Après le véritable boom des jeux de société de la fin des années 2000, la famille a laissé plusieurs boîtes avec des jeux. L'un d'eux est le jeu "Hare and Hedgehog" dans la version allemande originale. Un jeu pour plusieurs joueurs, dans lequel l’élément aléatoire est minimisé, et le calcul sobre et la capacité du joueur à «regarder en avant» en plusieurs étapes l'emportent.
Mes fréquentes défaites dans le jeu m'ont amené à écrire «intelligence» informatique pour choisir le meilleur coup. Intelligence, idéalement capable de combattre le grand maître du lièvre et du hérisson (et quoi, le thé, pas les échecs, le jeu sera plus facile). Le reste de l'article décrit le processus de développement, la logique de l'IA et un lien vers la source.
Règles du jeu Hare and Hedgehog
Sur le terrain de jeu de 65 cellules, il y a plusieurs jetons de joueur, de 2 à 6 participants (mon dessin, non canonique, regarde, bien sûr, moyen):
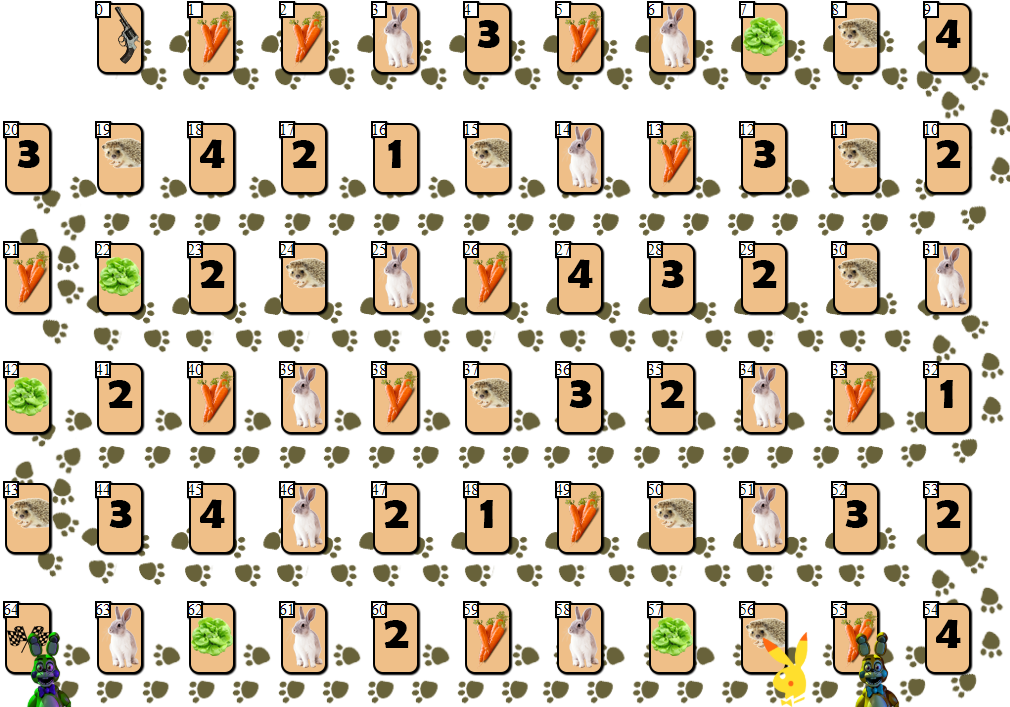
Hormis les cellules d'indices 0 (début) et 64 (arrivée), un seul joueur peut être placé dans chacune des cellules. Le but de chaque joueur est d'avancer vers la cellule d'arrivée, devant ses rivaux.
Le «carburant» pour aller de l'avant est la carotte - la «
monnaie » du jeu. Au début, chaque joueur reçoit 68 carottes, qu'il donne (et reçoit parfois) à mesure qu'il se déplace.
En plus des carottes, au début, le joueur reçoit 3 cartes à salade. La salade est un «artefact» spécial dont un joueur doit
se débarrasser avant l'arrivée. Se débarrasser de la laitue (et cela ne peut être fait que sur une cage à laitue spéciale, comme ceci:

), le joueur, notamment, reçoit des carottes supplémentaires. Avant cela, sautez votre mouvement. Plus il y a de joueurs devant la salade quittant la carte, plus ce joueur recevra de carottes: 10 x (la position du joueur sur le terrain par rapport aux autres joueurs). Autrement dit, le joueur debout sur le terrain en deuxième recevra 20 carottes, quittant la cage de la salade.
Les cellules avec les numéros 1 à 4 peuvent apporter plusieurs dizaines de carottes si la position du joueur correspond au numéro sur la cellule (1 à 4, la cellule avec le numéro 1 convient également pour les 4e et 6e positions sur le terrain), par analogie avec la cellule de laitue.
Le joueur peut sauter le mouvement, en restant sur la cage avec l'image des carottes et recevoir ou donner 10 carottes pour cette action. Pourquoi un joueur devrait-il donner du «carburant»? Le fait est qu'un joueur ne peut finir que 10 carottes après son dernier coup (20 si vous finissez deuxième, 30 si vous terminez troisième, etc.).
Enfin, le joueur peut obtenir 10 x N carottes en faisant N pas sur le hérisson
libre le
plus proche (si le hérisson le plus proche est occupé, un tel mouvement est impossible).
Le coût pour aller de l'avant est calculé non proportionnellement au nombre de mouvements, selon la formule (avec arrondi):
fracN+N22 ,
où N est le nombre de pas en avant.
Ainsi, pour avancer d'une cellule, le joueur donne 1 carotte, 3 carottes pour 2 cellules, 6 carottes pour 3 cellules, 10 pour 4, ..., 210 carottes pour faire avancer 20 cellules.
La dernière cellule - la cellule avec l'image d'un lièvre - introduit un élément de hasard dans le jeu. Après s'être tenu sur une cage avec un lièvre, le joueur pioche une carte spéciale de la pile, après quoi une action est effectuée. Selon la carte et la situation du jeu, le joueur peut perdre des carottes, obtenir des carottes supplémentaires ou sauter un tour. Il convient de noter que parmi les cartes avec des «effets», il existe plusieurs autres scénarios négatifs pour le joueur, ce qui encourage le jeu à être prudent et calculé.
Mise en œuvre sans IA
Dans la toute première implémentation, qui deviendra ensuite la base du développement du jeu «intellect», je me suis limité à l'option dans laquelle chaque joueur fait un pas - une personne.
J'ai décidé d'implémenter le jeu en tant que client - un site Web statique d'une page, dont toute la «logique» est implémentée sur le JS et le serveur - l'application API WEB. Le serveur est écrit en .NET Core 2.1 et produit un artefact d'assemblage - un fichier dll, qui peut être exécuté sous Windows / Linux / Mac OS.
La «logique» de la partie client est minimisée (ainsi que l'UX, puisque l'interface graphique est purement utilitaire). Par exemple, le client Web n'effectue pas lui-même la vérification pour voir si les règles demandées par le joueur sont acceptables. Cette vérification est effectuée sur le serveur. Le serveur indique au client les mouvements que le joueur peut effectuer à partir de la position de jeu actuelle.
Le serveur est une
machine Moore classique. La logique du serveur manque de concepts tels que «client connecté», «session de jeu», etc.
Le serveur ne fait que traiter la commande reçue (HTTP POST). Le
modèle de «commande» est implémenté sur le serveur. Le client peut demander l'exécution de l'une des commandes suivantes:
- commencer un nouveau jeu, c'est-à-dire "Placer" les jetons du nombre spécifié de joueurs sur un plateau "propre"
- effectuer le mouvement indiqué dans la commande
Pour la deuxième équipe, le client envoie au serveur la position de jeu actuelle (objet de la classe Disposition), c'est-à-dire une description du formulaire suivant:
- position, nombre de carottes et de laitue pour chaque lièvre, plus un champ booléen supplémentaire indiquant que le lièvre manque son tour
- indice du lièvre en mouvement.
Le serveur n'a pas besoin d'envoyer d'informations supplémentaires - par exemple, des informations sur le terrain de jeu. Tout comme pour l'enregistrement d'un croquis d'échecs, il n'est pas nécessaire de peindre la disposition des cellules noires et blanches sur le tableau - cette information est considérée comme une constante.
