Notre entrepôt, de la taille de deux carrés rouges et d'une hauteur de 5 étages, est ouvert toute l'année et ne dort jamais - 24/7 364 jours par an (le seul jour de congé est le 1er janvier). Nous avons stocké et entretenu plus de 8 000 000 de marchandises, chaque jour plus de 300 opérateurs changent. Ils travaillent avec des marchandises provenant du monde entier et collectent les commandes des utilisateurs de quatre pays: la Russie, l'Ukraine, la Biélorussie et le Kazakhstan. À une telle échelle, les affaires nécessitent une automatisation irréprochable.
Sous la coupe, moi, Pasha Finkelstein - chef d'équipe du développement et de l'automatisation de l'entrepôt - vous dirai ce qu'une solution open source peut développer si vous y attachez une bonne équipe de développement et une tâche commerciale très spécifique.

Logique de base
Trois processus principaux de tout entrepôt: l'acceptation des marchandises, leur stockage et leur expédition. Le cycle simplifié de notre entrepôt ressemble à ceci: identification primaire, contrôle qualité, placement, sélection et réservation pour une commande, recherche, tri, emballage, transfert vers un service de livraison. Lorsque le client retourne le produit, le cycle se répète. Chaque entité physique participant à ces processus a sa propre représentation informative, par exemple: camion, produit, cellule d'armoire, colis, matériel d'emballage, conteneur, etc. Tous les mouvements et changements importants dans le statut des marchandises sont traduits dans des systèmes comptables et absolument chaque action avec les marchandises à l'intérieur de l'entrepôt est enregistrée.
WMS (Warehouse Management System) contrôle le cycle de vie de chaque produit dans l'entrepôt, à partir du moment où le camion avec les marchandises du fournisseur arrive à l'entrepôt jusqu'à ce que les marchandises soient expédiées au client.

Les spécificités de l'automatisation de la mode
Notre entreprise travaille dans le domaine de la mode et du lifestyle, qui pose certaines tâches dans l'entrepôt: le produit peut être fragile (lunettes, montres), taille non standard (bottes d'hiver ou bijoux), premium (dans un emballage spécial) - ou posséder d'autres caractéristiques spécifiques qui l'entrepôt doit tenir compte. Par conséquent, il est impossible d'abandonner complètement l'utilisation du travail manuel dans les zones de stockage.

Tous les autres processus sont automatisés - acceptation des marchandises, transfert vers la zone d'expédition, tri, emballage et préparation de l'expédition. Chacun de ces processus nécessite un équipement spécial et un processus opérationnel. La magie se produit lorsque tous ces processus «se collent» et commencent à fonctionner ensemble - grâce à nos systèmes.
Toute surveillance de l'automatisation de l'entrepôt - que ce soit une interface qui contribue aux erreurs de l'opérateur, un processus non optimal, etc. - Il s'agit d'un retard d'expédition, du temps d'arrêt de l'ensemble du complexe, d'énormes pertes. De plus, à chaque erreur, nous créons une expérience client négative. Par conséquent, il est important pour nous que l'entrepôt fonctionne comme une horloge.
Open source et chemin vers son propre développement
Au stade de l'ouverture, nous avons utilisé un entrepôt externe. Avec la croissance des volumes, nous avons commencé à comprendre que nous avions besoin d'un contrôle total sur les processus opérationnels et d'un taux de changement élevé de ces processus, nous avons donc décidé de nous diriger vers notre propre entrepôt et développement.

La principale question qui nous a alors été posée était l'élaboration des processus opérationnels dans tous les détails. Jusqu'où et comment vont les employés, combien d'analyses ils font, etc. Et déjà sur ces processus, il était nécessaire de déployer WMS, qui gère les activités opérationnelles et automatise les opérations de routine.
Pour commencer, ils ont pris une solution open source en Java puis ont décidé de constituer leur propre équipe de développement, d'autant plus qu'il existe déjà une fondation adaptée. Nous avons augmenté les fonctionnalités, puis repris le cœur du système: nous nous sommes débarrassés de l'héritage et d'un gros client, avons effectué le refactoring, développé de nouveaux services pour soutenir les processus opérationnels.
