Aujourd'hui, sur les sites thématiques étrangers sur le Big Data, vous pouvez trouver une mention d'un outil relativement nouveau pour l'écosystème Hadoop comme Apache NiFi. Il s'agit d'un outil ETL open source moderne. Architecture distribuée pour un chargement parallèle et un traitement des données rapides, un grand nombre de plug-ins pour les sources et les transformations, le versionnage des configurations ne sont qu'une partie de ses avantages. Avec toute sa puissance, NiFi reste assez simple à utiliser.
Chez Rostelecom, nous nous efforçons de développer le travail avec Hadoop, nous avons donc déjà essayé et évalué les avantages d'Apache NiFi par rapport à d'autres solutions. Dans cet article, je vais vous dire comment cet outil nous a attiré et comment nous l'utilisons.
Contexte
Il n'y a pas si longtemps, nous étions confrontés au choix d'une solution pour charger des données de sources externes dans un cluster Hadoop. Pendant longtemps, nous avons utilisé
Apache Flume pour résoudre de tels problèmes. Il n'y a eu aucune plainte concernant Flume dans son ensemble, à l'exception de quelques points qui ne nous convenaient pas.
La première chose que nous, en tant qu'administrateurs, n'aimions pas, c'est que l'écriture de la configuration Flume pour effectuer le prochain téléchargement trivial ne pouvait pas être confiée à un développeur ou à un analyste qui n'était pas plongé dans les subtilités de cet outil. La connexion de chaque nouvelle source a nécessité une intervention obligatoire de l'équipe d'administration.
Le deuxième point était la tolérance aux pannes et la mise à l'échelle. Pour les téléchargements lourds, par exemple via syslog, il était nécessaire de configurer plusieurs agents Flume et de définir un équilibreur devant eux. Tout cela devait alors être en quelque sorte surveillé et restauré en cas de panne.
Troisièmement , Flume n'a pas permis de télécharger des données à partir de divers SGBD et de travailler avec certains autres protocoles prêts à l'emploi. Bien sûr, dans les vastes étendues du réseau, vous pouvez trouver des moyens de faire fonctionner Flume avec Oracle ou SFTP, mais prendre en charge de tels vélos n'est pas du tout agréable. Pour charger des données à partir du même Oracle, nous avons dû utiliser un autre outil -
Apache Sqoop .
Franchement, par nature, je suis une personne paresseuse et je ne voulais pas du tout soutenir le zoo des solutions. Et je n'aimais pas que tout ce travail soit fait par moi-même.
Il existe, bien sûr, des solutions assez puissantes sur le marché des outils ETL qui peuvent fonctionner avec Hadoop. Il s'agit notamment d'Informatica, IBM Datastage, SAS et Pentaho Data Integration. Ce sont ceux qui sont le plus souvent entendus par les collègues de l'atelier et ceux qui me viennent à l'esprit en premier. Soit dit en passant, nous utilisons IBM DataStage for ETL sur des solutions de la classe Data Warehouse. Mais il est arrivé historiquement que notre équipe n'ait pas pu utiliser DataStage pour les téléchargements dans Hadoop. Encore une fois, nous n'avions pas besoin de toute la puissance des solutions de ce niveau pour effectuer des conversions et des téléchargements de données assez simples. Ce qu'il nous fallait, c'était une solution avec une bonne dynamique de développement, capable de travailler avec de nombreux protocoles et une interface pratique et intuitive que non seulement un administrateur qui comprenait toutes ses subtilités était capable de gérer, mais aussi un développeur avec un analyste, qui sont souvent pour nous clients des données elles-mêmes.
Comme vous pouvez le voir dans le titre, nous avons résolu les problèmes ci-dessus avec Apache NiFi.
Qu'est-ce que Apache NiFi
Le nom NiFi vient de «Niagara Files». Le projet a été développé par la US National Security Agency pendant huit ans, et en novembre 2014, son code source a été ouvert et transféré à l'Apache Software Foundation dans le cadre du
programme de transfert de technologie de la
NSA .