En réponse, le serveur indique si la commande s'est terminée avec succès. Techniquement, un client peut, par exemple, demander un déplacement invalide. Ou essayez de créer un nouveau jeu pour un seul participant, ce qui n'a évidemment aucun sens.
Si l'équipe réussit, la réponse contiendra une nouvelle
position de jeu, ainsi qu'une liste de mouvements pouvant être effectués par le joueur suivant dans la ligne (en cours pour la nouvelle position).
En plus de cela, la réponse du serveur contient certains champs de service. Par exemple, le texte d'une carte de lièvre «retiré» par un joueur à un pas sur la cellule correspondante.
Tour du joueur
Le tour du joueur est codé comme un entier:
- 0, si le joueur est obligé de rester dans la cellule actuelle,
1, 2, ... N pour 1, ... N avance, - -1, -2, ... -M pour déplacer 1 ... M cellules vers le hérisson libre le plus proche,
- 1001, 1002 - codes spéciaux pour un joueur qui décide de rester sur la cellule de carotte et de recevoir (1001) ou de donner (1002) 10 carottes pour cela.
Implémentation logicielle
Le serveur reçoit le JSON de la commande demandée, l’analyse dans l’une des classes de demande correspondantes et exécute l’action demandée.
Si le client (joueur) a demandé de se déplacer avec le code CMD de la position (POS) transférée à l'équipe, le serveur effectue les actions suivantes:
- vérifie si un tel mouvement est possible
- crée une nouvelle position à partir de la position actuelle, en y appliquant les modifications correspondantes,
obtient de nombreux mouvements possibles pour une nouvelle position. Permettez-moi de vous rappeler que l'index du joueur effectuant le mouvement est déjà inclus dans l'objet qui décrit la position , - renvoie au client une réponse avec une nouvelle position, des mouvements possibles ou le drapeau de réussite égal à faux, et une description de l'erreur.
La logique de vérification de l'admissibilité du déménagement demandé (CMD) et de construction d'une nouvelle position s'est avérée un peu plus proche que nous le souhaiterions. Avec cette logique, la méthode pour trouver des mouvements acceptables a quelque chose en commun. Toutes ces fonctionnalités sont implémentées par la classe TurnChecker.
A l'entrée des méthodes check / execute, TurnChecker reçoit un objet de la classe de la position de jeu (Disposition). L'objet Disposition contient un tableau de données de joueur (Haze [] Hazes), l'index du joueur effectuant le mouvement + quelques informations de service qui sont remplies pendant le fonctionnement de l'objet TurnChecker.
Le terrain de jeu décrit la classe FieldMap, qui est implémentée en tant que
singleton . La classe contient un tableau de cellules + quelques informations supplémentaires utilisées pour simplifier / accélérer les calculs ultérieurs.
Considérations sur les performancesDans l'implémentation de la classe TurnChecker, j'ai essayé d'éviter autant que possible les boucles. Le fait est que les méthodes d'obtention de l'ensemble des mouvements / exécution autorisés d'un mouvement seront par la suite appelées des milliers (dizaines de milliers) fois au cours de la procédure de recherche d'un mouvement quasi optimal.
Ainsi, par exemple, je calcule le nombre de cellules qu'un joueur peut utiliser avec N carottes, en utilisant la formule:
return ((int)Math.Pow(8 * N + 1, 0.5) - 1) / 2;
En vérifiant si la cellule i est occupée par l'un des joueurs, je ne passe pas par la liste des joueurs (car cette action devra probablement être effectuée plusieurs fois), mais je me tourne vers le dictionnaire du formulaire
[cell_index, busy_cell_ flag] rempli à l'avance.
Lorsque je vérifie si la cellule hérisson spécifiée est la plus proche (derrière) de la cellule actuelle occupée par le joueur, je compare également la position demandée avec une valeur d'un dictionnaire de la forme
[index_cellulaire, index_herisson le plus proche] - informations statiques.
Implémentation avec l'IA
Une commande est ajoutée à la liste des commandes traitées par le serveur: exécuter un déplacement quasi optimal sélectionné par le programme. Cette équipe est une petite modification de la commande «Déplacement du joueur», dont, en fait, le champ de déplacement (
CMD ) a été supprimé.
La première décision qui vient à l'esprit est d'utiliser l'heuristique pour sélectionner le «meilleur coup» possible. Par analogie avec les échecs, nous pouvons évaluer chacune des positions de jeu obtenues avec notre coup en fixant une sorte de note pour cette position.
Évaluation de position heuristique
Par exemple, aux échecs, faire une évaluation (sans ramper dans la nature des ouvertures) est assez simple: au minimum, vous pouvez calculer le «coût» total des pièces en prenant la valeur de chevalier / évêque pour 3 pions, la valeur d'une tour à 5 pions, la reine à 9 et le roi à
int Pions MaxValue . Il est facile d'améliorer l'estimation, par exemple en y ajoutant (avec un facteur de correction - facteur / exposant ou autre fonction):
- le nombre de mouvements possibles depuis la position actuelle,
- rapport des menaces aux figures ennemies / menaces de l'ennemi.
Une évaluation spéciale est donnée à la position du tapis:
int.MaxValue , si le mat est placé sur l'ordinateur,
int.MinValue si le mat a mis la personne.
Si vous ordonnez au processeur d'échecs de choisir le coup suivant, guidé uniquement par une telle évaluation, le processeur ne choisira probablement pas les pires coups. En particulier:
- Ne manquez pas l'occasion de prendre un plus gros morceau ou un échec et mat,
- très probablement, il ne conduira pas les chiffres dans les coins,
- Cela ne remet pas le chiffre en cause (compte tenu du nombre de menaces dans l'évaluation).
Bien sûr, de tels mouvements de l'ordinateur ne lui laisseront aucune chance de succès avec un adversaire qui fait ses mouvements dans le moindre sens. L'ordinateur ignorera toutes les fiches. De plus, il n'hésite sans doute même pas à échanger la reine contre un pion.
Néanmoins, l'algorithme d'évaluation heuristique de la position de jeu actuelle aux échecs (sans revendiquer les lauriers du programme champion) est assez transparent. Vous ne pouvez pas dire sur le jeu Hare and Hedgehog.
Dans le cas général, dans le jeu le Lièvre et le Hérisson, une maxime plutôt floue fonctionne: «
il vaut mieux aller plus loin avec plus de carottes et moins de laitue ». Cependant, tout n'est pas si simple. Disons que si un joueur a 1 carte à salade au milieu de la partie, cette option peut être assez bonne. Mais le joueur debout sur la ligne d'arrivée avec une carte à salade sera évidemment en situation de perte. En plus de l'algorithme d'évaluation, je voudrais également avoir la possibilité de «jeter un œil» un peu plus loin, tout comme les menaces pesant sur les pièces peuvent être comptées dans une évaluation heuristique d'une position d'échecs. Par exemple, il convient de considérer le bonus de carottes reçues par un joueur quittant la cellule de laitue / cellule de position (1 ... 4), en tenant compte du nombre de joueurs devant.
J'ai déduit la note finale en fonction:
E = Ks * S + Kc * C + Kp * P,
où S, C, P sont des notes calculées en utilisant des cartes à salade (S) et des carottes © dans les mains du joueur, P est les notes données au joueur pour la distance parcourue.
Ks, Kc, Kp sont les facteurs de correction correspondants (ils seront discutés plus loin).
Le moyen le plus simple est de déterminer la marque
du chemin parcouru :
P = i * 3, où i est l'indice de la cellule sur laquelle se trouve le joueur.
Le classement C (carottes) est déjà plus difficile.
Pour obtenir une valeur C spécifique, je choisis l'une des 3 fonctions
C0,C1,C2 à partir d'un argument (le nombre de carottes sur les mains). L'indice de la fonction C ([0, 1, 2]) est déterminé par la position relative du joueur sur le terrain de jeu:
- [0] si le joueur a terminé moins de la moitié du terrain de jeu,
- [2] si un joueur a assez de carottes (mb, voire abondantes) pour finir,
- [1] dans les autres cas.
