Est-il possible de catégoriser tous les événements arrivant au SIEM et quel système de catégorisation utiliser pour cela? Comment appliquer des catégories dans les règles de corrélation et la recherche d'événements? Nous analyserons ces questions et d'autres dans un nouvel article du cycle consacré à la méthodologie de création de règles de corrélation prêtes à l'emploi pour les systèmes SIEM.
Image: WorktrooperCet article a été co-écrit avec
Mikhail Maximov et
Alexander Kovtun .
Nous vous avertissons: l'article est volumineux, car il décrit la construction du système de catégorisation et nos chaînes de raisonnement. Si vous êtes trop paresseux pour le lire dans son intégralité, alors vous pouvez immédiatement aller à la section avec des
conclusions - là, nous avons résumé tout ce qui a été discuté dans l'article et résumé les résultats.
Dans un
article précédent, nous avons constaté que les événements contiennent de nombreuses informations importantes qui ne peuvent pas être perdues dans le processus de normalisation. La description du schéma d'interaction fait référence à ce type de données. Pour systématiser les types d'interaction, nous avons fait ce qui suit:
- identifié les principaux schémas inhérents à tout type d'événement;
- déterminé quelles entités participent aux programmes;
- formé l'ensemble de base des champs nécessaires pour décrire toutes les entités trouvées dans l'événement initial et le canal d'interactions entre elles.
À la suite de l'analyse des journaux de divers types de logiciels et de matériel, nous avons pu distinguer les entités: sujet, objet d'interaction, source et émetteur.
Parlons maintenant de la sémantique de l'interaction de ces entités et de sa réflexion dans la catégorisation des événements. Avant de décrire l'approche de la formation et des catégories, il est nécessaire de répondre à deux questions: pourquoi il est nécessaire de déterminer les catégories d'événements et quelles propriétés le système de cathétérisme devrait avoir.
Déterminons d'abord pourquoi les événements doivent être classés. En bref: une catégorisation est nécessaire pour fonctionner aussi bien avec des événements sémantiquement similaires, quel que soit le type de source. Nous nous référons aux types de sources dont l'objectif principal est la source: équipements réseau, systèmes d'exploitation, logiciels d'application. L'expression «travailler de la même manière avec des événements sémantiquement similaires» doit être comprise comme suit:
- Les événements sémantiquement similaires de tout type de source ont une catégorie commune.
- Pour les événements de chaque catégorie, des règles claires pour remplir les champs du schéma sont définies. Nous combattons donc efficacement le chaos qui se produit au stade de la normalisation des événements et conduit souvent à de multiples faux positifs des règles de corrélation.
- La gestion des catégories vous permet d'éviter les vérifications inutiles dans le code des règles de corrélation afin de comprendre la sémantique de l'événement. Par exemple, il n'est pas nécessaire de vérifier la disponibilité des données dans certains champs pour déterminer que l'événement décrit l'entrée de l'utilisateur et non la sauvegarde du système.
- La catégorisation est une base terminologique générale qui aide à rédiger les règles de corrélation et d'enquête sur les incidents, à opérer avec un seul ensemble de termes et leurs significations généralement acceptées. Par exemple, pour bien comprendre que la modification de la configuration réseau et la modification de la configuration logicielle sont des types d'événements complètement différents qui ont des significations complètement différentes.
Pour obtenir tout cela, vous devez créer un système de catégorisation des événements et l'utiliser lors de l'écriture de règles de corrélation, des enquêtes sur les incidents et dans les cas où plusieurs personnes travaillent dans une organisation dotée d'un système SIEM.
Quant aux exigences du système de catégorisation, il doit satisfaire quatre propriétés:
- Sans ambiguïté . Un même événement doit être assigné à une et une seule catégorie.
- Compacité . Le nombre total de catégories doit être tel qu'elles puissent être facilement mémorisées par un expert.
- Hiérarchie . Le système doit être construit sur un schéma hiérarchique et se composer de plusieurs niveaux, car il s'agit de la structure la plus simple à retenir. De plus, la hiérarchie devrait être construite sur le principe du «du général au particulier»: au premier niveau, il y a des catégories plus «générales» et au dernier - des catégories hautement spécialisées.
- Extensibilité . Les principes selon lesquels il est construit devraient permettre de mettre à jour le système de catégorisation lorsque de nouveaux types d'événements apparaissent nécessitant des catégories distinctes, sans changer l'approche principale.
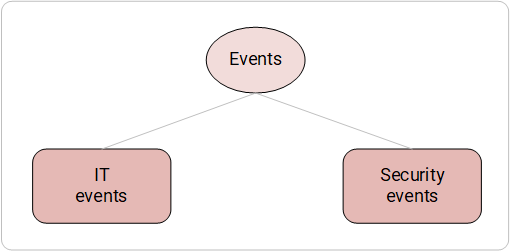
Passons à la description du système de catégorisation: nous allons commencer par deux grands domaines, qui incluent des sources d'événements connectés à SIEM et dans lesquels ils génèrent des événements.
Domaines source et événement
Le déploiement de SIEM commence souvent par la connexion de sources qui génèrent des événements disparates. Une propriété importante de ces événements est qu'ils reflètent la fonctionnalité des sources elles-mêmes.
On distingue deux domaines globaux:
- Sources informatiques - logiciels d'application et matériel à l'échelle du système qui génèrent des événements informatiques.
- Sources IB - logiciels et matériels spécialisés pour la sécurité des informations de l'entreprise qui génèrent des événements IB.
Considérez les différences fondamentales entre les événements de ces domaines.
Les sources informatiques signalent la survenance de tout phénomène dans le système automatisé, sans leur évaluation du niveau de sécurité - «bon» ou «mauvais». Exemples: application d'une nouvelle configuration par un appareil, sauvegarde de données, transfert d'un fichier sur un réseau, désactivation d'un port réseau sur un commutateur.
Contrairement aux sources informatiques, les sources SI ont des connaissances externes supplémentaires sur la façon d'interpréter certains événements du point de vue de la sécurité - la politique. Ainsi, l'utilisation de politiques permet aux sources du SI de prendre des décisions - si le phénomène observé est «bon» ou «mauvais» - et de le signaler au SIEM via les événements IB générés.
