Hier, j'ai reçu une lettre d'une dixième niveleuse de Sibérie qui veut devenir développeur de microprocesseurs. Elle a déjà obtenu des résultats dans ce domaine - elle a ajouté l'instruction de multiplication au processeur schoolMIPS le plus simple, l'a synthétisé pour le FPGA Intel FPGA MAX10, a déterminé la fréquence maximale et la productivité accrue des programmes simples. Elle a d'abord fait tout cela dans le village de Burmistrovo, dans la région de Novossibirsk, puis lors d'une conférence à Tomsk.
Maintenant, Dasha Krivoruchko (c'est le nom de la dixième niveleuse) a déménagé dans un pensionnat de Moscou et me demande quoi d'autre elle devrait concevoir. Je pense qu'à ce stade de sa carrière, elle devrait concevoir un accélérateur matériel pour les réseaux de neurones basé sur un réseau systolique pour la multiplication matricielle. Utilisez le langage de description du matériel Verilog et Intel FPGA FPGA, mais pas le MAX10 bon marché, mais quelque chose de plus cher pour accueillir un grand réseau systolique.
Après cela, comparez les performances de la solution matérielle avec le programme exécuté sur le processeur schoolMIPS, ainsi qu'avec le programme Python exécuté sur l'ordinateur de bureau. Comme cas de test, utilisez la reconnaissance des nombres à partir d'une petite matrice.

En fait, toutes les parties de cet exercice ont déjà été développées par différentes personnes, mais le but est de mettre cela dans un seul exercice documenté, qui peut ensuite être utilisé comme base pour le cours en ligne et pour les compétitions pratiques:
1) eNano, le département pédagogique de RUSNANO, qui a organisé par le passé des séminaires Charles Danchek sur la conception de l'électronique moderne (itinéraire RTL-GDSII) pour les étudiants et travaille actuellement sur un cours en ligne de ce type (conception de matériel au niveau des transferts de registres + réseaux de neurones) est intéressé cours lite pour les étudiants avancés. Ici, Charles et moi sommes à leur bureau:

2) La base des Jeux Olympiques pourrait être intéressée par
les Jeux Olympiques NTI , avec lesquels j'ai soulevé cette question il y a quelques semaines à Moscou. Pour un tel exemple, les participants aux olympiades pourraient ajouter un matériel pour différentes fonctions d'activation. Voici des collègues des Jeux Olympiques NTI:

Donc, si Dasha développe cela, elle pourrait théoriquement introduire son accélérateur bien décrit à la fois à RUSNANO et à la NTI Olympiad. Je pense que cela serait bénéfique pour l'administration de son école - il pourrait être diffusé à la télévision ou envoyé au concours Intel FPGA en général. Voici
quelques Russes de Saint-Pétersbourg à la finale du concours Intel FPGA à Santa Clara, en Californie :

Parlons maintenant du côté technique du projet. L'idée de l'accélérateur de masse systolique est décrite dans un article traduit par l'éditeur de Khabra Vyacheslav Golovanov
SLY_G Pourquoi les TPU sont-ils si adaptés à l'apprentissage en profondeur?Voici à quoi ressemble un graphique de réseau de neurones de flux de données pour une reconnaissance facile:

Un élément de calcul primitif qui effectue des multiplications et des ajouts:

Une structure hautement pipeline de tels éléments, ce tableau systolique pour la multiplication matricielle est:

Sur Internet, il y a un tas de code sur Verilog et VHDL avec l'implémentation d'un tableau systolique, par exemple, le code est
sous cet article de blog :

module top(clk,reset,a1,a2,a3,b1,b2,b3,c1,c2,c3,c4,c5,c6,c7,c8,c9); parameter data_size=8; input wire clk,reset; input wire [data_size-1:0] a1,a2,a3,b1,b2,b3; output wire [2*data_size:0] c1,c2,c3,c4,c5,c6,c7,c8,c9; wire [data_size-1:0] a12,a23,a45,a56,a78,a89,b14,b25,b36,b47,b58,b69; pe pe1 (.clk(clk), .reset(reset), .in_a(a1), .in_b(b1), .out_a(a12), .out_b(b14), .out_c(c1)); pe pe2 (.clk(clk), .reset(reset), .in_a(a12), .in_b(b2), .out_a(a23), .out_b(b25), .out_c(c2)); pe pe3 (.clk(clk), .reset(reset), .in_a(a23), .in_b(b3), .out_a(), .out_b(b36), .out_c(c3)); pe pe4 (.clk(clk), .reset(reset), .in_a(a2), .in_b(b14), .out_a(a45), .out_b(b47), .out_c(c4)); pe pe5 (.clk(clk), .reset(reset), .in_a(a45), .in_b(b25), .out_a(a56), .out_b(b58), .out_c(c5)); pe pe6 (.clk(clk), .reset(reset), .in_a(a56), .in_b(b36), .out_a(), .out_b(b69), .out_c(c6)); pe pe7 (.clk(clk), .reset(reset), .in_a(a3), .in_b(b47), .out_a(a78), .out_b(), .out_c(c7)); pe pe8 (.clk(clk), .reset(reset), .in_a(a78), .in_b(b58), .out_a(a89), .out_b(), .out_c(c8)); pe pe9 (.clk(clk), .reset(reset), .in_a(a89), .in_b(b69), .out_a(), .out_b(), .out_c(c9)); endmodule module pe(clk,reset,in_a,in_b,out_a,out_b,out_c); parameter data_size=8; input wire reset,clk; input wire [data_size-1:0] in_a,in_b; output reg [2*data_size:0] out_c; output reg [data_size-1:0] out_a,out_b; always @(posedge clk)begin if(reset) begin out_a<=0; out_b<=0; out_c<=0; end else begin out_c<=out_c+in_a*in_b; out_a<=in_a; out_b<=in_b; end end endmodule
Je note que ce code n'est pas optimisé et généralement maladroit (et même écrit de manière non professionnelle - la source dans la publication utilise des affectations de blocs dans @ (posedge clk) - je l'ai corrigé). Dasha pourrait par exemple utiliser Verilog pour générer des constructions pour un code plus élégant.
En plus de deux réalisations extrêmes du réseau neuronal (sur le processeur et sur le réseau systolique), Dasha pourrait envisager d'autres options plus rapides que le processeur, mais pas aussi voraces que les opérations de multiplication comme un réseau systolique. Il est vrai que cela est plus probable non pas pour les écoliers, mais pour les élèves.
Une option est un périphérique d'exécution avec un grand nombre de blocs fonctionnels fonctionnant en parallèle, comme dans un processeur hors service:

Une autre option est ce que l'on appelle le tableau reconfigurable à gros grains - une matrice d'éléments quasi-processeurs, dont chacun a un petit programme. Ces éléments de processeur sont idéalement similaires aux cellules FPGA / FPGA, mais ne fonctionnent pas avec des signaux individuels, mais avec des groupes de bits / nombres sur les bus et les registres - voir le
rapport en direct de la naissance d'un acteur majeur de l'IA matérielle, qui accélère TensorFlow et rivalise avec NVidia " .
Maintenant, la lettre originale de Dasha:
Bonjour, Yuri.
En 2017, j'ai étudié dans votre école à LSHUP dans votre atelier et en octobre 2017 j'ai participé à une conférence à Tomsk en octobre de la même année avec le travail consacré à l'intégration de l'unité de multiplication dans le processeur SchooolMIPS.
Je voudrais continuer ce travail maintenant. Pour le moment, j'ai réussi à obtenir la permission à l'école de prendre ce sujet comme un petit cours. Avez-vous l'opportunité de m'aider dans la poursuite de ce travail?
PS Comme le travail est effectué dans un format spécifique, il est nécessaire de rédiger une introduction et une revue de la littérature sur le sujet. Veuillez indiquer les sources à partir desquelles vous pouvez obtenir des informations sur l'histoire du développement de ce sujet, sur les philosophies architecturales, etc., si vous avez de telles ressources à l'esprit.
De plus, en ce moment je vis à Moscou dans un pensionnat, il peut être plus facile d'interagir.
Cordialement
Daria Krivoruchko.
Dasha a enseigné Verilog et la conception au niveau du registre avec l'aide de moi et du livre
«Circuit numérique et architecture informatique» de David Harris et Sarah Harris . Cependant, si vous êtes un écolier / écolière et que vous souhaitez comprendre les concepts de base à un niveau très simple, la maison d'édition DMK-Press a publié pour vous une
traduction russe du manga japonais 2013 sur les circuits numériques créés par Amano Hideharu et Meguro Koji. Malgré la forme frivole de la présentation, le livre présente correctement les éléments logiques et les déclencheurs D,
puis les lie aux FPGA :
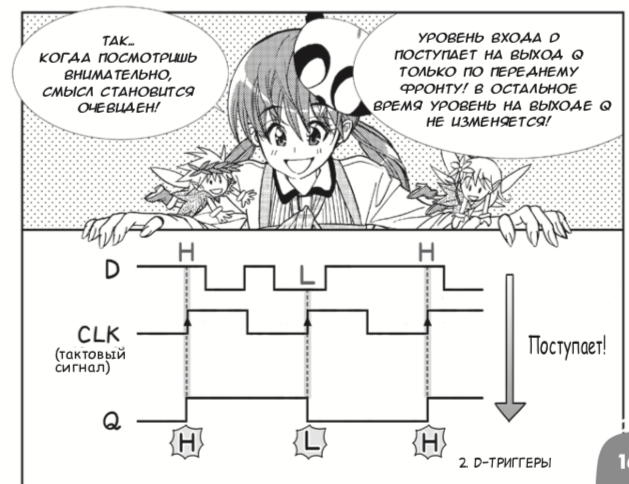
Voici à quoi ressemblait l'
école d'été pour les jeunes programmeurs de la région de Novossibirsk, où Dasha a appris Verilog, les FPGA, une méthodologie de développement de transfert de registre (Register Transfer Level - RTL):


Et voici le discours de Dasha à la conférence de Tomsk avec un autre élève de dixième, Arseniy Chegodaev:
Après la conversation de Dasha avec moi et Stanislav Zhelnio
sparf , le principal créateur du noyau du processeur éducatif schoolMIPS pour la mise en œuvre sur les FPGA:

Le projet schoolMIPS est accompagné d'une documentation sur
https://github.com/MIPSfpga/schoolMIPS . Dans la configuration la plus simple de ce cœur de processeur de formation, il n'y a que 300 lignes dans Verilog, tandis que dans le cœur industriel embarqué de la classe moyenne, il y a environ 300 000 lignes. Néanmoins, Dasha a pu ressentir à quoi ressemble le travail des concepteurs de l'industrie, qui changent le décodeur et le dispositif d'exécution de la même manière lorsqu'ils ajoutent de nouvelles instructions au processeur:
En conclusion, nous présentons des photos du doyen de l'Université de Samara Ilya Kudryavtsev, qui souhaite créer une école d'été et des olympiades avec des processeurs FPGA pour les futurs candidats:

Et une photo des employés de Zelenograd MIET qui prévoient déjà une telle école d'été l'année prochaine:

Les matériaux de RUSNANO et les matériaux possibles des Jeux Olympiques NTI, ainsi que les réalisations qui ont été faites au cours des deux dernières années dans la mise en œuvre des FPGA et de la microarchitecture dans le programme du HSE MIEM, de l'Université d'État de Moscou et de
Kazan Innopolis, devraient bien aller à un endroit et à un autre.