Étapes d'automatisation
Les principaux changements ont été opérés par les «vagues» et la restructuration des processus eux-mêmes.
À ce jour, il est passé par neuf étapes de modernisation, et nous ne prévoyons pas de nous attarder sur cela.
- Aux première et deuxième étapes, nous avons automatisé les processus d'expédition des commandes - nous avons ajouté des convoyeurs, une logique de tri des marchandises, un tri automatisé des commandes par palettes.
- Dans les troisième et quatrième étapes, nous nous sommes concentrés sur les processus d'acceptation: nous avons appris à séparer les flux de marchandises entrantes par différents types et zones de stockage.
- La cinquième phase a ajouté des ascenseurs automatisés entre les étages - c'est ainsi que les travaux ont commencé dans la zone de stockage.
- La sixième phase a été la plus critique lorsque nous avons fermé les zones d'acceptation et d'expédition, parcourant toute l'automatisation.
- Dans les septième et huitième phases, nous avons apporté des modifications aux processus dans la zone d'acceptation et ajouté de nouvelles zones, ascenseurs et convoyeurs: nous avons mis à l'échelle l'automatisation existante.
- Dans la neuvième phase, ils ont ajouté un nouveau bâtiment à l'entrepôt et l'ont intégré au système d'automatisation existant.
Implémentation
Nos technologies de base: Java, Postgres, Wildfly, Redis, ActiveMQ.
WMS est écrit en Java 8. Mais il n'y a pas si longtemps, nous avons corrigé le dernier module, qui empêchait la transition vers Java 11, qui sera mis à jour dans un avenir proche.
Un rack de serveur installé directement dans l'entrepôt est réservé à WMS. Cela nous donne beaucoup plus de confiance que WMS fonctionnera même si l'électricité et / ou Internet sont coupés. La seule chose qui en souffrira, c'est que les messages adressés au système comptable seront retardés. WildFly est utilisé comme serveur d'applications, bien que ce ne soit pas encore la dernière version. La migration vers ce dernier est également prévue. Tout a déjà été écrit pour le déménagement, mais n'a pas encore réussi à effectuer des tests fonctionnels et de charge, et avant la nouvelle année, la charge est relativement élevée. Un ActiveMQ éprouvé est également utilisé.

Les données que nous stockons dans PostgreSQL. L'essence principale de notre système est évidemment un produit. Parfois, les employés de l'entrepôt proposent des solutions de contournement pour simplifier leur travail, par exemple, ils scannent le même code à barres 50 fois, et le produit lui-même est simplement jeté à la main sans scanner, sans entrer dans les détails, jeans ou T-shirts, nous avons donc entré des étiquettes identifiant une unité spécifique marchandises, en le soutenant dans l'infrastructure. Les informations sur ces unités sont stockées dans une base de données PostgreSQL de 2 téraoctets.
La majeure partie de la place y est occupée, même pas par des marchandises, mais par un audit des actions des magasiniers. Étant un système critique pour l'entreprise, l'entrepôt doit savoir pourquoi quelque chose est apparu dans le système ou a disparu - nous ne pouvons pas autoriser des changements non retracés. En ce moment, nous envisageons de prendre cette partie de la base de données dans une entité distincte dans MongoDB.
Les postes de travail du personnel d'entrepôt sont des clients Web légers. Quelque part au début de l'automatisation, tout cela fonctionnait selon le principe d'un client lourd, ce qui créait certaines difficultés, notamment avec les grandes versions, qui incluaient des changements d'interface: environ 150 postes de travail devaient être mis à jour manuellement. Cela et le fait que nous ne pouvions pas libérer sans temps d'arrêt nous ont fixé des limites - nous ne pouvions pas déployer plus de deux fois par semaine, tôt le matin, à la fin du quart de nuit, ce qui ne peut pas être appelé un horaire pratique. Nous avons maintenant transféré WMS sur le Web et d'ici la fin de l'année, nous abandonnerons complètement les gros clients, ce qui nous simplifiera considérablement les changements d'interface utilisateur. Le Web et la mise en cluster ajoutés à l'une des étapes suppriment les restrictions sur la fréquence et l'heure des versions - désormais, les utilisateurs ne se renseigneront sur les versions qu'en cas de problème.
