
Dans un article précédent, nous avons mis à l'échelle l'ensemble de répliques MongoDB et introduit StatefulSet. Nous allons maintenant prendre en charge l'orchestration du cluster haute disponibilité Elasticsearch (avec d'autres nœuds maîtres, nœuds de données et nœuds clients) et utiliser ES-HQ et Kibana.
Vous aurez besoin de:
- Une compréhension de base d'Elasticsearch, de ses types de nœuds et de leurs rôles.
- Un cluster Kubernetes fonctionnel avec au moins trois nœuds (au moins quatre cœurs, 4 Go).
- Capacité à travailler avec Kibana.
Architecture de déploiement
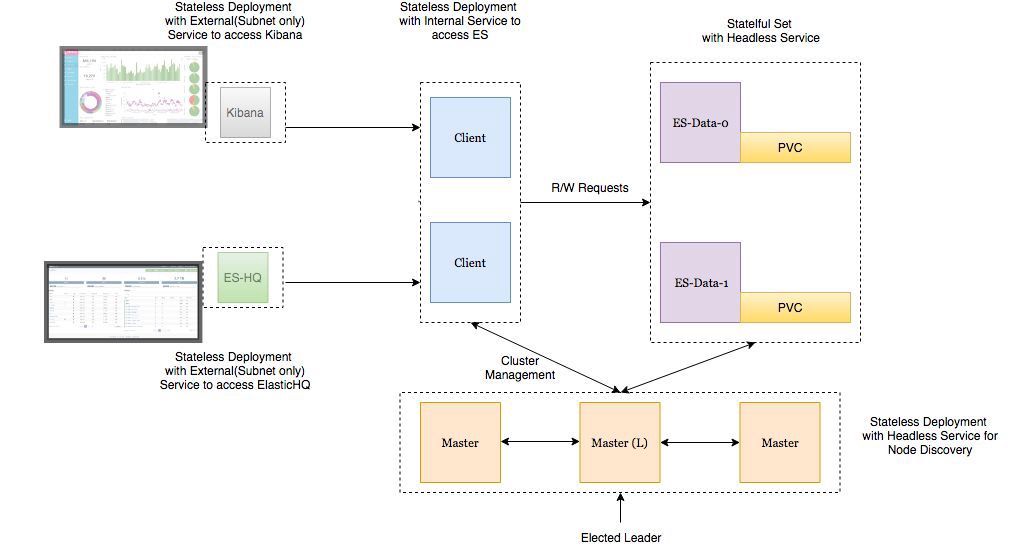
- Les nœuds de données Elasticsearch sont déployés en tant que StatefulSet avec un service sans tête afin que nous ayons des identifiants de réseau stables .
- Les masternodes Elasticsearch sont déployés en tant que ReplicaSet avec un service sans tête. C'est pour la découverte automatique .
- Les pods sur les nœuds clients Elasticsearch sont déployés en tant que ReplicaSet avec un service interne afin que vous puissiez envoyer des demandes de lecture / écriture aux nœuds de données.
- Les modules Kibana et ElasticHQ sont déployés en tant que ReplicaSet avec des services disponibles en dehors du cluster Kubernetes , mais situés à l'intérieur du sous-réseau (ils ne s'ouvrent pas vers l'extérieur sauf si nécessaire).
- HPA (Horizonal Pod Autoscaler) est déployé pour les nœuds clients et est responsable de l'autoscaling horizontal à haute charge.
"N'oubliez pas de configurer l'environnement:
- Variable ES_JAVA_OPTS .
- Variable CLUSTER_NAME .
- La variable NUMBER_OF_MASTERS pour le déploiement des maîtres afin d'éviter la situation de split-brain. Si nous avons 3 maîtres, spécifiez 2.
- Règles anti-affinité pour des foyers similaires afin d'assurer une haute fiabilité en cas de chute du nœud de travail.