Prenons l'exemple suivant: Ainsi, en général, un pare-feu de niveau nouvelle génération considère un événement de transfert de fichiers sur le réseau comme «mauvais»: il s'avère que le fichier est un document Word qui est transféré du réseau interne de l'entreprise à un serveur externe via FTP, et la stratégie configurée interdit de telles interactions informationnelles. La désactivation du port réseau est interprétée comme une violation des droits d'accès par la décision de contrôler les actions des administrateurs: puisque la déconnexion du port est effectuée par l'utilisateur Alex, qui n'y a pas de droits, et se produit pendant ses heures non travaillées, selon la politique de sécurité configurée.
Cependant, il n'est pas tout à fait vrai de dire que les sources de sécurité de l'information ne génèrent que des événements de sécurité de l'information. Les sources IB génèrent des événements IB et IT. Les sources SI génèrent des événements informatiques, en règle générale, lorsqu'elles signalent un changement dans leur état: changements de configuration, commutation de nœuds de cluster et sauvegardes. En général, ces événements peuvent être attribués à l'audit interne des actions et à l'état de la source. Dans le même temps, lorsque l'activité concerne l'application de politiques de sécurité, la même source génère déjà des événements de sécurité des informations, rapportant ainsi les résultats de leur application.
Nous avons délibérément décrit les différences entre les deux domaines avec autant de détails. Les événements de chaque domaine ont leur propre signification et peuvent parfois différer fondamentalement les uns des autres. Ces différences ont conduit à l'existence de deux systèmes de catégorisation d'événements distincts responsables des événements informatiques et des événements de sécurité de l'information.
 Domaines d'événements
Domaines d'événementsIl existe un autre type rare de sources qui génèrent des événements d'un troisième domaine distinct - le domaine des attaques. Les événements de ce domaine peuvent être obtenus à partir de sources du niveau de protection des points d'extrémité (Endpoint Protection), d'autres SIEM subordonnés (s'ils sont organisés dans une hiérarchie) ou d'autres solutions capables de déterminer, sur la base de l'analyse d'événements informatiques et (ou) de sécurité des informations, qu'un système automatisé ou une partie est soumise à une attaque de pirate.
Dans le cadre de cette série d'articles, nous utiliserons les concepts suivants pour séparer les attaques et les événements de sécurité de l'information des moyens de défense de bout en bout:
- Une attaque est une séquence malveillante d'actions d'un attaquant visant à atteindre un objectif spécifique au sein d'une entreprise.
- Une attaque peut consister en un ou plusieurs événements - une chaîne d'événements de sécurité des informations et / ou des événements informatiques qui constituent des violations des politiques de sécurité des informations.
Il existe plusieurs approches pour catégoriser les attaques, par exemple, la popularité croissante de
MITER Adversarial Tactics, Techniques, and Common Knowledge (ATT & CK) , mais nous ne considérerons pas ce domaine dans nos articles.
Système de catégorisation des événements informatiques
Les logiciels et le matériel d'application à l'échelle du système, que nous attribuons aux sources informatiques des événements, sont conçus pour mettre en œuvre ou prendre en charge certains processus pour remplir ses tâches. Au cours de leur décision, les faits commis sont enregistrés par des événements informatiques distincts. Ils peuvent être attribués au processus dans lequel chacun d'eux s'est produit.
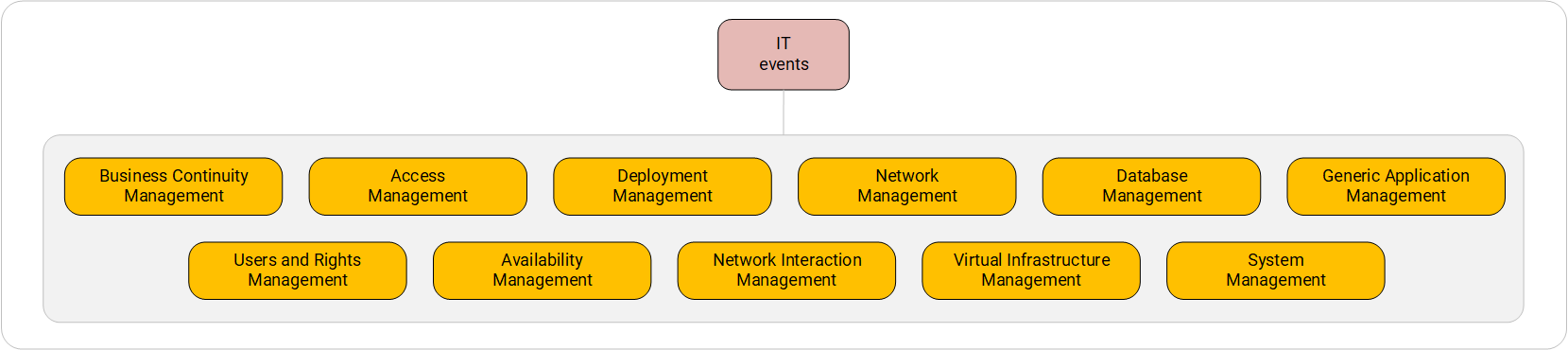
En isolant les processus se produisant dans les sources informatiques, nous pouvons former le premier niveau de catégorisation (que nous appellerons plus tard le contexte). Il définira un champ sémantique qui interprétera correctement les événements informatiques.
Lors de l'analyse des événements, il apparaît clairement que chacun d'eux décrit l'interaction de plusieurs entités dans le cadre d'un processus déjà défini. En sélectionnant la principale de ces entités comme objet d'interaction, nous formons le deuxième niveau de catégorisation.
Le comportement de l'entité principale dans l'événement dans le cadre d'un processus spécifique jouera le rôle du troisième niveau de catégorisation des événements informatiques.
Au total, à la sortie, nous avons obtenu les niveaux suivants:
- Contexte (processus) dans lequel l'événement s'est produit.
- L'objet (entité principale) décrit par l'événement.
- La nature du comportement de l'objet dans le contexte.
Ainsi, nous avons formé trois niveaux de catégorisation des événements informatiques, vous permettant d'opérer facilement sur des événements sémantiquement similaires provenant de différents types de sources dans l'infrastructure informatique.
Pour garantir l'unicité du système de catégorisation résultant, nous formerons des domaines distincts pour chaque niveau.
 Système de catégorisation des événements informatiques. Premier niveau.