Il y a aussi un «exotique» intéressant dans notre entrepôt. Par exemple, le Haskell mentionné dans
Technoradar , sur lequel le back-end de la visualisation du trieur d'articles est écrit (il s'agit d'une telle machine qui peut composer des marchandises à partir d'un seul colis et les remettre à l'opérateur d'assemblage). Il y a un problème purement informatique, qui est facilement résolu dans un style fonctionnel. Naturellement, personne n'utilisera Haskell pour des projets à grande échelle.
Un autre élément de l'entrepôt que nous avons mentionné dans l'
article sur Technoradar est une machine d'
état auto-écrite qui «surveille» la séquence correcte des actions avec chaque produit. Comme tout le système, il s'est développé de manière itérative, en commençant par un ensemble simple de contraintes. Maintenant, c'est une chose très pratique, profondément intégrée dans notre système. Nous espérons le mettre en
open source dans un proche avenir - il nous sera peut-être utile non seulement.
Équipements d'automatisation
Quelle automatisation sans équipement! L'ensemble de l'entrepôt est emmêlé dans tout un réseau de convoyeurs.
Le trieur d'articles mentionné ci-dessus fonctionne au stade de l'expédition, vous permettant de disposer des dizaines de milliers d'unités de marchandises collectées dans le stock pour des commandes spécifiques. À une certaine époque, le trieur a évité à nos opérateurs de devoir voyager avec un chariot dans l'entrepôt pour collecter les marchandises nécessaires. Les commandes sont réparties, chaque opérateur ne collecte les marchandises que depuis son étage (gain de temps lors du déplacement) et le trieur s'assure que les marchandises des différents étages passent automatiquement dans les bonnes commandes. La modification du processus opérationnel de 4 fois a accéléré le montage de la commande et réduit considérablement le nombre d'erreurs.
Tout l'équipement automatisé est fourni par notre partenaire. Pour la gestion des unités spécifiques, ils ont leur propre système, qui est situé dans le rack de serveur à côté de notre WMS. Entre les systèmes, l'intégration est configurée sur un protocole de haut niveau - nous communiquons via SOAP. À partir de nos processus opérationnels à l'intérieur de WMS, nous nous tournons vers leur système lorsque, par exemple, nous devons déplacer un conteneur de marchandises du point A au point B. du point de vue de notre système, toute cette automatisation semble assez simple, malgré sa réelle complexité interne.
Bien sûr, cette simplicité apparente n'a pas fonctionné tout de suite. Aux premières étapes de l'automatisation, nous avons eu un «broyage mutuel» des technologies. Une fois que le convoyeur a littéralement brûlé nos marchandises - la vitesse de la bande transporteuse était trop élevée, il a «mâché» les marchandises et il a brûlé, ce qui a bloqué le montage d'autres commandes. L'histoire la plus difficile s'est peut-être produite au début de l'automatisation, lorsque nous avons lancé la première phase. Hier, l'entrepôt était entièrement manuel et aujourd'hui, après avoir commuté l'interrupteur, il devrait devenir automatique. Mais rien n'a fonctionné: en raison d'une erreur dans l'intégration du système, les messages des uns et des autres ont été interprétés de manière incorrecte, ce qui s'est traduit par plusieurs jours d'indisponibilité de l'entrepôt et des millions de pertes pour nous.
Maintenant, le partenaire est présent dans notre entrepôt, prévoit d'organiser l'équipement avec nous lorsqu'il s'agit d'une nouvelle série d'automatisation, aide à tester de nouveaux blocs.