"
Déployons ces services dans le cluster GKE.
kind: Namespace metadata: name: elasticsearch --- apiVersion: apps/v1beta1 kind: Deployment metadata: name: es-master namespace: elasticsearch labels: component: elasticsearch role: master spec: replicas: 3 template: metadata: labels: component: elasticsearch role: master spec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 podAffinityTerm: labelSelector: matchExpressions: - key: role operator: In values: - master topologyKey: kubernetes.io/hostname initContainers: - name: init-sysctl image: busybox:1.27.2 command: - sysctl - -w - vm.max_map_count=262144 securityContext: privileged: true containers: - name: es-master image: quay.io/pires/docker-elasticsearch-kubernetes:6.2.4 env: - name: NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: NODE_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: CLUSTER_NAME value: my-es - name: NUMBER_OF_MASTERS value: "2" - name: NODE_MASTER value: "true" - name: NODE_INGEST value: "false" - name: NODE_DATA value: "false" - name: HTTP_ENABLE value: "false" - name: ES_JAVA_OPTS value: -Xms256m -Xmx256m - name: PROCESSORS valueFrom: resourceFieldRef: resource: limits.cpu resources: limits: cpu: 2 ports: - containerPort: 9300 name: transport volumeMounts: - name: storage mountPath: /data volumes: - emptyDir: medium: "" name: "storage" --- apiVersion: v1 kind: Service metadata: name: elasticsearch-discovery namespace: elasticsearch labels: component: elasticsearch role: master spec: selector: component: elasticsearch role: master ports: - name: transport port: 9300 protocol: TCP clusterIP: None view rawes-master.yml hosted with love by GitHub
(Déploiement et service sans tête pour les nœuds maîtres)
root$ kubectl -n elasticsearch get all NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE deploy/es-master 3 3 3 3 32s NAME DESIRED CURRENT READY AGE rs/es-master-594b58b86c 3 3 3 31s NAME READY STATUS RESTARTS AGE po/es-master-594b58b86c-9jkj2 1/1 Running 0 31s po/es-master-594b58b86c-bj7g7 1/1 Running 0 31s po/es-master-594b58b86c-lfpps 1/1 Running 0 31s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc/elasticsearch-discovery ClusterIP None <none> 9300/TCP 31s
Il est intéressant d'étudier les journaux des foyers sur les nœuds maîtres et de voir comment le maître est sélectionné parmi eux maintenant et comment ce sera plus tard lorsque nous ajouterons de nouveaux nœuds de données et des nœuds clients.
root$ kubectl -n elasticsearch logs -f po/es-master-594b58b86c-9jkj2 | grep ClusterApplierService [2018-10-21T07:41:54,958][INFO ][oecsClusterApplierService] [es-master-594b58b86c-9jkj2] detected_master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300}, added {{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300},{es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [3]])
Ici, vous pouvez voir que sous es-master avec le nom es-master-594b58b86c-bj7g7 est sélectionné par le maître, et les deux autres pods y sont ajoutés et l'un à l'autre.
Le service sans recherche elasticsearch-discovery est installé par défaut dans l'image Docker en tant que variable d'environnement et est utilisé pour la détection dans les nœuds. Ce paramètre peut être remplacé si vous le souhaitez.
De même, nous déployons des nœuds de données et des nœuds clients . Voir les configurations ci-dessous.