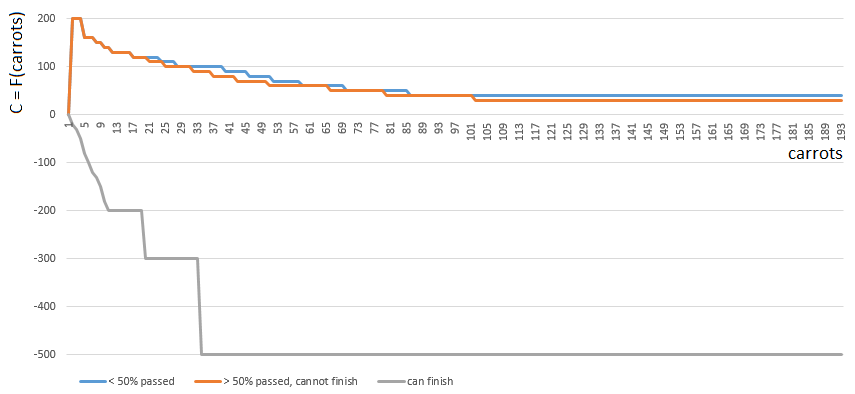
Les fonctions 0 et 1 sont similaires: la «valeur» de chaque carotte dans les mains du joueur diminue progressivement avec l'augmentation du nombre de carottes dans les mains. Le jeu encourage rarement les Plyushkins. Dans le cas 1 (la moitié du champ est passée), la valeur des carottes diminue un peu plus vite.
La fonction 2 (le joueur peut terminer), au contraire, impose une grande amende (valeur de coefficient négative) à chaque carotte dans les mains du joueur - plus il y a de carottes, plus le coefficient de pénalité est élevé. Puisqu'avec un excès de carottes la finition est interdite par les règles du jeu.
Avant de calculer la quantité de carottes sur les mains du joueur est spécifié en tenant compte des carottes par coup de la cellule de laitue / cellule numéro 1 ... 4.
Une catégorie «
laitue » S est déduite de la même manière. En fonction de la quantité de salade sur les mains du joueur (0 ... 3), une fonction est sélectionnée
S0,S1,S2 ou
S3 . Argument de fonction
S0−S3 . - encore une fois, le chemin «relatif» parcouru par le joueur. A savoir, le nombre de cellules avec salade restant devant (par rapport à la cellule occupée par le joueur):
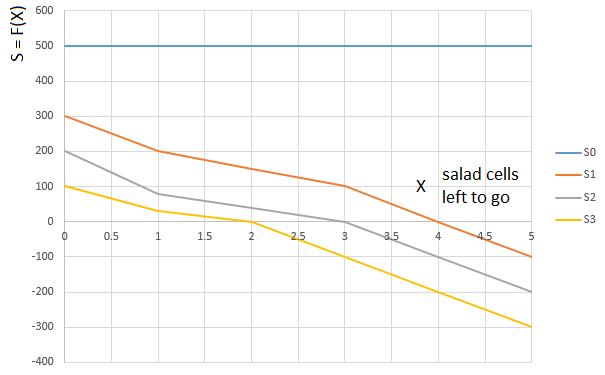
La courbe
S0 - fonction d'évaluation (S) sur le nombre de cellules de laitue devant le joueur (0 ... 5), pour un joueur avec 0 carte de laitue en main,
la courbe
S1 - la même fonction pour un joueur avec une carte de salade en main, etc.
La note finale (E = Ks * S + Kc * C + Kp * P) prend ainsi en compte:
- la quantité supplémentaire de carottes que le joueur recevra immédiatement avant son propre mouvement,
- le chemin du joueur
- la quantité de carottes et de laitue sur les mains qui affectent de façon non linéaire le score.
Et voici comment un ordinateur joue, en choisissant le prochain coup avec le score heuristique maximum:
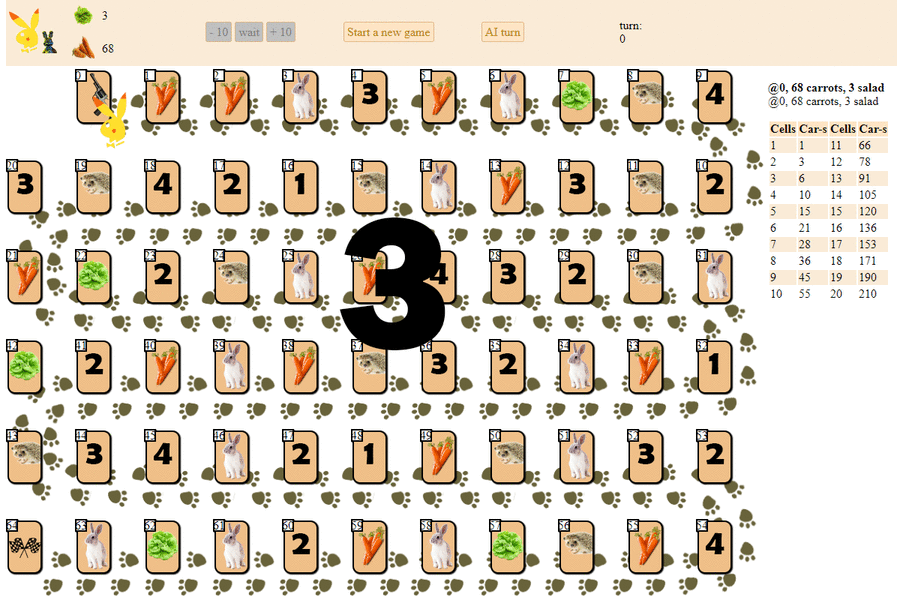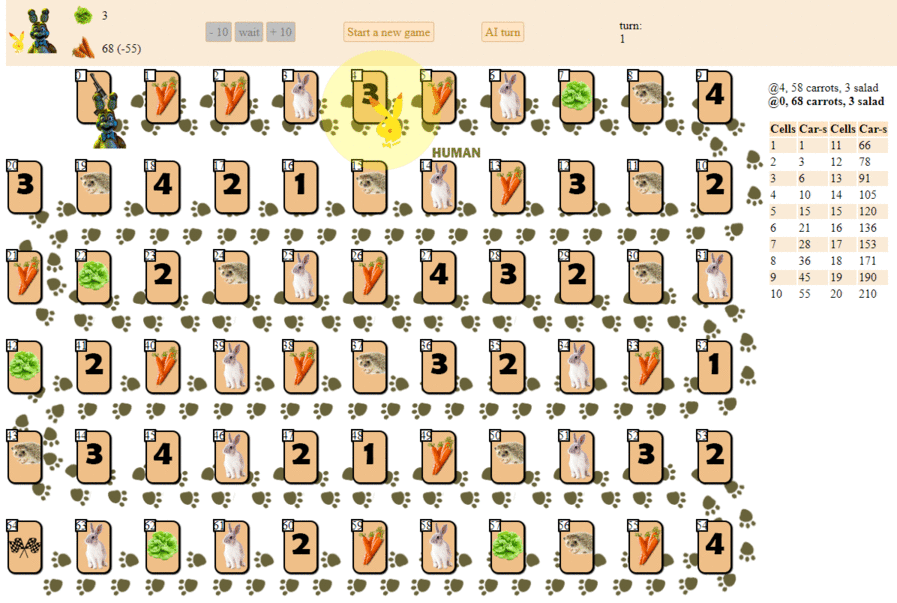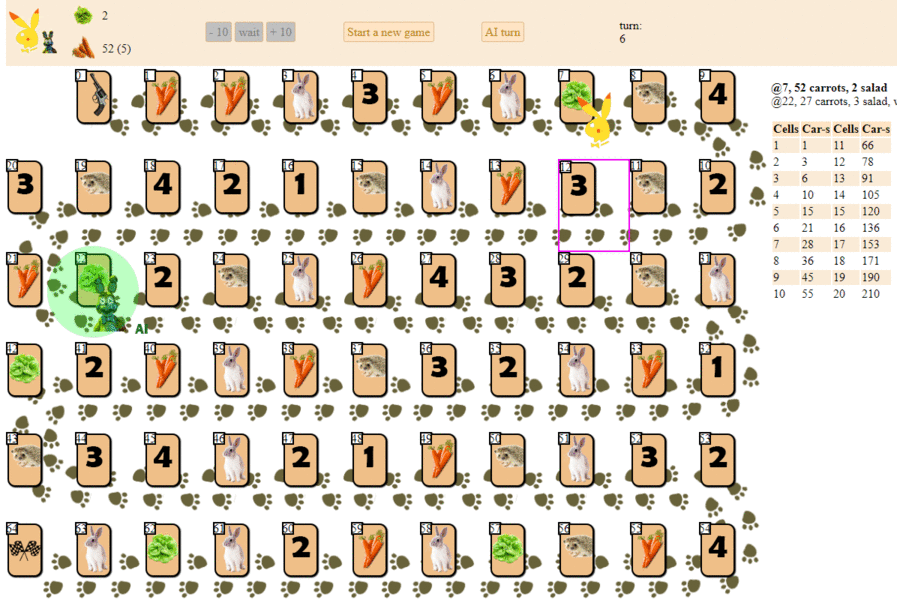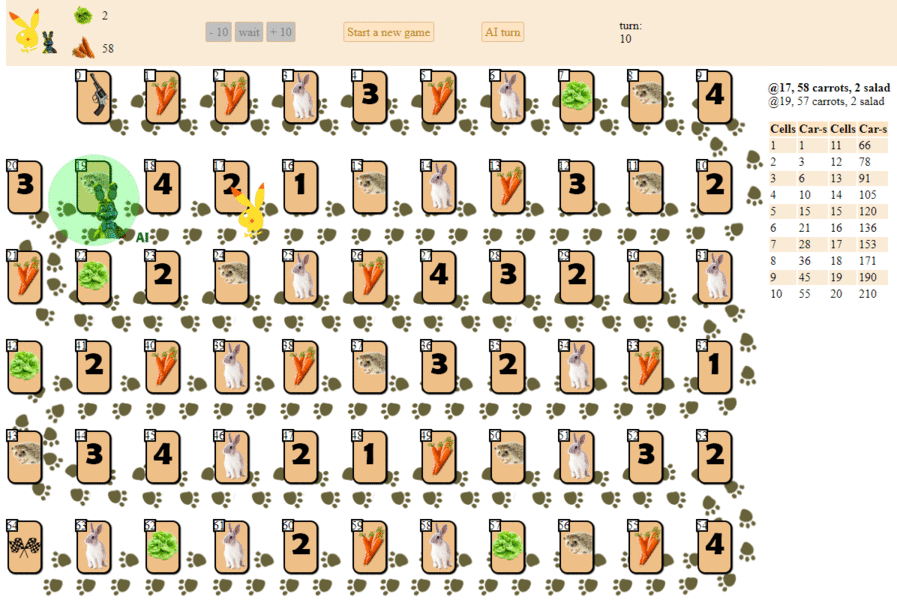
En principe, les débuts ne sont pas si mauvais. Cependant, il ne faut pas s'attendre à un bon jeu d'une telle IA: au milieu du jeu, le «robot» vert commence à faire des mouvements répétés, et à la fin il fait plusieurs itérations de mouvements en avant - en arrière vers le hérisson, jusqu'à ce qu'il finisse finalement. En partie à cause du hasard, il finira derrière le joueur - une personne par une douzaine de coups.
Notes de mise en œuvreLe calcul de l'évaluation est géré par une classe spéciale - EstimationCalculator. Les fonctions d'évaluation de la position par rapport aux cartes carotte-salade sont chargées dans des tableaux dans le constructeur statique de la classe de calculatrice. En entrée, la méthode d'estimation de position reçoit l'objet de position lui-même et l'index du joueur, du «point de vue» dont la position est évaluée par l'algorithme. Autrement dit, la même position de jeu peut recevoir plusieurs notes différentes, selon le joueur pour lequel les points virtuels sont pris en compte.
Arbre de décision et algorithme Minimax
Nous utilisons l'algorithme de prise de décision dans le jeu antagoniste Minimax. Très bien, à mon avis, l'algorithme est décrit dans
ce post (traduction) .
Nous enseignons au programme à «regarder» quelques pas en avant. Supposons que, à partir de la position actuelle (et l'arrière-plan n'est pas important pour l'algorithme - comme nous nous en souvenons, le programme fonctionne comme