NiFi est un outil ETL / ELT open source qui peut fonctionner avec de nombreux systèmes, et pas seulement avec les classes Big Data et Data Warehouse. En voici quelques-uns: HDFS, Hive, HBase, Solr, Cassandra, MongoDB, ElastcSearch, Kafka, RabbitMQ, Syslog, HTTPS, SFTP. Vous pouvez voir la liste complète dans la
documentation officielle.
Le travail avec un SGBD spécifique est implémenté en ajoutant le pilote JDBC approprié. Il existe une API pour écrire votre module en tant que récepteur ou convertisseur de données supplémentaire. Des exemples peuvent être trouvés
ici et
ici .
Caractéristiques clés
NiFi utilise une interface Web pour créer DataFlow. Un analyste qui a récemment commencé à travailler avec Hadoop, un développeur et un administrateur barbu s'en occupera. Les deux derniers peuvent interagir non seulement avec des «rectangles et des flèches», mais aussi avec l'
API REST pour collecter des statistiques, surveiller et gérer les composants DataFlow.
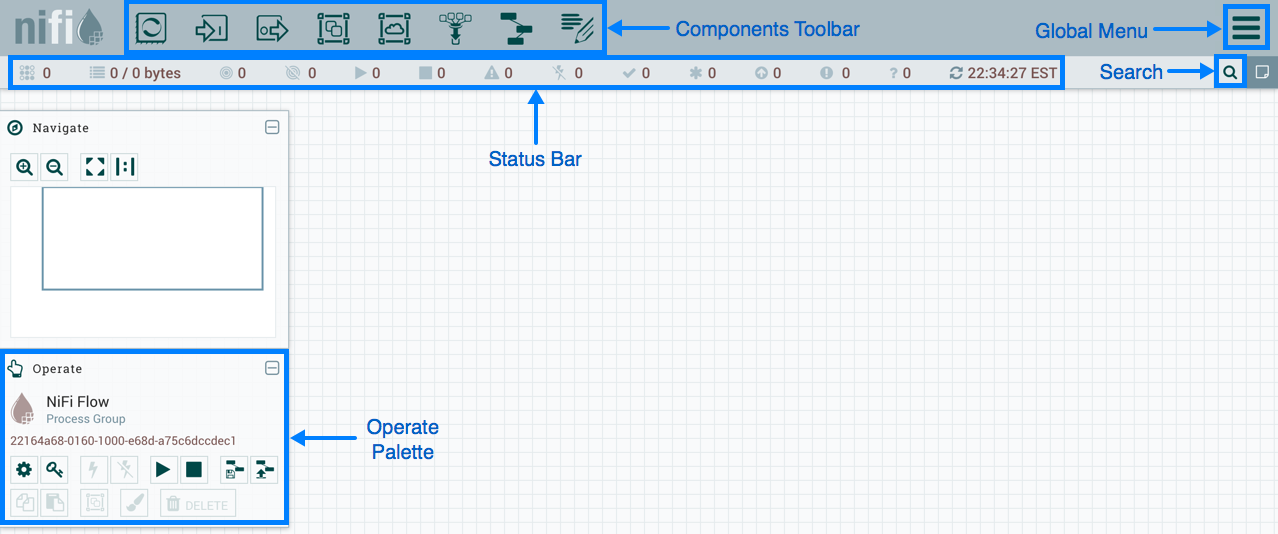 Gestion basée sur le Web NiFi
Gestion basée sur le Web NiFiCi-dessous, je vais montrer quelques exemples DataFlow pour effectuer certaines opérations courantes.