Équipe et scrumban
Le développement de l'ensemble de ce système est désormais engagé dans une équipe de 12 personnes. À l'une des dernières étapes de l'apogée de la modernisation, lorsque des processus automatisés séparément devaient être combinés en quelque chose d'entier, jusqu'à 20 développeurs à eux seuls ont participé (cette étape a nécessité 132 hommes-mois et inclus plus de 1500 commits). Mais à la fin des transformations à grande échelle, certaines personnes ont décidé d'apprendre Go ou Python et sont passées à d'autres équipes de développement.
Dans l'équipe, nous avons des chefs de projet «classiques» qui combinent les fonctions d'un produit et d'un projet informatique (en moyenne, un PM pour 5-6 personnes). Ses tâches incluent la communication avec notre principal client - un entrepôt représenté par son directeur et le département de développement des processus opérationnels. Pour notre part, nous nous préoccupons davantage de la modernisation technique - choisir la bonne pile, les mises à jour, etc. - Et les gars de l'entrepôt réfléchissent à l'optimisation des processus.
Parfois, nous consacrons nous-mêmes du temps à la R&D sur le terrain. Dans le sens littéral, nous arrivons à l'entrepôt, communiquons avec les équipes supérieures, avec les opérateurs ordinaires, et clarifions les problèmes qu'ils rencontrent, ce qui est pratique et peu pratique pour travailler. En d'autres termes, nous effectuons des recherches sur l'expérience utilisateur.
Grâce à cette approche, par exemple, nous avons transformé l'interface du lieu de travail d'un employé qui effectue la réception des marchandises. Au départ, c'était une interface d'entreprise complexe avec de nombreux champs, boutons et abréviations au lieu d'explications textuelles. Mais nous avons essayé d'optimiser le processus, ainsi que la conception, en la rendant plus similaire à la page de recherche Google principale - pas si belle, mais très fonctionnelle. Plus l'interface est simple et moins l'opérateur dispose d'options, où cliquer et quoi numériser, moins il y a d'erreurs (et le temps nécessaire pour les corriger).
Et les connaissances accumulées sur l’optimisation des détails nous dépassent maintenant aux moments les plus inattendus: une fois que notre équipe était dans l’institution et à un moment donné, presque tous les participants ont regardé la séquence des actions du caissier. Après environ 40 secondes, un collègue a exprimé l'idée générale: "Pas de manière très optimale, vous pouvez le simplifier."
Bien que la relation entre les rôles dans l'équipe soit assez classique, nous avons choisi un scrumban pour la méthodologie de développement.
Nous avons beaucoup expérimenté les méthodologies, tandis que les données «d'entrée» n'étaient pas standard. Par exemple, nous avons eu des versions plutôt rares. La restriction susmentionnée de deux versions par semaine a agi de la part des processus, mais en fait, nous avons déployé beaucoup moins souvent - en moyenne une fois toutes les deux semaines. De plus, nous avions un matériel d'automatisation d'entrepôt, qui est développé par une entreprise externe pour une cascade propre, où tous les changements sont prévus deux ans à l'avance avec toute la documentation nécessaire. Cependant, nous ne pouvions pas nous-mêmes suivre leur exemple: nous devions apporter régulièrement des modifications au système, et forcer le client à écrire une tâche détaillée pour chacun d'eux était inutile.
Le scrumban est donc un compromis qui a rendu tout le monde heureux. Nous utilisons un processus itératif, mais le sprint est la version qui nous convient. Une fois par mois, nous rencontrons le client et planifions les versions: nous discutons de quoi et de quelle semaine nous déployons. À l'intérieur du sprint, le kanban est implémenté - avec un arriéré de tâches, de progrès, etc. Certes, ce processus évolue progressivement - par exemple, nous n'avons pas de tableau kanban. Juste au moment où un développeur termine sa tâche, il reçoit le suivant du pool conformément aux plans de la prochaine version et aux compétences du développeur.
Nous aimons cette approche. Il offre la flexibilité nécessaire dans les itérations et donne au client professionnel la prévisibilité des dates auxquelles certains commits seront mis en œuvre. Et il n'est pas si important pour nous que cette méthodologie soit appelée. L'essentiel est que tout fonctionne.