une machine Moore ), numéroté par le numéro 1, le programme peut effectuer deux mouvements. Nous obtenons deux positions possibles, 2 et 3. Vient ensuite le tour du joueur - la personne (dans le cas général - l'ennemi). À partir de la 2e position, l'adversaire a 3 coups, de la troisième - seulement deux coups. Ensuite, le tour de recommencer revient au programme qui, au total, peut effectuer 10 mouvements à partir de 5 positions possibles:
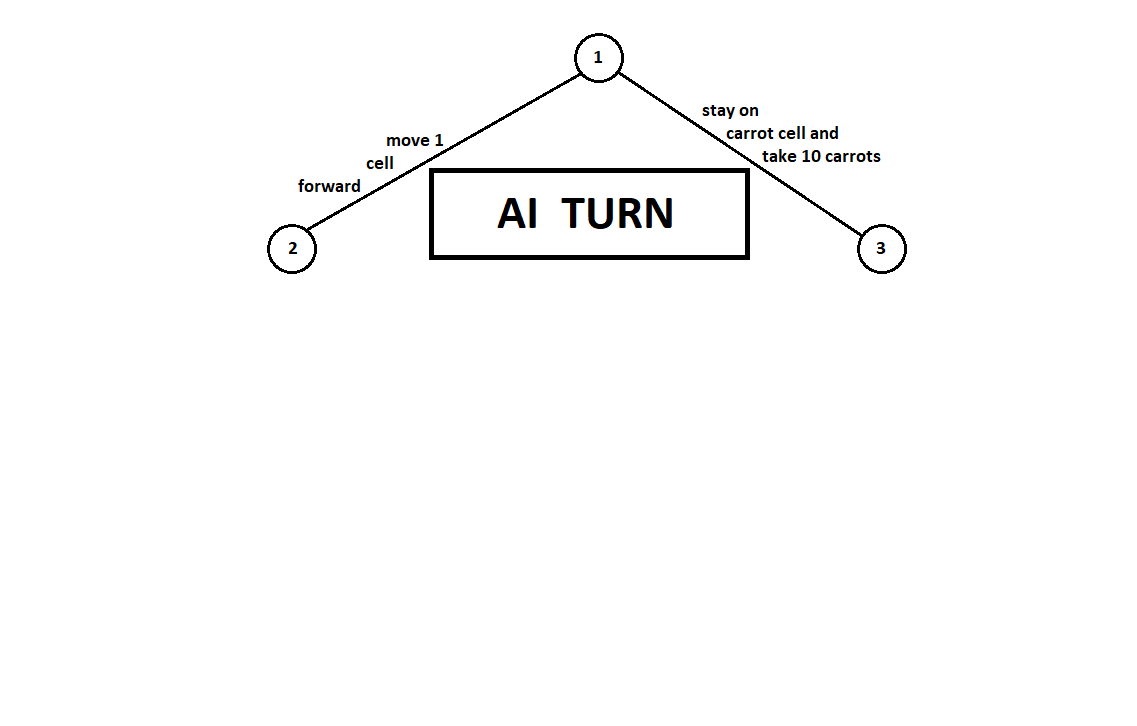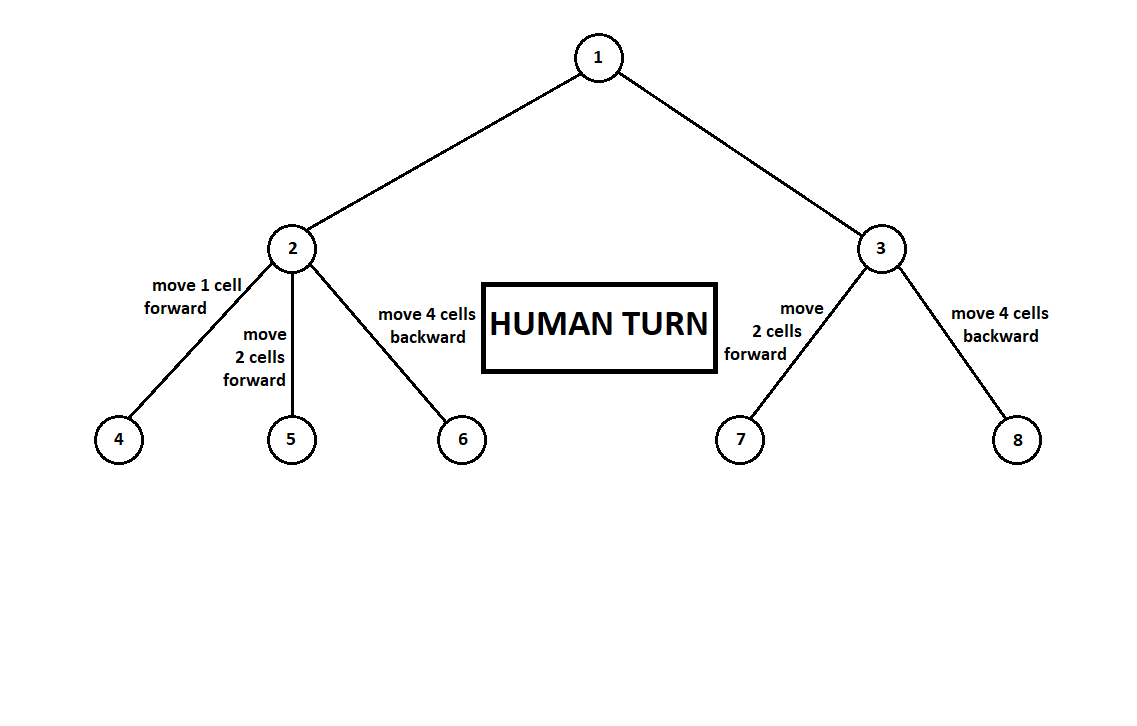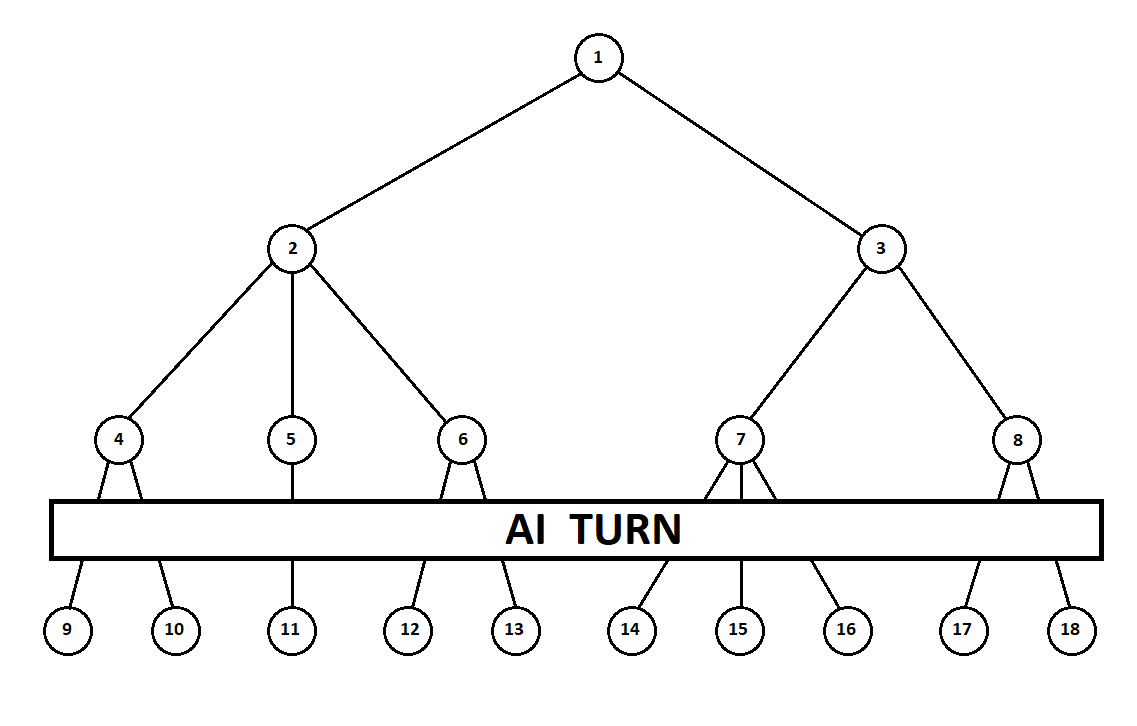
Supposons que, après le deuxième mouvement de l'ordinateur, le jeu se termine et chacune des positions reçues est évaluée du point de vue des premier et deuxième joueurs. Et nous avons déjà implémenté l'algorithme d'évaluation. Évaluons chacune des positions finales (feuilles de l'arbre 9 ... 18) sous la forme d'un vecteur
[v0,v1] ,
où
v0 - score calculé pour le premier joueur,
v1 - score du deuxième joueur:
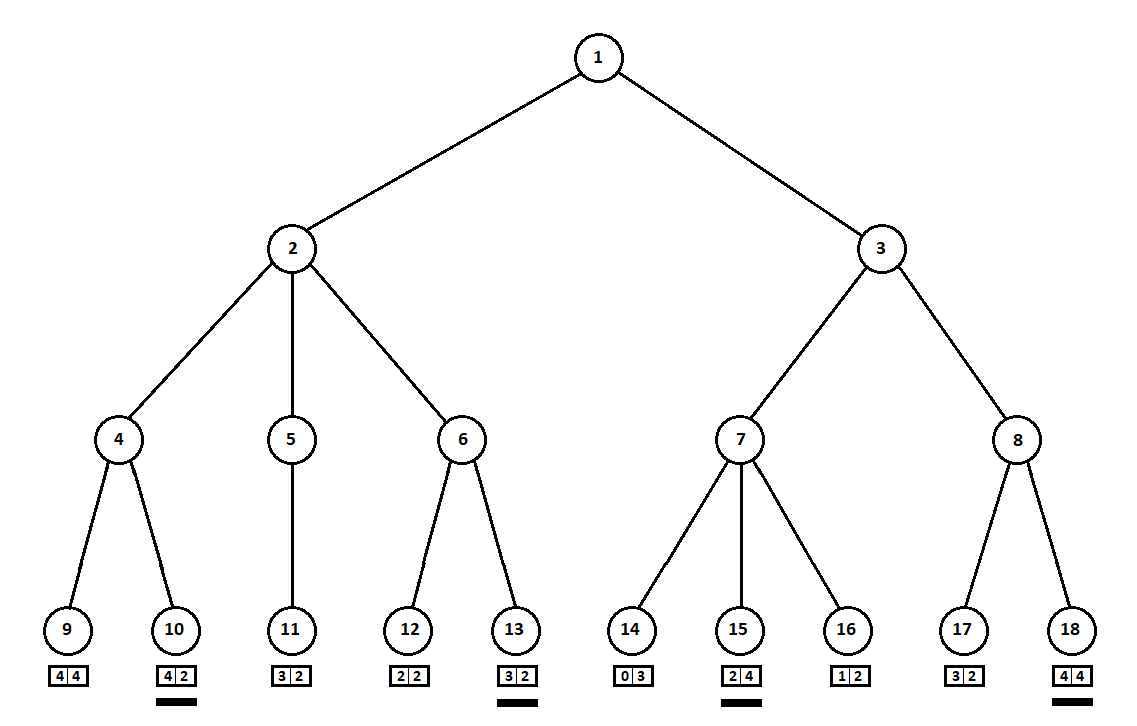
Puisque l'ordinateur fait le dernier pas, il choisira évidemment les options dans chacun des sous-arbres ([9, 10], [11], [12, 13], [14, 15, 16], [17, 18]) ce qui lui donne une meilleure note. La question se pose immédiatement: selon quel principe choisir la «meilleure» position?
Par exemple, il y a deux mouvements, après quoi nous avons des positions avec des notes [5; 5] et [2; 1]. Évalue le premier joueur. Deux alternatives sont évidentes:
- sélection de la position avec la valeur absolue maximale du i-ème score pour le i-ème joueur. En d'autres termes, le noble coureur Leslie, avide de victoire, sans égard aux concurrents. Dans ce cas, une position avec une estimation de [5; 5].
- le choix d'un poste avec la note maximale par rapport aux estimations des concurrents est le rusé professeur Faith, qui ne manque pas l'occasion d'infliger de sales tours à l'ennemi. Par exemple, prendre intentionnellement du retard sur un joueur qui prévoit de partir de la deuxième position. Un élément avec une note [2; 1].