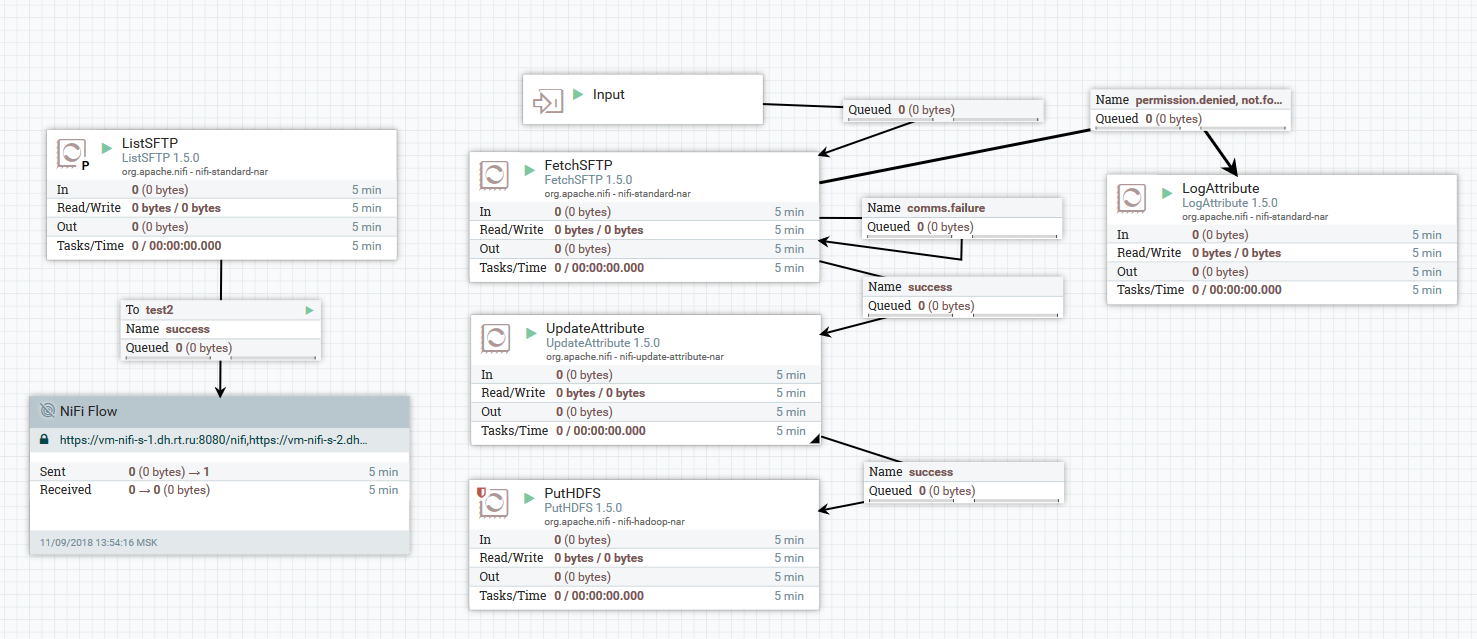 Exemple de téléchargement de fichiers d'un serveur SFTP vers HDFS
Exemple de téléchargement de fichiers d'un serveur SFTP vers HDFSDans cet exemple, le processeur ListSFTP effectue une liste de fichiers sur le serveur distant. Le résultat de cette liste est utilisé pour le chargement de fichiers parallèles par tous les nœuds du cluster par le processeur FetchSFTP. Après cela, des attributs sont ajoutés à chaque fichier, obtenus en analysant son nom, qui sont ensuite utilisés par le processeur PutHDFS lors de l'écriture du fichier dans le répertoire final.