Déployer le nœud de données:
kind: Namespace metadata: name: elasticsearch --- apiVersion: storage.k8s.io/v1beta1 kind: StorageClass metadata: name: fast provisioner: kubernetes.io/gce-pd parameters: type: pd-ssd fsType: xfs allowVolumeExpansion: true --- apiVersion: apps/v1beta1 kind: StatefulSet metadata: name: es-data namespace: elasticsearch labels: component: elasticsearch role: data spec: serviceName: elasticsearch-data replicas: 3 template: metadata: labels: component: elasticsearch role: data spec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 podAffinityTerm: labelSelector: matchExpressions: - key: role operator: In values: - data topologyKey: kubernetes.io/hostname initContainers: - name: init-sysctl image: busybox:1.27.2 command: - sysctl - -w - vm.max_map_count=262144 securityContext: privileged: true containers: - name: es-data image: quay.io/pires/docker-elasticsearch-kubernetes:6.2.4 env: - name: NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: NODE_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: CLUSTER_NAME value: my-es - name: NODE_MASTER value: "false" - name: NODE_INGEST value: "false" - name: HTTP_ENABLE value: "false" - name: ES_JAVA_OPTS value: -Xms256m -Xmx256m - name: PROCESSORS valueFrom: resourceFieldRef: resource: limits.cpu resources: limits: cpu: 2 ports: - containerPort: 9300 name: transport volumeMounts: - name: storage mountPath: /data volumeClaimTemplates: - metadata: name: storage annotations: volume.beta.kubernetes.io/storage-class: "fast" spec: accessModes: [ "ReadWriteOnce" ] storageClassName: fast resources: requests: storage: 10Gi --- apiVersion: v1 kind: Service metadata: name: elasticsearch-data namespace: elasticsearch labels: component: elasticsearch role: data spec: ports: - port: 9300 name: transport clusterIP: None selector: component: elasticsearch role: data view rawes-data.yml hosted with love by GitHub
(StatefulSet et service sans tête pour les nœuds de données)
Le service sans tête sur les nœuds de données délivre des identifiants de réseau stables aux nœuds et facilite le transfert de données entre les nœuds.
Il est important de formater le volume permanent avant de le fixer au foyer. Spécifiez simplement le type de volume lorsque vous créez la classe de stockage. Vous pouvez également définir un paramètre permettant l'expansion automatique du volume . Lisez les détails ici .
parameters: type: pd-ssd fsType: xfs allowVolumeExpansion: true ...
Déployer des nœuds clients:
kind: Namespace metadata: name: elasticsearch --- apiVersion: apps/v1beta1 kind: Deployment metadata: name: es-client namespace: elasticsearch labels: component: elasticsearch role: client spec: replicas: 2 template: metadata: labels: component: elasticsearch role: client spec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 podAffinityTerm: labelSelector: matchExpressions: - key: role operator: In values: - client topologyKey: kubernetes.io/hostname initContainers: - name: init-sysctl image: busybox:1.27.2 command: - sysctl - -w - vm.max_map_count=262144 securityContext: privileged: true containers: - name: es-client image: quay.io/pires/docker-elasticsearch-kubernetes:6.2.4 env: - name: NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: NODE_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: CLUSTER_NAME value: my-es - name: NODE_MASTER value: "false" - name: NODE_DATA value: "false" - name: HTTP_ENABLE value: "true" - name: ES_JAVA_OPTS value: -Xms256m -Xmx256m - name: NETWORK_HOST value: _site_,_lo_ - name: PROCESSORS valueFrom: resourceFieldRef: resource: limits.cpu resources: limits: cpu: 1 ports: - containerPort: 9200 name: http - containerPort: 9300 name: transport volumeMounts: - name: storage mountPath: /data volumes: - emptyDir: medium: "" name: storage --- apiVersion: v1 kind: Service metadata: name: elasticsearch namespace: elasticsearch annotations: cloud.google.com/load-balancer-type: Internal labels: component: elasticsearch role: client spec: selector: component: elasticsearch role: client ports: - name: http port: 9200 type: LoadBalancer view rawes-client.yml hosted with love by GitHub
(Déployer et service externe pour les nœuds clients)
Le service déployé ici permet d'accéder au cluster ES en dehors du cluster Kubernetes, mais se trouve toujours à l'intérieur du sous-réseau. L'annotation cloud.google.com/load-balancer-type: Internal est responsable de cela.
Mais si l'application qui accède au cluster ES pour la lecture et l'écriture est déployée à l'intérieur du cluster, l'accès au service ElasticSearch peut être obtenu à l' adresse http: //elasticsearch.elasticsearch: 9200 .
