveur de combat des utilitaires d'assemblage et de la responsabilité étrangère.
Nous considérons maintenant le déployeur comme un remplacement pour capistrano (puisque nous n'avons pas de rubistes, nous n'avons pas non plus le désir de travailler avec sa DSL) et prévoyons de transférer l'assemblage du côté gitlab. Dans certains projets non critiques, nous avons déjà réussi à l'essayer et jusqu'à présent, nous sommes satisfaits: cela semble plus facile, nous n'avons rencontré aucune restriction.
Gitflow: rc-branches → tags
Le développement s'effectue en cycles hebdomadaires. Au cours des cinq jours, une nouvelle version est en cours de développement: le développeur accepte les améliorations et les correctifs prévus pour la semaine prochaine. Vendredi soir, le gel du code se produit automatiquement. Lundi, les tests de la nouvelle version commencent, des améliorations sont apportées et à la mi-fin de la semaine de travail, une version est disponible.
Auparavant, nous utilisions des branches avec des noms de la forme rc18-47, ce qui signifie que la version candidate est la 47e semaine de 2018. Le gel du code consistait à extraire la branche rc de develop. Mais en octobre de cette année, nous sommes passés aux balises. Les tags ont été définis avant, mais après coup, après la sortie et la fusion de rc avec master. Maintenant, l'apparence de la balise conduit à un déploiement automatique, et le gel est une fusion de développer en maître.
Nous nous sommes donc débarrassés des entités supplémentaires dans git et des variables dans le processus.
Maintenant, nous «tirons» les projets en retard dans le processus vers un flux de travail similaire.
Conclusion
L'automatisation des processus, leur optimisation, ainsi que le développement, est une question constante: tant que le produit évolue activement et que l'équipe travaille, il y aura des tâches correspondantes. De nouvelles idées apparaissent sur la façon de se débarrasser des actions de routine: les fonctionnalités sont implémentées dans gitlab-ci.
À mesure que les applications se développent, les processus CI commencent à prendre un temps inacceptable - il est temps de travailler sur leurs performances. Étant donné que les approches et les outils deviennent obsolètes, vous devez prendre le temps de les refactoriser, de les réviser et de les mettre à jour.