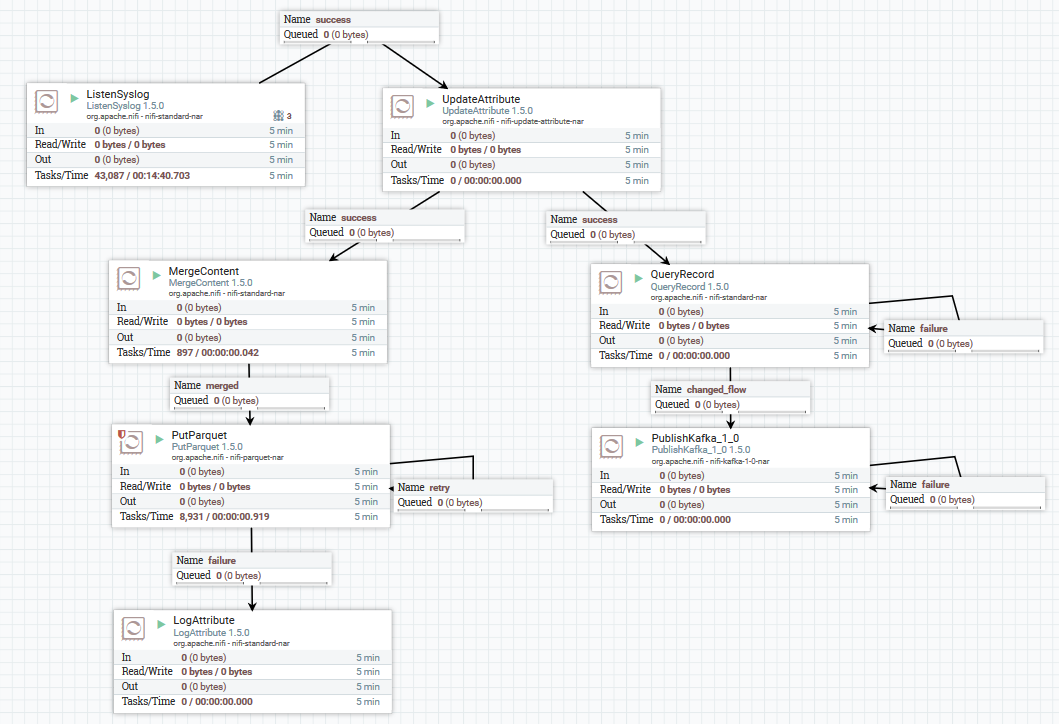 Un exemple de téléchargement de données syslog dans Kafka et HDFS
Un exemple de téléchargement de données syslog dans Kafka et HDFSIci, en utilisant le processeur ListenSyslog, nous obtenons le flux de messages d'entrée. Après cela, des attributs concernant l'heure de leur arrivée dans NiFi et le nom du schéma dans le registre de schéma Avro sont ajoutés à chaque groupe de messages. Ensuite, la première branche est dirigée vers l'entrée du processeur QueryRecord, qui, sur la base du schéma spécifié, lit les données et les analyse à l'aide de SQL, puis les envoie à Kafka. La deuxième branche est envoyée au processeur MergeContent, qui agrège les données pendant 10 minutes, puis les transmet au processeur suivant pour conversion au format Parquet et enregistrement sur HDFS.
Voici un exemple de la façon dont vous pouvez styliser un DataFlow:
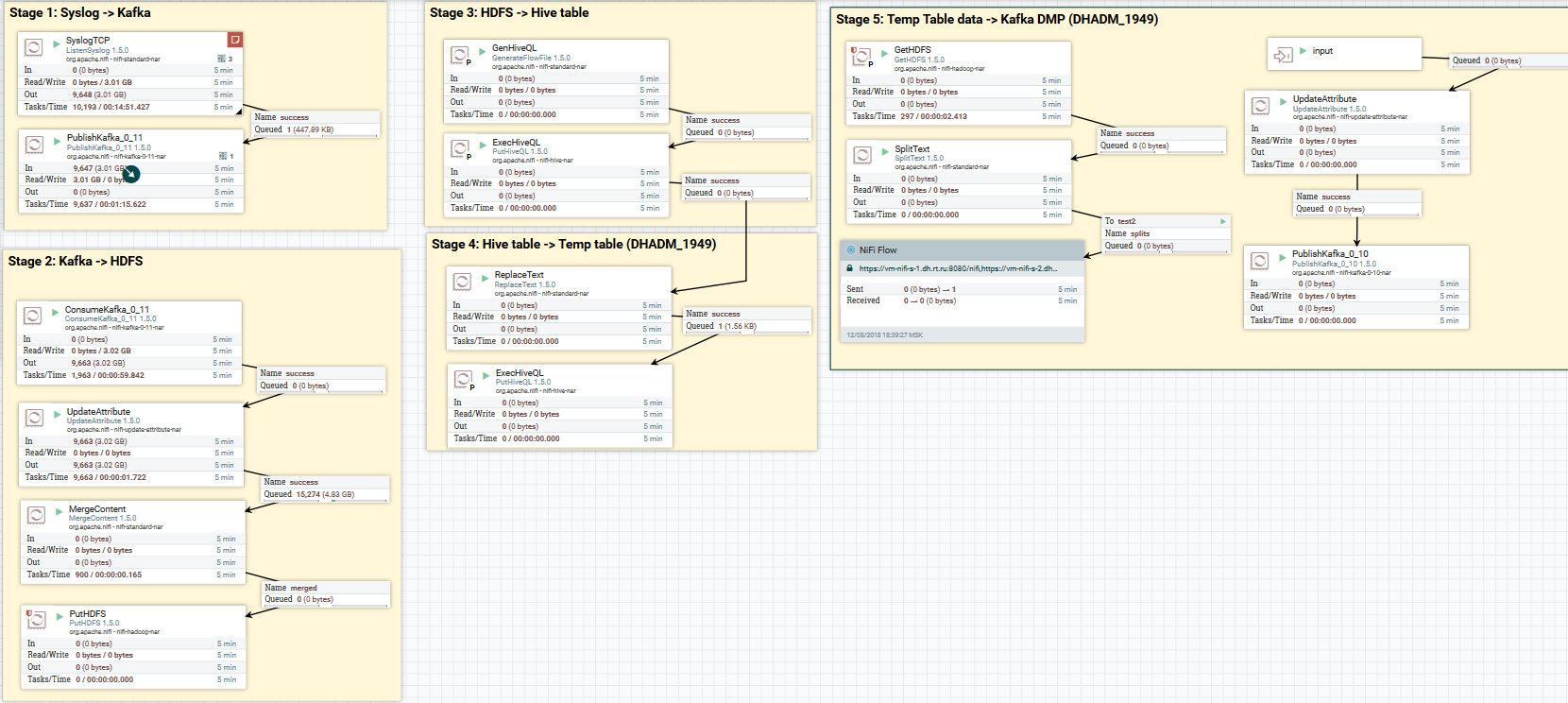 Téléchargez les données syslog sur Kafka et HDFS. Effacement des données dans Hive
