
DeepMind crée des algorithmes vraiment incroyables qui sont capables de ce que les systèmes de machine ne pouvaient pas réaliser auparavant. En particulier, le réseau neuronal
AlphaGo a pu battre les meilleurs joueurs du monde. Selon les experts, les capacités du système ont désormais tellement augmenté qu'il n'est même plus logique d'essayer de le vaincre - le résultat est prédéterminé.
Néanmoins, l'entreprise ne s'arrête pas là, mais continue de fonctionner. Grâce à la recherche de ses employés,
une version améliorée d'AlphaGo, appelée AlphaZero, est née. Comme indiqué dans le titre, le système lui-même a pu apprendre à jouer à trois jeux logiques à la fois: les échecs, le shogi et le go.
La différence entre la nouvelle version et toutes les précédentes
était que le système lui-même apprenait presque tout. Elle est partie de zéro et a rapidement appris à jouer parfaitement les trois matchs. Personne n'a aidé AlphaZero - le système "a tout compris".
Les échecs étaient inclus dans le jeu, plutôt, selon la tradition - ce n'est rien de difficile d'apprendre à un ordinateur à jouer aux échecs, non. Pour la première fois, un système informatique a été introduit dans le jeu dans les années 1950. Puis, déjà dans les années 60, le programme
Mac Hack IV a été créé, qui a commencé à battre les rivaux humains. Au fil du temps, les programmes d'échecs se sont progressivement améliorés et en 1997, IBM a développé «l'ordinateur d'échecs» Deep Blue, qui a réussi à battre Grandmaster et champion du monde Garry Kasparov.
Comme il le souligne lui-même, à l'heure actuelle, de nombreuses applications sur un smartphone jouent mieux aux échecs que Deep Blue. Ayant atteint la perfection dans la création de systèmes capables de jouer aux échecs, les développeurs ont commencé à créer de nouvelles versions de rivaux informatiques humains - en particulier, ils ont réussi à enseigner à l'ordinateur à jouer au go. Auparavant, ce jeu avec une histoire millénaire était considéré comme l'un des plus inaccessibles à la "compréhension" de l'ordinateur. Mais les temps ont changé. Comme mentionné ci-dessus, AlphaGo a atteint un niveau si élevé de maîtrise du jeu de go qu'une personne ne se tenait pas à proximité.
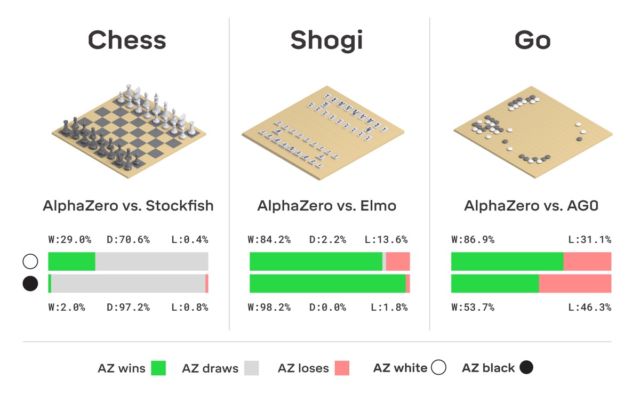
Soit dit en passant, AlphaGo a reçu cette année une mise à jour, grâce à laquelle le réseau de neurones peut désormais apprendre diverses stratégies pour jouer sans intervention humaine. Jouant avec lui-même encore et encore, AlphaGo s'améliore. C'est ce type de système d'entraînement que le «descendant» d'AlphaGo utilise - le réseau neuronal AlphaZero. En seulement trois jours, elle a atteint un tel niveau de maîtrise en Go qu'elle a battu la version originale d'AlphaGo avec un score de 100 à 0. La seule chose que le système reçoit initialement est les règles du jeu.
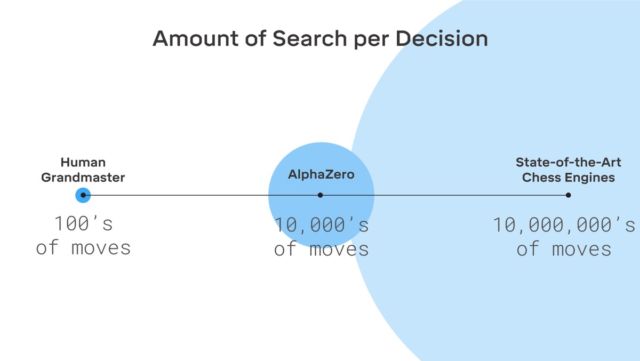
Il n'y a pas de fiction ici, DeepMind utilise le système bien connu de machine learning de renforcement. L'ordinateur cherche à gagner, car pour chaque victoire reçoit une récompense (points). De plus, AlphaZero perd des millions de combinaisons dans le processus d'apprentissage. AlphaZero ne passe que 0,4 seconde pour mal calculer le prochain coup et évaluer la probabilité de gagner. Quant à l'AlphaGo de la version originale, le réseau neuronal était composé de deux éléments, deux réseaux neuronaux - l'un a déterminé le prochain mouvement possible et le second a calculé les probabilités.
Pour atteindre le niveau maître dans Go AlphaZero, vous devez «faire défiler» environ 4,5 millions de jeux lorsque vous jouez avec vous-même. Mais AlphaGo a nécessité 30 millions de jeux.
Il convient de noter qu'AlphaZero a été créé spécifiquement pour jouer au go. L'entreprise n'a pas oublié cela. Mais en plus d'aller, le système est capable d'apprendre et de deux autres jeux, qui ont été mentionnés ci-dessus. Le système utilisé est le même: l'apprentissage automatique avec renforcement. Il est à noter qu'AlphaZero ne fonctionne qu'avec des tâches comportant un certain nombre de solutions. Le système a également besoin d'un modèle d'environnement (virtuel).
Fait intéressant, Kasparov lui-même pense qu'une personne peut obtenir beaucoup de systèmes comme AlphaGo - vous pouvez en apprendre beaucoup.
Actuellement, les développeurs sont confrontés à la tâche d'enseigner à un ordinateur à jouer au poker mieux que n'importe qui, et également à créer un système qui peut battre n'importe quel esportiste dans un combat loyal. En tout cas, il est clair que les réseaux de neurones et l'IA sont capables de beaucoup.