Pas comme tout le monde - en utilisant l'inventaire et la surveillance comme exemple
En développant des processus opérationnels, nous sommes partis des besoins de notre industrie, nous avons donc pas mal de fonctionnalités individuelles.
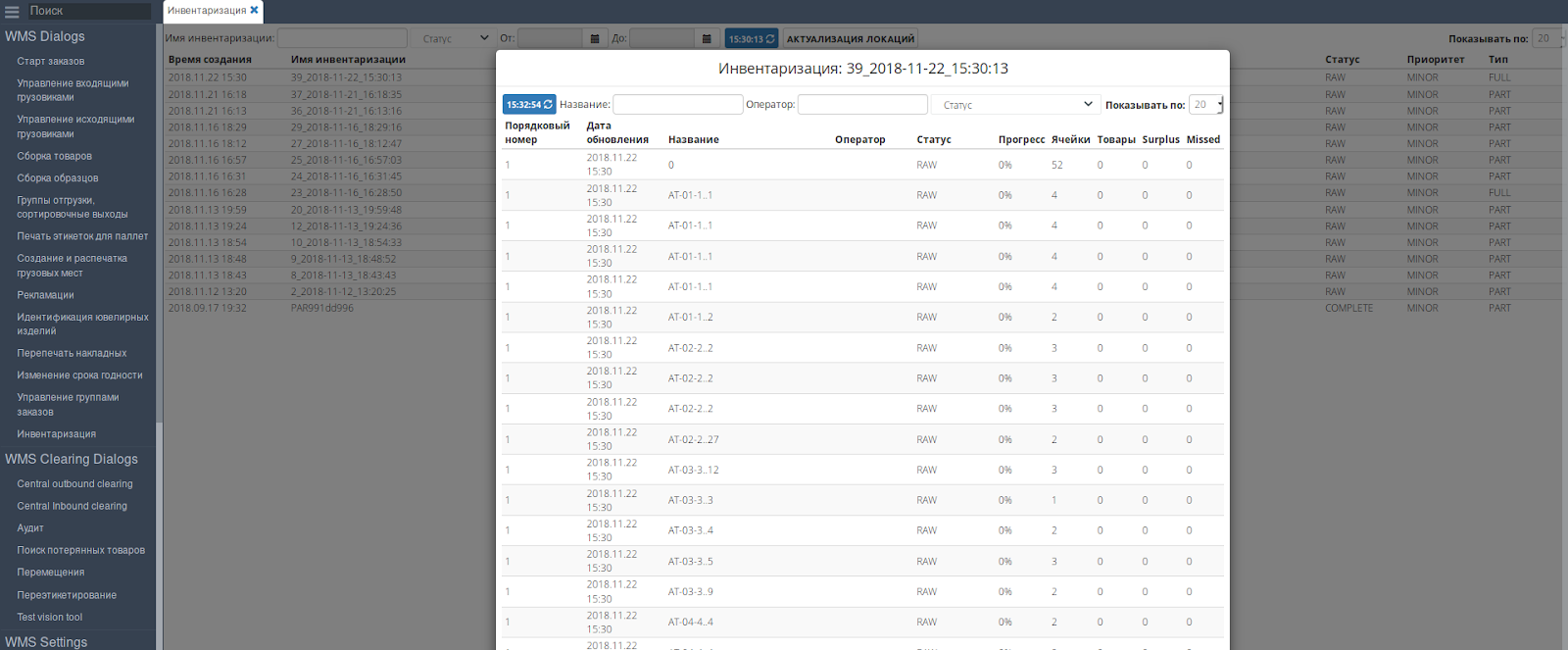
Un bon exemple est un inventaire. Selon la loi, elle doit être effectuée à l'entrepôt une fois par an, mais nos exigences commerciales déterminent un suivi plus étroit du stock. Premièrement, nous voulons refléter des informations pertinentes sur la disponibilité des produits sur le site Web, et deuxièmement, nos partenaires B2B, les marques de mode ont besoin des mêmes informations pertinentes. Par conséquent, un inventaire a lieu quotidiennement, 364 jours par an, étagère après étagère dans l'ensemble du complexe de 5 étages de plusieurs bâtiments. Et ce processus est entièrement pris en charge par notre WMS - il serait difficile de mettre en œuvre une telle solution.