Lorsque vous développez les nœuds de données et les nœuds clients, ils seront automatiquement ajoutés au cluster. (Cherchez le maître sous les journaux)
root$ kubectl -n elasticsearch get pods -l role=data NAME READY STATUS RESTARTS AGE es-data-0 1/1 Running 0 48s es-data-1 1/1 Running 0 28s -------------------------------------------------------------------- root$ kubectl apply -f es-client.yml root$ kubectl -n elasticsearch get pods -l role=client NAME READY STATUS RESTARTS AGE es-client-69b84b46d8-kr7j4 1/1 Running 0 47s es-client-69b84b46d8-v5pj2 1/1 Running 0 47s -------------------------------------------------------------------- root$ kubectl -n elasticsearch get all NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE deploy/es-client 2 2 2 2 1m deploy/es-master 3 3 3 3 9m NAME DESIRED CURRENT READY AGE rs/es-client-69b84b46d8 2 2 2 1m rs/es-master-594b58b86c 3 3 3 9m NAME DESIRED CURRENT AGE statefulsets/es-data 2 2 3m NAME READY STATUS RESTARTS AGE po/es-client-69b84b46d8-kr7j4 1/1 Running 0 1m po/es-client-69b84b46d8-v5pj2 1/1 Running 0 1m po/es-data-0 1/1 Running 0 3m po/es-data-1 1/1 Running 0 3m po/es-master-594b58b86c-9jkj2 1/1 Running 0 9m po/es-master-594b58b86c-bj7g7 1/1 Running 0 9m po/es-master-594b58b86c-lfpps 1/1 Running 0 9m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc/elasticsearch LoadBalancer 10.9.121.160 10.9.120.8 9200:32310/TCP 1m svc/elasticsearch-data ClusterIP None <none> 9300/TCP 3m svc/elasticsearch-discovery ClusterIP None <none> 9300/TCP 9m -------------------------------------------------------------------- #Check logs of es-master leader pod root$ kubectl -n elasticsearch logs po/es-master-594b58b86c-bj7g7 | grep ClusterApplierService [2018-10-21T07:41:53,731][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] new_master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300}, added {{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [1] source [zen-disco-elected-as-master ([1] nodes joined)[{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300}]]]) [2018-10-21T07:41:55,162][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-master-594b58b86c-9jkj2}{x9Prp1VbTq6_kALQVNwIWg}{7NHUSVpuS0mFDTXzAeKRcg}{10.9.125.81}{10.9.125.81:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [3] source [zen-disco-node-join[{es-master-594b58b86c-9jkj2}{x9Prp1VbTq6_kALQVNwIWg}{7NHUSVpuS0mFDTXzAeKRcg}{10.9.125.81}{10.9.125.81:9300}]]]) [2018-10-21T07:48:02,485][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-data-0}{SAOhUiLiRkazskZ_TC6EBQ}{qirmfVJBTjSBQtHZnz-QZw}{10.9.126.88}{10.9.126.88:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [4] source [zen-disco-node-join[{es-data-0}{SAOhUiLiRkazskZ_TC6EBQ}{qirmfVJBTjSBQtHZnz-QZw}{10.9.126.88}{10.9.126.88:9300}]]]) [2018-10-21T07:48:21,984][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-data-1}{fiv5Wh29TRWGPumm5ypJfA}{EXqKGSzIQquRyWRzxIOWhQ}{10.9.125.82}{10.9.125.82:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [5] source [zen-disco-node-join[{es-data-1}{fiv5Wh29TRWGPumm5ypJfA}{EXqKGSzIQquRyWRzxIOWhQ}{10.9.125.82}{10.9.125.82:9300}]]]) [2018-10-21T07:50:51,245][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-client-69b84b46d8-v5pj2}{MMjA_tlTS7ux-UW44i0osg}{rOE4nB_jSmaIQVDZCjP8Rg}{10.9.125.83}{10.9.125.83:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [6] source [zen-disco-node-join[{es-client-69b84b46d8-v5pj2}{MMjA_tlTS7ux-UW44i0osg}{rOE4nB_jSmaIQVDZCjP8Rg}{10.9.125.83}{10.9.125.83:9300}]]]) [2018-10-21T07:50:58,964][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-client-69b84b46d8-kr7j4}{gGC7F4diRWy2oM1TLTvNsg}{IgI6g3iZT5Sa0HsFVMpvvw}{10.9.124.82}{10.9.124.82:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [7] source [zen-disco-node-join[{es-client-69b84b46d8-kr7j4}{gGC7F4diRWy2oM1TLTvNsg}{IgI6g3iZT5Sa0HsFVMpvvw}{10.9.124.82}{10.9.124.82:9300}]]]) ] [es maître-594b58b86c-bj7g7] ajouté {{es-master-594b58b86c-9jkj2} {} {x9Prp1VbTq6_kALQVNwIWg 7NHUSVpuS0mFDTXzAeKRcg} {} {10.9.125.81 10.9 root$ kubectl -n elasticsearch get pods -l role=data NAME READY STATUS RESTARTS AGE es-data-0 1/1 Running 0 48s es-data-1 1/1 Running 0 28s -------------------------------------------------------------------- root$ kubectl apply -f es-client.yml root$ kubectl -n elasticsearch get pods -l role=client NAME READY STATUS RESTARTS AGE es-client-69b84b46d8-kr7j4 1/1 Running 0 47s es-client-69b84b46d8-v5pj2 1/1 Running 0 47s -------------------------------------------------------------------- root$ kubectl -n elasticsearch get all NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE deploy/es-client 2 2 2 2 1m deploy/es-master 3 3 3 3 9m NAME DESIRED CURRENT READY AGE rs/es-client-69b84b46d8 2 2 2 1m rs/es-master-594b58b86c 3 3 3 9m NAME DESIRED CURRENT AGE statefulsets/es-data 2 2 3m NAME READY STATUS RESTARTS AGE po/es-client-69b84b46d8-kr7j4 1/1 Running 0 1m po/es-client-69b84b46d8-v5pj2 1/1 Running 0 1m po/es-data-0 1/1 Running 0 3m po/es-data-1 1/1 Running 0 3m po/es-master-594b58b86c-9jkj2 1/1 Running 0 9m po/es-master-594b58b86c-bj7g7 1/1 Running 0 9m po/es-master-594b58b86c-lfpps 1/1 Running 0 9m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc/elasticsearch LoadBalancer 10.9.121.160 10.9.120.8 9200:32310/TCP 1m svc/elasticsearch-data ClusterIP None <none> 9300/TCP 3m svc/elasticsearch-discovery ClusterIP None <none> 9300/TCP 9m -------------------------------------------------------------------- #Check logs of es-master leader pod root$ kubectl -n elasticsearch logs po/es-master-594b58b86c-bj7g7 | grep ClusterApplierService [2018-10-21T07:41:53,731][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] new_master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300}, added {{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [1] source [zen-disco-elected-as-master ([1] nodes joined)[{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300}]]]) [2018-10-21T07:41:55,162][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-master-594b58b86c-9jkj2}{x9Prp1VbTq6_kALQVNwIWg}{7NHUSVpuS0mFDTXzAeKRcg}{10.9.125.81}{10.9.125.81:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [3] source [zen-disco-node-join[{es-master-594b58b86c-9jkj2}{x9Prp1VbTq6_kALQVNwIWg}{7NHUSVpuS0mFDTXzAeKRcg}{10.9.125.81}{10.9.125.81:9300}]]]) [2018-10-21T07:48:02,485][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-data-0}{SAOhUiLiRkazskZ_TC6EBQ}{qirmfVJBTjSBQtHZnz-QZw}{10.9.126.88}{10.9.126.88:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [4] source [zen-disco-node-join[{es-data-0}{SAOhUiLiRkazskZ_TC6EBQ}{qirmfVJBTjSBQtHZnz-QZw}{10.9.126.88}{10.9.126.88:9300}]]]) [2018-10-21T07:48:21,984][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-data-1}{fiv5Wh29TRWGPumm5ypJfA}{EXqKGSzIQquRyWRzxIOWhQ}{10.9.125.82}{10.9.125.82:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [5] source [zen-disco-node-join[{es-data-1}{fiv5Wh29TRWGPumm5ypJfA}{EXqKGSzIQquRyWRzxIOWhQ}{10.9.125.82}{10.9.125.82:9300}]]]) [2018-10-21T07:50:51,245][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-client-69b84b46d8-v5pj2}{MMjA_tlTS7ux-UW44i0osg}{rOE4nB_jSmaIQVDZCjP8Rg}{10.9.125.83}{10.9.125.83:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [6] source [zen-disco-node-join[{es-client-69b84b46d8-v5pj2}{MMjA_tlTS7ux-UW44i0osg}{rOE4nB_jSmaIQVDZCjP8Rg}{10.9.125.83}{10.9.125.83:9300}]]]) [2018-10-21T07:50:58,964][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-client-69b84b46d8-kr7j4}{gGC7F4diRWy2oM1TLTvNsg}{IgI6g3iZT5Sa0HsFVMpvvw}{10.9.124.82}{10.9.124.82:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [7] source [zen-disco-node-join[{es-client-69b84b46d8-kr7j4}{gGC7F4diRWy2oM1TLTvNsg}{IgI6g3iZT5Sa0HsFVMpvvw}{10.9.124.82}{10.9.124.82:9300}]]])
Les journaux du module principal principal indiquent clairement quand chaque nœud est ajouté au cluster. C'est utile de savoir lors du débogage.