Système de catégorisation des événements informatiques. Premier niveau.Une approche de processus similaire pour travailler avec les systèmes informatiques est également utilisée dans ITSM (IT Service Management, IT service management), qui postule certains processus de base qui ont lieu dans les services informatiques. Nous nous appuierons sur cette approche lors de la formation de processus possibles, ou en d'autres termes, de contextes, lors de l'examen des sources d'événements informatiques.
Nous distinguons les principaux processus de ce niveau:
- Gestion de la continuité des activités - événements liés aux opérations pour maintenir le fonctionnement continu des systèmes: processus de réplication, migration et synchronisation des machines virtuelles, des bases de données et des stockages, opérations de sauvegarde et de restauration;
- Gestion des utilisateurs et des droits ( gestion des utilisateurs et des droits) - événements liés à l'utilisation des groupes et des comptes d'utilisateurs;
- Gestion des accès - événements associés aux processus d'authentification, d'autorisation, de comptabilité (AAA) et à toute tentative d'accès au système;
- Gestion de la disponibilité - événements associés à toutes les actions pour démarrer, arrêter, allumer, éteindre, arrêter des entités, y compris les messages d'information des systèmes de contrôle d'accès aux entités;
- Gestion du déploiement (gestion des événements) - événements associés à l'introduction de nouvelles entités dans le système de l'extérieur, ainsi qu'à la suppression de l'entité de ce système;
- Gestion des interactions réseau - événements liés à la transmission de données via le réseau, y compris l'établissement de connexions, l'ouverture et la fermeture de tunnels;
- Gestion du réseau - événements liés à la pile réseau: y compris toutes les actions avec des politiques et des règles pour le filtrage du réseau;
- Gestion de l'infrastructure virtuelle (gestion de l'infrastructure virtuelle) - événements liés à l'infrastructure de virtualisation;
- Gestion de la base de données - événements liés au fonctionnement du SGBD et aux actions des utilisateurs et des processus qu'il contient;
- Gestion du système - événements liés au fonctionnement du système d'exploitation et des logiciels qui font partie du système d'exploitation;
- Generic Application Management (gestion d'autres applications) - événements associés au fonctionnement d'autres applications installées par l'utilisateur et ne faisant pas partie du système d'exploitation.
Il est important de comprendre que différents processus peuvent se produire sur la même source informatique. Ainsi, par exemple, dans le service DHCP déployé sur Unix, le processus de gestion du réseau (générant, par exemple, un événement de mise à jour d'adresse IP sur les nœuds) et le processus de gestion du système, générant un événement de redémarrage du service ou une erreur d'analyse du fichier de configuration, peuvent se produire.
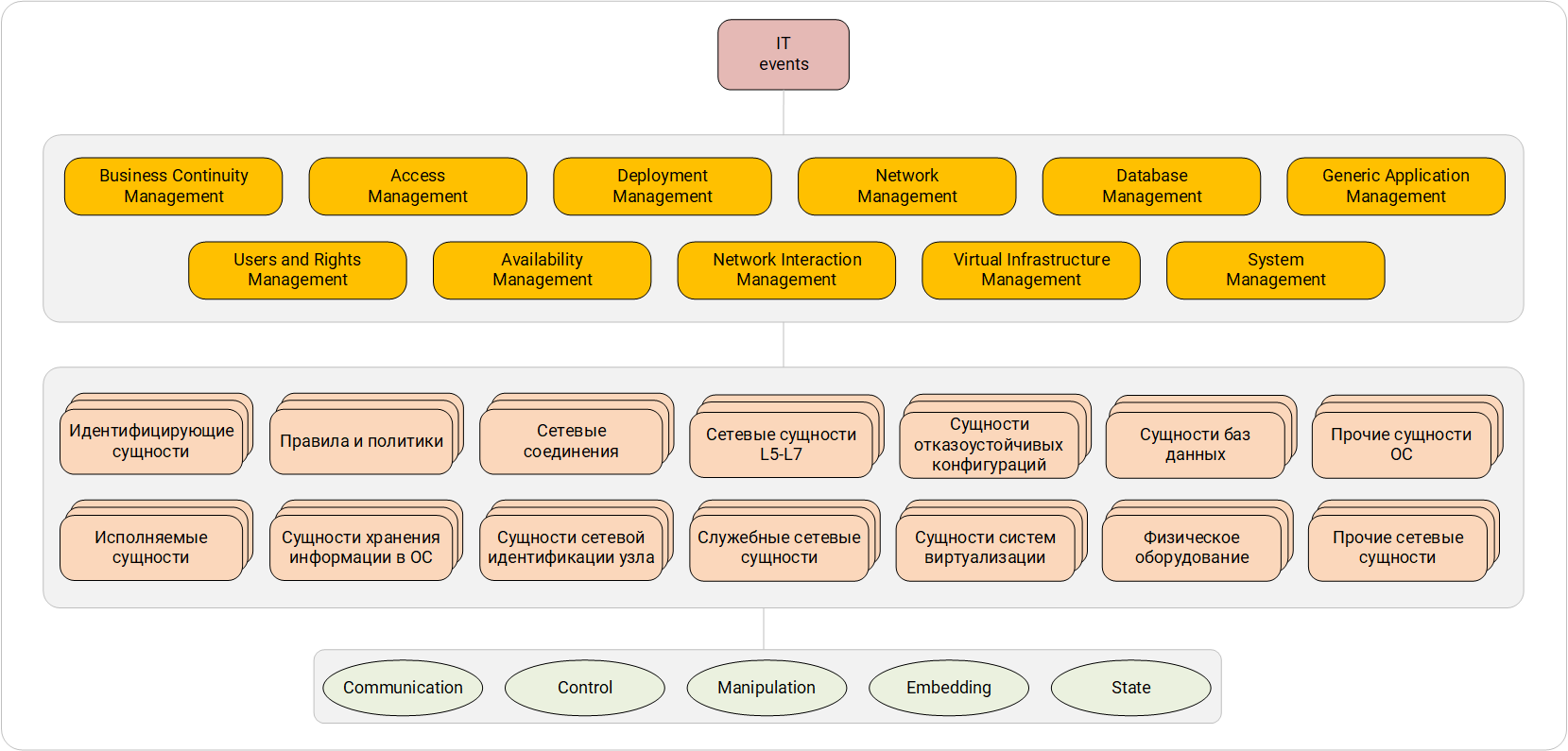
Le deuxième niveau de catégorisation des événements informatiques (entités)
 Système de catégorisation des événements IB. Les premier et deuxième niveaux.