Désormais, l'inventaire est en cours de mise à jour pour augmenter l'efficacité de ce processus.

Un autre exemple de notre propre développement est le suivi. Il est implémenté via un client Web et vous permet d'afficher et de suivre des métriques très intéressantes. De plus, une représentation visuelle de ces métriques est importante pour nous. En fait, la surveillance est un entrepôt représenté dans un calendrier simple, où nous voyons clairement à quels endroits tout fonctionne bien et où les problèmes sont observés (jusqu'à un opérateur spécifique). Plus important encore, avec ce point de vue, nous pouvons comprendre pourquoi ces problèmes se posent.
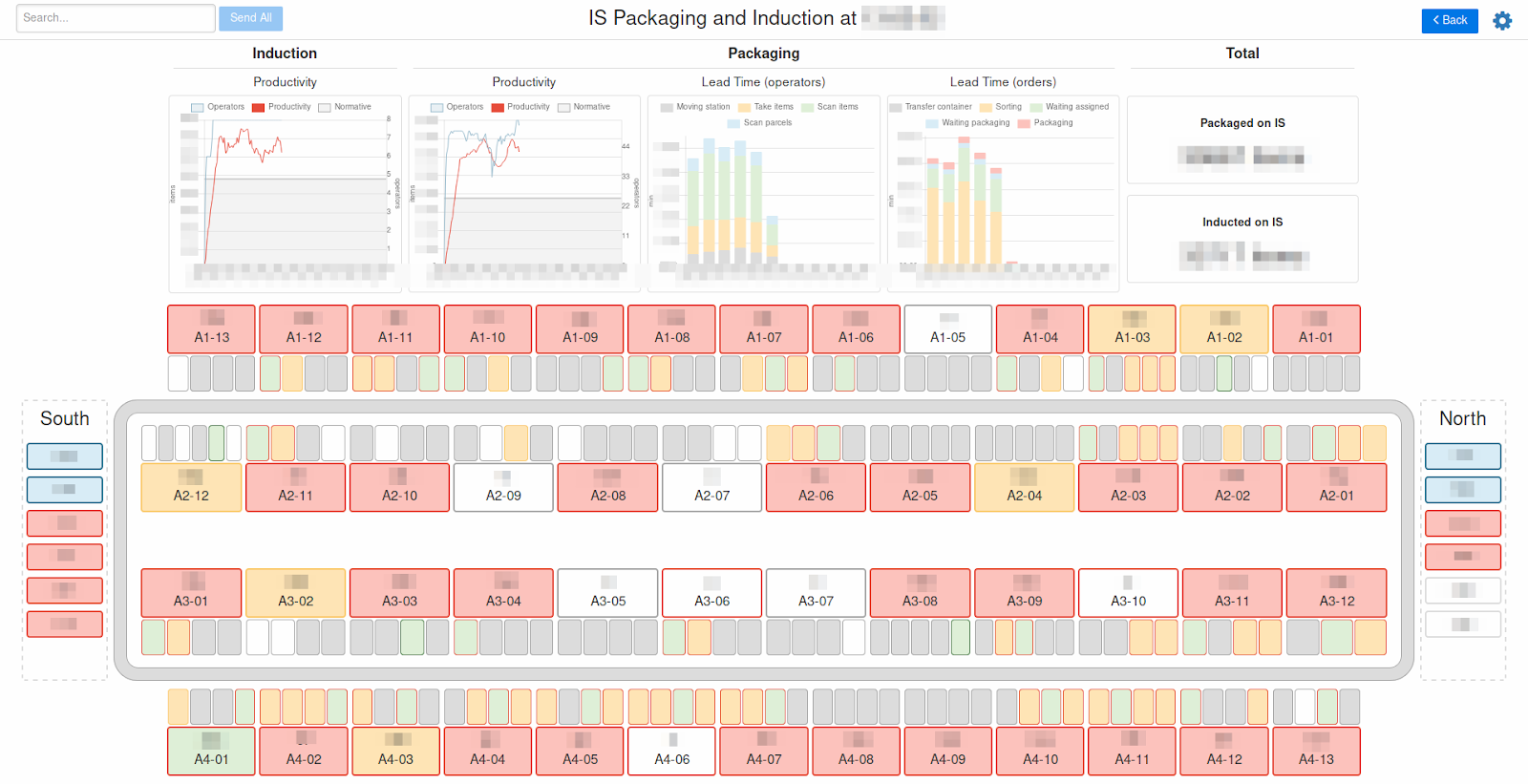
KPI Warehouse Workers et Redis
L'introduction de nouvelles technologies, de mises à jour, de refactoring - tout est génial. Mais notre WMS fonctionne dans les affaires réelles, nous devons donc résoudre non seulement ces problèmes. Une partie de notre travail est la protection contre les «pirates» internes - des employés d'entrepôt ingénieux qui inventent de nouvelles façons d'exécuter les KPI en contournant la tâche.
Par exemple, il n'y a pas si longtemps, nous avons été obligés d'ajouter Redis à la pile pour empêcher les utilisateurs de se connecter au système à partir de plusieurs postes de travail en même temps et d'implémenter un délai d'expiration de session. Le fait est que les employés de l'entrepôt ont réalisé que travailler avec la même connexion et recevoir une prime pour avoir dépassé le KPI est beaucoup plus rentable que d'augmenter leur propre productivité.
Étant donné que la résolution du problème commercial nécessitait des changements à divers endroits du système, d'un point de vue technique, c'était un défi très intéressant.