Dans mon implémentation logicielle, j'ai fait de l'algorithme de sélection de grade (une fonction qui mappe le vecteur de grade à une valeur scalaire pour le ième joueur) un paramètre personnalisé. D'autres tests ont montré, à ma grande surprise, la supériorité de la première stratégie - le choix de la position par la valeur absolue maximale
vi .
Caractéristiques de l'implémentation logicielleSi la première option pour choisir la meilleure note est spécifiée dans les paramètres de l'IA (classe TurnMaker), le code de la méthode correspondante prendra la forme:
int ContractEstimateByAbsMax(int[] estimationVector, int playerIndex) { return estimationVector[playerIndex]; }
La deuxième méthode - le maximum par rapport aux positions des concurrents - est mise en œuvre un peu plus compliquée:
int ContractEstimateByRelativeNumber(int[]eVector, int player) { int? min = null; var pVal = eVector[player]; for (var i = 0; i < eVector.Length; i++) { if (i == player) continue; var val = pVal - eVector[i]; if (!min.HasValue || min.Value > val) min = val; } return min.Value; }
Certaines estimations (soulignées dans la figure) sont transférées au niveau supérieur. L'ennemi doit maintenant choisir une position, sachant quelle position ultérieure l'algorithme choisira:
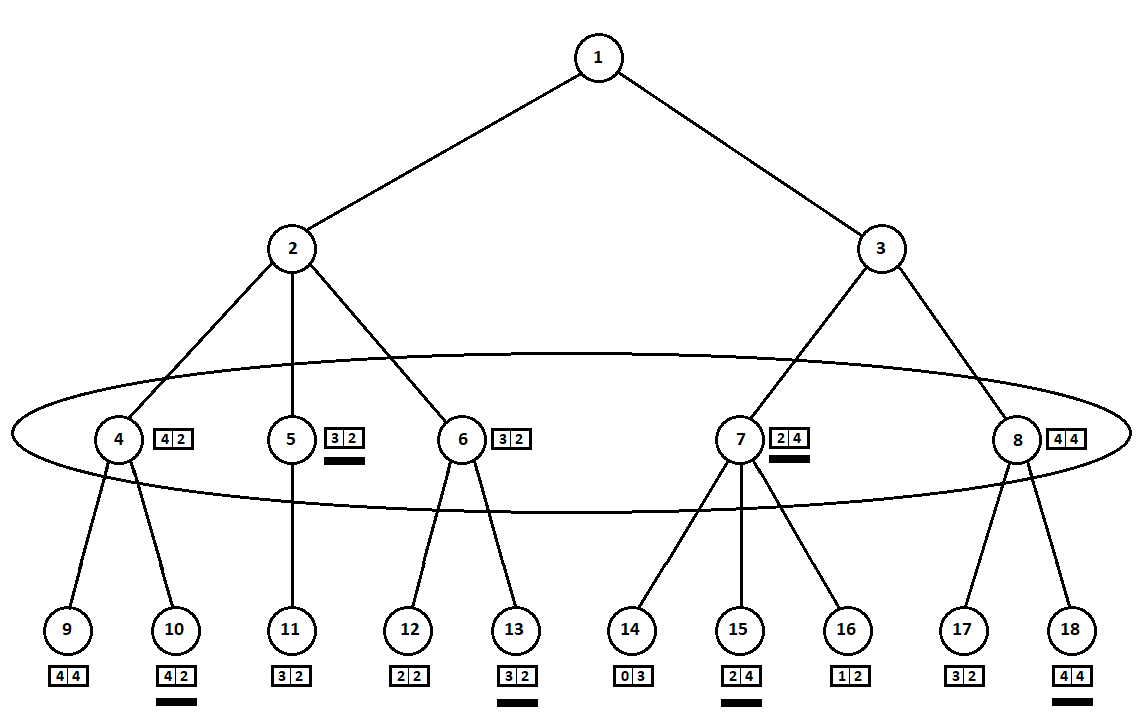
L'adversaire, évidemment, choisira pour lui la position la mieux notée (celle où la
deuxième coordonnée du vecteur prend la plus grande valeur). Ces estimations sont à nouveau soulignées dans le graphique.
Enfin, nous revenons au tout premier mouvement. L'ordinateur sélectionne, et il préfère le mouvement avec la première coordonnée la plus grande du vecteur:
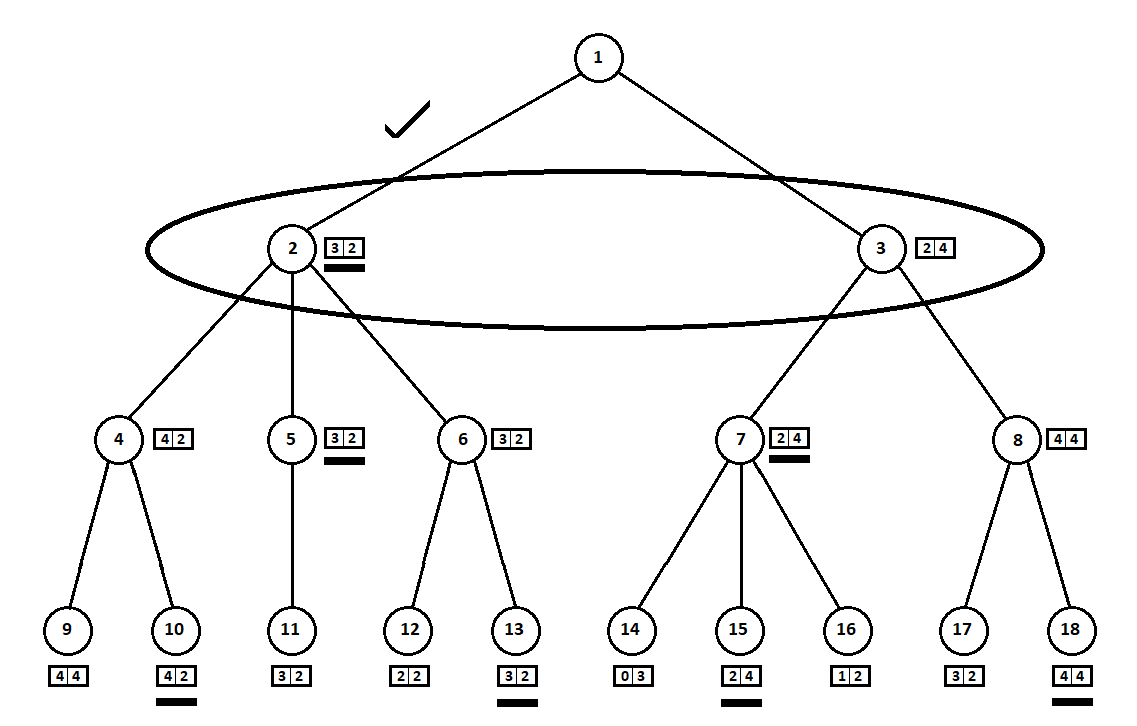
Ainsi, le problème est résolu - un mouvement quasi optimal est trouvé. Supposons qu'un score heuristique de 100% en position foliaire sur un arbre indique un futur gagnant. Ensuite, notre algorithme choisira sans équivoque le meilleur coup possible.
Cependant, le score heuristique n'est précis à 100% que lorsque la position
finale du jeu est évaluée - un (ou plusieurs) joueurs ont terminé, le gagnant est déterminé. Par conséquent, ayant la possibilité d'anticiper N mouvements - autant qu'il en faut pour gagner des rivaux de force égale, vous pouvez choisir le mouvement optimal.
Mais un jeu typique pour 2 joueurs dure en moyenne environ 30 à 40 coups (pour trois joueurs - environ 60 coups, etc.). De chaque position, un joueur peut généralement faire environ 8 mouvements. Par conséquent, un arbre complet de positions possibles pour 30 mouvements comprendra environ

= 1237940039285380274899124224 crêtes!
Dans la pratique, la création et l'analyse d'une arborescence de ~ 100 000 positions sur mon PC prennent environ 300 millisecondes. Ce qui nous donne une limite sur la profondeur de l'arbre en 7 à 8 niveaux (mouvements), si nous voulons nous attendre à une réponse informatique d'au plus une seconde.