Système de catégorisation des événements IB. Les premier et deuxième niveaux.Le deuxième niveau reflète l'objet d'interaction décrit dans l'événement. Notez qu'un événement peut décrire plusieurs entités. Par exemple, prenez l'événement suivant: "l'utilisateur a envoyé une demande au serveur de certificats pour l'émission d'un certificat personnel." Dans les événements de ce type, il est nécessaire de choisir une entité de base comme objet d'interaction, qui est centrale dans l'événement. Ici, nous pouvons déterminer que l'entité principale est une «demande à un serveur de certification», car l'utilisateur est évidemment le sujet de l'interaction, et le certificat personnel est le résultat de l'interaction du sujet et de l'objet. En collectant et en analysant un large éventail d'événements, nous pouvons distinguer des groupes d'entités:
- identification : compte d'utilisateur, groupe d'utilisateurs, certificat - entités qui vous permettent d'identifier l'utilisateur ou le système;
- exécutable : application, module exécutable - tout ce qui peut être lancé par le système d'exploitation et contient un certain algorithme;
- règles et stratégies : toutes les règles, stratégies d'accès, y compris les stratégies de groupe Windows OC;
- l'essence du stockage d'informations dans le système d'exploitation : un fichier, une clé de registre, un objet d'un groupe de répertoires - tout ce qui peut servir de stockage d'informations au niveau de l'application;
- connexions réseau : sessions, flux, tunnels - entités qui transportent un flux de données d'un nœud à un autre;
- Entités d'identification réseau du nœud : adresse réseau, socket, directement le nœud réseau lui-même - toutes ces entités dont aucun système de surveillance ne peut se passer;
- réseau L5-L7 : message électronique, flux multimédia, liste de distribution - entités qui transmettent des informations aux niveaux L5-L7 du modèle OSI;
- réseau de service : zone DNS, table de routage. Ces entités sont responsables du bon fonctionnement du réseau, sans porter de charge utile pour l'utilisateur final;
- entités de configurations tolérantes aux pannes : RAID, éléments de réseau de cluster;
- l'essence des systèmes de virtualisation : machines virtuelles, disques durs virtuels, instantanés de machines virtuelles;
- entités de base de données : tables, bases de données, SGBD;
- équipements physiques : appareils enfichables, éléments ACS (tourniquets, caméras IP);
- autres entités OS : une commande dans la console de gestion, la console système, le journal système - les entités OS qui ne rentrent pas dans d'autres catégories;
- autres entités de réseau : interface de réseau, ressource de réseau public - les entités du sous-système de réseau qui ne rentrent pas dans d'autres catégories.
Ces groupes ne prétendent pas être exhaustifs, mais couvrent les principales tâches d'attribution des catégories de deuxième niveau. Si nécessaire, les groupes représentés peuvent s'étendre.
Le troisième niveau de catégorisation des événements informatiques (nature de l'interaction)
 Système de catégorisation des événements informatiques. Les premier, deuxième et troisième niveaux.
Système de catégorisation des événements informatiques. Les premier, deuxième et troisième niveaux.Dans un processus spécifique, le comportement de l'entité principale peut être réduit aux valeurs suivantes:
- Contrôle - interaction qui affecte le fonctionnement de l'entité;
- Communication - communication entre entités;
- Manipulation - actions pour travailler avec l'entité elle-même, y compris la manipulation de ses données;
- Incorporation - interaction, à la suite de laquelle une nouvelle entité est ajoutée au contexte (ou l'entité est supprimée du contexte);
- État - événements d'information sur les changements d'état d'une entité.
Le dernier domaine se distingue entre autres: il comprend des événements qui ne décrivent en fait aucune interaction, mais contiennent des informations sur l'entité ou les transitions d'entité entre états. Par exemple, un événement qui décrit uniquement l'état actuel du système (sur l'heure actuelle du système, sur un changement de statut d'une licence de produit).
Les événements décrivent non seulement l'interaction elle-même, mais aussi son résultat. Il est important de comprendre que le contexte, l'essence principale et le comportement d'un objet dans le contexte ne dépendent pas du résultat de l'interaction. Le résultat peut être «succès» et «échec». Un événement peut également décrire le processus continu d'interaction incomplète. Nous appellerons ce statut «en cours».
Formation d'un ensemble de données basé sur trois niveaux
Pour chaque domaine de chaque niveau, vous pouvez sélectionner un ensemble de données spécifique contenant des événements.
Analysons un exemple d'événement:

Il peut être interprété comme «la connexion du nœud 10.0.1.5 au nœud 192.168.149.2 a été déconnectée». En regardant le contexte d'un événement, vous pouvez voir qu'il décrit une connexion réseau. En conséquence, nous tombons dans le contexte de la «gestion des interactions réseau».
Ensuite, nous déterminons l'entité principale de l'événement. Évidemment, l'événement décrit trois entités: deux nœuds et une connexion réseau. Sur la base des recommandations ci-dessus, nous comprenons que l'entité principale dans ce cas n'est qu'une connexion réseau et que les nœuds sont des participants à l'interaction, des points de terminaison qui effectuent des actions sur l'entité. Au total, nous obtenons l'entité principale du domaine Connexions réseau, et l'action effectuée sur l'entité est la «fermeture du canal de communication», qui peut être attribuée au domaine de la communication.
Cependant, nous avons encore beaucoup de données qui pourraient être enregistrées à partir de l'événement. Ainsi, un ensemble d'entités du deuxième niveau «Connexions réseau» ont des propriétés communes:
- initiateur de connexion (adresse + port + interface);
- récepteur (cible) de la connexion (adresse + port + interface);
- Protocole sur lequel la connexion est établie.
De plus, par exemple, l'action du troisième niveau de catégorisation «fermeture de la connexion», appartenant au domaine Communication, peut contenir les données suivantes, quelle que soit la connexion fermée et quelle source l'a signalé:
- nombre d'octets envoyés / envoyés;
- nombre de paquets transmis / envoyés;
- durée.
A titre d'exemple, on peut distinguer un ensemble d'entités de base «Entités de stockage d'informations dans l'OS», qui se caractérisent par les données suivantes:
- nom de l'entité;
- le chemin de localisation de l'entité dans le système d'exploitation;
- taille de l'entité;
- privilèges d'accès à l'entité.