Téléchargez les données syslog sur Kafka et HDFS. Effacement des données dans HiveMaintenant sur la conversion des données. NiFi vous permet d'analyser des données avec des données régulières, d'exécuter SQL dessus, de filtrer et d'ajouter des champs et de convertir un format de données en un autre. Il possède également son propre langage d'expression, riche en divers opérateurs et fonctions intégrées. Avec lui, vous pouvez ajouter des variables et des attributs aux données, comparer et calculer des valeurs, les utiliser plus tard dans la formation de divers paramètres, tels que le chemin pour écrire dans HDFS ou une requête SQL dans Hive. Lisez plus
ici .
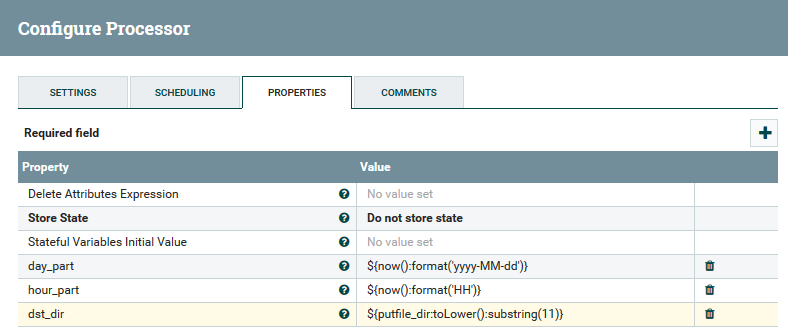 Un exemple d'utilisation de variables et de fonctions dans le processeur UpdateAttribute
Un exemple d'utilisation de variables et de fonctions dans le processeur UpdateAttributeL'utilisateur peut suivre le chemin complet des données, observer la modification de leur contenu et de leurs attributs.