Caractéristiques de l'implémentation logicielleDe toute évidence, une méthode récursive est nécessaire pour construire un arbre de positions et trouver le meilleur mouvement. À l'entrée de la méthode - la position actuelle (dans laquelle, comme nous le rappelons, le joueur fait déjà un mouvement) et le niveau d'arbre actuel (numéro de mouvement). Dès que nous descendons au niveau maximum autorisé par les paramètres de l'algorithme, la fonction renvoie un vecteur d'estimation de position heuristique du «point de vue» de chacun des joueurs.
Un ajout important : la descente sous l'arbre doit également être arrêtée lorsque le joueur actuel a terminé. Sinon (si l'algorithme de sélection de la meilleure position par rapport aux positions des autres joueurs est sélectionné), le programme peut «piétiner» à l'arrivée pendant longtemps, «se moquer» de l'adversaire. De plus, de cette façon, nous réduirons légèrement la taille de l'arbre en fin de partie.
Si nous ne sommes pas encore au niveau ultime de récursivité, alors nous sélectionnons les mouvements possibles, créons une nouvelle position pour chaque mouvement et la passons à l'appel récursif de la méthode actuelle.
Pourquoi Minimax?Dans l'interprétation originale des joueurs sont toujours deux. Le programme calcule le score exclusivement à partir de la position du premier joueur. Par conséquent, lors du choix de la «meilleure» position, le joueur avec l'index 0 recherche une position avec une note maximale, le joueur avec l'index 1 recherche une minimum.
Dans notre cas, la note doit être un vecteur afin que chacun des N joueurs puisse l'évaluer de son «point de vue», à mesure que la note monte dans l'arbre.
Tuning AI
Ma pratique de jouer contre l'ordinateur a montré que l'algorithme n'est pas si mauvais, mais toujours inférieur aux humains. J'ai décidé d'améliorer l'IA de deux manières:
- optimiser la construction / traversée de l'arbre de décision,
- améliorer l'heuristique.
Optimisation de l'algorithme Minimax
Dans l'exemple ci-dessus, nous pourrions refuser de considérer la position 8 et de «sauvegarder» 2 à 3 sommets de l'arbre:
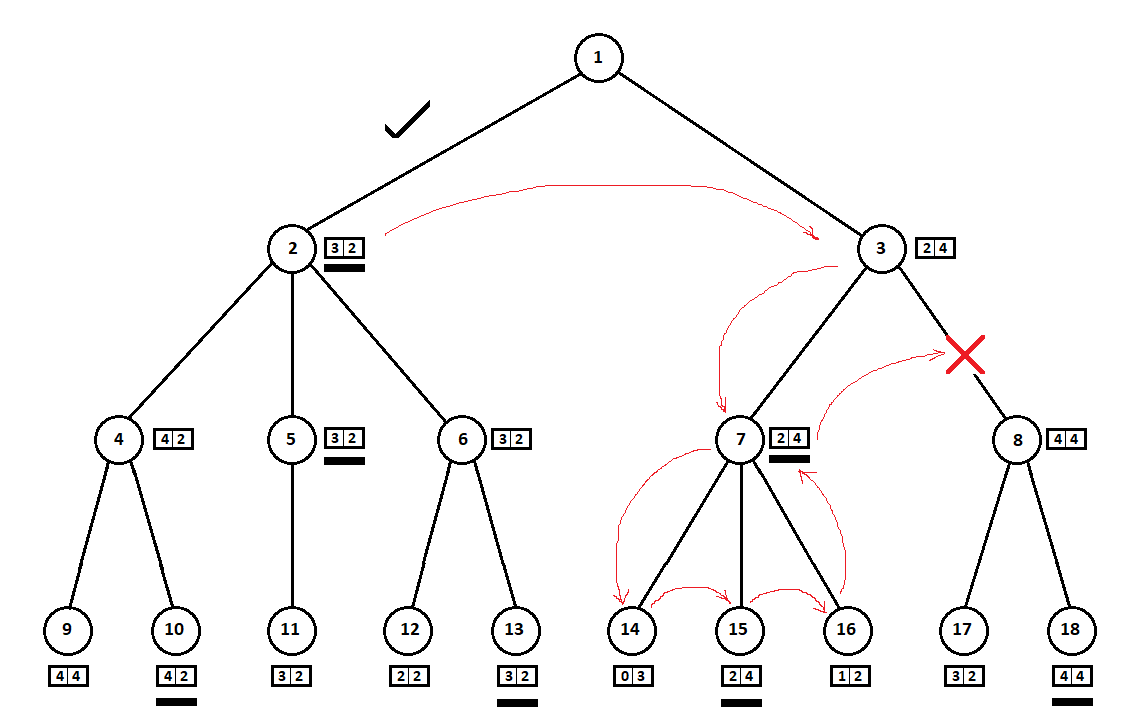
On marche autour de l'arbre de haut en bas, de gauche à droite. En contournant le sous-arbre à partir de la position 2, nous avons déduit la meilleure estimation pour le mouvement 1 -> 2: [3, 2]. En contournant le sous-arbre avec la racine en position 7, nous avons déterminé la note actuelle (meilleure pour le mouvement 3 -> 7): [2, 4]. Du point de vue de l'ordinateur (premier joueur), le score [2, 4] est pire que le score [3, 2]. Et puisque l'adversaire de l'ordinateur choisit le coup de la position 3, quel que soit le score pour la position 8, le score final pour la position 3 sera a priori pire que le score obtenu pour la troisième position. Par conséquent, le sous-arbre avec la racine en position 8 ne peut pas être construit et non évalué.
La version optimisée de l'algorithme Minimax, qui vous permet de couper les sous-arbres en excès, est appelée
l'algorithme d'écrêtage alpha-bêta . L'implémentation de cet algorithme nécessitera des modifications mineures du code source.
Caractéristiques de l'implémentation logicielleDeux paramètres entiers sont également transmis à la méthode CalcEstimate de la classe TurnMaker - alpha, qui est initialement égale à int.MinValue et beta, qui est égale à int.MaxValue. De plus, après avoir reçu une estimation du mouvement actuel considéré, un pseudocode du formulaire est exécuté:
e = _[0]
Une caractéristique importante de l'implémentation logiciellela méthode d'écrêtage alpha-bêta, par définition, conduit à la même solution que l'algorithme Minimax «propre». Pour vérifier si la logique de la prise de décision a changé (ou plutôt, les résultats sont des mouvements), j'ai écrit un test unitaire dans lequel le robot a effectué 8 mouvements pour chacun des 2 adversaires (16 mouvements au total) et enregistré la série de mouvements résultante - avec option d'écrêtage désactivée .
Ensuite, dans le même test, la procédure a été répétée avec l' option d'écrêtage activée . Après cela, la séquence de mouvements a été comparée. L'écart dans les mouvements indique une erreur dans la mise en œuvre de l'algorithme d'écrêtage alpha-bêta (échec du test).
Optimisation d'écrêtage alpha-bêta mineure
Avec l'option d'écrêtage activée dans les paramètres de l'IA, le nombre de sommets dans l'arbre de position a été réduit en moyenne de 3 fois. Ce résultat peut être quelque peu amélioré.
Dans l'exemple ci-dessus:
«coïncidait» si bien que, avant le sous-arbre avec le sommet en position 3, nous avons examiné le sous-arbre avec le sommet en position 2. Si la séquence était différente, nous pourrions commencer par le «pire» sous-arbre et ne pas arriver à la conclusion qu'il est inutile de considérer la position suivante .
En règle générale, l'écrêtage sur un arbre se révèle plus «économique», ses sommets descendants au même niveau (c'est-à-dire tous les mouvements possibles depuis la position i) sont déjà triés par l'estimation de position actuelle (sans regarder en profondeur). En d'autres termes, nous supposons que le meilleur mouvement (du point de vue heuristique) est plus susceptible d'obtenir une meilleure note finale. Ainsi, avec une certaine probabilité, nous trions l'arbre afin que le «meilleur» sous-arbre soit considéré avant le «pire», ce qui nous permettra de couper plus d'options.
L'évaluation de la position actuelle est une procédure coûteuse. Si auparavant il nous suffisait d'évaluer uniquement les positions terminales (feuilles), alors maintenant l'évaluation est faite pour tous les sommets de l'arbre. Cependant, comme l'ont montré les tests, le nombre total d'estimations faites était encore légèrement inférieur à celui de la variante sans le tri initial des mouvements possibles.