Un ensemble d'actions liées à cette entité, par exemple la «copie», qui est incluse dans le domaine de troisième niveau «Manipulation», peut être caractérisé par les propriétés suivantes:
- Le nouveau nom de l'entité
- une nouvelle façon d'organiser l'entité;
- Nouveaux privilèges d'accès aux entités.
En option, nous pouvons obtenir toutes ces données de l'événement. L'essentiel est que la catégorie que nous avons définie nous permet de mettre en évidence un ensemble spécifique de données qui peuvent être extraites de l'événement, sachant à l'avance que ces données seront sémantiquement similaires.
Et à cet égard, les catégories deviennent un outil pratique. En comparant un certain ensemble de ces données à chaque niveau de domaine, nous avons la possibilité de stocker des données sémantiquement similaires dans les mêmes champs d'un événement normalisé, quels que soient le fabricant et le modèle de la source d'événement. Cela simplifie considérablement la recherche de données dans un grand volume d'événements et, par conséquent, la mise en œuvre de corrélations pour de tels événements.
Exemples de système de catégorisation
Situation 1: Vous devez trouver tous les événements qui décrivent la connexion et la déconnexion des périphériques de toutes les sources.Chacune des sources génère des événements, après normalisation dont les catégories contiennent les catégories Niveau 1 (premier niveau de catégorisation), Niveau 2 (deuxième niveau) et Niveau 3 (troisième niveau). Dans la situation décrite, tous les événements d'intérêt contiendront des catégories:- Niveau 2: équipement physique;
- Niveau 3: intégration.
, .
, :
Select * from events where Level2 = “< >” and Level3 = “Embedding” and time between (< >)
Situation 2: Il est nécessaire de trouver tous les événements qui décrivent une tentative de modification des objets du système de fichiers avec un nom commençant par «boot».
Les sources connectées à SIEM peuvent produire des événements de modification de fichier complètement différents. Cependant, l'attribution des catégories appropriées aux événements vous permet de sélectionner le nécessaire dans l'ensemble du tableau:
- Niveau 1: gestion du système;
- Niveau 2: Entités de stockage d'informations dans le système d'exploitation;
- Niveau 3: Manipulation.
De plus, une condition est spécifiée par le nom de fichier: en utilisant des ensembles de données prédéfinis, nous pouvons nous attendre à ce que pour cette catégorie le nom de fichier soit dans le champ object.name. Par conséquent, pour sélectionner des événements, vous pouvez former la requête suivante:
Select * from events where Level1 = “System Management” and Level2 = “< >” and Level3 = “Manipulation” and (object.name like “boot.%”)
Si une entité a été copiée, nous trouverons des informations à son sujet et qu'elle a été copiée à partir d'une autre entité - cela donnera un élan à une enquête plus approfondie.
Cas 3: Il est nécessaire de fournir un profilage simple des connexions réseau sur les routeurs frontaliers de différents fabricants installés dans les succursales de l'entreprise. SIEM reçoit des événements de chacun de ces routeurs de périphérie.
Chacun des routeurs génère des événements informatiques, après normalisation dont les champs Niveau 1, Niveau 2, Niveau 3 contiennent des catégories. Dans l'exemple décrit, pour le profilage, il est nécessaire et suffisant d'analyser les événements concernant l'ouverture et la fermeture des connexions réseau. Selon le système de catégorisation présenté, ces événements contiendront les champs de catégorie suivants:
- Niveau 1: gestion des interactions réseau;
- Niveau 2: Connexions réseau;
- Niveau 3: Communication.
De plus, pour les opérations d'ouverture et de fermeture de connexions, vous pouvez spécifier les actions «ouvrir» et «fermer», ainsi que le statut de l'action «succès».
De plus, ayant des ensembles de données pour chacune des catégories de la catégorie, vous pouvez être sûr que l'heure de début de la connexion sera enregistrée dans l'événement d'ouverture de connexion et que les informations sur les nœuds participant à l'interaction réseau seront placées dans l'événement de fermeture de connexion, ainsi que dans les champs «Nombre d'octets transmis», «nombre de paquets transmis» et «durée» seront placés les données correspondantes sur la durée de la connexion et la quantité d'informations transmises, respectivement.
Ainsi, en filtrant le flux d'événements par les catégories et actions spécifiées, vous pouvez sélectionner uniquement les événements nécessaires pour l'opération de profilage, sans avoir à spécifier une liste d'identificateurs d'événements spécifiques.
Système de catégorisation des événements IB
Avant de parler du système de catégorisation, notons que nous ne considérerons que les événements provenant des défenses. La catégorisation des attaques de pirates en tant que chaînes d'actions malveillantes est un domaine distinct avec son propre système de catégorisation.
Le système de catégorisation des événements de sécurité de l'information est basé sur un certain paradigme. Il est formulé comme suit: tout incident qui se produit dans un système automatisé se reflète sur un ou plusieurs supports à la fois: le niveau d'un hôte spécifique, le niveau du réseau et le niveau de l'environnement physique.
Les outils de sécurité opérant à ces niveaux identifient l'incident ou ses «échos» et génèrent des événements de sécurité de l'information qui entrent dans le SIEM.
Par exemple, la transmission d'un fichier malveillant sur un réseau à un hôte spécifique peut être détectée au niveau du réseau et de l'hôte, dans le processus de traitement du trafic réseau au moyen de la protection du réseau ou en analysant les zones de mémoire RAM avec les modules de protection antivirus appropriés.
L'accès physique non autorisé aux locaux peut être détecté au niveau de l'environnement physique au moyen de systèmes de contrôle d'accès et au niveau de l'hôte, au moyen de SZI de la NSD lorsque l'utilisateur est autorisé à héberger pendant les heures creuses.
Lorsque vous travaillez avec des événements SI, il est souvent nécessaire de comprendre dans quel environnement l'incident a été enregistré. Et déjà en partant de là, construisez un nouveau chemin d'investigation ou formez la logique de la règle de corrélation. Ainsi, l'environnement de détection est le premier niveau d'un système de catégorisation.