Nous avons déployé tous les composants, et maintenant nous devons vérifier:
1) Déployez Elasticsearch à partir d'un cluster Kubernetes à l'aide d'un conteneur Ubuntu.
root$ kubectl run my-shell --rm -i --tty --image ubuntu -- bash root@my-shell-68974bb7f7-pj9x6:/# curl http://elasticsearch.elasticsearch:9200/_cluster/health?pretty { "cluster_name" : "my-es", "status" : "green", "timed_out" : false, "number_of_nodes" : 7, "number_of_data_nodes" : 2, "active_primary_shards" : 0, "active_shards" : 0, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 0, "delayed_unassigned_shards" : 0, "number_of_pending_tasks" : 0, "number_of_in_flight_fetch" : 0, "task_max_waiting_in_queue_millis" : 0, "active_shards_percent_as_number" : 100.0 }
2) Déployez Elasticsearch depuis l'extérieur du cluster via l'adresse IP du GCP de l'équilibreur interne (dans notre cas, 10.9.120.8 ).
root$ curl http://10.9.120.8:9200/_cluster/health?pretty { "cluster_name" : "my-es", "status" : "green", "timed_out" : false, "number_of_nodes" : 7, "number_of_data_nodes" : 2, "active_primary_shards" : 0, "active_shards" : 0, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 0, "delayed_unassigned_shards" : 0, "number_of_pending_tasks" : 0, "number_of_in_flight_fetch" : 0, "task_max_waiting_in_queue_millis" : 0, "active_shards_percent_as_number" : 100.0 }
3) Règles anti-affinité pour les foyers ES.
root$ kubectl -n elasticsearch get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE es-client-69b84b46d8-kr7j4 1/1 Running 0 10m 10.8.14.52 gke-cluster1-pool1-d2ef2b34-t6h9 es-client-69b84b46d8-v5pj2 1/1 Running 0 10m 10.8.15.53 gke-cluster1-pool1-42b4fbc4-cncn es-data-0 1/1 Running 0 12m 10.8.16.58 gke-cluster1-pool1-4cfd808c-kpx1 es-data-1 1/1 Running 0 12m 10.8.15.52 gke-cluster1-pool1-42b4fbc4-cncn es-master-594b58b86c-9jkj2 1/1 Running 0 18m 10.8.15.51 gke-cluster1-pool1-42b4fbc4-cncn es-master-594b58b86c-bj7g7 1/1 Running 0 18m 10.8.16.57 gke-cluster1-pool1-4cfd808c-kpx1 es-master-594b58b86c-lfpps 1/1 Running 0 18m 10.8.14.51 gke-cluster1-pool1-d2ef2b34-t6h9
Notez que nous n'avons pas deux foyers similaires sur le même nœud, nous avons donc assuré une grande fiabilité en cas de défaillance d'un nœud.