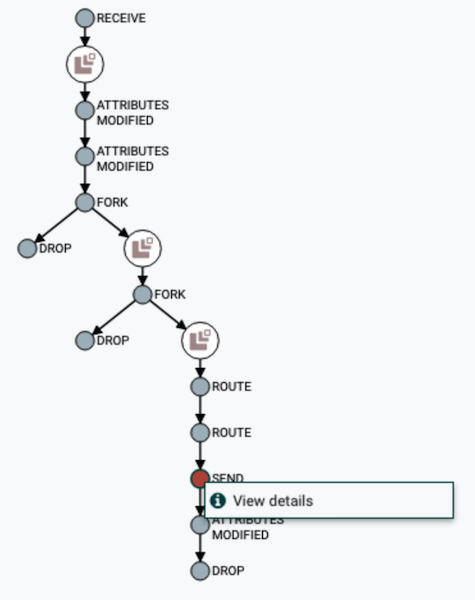 Visualisation de la chaîne DataFlow
Visualisation de la chaîne DataFlow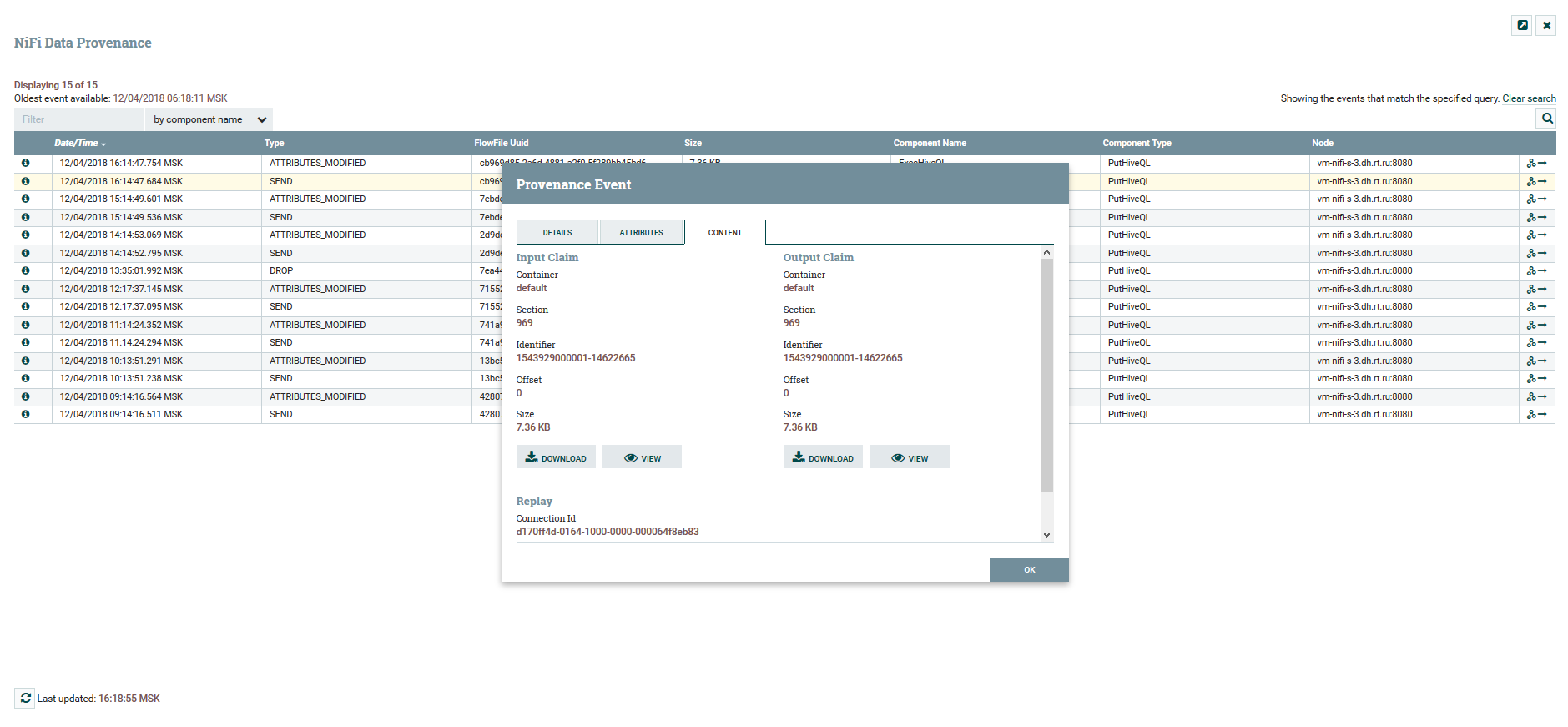 Afficher le contenu et les attributs de données
Afficher le contenu et les attributs de donnéesPour versionner DataFlow, il existe un service de
registre NiFi distinct. En le configurant, vous avez la possibilité de gérer les modifications. Vous pouvez exécuter des modifications locales, annuler ou télécharger n'importe quelle version précédente.
 Menu de contrôle de version
Menu de contrôle de versionEn NiFi, vous pouvez contrôler l'accès à l'interface Web et la séparation des droits des utilisateurs. Les mécanismes d'authentification suivants sont actuellement pris en charge:
L'utilisation simultanée de plusieurs mécanismes à la fois n'est pas prise en charge. Pour autoriser les utilisateurs du système, FileUserGroupProvider et LdapUserGroupProvider sont utilisés. En savoir plus à ce sujet
ici .
Comme je l'ai dit, NiFi peut fonctionner en mode cluster. Cela offre une tolérance aux pannes et permet une mise à l'échelle horizontale de la charge. Il n'y a pas de nœud maître fixe statiquement. Au lieu de cela,