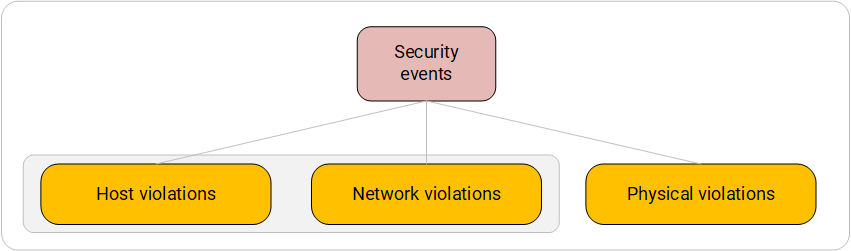
Le premier niveau du système de catégorisation des événements de l'IB
 Système de catégorisation des événements IB. Premier niveau.
Système de catégorisation des événements IB. Premier niveau.- Violations de l'hôte (événements du niveau hôte) - événements provenant des moyens de protection installés sur les postes de travail et serveurs finaux. En règle générale, les événements de sécurité de l'information de ce niveau décrivent le déclenchement de politiques de sécurité à la suite de l'analyse de l'état interne de l'hôte au moyen d'une protection. Sous l'analyse de l'état interne, on entend ici l'analyse des processus en cours, des données dans les domaines de la RAM, des fichiers sur le disque.
Types de sources d'événements : outils de protection antivirus, systèmes de surveillance de l'intégrité, systèmes de détection d'intrusion au niveau de l'hôte, contrôle d'accès et systèmes de contrôle d'accès. - Violations de réseau - événements provenant de systèmes qui analysent le trafic réseau et lui appliquent un ensemble de politiques de sécurité établies.
Types de sources d'événements : pare-feu, systèmes de détection et de prévention des intrusions, systèmes de détection DDoS. Certaines protections d'hôte disposent également de modules d'analyse du trafic réseau distincts. Par exemple, des outils de protection antivirus et certains dispositifs antivirus domestiques de NSD. - Violations physiques (violations du niveau de l'environnement physique) - événements provenant de la sécurité physique.
Types de sources d'événements : systèmes de sécurité de périmètre, systèmes de contrôle d'accès, systèmes de protection contre les fuites d'informations via des canaux vibro-acoustiques et des canaux PEMIN.
Cette catégorie comprend également les incidents identifiés par le service de sécurité physique ou économique au cours des activités internes et introduits dans les bases de données internes de l'entreprise, dont les informations peuvent être collectées par le SIEM. Pour des raisons d'organisation, il s'agit d'un événement extrêmement rare, mais toujours possible.
Les deuxième et troisième niveaux du système de catégorisation des événements de l'IB
Le deuxième niveau du système de catégorisation est associé au premier, mais présente des fonctionnalités en raison des conditions préalables suivantes:
- les incidents de sécurité des informations ne se produisent pas toujours dans l'environnement physique;
- les incidents dans l'environnement physique ne sont pas toujours associés à des incidents de sécurité de l'information, mais il y a aussi des intersections;
- les incidents au niveau du réseau et de l'hôte final ont souvent une structure et une sémantique similaires.
Par conséquent, au deuxième niveau, un groupe de catégories correspondant aux violations du niveau de l'environnement physique et des groupes de catégories communes aux violations du réseau et du niveau hôte sont distingués.
Le troisième niveau du système de catégorisation clarifie le second et décrit directement les violations elles-mêmes, dont l'essence se reflète dans les événements de sécurité de l'information.
Nous avons analysé les systèmes de catégorisation d'événements pour les solutions de sécurité IBM QRadar, Micro Focus Arcsight et Maxpatrol SIEM pour les violations au niveau du réseau et de l'hôte. Selon les résultats, ils ont conclu: ils sont tous très similaires et
eCSIRT.net mkVI peut servir de système de catégorisation le plus complet et unificateur. C'est elle qui a été prise comme base dans le système de catégorisation ci-dessous.
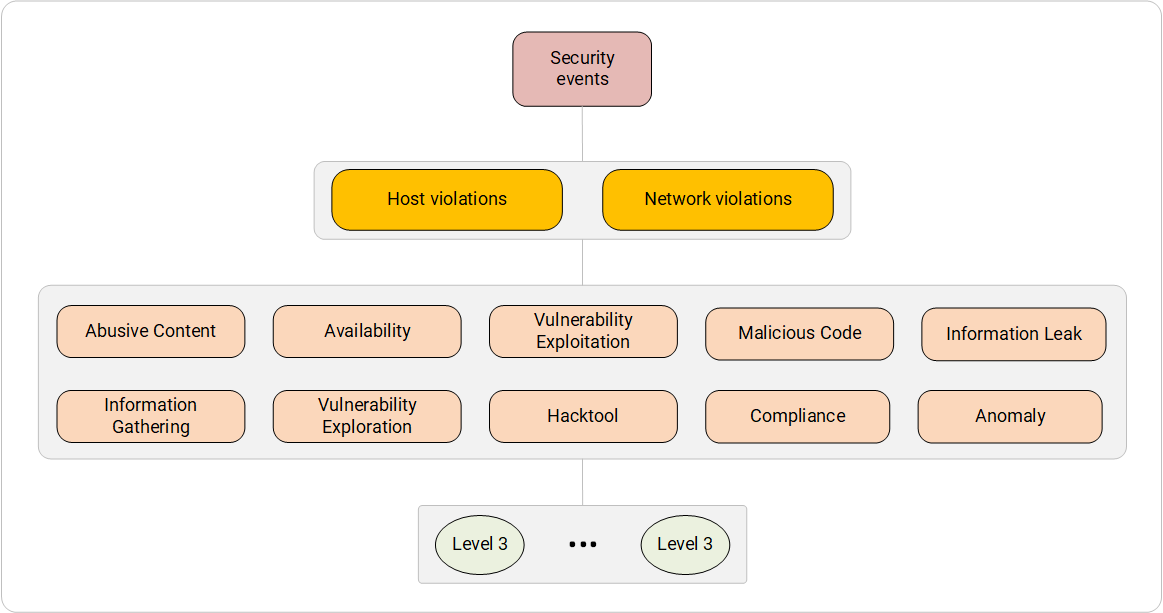 Système de catégorisation des événements IB. Violations au niveau de l'hôte et au niveau du réseau.
Système de catégorisation des événements IB. Violations au niveau de l'hôte et au niveau du réseau.- Contenu abusif - contenu livré légalement à l'utilisateur final, provoquant des actions illégales (intentionnelles ou non intentionnelles) ou contenant des données malveillantes / indésirables.