Mise à l'échelle
Nous pouvons déployer des services de mise à l'échelle automatique pour les nœuds clients en fonction de la limite du processeur. Exemple HPA pour un nœud client:
apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: es-client namespace: elasticsearch spec: maxReplicas: 5 minReplicas: 2 scaleTargetRef: apiVersion: extensions/v1beta1 kind: Deployment name: es-client targetCPUUtilizationPercentage: 80
La mise à l'échelle automatique ajoute des pods sur le nœud client au cluster, et cela peut être vu dans les journaux de n'importe quel pod sur le nœud maître.
Pour les pods sur les nœuds de données , il vous suffit d'augmenter le nombre de répliques dans le panneau de configuration Kubernetes ou dans la console GKE. Le nœud de données créé lui-même sera ajouté au cluster et commencera à répliquer les données des autres nœuds.
Je n'ai pas besoin de mise à l'échelle automatique sur les nœuds maîtres - ils ne stockent que des données sur l'état du cluster. Mais si vous comptez ajouter des nœuds de données, assurez-vous que le nombre de nœuds maîtres dans le cluster est impair , et n'oubliez pas de modifier la variable NUMBER_OF_MASTERS pour l'environnement.
Déployer Kibana et ES-HQ
Kibana et ES-HQ
Kibana est un outil simple pour visualiser les données ES, et ES-HQ aide à administrer et surveiller le cluster Elasticsearch. Lors du déploiement de Kibana et ES-HQ, n'oubliez pas que:
- Nous transmettons le nom du cluster ES à l'image Docker en tant que variable d'environnement.
- Le service d'accès au déploiement Kibana / ES-HQ reste au sein de l'entreprise, c'est-à-dire qu'aucune adresse IP publique n'est créée. Nous utilisons l'équilibreur de charge GCP interne.
Déployer Kibana
kind: Namespace metadata: name: elasticsearch --- apiVersion: apps/v1beta1 kind: Deployment metadata: name: es-kibana namespace: elasticsearch labels: component: elasticsearch role: kibana spec: replicas: 1 template: metadata: labels: component: elasticsearch role: kibana spec: containers: - name: es-kibana image: docker.elastic.co/kibana/kibana-oss:6.2.2 env: - name: CLUSTER_NAME value: my-es - name: ELASTICSEARCH_URL value: http://elasticsearch:9200 resources: limits: cpu: 0.5 ports: - containerPort: 5601 name: http --- apiVersion: v1 kind: Service metadata: name: kibana annotations: cloud.google.com/load-balancer-type: "Internal" namespace: elasticsearch labels: component: elasticsearch role: kibana spec: selector: component: elasticsearch role: kibana ports: - name: http port: 80 targetPort: 5601 protocol: TCP type: LoadBalancer view rawes-kibana.yml hosted with love by GitHub
(Déploiement et service Kibana)
Déployer ES-HQ
kind: Namespace metadata: name: elasticsearch --- apiVersion: apps/v1beta1 kind: Deployment metadata: name: es-hq namespace: elasticsearch labels: component: elasticsearch role: hq spec: replicas: 1 template: metadata: labels: component: elasticsearch role: hq spec: containers: - name: es-hq image: elastichq/elasticsearch-hq:release-v3.4.0 env: - name: HQ_DEFAULT_URL value: http://elasticsearch:9200 resources: limits: cpu: 0.5 ports: - containerPort: 5000 name: http --- apiVersion: v1 kind: Service metadata: name: hq annotations: cloud.google.com/load-balancer-type: "Internal" namespace: elasticsearch labels: component: elasticsearch role: hq spec: selector: component: elasticsearch role: hq ports: - name: http port: 80 targetPort: 5000 protocol: TCP type: LoadBalancer view rawes-hq.yml hosted with love by GitHub
(Déployer et service ES-HQ)
Nous accédons aux deux services via l'équilibreur interne créé.