Caractéristiques de l'implémentation logicielleL'algorithme de découpage alpha-bêta renvoie le même mouvement que l'algorithme Minimax d'origine. Cela vérifie le test unitaire que nous avons écrit, en comparant deux séquences de mouvements (pour un algorithme avec écrêtage et sans). L'écrêtage alpha-bêta avec tri , dans le cas général, peut indiquer un mouvement différent comme un mouvement quasi optimal.
Pour tester le bon fonctionnement de l'algorithme modifié, vous avez besoin d'un nouveau test. Malgré la modification, l'algorithme trié doit produire exactement le même vecteur d'estimation final ([3, 2] dans l'exemple de la figure) que l'algorithme non trié comme l'algorithme Minimax d'origine.
Dans le test, j'ai créé une série de positions de test et sélectionné de chacune selon le «meilleur» mouvement, en activant et désactivant l'option de tri. Il a ensuite comparé le vecteur d'évaluation obtenu de deux manières.
De plus, étant donné que les positions pour chacun des mouvements possibles dans le sommet actuel de l'arbre sont triées par évaluation heuristique, l'idée suggère de rejeter immédiatement certaines des pires options. Par exemple, un joueur d'échecs peut envisager un coup dans lequel il substitue sa tour à un coup de pion. Cependant, en "déroulant" la situation en profondeur de 3, 4 ... pas en avant, il remarquera immédiatement les options lorsque, par exemple, l'adversaire met l'attaque de l'évêque de sa reine.
Dans les paramètres de l'IA, j'ai défini le vecteur «découpage des pires options». Par exemple, un vecteur de la forme [0, 0, 8, 8, 4] signifie que:
- en regardant un [0] et deux [0] pas en avant, le programme considérera tous les mouvements possibles, car 0 ,
- [8] [8] , 8 “” , , ,
- [4], 4 “” .
Le tri étant activé pour l'algorithme d'écrêtage alpha-bêta et un vecteur similaire dans les paramètres d'écrêtage, le programme a commencé à dépenser environ 300 millisecondes pour sélectionner un mouvement quasi optimal, «allant plus loin» 8 pas en avant.Optimisation heuristique
Malgré la quantité décente de positions de sommets itérées dans l'arbre et «profondes» en regardant vers l'avant à la recherche d'un mouvement quasi optimal, l'IA avait plusieurs faiblesses. J'ai défini l'un d'eux comme un « piège à lapin ».Piège à lièvre. ( 8 — 10 15), . “” ( !):
. :
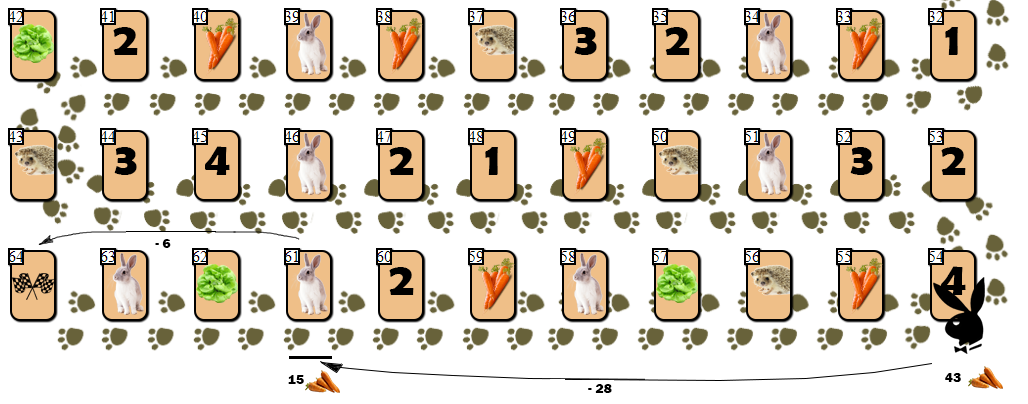
54 (43), — 10 55 . AI, , (61), 28 . , 6 9 ( 10 ).
, ( ), , 4 — 6 . , , , AI ?
,
, . AI . , , . “ ” :
65 — “” , , . , , , () .
Facteurs de correction
Plus tôt, en donnant une formule d'estimation heuristique de la position actuelleE = Ks * S + Kc * C + Kp * P,j'ai mentionné, mais je n'ai pas décrit, les facteurs de correction.Le fait est que la formule elle-même et les ensembles de fonctionsC 0 . . C 2 , S 0 . . S 5 , ont été déduits par moi intuitivement, sur la base de la soi-disant "Le bon sens." Au minimum, je voudrais sélectionner ces coefficients Ks, Kc et Kp afin que l'estimation soit aussi adéquate que possible. Comment évaluer la «pertinence» de l'évaluation? L'évaluation est une quantité sans dimension et ne peut être comparée qu'à une autre estimation. J'ai pu trouver la seule façon d'affiner les coefficients de correction: j'aimis dans le programme une série «d'études» stockées dans un fichier CSV avec des données de la forme 45;26;2;f;29;19;0;f;2 ...
Cette ligne signifie littéralement ce qui suit:- le premier joueur est sur la case 45, il a 26 cartes de carottes et 2 cartes salade en main, le joueur ne manque pas un coup (f = faux). Le droit de bouger est toujours le premier joueur.
- le deuxième joueur sur la cellule 29 avec 19 cartes de carottes et sans cartes de salade, ne manque pas un coup.
- le chiffre deux signifie que, «décidant» l'étude, j'ai supposé que le deuxième joueur est dans une situation gagnante.
Après avoir mis 20 croquis dans le programme, je les ai «téléchargés» dans le client Web du jeu, puis triés chaque croquis. En analysant le croquis, j'ai alternativement fait des mouvements pour chacun des joueurs, jusqu'à ce que je décide du «gagnant». Ayant terminé l'évaluation, je l'ai envoyée dans une équipe spéciale au serveur.Après avoir évalué 20 études (bien sûr, il vaudrait la peine d'en analyser davantage), j'ai évalué chacune des études du programme. Dans l'évaluation, les valeurs de chacun des facteurs de correction, de 0,5 à 2 par incréments de 0,1 - total16 3 = 4096 variantes de triplets de coefficients. Si le score du premier joueur s'avérait supérieur au score du deuxième joueur et qu'une instruction similaire était stockée dans la ligne du dossier d'étude (la dernière valeur de la ligne est 1), le «hit» était compté. De même pour une situation miroir. Sinon, un glissement a été compté. En conséquence, j'ai choisi les triplets pour lesquels le pourcentage de «hits» était maximum (16 sur 20). Environ 250 des 4096 vecteurs sont sortis, dont j'ai sélectionné le «meilleur», encore une fois, «à l'œil», et l'ai installé dans les paramètres de l'IA.Résumé
En conséquence, j'ai obtenu un programme de travail, qui, en règle générale, me bat dans la version individuelle contre l'ordinateur. Les statistiques sérieuses de victoires et de défaites pour la version actuelle du programme ne se sont pas encore accumulées. Peut-être que le réglage ultérieur facile de l'IA rendra mes victoires impossibles. Ou presque impossible, car le facteur des cellules de lièvre demeure.Par exemple, dans la logique du choix des notes (maximum absolu ou maximum par rapport aux autres joueurs), j'essaierais certainement une option intermédiaire. Au minimum, si la valeur absolue du score du ième joueur est égale, il est raisonnable de choisir le mouvement menant à la position avec une valeur relative plus grande du score (un hybride du noble Leslie et du perfide Feith).Le programme est entièrement fonctionnel pour la version à 3 joueurs. Cependant, on soupçonne que la «qualité» des mouvements de l'IA pour jouer avec 3 joueurs est plus faible que pour jouer avec deux joueurs. Cependant, lors du dernier test, j'ai perdu contre l'ordinateur - peut-être par négligence, évaluant avec désinvolture la quantité de carottes dans mes mains et arrivant à la ligne d'arrivée avec un excès de «carburant».Jusqu'à présent, le développement de l'IA est entravé par le manque d'une personne - un «testeur», c'est-à-dire un adversaire vivant d'un «génie» informatique. J'ai moi-même joué assez de Hare et Hedgehog à la nausée et forcé d'interrompre au stade actuel.→ Lien vers le référentiel avec la source