Catégories de troisième niveau : Spam, Phishing.
Types de sources d'événements : serveurs proxy avec contrôle de contenu (Microsoft Threat Management Gateway), outils de protection du trafic Web (Cisco Web Security Appliance, lame de filtrage Check Point URL), outils de protection du courrier (Cisco Email Security Appliance, Kaspersky Secure Mail Gateway), Sécurité de l'hôte final avec des modules de contrôle Web et de messagerie intégrés (McAfee Internet Security, Kaspersky Internet Security). - Collecte d'informations - collecte de données sur l'objet de la protection contre les sources d'information ouvertes et fermées, en utilisant des méthodes de collecte actives et passives.
Catégories de troisième niveau : empreinte digitale, reniflement, numérisation, Bruteforce.
Types de sources d'événements : en règle générale, fonctionnalités de sécurité réseau, à savoir: pare-feu (Cisco Adaptive Security Appliance, lame Checkpoint Firewall), outils de détection et de prévention des intrusions (Cisco Firepower Next-Generation IPS, lame Check Point IPS). - Disponibilité - une violation malveillante ou accidentelle de la disponibilité des services et systèmes individuels en général.
Catégories de troisième niveau : DDoS, DoS, Flood.
Types de sources d'événements : pare-feu et systèmes de détection et de prévention des intrusions, ainsi que des systèmes de détection et de blocage des attaques DoS réseau (Arbor Pravail APS, Arbour Peakflow SP, Radware DefensePro, IFI Soft APK «Perimeter»). - Exploration des vulnérabilités - Identifie une vulnérabilité ou un groupe de vulnérabilités. Il est important de noter que cette catégorie décrit les événements de sécurité des informations concernant la détection de vulnérabilité, mais pas son fonctionnement.
Catégories de troisième niveau : Firmware, Software.
Types de sources d' événements: événements du SIEM intégré ou du scanner d'audit et de sécurité externe intégré (Tenable Nessus Vulnerability Scanner, Positive Technologies Maxpatrol 8, Positive Technologies XSpider, Qualys Vulnerability Scanner, Burp Suit). - Exploitation de la vulnérabilité (exploitation de la vulnérabilité) - identification de l'impact négatif délibéré sur le système ou exploitation de la vulnérabilité du système. Dans ce cas, les catégories de troisième niveau peuvent souvent inclure des techniques d'attaque individuelles répertoriées dans MITRE ATT & CK (lien) et définies par des fonctions de sécurité.
Catégories de troisième niveau : entités externes XML, script intersite, désérialisation non sécurisée, empoisonnement du routage, etc.
Types de sources d'événements : systèmes de détection et de prévention des intrusions au niveau du réseau (Positive Technologies Network Attack Discovery, Positive Technologies Web Application Firewall, Imperva Web Application Firewall, Cisco Firepower Next Generation IPS, Check Point IPS blade)) ou au niveau de l'hôte (Carbon Black Cb Defense, Modules de protection antivirus HIPS, OSSEC). - Hacktool (hacking utilities): utilisation d'utilitaires utilisés pour pirater des systèmes ou mettre en œuvre d'autres actions illégales pour obtenir des informations confidentielles et contourner les outils de sécurité.
Catégories de troisième niveau : Scanner, Bruteforcer, Exploit Kit, Password dumper, Vulnerability scanner, TOR client, Sniffer, Shellcode, Keylogger.
Types de sources d'événements : systèmes de détection et de prévention des intrusions au niveau du réseau et au niveau de l'hôte, scanners de sécurité et d'audit, outils de protection antivirus. - Code malveillant - Détecte l'utilisation de code malveillant.
Catégories de troisième niveau : Virus, Ver, Botnet, Rootkit, Bootkit, Trojan, Backdoor, Cryptor.
Types de sources d'événements : tous les outils de protection antivirus du réseau et de l'hôte, systèmes de détection et de prévention des intrusions au niveau du réseau. - Conformité (violation de la conformité) - l'identification des faits de non-conformité aux contrôles définis dans les politiques de conformité. Dans ce cas, les politiques de conformité signifient les exigences PCI DSS, la commande FSTEC n ° 21 et les normes de sécurité de l'entreprise.
Catégories de troisième niveau : contrôle d'intégrité, contrôle des paramètres du système d'exploitation, contrôle des paramètres de l'application.
Types de sources d'événements : scanners de sécurité et d'audit. - Fuite d'informations - fuite de données confidentielles via n'importe quel canal de communication.
Catégories de troisième niveau : e-mail, Messenger, réseau social, appareil mobile, stockage amovible.
Types de sources d'événements : systèmes de prévention des fuites de données (Rostelecom - Solar Dozor, InfoWatch Traffic Monitor). - Anomalie (anomalies) - une déviation significative des paramètres de l'objet de protection ou de son comportement par rapport à la norme précédemment établie.
Catégories de troisième niveau : statistiques, comportementales.
Types de sources d'événements : outils de protection réseau de nouvelle génération, systèmes de prévention des fuites de données, systèmes de classe d'analyse du comportement des utilisateurs et des entités (Splunk User Behavior Analytics, Securonix User and Entity Behavior Analytics, Exabeam Advanced Analytics).
 Système de catégorisation des événements IB. Violations du niveau de l'environnement physique.
Système de catégorisation des événements IB. Violations du niveau de l'environnement physique.Les violations de l'environnement physique, importantes du point de vue de la sécurité de l'information, ont leur propre "branche" distincte dans le système de catégorisation. Il est important que dans ce cas le système de catégorisation ne comporte qu'un seul niveau.
Une telle représentation «tronquée» du système de catégorisation est principalement due à des cas extrêmement rares d'intégration de SIEM avec des équipements de sécurité physique. Les exceptions sont les systèmes de contrôle d'accès et de comptabilité (ACS), qui sont souvent connectés au SIEM. Sinon, lors de la compilation de cette «branche» du système de catégorisation, nous n'avions pas suffisamment de données statistiques pour systématiser cette direction particulière.
- Vol (vol) - vol de supports physiques ou d'appareils informatiques (ordinateurs portables, tablettes, smartphones) contenant des informations confidentielles sur le territoire de l'entreprise ou des employés de l'entreprise.