Apache Zookeeper sélectionne un nœud comme coordinateur et un comme principal. Le coordinateur reçoit des informations sur leur état des autres nœuds et est responsable de leur connexion et déconnexion du cluster.
Le nœud principal est utilisé pour démarrer des processeurs isolés, qui ne doivent pas s'exécuter sur tous les nœuds simultanément.
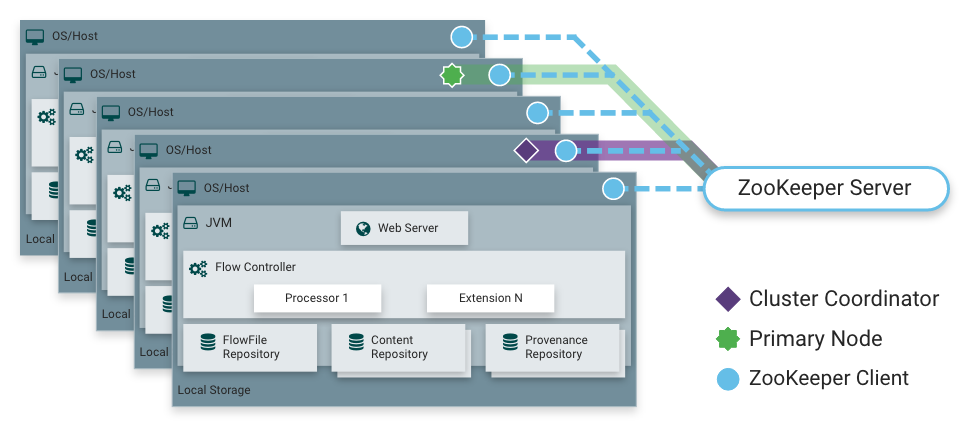 Fonctionnement NiFi dans un cluster
Fonctionnement NiFi dans un cluster Distribution de charge par nœuds de cluster en utilisant le processeur PutHDFS comme exemple
Distribution de charge par nœuds de cluster en utilisant le processeur PutHDFS comme exempleUne brève description de l'architecture et des composants NiFi
 Architecture d'instance NiFi
Architecture d'instance NiFiNiFi est basé sur le concept de «Flow Based Programming» (
FBP ). Voici les concepts et composants de base que chaque utilisateur rencontre:
FlowFile - une entité qui représente un objet avec un contenu de zéro ou plusieurs octets et ses attributs correspondants. Cela peut être soit les données elles-mêmes (par exemple, le flux de messages Kafka), soit le résultat du processeur (PutSQL, par exemple), qui ne contient pas de données en tant que telles, mais uniquement les attributs générés à la suite de la requête. Les attributs sont des métadonnées FlowFile.