Les surprises du personnel de l'entrepôt ne s'arrêtent pas là. Presque immédiatement après la sortie de la session, PostgreSQL a commencé à planter. Nous avons recherché les raisons de la dégradation inattendue de la base pendant plusieurs jours, jusqu'à ce que nous constations que la question, encore une fois, était l'ingéniosité. Une fille allait souvent fumer. Lorsqu'elle a quitté le lieu de travail, elle a été éliminée de la session et pour se reconnecter, il a été nécessaire de retrouver le quart supérieur et de scanner son badge. Réduisant ses errances dans l'entrepôt, elle a simplement déchiré le code à barres de l'un des chariots et fixé le bouton du scanner avec du ruban adhésif, le réglant pour scanner constamment ce code à barres. Et cela pourrait passer inaperçu pendant longtemps si le code-barres ne provenait pas du chariot, qui contenait 800 unités de marchandises. À chaque analyse, une énorme requête SQL a été générée pour valider les marchandises, ce qui a «tué» la base de données avec de tels «DDoS internes». J'ai dû faire attention aux restrictions sur le nombre de scans par unité de temps et sur le nombre de marchandises dans le chariot.
Il y a déjà pas mal d'histoires de ce type et nous en sommes constamment confrontés à de nouvelles. De plus, le système doit s'adapter à chaque fois à de nouvelles conditions. Dans de telles situations, on ne peut pas se limiter uniquement aux méthodes administratives - ce qui s'est produit une fois peut très bien se répéter.

Où allons-nous ensuite?
Il semble impossible d'optimiser les processus et l'automatisation des entrepôts. Cela dure 5 ans dans l'entreprise, et, comme je l'ai dit plus haut, même après l'étape 9, on ne va pas s'arrêter. La société continue de se développer à la fois en B2C et en B2B, donc dans un proche avenir, nous prévoyons un autre grand projet - l'ouverture d'un autre entrepôt, cela nécessitera soit une réécriture à grande échelle du système existant, soit la création d'un système similaire à partir de zéro dans un nouvel endroit. Et c'est un nouveau défi intéressant à la jonction des affaires, des installations physiques, des processus opérationnels et des solutions techniques.