Types de sources d'événements : bases d'incidents des services de sécurité physique, systèmes du personnel. - Intrusion (pénétration physique) - contournement non autorisé ou non réglementé du système de protection physique.
Types de sources d'événements : bases d'incidents des services de sécurité physique, ACS, systèmes de sécurité de périmètre. - Dommages (dommages) - dommages ciblés, destruction, réduction de la durée de vie de l'équipement ou des canaux de communication.
Types de sources d'événements : base de données des incidents de sécurité physique.
Exemples d'utilisation de systèmes de catégorisation
Nous appliquons le système de catégorisation décrit pour écrire des règles de corrélation de haut niveau et rechercher des événements dans le processus d'enquête. Considérez deux situations.
Situation 1 : au moyen de la règle de corrélation, il est nécessaire d'identifier une fuite d'informations confidentielles due au piratage des actifs du système automatisé. SIEM reçoit des événements des fonctionnalités de sécurité suivantes:
- systèmes de prévention des fuites de données;
- systèmes de détection et de prévention des intrusions au niveau du réseau;
- systèmes de détection et de prévention des intrusions au niveau de l'hôte;
- outil de protection antivirus.
Chacun d'eux génère des événements IB, après normalisation dans les
champs Level1 ,
Level2 ,
Level3 dont les catégories sont apposées.
Le texte de la règle de corrélation en pseudo-code peut ressembler à ceci:
# . «Host_poisoning event Host_poisoning»: # , group by dst.host # hostname/fqdn/ip , filter { Level2 = “Malicious Code” OR Level2 = “Vulnerability Exploitation” } # : event Data_leak: group by dst.host filter { Level2 = “Information Leak” AND Level3 = “Email” # } # Host_poisoning_and_data_leakage: «Host_poisoning», «Data_leak» 24 : rule Host_poisoning_and_data_leakage: (Host_poisoning —> Data_leak) within 24h emit { # — }
Situation 2: nous enquêtons sur l'incident sur un hôte spécifique - alexhost.company.local. Vous devez comprendre ce qui lui est arrivé entre 04h00 et 06h00 le 11/08/2018. Pendant ce temps, il y a environ 21,6 millions d'événements de cet hôte dans le SIEM lui-même (le flux d'événements moyen est de 3000 EPS). Il est maintenant 11h00 le 09/09/2018, tous les événements sont dans la base de données SIEM, au moment de l'incident, aucune règle de corrélation n'a été établie dans SIEM.
De toute évidence, l'analyse manuelle de tous les événements est une mauvaise idée. Il faut en quelque sorte réduire leur volume et localiser le problème. Essayons de rechercher des événements qui nous intéressent dans cet ensemble. Un exemple de requête utilisera une syntaxe de type SQL.
- Nous apprenons que nous avons «vu» des remèdes à ce moment:
Select * from events where Level1 in (“Host violations”, “Network violations”, “Physical violations”) and dst.dost=“alexhost.company.local” and time between (< >)
Supposons que nous ayons reçu 10 000 événements de domaines de violations d'hôte et de violations de réseau pour cette demande. Quoi qu'il en soit, beaucoup, pour une analyse manuelle. - Essayons de comprendre si l'hôte aurait pu être piraté pendant l'incident, et peu importe pour nous quel type de protection cela signifie.
Select * from events where Level2 in (“Vulnerability Exploitation”) and dst.dost=“alexhost.company.local” and time between (< >)
Supposons que nous ayons reçu 500 événements pour cette demande des systèmes de détection et de prévention des intrusions au niveau du réseau et de l'hôte. Super! Vous pouvez déjà travailler avec cela manuellement. - Au cours de l'enquête, nous avons réalisé que le piratage avait eu lieu au sein de l'entreprise. Nous essaierons de savoir si l'un des outils de protection a «vu» l'installation ou l'exécution d'outils de piratage sur l'un des hôtes de l'entreprise.
Select * from events where Level3 = “Exploit kit” and time between (< 3 >)
Conclusions
Nous avons décrit les principes de construction d'un système de catégorisation des événements et mis en avant les
exigences qui ont déterminé les approches et les principes de sa formation. Sur la base des spécificités des sources d'événements liées au SIEM, le système de catégorisation a été divisé en deux domaines: la catégorisation des événements à partir de sources informatiques et la catégorisation des événements à partir de sources d'informations.
Le système de catégorisation des événements informatiques a été formé sur la base des principes suivants:
- Les événements informatiques reflètent les étapes ou les détails des processus informatiques pris en charge ou mis en œuvre par les sources d'événements.
- Le système de catégorisation se compose de 3 niveaux principaux et d'un niveau supplémentaire qui détermine le succès ou l'échec de l'action décrite dans l'événement.
- Au premier niveau, on distingue les processus informatiques au sein desquels opère la source des événements.
- Le deuxième niveau décrit les entités de base impliquées dans ce processus.
- Le troisième niveau détermine quelles actions sont effectuées par telle ou telle entité dans le processus.
- Un niveau supplémentaire décrit le statut de ces actions (succès, échec).
Le système de catégorisation des événements de l'IB est basé sur les principes suivants:
- La catégorisation s'applique exclusivement aux événements de sécurité des informations collectés à partir des équipements de sécurité et n'affecte pas la catégorisation des attaques contre les systèmes automatisés. Des différences entre les attaques et les événements de sécurité de l'information ont été données au début de l'article.
- Le système de catégorisation se compose de 3 niveaux.
- Au premier niveau, des domaines sont identifiés dans lesquels des violations de SI peuvent être enregistrées: violations du niveau d'hôte, du réseau et de l'environnement physique.
- Le deuxième niveau de catégorisation est formé par des classes spécifiques de violations.
- , .
.

. , . , , .
Série d'articles:Profondeurs SIEM: corrélations prêtes à l'emploi. Partie 1: Marketing pur ou problème insoluble?Profondeurs SIEM: corrélations prêtes à l'emploi. Partie 2. Le schéma de données comme reflet du modèle «monde»Profondeurs SIEM: corrélations prêtes à l'emploi. 3.1. (
)
Profondeurs SIEM: corrélations prêtes à l'emploi. 3.2.Profondeurs SIEM: corrélations prêtes à l'emploi. Partie 4. Modèle de système comme contexte de règles de corrélationProfondeurs SIEM: corrélations prêtes à l'emploi. Partie 5. Méthodologie pour développer des règles de corrélation