Le processeur FlowFile est exactement l'essence qui fait le travail de base en NiFi. Un processeur, en règle générale, a une ou plusieurs fonctions pour travailler avec FlowFile: création, lecture / écriture et modification de contenu, lecture / écriture / modification d'attributs, routage. Par exemple, le processeur ListenSyslog reçoit des données à l'aide du protocole syslog, créant des FlowFiles avec les attributs syslog.version, syslog.hostname, syslog.sender et autres. Le processeur RouteOnAttribute lit les attributs du FlowFile d'entrée et décide de le rediriger vers la connexion appropriée avec un autre processeur, en fonction des valeurs des attributs.
Connexion - fournit une connexion et un transfert FlowFile entre divers processeurs et certaines autres entités NiFi. La connexion place le FlowFile dans une file d'attente, puis le transmet le long de la chaîne. Vous pouvez configurer la façon dont les FlowFiles sont sélectionnés dans la file d'attente, leur durée de vie, le nombre maximal et la taille maximale de tous les objets de la file d'attente.
Groupe de processus - un ensemble de processeurs, leurs connexions et d'autres éléments DataFlow. C'est un mécanisme pour organiser de nombreux composants en une seule structure logique. Aide à simplifier la compréhension de DataFlow. Les ports d'entrée / sortie sont utilisés pour recevoir et envoyer des données à partir de groupes de processus. En savoir plus sur leur utilisation
ici .
Le référentiel FlowFile est l'endroit où NiFi stocke toutes les informations qu'il connaît sur chaque FlowFile existant dans le système.
Référentiel de contenu - le référentiel dans lequel se trouve le contenu de tous les FlowFiles, c'est-à-dire les données transmises elles-mêmes.
Référentiel de provenance - Contient une histoire sur chaque FlowFile. Chaque fois qu'un événement se produit avec FlowFile (création, modification, etc.), les informations correspondantes sont entrées dans ce référentiel.
Serveur Web - fournit une interface Web et une API REST.
Conclusion
Avec NiFi, Rostelecom a pu améliorer le mécanisme de livraison des données à Data Lake sur Hadoop. En général, l'ensemble du processus est devenu plus pratique et plus fiable. Aujourd'hui, je peux affirmer avec confiance que NiFi est idéal pour le téléchargement sur Hadoop. Nous n'avons aucun problème dans son fonctionnement.
Soit dit en passant, NiFi fait partie de la distribution de flux de données Hortonworks et est activement développé par Hortonworks lui-même. Il a également un sous-projet Apache MiNiFi intéressant, qui vous permet de collecter des données à partir de divers appareils et de les intégrer dans DataFlow à l'intérieur de NiFi.
Informations supplémentaires sur NiFi
C’est peut-être tout. Merci à tous pour votre attention. Écrivez dans les commentaires si vous avez des questions. Je leur répondrai avec plaisir.