root$ kubectl -n elasticsearch get svc -l role=kibana NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kibana LoadBalancer 10.9.121.246 10.9.120.10 80:31400/TCP 1m root$ kubectl -n elasticsearch get svc -l role=hq NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE hq LoadBalancer 10.9.121.150 10.9.120.9 80:31499/TCP 1m
http: // <External-Ip-Kibana-Service> / app / kibana # / home? _g = ()
(Panneau de configuration Kibana)
http: // <External-Ip-ES-Hq-Service> / #! / clusters / my-es
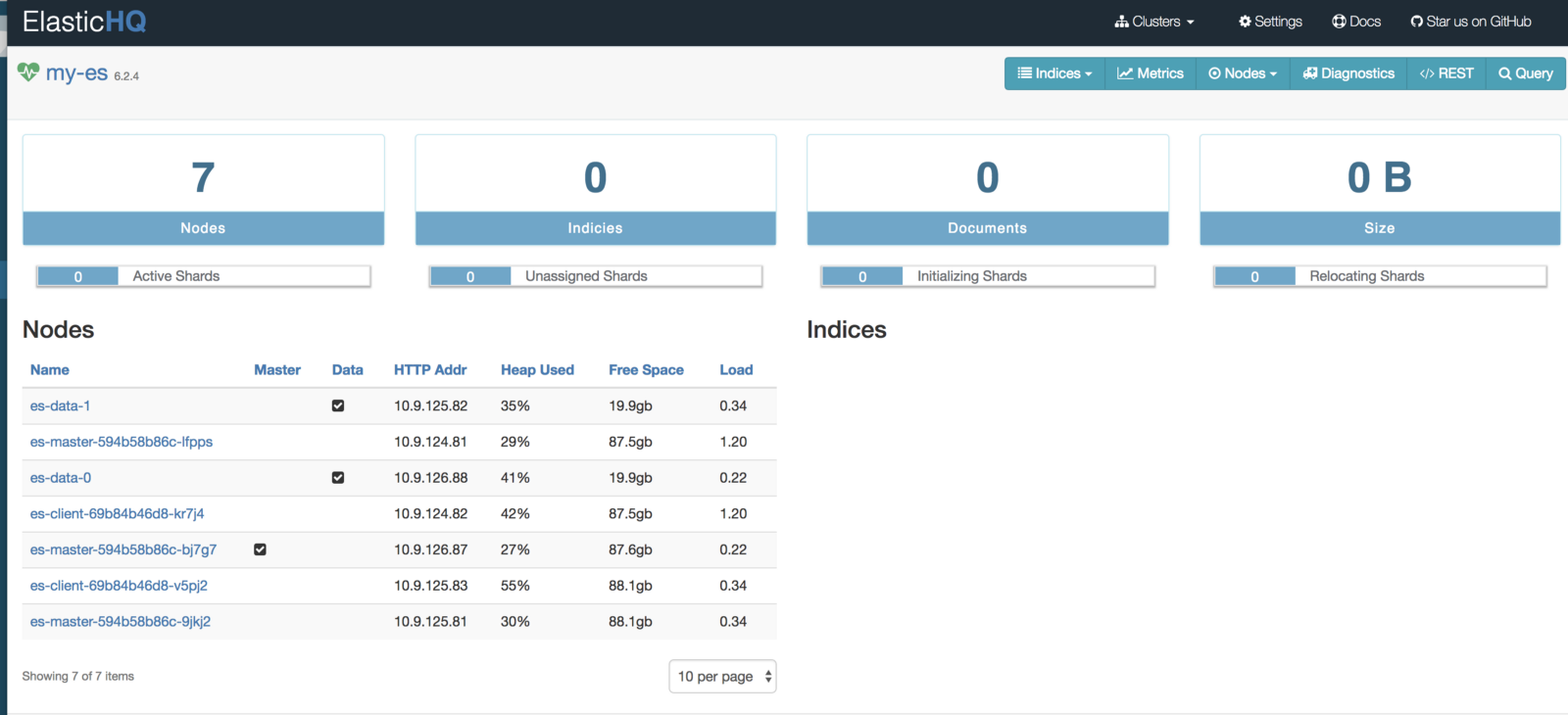
(Panneau de configuration ElasticHQ pour surveiller et gérer le cluster)
ES est l'un des systèmes de recherche et d'analyse distribués les plus populaires et, chez Kubernetes, il résout les problèmes clés de mise à l'échelle et de haute disponibilité. De plus, de nouveaux clusters ES dans Kubernetes sont déployés instantanément.